List introduction
Each string in the List in Redis becomes an element. A List can store up to 2 ^ 32 - 1 elements.
In Redis, you can insert (LPUSH) and pop-up (LPOP) at both ends of the list. You can also get the list of elements in the specified range and the elements of the specified index subscript. List is a flexible data structure, which can act as stack and queue. There are many application scenarios in actual development.
- List types have the following characteristics:
- The elements in the list are ordered. The order is determined when the data is inserted. You can obtain a list of elements or elements within a range through the index subscript;
- Elements in the list can be repeated;
Common operations of List
- LPUSH key value [value...]: insert one or more values into the header of the key list; Leftmost, head insertion
- RPUSH key value [value...]: insert one or more values into the footer of the key list; Rightmost and tail interpolation
- LPOP key: remove and return the header element of the key list;
- RPOP key: remove and return the last element of the key list;
- LRANGE key start stop: returns the elements within the specified interval in the list key. The interval is specified by offset start and stop`
- BLPOP key [key...] timeout: pop up an element from the header of the key list. If there is no element in the list, block and wait for seconds. If timeout=0, block and wait all the time;
- BRPOP key [key...] timeout: pop up an element from the end of the key list. If there is no element in the list, block and wait for seconds. If timeout=0, block and wait all the time;
Application scenario
- User message list display (pagination display is supported)
- Message queue
List implementation
- Redis adopts quicklist (double ended linked List) and ziplist as the bottom implementation of List;
- You can improve the efficiency of data access by setting the maximum capacity of each ziplost and the data compression range of quicklist;
- List Max ziplist size: set the maximum size of data that can be stored in a single ziplist node. If it exceeds the size, it will be split and stored in a new ziplist node;
- List compress depth: 0 means that all nodes are not compressed, 1 means that one node goes back from the head node, one node goes forward from the tail node without compression, and all other nodes are compressed, 2, 3, 4... And so on;
ziplist
- ziplist is a specially coded two-way linked list. Its design goal is to improve storage efficiency;
- ziplist can be used to store strings or integers, where integers are encoded in a true binary representation rather than a sequence of strings. It can provide push and pop operations at both ends of the table with O(1) time complexity;
- Because the ziplist is a memory continuous collection, the ziplist traversal only needs to add the length of the current node to the pointer of the current node or subtract the length of the previous node to get the data of the next node or the data of the previous node. In this way, the pointer is omitted, thus saving storage space, And because the memory is continuous, the efficiency of data reading is much higher than that of ordinary linked list.
Source code reading
The following is the translated zipplist source code comments (add some bloggers' own understanding). If there are errors, thank you for your correction
/*
* ZIPLIST OVERALL LAYOUT
* ======================
*
* ziplist The general layout of the is as follows:
*
* <zlbytes> <zltail> <zllen> <entry> <entry> ... <entry> <zlend>
*
* Note: if not otherwise specified, all fields are stored in small end.
*
* <uint32_t zlbytes> Is an unsigned integer, 32bit. Used to indicate the total number of bytes occupied by ziplost.
* ziplist The total number of bytes occupied, including the four bytes of the zlbytes field itself.
* This value is mainly used when the change of entry element in ziplist causes memory reallocation in ziplist, or when calculating the location of zlend
* When traversing data in a collection, you do not need to traverse it first.
*
* <uint32_t zltail> 32bit,Indicates the offset bytes of the last entry in the ziplost table in the ziplost.
* Through zltail, we can easily find the last item, so that we can quickly perform push or pop operations at the end of the ziplost without traversing the entire collection.
*
* <uint16_t zllen> 16bit,Represents the number of data items (entries) in the ziplost.
*
* <uint8_t zlend> 8bit,ziplist The last byte is an end tag with a fixed value equal to 0xFF. If converted to decimal, it is 255.
* entry It refers to the data item that actually stores data, with variable length, which will be explained in detail below
* ZIPLIST ENTRIES
* ===============
*/
#define ZIPLIST_ Bytes (ZL) (* ((uint32_t *) (ZL)) / / get the pointer of zlbytes of ziplist
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t)))) // Get the pointer of zltail ist
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2))) // Get the pointer of zllen of ziplist
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t)) // ziplist header size
#define ZIPLIST_ END_ Size (sizeof (uint8_t)) / / ziplist end flag bit size
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE) / / get the pointer of the first element
#define ZIPLIST_ ENTRY_ Tail (ZL) ((ZL) + intrev32ifbe (ziplist_tail_offset (ZL)) / / get the pointer of the last element
#define ZIPLIST_ ENTRY_ End (ZL) ((ZL) + intrev32ifbe (ziplist_bytes (ZL)) - 1) / / get the end flag bit pointer
unsigned char *ziplistNew(void) { // Create a compressed table
unsigned int bytes = ZIPLIST_HEADER_SIZE+1; // zip header plus end identifier digit
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); // Size conversion
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0; // len is assigned to 0
zl[bytes-1] = ZIP_END; // End flag bit assignment
return zl;
}
Graphic Ziplist
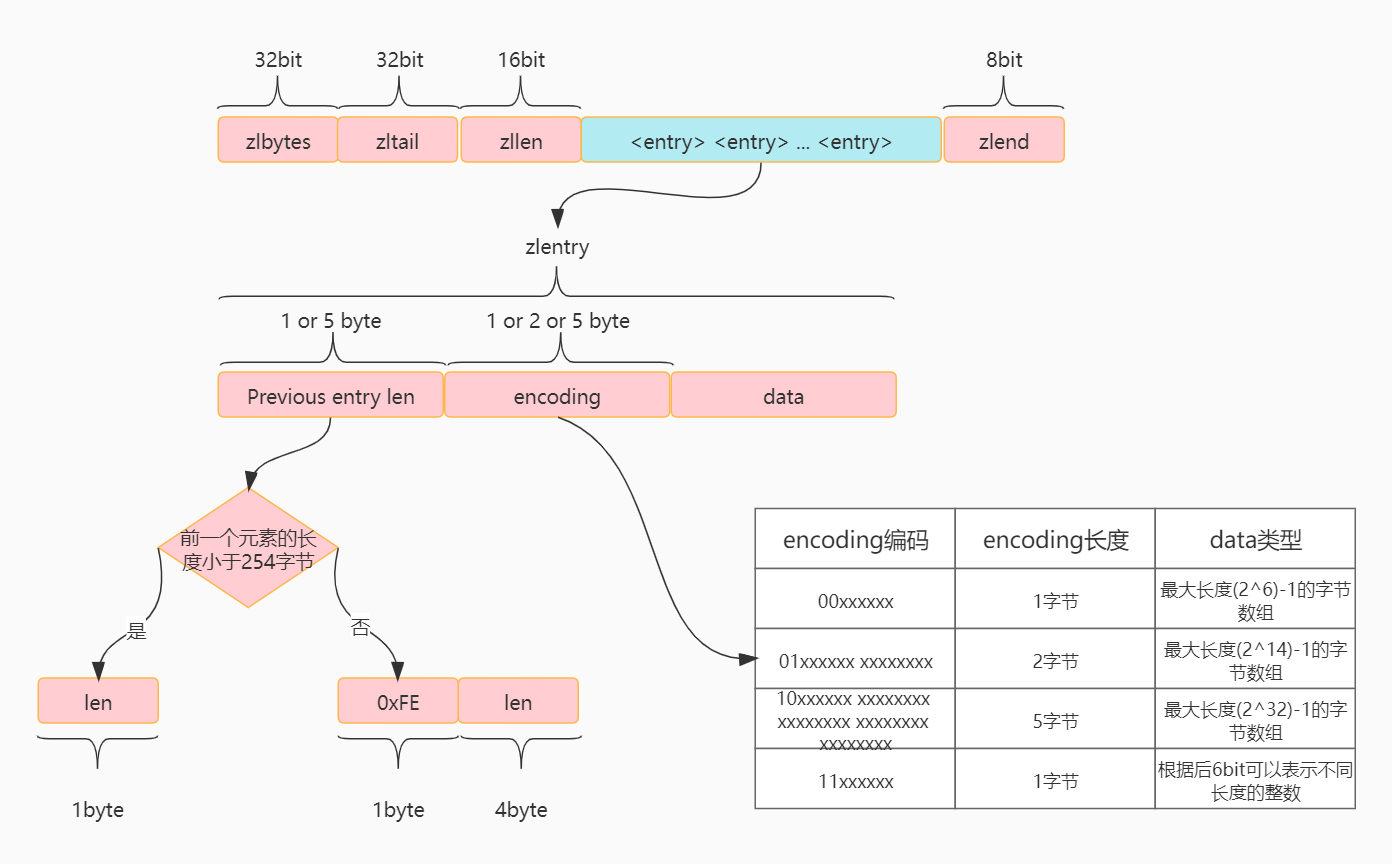
zlentry data structure
/*
* The compressed list node corresponds to the entry in Ziplist above
* zlentry Each node consists of three parts: Previous entry len, encoding and data
* prevlengh: Record the length of the last node to facilitate reverse traversal of the ziplost
* encoding: Coding. Since ziplist is used to save space, ziplist has a variety of codes to represent strings or integers of different lengths.
* data: Used to store the real data of the entry
* The structure defines seven fields, mainly to meet various variable factors
*/
typedef struct zlentry {
unsigned int prevrawlensize; //Prevrawlen size describes the size of prevrawlen, which can be divided into 1 byte and 5 bytes
unsigned int prevrawlen; //prevrawlen is the length of the previous node,
unsigned int lensize; //lensize is the byte size required to encode len
unsigned int len; //len is the current node length
unsigned int headersize; //header size of current node
unsigned char encoding; //Coding method of node
unsigned char *p; //Pointer to node
} zlentry;
The above design structure of Ziplist ensures the saving of space and the efficiency of query. However, when zlentry is added or deleted, Ziplist cannot be modified directly in the original space. Every change needs to open up a new space to copy and modify. In such a scenario, once there are too many internal elements in Ziplist, it will lead to a sharp decline in performance. Therefore, Redis has made a layer of optimization in the implementation. When the Ziplist is too large, it will be divided into multiple ziplists, and then connected in series through a two-way linked list.
quickList
Redis quicklist is a data structure modified for linked list and compressed list after redis version 3.2. It is a mixture of zipList and linkedList. Compared with linked list, Redis quicklist compresses memory and further improves efficiency.
Source code reading
/*
* quicklist Is a 40 byte structure (on a 64 bit system) that describes a quick list.
* 'count' The sum of the number of all ziplost data items.
* 'len' quicklist Number of nodes.
* 'compress' 16bit,The node compression depth setting stores the value of the list compress depth parameter.
* -1:Prohibit compression
* >0:The first n nodes of the head / tail node are not compressed, and other nodes are compressed
* 'fill' 16bit,ziplist The size setting stores the value of the list Max ziplost size parameter.
*/
typedef struct quicklist {
quicklistNode *head; /* Pointer to the head node (the first node on the left). */
quicklistNode *tail; /* Pointer to the tail node (the first node on the right). */
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : QL_FILL_BITS; /* fill factor for individual nodes */
unsigned int compress : QL_COMP_BITS; /* depth of end nodes not to compress;0=off */
unsigned int bookmark_count: QL_BM_BITS;
quicklistBookmark bookmarks[];
} quicklist;
/*
* quicklistNode Is a 32 byte structure that describes a ziplost of a quick list.
* count: 16 bits, The number of data items contained in the zip list.
* encoding: 2 bits, 1: RAW Uncompressed, 2: LZF is compressed using LZF compression algorithm
* container: 2 bits, 1: NONE, 2: ZIPLIST. At present, this value can only be 2: ZIPLIST
* recompress: 1 bit, boolean,true if the node is temporarily decompressed for use. Wait until you have a chance to compress it again
* attempted_compress: 1 bit, boolean,It is used for verification during the test and need not be concerned
* extra: 10 bits, Reserved field
*/
typedef struct quicklistNode {
struct quicklistNode *prev; /* Pointer to the previous node of the linked list. */
struct quicklistNode *next; /* Pointer to the next node after the linked list. */
unsigned char *zl; /* Data pointer. If the data of the current node is not compressed, it points to a ziplost structure; Otherwise, it points to a quicklistLZF structure. */
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
/*
* quicklistLZF Is a 4+N byte structure that represents a compressed ziplost
* sz: Represents the size of the zip list after compression.
* compressed: It is a flexible array member, which stores the compressed ziplist byte array.
*/
typedef struct quicklistLZF {
unsigned int sz; /* LZF size in bytes*/
char compressed[];
} quicklistLZF;
Graphical quickList
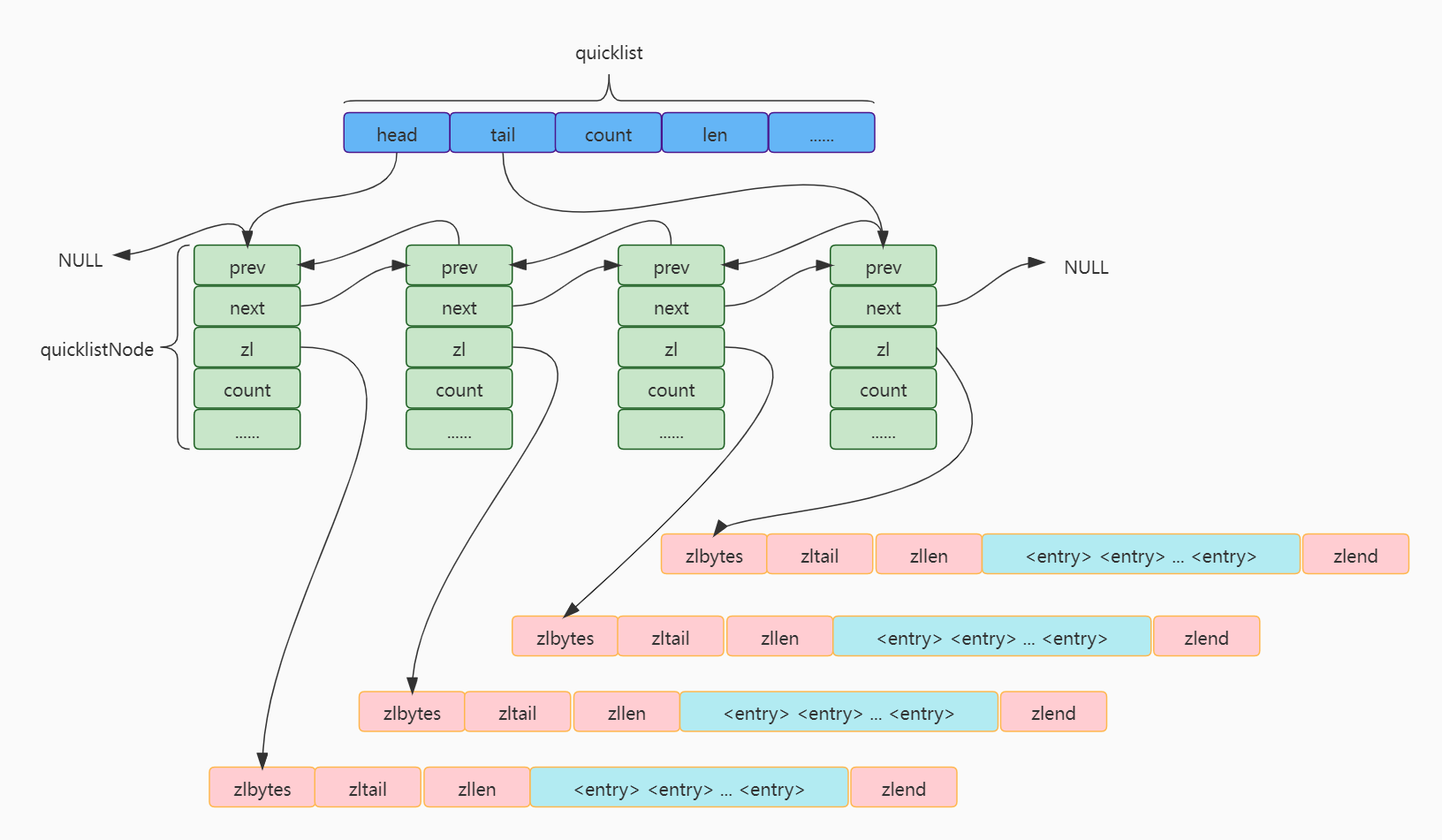
By controlling the size of ziplist, the impact on performance in the case of large ziplist copy is well solved. Each change only needs to be operated on a specific short ziplost.
Your praise is the biggest driving force for my creation. If it's good, can I have a three company