preface
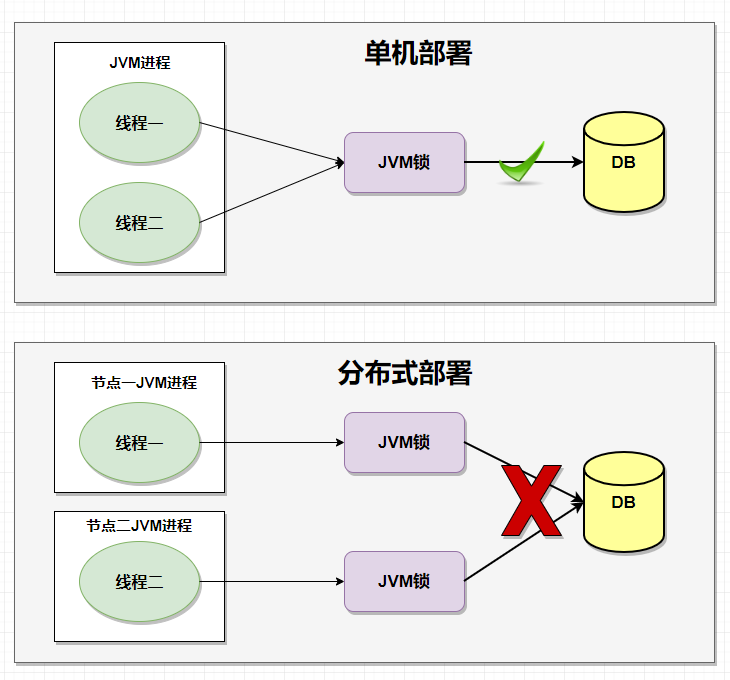
In Java, we are familiar with locks. The commonly used locks are synchronized and Lock. In Java Concurrent Programming, we use locks to solve the problem of data inconsistency caused by multiple threads competing for the same shared resource or variable. However, JVM locks can only be used for a single application service. With the development of our business, The system deployed in a single machine has long evolved into a distributed system. Due to the multithreading and multi process of the distributed system and distributed on different machines, the concurrency control of JVM Lock has no effect at this time. In order to solve the cross JVM Lock and control the access to shared resources, distributed Lock was born.
What is distributed lock
Distributed lock is a way to control synchronous access to shared resources between distributed systems. In distributed systems, it is often necessary to coordinate their actions. If different systems or different hosts of the same system share one or a group of resources, they often need to be mutually exclusive to prevent interference with each other to ensure consistency. In this case, distributed locks need to be used
Why can't JVM lock in distributed mode?
We can see from the code that why the jvm lock under the cluster is unreliable? Let's simulate the scene of rush purchase of goods. Ten users of service A rush to buy the goods, and ten users of service B rush to buy the goods. When one user succeeds in rush purchase, other users can't place an order for the goods. So, will service A or service B rush to the goods? Let's have A look
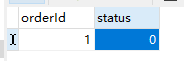
When one of the users succeeds in snapping up, the status will change to 1
GrabService:
public interface GrabService {
/**
* Rush for orders
* @param orderId
* @param driverId
* @return
*/
public ResponseResult grabOrder(int orderId, int driverId);
}
GrabJvmLockServiceImpl:
@Service("grabJvmLockService")
public class GrabJvmLockServiceImpl implements GrabService {
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId, int driverId) {
String lock = (orderId+"");
synchronized (lock.intern()) {
try {
System.out.println("user:"+driverId+" Execute order logic");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("user:"+driverId+" checkout success ");
}else {
System.out.println("user:"+driverId+" Order failed");
}
} finally {
}
}
return null;
}
}
OrderService :
public interface OrderService {
public boolean grab(int orderId, int driverId);
}
OrderServiceImpl :
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper mapper;
public boolean grab(int orderId, int driverId) {
Order order = mapper.selectByPrimaryKey(orderId);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(order.getStatus().intValue() == 0) {
order.setStatus(1);
mapper.updateByPrimaryKeySelective(order);
return true;
}
return false;
}
}
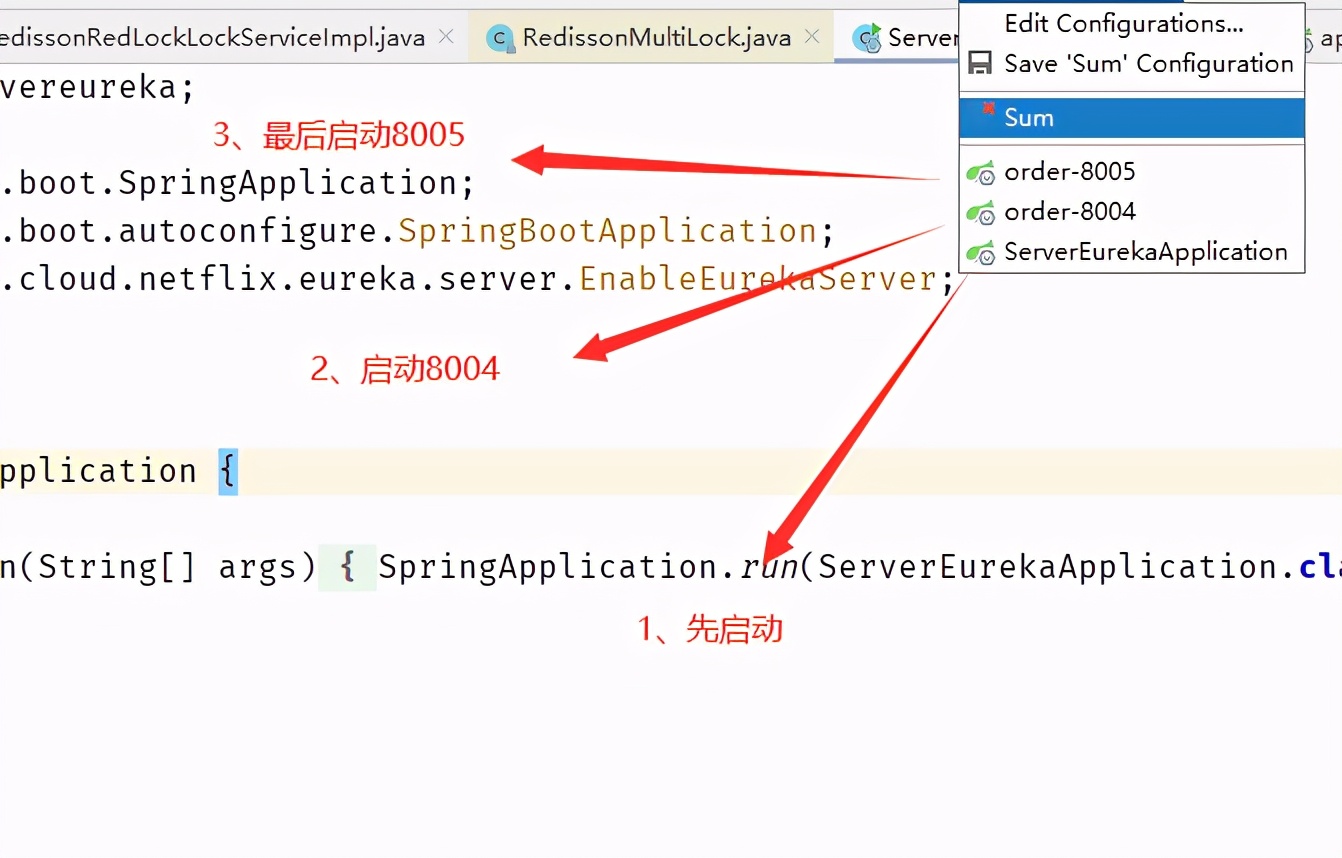
Here, we simulate the cluster environment and start two ports, 8004 and 8005, for access
Here we test with jmeter
If you don't know jmeter, you can see my previous article on pressure measurement of tomcat: tomcat optimization
Project startup sequence: start the server Eureka registry first, and start ports 8004 and 8005
Test results:
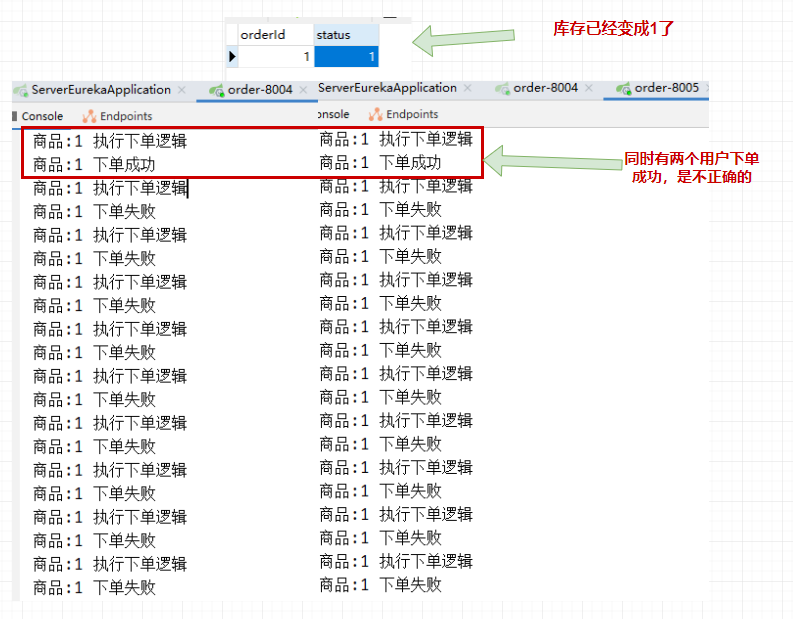
Here we can see that both 8004 service and 8005 service # have a user to place a successful order for this product, but only one user can grab this product. Therefore, if the jvm lock is in cluster or distributed, it can not guarantee access to the data of shared variables. At the same time, only one thread can access it, which can not solve the problem of distributed and cluster environment. So you need to use distributed locks.
Three implementation methods of distributed lock
There are three ways to implement distributed locks:
- Implementation of distributed lock based on Database
- Implementing distributed lock based on Redis
- Implementation of distributed lock based on Zookeeper
Today, we are mainly talking about distributed locks based on Redis
reids implements distributed locks in three ways
1. Implementation of distributed lock in SETNX based on redis
2. Redisson implements distributed locks
4. Using redLock to realize distributed lock
Directory structure:
Method 1: implement distributed lock based on SETNX
Set the value of the key to value if and only if the key does not exist.
If the given key already exists, SETNX will not take any action.
setnx: set only when the key exists and no operation is performed and the key does not exist
Locking:
SET orderId driverId NX PX 30000
If the above command is executed successfully, the client successfully obtains the lock, and then can access the shared resources; If the above command fails to execute, it indicates that obtaining the lock fails.
Release lock:
The key is to judge whether you added the lock yourself.
GrabService :
public interface GrabService {
/**
* Rush for orders
* @param orderId
* @param driverId
* @return
*/
public ResponseResult grabOrder(int orderId, int driverId);
}
GrabRedisLockServiceImpl :
@Service("grabRedisLockService")
public class GrabRedisLockServiceImpl implements GrabService {
@Autowired
StringRedisTemplate stringRedisTemplate;
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId , int driverId){
//Generate key
String lock = "order_"+(orderId+"");
/*
* In case 1, what if the lock is not released, for example, half of the business logic is executed, the operation and maintenance service is restarted, or the server hangs up and does not go finally?
* Add timeout
*/
// boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId+"");
// if(!lockStatus) {
// return null;
// }
/*
* Case 2: if the timeout is added, the operation and maintenance will restart
*/
// boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId+"");
// stringRedisTemplate.expire(lock.intern(), 30L, TimeUnit.SECONDS);
// if(!lockStatus) {
// return null;
// }
/*
* Case 3: the timeout time should be added at one time and should not be divided into two lines of code,
*
*/
boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId+"", 30L, TimeUnit.SECONDS);
if(!lockStatus) {
return null;
}
try {
System.out.println("user:"+driverId+" Execute order grabbing logic");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("user:"+driverId+" Order grabbing succeeded");
}else {
System.out.println("user:"+driverId+" Order grabbing failed");
}
} finally {
/**
* This kind of release lock may release someone else's lock.
*/
// stringRedisTemplate.delete(lock.intern());
/**
* The following code avoids releasing other people's locks
*/
if((driverId+"").equals(stringRedisTemplate.opsForValue().get(lock.intern()))) {
stringRedisTemplate.delete(lock.intern());
}
}
return null;
}
}
Someone may ask here, what will I do if the execution time of my business exceeds the time of lock release? We can use the daemon thread. As long as our current thread still holds the lock, at 10S, the daemon thread will automatically add time to the thread and continue the expiration time of 30S. Until the lock is released, the contract will not be renewed. Open a child thread. The original time is N, and continue N every N/3
Focus:
- key is our target to lock, such as order ID.
- driverId is our product ID, which should ensure that all requests for locks from all clients are unique for a long enough period of time. That is, an order is robbed by a user.
- NX indicates that SET can succeed only when orderId does not exist. This ensures that only the first requesting client can obtain the lock, while other clients cannot obtain the lock until the lock is released.
- PX 30000 indicates that this lock has an automatic expiration time of 30 seconds. Of course, 30 seconds here is just an example. The client can choose the appropriate expiration time.
- This lock must be set with an expiration time. Otherwise, when a client acquires the lock successfully, if it crashes or can no longer communicate with Redis node due to network partition, it will always hold the lock, and other clients will never be able to obtain the lock. antirez also emphasized this point in the later analysis, and called this expiration time lock validity time. The client that obtains the lock must complete the access to the shared resource within this time.
- This operation cannot be split. SETNX orderId driverId
Exhibit OrderID 30 although the execution effect of these two commands is the same as that of a SET command in the previous algorithm description, they are not atomic. If the client crashes after executing SETNX, there will be no chance to execute express, resulting in it holding the lock all the time. Cause deadlock.
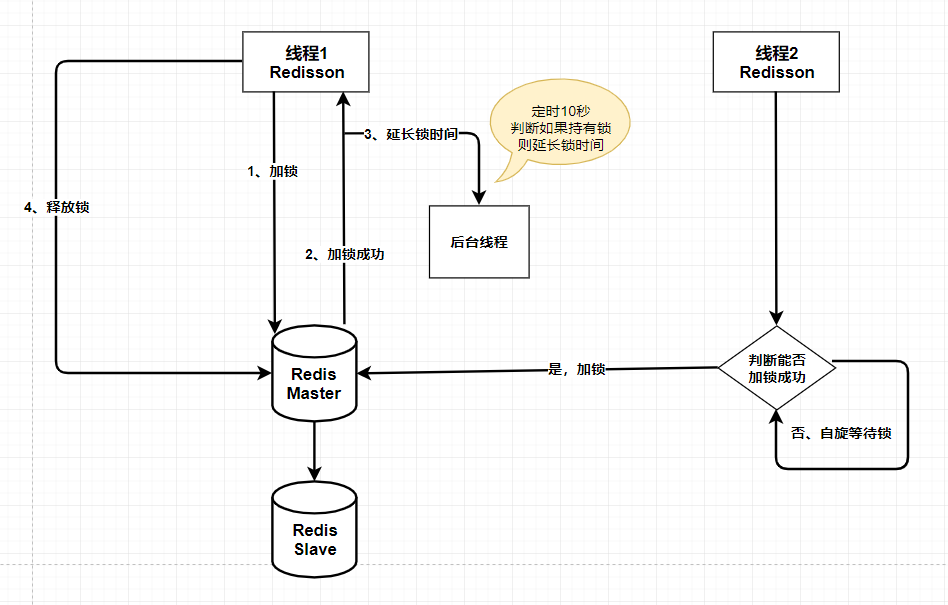
Method 2: implement distributed lock based on redisson
flow chart:
Code implementation:
@Service("grabRedisRedissonService")
public class GrabRedisRedissonServiceImpl implements GrabService {
@Autowired
RedissonClient redissonClient;
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId , int driverId){
//Generate key
String lock = "order_"+(orderId+"");
RLock rlock = redissonClient.getLock(lock.intern());
try {
// This code sets the key timeout of 30 seconds by default. After 10 seconds, it will be delayed again
rlock.lock();
System.out.println("user:"+driverId+" Execute order grabbing logic");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("user:"+driverId+" Order grabbing succeeded");
}else {
System.out.println("user:"+driverId+" Order grabbing failed");
}
} finally {
rlock.unlock();
}
return null;
}
}
Focus:
- redis failed.
If redis fails, all clients cannot obtain locks and the service becomes unavailable. To improve availability. We configure master-slave for redis. When the master is unavailable, the system switches to slave. Because the master-slave replication of redis is asynchronous, it may lead to the loss of lock security. 1 Client 1 obtained the lock from the master.
2. The Master is down, and the key of the storage lock has not yet been synchronized to the Slave. 3. Upgrade Slave to Master. 4. Client 2 obtains the lock corresponding to the same resource from the new Master. Client 1 and client 2 hold the lock of the same resource at the same time. The security of the lock was broken. - How long is the lock validity time set? If the setting is too short, the lock may expire before the client completes the access to the shared resources, thus losing protection; If the setting is too long, once a client holding a lock fails to release the lock, all other clients will be unable to obtain the lock, so they will not work normally for a long time. It should be set a little shorter. If the thread holds the lock, the thread will automatically extend the validity period
Method 3: realize distributed lock based on RedLock
For the above two points, antirez designed the Redlock algorithm
Andrez, the author of Redis, gave a better implementation, called Redlock, which is the official guidance specification of Redis for implementing distributed locks. The algorithm description of Redlock is put on the official website of Redis:
https://redis.io/topics/distlock
Purpose: mutually exclusive access to shared resources
Therefore, antirez proposed a new distributed lock algorithm, Redlock, which is based on N completely independent Redis nodes (usually n can be set to 5), which means that n Redis data are not interconnected, similar to several strangers
Code implementation:
@Service("grabRedisRedissonRedLockLockService")
public class GrabRedisRedissonRedLockLockServiceImpl implements GrabService {
@Autowired
private RedissonClient redissonRed1;
@Autowired
private RedissonClient redissonRed2;
@Autowired
private RedissonClient redissonRed3;
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId , int driverId){
//Generate key
String lockKey = (RedisKeyConstant.GRAB_LOCK_ORDER_KEY_PRE + orderId).intern();
//Red lock
RLock rLock1 = redissonRed1.getLock(lockKey);
RLock rLock2 = redissonRed2.getLock(lockKey);
RLock rLock3 = redissonRed2.getLock(lockKey);
RedissonRedLock rLock = new RedissonRedLock(rLock1,rLock2,rLock3);
try {
rLock.lock();
// This code sets the key timeout of 30 seconds by default. After 10 seconds, it will be delayed again
System.out.println("user:"+driverId+" Execute order grabbing logic");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("user:"+driverId+" Order grabbing succeeded");
}else {
System.out.println("user:"+driverId+" Order grabbing failed");
}
} finally {
rLock.unlock();
}
return null;
}
}
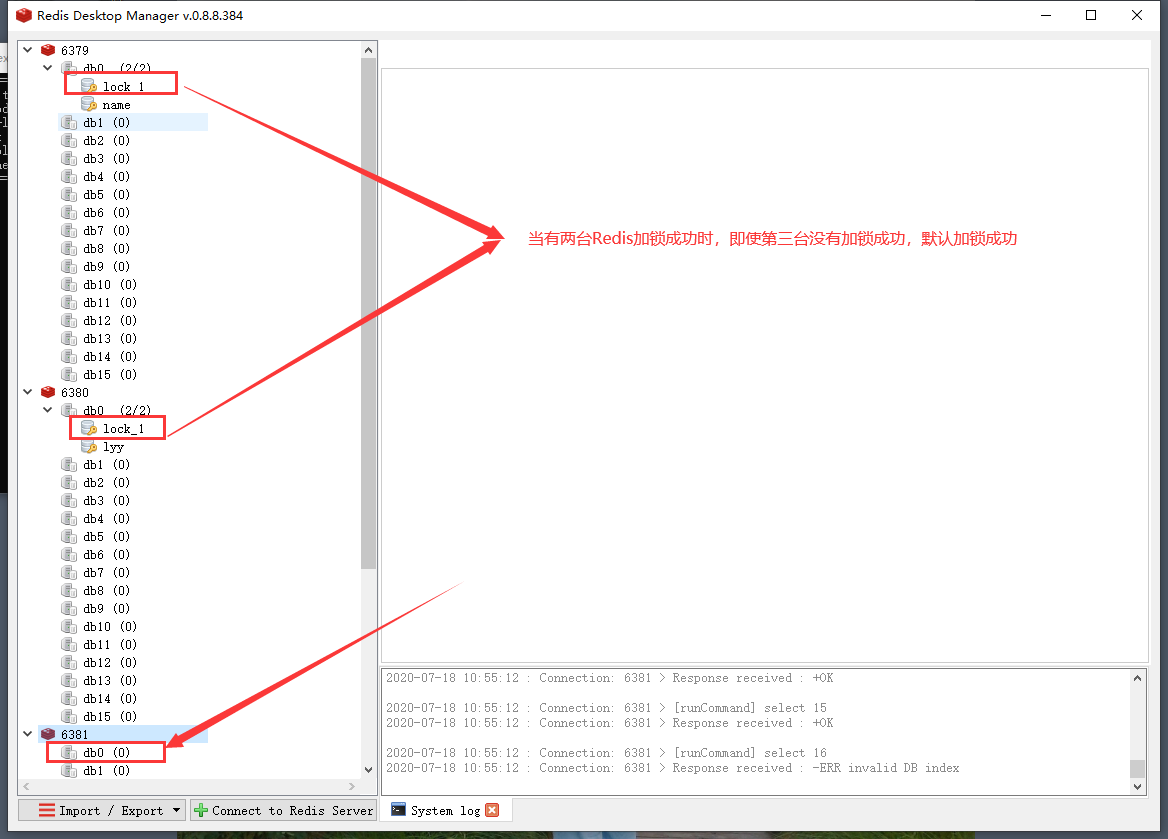
The client running the Redlock algorithm performs the following steps in turn to complete the operation of obtaining the lock:
- Gets the current time in milliseconds.
- Perform the operations of {obtaining locks} to N Redis nodes in sequence. This acquisition operation is the same as the previous process of "acquiring lock" based on a single Redis node, including value driverId and expiration time (such as "PX 30000", i.e. the effective time of the lock). In order to ensure that the algorithm can continue to run when a Redis node is unavailable, the operation of {acquiring lock} also has a timeout time, which is much less than the effective time of the lock (tens of milliseconds).
- After the client fails to obtain a lock from a Redis node, it should immediately try the next Redis node. The failure here should include any type of failure. For example, the Redis node is unavailable, or the lock on the Redis node has been held by other clients
- Calculate the total time spent in the whole lock acquisition process by subtracting the time recorded in step 1 from the current time. If the client successfully obtains the lock from most Redis nodes (> = n / 2 + 1), for example: if five machines are locked successfully, three machines will be locked successfully by default, and the total time spent acquiring the lock does not exceed the lock validity time, then the client will consider that the lock is finally obtained successfully; Otherwise, it is considered that the final acquisition of the lock failed
- If the lock is finally obtained successfully, the effective time of the lock should be recalculated, which is equal to the effective time of the original lock minus the time consumed to obtain the lock calculated in step 3.
- If the lock acquisition fails in the end (probably because the number of Redis nodes acquiring the lock is less than N/2+1, or the time consumed in the whole process of acquiring the lock exceeds the initial effective time of the lock), the client should immediately initiate the operation of "releasing the lock" to all Redis nodes (i.e. the Redis Lua script described earlier).
The above description only describes the process of obtaining locks, but the process of releasing locks is relatively simple: the client initiates the operation of releasing locks to all Redis nodes, regardless of whether these nodes succeed in obtaining locks at that time.
summary
summary
Generally speaking, if you want to change your career to be a programmer, Java development can be your first choice. But no matter what programming language you choose, improving your hardware strength is the only way to get a high salary.
If you follow this learning route, you will have a more systematic knowledge network, and you won't learn the knowledge very scattered. Personally, I don't recommend reading Java programming ideas and Java core technology at the beginning. After reading them, you will definitely give up learning. It is suggested that you can watch some videos to learn. When you can get started and buy these books, it is very rewarding.
These videos can be shared free of charge if necessary, Click here to get it for free
The surface describes only the process of acquiring locks, while the process of releasing locks is relatively simple: the client initiates the operation of releasing locks to all Redis nodes, regardless of whether these nodes succeed in acquiring locks at that time.
summary
summary
Generally speaking, if you want to change your career to be a programmer, Java development can be your first choice. But no matter what programming language you choose, improving your hardware strength is the only way to get a high salary.
If you follow this learning route, you will have a more systematic knowledge network, and you won't learn the knowledge very scattered. Personally, I don't recommend reading Java programming ideas and Java core technology at the beginning. After reading them, you will definitely give up learning. It is suggested that you can watch some videos to learn. When you can get started and buy these books, it is very rewarding.
These videos can be shared free of charge if necessary, Click here to get it for free