1, Background of the incident
One day last month, due to the lack of cluster space, an employee with higher authority in the company executed the manual cleaning command on an online cluster through the springboard machine and frantically executed hadoop fs -rmr -skipTrash /user/hive/warehouse/xxxxx. Suddenly, I didn't know whether it was the editor problem or line feed problem, and the command was truncated, The command became hadoop fs -rmr -skipTrash /user/hive/warehouse, and the tragedy began to happen now!?
/The user/hive/warehouse directory stores the data of all hive tables. The associated companies have multiple business lines. Once lost, it means huge losses. The addition of the - skipTrash parameter means that the deleted data will not be put into the recycle bin, but will be deleted directly. If this parameter is not added, it is easy to retrieve it. You can find it directly in the recycle bin. Unfortunately, you can't escape Murphy's law. The most worried thing happened.
The only thing that leaders can't solve is my little brother. Let's see what I can do next.
2, Emergency measures
The O & M found me at the first time and said that the / user/hive/warehouse directory was deleted by mistake. I was also shocked at that time. It's over! With my only intuition, I immediately stopped the HDFS cluster! The latter proved to be a wise choice.
Intuitive scheme
- Restore via snapshot? hdfs snapshot has never been used or created, so this road is blocked
- Recover through recycle bin? The - skipTrash parameter is added during deletion. It will not be put in the recycle bin, and this road is blocked
- Delete the library and run away to become a legend? Well, not bad
3, Analysis process
If you want to recover data, you must first understand the process of hdfs deleting files. The deletion logic of each file system is different. After understanding the hdfs deletion process, you can know what the above hadoop fs -rmr xxxx has done, whether it has been saved, how to save it, and so on.
-
hdfs file deletion process
The following is the method to delete the path of HDFS. The source path is org apache. hadoop. hdfs. server. namenode. FSNamesystem. delete()
boolean delete(String src, boolean recursive, boolean logRetryCache) throws IOException { waitForLoadingFSImage(); BlocksMapUpdateInfo toRemovedBlocks = null; writeLock(); boolean ret = false; try { checkOperation(OperationCategory.WRITE); checkNameNodeSafeMode("Cannot delete " + src); toRemovedBlocks = FSDirDeleteOp.delete( // @1 this, src, recursive, logRetryCache); ret = toRemovedBlocks != null; } catch (AccessControlException e) { logAuditEvent(false, "delete", src); throw e; } finally { writeUnlock(); } getEditLog().logSync(); if (toRemovedBlocks != null) { removeBlocks(toRemovedBlocks); // @2 } logAuditEvent(true, "delete", src); return ret; }Three important things are done in code @1
① Delete the path from the directory tree maintained by NameNode, which is the fundamental reason why you can't view the path through hadoop fs -ls xxx or other APIs after deleting
② Find out the block information associated with the deleted path. Each file contains multiple block blocks distributed in each DataNode. At this time, the block blocks on the physical disk on the DataNode are not physically deleted
③ Record the deletion log to editlog (this step is also very important, even the key to recovering data later)
Code @2 adds the information of the block to be deleted to org apache. hadoop. hdfs. server. blockmanagement. In the invalideblocks object maintained in blockmanager, invalideblocks is specifically used to save copies of data blocks waiting to be deleted
The above steps do not involve real physical deletion
BlockManager
BlockManager manages the life cycle of HDFS blocks and maintains block related information in Hadoop clusters, including a series of functions such as fast reporting, replication, deletion, monitoring, marking and so on.
There is a method invalidewforonenode() in BlockManager, which is specially used to delete the blocks stored in invalidblocks to be deleted on a regular basis. This method will periodically cycle the logic of putting the blocks to be deleted into the DatanodeDescriptor in the internal thread class ReplicationMonitor of BlockManager when the NameNode is started. The call path of the method is as follows:
org.apache.hadoop.hdfs.server.namenode.NameNode#initialize(Configuration conf) org.apache.hadoop.hdfs.server.namenode.NameNode#startCommonServices(Configuration conf) org.apache.hadoop.hdfs.server.namenode.FSNamesystem#startCommonServices(Configuration conf, HAContext haContext) org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#activate(Configuration conf) org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.ReplicationMonitor#run() org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#computeDatanodeWork() org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#computeDatanodeWorkcomputeInvalidateWork(int nodesToProcess) org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#invalidateWorkForOneNode(DatanodeInfo dn) org.apache.hadoop.hdfs.server.blockmanagement.InvalidateBlocks#invalidateWork(final DatanodeDescriptor dn)The BlockManager maintains the invalideblocks and stores the blocks to be deleted. When the NameNode is started, the BlockManager will start a thread separately and regularly put the block information to be deleted into the invalideblocks, Each time, the blockinvalidelinimit (from the configuration item dfs.block.invalidate.limit, 1000 by default) will be taken out from the invalideblocks queue for each DataNode. The block logic is in BlockManager The computeinvalidatework() method will put the block information to be deleted into the invalideblocks array in the DatanodeDescriptor. When the DatanodeManager heartbeat through the DataNode and NameNode, it will build the instruction set to delete the block. The NameNode then sends the instruction to the DataNode. The heartbeat is called by the DatanodeProtocol. The call path of the method is as follows:
org.apache.hadoop.hdfs.server.protocol.DatanodeProtocol#sendHeartbeat() org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer#sendHeartbeat() org.apache.hadoop.hdfs.server.namenode.FSNamesystem#handleHeartbeat() org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager#handleHeartbeat()
DatanodeManager. The instruction to build and delete in handleheartbeat() is sent to DataNode, and the code to be sent by NameNode is as follows:
/** Handle heartbeat from datanodes. */ public DatanodeCommand[] handleHeartbeat(Formal parameter strategy){ // .... Other code logic is omitted //check block invalidation Block[] blks = nodeinfo.getInvalidateBlocks(blockInvalidateLimit); if (blks != null) { cmds.add(new BlockCommand(DatanodeProtocol.DNA_INVALIDATE, blockPoolId, blks)); } // .... The rest of the code logic is omitted return new DatanodeCommand[0]; }The characteristic of regular round robin + limit 1000 block deletion determines that the HDFS deleted data will not be physically deleted immediately, and the number of deleted data at one time is also limited. Therefore, in the above emergency measures, it is the wisest choice to stop the HDFS cluster immediately. Although some data has been deleted in the round robin, the earlier the HDFS cluster is stopped after the incident, the less data will be deleted, The smaller the loss!
EditLog
Another key to data recovery is EditLog. EditLog records every log record of HDFS operation, including deletion. The file operation types we are familiar with are only add, delete and change, but in the field of HDFS, there are far more than these operations. Let's take a look at the enumeration class of EditLog operation type org apache. hadoop. hdfs. server. namenode. FSEditLogOpCodes
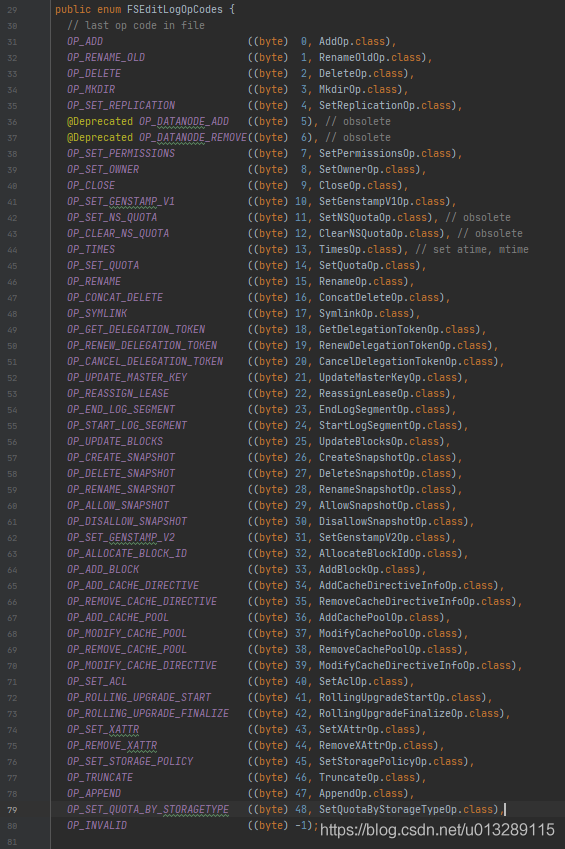
More than 40 operation types in total! It breaks people's impression that there are only several operations of adding, deleting and rereading documents. Does it break your imagination?
What does EditLog look like? In hadoop configuration parameter DFS namenode. name. Dir can find the path
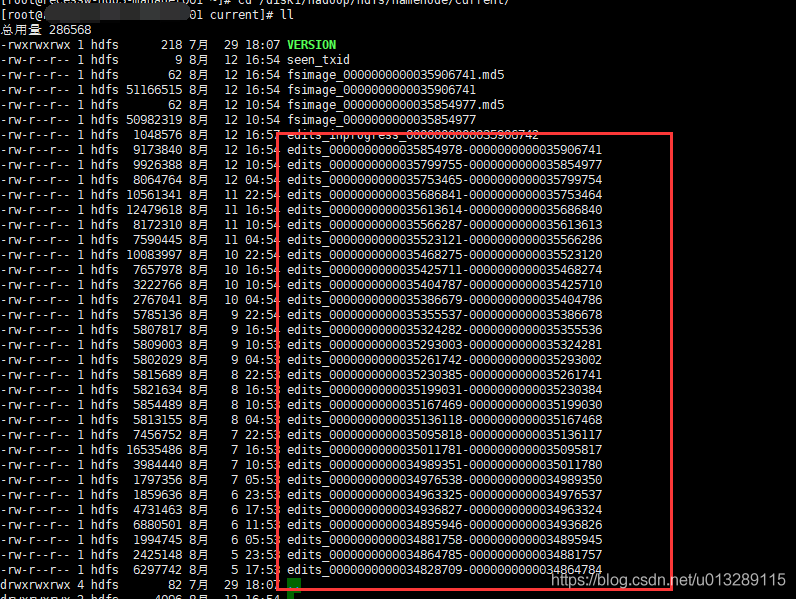
The EditLog file here is a serialized binary file and cannot be viewed directly. hdfs has its own parsing command, which can be parsed into xml plaintext format. Let's parse it
hdfs oev -i edits_0000000000035854978-0000000000035906741 -o edits.xml
see file
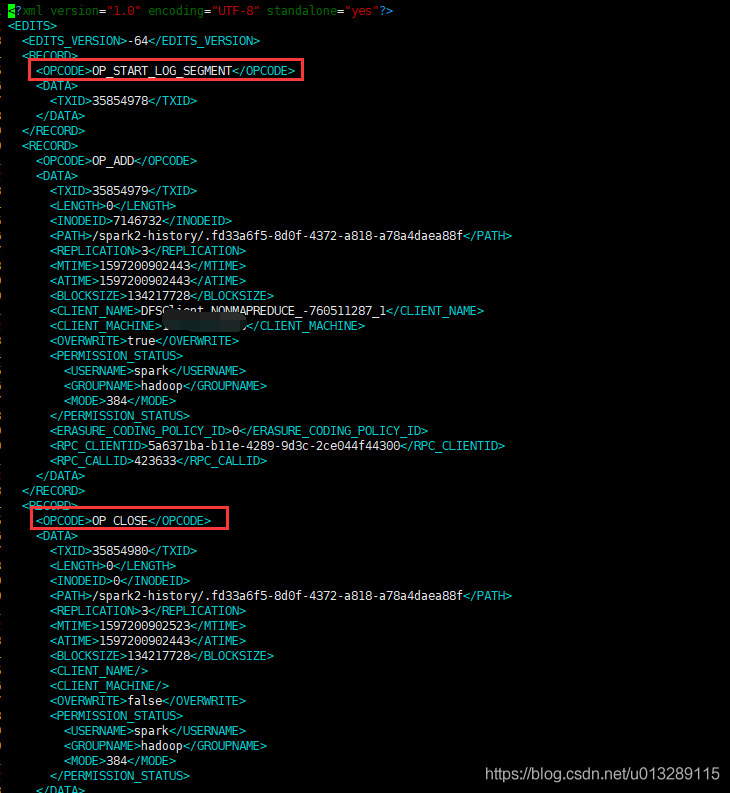
Each operation of HDFS will RECORD a string of records. Different operations in RECORD contain different field attributes, but the attribute of all operations is OPCODE, which corresponds to the above enumeration class org apache. hadoop. hdfs. server. namenode. More than 40 operations in fseditlogopcodes
Loading of hdfs metadata
When hdfs starts, NameNode will load fsimage. Fsimage records the full amount of path information available to hdfs. During the start-up process, only fsimage? This sentence is not entirely correct! At the same time of startup, the EditLog that has not been merged into fsimage will be loaded. The specific details of fsimage will not be expanded here. Take chestnuts for example:
Suppose Hadoop generates Fsimage files every 3 minutes by checkpoint and one file every 1 minute by editlog. The following files are generated in sequence:
fsimage_1 editlog_1 editlog_2 editlog_3 fsimage_2 editlog_4 editlog_5
When the NameNode is started, the fsimage file with the largest suffix timestamp and the editlog file generated behind it will be loaded, that is, fsimage will be loaded_ 2,editlog_4,editlog_5 into NameNode memory. Suppose that the operation of hadoop fs -rmr xxx is recorded in editlog_5 above, after restarting the NameNode, we can no longer see the xxx path in hdfs. If we put fsimage_2 delete, and the NameNode will load fsimage_1,editlog_1,editlog_2. At this time, xxx in the metadata has not been deleted. If the DataNode does not physically delete the block at this time, the data can be recovered, but the editlog_4,editlog_5. The corresponding hdfs operation will be lost. Is there a better way?
Scheme determination
Scheme 1: delete fsimage_2. From the last checkpoint, that is, fsimage_1. The actual configuration of our cluster is to generate fsimage files once an hour. That is to say, this recovery scheme will lead to the loss of all new files added by hdfs in nearly an hour. The daily workflow of the cluster is about 2w. I don't know how many things have happened in this hour. The conceivable consequence is a pile of errors after recovery, which is obviously not the best scheme
Scheme 2: modify editlog_5. Change the operation of deleting xxx to other safe operation types, so that you can see this path again after restarting NameNode. good idea! Just do it!
4, Disaster repeats itself
In order to fully demonstrate the recovery process, I found a test environment to demonstrate it again. Please do not demonstrate in the production environment!!!
-
Delete path
bash-4.2$ hadoop fs -ls /tmp/user/hive Found 1 items drwxrwxrwx - hdfs hdfs 0 2020-08-13 15:02 /tmp/user/hive/warehouse bash-4.2$ hadoop fs -rmr -skipTrash /tmp/user/hive/warehouse rmr: DEPRECATED: Please use '-rm -r' instead. Deleted /tmp/user/hive/warehouse bash-4.2$ bash-4.2$ hadoop fs -ls /tmp/user/hive bash-4.2$
-
Turn off the HDFS cluster
-
Parsing editlog
Find the editlog file that belongs to the deletion operation within the time point range and parse it
hdfs oev -i edits_0000000000005827628-0000000000005827630 -o editlog.xml
View editlog XML, the log of deletion operation has been recorded in it
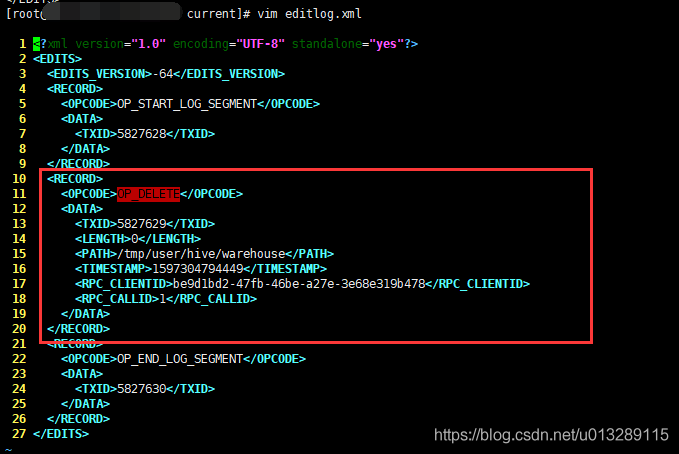
-
Replace delete operation
Put op_ Replace the delete operation with a safer operation, for example:
<RECORD> <OPCODE>OP_SET_OWNER</OPCODE> <DATA> <TXID>5827629</TXID> <SRC>/tmp/user/hive/warehouse</SRC> <USERNAME>hadoop</USERNAME> </DATA> </RECORD>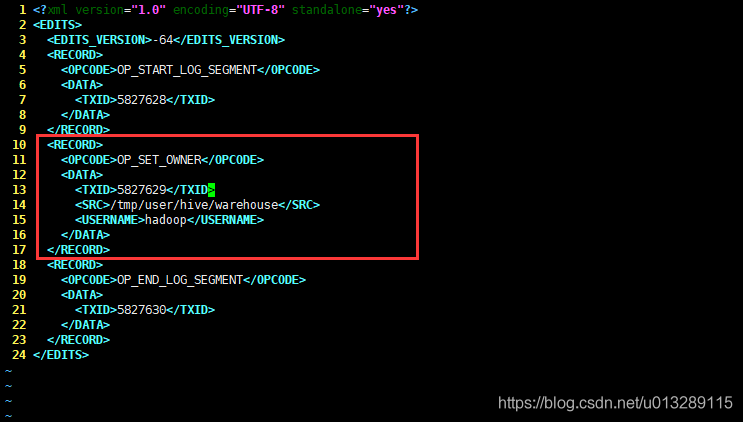
Note: TXID must be the same!!!
-
Inverse parsing to editlog
# De parse the changed xml file into editlog hdfs oev -i editlog.xml -o edits_0000000000005827628-0000000000005827630.tmp -p binary # Rename the previous editlog mv edits_0000000000005827628-0000000000005827630 edits_0000000000005827628-0000000000005827630.bak # Replace the parsed editlog mv edits_0000000000005827628-0000000000005827630.tmp edits_0000000000005827628-0000000000005827630
-
Copy to JournalNodes
The modified editlog needs to be stored in the local editlog storage directory of all JournalNode nodes, which can be found in DFS JournalNode. edits. Dir found
scp edits_0000000000005827628-0000000000005827630 xxx001:/hadoop/hdfs/journal/master/current/ scp edits_0000000000005827628-0000000000005827630 xxx002:/hadoop/hdfs/journal/master/current/ scp edits_0000000000005827628-0000000000005827630 xxx003:/hadoop/hdfs/journal/master/current/
-
Start HDFS
After starting hdfs, check whether the deleted directory has been restored
bash-4.2$ hadoop fs -ls /tmp/user/hive Found 1 items drwxrwxrwx - hadoop hdfs 0 2020-08-13 15:41 /tmp/user/hive/warehouse
The deleted * * / tmp/user/hive/warehouse * * directory has been successfully restored!!
5, Experience summary
- In terms of recovery degree, some block blocks have been deleted, and errors such as block missed will be reported when reading, but the loss has been minimized. The amount of deletion depends on the time to stop the hdfs cluster after the deletion. The earlier the deletion, the smaller the loss
- From the aspect of prevention, the authority must be well controlled. Because the authority of the online springboard machine is too arbitrary, it leads to misoperation
- The specification of hdfs deleting data must not add - skipTrash for forced deletion, and put it into the recycle bin to give yourself and the company more room for recovery
- This is a valuable experience. For the first time, I felt the tension during the handling and the excitement after the successful solution. Afterwards, the milk tea has been received, and the party also saved his job. Ha ha
Author: King of comedy
last
How to get free architecture learning materials?
Data acquisition method: click the blue portal below
Java learning and interview; Free access to documents and video resources

Due to space reasons, we won't show more
)
[external chain picture transferring... (img-YKFW0Usb-1623615718444)]
[external chain picture transferring... (img-ouSCycQ5-1623615718445)]
[external chain picture transferring... (img-0wRomx6y-1623615718445)]
[external chain picture transferring... (img-of2dUEbe-1623615718445)]
[external chain picture transferring... (img-Pz8mv0qJ-1623615718446)]
[external chain picture transferring... (img-SgxWYRxT-1623615718446)]
Due to space reasons, we won't show more