Scene introduction
- Originally there were 1 billion numbers, but now there are 100000 numbers. It is necessary to quickly and accurately judge whether these 100000 numbers are in the 1 billion number library?
Solution 1: store 1 billion numbers in the database and query the database. The accuracy is improved, but the speed will be relatively slow.
Solution 2: put 1 billion numbers into memory, such as Redis cache. Here we calculate the memory size: 1 billion * 8 bytes = 8gb. Through memory query, the accuracy and speed are improved, but about 8gb of memory space is a waste of memory space.
2. When we use the news client to watch the news, it will constantly recommend new content to us, which means that we need to redo every recommendation and remove the content we have seen,
How to remove weight effectively and quickly?
Implementation principle
In daily data structures, HashMap container is usually used to judge whether an element exists, because the Key of HashMap can return results within the time complexity of O(1), which is extremely efficient. However, the implementation of HashMap also has disadvantages. For example, the proportion of storage capacity is high. Considering the existence of load factor, usually the space can not be used up. Once you have a lot of values, the memory occupied by HashMap will become considerable, and the capacity will be continuously expanded to recalculate the hash value, which will have many problems.
Bloom filter
Bloom filter is used to quickly retrieve whether a key is in this container.
algorithm
initialization
An array with a length of n bits is required, and each bit is initialized to 0
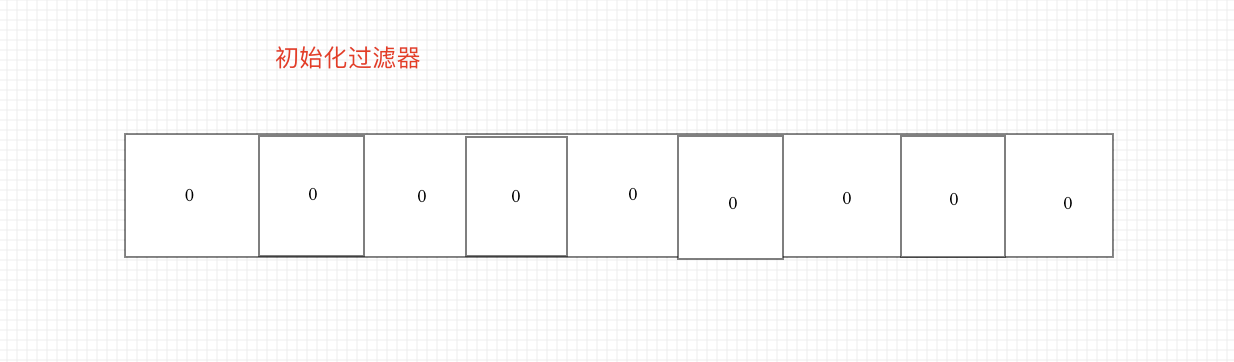
add to
K hash functions are required. Each function hashes the key into an integer, and then sets the position of the integer to 1 (generally, in order to ensure accuracy and efficiency, k=3, that is, a key will set three positions in the array to 1)
Example 1: store key ("baidu")
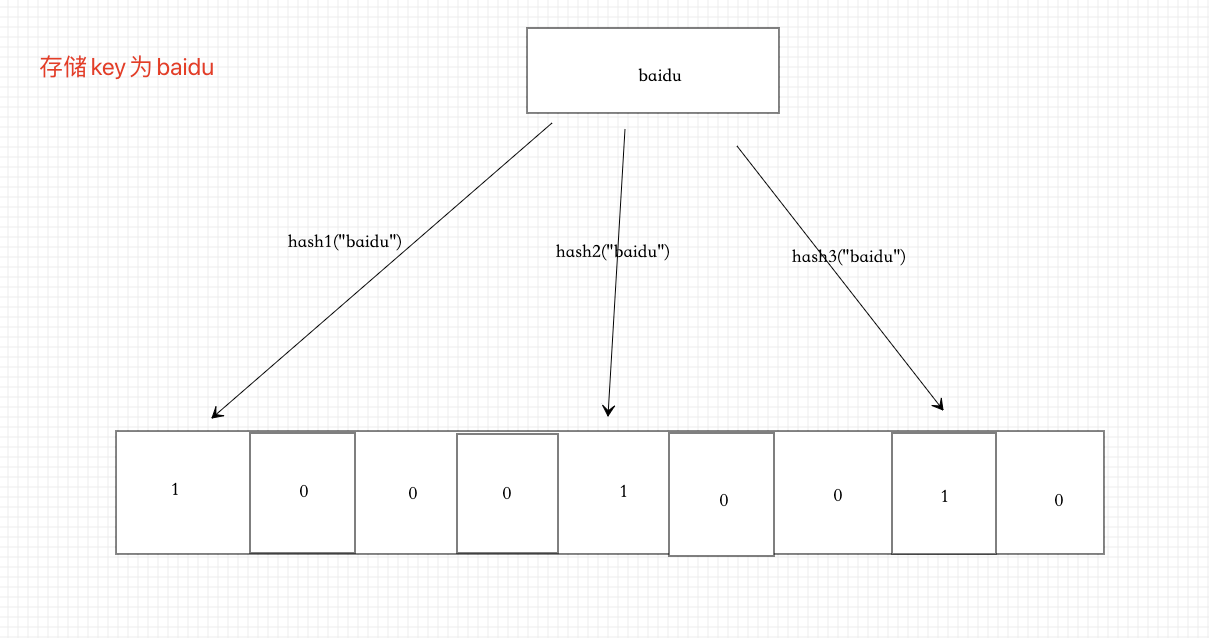
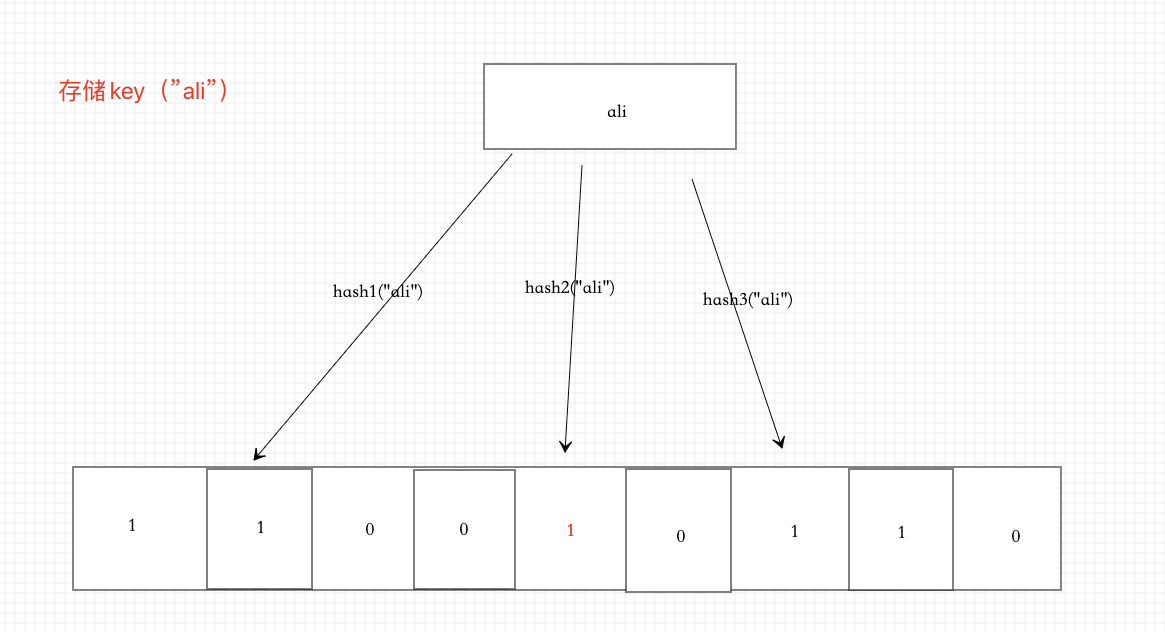
Example 2: store key ("ali")
Determine whether the data exists?
If one of the k hash functions calculated by the key is not 1, the key must not be in the current container. However, with the increase of data volume, if the corresponding places of the current key are all 1, does the current key necessarily exist? not always.
Therefore, when judging whether an element is in the current container and the same amount of data, the greater the k value, the lower the misjudgment rate.
advantage
The advantages are obvious. The binary array occupies very little memory, and the insertion and query speed are fast enough.
shortcoming
You cannot delete an element in a container
There is a certain probability of misjudgment when judging whether the current element is in the container
code implementation
Application of single architecture
The disadvantage is obvious. The historical data cannot be matched with the data in the container after project downtime or restart in the current jvm heap. It is better to choose the middleware redis to store the container
//Code block from Baidu Encyclopedia
// Build a bloom filter with an array length of 1 billion bits and k = 8
public class MyBloomFilter {
/**
* A bit with a length of 1 billion
*/
private static final int DEFAULT_SIZE = 256 << 22;
/**
* In order to reduce the error rate, the addition hash algorithm is used, so an 8-element prime array is defined
*/
private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* It is equivalent to building 8 different hash algorithms
*/
private static HashFunction[] functions = new HashFunction[seeds.length];
/**
* Initialize bitmap of Bloom filter
*/
private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* Add data
*
* @param value Value to be added
*/
public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//Calculate the hash value and modify the corresponding position in the bitmap to true
bitset.set(f.hash(value), true);
}
}
}
/**
* Judge whether the corresponding element exists
* @param value Elements to be judged
* @return result
*/
public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//If a hash function returns false, it will jump out of the loop
if (!ret) {
break;
}
}
return ret;
}
/**
* Test...
*/
public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
// Add 100 million data
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println(contains(id)); // true
System.out.println("" + contains("234567890")); //false
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}
Spring boot integrates redis to implement bloom filter
pom configuration
dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.5.7</version>
</dependency>
configure connections
@Configuration
public class RedissonConfig {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private String port;
// @Value("${spring.redis.password}")
// private String password;
@Bean
public RedissonClient getRedisson(){
Config config = new Config();
config.useSingleServer().setAddress("redis://" + host + ":" + port);
return Redisson.create(config);
}
}
code implementation
@Component
public class BloomFilterUtil {
@Autowired
private RedissonClient redissonClient;
/**
* Initialize filter
* @param bloomKey
*/
public void bloomFilterInit(String bloomKey){
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(bloomKey);
//Initialize bloom filter: the expected element is 100000000L, and the error rate is 1%
bloomFilter.tryInit(1000000L, 0.01);
//Set expiration time
//bloomFilter.expire(1, TimeUnit.DAYS);
}
/**
* Used to verify whether there is duplicate data
* @param bloomKey
* @param verifyKey
* @return true Duplicate false no duplicate
*/
public Boolean containsThisKey(String bloomKey, String verifyKey) {
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(bloomKey);
return !bloomFilter.add(verifyKey);
}
/**
* Delete the bloom filter
* @param bloomKey
*/
public void delThisBloomKey(String bloomKey){
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(bloomKey);
bloomFilter.delete();
}
}
thank https://www.cnblogs.com/ysocean/p/12594982.html