1, Foreword
This is the second source code analysis after the hard core ArrayList source code analysis, which promised me to read it once a day; After learning this article, you will have a comprehensive understanding of the structure and methods of HashMap; Superman doesn't know how strong he is in the interview; For example, the capacity expansion mechanism of HashMap, what is the maximum capacity, how the HashMap linked list is transferred to the red black tree, why the thread of HashMap is not safe, whether the key and value of HashMap can be null, etc;
2, Source code analysis
2.1 official practice
- Officials say * * HashMap implements the Map interface and has all Map operations; The key and value are allowed to be null** Practice whether it is like this;
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
map.put(null,null);
System.out.println(map);//{null=null}
}
If so, there is no error; Add a null key and value to see; Do not paste the code, and the final output is still a {null=null}; It indicates that the key of HashMap is unique;? How to ensure the uniqueness of key? Continue to analyze later;
- Continue to look at the official description. The difference between HashMap and HashTable is that HashMap is not synchronized, HashTable does not allow key and value is null; Practice it
public static void main(String[] args) {
Hashtable hashtable = new Hashtable();
hashtable.put(null,null);
}
The console is red!!! The output contents are as follows: shock, the key and value of HashTable really cannot be null;
{null=null}Exception in thread "main"
java.lang.NullPointerException
at java.util.Hashtable.put(Hashtable.java:459)
at test.HashMapTest.main(HashMapTest.java:17)
Process finished with exit code 1
Click the source code to see that the put method of hashtable starts with Make, and Make sure that the key and value cannot be null and synchronized; Life is doubtful, because knowledge seekers have never used hashtable code before;
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
- Continue to look at the official instructions. HashMap cannot guarantee the order of the contents in the map; Try it again. If so, what makes the original map order inconsistent? Follow up analysis
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
map.put("early morning","The baby cried");
map.put("noon","The baby is hungry");
map.put("night","Baby doesn't want to sleep");
System.out.println(map);//{noon = baby hungry, night = baby doesn't want to sleep, morning = baby crying}
}
The follow-up official instructions can not be described in just a few words. After the appetizer is finished, let's look at the specific source code. Remember to look at the Tip when reviewing;
Tip:
HashMap allows both key and value to be null;key is unique;
The difference between HashMap and HashTable is that HashMap is not synchronized, HashTable does not allow key, and value is null;
HashMap cannot guarantee the order of the contents in the Map
2.2 analysis of spatial parameter construction method
Test code
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
}
The source code of the construction method is as follows. The value of the load factor of the HashMap is 0.75 by default;
public HashMap() {//Default factor DEFAULT_LOAD_FACTOR=0.75; Initialization capacity is 16
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
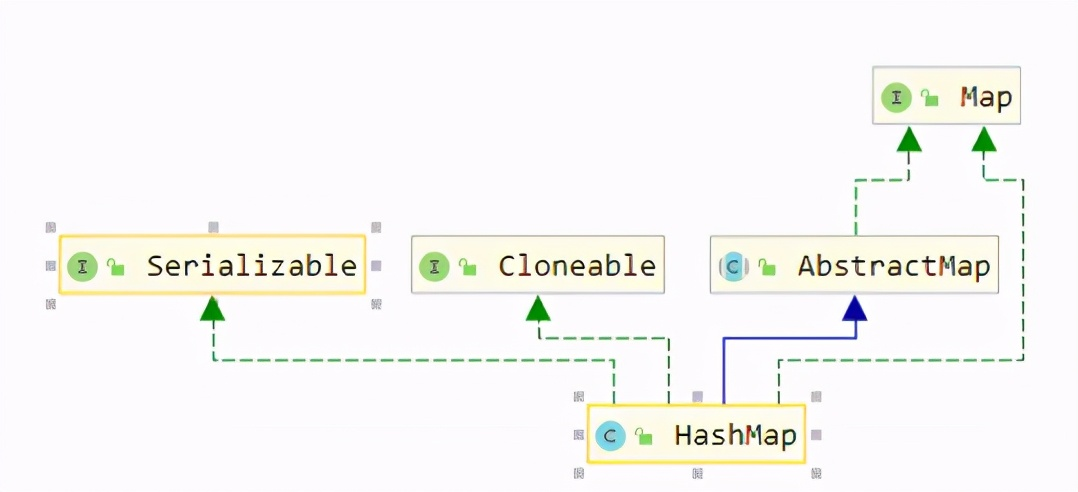
After walking through it, the parent class is as follows
HashMap --> AbstractMap --> Object
Look at the parent class map of HashMap. The structure is very simple, isn't it;
See here, knowledge seekers have two questions
Question 1: what is the load factor of 0.75?
Question 2: where is the initialization capacity 16?
First answer the question of initialization capacity 16. The knowledge seeker finds the member variable, and the default initialization capacity field value is 16; And the default initialization value must be a multiple of 2;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 default initialization capacity
Answer: load factor 0.75 refers to a capacity expansion mechanism of HashMap; For example, if the expansion factor is 0.7, the capacity is assumed to be 10; Capacity expansion occurs when the inserted data reaches the 10th * 0.7 = 7; Then the knowledge seeker calculates the HashMap expansion algorithm, 0.75 * 16 = 12; That is, after inserting 12 numbers, the HashMap will be expanded;
Tip: HashMap default factor 0.75; Initialization capacity 16; If the given initialization capacity is 12, the capacity will be expanded after inserting 12 numbers of data;
2.3 implementation principle analysis of HashMap
The description of the official source code is as follows: the implementation of HashMap is realized by bucket and hash table. When the capacity of bucket is too large, it will be transformed into tree node (similar to TreeMap, because the bottom layer of TreeMap is realized by red black tree, it is also right to say that bucket is transformed into red black tree);
Throw a question: what is a bucket?
Before answering the bucket, let's first understand what a hash table is
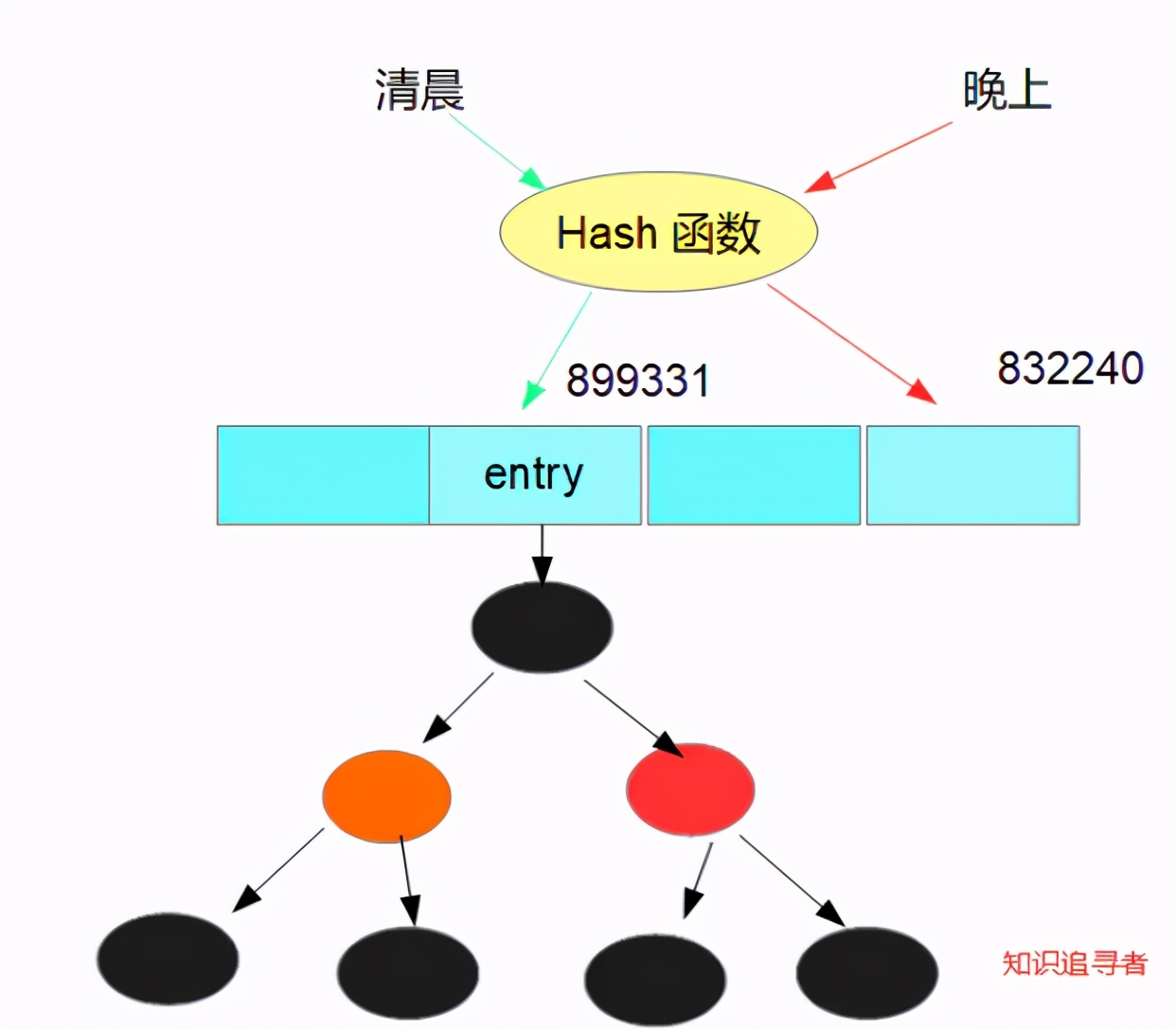
Hash table is essentially a linked list array; The int value calculated by hash algorithm finds the corresponding position on the array; Throw a picture for readers to see;
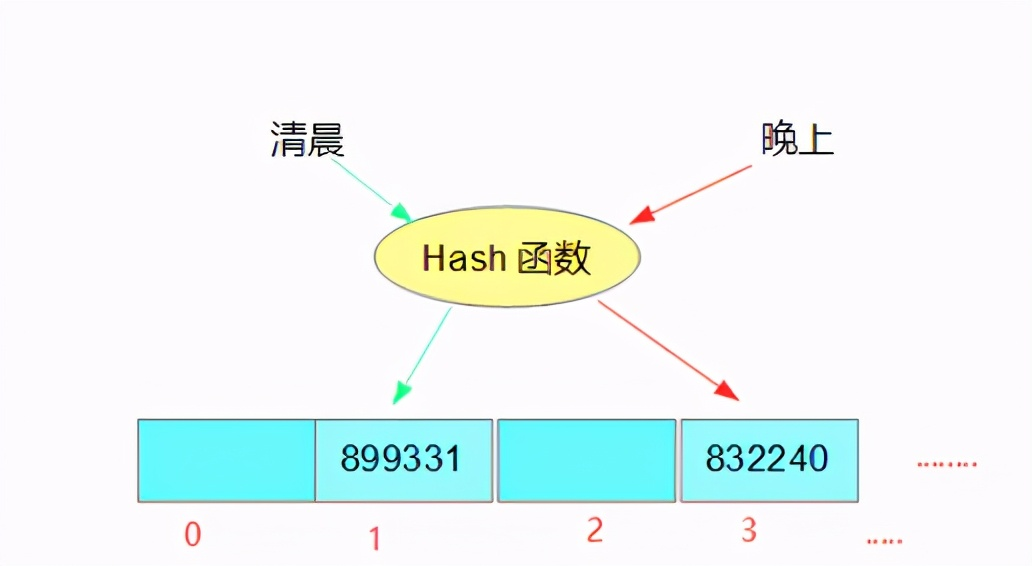
The knowledge seeker really broke his heart for the readers and threw you another method to calculate the hash value; Remember to review the hashCode() method of the java basic String class; If two objects are the same, the hash value is the same; If the contents of two strings are the same (equals method), the hash value is the same;
public static void main(String[] args) {
int hash_morning = Objects.hashCode("early morning");
int hash_night = Objects.hashCode("night");
System.out.println("matin hash value:"+hash_morning);//Morning hash value: 899331
System.out.println("Evening hash value:"+hash_night);//hash value at night: 832240
}
Continue to talk about our bucket. A bucket is each node in a linked list. You can also understand it as an entry on the tab in the figure below; Look at the picture
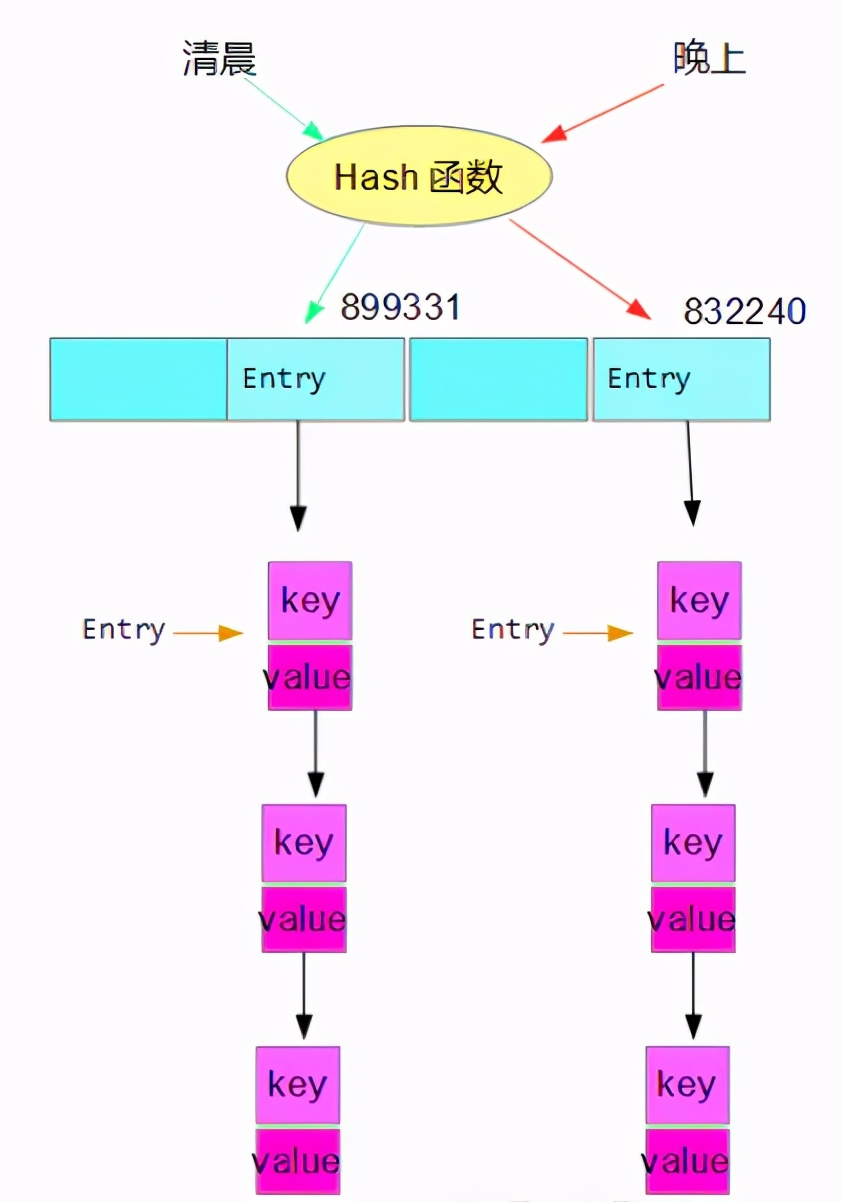
When the capacity of the bucket reaches a certain number, it will turn into a red black tree. Look at the picture
Readers here must have gained a lot. This is just an appetizer. Let's enter today's topic, source code analysis;
2.4 put method source code analysis
Test code
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>();
map.put("early morning","The baby cried");
System.out.println(map);
}
The first step is to enter the put method, which contains the putVal method
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);//
}
First hash the key, and then use it as the hash in putVal
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Look at the content of putVal method. Because only one data is inserted and the index is empty, the content in else will not be taken. The knowledge seeker will omit it here;
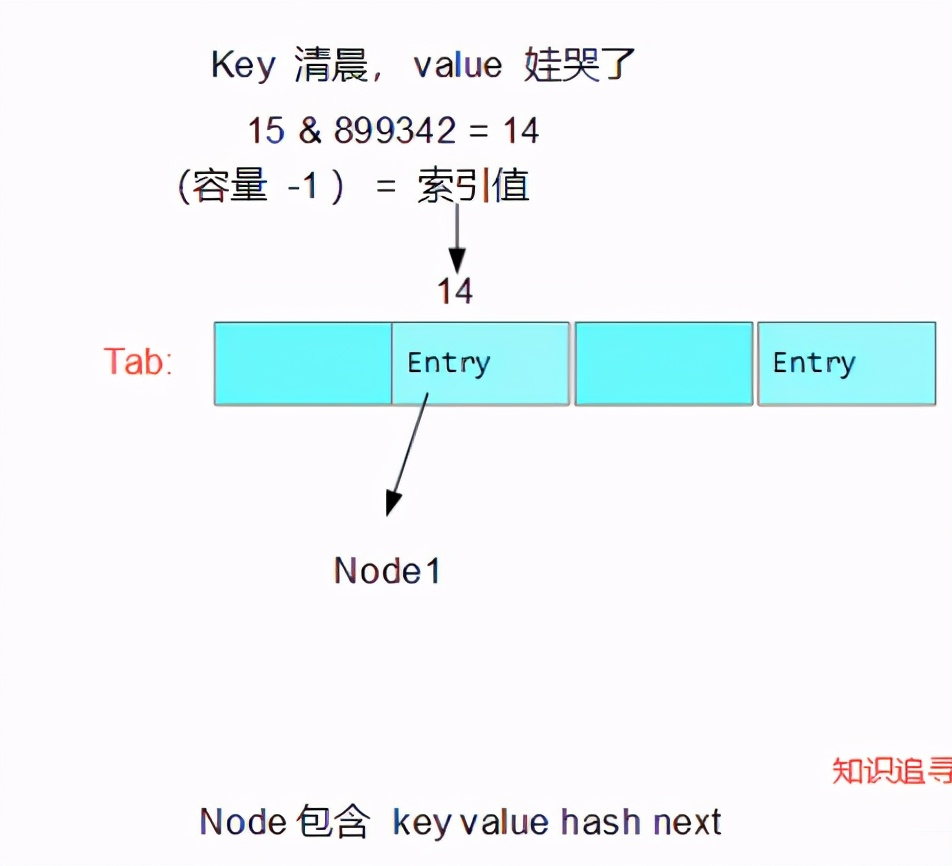
It can be clearly seen that a Node (Node < K, V > will be given below) is created and put into the tab. The tab is also well understood, which is a list of nodes; Its index i = (capacity - 1) & hash value is essentially the result of taking the hash value and, so it is a hash table;
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {//evict =true
Node<K,V>[] tab; Node<K,V> p; int n, i;// Declare tree array, tree node, n,i
if ((tab = table) == null || (n = tab.length) == 0)//table is empty
n = (tab = resize()).length; // Resize() is node < K, V > [] resize() n is the length of the tree, which is n=16 according to the initial capacity
if ((p = tab[i = (n - 1) & hash]) == null) // i = (16-1) & hash ---> 15 & 899342 = 14 ;
tab[i] = newNode(hash, key, value, null);// Create a new node and insert data
else {
.......
}
++modCount;//Set structure modification times + 1
if (++size > threshold)// size=1 ; threshold=12
resize();
afterNodeInsertion(evict);
return null;
}
I made a chart here and recorded it
The Node code is as follows
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;//Hash value key value hash value of XOR
final K key;//key
V value;//value
Node<K,V> next;//Store next node
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
...........
The knowledge seeker went in for another night, ran through the code and turned to the following figure
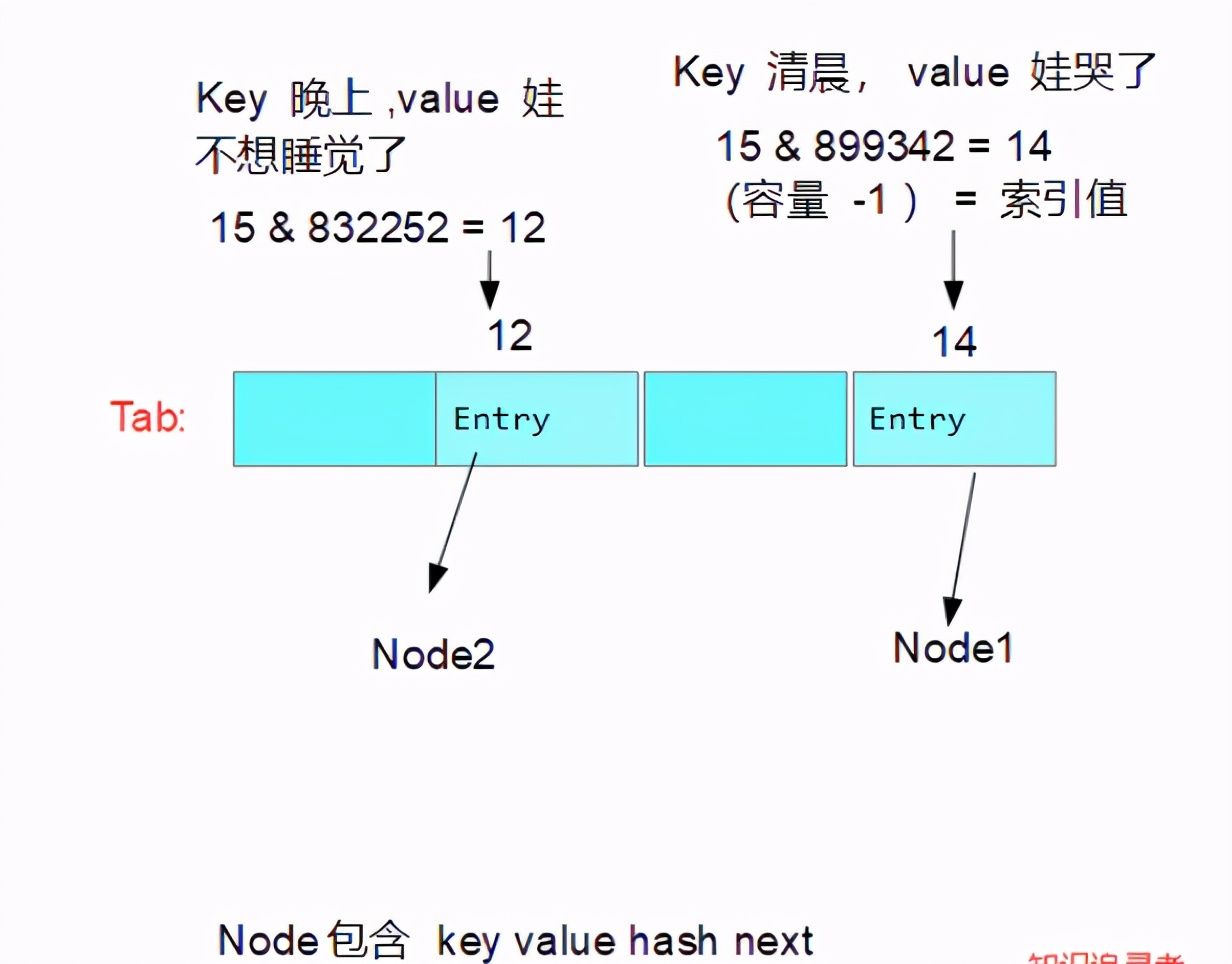
So the knowledge seeker puts forward an idea: the binary of 15 is 1111. After XOR is performed on the hash value of any key and value, the hash value of Node is obtained and then combined with the original 1111, that is, the last four bits of the binary of Node hash value shall prevail; The capacity of tab is 16; After saving a Node, the size is increased by 1, that is, only 12 values can be stored at most, and the capacity will be expanded; In this case, as long as the hash value is the same, there will be a collision, and then enter the else method. The problem arises. How to construct two identical Node hash values is a problem; Here are some examples:
Reference link: blog csdn. net/hl_ java/art…
public static void main(String[] args) {
System.out.println(HashMapTest.hash("Aa"));//2112
System.out.println(HashMapTest.hash("BB"));//2112
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
Continue the experiment. After finding that the hash value of the key is the same, it will enter the else method and add a Node to store Bb in the original AA Node attribute next; Wow, isn't this the implementation of an entry linked list
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {//evict =true
Node<K,V>[] tab; Node<K,V> p; int n, i;// Declare tree array, tree node, n,i
if ((tab = table) == null || (n = tab.length) == 0)//table is empty
n = (tab = resize()).length; // Resize() is node < K, V > [] resize() n is the length of node, which is n=16 according to the initial capacity
if ((p = tab[i = (n - 1) & hash]) == null) // I = (16-1) & hash -- > 15 & hash value
tab[i] = newNode(hash, key, value, null);// Create a new node and insert data
else {
Node<K,V> e; K k; // Declare node k
if (p.hash == hash && // p this node stores AA -- > A; hash 2112
((k = p.key) == key || (key != null && key.equals(k))))//The key content here is different, so it does not enter, so it is not the same node
e = p;
else if (p instanceof TreeNode)// This p is not a TreeNode, so we didn't switch to red black tree plus Node
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) { // The default number of buckets is 0
if ((e = p.next) == null) { // Assign the next Node of this Node p to e as null; The beginning of the linked list
p.next = newNode(hash, key, value, null);// P create a node to store BB -- > b
// Where TREEIFY_THRESHOLD = 8
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);//Treelization
break;
}
if (e.hash == hash && //Here is to determine whether p and e are the same Node
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;//If the key is the same, the new value will replace the old value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//Set structure modification times + 1
if (++size > threshold)// size=1 ; threshold=12
resize();
afterNodeInsertion(evict);
return null;
}
The knowledge seeker records that after the original key passes through the hash, if the hash value is the same, a linked list will be formed. Looking at the code, we also know that except for the first Entry on the Tab, the Node of each Entry behind is a bucket; You can see that a for loop is an infinite loop. If the hash value of the key is the same for 8 times, treeifyBin(tab, hash) will be called; The knowledge seeker understands that as long as the number of buckets reaches 8, the linked list nodes will be treed; This is array + linked list (the Node of each list is a bucket) - > array + red black tree; Why should the linked list be transformed into a red black tree? This takes into account the efficiency of the algorithm. The time complexity of the linked list is o(n), while the time complexity of the red black tree is o(logn), and the search efficiency of the tree is higher;
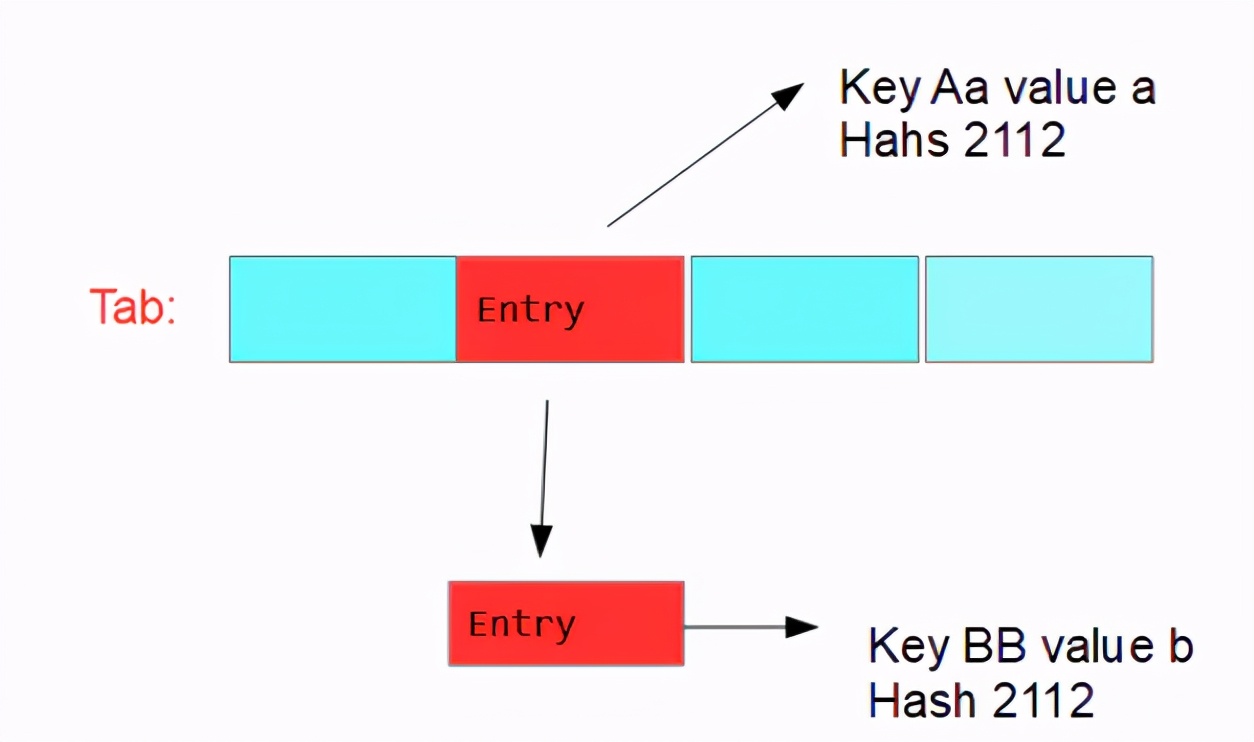
Tip: HashMap is essentially a string of hash tables; The hash table is first composed of array + linked list; After hash collision, a linked list will be formed, and the node of each linked list is a bucket; When the number of buckets reaches 8, the linked list will be transformed into a red black tree. At this time, the HashMap structure is array + red black tree; If the same key is inserted, the new value will replace the old value;
2.5 expansion source code analysis
Test code
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
}
First enter the HashMap initialization code
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);// Capacity 12, load factor 0.75
}
Enter the constructor to have a look; It is very simple that the maximum capacity of HashMap is the 30th power of 2; Secondly, since the input number is 12 and not the power of 2, the capacity expansion will be carried out, and the result of capacity expansion is very simple, that is, the power of 2 greater than the output value; The power of 2 greater than 12 is 16;
public HashMap(int initialCapacity, float loadFactor) {//initialCapacity=12,loadFactor=0.75
if (initialCapacity < 0)//If the capacity is less than 0, an illegal parameter exception is thrown
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)// MAXIMUM_ Capability = 1 < < 30, that is, the 30th power of 2; Record the maximum hashMap
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor)) // LoadFactor = 0.75 > 0, otherwise an illegal parameter exception will be thrown
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;//Load factor assignment
this.threshold = tableSizeFor(initialCapacity);// Returns the capacity of a quadratic length; At this point, threshold = 16
}
Click to see what tableSizeFor(initialCapacity) is; Multiple unsigned right bits or operations; Its purpose is to construct a 2-power 1; Very simple calculation, readers can calculate by themselves;
static final int tableSizeFor(int cap) {//cap=12
int n = cap - 1;// n =11
n |= n >>> 1;// 11. The result of unsigned shift to the right by 1 bit is in phase or with 11; n=15
n |= n >>> 2;//n=15
n |= n >>> 4;//n=15
n |= n >>> 8;//n=15
n |= n >>> 16;//n=15
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;//15+1=16
}
Tip: the capacity expansion mechanism of HashMap is the first quadratic power greater than the input capacity value
2.6 source code analysis
Test code
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
map.put("a","b");
map.get("a");
}
Enter get method
public V get(Object key) {
Node<K,V> e;//Declare Node e
return (e = getNode(hash(key), key)) == null ? null : e.value;// Get the Node according to the hash Value of the key, and the Node returns the Value
}
After entering the getNode(hash(key), key) method, you can see that the entry node on the tab has been preferentially selected; If not, it will enter the linked list or red black tree to traverse and compare the hash value to obtain the node; After reading the put source code, the get source code has no singularity;
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;// Declare node array tab, node first, E; n ,k
if ((tab = table) != null && (n = tab.length) > 0 &&// tab.length =16, i.e. capacity
(first = tab[(n - 1) & hash]) != null) { // It is the same as the calculated hash value of get; Hash value = (capacity - 1) & hash gets tab index; Then get the index value and assign it to first
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))//Directly check whether it is enrty on the tab, and directly return to the Node
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)//If it is a red black tree, it will traverse to obtain the node
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);//Otherwise, loop through the linked list to obtain nodes
}
}
return null;
}
2.7 hashCode source code analysis
Test code
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
map.put("a","b");
map.put("b","c");
int hashCode = map.hashCode();
System.out.println(hashCode);//4
}
Entering hashCode is to traverse the hash value of each entrySet and add it as the hash value of HashMap
public int hashCode() {
int h = 0;
Iterator<Entry<K,V>> i = entrySet().iterator();//iterator
while (i.hasNext())
h += i.next().hashCode();//Iterate and add the hash value of each entrySet
return h;
}
Make a verification
public static void main(String[] args) {
HashMap<String, Object> map = new HashMap<>(12);
map.put("a","b");
map.put("b","c");
Set<Map.Entry<String, Object>> entries = map.entrySet();
entries.stream().forEach(entry->{
System.out.println(entry.hashCode());
});
}
The output content is 1, 3;
Tip: the hashCode of HashMap is the sum of the hash values of entry, where the hash value of Node is the sum of the hash values of key and value;
3, Summary
- HashMap allows both key and value to be null;key is unique;
- The difference between HashMap and HashTable is that HashMap is not synchronized, HashTable does not allow key, and value is null;
- HashMap cannot guarantee the order of the contents in the Map
- HashMap default factor 0.75; Initialization capacity 16; If the given capacity is 12, inserting 12 numbers and then inserting data will expand the capacity;
- HashMap is essentially a string of hash tables; The hash table is first composed of array + linked list; After hash collision, a linked list will be formed, and the node of each linked list is a bucket; When the number of linked trees reaches hash8, the linked tree will be blackened, and the number of linked trees will be changed to hash8; If the same key is inserted, the new value will replace the old value;
- The capacity expansion mechanism of HashMap is the first quadratic power greater than the input capacity value; For example, 12 is 16 after capacity expansion; 17 after capacity expansion, it is 32;
- The hashCode of HashMap is the sum of the hash values of entry, where the hash value of Node is the sum of the hash values of key and value;
last
That's all I want to share with you this time
The information is all in -*** My study notes: real questions of large factory interview + micro service + MySQL+Java+Redis + algorithm + Network + Linux+Spring family bucket + JVM + study note map***
Finally, I will share a big gift package (learning notes) of the ultimate hand tearing architecture: distributed + micro services + open source framework + performance optimization
Is a string of hash tables; The hash table is first composed of array + linked list; After hash collision, a linked list will be formed, and the node of each linked list is a bucket; When the number of buckets reaches 8, the linked list will be transformed into a red black tree. At this time, the HashMap structure is array + red black tree; If the same key is inserted, the new value will replace the old value;
- The capacity expansion mechanism of HashMap is the first quadratic power greater than the input capacity value; For example, 12 is 16 after capacity expansion; 17 after capacity expansion, it is 32;
- The hashCode of HashMap is the sum of the hash values of entry, where the hash value of Node is the sum of the hash values of key and value;
last
That's all I want to share with you this time
The information is all in -*** My study notes: real questions of large factory interview + micro service + MySQL+Java+Redis + algorithm + Network + Linux+Spring family bucket + JVM + study note map***
Finally, I will share a big gift package (learning notes) of the ultimate hand tearing architecture: distributed + micro services + open source framework + performance optimization