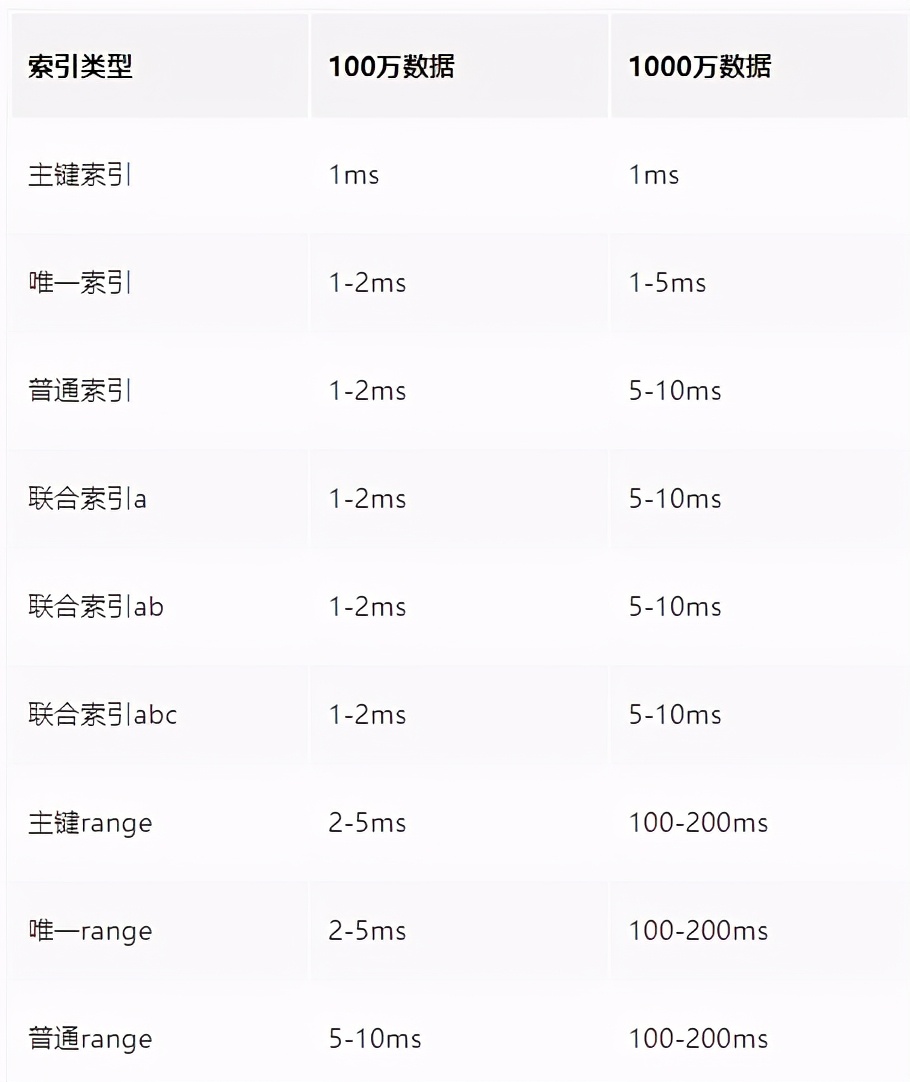
It is generally accepted in the industry that MySQL is in the best state with a single table capacity of less than 10 million, because its BTREE index tree is between 3 and 5
Think: why is the index tree height of 10 million MySQL single table 3 ~ 5?
Table building optimization
Basic principles of field design:
1. When the requirements are met, select as small a data type as possible and specify a short length
2. Tear down the variable length field into a separate table
Small fields have two main effects( InnoDB Default data page size 16 K): 1,With the same number of table records, the index KEY The smaller the, the smaller the height of the index tree, which can reduce the number of index queries 2,The less data stored in the data row, the more data rows can be stored in each data page. When querying, cross page queries are reduced, that is, one disk is reduced IO There are two types of cross page query: 1,Cross page query of data page and data page (basic principle 1 of correspondence) 2,Cross page query of data page and overflow page (corresponding basic principle 2)
Line format:
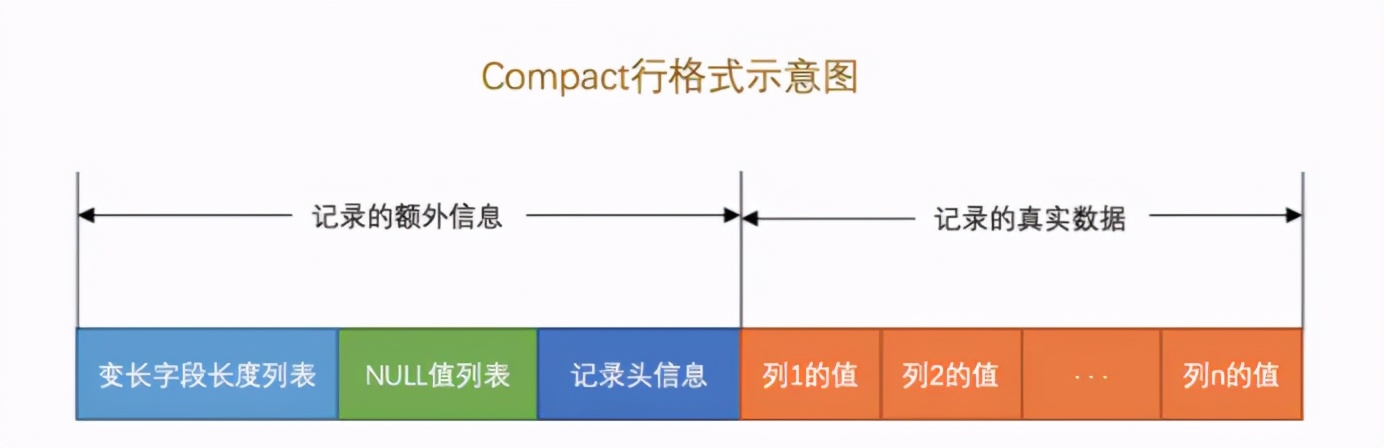
Compact row overflow:
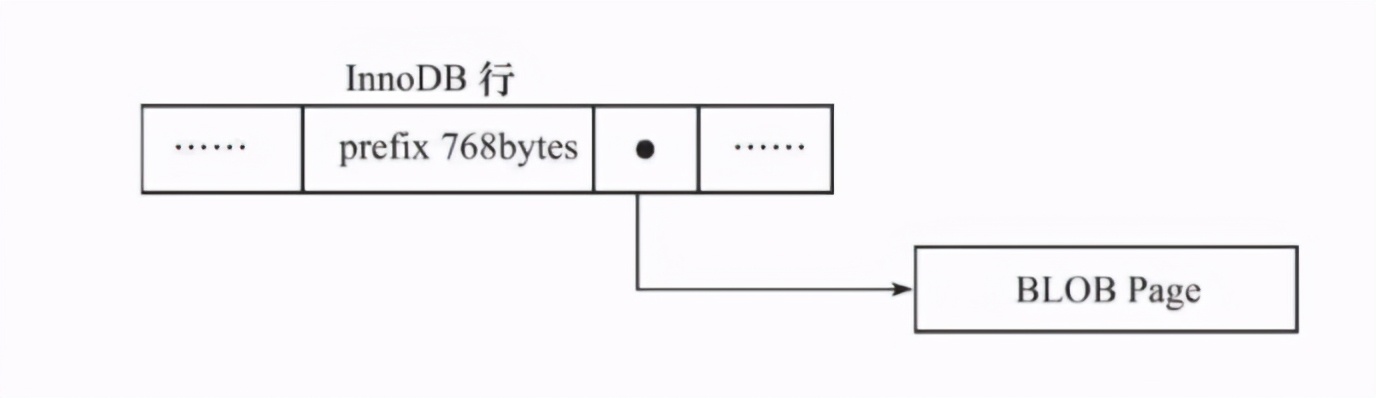
Dynamic row overflow:
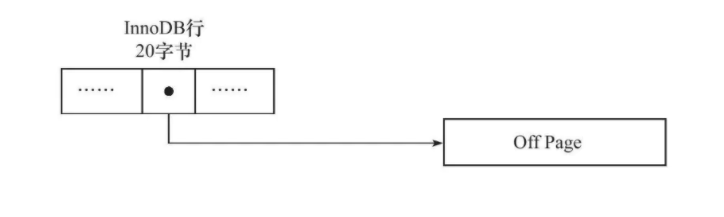
Under what circumstances will overflow Principle: as long as the sum of one line of records exceeds 8 k,Will overflow. Variable field types include blob,text,varchar
Index optimization
The main function of index is to find and sort. Index optimization is the most basic optimization means, and it is also the basic knowledge that programmers must master. It is the key length of this paper
Index classification
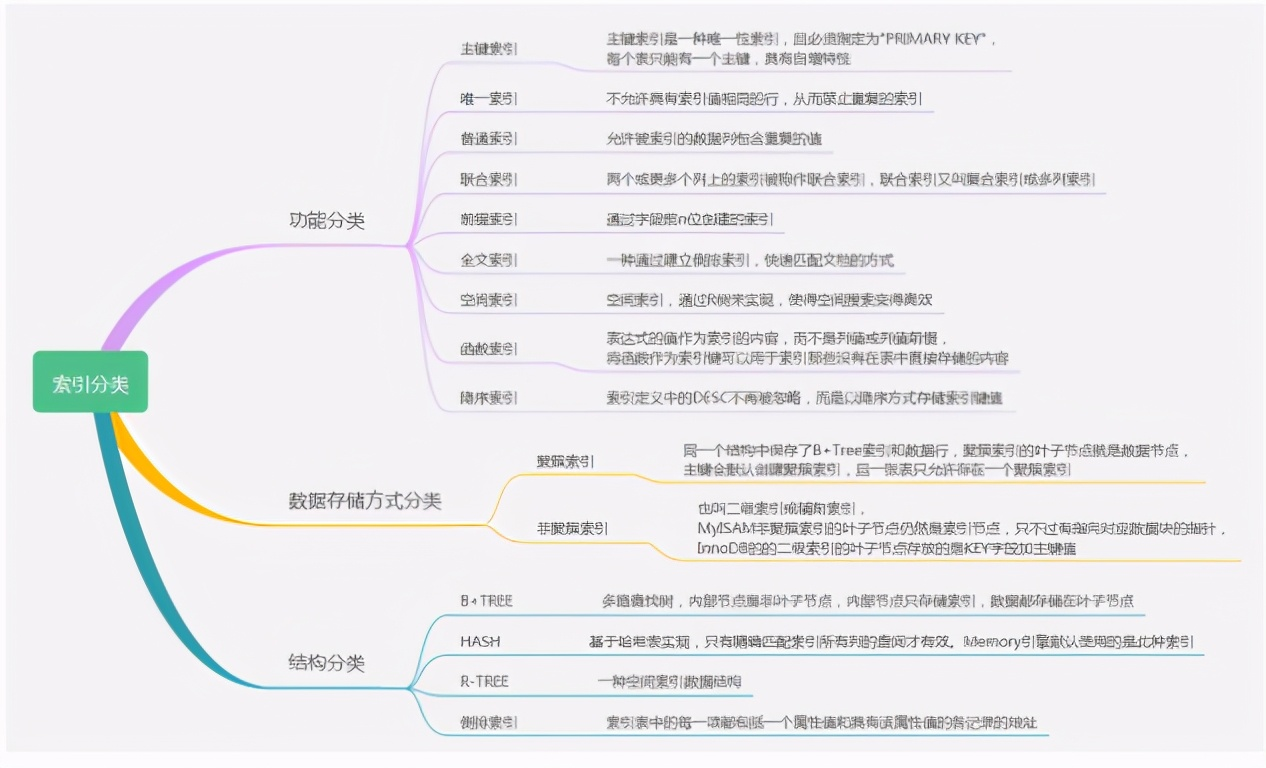
Database version: MySQL 8.0.17 CREATE TABLE `indexs` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'primary key ', `unique_index` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT 'unique index', `normal_index` int(11) NOT NULL DEFAULT '0' COMMENT 'General index', `union_index_a` int(11) NOT NULL DEFAULT '0' COMMENT 'Joint index a', `union_index_b` int(11) NOT NULL DEFAULT '0' COMMENT 'Joint index b', `union_index_c` int(11) NOT NULL DEFAULT '0' COMMENT 'Joint index c', `prefix_index` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT 'Prefix index', `fulltext_index` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '' COMMENT 'Full text index', `func_index` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Functional index', PRIMARY KEY (`id`), UNIQUE KEY `unique_index` (`unique_index`), KEY `normal_index` (`normal_index`), KEY `prefix_index` (`prefix_index`(10)), KEY `union_index_abc_desc` (`union_index_a`,`union_index_b`,`union_index_c` DESC), KEY `func_index` ((date(`func_index`))), FULLTEXT KEY `fulltext_index` (`fulltext_index`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
Spatial index


CREATE TABLE nodes (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT 'primary key ',
`geom` geometry NOT NULL,
`geohash` VARCHAR(10) AS (st_geohash(geom, 6)) VIRTUAL,
PRIMARY KEY (`id`),
SPATIAL KEY idx_nodes_geom (geom),
key idx_nodes_geohash(geohash)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
n := time.Now().Nanosecond()
longitude := fmt.Sprintf("116.%d", n)
latitude := fmt.Sprintf("39.%d", n)
sql := fmt.Sprintf("insert into nodes (geom) value(ST_GeometryFromText('POINT(%s %s)'))", longitude, latitude)
SELECT id, geohash, ST_Distance_Sphere(Point(116.4909484, 39.4909484), geom) as distance, ST_AsText(geom) geom FROM nodes WHERE geohash IN ('wtmknk','wtmkn6','wtmkne','wtmkn5','wtmknh','wtmkns','wtmknd','wtmkn4','wtmkn7') ORDER BY distance LIMIT 10;
LBS Most applications are based on MongoDB database MongoDB Built in geoindex It is very easy to use, and the additional slice characteristics are very suitable for LBS Such an application is simple for business MySQL Can use( todo)
Functional index

descending index

Unexpectedly, in the application scenario, the sorting of time fields is in reverse order in most business scenarios
Leftmost matching principle of joint index:

Thinking: why does this happen? (there are problems in the figure below, which have not been corrected)
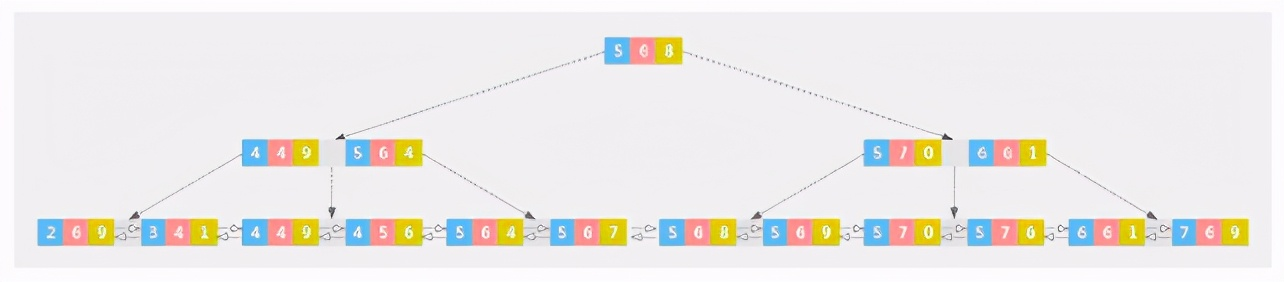
a: 234455555567 b: 644566667766 c: 919647890619 Prerequisite for using index: orderly data a Orderly can be used a,b Orderly can be used b,c Orderly can be used c,order by and group by The premise of using index is that the data is orderly a Always in order, so it can always be used a a = 5, b = 666677 b Orderly, so you can use b a = 5 and b = 6, c = 4789,c Orderly, so you can use c a > 4, b = 66667766, b Unordered, so it cannot be used From the index search process, a Uncertain b = 6,Look at the figure above. Which branch does node 568 go to? There are also six on the left and six on the right
What situations need to create an index
1,Primary key auto create primary key index 2,Fields frequently used as query criteria 3,Fields associated with other tables during query 4,Fields to be sorted during query (accessing indexed fields will greatly improve the sorting speed) 5,Fields counted or grouped during query (essentially, the grouping process is sorting)
What are the conditions not to create an index
1,Too few table records (less than 1000) 2,Frequently updated fields are not suitable for fields (the index improves the query speed, but also reduces the update speed. The update operation not only updates the records, but also updates the index) 3,where Fields not used by conditions 4,Fields where data is repeated and evenly distributed, such as gender
Several cases of index failure
1,Calculation, function and type conversion (including implicit conversion) will lead to index invalidation Analysis: the field type is a string, and the absence of quotation marks leads to implicit type conversion; Function: left(), right(),substring(),substring_index(),mid(),substr() 2,The joint index does not meet the leftmost matching principle, resulting in partial invalidation of the index (explained in detail below) 3,like Query is based on%At the beginning, leading to index invalidation 4,Query criteria include!=,<>,or,May cause index invalidation analysis: where a != 1 The optimizer thinks that the query result probability is most of the data of the table. It is better to go back to the table when going through the index than to scan the whole table directly 5,Use on index fields is null, is not null,May cause index invalidation analysis: null The value does not appear on the leaf node of the index tree like other values 6,The optimizer estimates that using full table scans is faster than using indexes, so indexes are not used Analysis: when the table index is queried, the best index will be used unless the optimizer uses full table scanning more effectively. The optimizer optimizes the full table scan depending on whether the data found using the best index exceeds 30% of the table%Data.
Open the slow query log and record the slow query sql
How slow is considered slow. In most business scenarios, range range range queries cannot be avoided. The optimization of the index is also to reach the range level, which is a balance point. Therefore, according to the index query time above, the slow query time is a reasonable value:

vi /etc/my.cnf.d/mysql-server.cnf stay[mysqld] Add the following configuration under the project slow_query_log = 1 slow-query-log-file = /var/lib/mysql/mysql_slow.log long_query_time = 0.01 log-queries-not-using-indexes = true systemctl restart mysqld Of the 10 items with the slowest execution time sql: mysqldumpslow -s t -t 10 /var/lib/mysql/mysql_slow.log
How to optimize slow sql?
EXPLAIN: analyze the usage of sql index. See EXPLAIN for details
show profiles: SET profiling = 1; Analyze the sql execution process (not much used in actual work)
COUNT(*) query
COUNT(constant) and COUNT(*)It refers to the number of rows of the qualified database table directly queried, which will be counted NULL Line of COUNT(Listing)Indicates that the value of the qualified column in the query is not NULL Number of rows COUNT(*)Optimization: select the smallest secondary index for optimization count If there is no secondary index, cluster index will be selected
Optimize LIMIT paging
LIMIT M,N Performance problems: full table scanning, Limit The principle is from the result set M Take out at the position N Bar output,Others abandoned 1,Fast paging with secondary index ids = select id from articles order by created_at desc limit 10000,10 select * from articles where id in (ids) Disadvantages: LIMIT M,N Problems already exist, but slow down, 10 million data 1-2 second 2,Using the beginning and end records of data, there is a change from full index scanning to range scanning 15 Article 21 2020-01-01 19:00:00 12 Article 20 2020-01-01 18:00:00 11 Article 18 2020-01-01 16:00:00 9 Article 17 2020-01-01 16:00:00 8 Article 15 2020-01-01 15:00:00 6 Article 14 2020-01-01 14:00:00 4 Article 13 2020-01-01 14:00:00 3 Article 12 2020-01-01 13:00:00 1 Article 11 2020-01-01 00:00:00 Note: 11, 9 and 6, 4 are the same first page: select * from articles order by created_at desc, id desc limit 3 Page 2: select * from articles where created_at <= '2020-01-01 16:00:00' and (created_at < '2020-01-01 16:00:00' or id < 11) order by created_at desc, id desc limit 3 previous page: select * from articles where created_at >= '2020-01-01 16:00:00' and (created_at > '2020-01-01 16:00:00' or id > 9) order by created_at desc, id desc limit 3 Current second page: select * from articles where created_at <= '2020-01-01 16:00:00' and (created_at < '2020-01-01 16:00:00' or id < 11) order by created_at desc, id desc limit 3 Next page: select * from articles where created_at <= '2020-01-01 14:00:00' and (created_at < '2020-01-01 14:00:00' or id < 6) order by created_at desc, id desc limit 3 Disadvantages: only the previous page and the next page, no page number
What is index selectivity?
Index selectivity( Selectivity),It refers to the index value without repetition (also known as cardinality, Cardinality)And table records(#T) Ratio of. Selectivity is an indicator of index filtering ability. The value range of the index is 0-1. When the selectivity is greater and closer to 1, the index value will be greater. Index selectivity( Index Selectivity)= Cardinality( Cardinality)/ Total number of rows(#T) SQL = SELECT COUNT(DISTINCT(field))/COUNT(*) AS Selectivity FROM Table name;
Index selectivity and prefix index
select count(distinct left(prefix_index, 1))/count(*) as sel1, count(distinct left(prefix_index, 2))/count(*) as sel2, count(distinct left(prefix_index, 3))/count(*) as sel3, count(distinct left(prefix_index, 4))/count(*) as sel4 from indexs

Single column index VS composite index (composite index with high concurrency tendency)
MySQL can only use one index when executing a query. If there are three single column indexes, MySQL will try to select the most restrictive index. Even the most restrictive single column index, its restrictive ability must be much lower than the multi column index on these three columns.
Index push down technology:


No index push down query process: The storage engine layer matches in the index union_index_a=4366964 Find out a piece of data, and then go back to the table to check all the data recorded in this row, and then return it to server Layer judgment where Meet the conditions union_index_c=1562544 Then filter out the data; Index push down query process: The storage engine layer matches in the index union_index_a=4366964 Find out a piece of data and judge whether the data is consistent union_index_c=1562544 If the condition is not met, filter it, and then go back to the table to check all the data recorded in this line, and then return it to server Layer judgment where Conditions; Index push down technology: reduce the number of table returns, reduce the storage engine layer and server Data transmission of layer
Code optimization
SQL precompiled
1,immediate SQL One SQL stay DB After receiving the final execution and returning, the general process is as follows: 1\. Lexical and semantic analysis; 2\. optimization SQL Statement and make execution plan; 3\. Execute and return results; As above, one SQL Directly follow the process, compile once and run once. Such ordinary statements are called Immediate Statements (immediate SQL). 2,precompile SQL However, in most cases, one SQL The statement may be called and executed repeatedly, or only individual values are different each time (for example select of where Different clause values, update of set Different clause values, insert of values Different values). Each time, you need to go through the above word meaning analysis, sentence optimization, formulation of execution plan, etc SQL Throughout the execution of the statement, Optimizer Is the most time-consuming. The so-called precompiled sentence is to translate this kind of sentence SQL The value in the statement is replaced by a placeholder, which can be regarded as SQL Statement templating or parameterization is generally called this kind of statement Prepared Statements. The advantages of precompiled sentences are summarized as follows: one compilation and multiple runs, eliminating the process of parsing and optimization.
In addition, precompiled statements can prevent SQL injection (think about the reason)
Most programming languages support precompiling, which can improve the efficiency of database execution through SQL precompiling
Use ORM framework to avoid Association query and standardize API interface
Table splitting optimization
MySQL has the best efficiency when the capacity of a single table is 10 million. If it exceeds 10 million, the table needs to be disassembled
Horizontal dismantling table
The data of a single table can be kept at a certain level, which is helpful to improve the performance The table structure of segmentation is the same, and the transformation of application layer is less. You only need to add routing rules Question: how many sheets are appropriate to open? 10, 50, 100? Analysis: it mainly depends on the business growth, such as user order table, 100000 orders a day, and 10 million data in 100 days. Four tables can last for one year, eight tables for two years, and so on (the number of sub tables remains a multiple of 4, and the reason will be explained below)
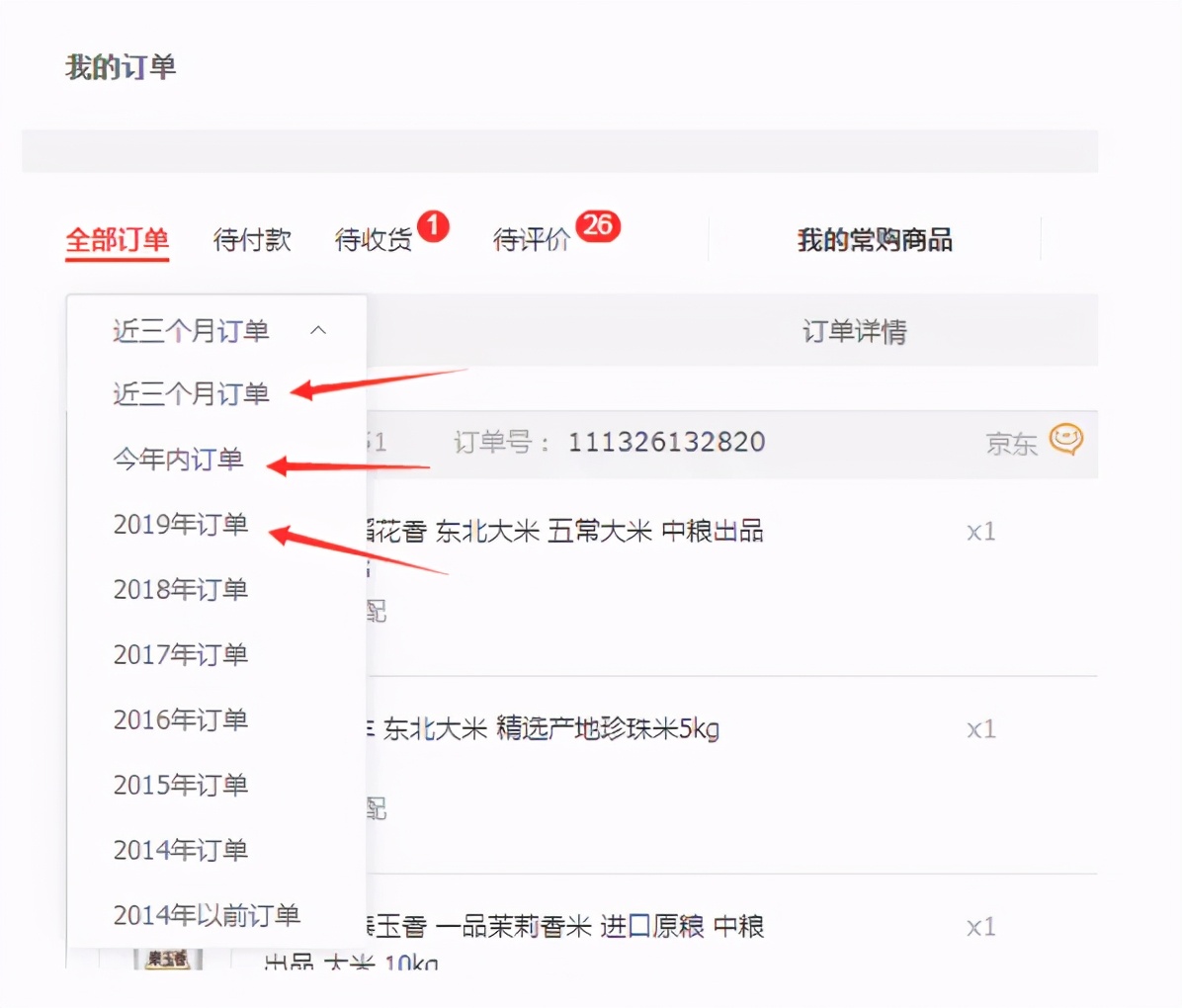
Hot and cold data separation
Split the hot data to reduce the amount of data in the hot data table and ensure the reading and writing performance of the hot data. The cold data has relatively few accesses, so it can be optimized in business. As shown in the figure below, JD splits the historical order data according to the time dimension
Split Vertically
Page overflow in the case of many fields, splitting small tables through large tables is more convenient for development and maintenance, and can also avoid the problem of cross page. The bottom layer of MYSQL is stored through data pages. If a record occupies too much space, it will lead to cross page and cause additional overhead.
Split by: 1,Try to put the attributes with short length and high access frequency in one table, which is called the main table 2,Try to put the attributes with long fields and low access frequency in one table, which is called extended table If both 1 and 2 are satisfied, the third point can also be considered: (3)Attributes that are frequently accessed together can also be placed in a table
Host optimization
Mainly for my Optimization of CNF configuration
Mainly dba Professional work and professional things are left to professional people. List more important and understandable parameters innodb_buffer_pool_size parameter SELECT @@innodb_buffer_pool_size/1024/1024/1024; show global variables like 'innodb_buffer_pool_size'; be used for innodb Cache of data and indexes, 128 by default M,innodb The most important performance parameters. Recommended value: no more than 80% of physical memory%(If the amount of data is small, it can be the amount of data+10%,Data volume 20 G,Physical memory is 32 G,It can be set at this time buffer pool For 22 G. ) innodb_buffer_pool_size=1G The buffer pool size must always be equal to or equal to innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances Multiple of. If you change the buffer pool size to not equal to or equal to innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances The value of the multiple of, The buffer pool size will be automatically adjusted to be equal to or equal to innodb_buffer_pool_chunk_size * innodb_buffer_pool_instances Value of multiple of SELECT @@innodb_buffer_pool_chunk_size/1024/1024/1024; // View the size of each cache pool show global variables like 'innodb_buffer_pool_chunk_size'; show global variables like 'innodb_buffer_pool_instances'; // Number of cache pools number of logical CPU s parameter innodb_dedicated_server=ON Let MySQL Automatically detect the memory resources of the server and determine innodb_buffer_pool_size, innodb_log_file_size and innodb_flush_method Values of three parameters innodb_flush_log_at_trx_commit parameter show global variables like 'innodb_flush_log_at_trx_commit'; The default is 1 Controls how transactions are committed and how logs are refreshed to the hard disk 0: from mysql of main_thread Storage engine per second log buffer Medium redo log Write to log file,And call the file system sync Operation to refresh the log to disk. (fast, unsafe) 1: Each time a transaction is committed, the storage engine log buffer Medium redo log Write to log file,And call the file system sync Operation to refresh the log to disk. (safety) 2: Each time a transaction is committed, the storage engine log buffer Medium redo log Write to log file,And by the storage engine main_thread Flushes logs to disk per second. When innodb_flush_log_at_trx_commit Set to 0, mysqld The crash of the process will result in the loss of all transaction data in the last second. When innodb_flush_log_at_trx_commit If it is set to 2, all transaction data in the last second may be lost only when the operating system crashes or the system loses power. sync_binlog parameter show global variables like 'sync_binlog'; The default is 1 0: At this time, the performance is the best, but the risk is also the greatest. Because once the system crash,stay binlog_cache All in binlog Information will be lost 1: Indicates that each transaction is committed, MySQL Will put binlog Brushing down is the safest setting with the greatest performance loss. In this way, when the host operating system where the database is located is damaged or suddenly powered down, the system may lose the data of one transaction. The write performance gap between the system set to 0 and 1 may be as high as 5 times or more innodb_flush_log_at_trx_commit=1 and sync_binlog=1 Is the safest, in mysqld Service crash or server host crash In the case of, binary log It is only possible to lose at most one statement or transaction. However, you can't have both fish and bear's paw. The double-1 mode will lead to frequent io Operation, so this mode is also the slowest way. "Dual 1 mode"Suitable for data security requirements are very high, and the disk IO The writing ability is sufficient to support business, such as order, transaction, recharge, payment and consumption system. In dual-1 mode, when the disk IO When the business needs cannot be met, the recommended practice is innodb_flush_log_at_trx_commit=2,sync_binlog=N (N 500 or 1000) This is it. MySQL famous"Dual 1 mode"
Thinking: master-slave replication uses InnoDB in the case of semi synchronous replication and does not allow it to degenerate into asynchronous replication_ flush_ log_ at_ trx_ commit=2,sync_ Can the binlog = n scheme ensure performance and no data loss? Is it reliable?
Master slave separation (optimized for reading)
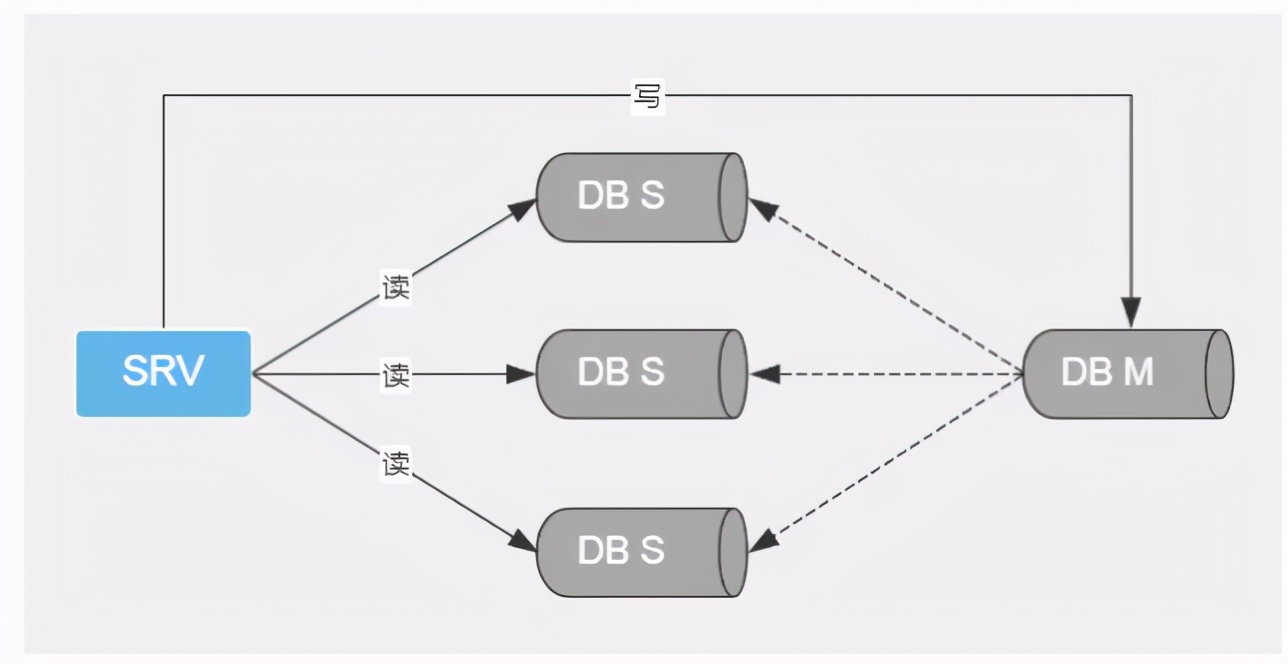
Extended reading:
be based on biglog Log point replication In case of failure, master-slave switching is required, and it is necessary to find binlog and position Point, and then point the master node to the new master node, which is relatively troublesome and error prone. be based on GTID Replication of( MySQL>=5.7 (recommended) GTID Global transaction ID(Global Transaction ID),Is the number of a committed transaction and a globally unique number. Instead of based on binlog and position Master slave replication synchronization mode of No MySQL Three replication methods 1,asynchronous Asynchronous replication 2,semisynchronous Semi synchronous replication 3,lossless replication Lossless replication enhanced semi synchronous replication The difference between semi synchronous replication and asynchronous replication is that when semi synchronous replication mechanism is adopted, Slave Hui Xiang Master Send a ACK Confirmation message, and Master of commit The operation will also be blocked until it is received Slave After the confirmation message, Master Will return the data modification results to the client. binlog Format: 1,row level: Only the modified details of the record are saved, not the record sql Benefits of statement context sensitive information (default) 2,statement level: Each one will modify the data sql Will be recorded in binlog in 3,mixed level: Above two level Through the previous comparison, it can be found that row level and statement level Each has its own advantages. If you can sql Sentence choice may have better performance and effect; Mixed level These are the above two leve The combination of. Parallel replication: (solve the problem of data delay in master-slave replication) Inter library concurrency The theoretical basis of inter library concurrency is as follows ---- There may be multiple libraries in an instance(schema),There are no dependencies between different libraries, so slave Over there for Every library(schema)Separate one SQL In this way, the efficiency of master-slave replication can be improved through multi-threaded parallel replication. This theory sounds OK, but in fact, an instance is just a business library, so this kind of concurrency between libraries has little effect; In other words, there are few applicable scenarios for this method. In view of this deficiency, it is necessary to"Group submission"Just solve it! Group submission The theoretical basis submitted by the group is as follows --- If multiple transactions can be committed at the same time, this indirectly indicates that there is no conflict on the locks of these transactions, That is to say, they hold different locks and do not affect each other; Logically, several transactions are regarded as a group slave with"group"Assign to SQL Thread execution, so many SQL Threads can run in parallel; Moreover, the effect is better than that of parallel granularity"Inter library concurrency"Better. WriteSet WriteSet Is standing"Group submission"Established between the foundations of master Adaptive packaging and grouping on mysql8.0 Master slave synchronization: 1,binlog format: row level 2,be based on GTID Replication of 3,Lossless replication 4,WriteSet Parallel replication
show global variables like 'query_cache_type'; Master: query_cache_type=OFF mysql8.0 Query caching has been discarded
Write library splitting (optimization for write)
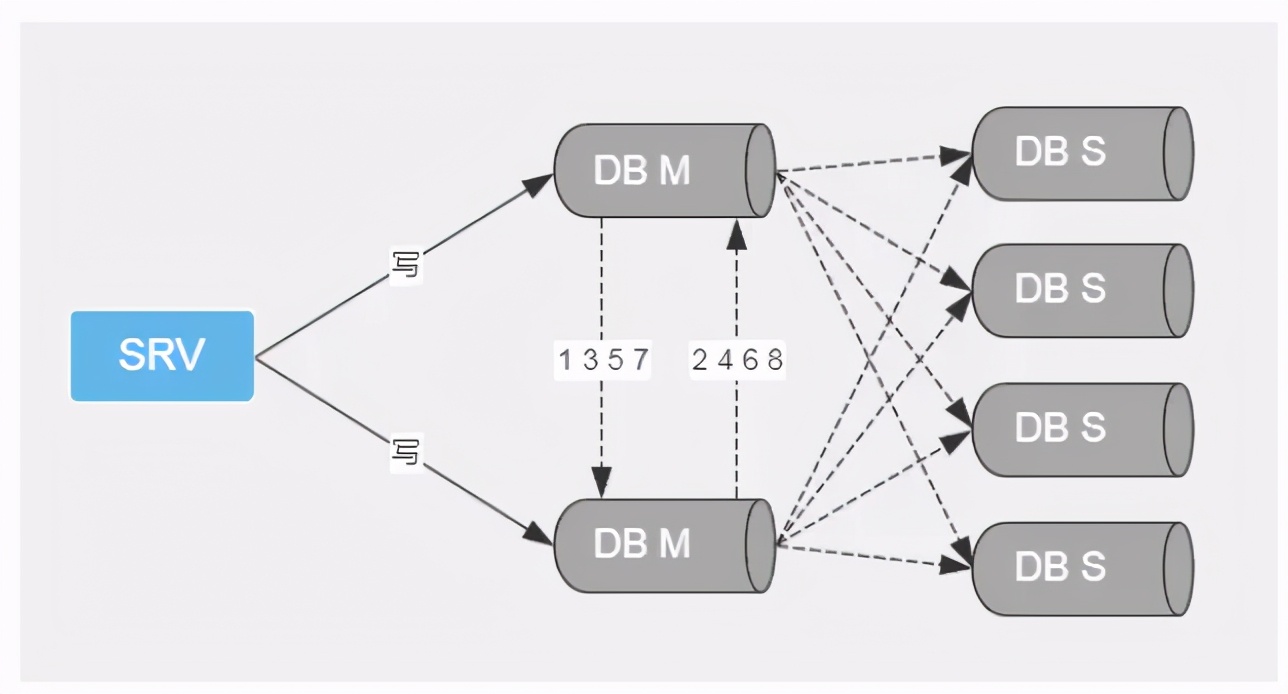
Misunderstanding: primary replication can not improve the write speed, but can only solve the primary single point problem. I haven't seen this architecture applied in practical work
Binary tree branch database and table
It mainly solves the problem of avoiding data splitting by row when expanding the database server. When expanding the number of database hosts by a multiple of 2, first split by database, and then split by table. Only 1 / 2 of the data needs to be transferred each time;
Routine data removal process:
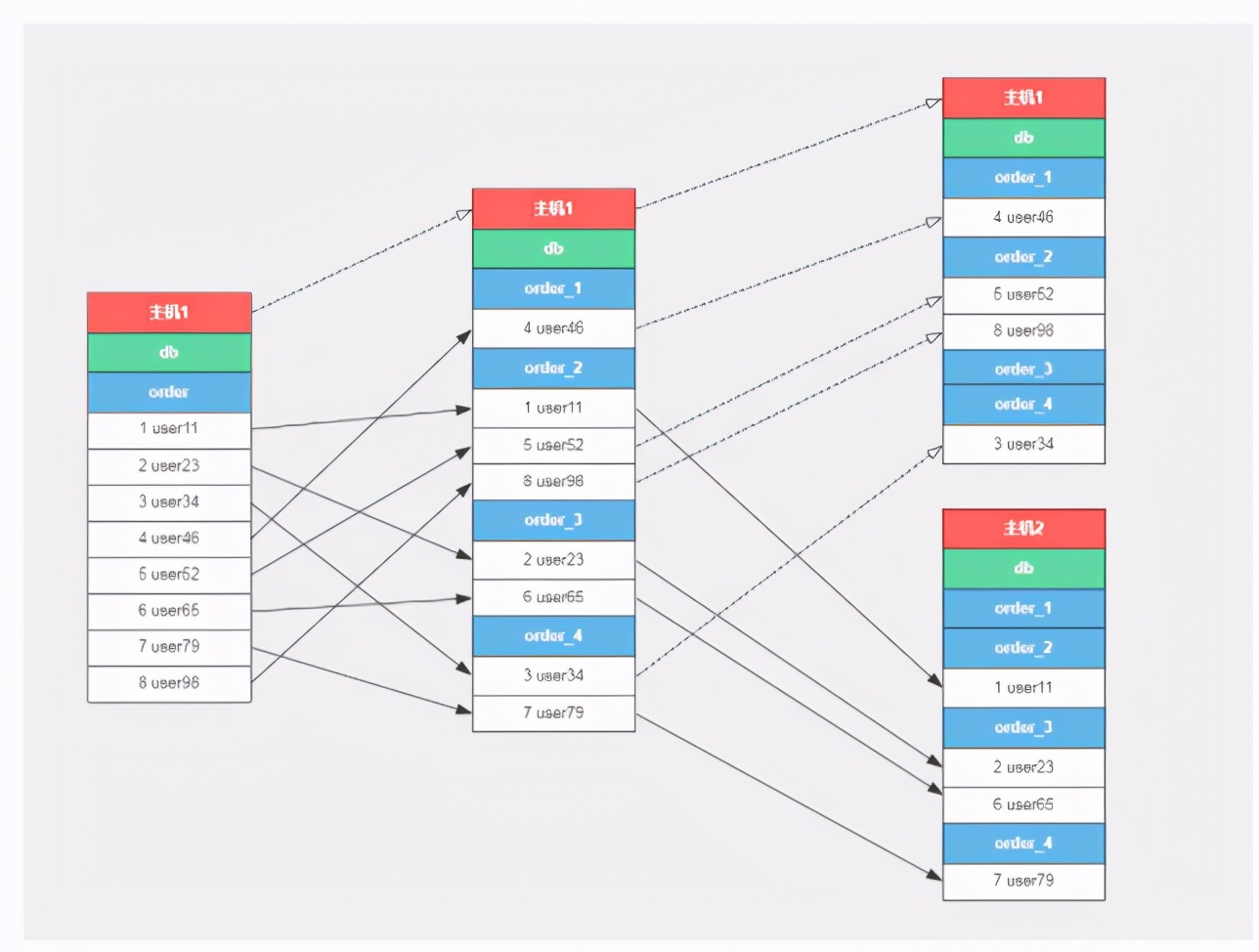
Data splitting process of binary tree branch database and table:
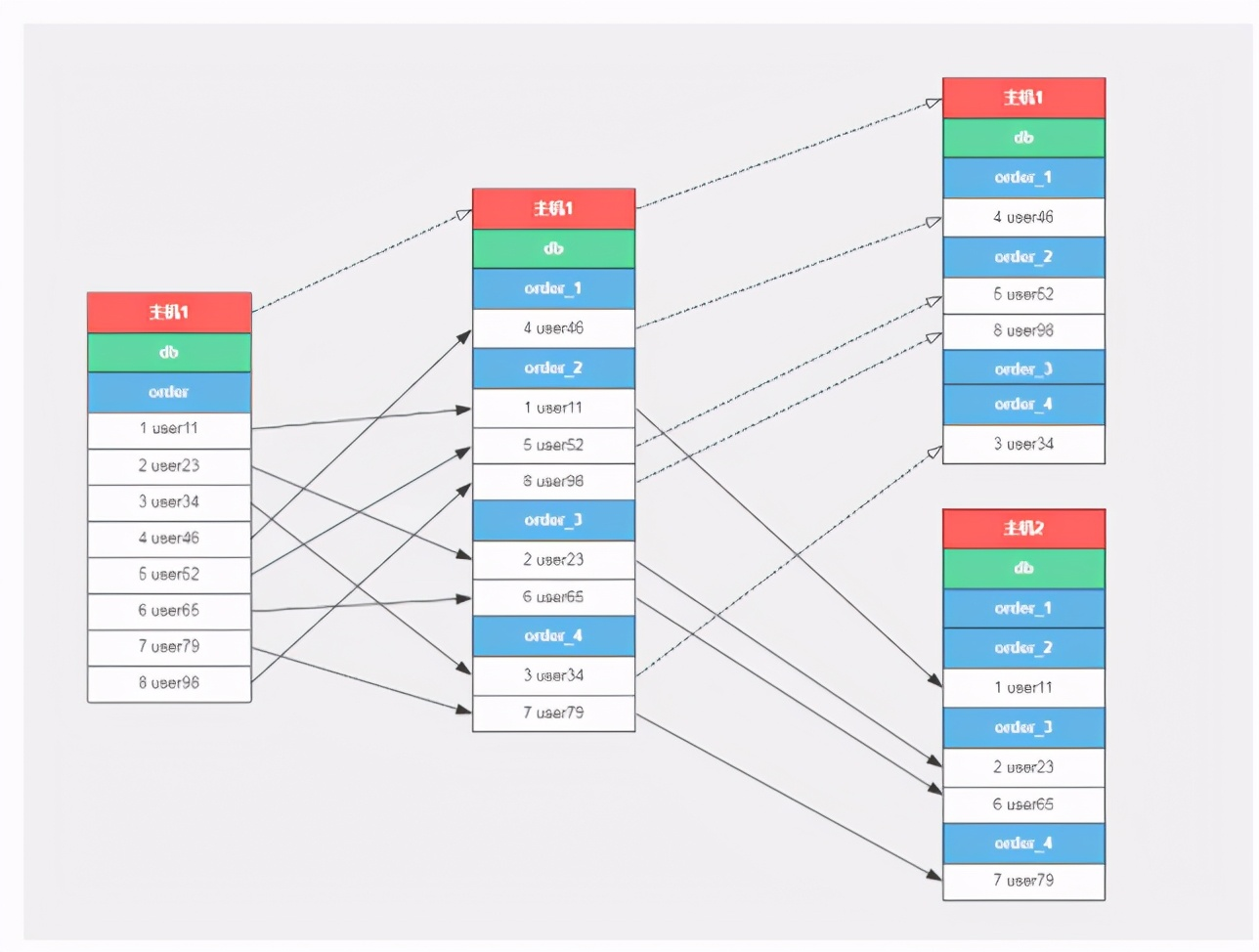
Divide the order table according to the rules of 8 libraries and 16 tables
// User database and table mapping relationship
$userId = user id;
// A database instance
$conn = Database connection;
$conns[0] = $conn;
// Two database instances
$conn1 = Database connection 1;
$conn2 = Database connection 2;
$conns[0] = $conn1;
$conns[1] = $conn2;
$dbConn, $dbName, $tableName = getConn($userId, $conns)
func getConn($userId, $conns) {
$dbCount = 8;
$tableCount = 16;
$dbHostCount = len($conns);
$dbIndex = $userId % $dbCount % $dbHostCount;
$tableIndex = $userId / 10 % $tableCount + 1;
$dbConn = $conns[$dbIndex - 1]
$dbName = "db_" + $dbIndex
$tableName = "order_" + $tableIndex
return $dbConn, $dbName, $tableName
}
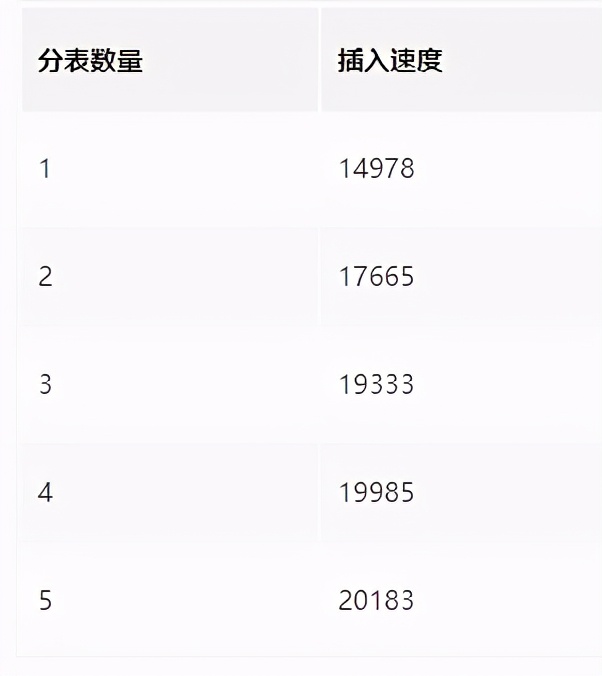
Summary: single table insertion is mainly due to the bottleneck of data construction speed, and multi table insertion is mainly due to disk IO There is a bottleneck, and multiple tables remain 3-5 Zhang is more suitable There is an article on the Internet that one library and one meter can be divided at the end. Judging from the results of pressure measurement of each meter, one library and one meter can not play a role mysql For all performance, one database, four tables and one small cluster are more suitable, 8 If there are 16 tables in a database, it can be divided into 32 small clusters, with 20000 inserts in each cluster QPS,32*2 = 64 Wan insert QPS;
Estimated index tree height:
hypothesis B+If the tree height is 2, that is, there is one root node and several leaf nodes, then this tree B+The total number of records stored in the tree is: the number of root node pointers*Number of record lines of a single leaf node Indicates the number of records in a single leaf node (page)=16K/1K=16. (Here, it is assumed that the data size of a row of records is 1 k,In fact, the size of many Internet business data records is usually 1 K Left and right). Assume primary key ID by bigint Type with a length of 8 bytes and a pointer size of InnoDB The source code is set to 6 bytes, so a total of 14 bytes. How many such units can be stored in a page actually represents the number of pointers, i.e. 16384/14=1170. Then you can calculate a tree with a height of 2 B+Tree, can store 1170*16=18720 Such a data record. According to the same principle, calculate a height of 3 B+Tree can store: 1170*1170*16=21902400 Such a record. So in InnoDB in B+The tree height is generally 1-3 Layer, it can meet tens of millions of data storage. When searching for data, one page search represents one IO,Therefore, the query through the primary key index usually only needs 1-3 second IO Operation can find the data.
page size selection of Innodb tablespace (I don't understand, todo)
Innodb page size You can choose 8 K, 16K, 32K, 64K In terms of space and memory utilization, page size The bigger the better. But from checkpoint On the contrary, page size Smaller, better performance In order to ensure the consistency of data, the database adopts checkpoint( checkpoint)The mechanism flushes the dirty pages in memory to disk and empties the old physical logs at the same time.
Locality principle and disk pre reading
Locality principle: when a data is used, the nearby data is usually used immediately. The data needed during program operation is usually concentrated. Due to the high efficiency of disk sequential reading (no seek time, only a little rotation time), pre reading can improve the efficiency of local programs I/O Efficiency. The length of pre read is generally an integral multiple of the page. A page is a logical block of computer management memory. Hardware and operating systems often divide the main memory and disk storage area into consecutive blocks of equal size. Each storage is called a page (in many operating systems, the size of a page is usually 4) k)
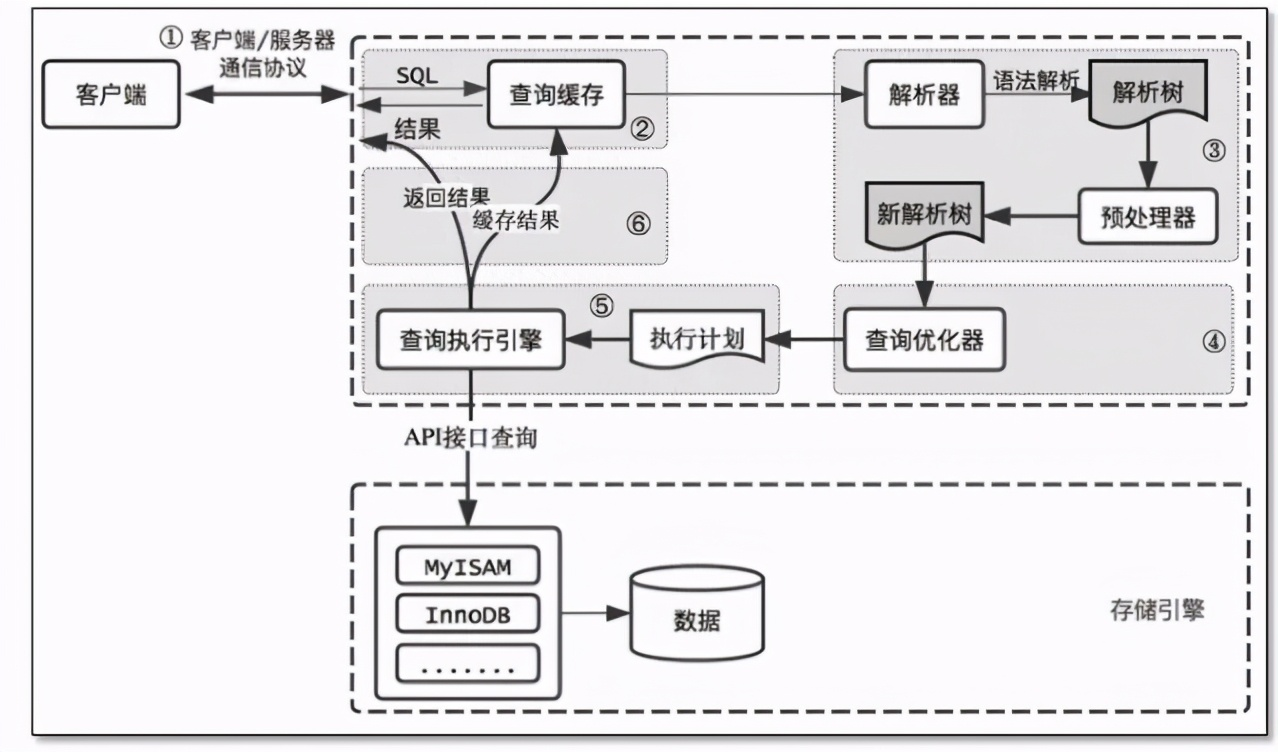
Final summary
After finishing the algorithm, the interview byte is no longer afraid. If you need to share these binary trees, linked lists, strings, stacks, queues and other major interview high-frequency knowledge points and analysis in the article, as well as the problem brushing of the algorithm, the partners of LeetCode Chinese version can praise it Click here to get it for free!
Finally, I will share a big gift package (learning notes) of the ultimate hand tearing architecture: distributed + micro services + open source framework + performance optimization
``
Locality principle: when a data is used, the nearby data is usually used immediately.
The data needed during program operation is usually concentrated.
Due to the high efficiency of disk sequential reading (no seek time, only a little rotation time), pre reading can improve I/O efficiency for local programs.
The length of pre read is generally an integral multiple of the page. A page is a logical block of computer management memory. Hardware and operating systems often divide the main memory and disk storage area into consecutive blocks of equal size. Each storage is called a page (in many operating systems, the size of a page is usually 4k)
[External chain picture transfer...(img-a646bot1-1623736541937)] # Final summary Get the algorithm, the interview byte is no longer afraid, there is a need to share these in the article**Binary tree, linked list, string, stack and queue, etc**,as well as**Algorithm problem brushing LeetCode Chinese version of the little friends can like it[Click here to get it for free!](https://docs.qq.com/doc/DSmxTbFJ1cmN1R2dB)** Finally, share one more**The ultimate hand tearing architecture gift bag(Study notes): Distributed+Microservices+Open source framework+performance optimization** [External chain picture transfer...(img-4yTxIPAU-1623736541938)]