Background:
Today, I found that someone made an invoice ocr to realize invoice character recognition, so as to solve the problem of inefficient and cumbersome manual input and greatly improve the work efficiency. However, his ocr doesn't seem to be very mature. I just want to call Baidu api to realize the invoice character recognition part, select what I want and write it into excel. It took some time, but it did, Share it and hope to help people in need
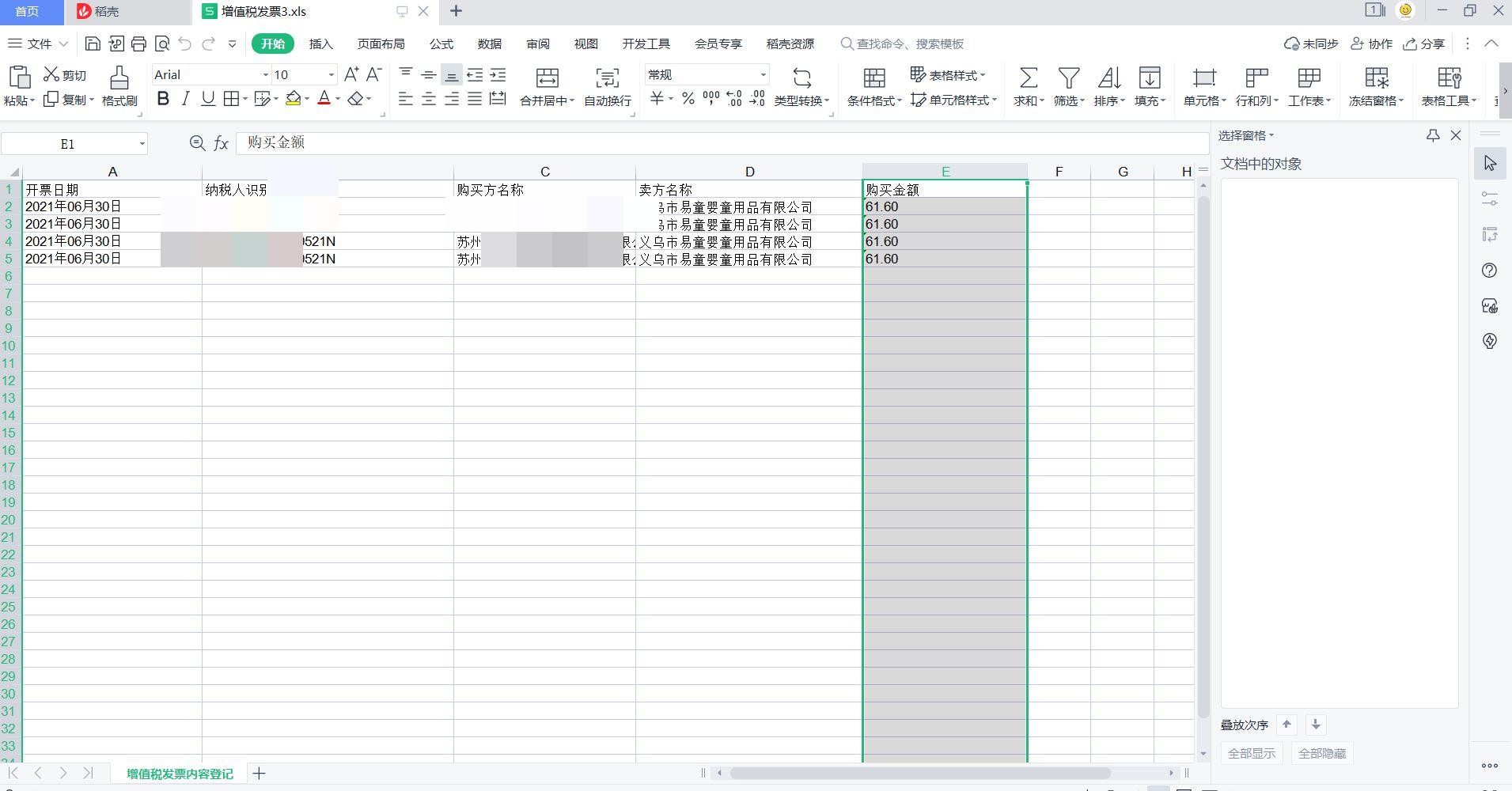
First on the renderings, design privacy, mosaic
 Write table
Write table
preparation
1. For environment configuration, you need to have the following four Libraries
import requests import base64 import os import xlwt
2. you need to register an account in Baidu intelligent cloud, then create a text recognition application in the management console, so that the website will give you a API key and a Secret Key. With these two strings of characters, we can proceed with the next operation and get the identity token access_. token
This is Baidu Intelligent Cloud management console.
Then create the application here
Select the character recognition direction and remember to check the VAT invoice. It should be selected by default
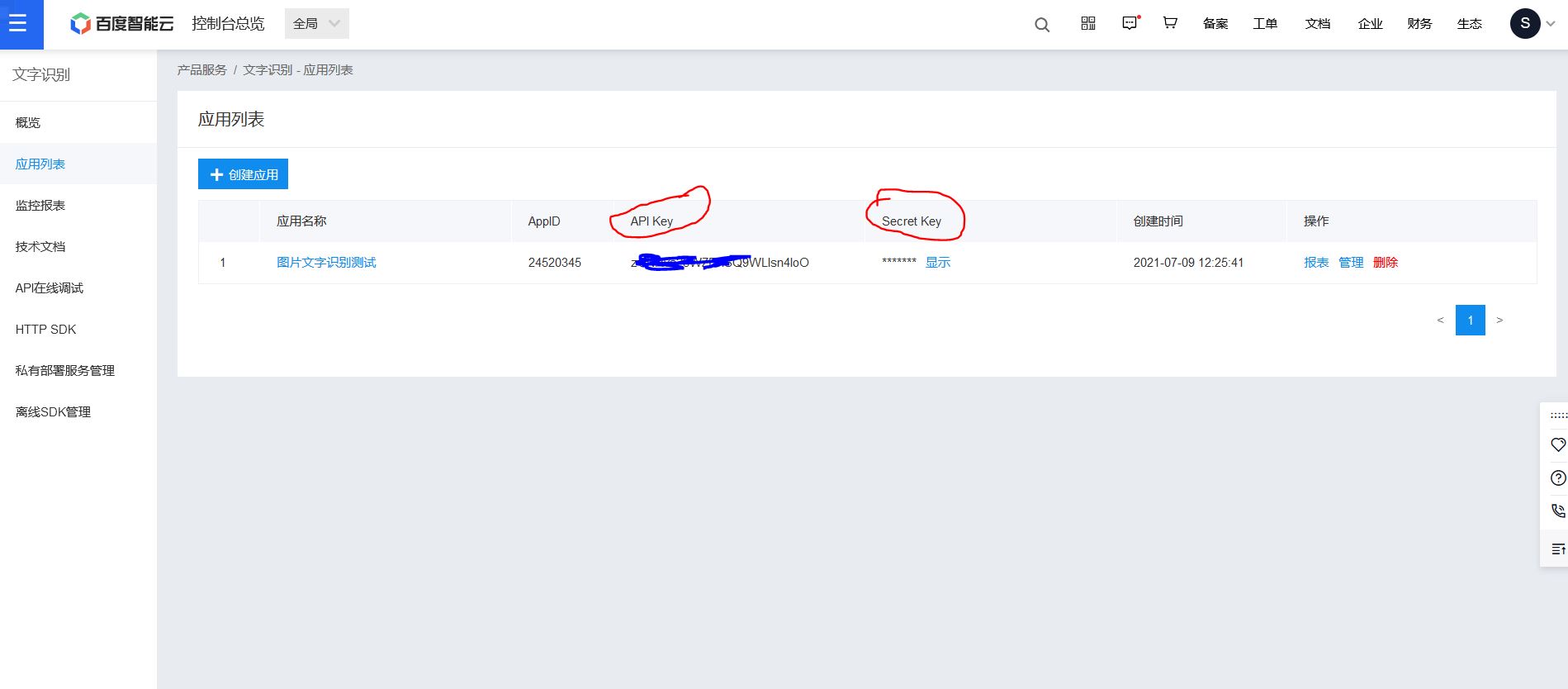
Here are the api key and Secret Key. At that time, the one in the code also needs to be replaced with its own to obtain access_token also needs
Then open the technical document, which has an api document to teach you how to obtain access_token
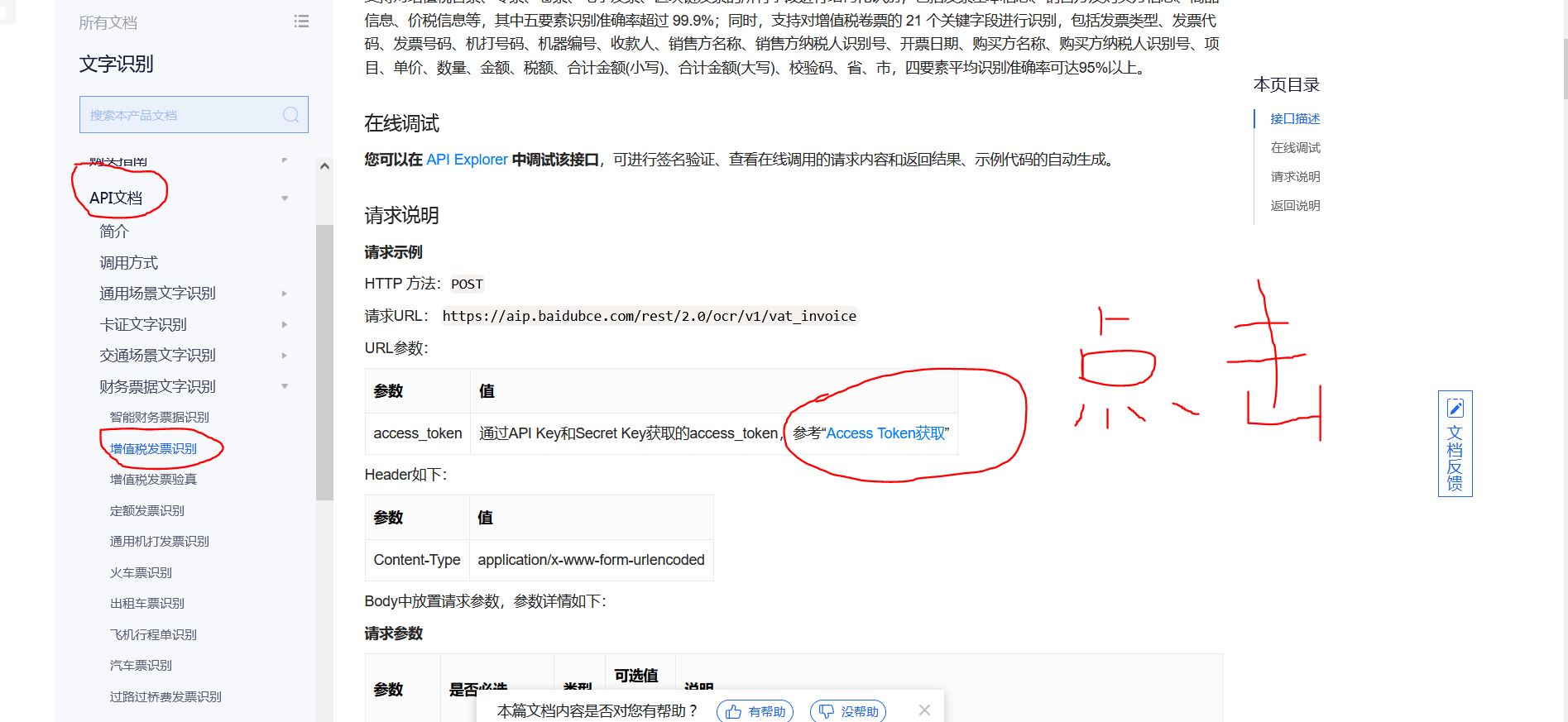
Get access_ The code of token is as follows. Please replace api key and Secret Key with your own
# encoding:utf-8
import requests
# client_id is the AK and client obtained on the official website_ Secret is the SK obtained on the official website
host = 'https://aip. baidubce. com/oauth/2.0/token? grant_ type=client_ credentials&client_ Id = [AK obtained on official website] & Client_ Secret = [SK obtained on official website] '
response = requests.get(host)
if response:
print(response.json())
Here we have access_ After the token is, we need to copy and paste it into the code, and our preparations are completed
Modify the invoice storage address path and access in the code_ The token can be used
There are comments in the code
Upper code
# encoding:utf-8
import requests
import base64
import os
import xlwt
'''
VAT invoice identification
'''
# Get invoice body content
def get_context(pic):
# print('getting picture body content! ')
data = {}
try:
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/vat_invoice"
# Open picture file in binary mode
f = open(pic, 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
# You need to replace it with your own access_token
access_token = 'Yours access_token'
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
# print (response.json())
json1 = response.json()
data['SellerRegisterNum'] = json1['words_result']['SellerRegisterNum']
data['InvoiceDate'] = json1['words_result']['InvoiceDate']
data['PurchasserName'] = json1['words_result']['PurchaserName']
data['SellerName'] = json1['words_result']['SellerName']
data['AmountInFiguers'] = json1['words_result']['AmountInFiguers']
# print(data['AmountInFiguers'])
# print('body content obtained successfully! ')
return data
except Exception as e:
print(e)
return data
# Defines the function that generates the image path
def pics(path):
print('Generating picture path')
#Generate an empty list for storing picture paths
pics = []
# Traverse the folder, find the files with suffixes jpg and png, and add them to the list after sorting
for filename in os.listdir(path):
if filename.endswith('jpg') or filename.endswith('png'):
pic = path + '/' + filename
pics.append(pic)
print('Image path generation succeeded!')
return pics
# Define a function to get the body content of all files in the folder, return one dictionary at a time, and store all the returned dictionaries in a list
def datas(pics):
datas = []
for p in pics:
data = get_context(p)
datas.append(data)
return datas
# Define a function that writes data to excel
def save(datas):
print('Writing data!')
book = xlwt.Workbook(encoding='utf-8', style_compression=0)
sheet = book.add_sheet('VAT invoice content registration', cell_overwrite_ok=True)
# Set the header, which can be set according to your own needs. I have set five here
title = ['Billing date', 'Taxpayer identification number', 'Name of purchaser', 'Name of seller', 'Purchase amount']
for i in range(len(title)):
sheet.write(0, i, title[i])
for d in range(len(datas)):
for j in range(len(title)):
sheet.write(d + 1, 0, datas[d]['InvoiceDate'])
sheet.write(d + 1, 1, datas[d]['SellerRegisterNum'])
sheet.write(d + 1, 2, datas[d]['PurchasserName'])
sheet.write(d + 1, 3, datas[d]['SellerName'])
sheet.write(d + 1, 4, datas[d]['AmountInFiguers'])
print('Data writing succeeded!')
book.save('VAT invoice.xls')
def main():
print('Start execution!!!')
# This is the storage address of your invoice, which can be changed by yourself
path = 'D:/fapiao'
Pics = pics(path)
Datas = datas(Pics)
save(Datas)
print('End of execution!')
if __name__ == '__main__':
main()
be careful:
This project can realize suffix jpg and png's value-added tax invoice text recognition and write it into excel. If other formats are required, it can be modified slightly
Baidu Intelligent Cloud return to the field is very rich, on demand for use, this battle I choose five fields, please use your own modification, are included in the json file returned.
To sum up, path and access have been modified_ Token can be used. Isn't it very convenient
Thank you for reading. See you next time!!!