preface
Note:
Hello, everyone. I'm my mother's eldest son,
Contact information of the author
QQ: 3302254385
Wechat: yxc3302254385
Make a friend!
The article contains a lot of content. If you don't want to see the business scenario, you can directly find the required code cv through the directory!
Creation is not easy, thank you very much!!!
Business scenario analysis
Let's start with the business scenario:
Similar to the small program in the figure below, the scene of voting ranking list!!!
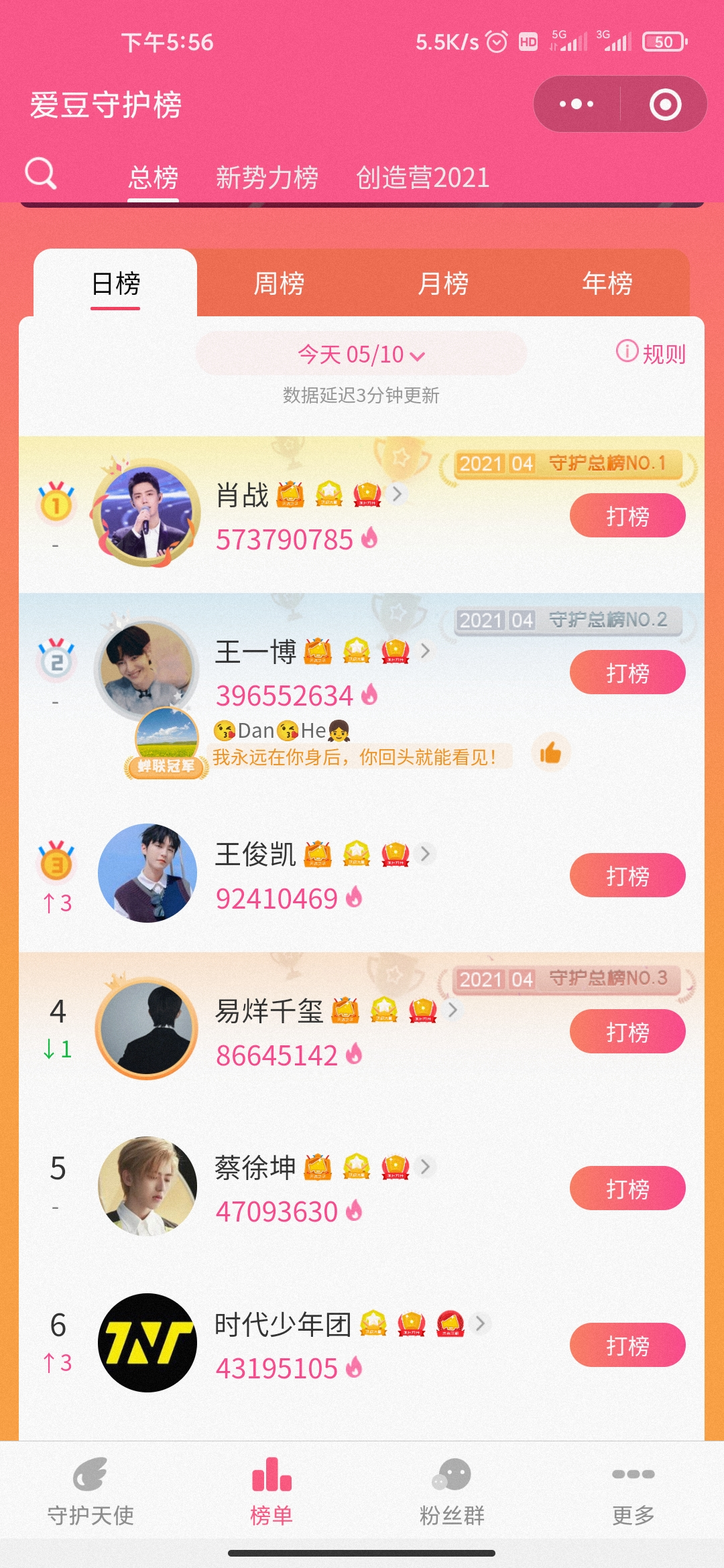
Analyze first
- First, there are a lot of love beans who can vote, so they need to be ranked
- Second, the need for statistics on users' voting data is usually highly concurrent
- Third, when users use this small program, the main page is the ranking list, which is used as a hot data with high traffic
Technical solutions
According to the analyzed business scenarios, what technology solutions should we use better and what problems will arise!!
- For this voting scenario, the real-time performance of data is not high. We can use cache to completely replace our database, because 1 With the characteristics of high concurrency and large number of visits, it is impossible to use the database to directly query and synchronize updates. A single machine must explode!!! 2. Use cache to save database cost 3 Fast cache speed
- Because we use the cache to replace the database, we need to add the likes of love beans, love beans ranking list, users' likes, etc!!! Asynchronously update the cached data to the database or asynchronously update the database data to the cache
Update the likes of love beans:
We can use ZSet in Redis to rank Aidou through her weight coefficient (like amount). Each time a user likes, we only need to increase the weight coefficient in the cache, and then update this (like amount to the database regularly)
Update love bean ranking:
Because the basic information of Aidou may be modified, but the likes of Aidou are counted through the cache, so the likes are updated to the database first, and then the data of the database is sorted and updated to the cache!
Query all the ranking data of Aidou, put the data in the List type in Redis, and get the data through our range method and paging algorithm!
Update user's likes
I Each user will have their own number of likes and refresh it every day. For the event of likes, the general user can only deliver all the votes in one minute!! Therefore, when deducting the user's daily votes, you can also use the cache as the deduction of votes without querying the database 10 times after the user likes it 10 times!!
II Each user's like operation will be recorded. It is not necessary to insert the database during the peak period. We can put the data into the cache, cut the peak of the traffic as a middleware, and then batch write it to the database! Redis's List can be used as a double ended queue, which can be brushed back to our database in batch in the form of FIFO (first in first out)! - What about cache breakdown caused by cache failure during data update? If you call our database directly, it will cause the db to hang up (using the cache copy method, or you can limit the flow. Only one thread can access the database and update the cache, using Semaphore under JUC package)
- For mass caching operations, it's not just that we save a simple key such as token, but value. How can we write so much data into our cache at one time or in batch to save unnecessary time-consuming similar to connection (optimize with Pipeline pipeline to reduce the resources and time consumed in server connection, that is, reduce)
Redis knowledge review Or supplement
In order to help you review the knowledge points and help Xiaobai understand, it doesn't involve specific orders!!! Mainly data structures and usage scenarios
List
- Single Value, multi Value, ordered set, not unique
- It is a string linked list, left and right can be inserted and added
- If the key does not exist, create a new linked list. If all the values are removed, the corresponding key will disappear
- Using the Lists structure, we can easily realize the latest news ranking and other functions. Another application of List is message queue. You can use the PUSH operation of List to store the task in the List, and then the working thread takes out the task for execution with POP operation.
- Redis's list is a two-way linked list with each sub element of String type. You can add or delete elements from the head or tail of the list through push and pop operations. In this way, the list can be used as a stack or a queue

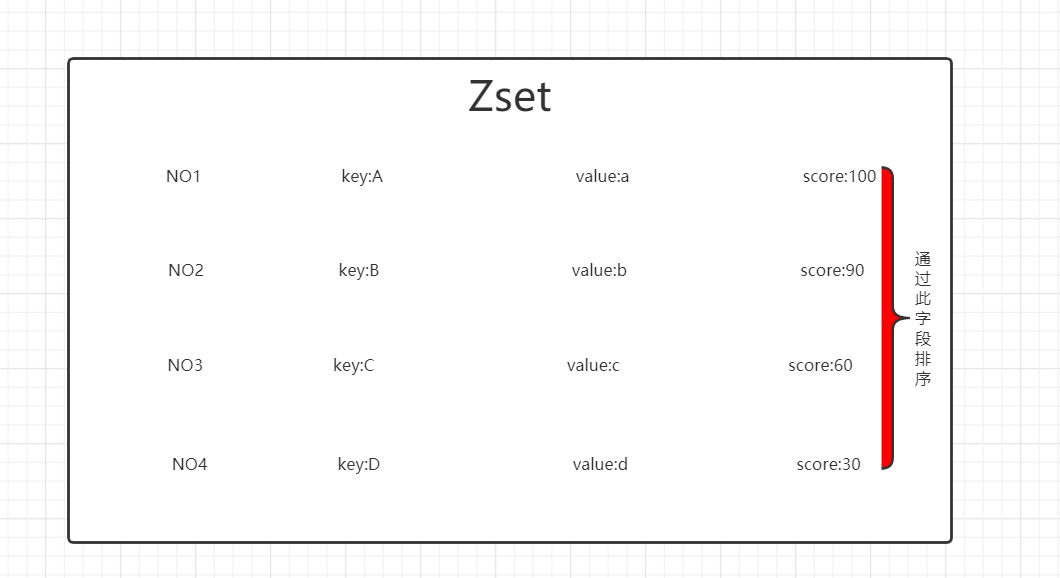
ZSet
- Like a Set, a sort Set consists of unique, non repeating string elements, similar to the mixture between Set and Hash
- Although the elements in the collection are not ordered, each element in the ordered collection is associated with a floating-point value called score (which is why this type is also similar to hash because each element is mapped to a value).
- ZADD is similar to SADD, but has an additional parameter (placed before the element to be added), that is, score. ZADD is also variable, so you are free to specify multiple score value pairs
- The sorting set is implemented through a dual port data structure, which contains a jump table and a hash table, so every time we add an element, Redis performs O(log(N)) operations. This is good, but when we ask to sort the elements, Redis doesn't need to do any work at all. It has sorted all the elements
Pipeline
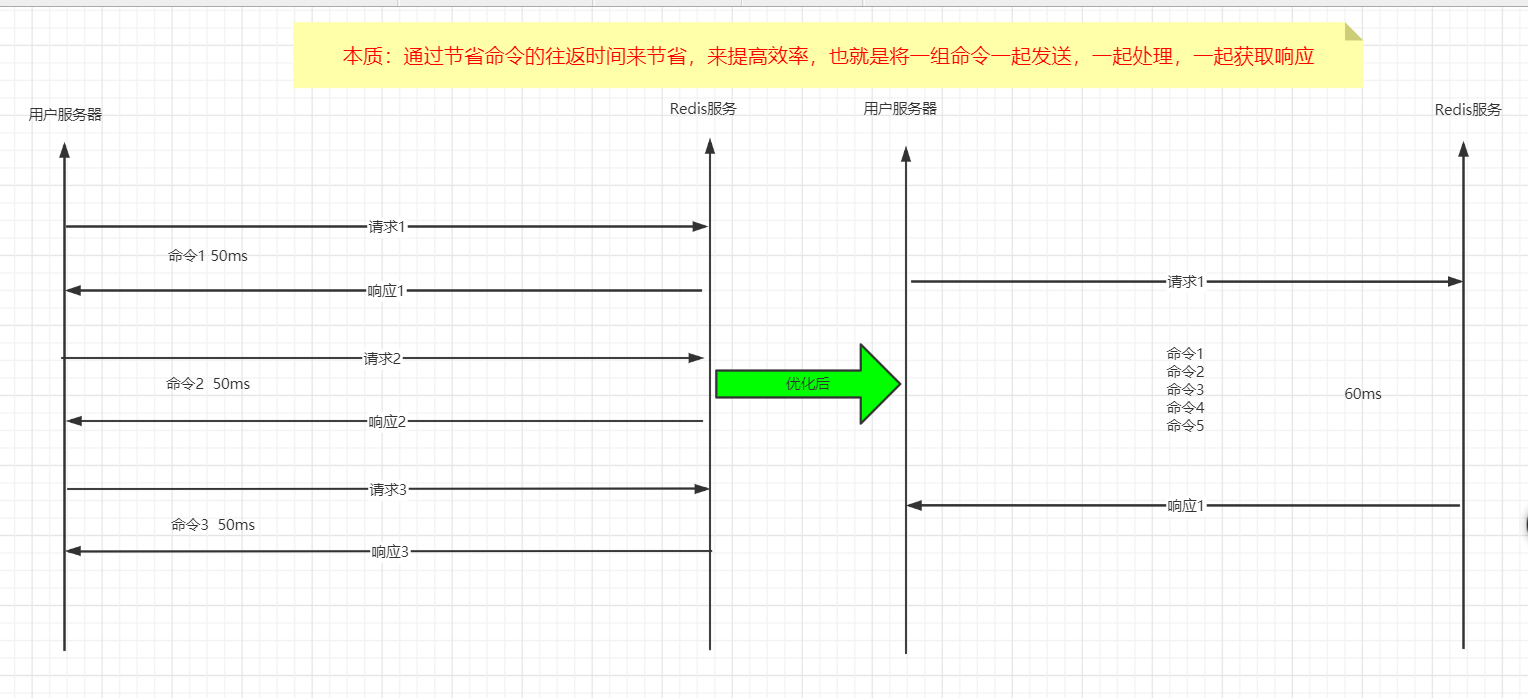
Redis is a TCP service based on client server model and request / response protocol.
This means that normally a request follows the following steps:
The client sends a query request to the server and listens for the return of the Socket, usually in blocking mode, waiting for the server to respond.
The server processes the command and returns the result to the client.
Therefore, for example, the following is the execution of four command sequences:
Client: INCR X Server: 1 Client: INCR X Server: 2 Client: INCR X Server: 3 Client: INCR X Server: 4
The client and server connect through the network. This connection can be fast (loopback interface) or slow (a network connection with multiple hops is established). No matter how long the network delays, data packets can always reach the server from the client, and return data from the server to the client.
This time is called RTT (Round Trip Time) When the client needs to execute multiple requests in a batch, it is easy to see how this affects performance (for example, adding many elements to the same list or filling the database with many Keys). For example, if the RTT time is 250 milliseconds (under a very slow connection), even if the server can process 100k requests per second, we can only process up to 4 requests per second.
If the loopback interface is adopted, the RTT is much shorter (for example, my host ping 127.0.0.1 only takes 44 milliseconds), but it is still a lot of overhead in a batch write operation. Fortunately, there is a way to improve this situation.
Redis pipeline
A request / response server can handle new requests even if the old requests have not been responded to. This allows multiple commands to be sent to the server without waiting for a reply, which is read in the last step.
This is pipelining, a technology widely used for decades. For example, many POP3 protocols have been implemented to support this function, which greatly speeds up the process of downloading new mail from the server.
Redis has long supported pipelining technology, so no matter what version you are running, you can use pipelining to operate redis. The following is an example:
$ (printf "PING\r\nPING\r\nPING\r\n"; sleep 1) | nc localhost 6379 +PONG +PONG +PONG
This time we did not spend RTT cost for each command, but only the cost time of one command.
Very clearly, the first example of sequential operation with pipes is as follows:
Client: INCR X Client: INCR X Client: INCR X Client: INCR X Server: 1 Server: 2 Server: 3 Server: 4
Important note:
When using the pipeline to send commands, the server will be forced to reply to a queue reply, which takes up a lot of memory. Therefore, if you need to send a large number of commands, it is best to process them in batches according to a reasonable number, such as 10K command, read reply, and then send another 10K command, etc. This speed is almost the same, but the 10K command queue needs a lot of memory to organize the returned data content.
Pipeline VS Scripting
A large number of pipeline application scenarios can be processed more efficiently through Redis script (Redis version > = 2.6), which performs a lot of work on the server side. A major advantage of the script is that it can read and write data with minimal delay, making the operations such as reading, calculation and writing very fast (pipeline cannot be used in this case, because the client needs to read the results returned by the command before writing the command).
Applications may sometimes send EVAL or EVALSHA commands in pipeline. Redis explicitly supports this situation through the SCRIPT LOAD command (to ensure the successful invocation of EVALSHA).
(ZSet,Lits) realize the user's praise function
Note:
Here is a comment based on the speed limit of ip address: IpInterceptor. See my blog for the specific implementation!
Java interface speed limiter - > annotation and reflection, enumeration, AOP interceptor, exception handling center, Redis actual combat
/**
* User likes
* @param likeUserOpenId Love bean id
* @param userSession Generate a third-party session token based on the opend of the applet user
* @return
*/
@IpInterceptor(requestCounts = 20,expiresTimeSecond = 60,isRestful = true,restfulParamCounts = 2)
@GetMapping("/userLikeDemo/{userSession}/{likeUserOpenId}")
public Result userLikeDemo(@PathVariable("likeUserOpenId") String likeUserOpenId,@PathVariable("userSession")String userSession) {
//1. Obtain the current identity of the user and replace the OpenId of the current registered user from redis through 3rdsession
String openId = (String)redisUtil.get(userSession);
if(SuperUtil.isNullOrEmpty(openId)){
return Result.handelLose("User identity exception!!!",200);
}
//Click like
boolean clickFlag = userService.userLikeDemo(openId, likeUserOpenId);
//It means you like it successfully
if(clickFlag){
return Result.handelSuccess("Like success");
//Failed to like
}else {
return Result.handelLose500("Failed to like,There are no votes left");
}
}
//--------------------------------------------------------------------------------------------------------------
/**
* Implementation of user like function
* 1.Check whether the user still likes the number of times through userOpenId
* 2.If yes, please like this likeUserOpenId user
* 3.And generate praise records
* @param userOpenId
* @param likeUserOpenId
* @return true Like success false like failure, no votes
*/
@Override
public boolean userLikeDemo(String userOpenId, String likeUserOpenId) {
//Initial parameter preparation
//The record flag true minus the default number of votes; false minus the number of votes purchased
boolean recordFlag = true;
//Is there a flag for the number of votes
boolean hasCountFlag=true;
//. first query whether this user's likes exist in redis
Integer defaultCount = (Integer) redisUtil.hget(USER_LIKE_COUNTS_PREFIX + userOpenId, "DEFAULT");//Default likes
Integer buyCount = (Integer) redisUtil.hget(USER_LIKE_COUNTS_PREFIX + userOpenId, "BUY"); //Number of likes to brush gifts
//If there is no data in the cache
if (SuperUtil.isNullOrEmpty(defaultCount) || SuperUtil.isNullOrEmpty(buyCount)) {
//1. Then query the database according to the user number
User user = userMapper.selectOne(new QueryWrapper<User>().eq("user_open_id", userOpenId));
//2. Judge whether the user has the default number of votes? Use default votes: use purchase votes
if (user.getUserDefaultLikeCount() >= 1) {
//Use default number of votes - 1
user.setUserDefaultLikeCount(user.getUserDefaultLikeCount() - 1);
} else if (user.getUserBuyLikeCount() >= 1) {
//Number of votes purchased - 1
user.setUserBuyLikeCount(user.getUserBuyLikeCount() - 1);
recordFlag = false;
} else {
hasCountFlag=false;
}
//3. Write the data back to redis and set 30 minute expiration
redisUtil.hset(USER_LIKE_COUNTS_PREFIX + user.getUserOpenId(), "DEFAULT", user.getUserDefaultLikeCount(), 30 * 60);
redisUtil.hset(USER_LIKE_COUNTS_PREFIX + user.getUserOpenId(), "BUY", user.getUserBuyLikeCount(), 30 * 60);
//It means that there is no vote like and the counting fails. Wait until the cache is loaded successfully and return directly
if(!hasCountFlag){
return false;
}
//The data representing the user is in the cache
} else {
//Because the like function is implemented based on redis, the number of users' likes will have a half-hour expiration period. This expiration period helps us brush the user's like records back to the database to ensure the consistency between the database and the cache
//However, if the user card has a bug and waits until the last minute to like, but the like data in our cache has not been updated to the database, and the data in the database replaces the data in the cache, it will lead to the problem of multiple investment
//Therefore, every time we like, we refresh the expiration time of the cache to ensure that the last like can have half an hour to brush the data back to the database
//1. Refresh cache time
redisUtil.expire(USER_LIKE_COUNTS_PREFIX+userOpenId,30*60);
//2. Judge whether the user has votes
if (defaultCount >= 1) {
//Use default number of votes - 1
redisUtil.hdecr(USER_LIKE_COUNTS_PREFIX + userOpenId, "DEFAULT", 1);
recordFlag = true;
} else if (buyCount >= 1) {
//Number of votes purchased - 1
redisUtil.hdecr(USER_LIKE_COUNTS_PREFIX + userOpenId, "BUY", 1);
recordFlag = false;
} else {
//No votes returned directly
return false;
}
}
//END if the number of votes is successfully reduced, the user's likes will be inserted into the redis (List) List
StringBuilder record=new StringBuilder(userOpenId).append("_").append(likeUserOpenId).append("_").append((recordFlag)?1:2);
//Refresh love bean votes
redisTemplate.opsForZSet().incrementScore(USER_LIKE_PREFIX,likeUserOpenId,1);
//Push likes to cache
redisUtil.lLeftPush(LIKE_RECORED_PREFIX,record);
return true;
}
(List, Pipeline pit avoidance) realize the synchronization of user praise data
Note:
Here, you need to calculate the number of likes used by users through the like records in the cache, and update the user's like records and like numbers synchronously in the database!
Before using Pipeline to execute the command set, there is a problem about serialization. It is easy to make mistakes when the serialization method of redisTemplate is not configured!!
Let's take a look at the source code of redisTemplate. By default, JdkSerializationRedisSerializer is loaded
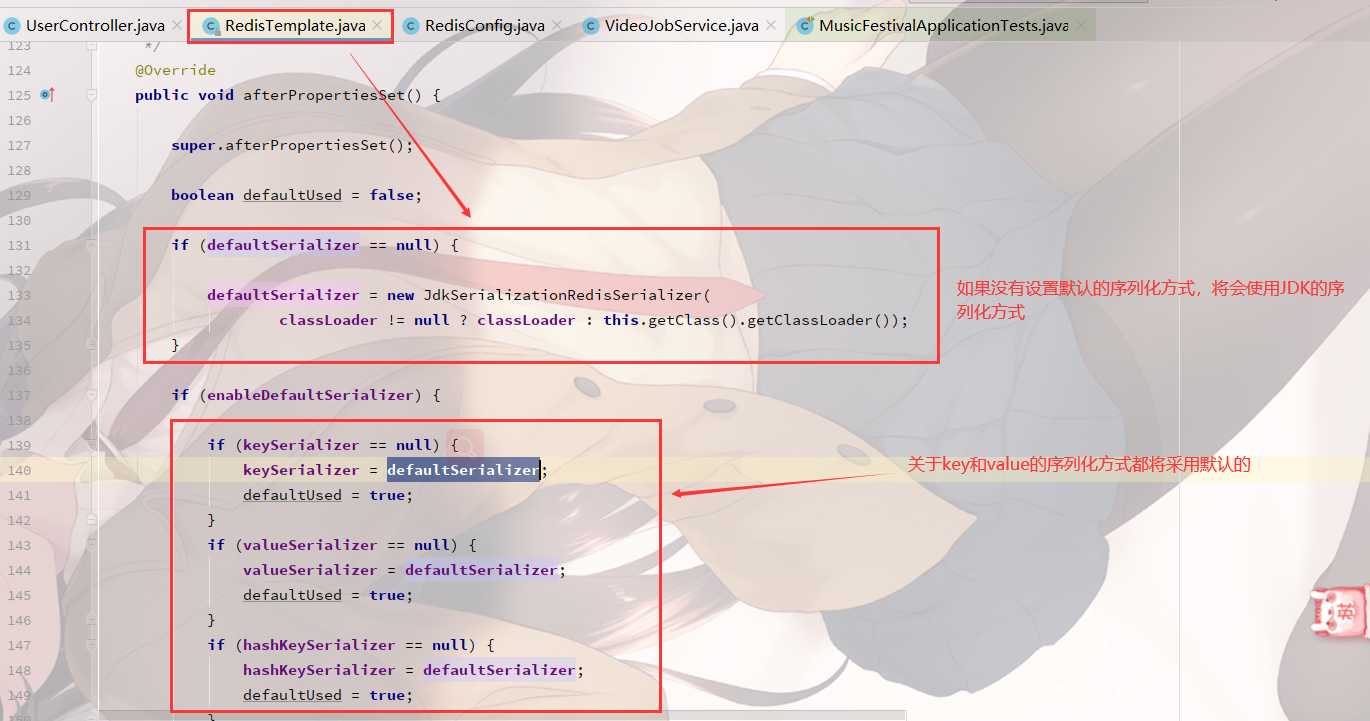
When the default serialization method is used without setting the serialization method! An error will be reported when using fastjason to deserialize an object!
org.springframework.data.redis.serializer.SerializationException: Could not deserialize: syntax error, pos 1, line 1, column 2sb; nested exception is com.alibaba.fastjson.JSONException: syntax error, pos 1, line 1, column 2sb at com.alibaba.fastjson.support.spring.FastJsonRedisSerializer.deserialize(FastJsonRedisSerializer.java:67) at org.springframework.data.redis.core.RedisTemplate.deserializeMixedResults(RedisTemplate.java:617) at org.springframework.data.redis.core.RedisTemplate.lambda$executePipelined$1(RedisTemplate.java:335) at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:228) at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:188) at org.springframework.data.redis.core.RedisTemplate.execute(RedisTemplate.java:175) at org.springframework.data.redis.core.RedisTemplate.executePipelined(RedisTemplate.java:324) at org.springframework.data.redis.core.RedisTemplate.executePipelined(RedisTemplate.java:314)
When using Pipeline to execute the command set, if the command has various return values, it is recommended to use the StringRedisSerializer serialization method, otherwise it will also lead to serialization problems, as shown in the following columns
List<Object> resultList = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public String doInRedis(RedisConnection connection) throws DataAccessException {
connection.lRange("USER_LIST".getBytes(),0,-1);
connection.set("cc".getBytes(),"test".getBytes());
connection.get("cc".getBytes());
connection.set("user".getBytes(),JSON.toJSONBytes(new User().setUserOpenId("6666").setUserCity("Shanghai")));
return null;
}
});//The serialization of String must be used here, because there will be many returned results, so the results will be processed according to String uniformly

All right! Start our official project actual combat code!!
/**
* The user's likes and the number of remaining tickets will be synchronized to the database every minute
*/
@Scheduled(cron = "0 0/1 * * * ?")
public void synLikeRecordDemo(){
//A collection used to store the batch addition of likes
List<LikeRecord> likeRecordList=new LinkedList<LikeRecord>();
//Count the usage of various likes of users
Map<String,Integer> map = new HashMap(256);
//Count the current users who use the number of likes, and the user resolution object
Set<String> userOpenIdSet = new HashSet(128);
//Batch modified collection
List<User> userCountList = new LinkedList<User>();
//Update voting records
executorService.execute(()->{
//Redis key to access
byte[] key =LIKE_RECORED_PREFIX.getBytes();
log.info("-----------------------------------------------------------------------Update the voting record and the number of votes left by the user-----------------------------------------------------------------------");
//The total number of cycles is one external cycle (one Pipelined) and 100 internal cycles
int allLoopCount=0;
//The number of times of the last inner loop (execute Pipelined once, which contains the command set)
int endInnerLoopCount=100;
//1. Query the length of the current queue
Long listSize = redisTemplate.opsForList().size("test_list");
//2. Calculate the number of outer loops and the number of the last inner loop, and execute 1000 commands at most each time
if(listSize>=1000){
allLoopCount=10;
}else{
endInnerLoopCount=(int)(listSize%100);
endInnerLoopCount=(endInnerLoopCount==0)?100:endInnerLoopCount;
allLoopCount=(int)Math.ceil(listSize / 100.0);
}
for (int i = 1; i <=allLoopCount ; i++) {
//The number of internal cycles is 100 by default. When it comes to the last time, the cycle is carried out according to the last cycle number according to the above calculation data
AtomicInteger innerLoopCount=new AtomicInteger(100);
if(i==allLoopCount){
innerLoopCount.set(endInnerLoopCount);
}
//3. Enable Pipelined execution command. The returned results of the execution command are in -- > pipelinedlist
List<Object> pipelinedList = redisTemplate.executePipelined(new RedisCallback<Object>() {
@Override
public Object doInRedis(RedisConnection connection) throws DataAccessException {
//Execute multiple commands to fetch data
for (int j = 1; j <= innerLoopCount.get(); j++) {
connection.listCommands().rPop(key);
}
//null must be returned here, and the final pipeline execution result will be returned to the outermost layer
return null;
}
//The serialization of String must be used here, because there will be many returned results, so the results will be processed according to String uniformly
},new StringRedisSerializer());
//4. Data processing
pipelinedList.forEach(item->{
String[] params =String.valueOf(item).split("_");
//Analyze whether the user uses the default or purchased votes. 1 is the default votes and 2 is the number of gifts
Integer likeType=Integer.parseInt(params[2]);
//Generate the likes record object and add it to the batch modified collection
likeRecordList.add(new LikeRecord().setClickUserOpenid(params[0]).setLikeUserOpenid(params[1]).setIsDefault(Integer.parseInt(params[2])));
//--------------------------------Calculate the number of votes used by each user and which votes were used respectively--------------------------------------
//The user id is stored in the set, and the number of votes of those users needs to be modified
userOpenIdSet.add(params[0]);
//Calculate the number and type of votes used by users to like and which user's key key = user ID + user's like type
StringBuilder hashKey =new StringBuilder(params[0]).append("_") .append((likeType == 1) ? "default" : "buy");
//Get the calculated votes according to the hashKey
Integer userUseCount = map.get(hashKey);
//If it is blank, it represents the number of likes of this user for the first time
if(SuperUtil.isNullOrEmpty(userUseCount)){
//. store the user's key and count likes in the map
map.put(hashKey.toString(),1);
}else {
//. this record is not the number of times the user likes it for the first time
userUseCount++;
map.put(hashKey.toString(),userUseCount);
}
});//Processing pipeline data
}//Outermost cycle
//Analyze the number of likes of a specific user and the number of votes used respectively
if(!userOpenIdSet.isEmpty()){
userOpenIdSet.forEach(userOpenId->{
//Analyze the number of votes used according to the user's number
Integer defaultCount = map.get(userOpenId + "_default");
Integer buyCount =map.get(userOpenId+"_buy");
//Save the corresponding user number and the number of votes used by the user into the object and then into the set to be modified
userCountList.add( new User().setUserOpenId(userOpenId).setUserDefaultLikeCount(defaultCount).setUserBuyLikeCount(buyCount));
});
}
//Like records are inserted into the database in batches
if(!likeRecordList.isEmpty()){
likeRecordService.saveBatch(likeRecordList,likeRecordList.size());
}
//Update the number of likes used by users
if(!userCountList.isEmpty()){
userMapper.upadateUserCountByOpenId(userCountList);
}
});//Child thread end
}
(Zset) realize the synchronization of love bean votes
Synchronize the number of love bean votes of ZSet in the cache to the database!
/**
* Sync player likes every 4 and a half minutes
*/
@Scheduled(cron = "0/30 0/4 * * * ?")
public void synUserRanking(){
//User store update user likes data set
List<User> userList = new LinkedList<>();
//Create child threads to execute tasks
executorService.execute(()-> {
System.out.println("-----------------------------------------------------------------------Sync player likes-----------------------------------------------------------------------");
//1. Take out the likes of all players from redis and the OpenId of players from set
Set<ZSetOperations.TypedTuple<Object>> userLikeSet = redisTemplate.opsForZSet().rangeWithScores("USER_LIKE", 0, -1);
//2. If the set set is not empty, traverse the value
if (SuperUtil.notNull(userLikeSet)) {
//3. Traverse the corresponding User number and likes, store them in the User object, and then store them in the collection for unified modification
for (ZSetOperations.TypedTuple<Object> typedTuple : userLikeSet) {
userList.add(new User().setUserOpenId((String) typedTuple.getValue()).setUserLike(new BigInteger(String.valueOf(typedTuple.getScore().intValue()))));
}
}
//4.end the last value will batch modify the player's likes to the database
if (!userList.isEmpty()) {
userMapper.updateBatchByOpenId(userList);
}
});
}
(List) realize the query and update of love bean List. If the cache needs to be updated, how to solve the cache breakdown?
The first point is to ensure that all users access the cache and update the cache regularly, but the cache will not be broken down
Do you still remember a small series of questions we will encounter when we first learn Java?
/**
*Now there is a variable int a=6; int b=10; Exchange 2 variable values!!!
*/
public static void exchangeNumber(int a,int b){
int c=0;
c=a;
a=b;
b=c;
System.out.println(a+"--"+b);
}
public static void main(String[] args) {
exchangeNumber(6,10);
}
We usually use an intermediate variable to exchange!!!
My solution here is also based on such an intermediate variable!!!
1. We load the data into the cache and load two copies without setting the expiration time. When we update the cache, we first delete the first cache until the first cache is successfully updated, then delete the second cache and update the second cache
2. When the user requests, first query the first cache. Because the cache needs to be updated, there is a gap time when loading data and updating, so we go to access the second cache. Because it does not fail, we can ensure that no matter how many user threads we go, we are walking cache data, and there is no cache gap period, resulting in penetration!
Specific implementation of user reading data:
/**
* Query the user list and rank according to likes
* @param pageIndex Current page number
* @return
*/
@GetMapping("/userMatchData/{pageIndex}")
public Result userMatchData(@PathVariable("pageIndex")Long pageIndex ){
Long pageStart=(pageIndex-1)*10;
Long pageEnd=(pageIndex*10)-1;
//First, judge whether there is data in the cache
if(redisUtil.hasKey("USER_LIST")){
//1. Query the data from the cache
List user_list = redisTemplate.opsForList().range("USER_LIST", pageStart, pageEnd);
//2. Return the result to the front end
return Result.handelSuccess("Query user leaderboard succeeded",user_list);
//No cache copy query
}else {
List user_list_copy = redisTemplate.opsForList().range("USER_LIST_COPY", pageStart, pageEnd);
//2. Return the result to the front end
return Result.handelSuccess("Query user leaderboard succeeded",user_list_copy);
}
}
When updating the cache, a spin lock method is adopted to ensure that the cache must be updated before the replica cache can be released!!
Update ranking data:
/**
* Update the user ranking data in redis every 5 minutes
*/
@Scheduled(cron = "0 0/5 * * * ?")
public void repalceUserList(){
executorService.execute(()->{
//1. Query all users participating in the competition
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
//First, the query condition is that the contestants query in descending order according to the number of users' likes
queryWrapper.eq("user_type",2).orderBy(true,false,"user_like");
//query
List<User> userList = userMapper.selectList(queryWrapper);
//2. Delete the user ranking data in redis. At this time, all user visits have been recorded in our copy
redisUtil.del("USER_LIST");
//3. Set the newly queried results to redis
redisTemplate.opsForList().rightPushAll("USER_LIST",userList);
//4. The thread sleeps for 50ms to ensure that the data can be synchronized to redis
try {
Thread.sleep(50);
} catch (InterruptedException e) {
e.printStackTrace();
}
//5. Use spin lock to judge whether the user ranking data cache is set successfully
while (redisUtil.hasKey("USER_LIST")){
//6. Delete cache copy
redisUtil.del("USER_LIST_COPY");
//7. Update the cache copy again
redisTemplate.opsForList().rightPushAll("USER_LIST_COPY",userList);
log.info("to update redis User ranking data succeeded!!!");
return;
}
});
}
Note: there is a pit here. Why use the sub threads of the thread pool to update the cache!! The main reason is that there is only one thread to execute the scheduled task in Spring by default, which means that multiple scheduled tasks need to be executed every 5 minutes. It is not parallel, but serial. If one scheduled task is not executed, another scheduled task will not be executed, You need to configure it here (it's not mentioned in many tutorials) or you can use Quarzt!!! You can check out another blog I wrote (not yet!!)
Thread pool creation
Because we need to use the thread pool, we generally do not use the default strategy. According to your business scenario, the default thread pool creation method may lead to a waste of resources or an excessive number of threads created. If the server does not support it at all, it is unknown. The detailed parameters created are written clearly and can be referred to directly!!! Here, it is created uniformly through the configuration class and injected into the Spring container, which is convenient for other places to call!!
**
* @Author: Joker-CC
* @Path:
* @Date 2021/05/29 23:52
* @Description:
* @Version: 1.0
*/
@Configuration
public class ThreadConfig {
//Create thread pool
//Seven parameters
//int corePoolSize 1. The number of core threads is 2 -- >, which is equivalent to the default open area of the bank counter
//int maximumPoolSize 2. The maximum number of threads is 4 -- >, which is equivalent to the maximum opening of the bank counter -- > optimization 1 For cpu intensive computers, you can set up several cores as many as you have IO intensive usually needs to open threads twice the number of cpu cores. Only when the number of core threads + the len gt h of the blocking queue < the number of requested threads, the maximum number of threads will be triggered. Otherwise, the core thread will be used
//long keepAliveTime 3. The survival time of redundant idle threads is 10 minutes. When the number of threads in the current pool exceeds corePoolSize, when the idle time reaches eepAliveTime, the redundant threads will be destroyed until only corePoolSize threads are left.
//TimeUnit unit 4. Time unit of keepalivetime parameter -- > timeunit Minutes minutes
//BlockingQueue<Runnable> workQueue 5. The work queue (blocking queue) is equivalent to the bank according to FIFO (first input, first out)
//ThreadFactory threadFactory 6. Thread engineering uses the default thread factory
//RejectedExecutionHandler handler 7. Four rejection strategies: when the task in the work queue is full and the number of threads in the thread pool reaches the maximum, if a new task is submitted, the rejection strategy is to solve this problem
//① Where does CallerRunsPolicy come from? Where does it go!
//Execute the run method of the rejected task directly in the caller thread, and discard the task directly unless the thread pool has been shut down.
//② The AbortPolicy bank is full, and someone else comes in. If you don't deal with this person, throw an exception
//Directly discard the task and throw the RejectedExecutionException exception.
//③ The DiscardPolicy queue is full. Lose the task and no exception will be thrown!
//Just drop the task and do nothing.
//④ DiscardOldestPolicy / / when the queue is full, try to compete with the earliest one without throwing an exception!
//Discard the task that first entered the queue, and then try to put the rejected task into the queue.
@Bean(name = "diyThreadPool")
public ExecutorService createExecutorService(){
return new ThreadPoolExecutor(6,16,10L, TimeUnit.MINUTES,new LinkedBlockingQueue<>(1000), Executors.defaultThreadFactory(),new ThreadPoolExecutor.CallerRunsPolicy());
}
}