Catalogue of series articles
Practical data Lake iceberg lesson 1 Introduction
Practical data Lake iceberg lesson 2 iceberg underlying data format based on hadoop
Practice data Lake iceberg lesson 3 in sql client, read data from kafka to iceberg in sql
Practice data Lake iceberg lesson 4 in sql client, read data from kafka to iceberg in sql (upgrade to Flink 1.12.7)
Practical data Lake iceberg lesson 5 hive catalog features
Practical data Lake iceberg Lesson 6 writing from kafka to iceberg failure problem solving
Practical data Lake iceberg Lesson 7 real-time writing to iceberg
Practical data Lake iceberg Lesson 8 hive and iceberg integration
Practical data Lake iceberg Lesson 9 merging small files
Practice data Lake iceberg Lesson 10 snapshot deletion
Practice data Lake iceberg Lesson 11 test the complete process of partition table (making data, building tables, merging, deleting snapshots)
Practical data Lake iceberg Lesson 12 what is catalog
preface
Test the small file merging and snapshot deletion of the partition table to see the impact on the partition table
Simulated production environment
Test architecture: Log - > Kafka - > Flink - > iceberg
1. Manufacturing data
1.1 generate data
Requirements: the generated id range, generated data frequency and data date can be configured
package org.example;
import java.util.Calendar;
import java.util.Random;
/**
* Generate log
*
*/
public class GenerateLogWithDate
{
public static void main( String[] args ) throws InterruptedException {
if(args.length !=5){
System.out.println("<generate id Scope 1-?><Pause duration of each data in milliseconds><date yyyy><MM 0 start><dd>");
System.exit(0);
}
int len = 100000;
int sleepMilis = 1000;
Calendar cal = null;
// System. out. Println ("< generation id range > < pause duration of each data in milliseconds >);
if(args.length == 1){
len = Integer.valueOf(args[0]);
}
if(args.length == 2){
len = Integer.valueOf(args[0]);
sleepMilis = Integer.valueOf(args[1]);
}
if(args.length == 5){
cal = Calendar.getInstance();
int year = Integer.valueOf(args[2]);
int month = Integer.valueOf(args[3]);
int day = Integer.valueOf(args[4]);
cal.set(year,month,day);
}
Random random = new Random();
for(int i=0; i<10000000; i++){
System.out.println(i+"," + random.nextInt(len)+","+ Calendar.getInstance().getTimeInMillis() );
Thread.sleep(sleepMilis);
}
}
}
Package and run, and the effect is as follows:
[root@hadoop101 software]# java -jar log-generater-1.0-SNAPSHOT.jar 100000 1000 2022 0 20 0,54598,1643341060767 1,71915,1643341061768 2,69469,1643341062768 3,7125,1643341063768
java -jar /opt/software/log-generater-1.0-SNAPSHOT.jar 100000 1000 2022 0 20 > /opt/module/logs/withDateFileToKakfa.log [root@hadoop102 ~]# java -jar /opt/software/log-generater-1.0-SNAPSHOT.jar 100000 10 2022 0 27 > /opt/module/logs/withDateFileToKakfa.log Replacement date: [root@hadoop102 ~]# java -jar /opt/software/log-generater-1.0-SNAPSHOT.jar 1000000 1 2022 0 27 >> /opt/module/logs/withDateFileToKakfa.log [root@hadoop102 ~]# java -jar /opt/software/log-generater-1.0-SNAPSHOT.jar 1000000 1 2022 0 26 >> /opt/module/logs/withDateFileToKakfa.log [root@hadoop102 ~]# java -jar /opt/software/log-generater-1.0-SNAPSHOT.jar 1000000 1 2022 0 29 >> /opt/module/logs/withDateFileToKakfa.log
1.2 log->flume->kafka
First create topic behavior in kafka_ with_ date_ log.
flume agent configuration:
As a channel, kafka has no sink
cd $FLUME_HOME/conf
vim with-date-file-to-kafka.conf
a1.sources = r1 a1.channels = c1 a1.sources.r1.type = TAILDIR a1.sources.r1.positionFile = /var/log/flume/withDate_taildir_position.json a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/module/logs/withDateFileToKakfa.log a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.channels.c1.kafka.topic = behavior_with_date_log a1.channels.c1.kafka.consumer.group.id = flume-consumer2 #Bind the relationship between source and channel and sink and channel a1.sources.r1.channels = c1
Prepare startup and shutdown agent script:
[root@hadoop102 bin]# cat flumeWithDate.sh
#! /bin/bash
case $1 in
"start"){
for i in hadoop102
do
echo " --------start-up $i flume with-date-file-to-kafka.conf -------"
ssh $i "source /etc/profile;cd /opt/module/flume; nohup flume-ng agent --conf conf --conf-file conf/with-date-file-to-kafka.conf --name a1 -Dflume.root.logger=INFO,console >/opt/module/flume/logs/with-date-file-to-kafka.conf 2>&1 &"
done
};;
"stop"){
for i in hadoop102
do
echo " --------stop it $i flume with-date-file-to-kafka.conf -------"
ssh $i "ps -ef | grep with-date-file-to-kafka.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
done
};;
esac
Start agent
[root@hadoop102 bin]# flumeWithDate.sh start --------start-up hadoop102 flume with-date-file-to-kafka.conf ------- /etc/profile: line 49: HISTCONTROL: readonly variable
Check whether the data enters kafka
Discovery: I did go in
Consumption come out and have a look
[root@hadoop103 ~]# kafka-console-consumer.sh --topic behavior_with_date_log --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --from-beginning 4129299,24977,1643354586164 4129302,18826,1643354586465 4129255,98763,1643354581760 4129258,68045,1643354582060 4129261,42309,1643354582361 4129264,25737,1643354582661 4129267,63120,1643354582961 4129270,62009,1643354583261 4129273,36358,1643354583562 4129276,18414,1643354583862 4129279,73156,1643354584162 4129282,80180,1643354584463
2. Establish and test partition table
2.1 start Flink SQL
[root@hadoop101 ~]# sql-client.sh embedded -j /opt/software/iceberg-flink-runtime-0.12.1.jar -j /opt/software/flink-sql-connector-hive-2.3.6_2.12-1.12.7.jar -j /opt/software/flink-sql-connector-kafka_2.12-1.12.7.jar shell
2.2 build hiveCatalog
Continue using hiveDatalog6
You need to create a catalog every time you use it
Create catalog script:
CREATE CATALOG hive_catalog6 WITH ( 'type'='iceberg', 'catalog-type'='hive', 'uri'='thrift://hadoop101:9083', 'clients'='5', 'property-version'='1', 'warehouse'='hdfs:///user/hive/warehouse/hive_catalog6' );
Each catalog of database is shared
use catalog hive_catalog6;
create database iceberg_db6;
2.3 zoning table
CREATE TABLE hive_catalog6.iceberg_db6.behavior_with_date_log_ib ( i STRING, id STRING,otime STRING,dt STRING ) PARTITIONED BY ( dt )
View generated directories
[root@hadoop103 ~]# hadoop fs -ls -R /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/ drwxr-xr-x - root supergroup 0 2022-01-28 16:19 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/metadata -rw-r--r-- 2 root supergroup 1793 2022-01-28 16:19 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/metadata/00000-cbb96f75-6438-4cfd-8c09-9da953af8519.metadata.json
drop table matters:
The file under metadata will be deleted, and the directory from this table to medata will be retained!
Will be saved to the following directory:
/user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/metadata
3. Write the behavior data of kafka into the partition table
3.1 define kafka table as csv type (failed)
Define table as csv type
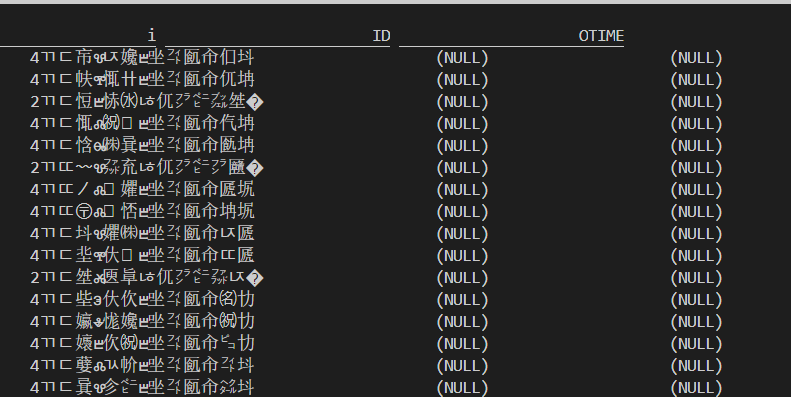
create table behavior_with_date_log ( i STRING,ID STRING,OTIME STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'behavior_with_date_log', 'properties.bootstrap.servers' = 'hadoop101:9092,hadoop102:9092,hadoop103:9092', 'properties.group.id' = 'rickGroup6', 'scan.startup.mode' = 'earliest-offset', 'csv.field-delimiter'=',', 'csv.ignore-parse-errors' = 'true', 'format' = 'csv' ) Each field is defined as STRING, It turns out that the front is garbled, and the last two fields are both null,What's the reason?
Each field is defined as STRING. It turns out that the front is garbled and the last two fields are null. Why?
No 'CSV Ignore parse errors' = 'true', the display is still NULL
Is there a problem with the separator? I copy the log separator directly to the table creation statement and rebuild it. It's still the same
Use Kafka console consumer There is no problem with direct consumption
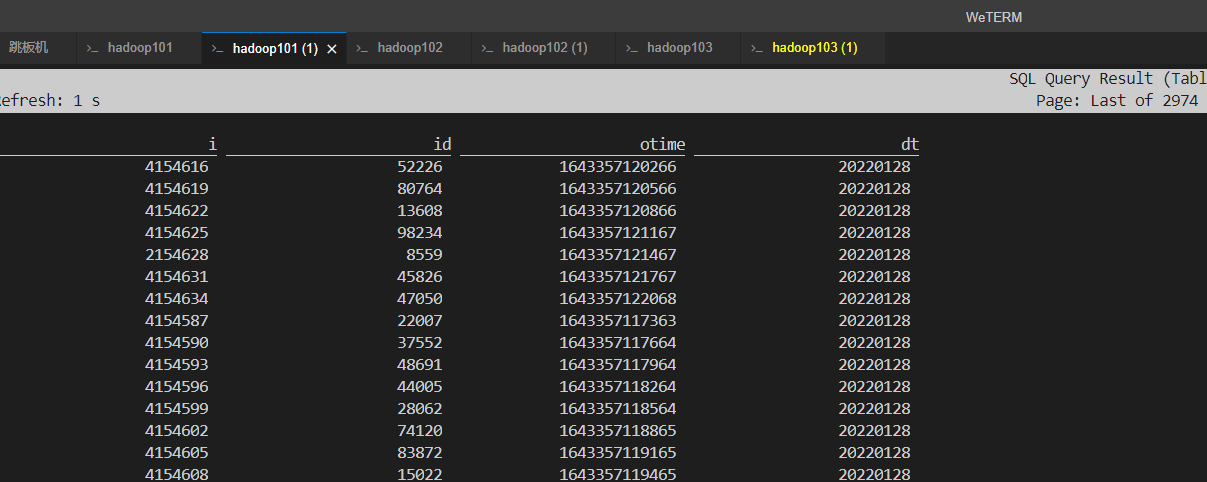
kafka-console-consumer.sh --topic behavior_with_date_log --bootstrap-server hadoop101:9092,hadoop102:9092,hadoop103:9092 --from-beginning 4132950,38902,1643354951608 4132903,27044,1643354946904 4132906,17342,1643354947204 4132909,42787,1643354947504 4132912,70169,1643354947805 4132915,68492,1643354948105 4132918,38690,1643354948405 4132921,53191,1643354948705 4132924,82465,1643354949006
Delete table rebuild statement:
drop table behavior_with_date_log
In fact, the table can be defined as raw type, but there is no built-in split function in flash SQL. With built-in split_index function, why can't show functions find split_index function?
3.2 define kafka table as raw type (successful)
create table behavior_with_date_log ( log STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'behavior_with_date_log', 'properties.bootstrap.servers' = 'hadoop101:9092,hadoop102:9092,hadoop103:9092', 'properties.group.id' = 'rickGroup6', 'scan.startup.mode' = 'earliest-offset', 'format' = 'raw' )
Flink SQL>
create table behavior_with_date_log
(
log STRING
) WITH (
'connector' = 'kafka',
'topic' = 'behavior_with_date_log',
'properties.bootstrap.servers' = 'hadoop101:9092,hadoop102:9092,hadoop103:9092',
'properties.group.id' = 'rickGroup6',
'scan.startup.mode' = 'earliest-offset',
'format' = 'raw'
);
[INFO] Table has been created.
sql syntax:
select split_index('4135009,73879,1643355157701',',',0), split_index('4135009,73879,1643355157701',',',1),split_index('4135009,73879,1643355157701',',',2);
SELECT TO_TIMESTAMP(FROM_UNIXTIME(1513135677000 / 1000, 'yyyy-MM-dd'));
etl the kafka original log and add the dt field. The sql is as follows:
select split_index(log,',',0) as i, split_index(log,',',1) as id,split_index(log,',',2) as otime , from_unixtime(cast(cast(split_index(log,',',2) as bigint)/1000 as bigint),'yyyyMMdd') as dt from behavior_with_date_log ;
3.3 sql for converting kafka table to partition table
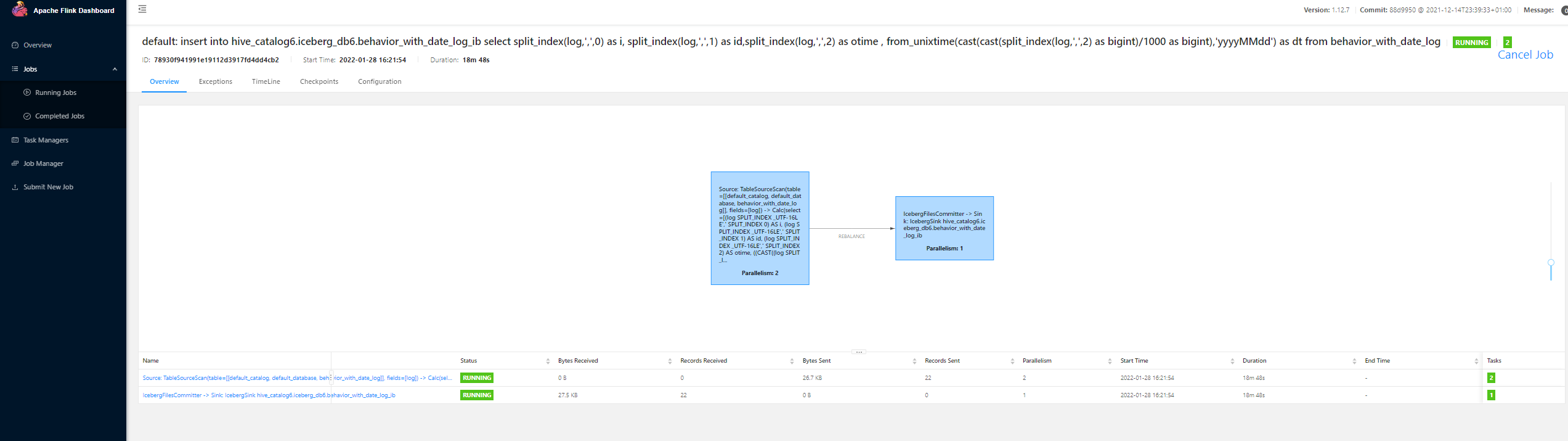
insert into hive_catalog6.iceberg_db6.behavior_with_date_log_ib select split_index(log,',',0) as i, split_index(log,',',1) as id,split_index(log,',',2) as otime , from_unixtime(cast(cast(split_index(log,',',2) as bigint)/1000 as bigint),'yyyyMMdd') as dt from behavior_with_date_log ;
3.4 actually execute sql summary in Flink sql
[root@hadoop101 ~]# sql-client.sh embedded -j /opt/software/iceberg-flink-runtime-0.12.1.jar -j /opt/software/flink-sql-connector-hive-2.3.6_2.12-1.12.7.jar -j /opt/software/flink-sql-connector-kafka_2.12-1.12.7.jar shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/module/flink-1.12.7/lib/log4j-slf4j-impl-2.16.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/module/hadoop-2.7.2/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
No default environment specified.
Searching for '/opt/module/flink-1.12.7/conf/sql-client-defaults.yaml'...found.
Reading default environment from: file:/opt/module/flink-1.12.7/conf/sql-client-defaults.yaml
No session environment specified.
Command history file path: /root/.flink-sql-history
▒▓██▓██▒
▓████▒▒█▓▒▓███▓▒
▓███▓░░ ▒▒▒▓██▒ ▒
░██▒ ▒▒▓▓█▓▓▒░ ▒████
██▒ ░▒▓███▒ ▒█▒█▒
░▓█ ███ ▓░▒██
▓█ ▒▒▒▒▒▓██▓░▒░▓▓█
█░ █ ▒▒░ ███▓▓█ ▒█▒▒▒
████░ ▒▓█▓ ██▒▒▒ ▓███▒
░▒█▓▓██ ▓█▒ ▓█▒▓██▓ ░█░
▓░▒▓████▒ ██ ▒█ █▓░▒█▒░▒█▒
███▓░██▓ ▓█ █ █▓ ▒▓█▓▓█▒
░██▓ ░█░ █ █▒ ▒█████▓▒ ██▓░▒
███░ ░ █░ ▓ ░█ █████▒░░ ░█░▓ ▓░
██▓█ ▒▒▓▒ ▓███████▓░ ▒█▒ ▒▓ ▓██▓
▒██▓ ▓█ █▓█ ░▒█████▓▓▒░ ██▒▒ █ ▒ ▓█▒
▓█▓ ▓█ ██▓ ░▓▓▓▓▓▓▓▒ ▒██▓ ░█▒
▓█ █ ▓███▓▒░ ░▓▓▓███▓ ░▒░ ▓█
██▓ ██▒ ░▒▓▓███▓▓▓▓▓██████▓▒ ▓███ █
▓███▒ ███ ░▓▓▒░░ ░▓████▓░ ░▒▓▒ █▓
█▓▒▒▓▓██ ░▒▒░░░▒▒▒▒▓██▓░ █▓
██ ▓░▒█ ▓▓▓▓▒░░ ▒█▓ ▒▓▓██▓ ▓▒ ▒▒▓
▓█▓ ▓▒█ █▓░ ░▒▓▓██▒ ░▓█▒ ▒▒▒░▒▒▓█████▒
██░ ▓█▒█▒ ▒▓▓▒ ▓█ █░ ░░░░ ░█▒
▓█ ▒█▓ ░ █░ ▒█ █▓
█▓ ██ █░ ▓▓ ▒█▓▓▓▒█░
█▓ ░▓██░ ▓▒ ▓█▓▒░░░▒▓█░ ▒█
██ ▓█▓░ ▒ ░▒█▒██▒ ▓▓
▓█▒ ▒█▓▒░ ▒▒ █▒█▓▒▒░░▒██
░██▒ ▒▓▓▒ ▓██▓▒█▒ ░▓▓▓▓▒█▓
░▓██▒ ▓░ ▒█▓█ ░░▒▒▒
▒▓▓▓▓▓▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒▒░░▓▓ ▓░▒█░
______ _ _ _ _____ ____ _ _____ _ _ _ BETA
| ____| (_) | | / ____|/ __ \| | / ____| (_) | |
| |__ | |_ _ __ | | __ | (___ | | | | | | | | |_ ___ _ __ | |_
| __| | | | '_ \| |/ / \___ \| | | | | | | | | |/ _ \ '_ \| __|
| | | | | | | | < ____) | |__| | |____ | |____| | | __/ | | | |_
|_| |_|_|_| |_|_|\_\ |_____/ \___\_\______| \_____|_|_|\___|_| |_|\__|
Welcome! Enter 'HELP;' to list all available commands. 'QUIT;' to exit.
Flink SQL> CREATE CATALOG hive_catalog6 WITH (
> 'type'='iceberg',
> 'catalog-type'='hive',
> 'uri'='thrift://hadoop101:9083',
> 'clients'='5',
> 'property-version'='1',
> 'warehouse'='hdfs:///user/hive/warehouse/hive_catalog6'
> );
2022-01-28 16:20:20,351 INFO org.apache.hadoop.hive.conf.HiveConf [] - Found configuration file file:/opt/module/hive/conf/hive-site.xml
2022-01-28 16:20:20,574 WARN org.apache.hadoop.hive.conf.HiveConf [] - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
[INFO] Catalog has been created.
Flink SQL> create table behavior_with_date_log
> (
> log STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'behavior_with_date_log',
> 'properties.bootstrap.servers' = 'hadoop101:9092,hadoop102:9092,hadoop103:9092',
> 'properties.group.id' = 'rickGroup6',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'raw'
> )
> ;
[INFO] Table has been created.
Flink SQL> insert into hive_catalog6.iceberg_db6.behavior_with_date_log_ib
> select split_index(log,',',0) as i, split_index(log,',',1) as id,split_index(log,',',2) as otime , from_unixtime(cast(cast(split_index(log,',',2) as bigint)/1000 as bigint),'yyyyMMdd') as dt from behavior_with_date_log ;
[INFO] Submitting SQL update statement to the cluster...
[INFO] Table update statement has been successfully submitted to the cluster:
Job ID: 78930f941991e19112d3917fd4dd4cb2
4. Repeat steps 1 and 3 to generate data for multiple days
Output file:
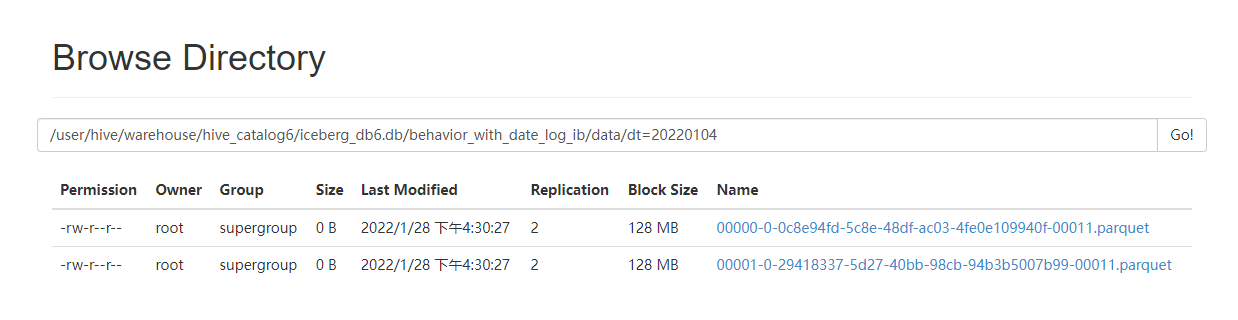
After 1 minute:
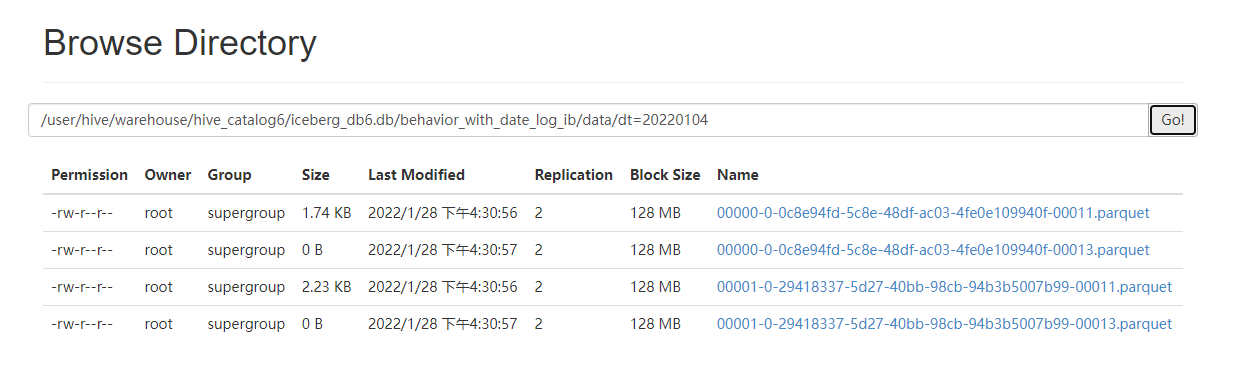
Why 2 files per minute?
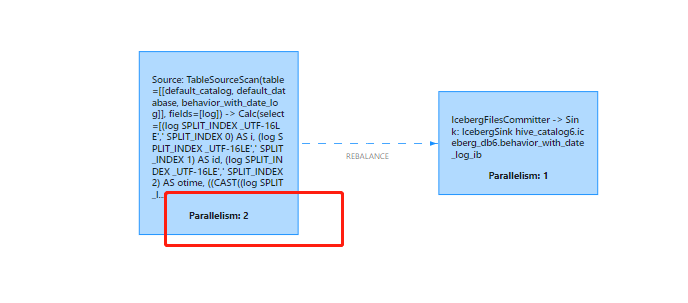
5. Merge small files and observe
Count the number of small files first
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data Found 6 items drwxr-xr-x - root supergroup 0 2022-01-28 17:36 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=19700101 drwxr-xr-x - root supergroup 0 2022-01-28 16:36 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220104 drwxr-xr-x - root supergroup 0 2022-01-28 17:30 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220126 drwxr-xr-x - root supergroup 0 2022-01-28 17:29 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220127 drwxr-xr-x - root supergroup 0 2022-01-28 16:29 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128 drwxr-xr-x - root supergroup 0 2022-01-28 17:37 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220129
Data file No. 28:
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128
Found 18 items
-rw-r--r-- 2 root supergroup 441875 2022-01-28 16:22 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00001.parquet
-rw-r--r-- 2 root supergroup 2842 2022-01-28 16:23 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00003.parquet
-rw-r--r-- 2 root supergroup 2819 2022-01-28 16:24 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00004.parquet
-rw-r--r-- 2 root supergroup 2833 2022-01-28 16:25 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00005.parquet
-rw-r--r-- 2 root supergroup 2801 2022-01-28 16:26 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00006.parquet
-rw-r--r-- 2 root supergroup 2824 2022-01-28 16:27 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00007.parquet
-rw-r--r-- 2 root supergroup 2802 2022-01-28 16:28 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00008.parquet
-rw-r--r-- 2 root supergroup 2781 2022-01-28 16:29 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00009.parquet
-rw-r--r-- 2 root supergroup 2000 2022-01-28 16:30 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00000-0-0c8e94fd-5c8e-48df-ac03-4fe0e109940f-00010.parquet
-rw-r--r-- 2 root supergroup 882110 2022-01-28 16:22 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00001.parquet
-rw-r--r-- 2 root supergroup 4385 2022-01-28 16:23 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00003.parquet
-rw-r--r-- 2 root supergroup 4364 2022-01-28 16:24 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00004.parquet
-rw-r--r-- 2 root supergroup 4383 2022-01-28 16:25 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00005.parquet
-rw-r--r-- 2 root supergroup 4340 2022-01-28 16:26 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00006.parquet
-rw-r--r-- 2 root supergroup 4357 2022-01-28 16:27 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00007.parquet
-rw-r--r-- 2 root supergroup 4347 2022-01-28 16:28 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00008.parquet
-rw-r--r-- 2 root supergroup 4340 2022-01-28 16:29 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00009.parquet
-rw-r--r-- 2 root supergroup 2688 2022-01-28 16:30 /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128/00001-0-29418337-5d27-40bb-98cb-94b3b5007b99-00010.parquet
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128 |wc
19 147 3813
In the number of files, the last line above 19-1 = 18 is 18 files.
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=19700101 |wc
43 339 8877
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220104 |wc
17 131 3391
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220126 |wc
5 35 858
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220127 |wc
109 867 22804
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220128 |wc
19 147 3813
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220129 |wc
21 163 4235
The data on the 29th is still being written:
[root@hadoop103 ~]# hadoop fs -ls /user/hive/warehouse/hive_catalog6/iceberg_db6.db/behavior_with_date_log_ib/data/dt=20220129 |wc
23 179 4657
6. Merge and delete old snapshots and observe
Not finished..., Continue after years...
Caused by: javax.jdo.JDOFatalUserException: Class org.datanucleus.api.jdo.JDOPersistenceManagerFactory was not found. NestedThrowables: java.lang.ClassNotFoundException: org.datanucleus.api.jdo.JDOPersistenceManagerFactory at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java:1175) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:808) at javax.jdo.JDOHelper.getPersistenceManagerFactory(JDOHelper.java:701) at org.apache.hadoop.hive.metastore.ObjectStore.getPMF(ObjectStore.java:521) at org.apache.hadoop.hive.metastore.ObjectStore.getPersistenceManager(ObjectStore.java:550) at org.apache.hadoop.hive.metastore.ObjectStore.initializeHelper(ObjectStore.java:405) at org.apache.hadoop.hive.metastore.ObjectStore.initialize(ObjectStore.java:342) at org.apache.hadoop.hive.metastore.ObjectStore.setConf(ObjectStore.java:303) at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:76) at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:136) at org.apache.hadoop.hive.metastore.RawStoreProxy.<init>(RawStoreProxy.java:58) at org.apache.hadoop.hive.metastore.RawStoreProxy.getProxy(RawStoreProxy.java:67) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.newRawStoreForConf(HiveMetaStore.java:628) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMSForConf(HiveMetaStore.java:594) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.getMS(HiveMetaStore.java:588) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.createDefaultDB(HiveMetaStore.java:659) at org.apache.hadoop.hive.metastore.HiveMetaStore$HMSHandler.init(HiveMetaStore.java:431) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.hive.metastore.RetryingHMSHandler.invokeInternal(RetryingHMSHandler.java:148) ... 24 more Caused by: java.lang.ClassNotFoundException: org.datanucleus.api.jdo.JDOPersistenceManagerFactory at java.net.URLClassLoader.findClass(URLClassLoader.java:381) at java.lang.ClassLoader.loadClass(ClassLoader.java:424) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349) at java.lang.ClassLoader.loadClass(ClassLoader.java:357) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at javax.jdo.JDOHelper$18.run(JDOHelper.java:2018) at javax.jdo.JDOHelper$18.run(JDOHelper.java:2016) at java.security.AccessController.doPrivileged(Native Method) at javax.jdo.JDOHelper.forName(JDOHelper.java:2015) at javax.jdo.JDOHelper.invokeGetPersistenceManagerFactoryOnImplementation(JDOHelper.java:1162) ... 45 more Process finished with exit code 1