Implementation of keras version of DeepLab-V3 + semantic segmentation Neural Network
network structure
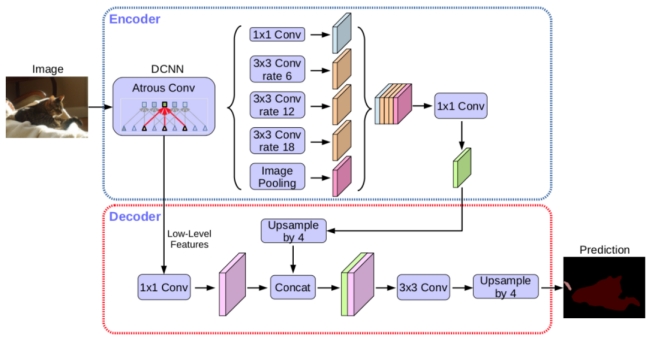
Deeplab series network models are developed from ResNet residual module, and on this basis, they are integrated with the implementation of empty convolution. Compared with Deeplab v3, Deeplab v3 + introduces the encoder decoder structure commonly used in semantic segmentation [25] [26] in order to integrate multi-scale information. The encoder provides rich semantic information, and the decoder restores fine object edges, so as to integrate low-level features and high-level features, which further improves the accuracy of segmentation boundary, At the same time, the resolution of the feature extracted by the encoder can be arbitrarily controlled, and the accuracy and time-consuming can be balanced by hole convolution.
The structure of DeepLab v3 + model is shown in Figure 3-6. The main body of its encoder is DCNN with hole convolution. Hole convolution is one of the keys of DeepLab model. Because the hole will cross pixels when extracting feature points, it can increase the receptive field without changing the size of the feature map, so that the information range contained in each convolution output becomes larger. For the encoder, it is conducive to extracting more effective features and extracting multi-scale information.
Meanwhile, the deep lab V3 + model adopts the ASPP (atlas spatial pyramid pooling) module to further extract multi-scale features by using different receptive fields and up sampling.
Complete code
Add Reference Library
from keras.preprocessing import image from keras.models import Model, load_model, Sequential from keras import backend as K from keras.utils import np_utils from keras.preprocessing.image import img_to_array from sklearn.preprocessing import LabelEncoder from keras import metrics from keras.losses import binary_crossentropy import matplotlib.pyplot as plt from keras.layers import Conv2D, MaxPooling2D, UpSampling2D, BatchNormalization, Reshape, Permute, Activation, Input from keras.layers import DepthwiseConv2D, ZeroPadding2D, GlobalAveragePooling2D, Lambda, Concatenate, Dropout, Conv2DTranspose from keras import layers from keras.utils.np_utils import to_categorical from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau, EarlyStopping, CSVLogger from keras.layers.merge import concatenate from PIL import Image from keras.optimizers import Adam import tensorflow as tf from keras.applications.resnet50 import ResNet50 import matplotlib as mpl import seaborn as sns import os import random import numpy as np import cv2 import matplotlib.pyplot as plt import shutil import pandas as pd import time from tqdm import * os.environ["CUDA_VISIBLE_DEVICES"] = "0" seed = 7 np.random.seed(seed)
Data loading
if not os.path.exists('./edge_clip/'):
!unzip /content/drive/MyDrive/edge_clip.zip -d ./
img_w = 512
img_h = 512
n_label = 1
classes = [0., 1.]
labelencoder = LabelEncoder()
labelencoder.fit(classes)
image_sets = os.listdir('/content/edge_clip/train/src/')
def load_img(path, grayscale=False):
if grayscale:
img = cv2.imread(path, cv2.IMREAD_GRAYSCALE) / 255.0
else:
img = cv2.imread(path)
img = np.array(img, dtype="float") / 255.0
return img
filepath = '/content/edge_clip/train/'
def get_train_val(val_rate=0.2):
train_url = []
train_set = []
val_set = []
for pic in os.listdir(filepath + 'src/'):
train_url.append(pic)
random.seed(14)
random.shuffle(train_url)
total_num = len(train_url)
val_num = int(val_rate * total_num)
for i in range(len(train_url)):
if i < val_num:
val_set.append(train_url[i])
else:
train_set.append(train_url[i])
return train_set, val_set
# data for training
def generateData(batch_size, data=[]):
# print 'generateData...'
while True:
train_data = []
train_label = []
batch = 0
for i in (range(len(data))):
url = data[i]
batch += 1
img = load_img(filepath + 'src/' + url)
img = img_to_array(img)
train_data.append(img)
label = load_img(filepath + 'label/' + url, grayscale=True)
label = img_to_array(label)
train_label.append(label)
if batch % batch_size == 0:
# print 'get enough bacth!\n'
train_data = np.array(train_data)
train_label = np.array(train_label)
yield (train_data, train_label)
train_data = []
train_label = []
batch = 0
# data for validation
def generateValidData(batch_size, data=[]):
# print 'generateValidData...'
while True:
valid_data = []
valid_label = []
batch = 0
for i in (range(len(data))):
url = data[i]
batch += 1
img = load_img(filepath + 'src/' + url)
img = img_to_array(img)
valid_data.append(img)
label = load_img(filepath + 'label/' + url, grayscale=True)
label = img_to_array(label)
valid_label.append(label)
if batch % batch_size == 0:
valid_data = np.array(valid_data)
valid_label = np.array(valid_label)
yield (valid_data, valid_label)
valid_data = []
valid_label = []
batch = 0
train_set, val_set = get_train_val()
len(train_set), len(val_set)
(8320, 2080)
Build model
def Upsample(tensor, size):
'''bilinear upsampling'''
name = tensor.name.split('/')[0] + '_upsample'
def bilinear_upsample(x, size):
resized = tf.image.resize(
images=x, size=size)
return resized
y = Lambda(lambda x: bilinear_upsample(x, size),
output_shape=size, name=name)(tensor)
return y
def ASPP(tensor):
'''atrous spatial pyramid pooling'''
dims = K.int_shape(tensor)
y_pool = AveragePooling2D(pool_size=(
dims[1], dims[2]), name='average_pooling')(tensor)
y_pool = Conv2D(filters=256, kernel_size=1, padding='same',
kernel_initializer='he_normal', name='pool_1x1conv2d', use_bias=False)(y_pool)
y_pool = BatchNormalization(name=f'bn_1')(y_pool)
y_pool = Activation('relu', name=f'relu_1')(y_pool)
# y_pool = Upsample(tensor=y_pool, size=[dims[1], dims[2]])
y_pool = Conv2DTranspose(filters=256, kernel_size=(2, 2),
kernel_initializer='he_normal', dilation_rate=512 // 16 - 1)(y_pool)
y_1 = Conv2D(filters=256, kernel_size=1, dilation_rate=1, padding='same',
kernel_initializer='he_normal', name='ASPP_conv2d_d1', use_bias=False)(tensor)
y_1 = BatchNormalization(name=f'bn_2')(y_1)
y_1 = Activation('relu', name=f'relu_2')(y_1)
y_6 = Conv2D(filters=256, kernel_size=3, dilation_rate=6, padding='same',
kernel_initializer='he_normal', name='ASPP_conv2d_d6', use_bias=False)(tensor)
y_6 = BatchNormalization(name=f'bn_3')(y_6)
y_6 = Activation('relu', name=f'relu_3')(y_6)
y_12 = Conv2D(filters=256, kernel_size=3, dilation_rate=12, padding='same',
kernel_initializer='he_normal', name='ASPP_conv2d_d12', use_bias=False)(tensor)
y_12 = BatchNormalization(name=f'bn_4')(y_12)
y_12 = Activation('relu', name=f'relu_4')(y_12)
y_18 = Conv2D(filters=256, kernel_size=3, dilation_rate=18, padding='same',
kernel_initializer='he_normal', name='ASPP_conv2d_d18', use_bias=False)(tensor)
y_18 = BatchNormalization(name=f'bn_5')(y_18)
y_18 = Activation('relu', name=f'relu_5')(y_18)
y = concatenate([y_pool, y_1, y_6, y_12, y_18], name='ASPP_concat')
y = Conv2D(filters=256, kernel_size=1, dilation_rate=1, padding='same',
kernel_initializer='he_normal', name='ASPP_conv2d_final', use_bias=False)(y)
y = BatchNormalization(name=f'bn_final')(y)
y = Activation('relu', name=f'relu_final')(y)
return y
def DeepLabV3Plus(img_height=512, img_width=512, nclasses=1):
print('*** Building DeepLabv3Plus Network ***')
base_model = ResNet50(input_shape=(
img_height, img_width, 3), weights='imagenet', include_top=False)
image_features = base_model.get_layer('conv4_block6_out').output
x_a = ASPP(image_features)
# x_a = Upsample(tensor=x_a, size=[img_height // 4, img_width // 4])
x_a = Conv2DTranspose(filters=256, kernel_size=(2, 2),
kernel_initializer='he_normal', dilation_rate=img_height // 16 * 3)(x_a)
x_b = base_model.get_layer('conv2_block3_out').output
x_b = Conv2D(filters=48, kernel_size=1, padding='same',
kernel_initializer='he_normal', name='low_level_projection', use_bias=False)(x_b)
x_b = BatchNormalization(name=f'bn_low_level_projection')(x_b)
x_b = Activation('relu', name='low_level_activation')(x_b)
x = concatenate([x_a, x_b], name='decoder_concat')
x = Conv2D(filters=256, kernel_size=3, padding='same', activation='relu',
kernel_initializer='he_normal', name='decoder_conv2d_1', use_bias=False)(x)
x = BatchNormalization(name=f'bn_decoder_1')(x)
x = Activation('relu', name='activation_decoder_1')(x)
x = Conv2D(filters=256, kernel_size=3, padding='same', activation='relu',
kernel_initializer='he_normal', name='decoder_conv2d_2', use_bias=False)(x)
x = BatchNormalization(name=f'bn_decoder_2')(x)
x = Activation('relu', name='activation_decoder_2')(x)
# x = Upsample(x, [img_height, img_width])
x = Conv2DTranspose(filters=256, kernel_size=(2, 2),
kernel_initializer='he_normal', dilation_rate=img_height // 4 * 3)(x)
x = Conv2D(nclasses, (1, 1), name='output_layer')(x)
x = Activation('sigmoid')(x)
'''
x = Activation('softmax')(x)
tf.losses.SparseCategoricalCrossentropy(from_logits=True)
Args:
from_logits: Whether `y_pred` is expected to be a logits tensor. By default,
we assume that `y_pred` encodes a probability distribution.
'''
model = Model(inputs=base_model.input, outputs=x, name='DeepLabV3_Plus')
print(f'*** Output_Shape => {model.output_shape} ***')
return model
model = DeepLabV3Plus(nclasses=1)
*** Building DeepLabv3Plus Network *** *** Output_Shape => (None, 512, 512, 1) ***
def dice_coef(y_true, y_pred, smooth=1):
intersection = K.sum(y_true * y_pred, axis=[1,2])
union = K.sum(y_true, axis=[1,2]) + K.sum(y_pred, axis=[1,2])
return K.mean( (2. * intersection + smooth) / (union + smooth), axis=0)
def dice_coef_loss(y_true, y_pred):
1 - dice_coef(y_true, y_pred, smooth=1)
def bce_logdice_loss(y_true, y_pred):
return binary_crossentropy(y_true, y_pred) - K.log(1. - dice_loss(y_true, y_pred))
model.compile(optimizer=Adam(lr=1e-4), loss=['binary_crossentropy', bce_logdice_loss], metrics=['accuracy'])
model training
EPOCHS = 5
BS = 4
model_path = '/content/drive/MyDrive/models/deeplab_v3.h5'
## callback policy
# Save training log
csvlogger = CSVLogger('/content/drive/MyDrive/training_deeplab_v3.csv', separator=',', append=True)
# Learning rate attenuation strategy
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=2, verbose=1) # Learning rate attenuation strategy
# Breakpoint training is conducive to restoring and saving the model
checkpoint = ModelCheckpoint(model_path, monitor='val_accuracy', verbose=1, save_best_only=True, save_weights_only=False, mode='auto', period=1)
# early stopping strategy
early_stopping = EarlyStopping(monitor='val_accuracy', patience=4, verbose=1, mode='auto')
train_numb = len(train_set)
valid_numb = len(val_set)
print("the number of train data is", train_numb)
print("the number of val data is", valid_numb)
H = model.fit(
generateData(BS, train_set),
steps_per_epoch=train_numb // BS,
epochs=EPOCHS, verbose=1,
validation_data=generateData(BS, val_set),
validation_steps=valid_numb // BS,
callbacks=[checkpoint, early_stopping, reduce_lr, csvlogger],
max_queue_size=BS
)
WARNING:tensorflow:`period` argument is deprecated. Please use `save_freq` to specify the frequency in number of batches seen. the number of train data is 8320 the number of val data is 2080 Epoch 1/5 75/2080 [>.............................] - ETA: 48:22 - loss: 0.6673 - accuracy: 0.7521
Thinking summary
- Model weight saving: generally, the small model will save the structure and weight of the model, while the large model only saves the weight of the model. Here, because there is a lambda layer in the upper sampling, the model structure cannot be saved. You can save the weight layer, define the model structure, and then load the weight;
- Training time: the training time of Deeplab-V3 + is so long that it is about 10 times longer than that of unet training. We can only guess that the up sampling and hole convolution are time-consuming??? Maybe you need to do a verification. Friends can tell me what they know;