I haven't written code for a long time recently. I suddenly want to be hot, so I fell in love with the starting point Chinese website (●) ˇ ∀ ˇ ●)
No more nonsense, give the code
Let's first analyze the website of starting point Chinese website
https://www.qidian.com/rank/yuepiao/year2022-month01/
Normal operation after we enter the website, press f12 and click network, as shown in the figure below
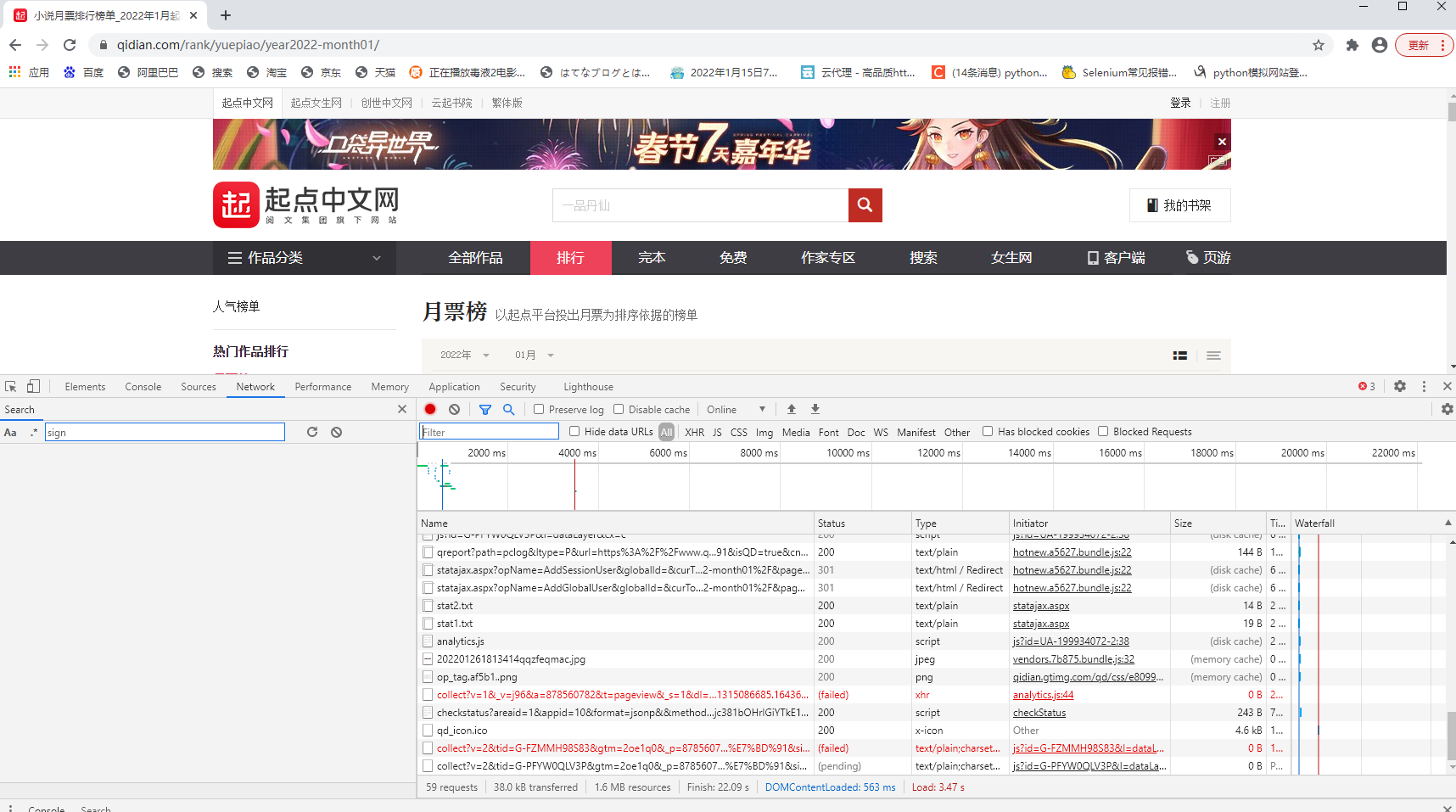
We need to find the content we want to crawl. Let's crawl the title and the number of monthly tickets today
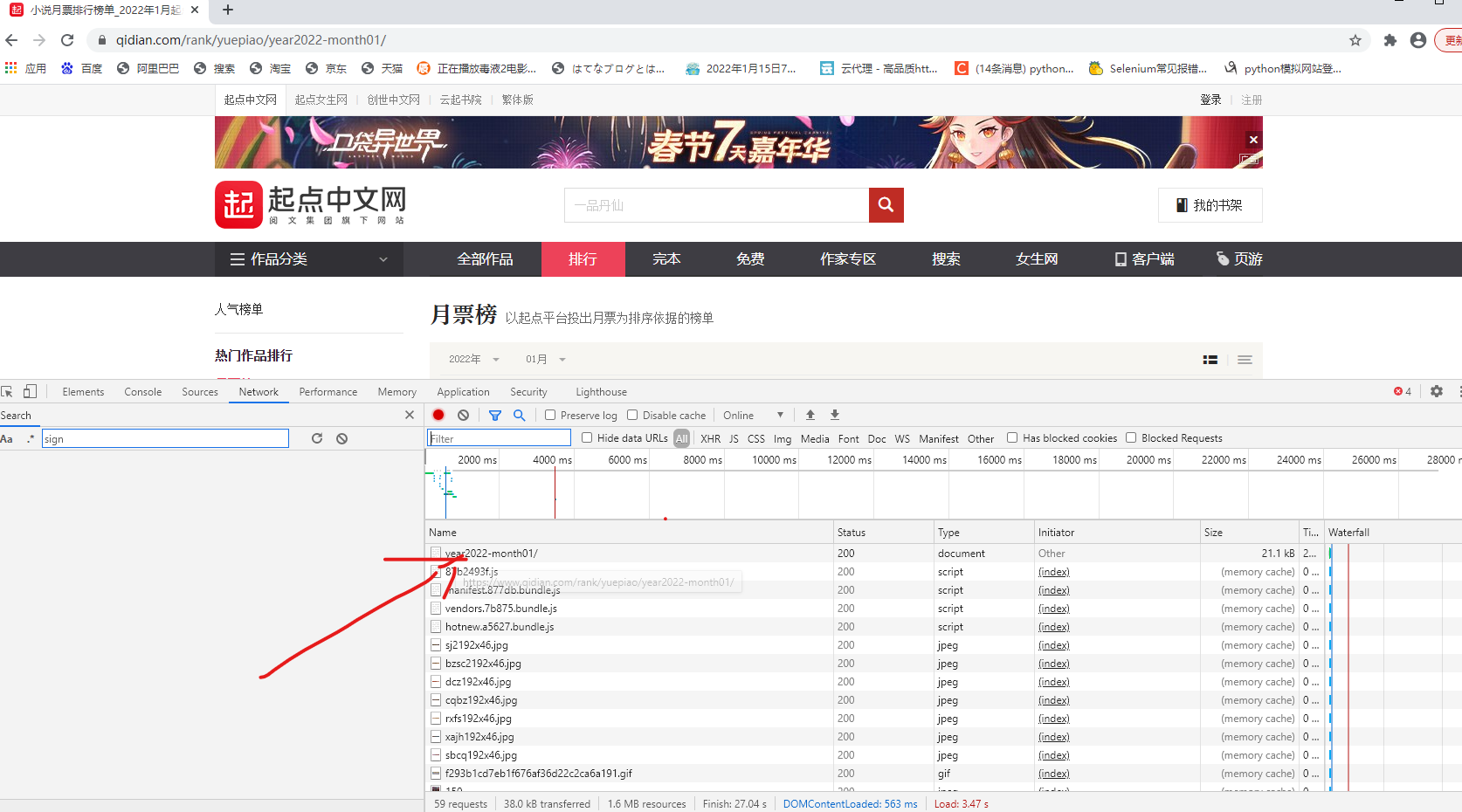
**Find the website indicated by the arrow, click in to check its preview, and find that there is no data we are looking for. Let's see whether it is in the Response. Search the Stargate with CTRL+f and find it in this
**
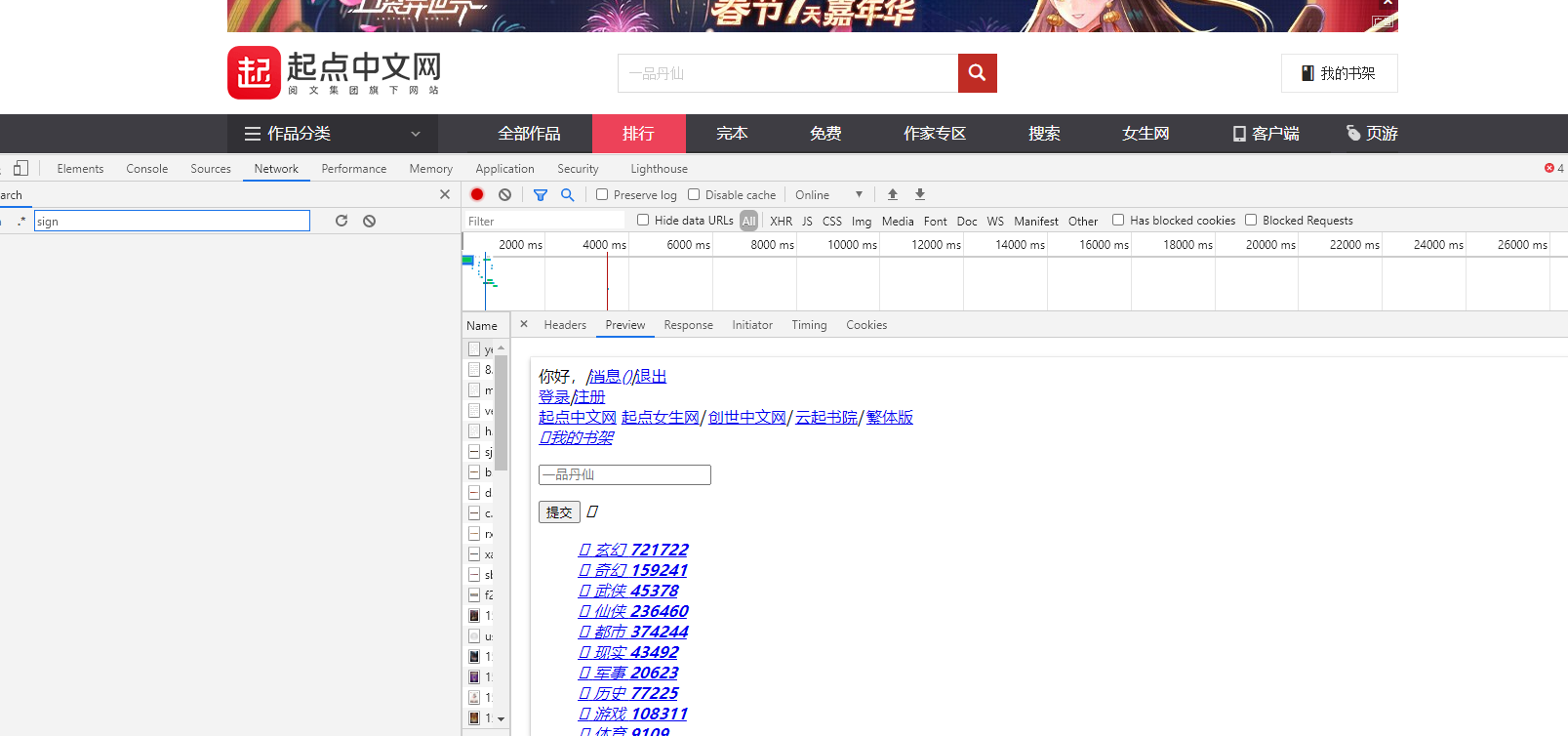
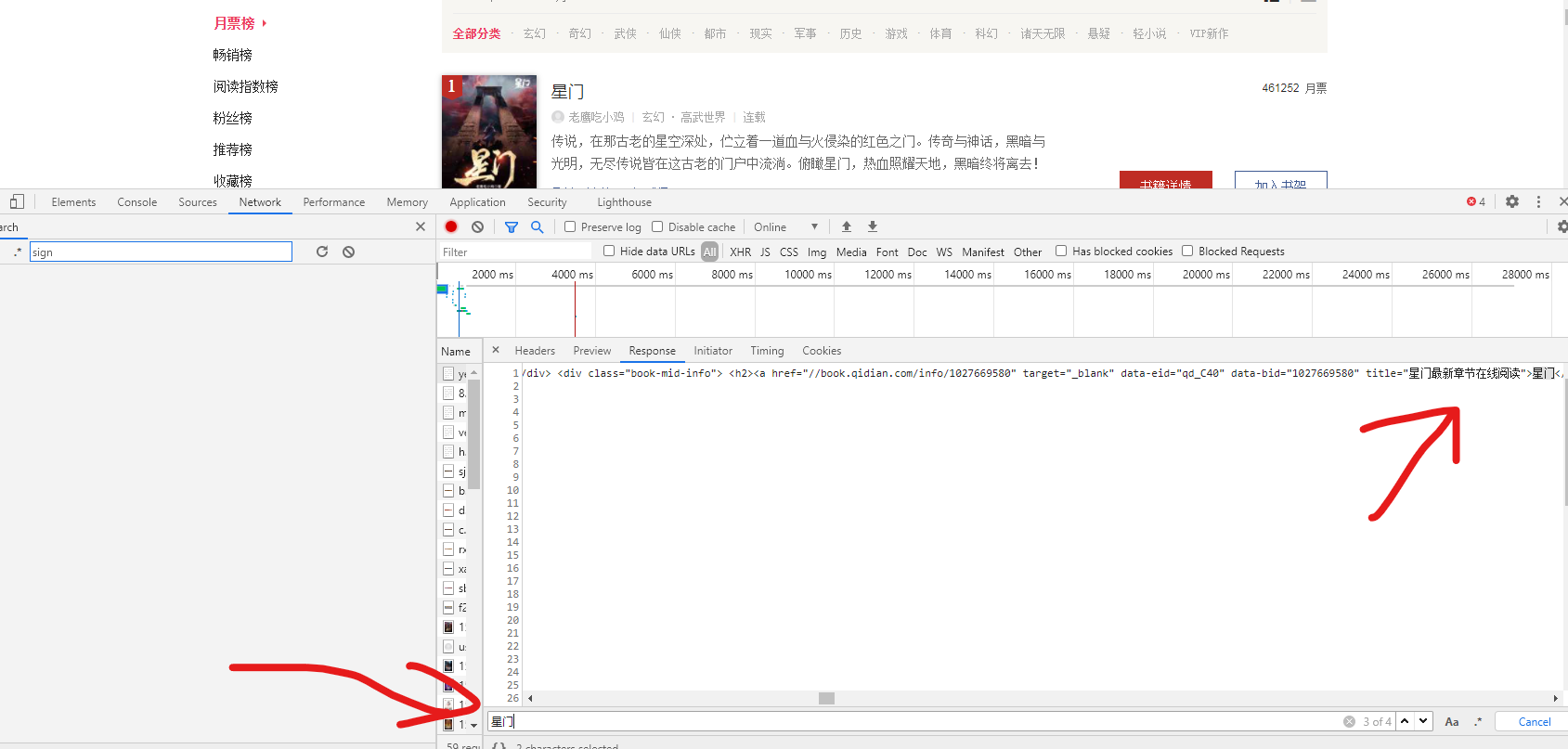
In this way, we get the title. The code of the title is as follows
import random
import requests
from lxml import etree
# Determine the website of the monthly ticket ranking list of the starting point Chinese website
url = 'https://www.qidian.com/rank/yuepiao/year2022-month01/'
# Request header
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36',
'referer': 'https://www.qidian.com/rank/',
'cookie': 'e1=%7B%22pid%22%3A%22qd_P_rank_01%22%2C%22eid%22%3A%22qd_C19%22%2C%22l1%22%3A4%7D; e2=%7B%22pid%22%3A%22qd_P_rank_01%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A4%7D; _yep_uuid=fd95b6b7-090e-c6e5-cb8c-b8387e5b29ab; _ga=GA1.1.376581816.1643601078; newstatisticUUID=1643601078_1599172947; _csrfToken=m8mDkhtjc381bOHrIGiYTkE1g3bUzgPZjExmmO9l; _ga_FZMMH98S83=GS1.1.1643601077.1.1.1643601098.0; _ga_PFYW0QLV3P=GS1.1.1643601077.1.1.1643601098.0'
}
# Response data
response = requests.get(url, headers=headers)
response_text = response.text
html_data = etree.HTML(response_text)
#Get the title through xpath
title_list = html_data.xpath('//h2/a/text()')
print(title_list)
**Run the code and you can see that the names of the novels on the first page have come out (in the form of list)
**

Of course, we also need to get monthly tickets for these novels
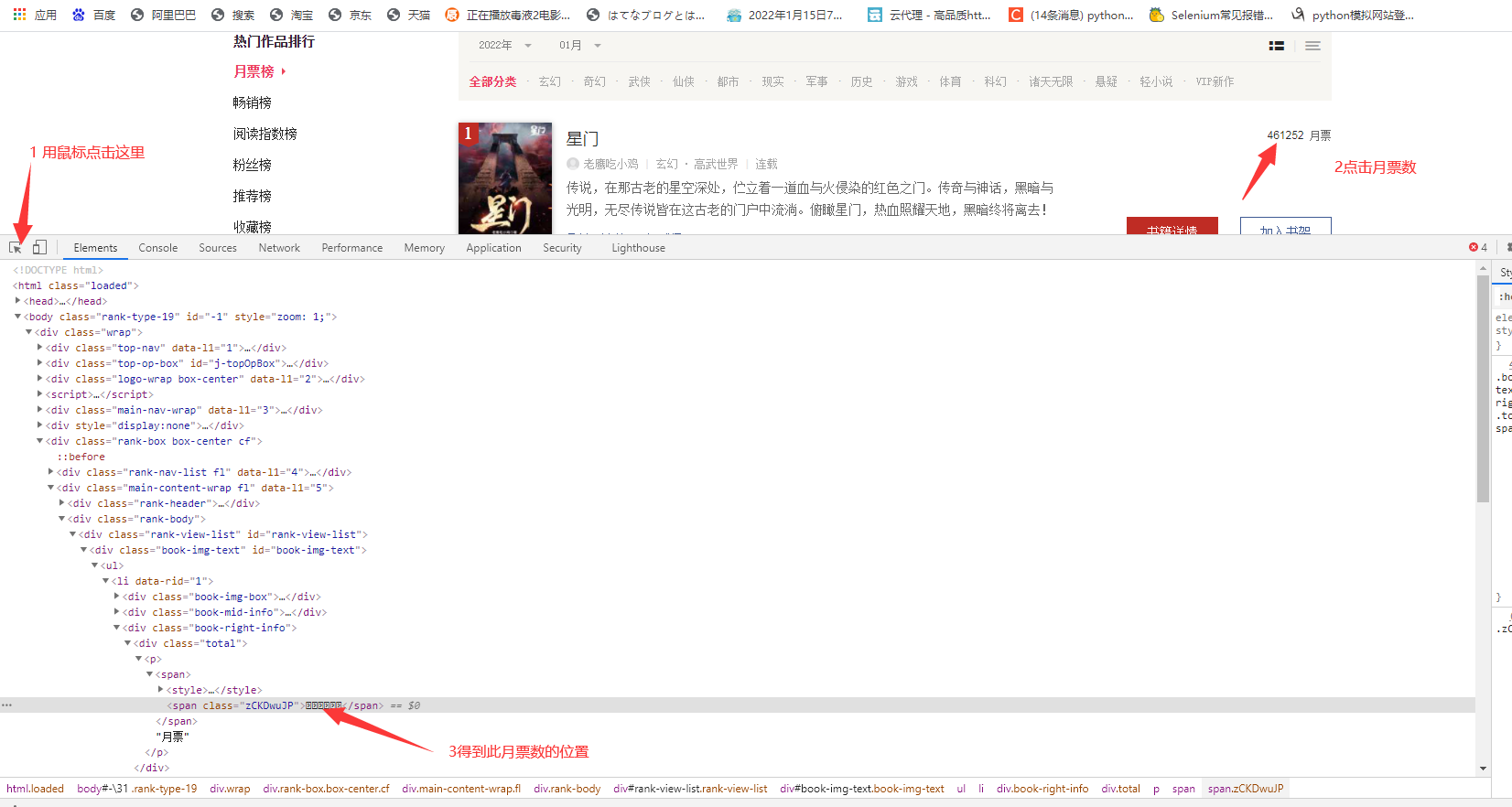
It can be seen that the number of monthly tickets is not directly displayed. Let's get the ones that are not displayed first
# Get the number of monthly tickets using regular
re_data = re.findall('</style><span class=".*?">(.*?)</span>', response_text)
print(re_data)
The effect is as follows
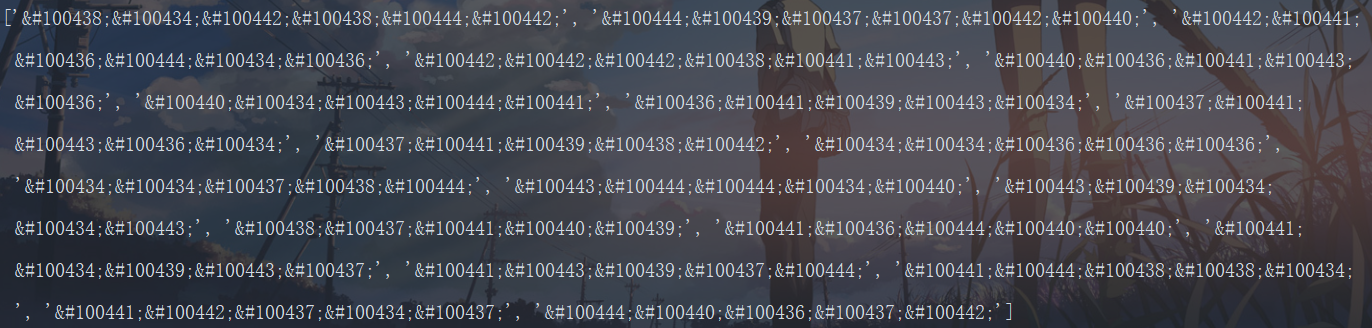
It can be seen that this is different from the display on the web page. What is this? So we can guess that the number of votes this month should be encrypted. In order to verify this idea, we found a src on the font
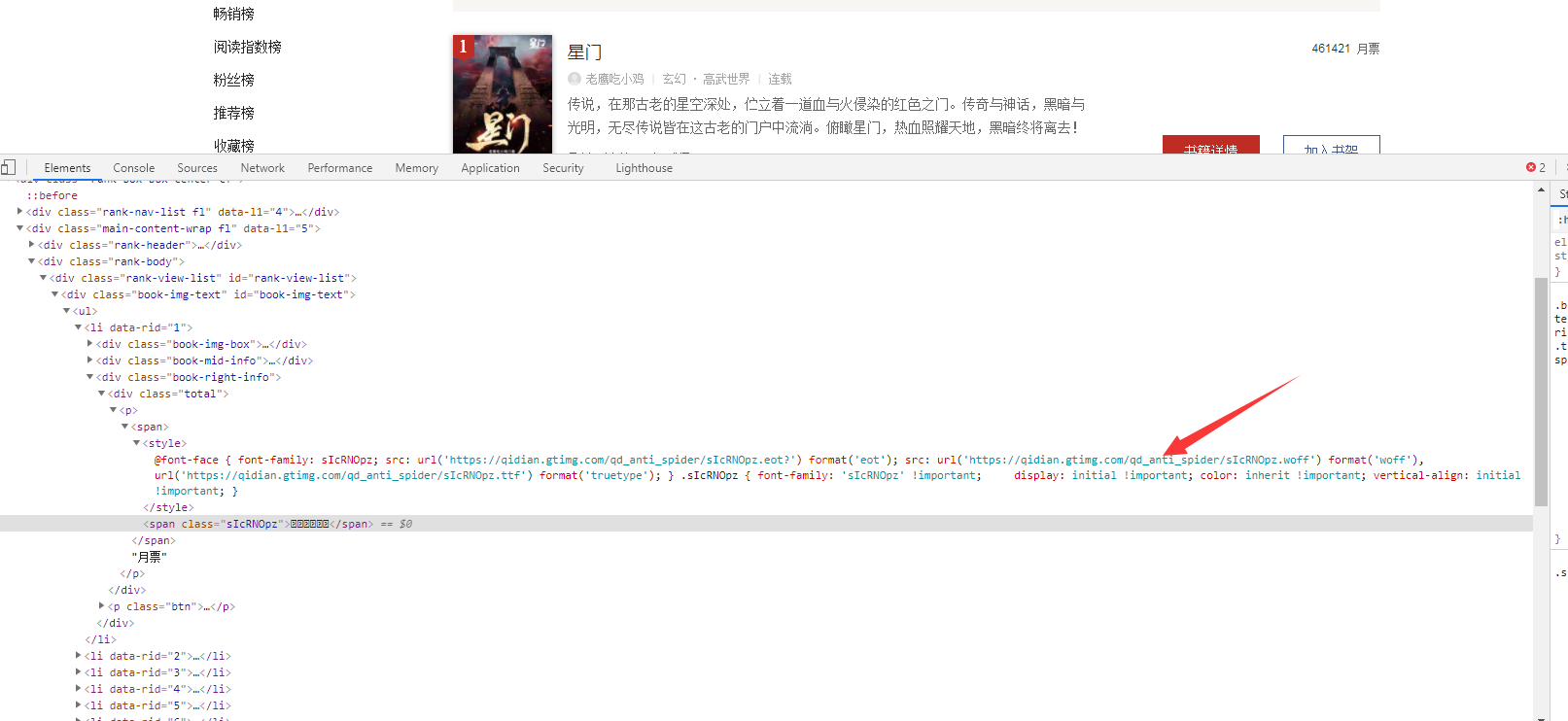
And this src is still dynamic (mentality collapse). Every time I enter this page, I will randomly generate the following font in the network for comparison
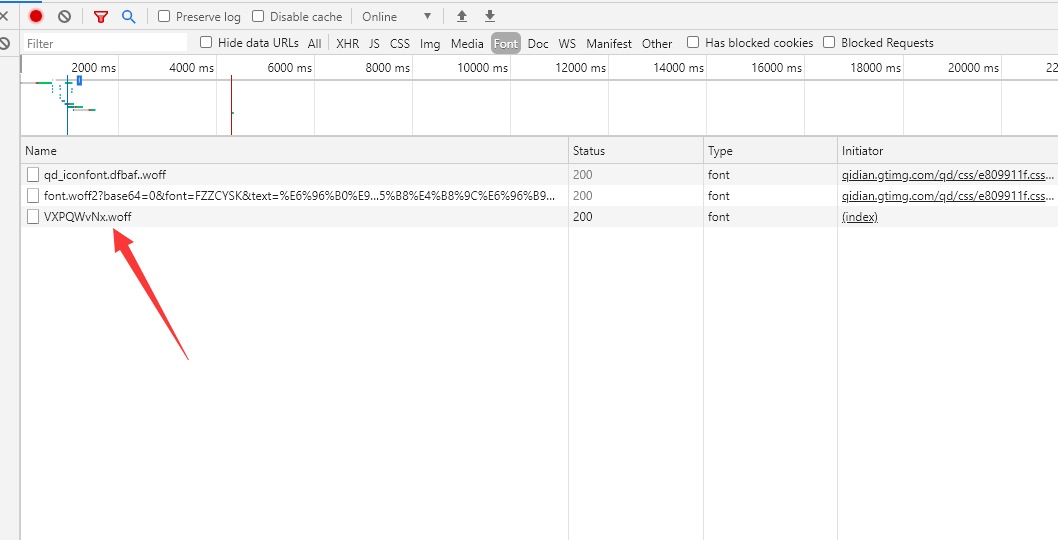
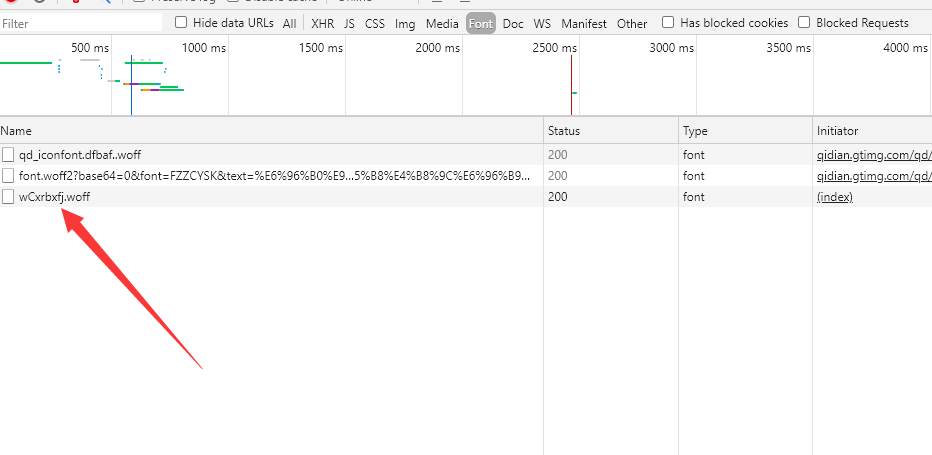
The code for obtaining the dynamic font url is as follows
# Get dynamic url using regular
font_url = re.findall(r"format\('eot'\); src: url\('(.*?)'\) format\('woff'\)", response_text)[0]
print(font_url)
Then the idea behind is clear. Just decrypt the encrypted data in the source code directly with the obtained font package
# Send a request to download the font encryption file
font_response = requests.get(font_url, headers=headers)
with open('jiemi.woff','wb')as f:
f.write(font_response.content)
#Parsing font decryption file
#Create TTFont object
font_obj = TTFont('jiemi.woff')
#Convert to xml plaintext format
font_obj.saveXML('jiemi.xml')
# Get mapping table
cmap_dict = font_obj.getBestCmap()
print("Font encryption mapping table", cmap_dict)
# Remove the special symbols after encryption &# 𘝤 =>100196 re_data
for i in enumerate(re_data):
new_font_list = re.findall(r'\d+', i[1])
re_data[i[0]] = new_font_list
print("Remove special symbols", re_data)
# Change the English number of the relationship mapping table into Arabic number {100196: '3'}
dict_e_a = {
"one": '1', "two": '2', "three": '3', "four": '4', "five": "5", "six": '6', "seven": "7", "eight": '8', "nine": '9',
"zero": '0'
}
# Traversal relation mapping table
for i in cmap_dict:
# Ergodic dict_e_a
for j in dict_e_a:
# dict_ The value of is equal to dict_ e_ Key of a
if cmap_dict[i] == j:
cmap_dict[i] = dict_e_a[j]
print("Relationship mapping table after replacing with numbers", cmap_dict)
# 10. Change the ciphertext to plaintext 100196 = "3" by matching the response, removing the value of special symbols and changing it to Arabic numerals
for i in re_data: # Remove the value of response and remove the special symbol [[], [], []]
print(i) # ['100388', '100389', '100388', '100385', '100385']
for j in enumerate(i): # 100388
# print(j)
for k in cmap_dict: # Relationship mapping table after changing to Arabic numerals
# print(k)
if j[1] == str(k):
print(j[0])
i[j[0]] = cmap_dict[k]
print("Number of monthly tickets after parsing", re_data)
# Splice a single plaintext into a complete number of monthly tickets
list_ = []
for i in re_data:
j = ''
for k in i:
j += k
list_.append(j)
print("Final monthly ticket plaintext data list", list_)
# 11. Combine the book name and dictionary name to form a dictionary {Book Name: "number of monthly tickets"}
rank_dict = {}
for i in range(len(title_list)):
rank_dict[title_list[i]] = list_[i]
This is not enough. I have made more than one page. It is not very difficult to turn the page. That is, it is not easy to decrypt. Observe the differences in the URLs of page 1, page 2 and page 3
first page: https://www.qidian.com/rank/yuepiao/year2022-month01/
Page 2: https://www.qidian.com/rank/yuepiao/year2022-month01-page2/
Page 3: https://www.qidian.com/rank/yuepiao/year2022-month01-page3/
The complete page turning code is as follows
import random
import requests
import time
from lxml import etree
from fontTools.ttLib import TTFont
import re
pages = int(input('Please enter the number of pages to query'))
for page in range(pages):
if page == 0:
# Determine the website of the monthly ticket ranking list of the starting point Chinese website
url = 'https://www.qidian.com/rank/yuepiao/year2022-month01/'
else:
pages_i=1
url = f'https://www.qidian.com/rank/yuepiao/year2022-month01-page{pages_i+page}/'
# Request header
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.193 Safari/537.36',
'referer': 'https://www.qidian.com/rank/',
'cookie': 'e1=%7B%22pid%22%3A%22qd_P_rank_01%22%2C%22eid%22%3A%22qd_C19%22%2C%22l1%22%3A4%7D; e2=%7B%22pid%22%3A%22qd_P_rank_01%22%2C%22eid%22%3A%22%22%2C%22l1%22%3A4%7D; _yep_uuid=fd95b6b7-090e-c6e5-cb8c-b8387e5b29ab; _ga=GA1.1.376581816.1643601078; newstatisticUUID=1643601078_1599172947; _csrfToken=m8mDkhtjc381bOHrIGiYTkE1g3bUzgPZjExmmO9l; _ga_FZMMH98S83=GS1.1.1643601077.1.1.1643601098.0; _ga_PFYW0QLV3P=GS1.1.1643601077.1.1.1643601098.0'
}
# Response data
response = requests.get(url, headers=headers)
response_text = response.text
html_data = etree.HTML(response_text)
# Get the title through xpath
title_list = html_data.xpath('//h2/a/text()')
print(title_list)
# Get the number of monthly tickets using regular
re_data = re.findall('</style><span class=".*?">(.*?)</span>', response_text)
print(re_data)
# Get dynamic url using regular
font_url = re.findall(r"format\('eot'\); src: url\('(.*?)'\) format\('woff'\)", response_text)[0]
# Send a request to download the font encryption file
font_response = requests.get(font_url, headers=headers)
with open('jiemi.woff','wb')as f:
f.write(font_response.content)
#Parsing font decryption file
#Create TTFont object
font_obj = TTFont('jiemi.woff')
#Convert to xml plaintext format
font_obj.saveXML('jiemi.xml')
# Get mapping table
cmap_dict = font_obj.getBestCmap()
print("Font encryption mapping table", cmap_dict)
# Remove the special symbols after encryption &# 𘝤 =>100196 re_data
for i in enumerate(re_data):
# print(i)
new_font_list = re.findall(r'\d+', i[1])
re_data[i[0]] = new_font_list
print("Remove special symbols", re_data)
# Change the English number of the relationship mapping table into Arabic number {100196: '3'}
dict_e_a = {
"one": '1', "two": '2', "three": '3', "four": '4', "five": "5", "six": '6', "seven": "7", "eight": '8', "nine": '9',
"zero": '0'
}
# Traversal relation mapping table
for i in cmap_dict:
# Ergodic dict_e_a
for j in dict_e_a:
# dict_ The value of is equal to dict_ e_ Key of a
if cmap_dict[i] == j:
cmap_dict[i] = dict_e_a[j]
print("Relationship mapping table after replacing with numbers", cmap_dict)
# 10. Change the ciphertext to plaintext 100196 = "3" by matching the response, removing the value of special symbols and changing it to Arabic numerals
for i in re_data: # Remove the value of response and remove the special symbol [[], [], []]
print(i) # ['100388', '100389', '100388', '100385', '100385']
for j in enumerate(i): # 100388
# print(j)
for k in cmap_dict: # Relationship mapping table after changing to Arabic numerals
# print(k)
if j[1] == str(k):
print(j[0])
i[j[0]] = cmap_dict[k]
print("Number of monthly tickets after parsing", re_data)
# Splice a single plaintext into a complete number of monthly tickets
list_ = []
for i in re_data:
j = ''
for k in i:
j += k
list_.append(j)
print("Final monthly ticket plaintext data list", list_)
# Combine the book name with the dictionary name to form a dictionary {Book Name: "number of monthly tickets"}
rank_dict = {}
for i in range(len(title_list)):
rank_dict[title_list[i]] = list_[i]
print(f"The first{page+1}Final result", rank_dict)
print('-'*50)
#Prevent reverse climbing and then sleep for 1 to 2 seconds
time.sleep(random.randint(1,2))
The effect is as follows:

Those who like this article can focus on me, and more good articles will be published later (● '◡' ●)