Elasticsearch
brief introduction
What is ElasticSearch?
ElasticSearch, abbreviated as ES, is an open-source and highly extended distributed full-text search engine. It is the core of the entire Elastic technology stack (ElasticSearch, Kibana, Beats and logstack are included in the ElasticSearch technology stack). It can store and retrieve data in near real time; It has good scalability and can be extended to hundreds of servers to process PB level data.
Full text search
For search engines such as Google and Baidu, they all generate indexes based on keywords in web pages. When searching, we enter keywords and return them by fuzzy matching in the background. For relational databases, simulation matching can sometimes be processed according to the leftmost matching principle (such as * * 'keyword%'), but in many cases, such as'% keyword ', ’%Keyword% '* * and so on need to retrieve the full text, which is very chicken ribs. Generally, the full text will not be stored in the relational database. Even if the index is established, it is troublesome to maintain. Using the mainstream technology is twice the result with half the effort. Summary:
- The data object searched is a large amount of unstructured text data.
- The number of file records reaches hundreds of thousands or millions or more.
- Support a large number of interactive text-based queries.
- Demand very flexible full-text search query.
- There are special needs for highly relevant search results, but there is no available relational database to meet them.
- A situation where there is relatively little demand for different record types, non text data operations, or secure transactions. In order to solve the performance problems of structured data search and unstructured data search, we need professional, robust and powerful full-text search engine.
install
Linux es single instance installation (take 5.2.2 as an example)
ES does not support root startup under lunix
Download ES: wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.2.2.tar.gz
Create directory mkdir es
Decompression: tar -zxvf elasticsearch-5.2.2 tar. gz -C /es
Create user adduser es
Initialize password passwd es
Give es user file permissions Chmod - R es
Create directory mkdir -p /usr/app/es
Move es to / usr/app/es mv /es /usr/app/es
Switch users su es
Switch directory cd /usr/app/es
Start es sh/ bin/elasticsearch
Test curl http://localhost:9200/
Window
Directly download the relevant packages and run elasticsearch. Com under the bin directory Bat file can start the ES service. In addition, I crawled some data on the Internet and directly used it for learning and testing.
Common operation
Restful introduction
ES supports calling in restful style. Restful Chinese name is table attribute state transfer. It is a protocol, architecture and atom for front-end and back-end interaction of Web applications. It can be simply understood that "the requested resource object and what operation you want to do with the resource object" can be obtained according to this style of URL.
ES common operations
Create index
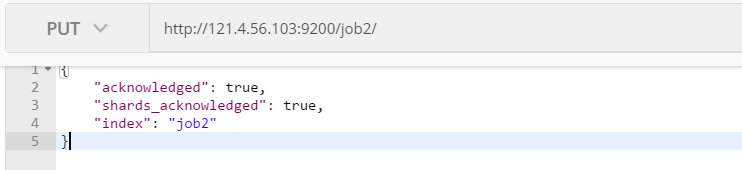
Created an index named job2, acknowledged: response results, shards_acknowledged: fragment result, index: index name.
View all indexes
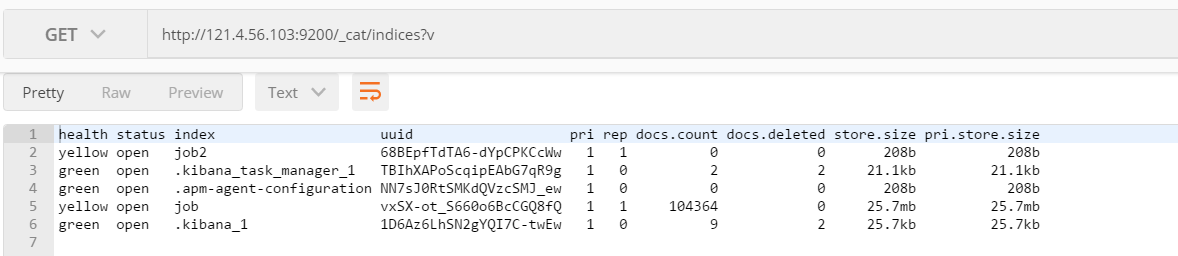
- Header meaning
- Health current server health status: green (cluster integrity) yellow (single point normal, cluster incomplete) red (single point abnormal)
- Status index on / off status
- Index index name
- uuid index unified number
- pri main slice quantity
- Number of rep copies
- docs.count number of documents available
- docs.deleted document deletion status (logical deletion)
- store.size the overall space occupied by the main partition and sub partition
- pri.store.size the space occupied by the main partition
View a single index
Command: http://121.4.56.103:9200/job
Return result:
{
"job": {
"aliases": {}, //alias
"mappings": {} //mapping
},
"settings": {
"index": {
"creation_date": "1622888417389", //Creation time
"number_of_shards": "1", //Number of slices
"number_of_replicas": "1",//Number of copies
"uuid": "vxSX-ot_S660o6BcCGQ8fQ", //Unique identification index Id
"version": {
"created": "7070099" //Version number
},
"provided_name": "job" //Submitted index name
}
}
}
}
Delete index

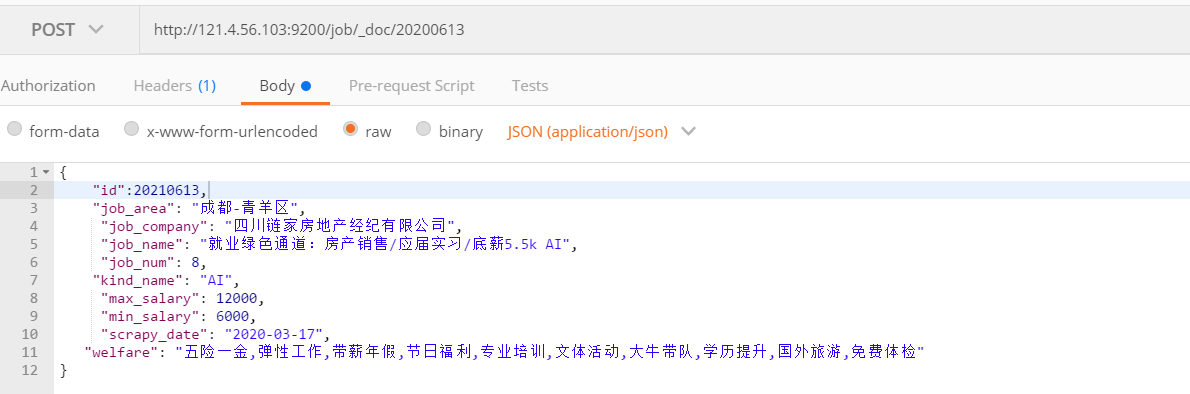
create documents
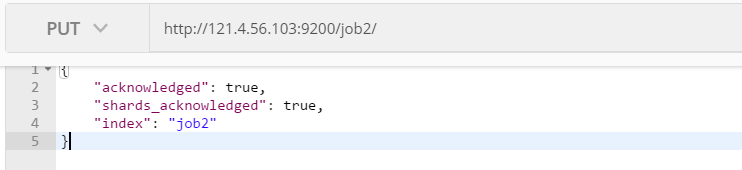
Return result:
{
"_index": "job", / / index name
"_type": "_doc", / / the default type is doc
"_id": "20210613", / / index ID
"_version": 1, / / index version number
"Result": "created", / / result
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 104364,
"_primary_term": 2
}
If no Id is specified, ES will randomly generate a UUID
Index document
Index by Id
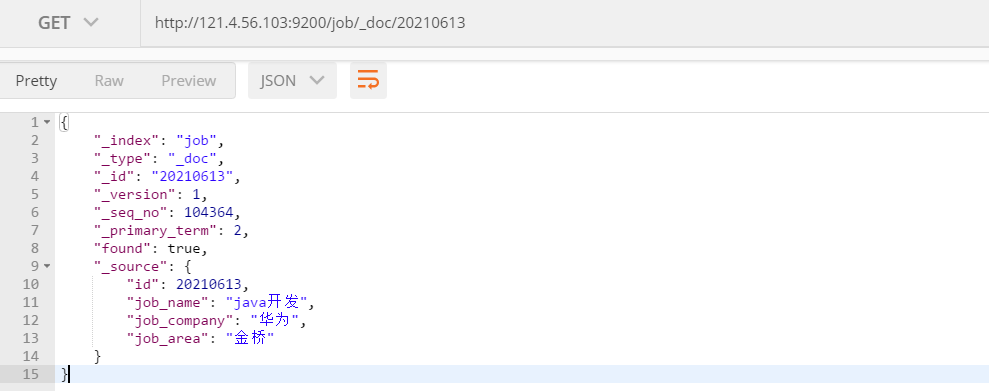
Query all
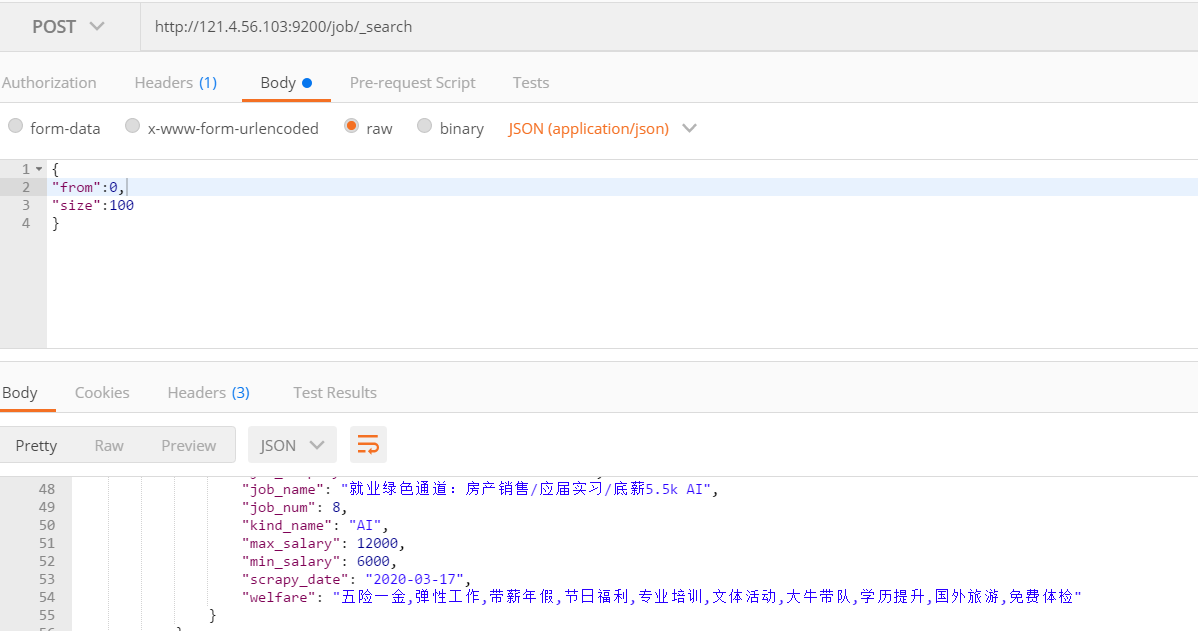
Because the data is too large, paging is selected here. from: offset, size: number of pages per page
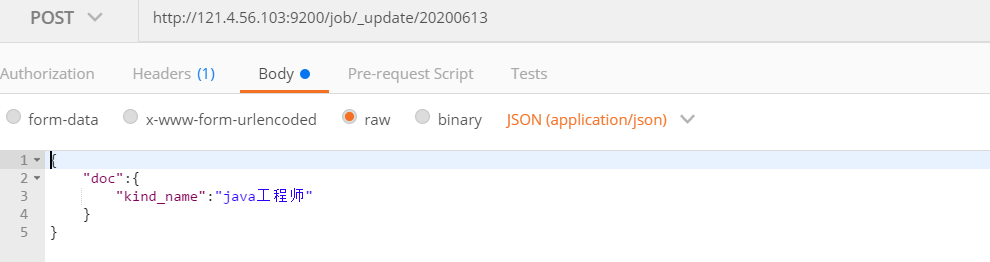
Modify document
Full modification
Local modification
remove document

Condition query
Query all
GET /job/_search
{
"query": {
"match_all": {}
}
, "from": 0
,"size": 200
}
The query result returns the specified field
GET /job/_search
{
"_source": ["job_name","job_company"],
"query": {
"match_all": {}
}
, "from": 0
,"size": 20
}
Query result sorting
GET /job/_search
{
"_source": ["job_name","job_company"],
"query": {
"match_all": {}
}
, "from": 0
,"size": 20
}
Multi condition query
GET /job/_search
{
"query": {
"bool": {
"must": [
{"match": {
"job_area": "Guangzhou"
}
},{"match": {
"kind_name": "java"
}
}]
}
}
, "from": 0
,"size": 20
}
According to job_area and kind_name query, and operation of type database. If it is or, replace must with or
Range query
GET /job/_search
{
"query": {
"bool": {
"must": [
{"match": {
"job_area": "Guangzhou"
}
},{"match": {
"kind_name": "java"
}
}],
"filter": {
"range": {
"max_salary": {
"gte": 20000,
"lte": 30000
}
}
}
}
}
, "from": 0
,"size": 20
}
Find 20 documents with a location in Guangzhou, a category of java and a salary of 20000 to 30000
Word segmentation and precise query
GET /job/_search
{
"query": {
"match": {
"job_name": "java AI"
}
}
, "from": 0
,"size": 20
}
GET /job/_search
{
"query": {
"match_phrase": {
"job_name": "java"
}
}
, "from": 0
,"size": 20
}
"java AI" will be staged above, and the result set of "java" and "Ai" will be found. The following will accurately match "java"
grouping
GET /job/_search
{
"aggs": {
"area_group": {
"terms": {
"field": "kind_name"
}
}
}
, "size": 0
}
According to kind_name is used to group. Sometimes the text format is the default. Aggregation operations such as grouping are prohibited. I need to set this
PUT job/_mapping
{
"properties": {
"kind_name": {
"type": "text",
"fielddata": true
}
}
}
Average
GET /job/_search
{
"aggs": {
"area_group": {
"terms": {
"field": "kind_name"
}
}
}
, "size": 0
}
Basic operation of Java advanced client
Java provides two clients to operate ES, namely Java Low Level REST Client and Java High Level REST Client:
- Java Low Level REST Client: a low-level REST client that interacts with the cluster through http. The user needs to group the request JSON string and parse the response JSON string. Compatible with all ES versions.
- Java High Level REST Client: a high-level REST client. Based on the low-level REST client, it adds relevant APIs such as marshalling request JSON string and parsing response JSON string. The version used needs to be consistent with that of the ES server, otherwise there will be version problems.
POM introduction
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.4</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.76</version>
</dependency>
<dependency>
<groupId>joda-time</groupId>
<artifactId>joda-time</artifactId>
<version>2.10.10</version>s
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
to configure
@Bean
public RestHighLevelClient getClient(){
RestHighLevelClient client=new RestHighLevelClient(
RestClient.builder(new HttpHost("121.4.56.103",9200,"http")));
return client;
}
basic operation
Create index
@org.junit.jupiter.api.Test
public void createIndex() throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("job2");
CreateIndexResponse response = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
Delete index
@org.junit.jupiter.api.Test
public void deleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("job2");
AcknowledgedResponse response = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println(response.isAcknowledged());
}
Find by Id
@org.junit.jupiter.api.Test
public void selectAll() throws IOException {
GetRequest getRequest = new GetRequest("job", "20210613");
GetResponse response = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(response.getSource()));
}
newly added
@org.junit.jupiter.api.Test
public void insertOne() throws IOException {
IndexRequest indexRequest = new IndexRequest("job");
indexRequest.id("202106131");
JobData data = new JobData();
data.setId(202106131);
data.setJob_name("java Background development");
data.setJob_area("Shanghai");
indexRequest.source(new ObjectMapper().writeValueAsString(data),XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
System.out.println(indexResponse.getResult());
}
Batch add
@org.junit.jupiter.api.Test
public void batchInsert() throws IOException {
int begin = 0;
int end = 100;
while (begin<=end){
BulkRequest bulkRequest = new BulkRequest();
List<JobData> jobData = jobDataMapper.selectList(begin, begin + 2000);
for (JobData data:jobData){
IndexRequest indexRequest = new IndexRequest("job");
indexRequest.id(data.getId().toString());
indexRequest.source(JSONObject.toJSONString(data), XContentType.JSON);
bulkRequest.add(indexRequest);
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest,RequestOptions.DEFAULT);
int status = bulk.status().getStatus();
System.out.println("==============================begin:"+begin+"===========status:"+status);
begin+=2000;
}
}
paging
@org.junit.jupiter.api.Test
public void pageSelect() throws IOException {
SearchRequest request = new SearchRequest("job");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0);
builder.size(200);
builder.sort(new FieldSortBuilder("max_salary").order(SortOrder.DESC));
request.source(builder);
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit searchHit:hits){
System.out.println(searchHit.getSourceAsString());
}
}
Condition query
@org.junit.jupiter.api.Test
public void conditionalQuery() throws IOException {
SearchRequest request = new SearchRequest("job");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0);
builder.size(200);
builder.sort(new FieldSortBuilder("max_salary").order(SortOrder.DESC));
builder.query(QueryBuilders.termQuery("job_area.keyword","Guangzhou"));
request.source(builder);
System.out.println(request.source().toString());
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit searchHit:hits){
System.out.println(searchHit.getSourceAsString());
}
}
Multi condition combined query
@org.junit.jupiter.api.Test
public void combinedQuery() throws IOException {
SearchRequest request = new SearchRequest("job");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.from(0);
builder.size(200);
builder.sort(new FieldSortBuilder("max_salary").order(SortOrder.DESC));
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
MatchQueryBuilder matchQuery1 = QueryBuilders.matchQuery("job_area.keyword", "Guangzhou");
MatchQueryBuilder matchQuery2 = QueryBuilders.matchQuery("kind_name.keyword", "java");
MatchQueryBuilder matchQuery3 = QueryBuilders.matchQuery("academic_requirement.keyword", "undergraduate");
boolQuery.must().add(matchQuery1);
boolQuery.must().add(matchQuery2);
boolQuery.must().add(matchQuery3);
builder.query(boolQuery);
request.source(builder);
System.out.println(request.source().toString());
SearchResponse search = restHighLevelClient.search(request, RequestOptions.DEFAULT);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit searchHit:hits){
System.out.println(searchHit.getSourceAsString());
}
}
Window cluster deployment
Node 1 profile
# ---------------------------------- Cluster ----------------------------------- cluster.name: my-es # ------------------------------------ Node ------------------------------------ node.name: es_node1 node.master: true node.data: true # ----------------------------------- Paths ------------------------------------ # ----------------------------------- Memory ----------------------------------- # ---------------------------------- Network ----------------------------------- network.host: localhost http.port: 9200 transport.tcp.port: 9300 # --------------------------------- Discovery ---------------------------------- # ---------------------------------- Gateway ----------------------------------- # ---------------------------------- Various ----------------------------------- http.cors.enabled: true http.cors.allow-origin: "*"
Node 2 profile
# ======================== Elasticsearch Configuration ========================= # ---------------------------------- Cluster ----------------------------------- cluster.name: my-es # ------------------------------------ Node ------------------------------------ node.name: es_node2 node.master: true node.data: true # ----------------------------------- Paths ------------------------------------ # ----------------------------------- Memory ----------------------------------- # ---------------------------------- Network ----------------------------------- network.host: localhost http.port: 9201 transport.tcp.port: 9301 # --------------------------------- Discovery ---------------------------------- discovery.seed_hosts: ["localhost:9300"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # ---------------------------------- Gateway ----------------------------------- # ---------------------------------- Various ----------------------------------- http.cors.enabled: true http.cors.allow-origin: "*"
Node 3 profile
cluster.name: my-es # ------------------------------------ Node ------------------------------------ node.name: es_node3 node.master: true node.data: true # ----------------------------------- Paths ------------------------------------ # ---------------------------------- Network ----------------------------------- network.host: localhost http.port: 9202 transport.tcp.port: 9302 # --------------------------------- Discovery ---------------------------------- discovery.seed_hosts: ["localhost:9301","localhost:9302"] discovery.zen.fd.ping_timeout: 1m discovery.zen.fd.ping_retries: 5 # ---------------------------------- Gateway ----------------------------------- # ---------------------------------- Various ----------------------------------- http.cors.enabled: true http.cors.allow-origin: "*"
Relevant data must be deleted during file replication. If the cluster cannot find the node during local operation, delete the data
Create a user index with 3 slices and 1 copy
[the external chain image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-l9zbcyhe-162409082321) (C: \ users \ administrator \ desktop \ notes \ create cluster node. png)]
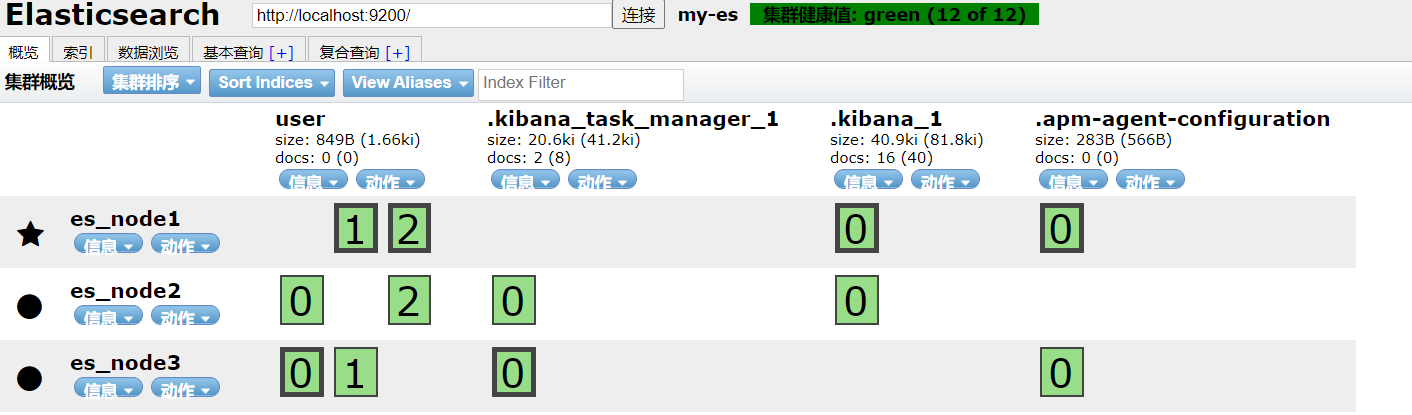
As shown in the figure, bold represents the partition master, and normal represents the backup node.
Core concept learning
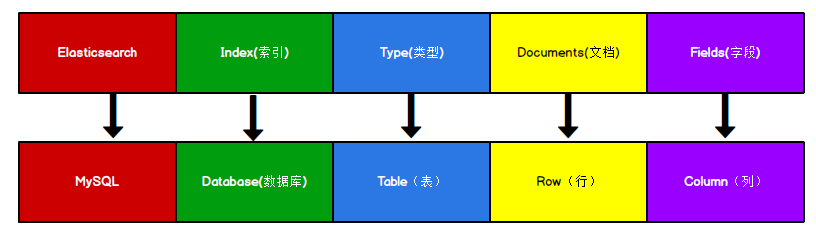
Index (index)
Index is a special data structure, which is used to organize data and speed up data reading. In ES, the index is generally composed of one or more slices, and the index name is unique.
Type
Category refers to the logical partition inside the index. It is uniquely represented inside the index by the name of type. The higher version has been discarded, and the default is_ doc.
Document
A piece of data inside the index is called a document. Compared with relational data, it is a row in the database table.
Fields
Fields are similar to columns in the database and are an integral part of the document.
Mapping
Mapping specifies the storage type, word segmentation method, whether to store and other information of the fields in the index, which is similar to the table structure in the database.
Node
Node is the basic unit of ES cluster, and each running instance is a node.
Cluster
The ES cluster consists of the same cluster Name is a service group composed of one or more nodes that work together and share data.
Shards (split)
When the amount of data in an index is too large, due to the memory and disk processing capacity of a single node, the node cannot respond to the request of the client quickly enough. At this time, it is necessary to split the data on an index horizontally, and each data part split is called a partition. Generally speaking, the shards are on different servers.
Replicas (backup)
Backup, also known as copy, is a backup of the primary partition. This backup is accurate. When a request comes, it will be indexed on the primary partition, distributed to the backup partition for indexing, and finally return the result.
Advanced knowledge point learning
Routing control
The choice of partition is determined by hash algorithm
shard = hash(routing) % number_of_primary_shards
routing indicates the id and number of the document_ of_ primary_ Shards indicates the number of slices,
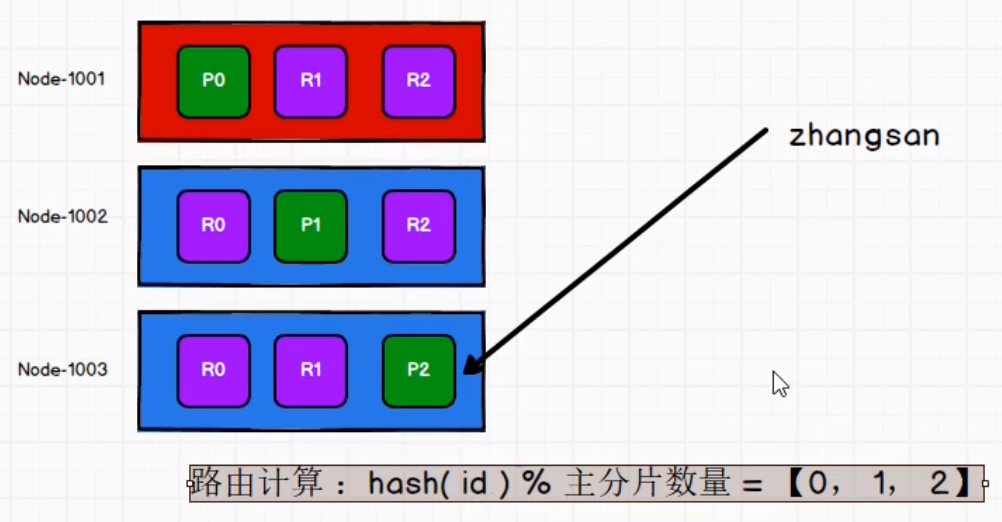
Once the number of slices is determined, it will never change.
Write data flow
Write operations such as new index and delete request are completed on the primary partition before they are further distributed to the replica. The response received by the client indicates that it has completed the work on the primary partition and replica, but when there are too many replicas, it will affect the performance. At this time, you can choose according to the actual parameter settings,
consistency
Consistency. By default, even if only before attempting to perform a write operation, the master shard will require that a specified number of quorum (or in other words, most of the shard copies must be active and available) before performing a write operation (where the shard copy can be the master shard or copy shard). This is to avoid write operation in case of network partition failure, resulting in data inconsistency. Specified quantity: int ((primary + number_of_replicas) / 2) + 1
The value of the consistency parameter can be set to:
- one: write operation is allowed as long as the primary partition status is ok.
- All: write operation is allowed only when the status of the primary partition and all replica partitions is OK.
- Quorum: the default value is quorum, that is, write operations are allowed when the status of most fragmented copies is OK.
Note that number in the calculation formula of the specified quantity_ of_ Replicas refers to the number of replica fragments set in the index setting, not the number of replica fragments in the current processing active state. If your index setting specifies that the current index has three replica fragments, the calculation result of the specified number is: int((1 primary + 3 replicas) / 2) + 1 = 3. If you start only two nodes at this time, the number of active fragment copies will not reach the specified number, so you will not be able to index and delete any documents.
timeout
What happens if there are not enough replica shards? Elasticsearch will wait and hope that more pieces will appear. By default, it waits up to 1 minute. If you want, you can use the timeout parameter to make it terminate earlier: 100 is 100 milliseconds and 30s is 30 seconds.
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-c6ayiom7-162409082327) (C: \ users \ administrator \ desktop \ notes \ writing process. png)]
Data reading process
When reading data, the client will randomly send the data to a node, and then the node will select the appropriate replica partition for request distribution. This node is called the coordination node.
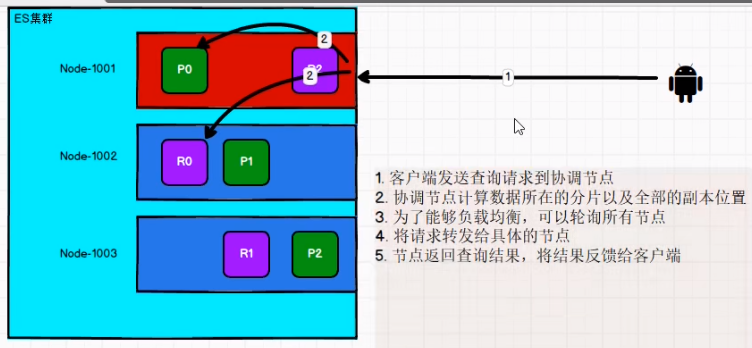
Document update process
[the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-gss88iet-162409082329) (C: \ users \ administrator \ desktop \ notes \ data update. png)]
The steps to partially update a document are as follows:
- The client sends an update request to Node 1.
- It forwards the request to Node 3 where the main partition is located.
- Node 3 retrieves the document from the main partition and modifies it_ JSON in the source field and try to re index the document of the main fragment. If the document has been modified by another process, it will retry step 3, exceeding retry_ on_ Give up after conflict times.
- If Node 3 successfully updates the document, it forwards the new version of the document to the replica fragments on Node 1 and Node 2 in parallel and re establishes the index. Once all replica fragmentation returns success, Node 3 returns success to the coordination node, and the coordination node returns success to the client.
When the master shard forwards changes to the replica shard, it does not forward update requests. Instead, it forwards a new version of the complete document. Keep in mind that these changes will be forwarded asynchronously to the replica shards, and there is no guarantee that they will arrive in the same order in which they were sent. If Elasticsearch only forwards change requests, the changes may be applied in the wrong order, resulting in a corrupted document.
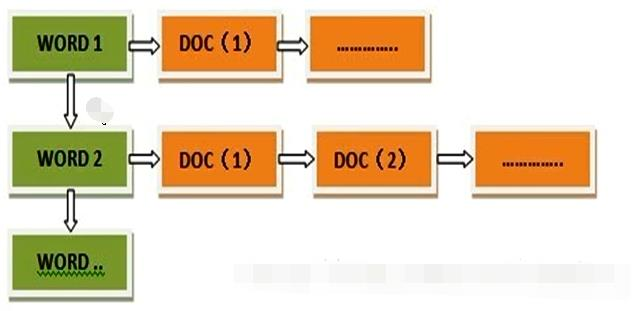
Inverted index
Inverted index is opposite to forward index concept.
- Forward index. The forward index associates the document with a id. First, look for the id, then find the document based on id, and finally compare whether the field in the document satisfies the condition. [the external link image transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-6q8yy9d8-1624090823240)(C:\Users\Administrator\Desktop \ notes \ front row. png)]
- Inverted index uses word segmentation to segment documents, associate fields with documents, find documents through reverse fields, and finally compare them.
Inverted index immutable
Early full-text retrieval would build a large inverted index for the whole document collection and write it to disk. Once the new index is ready, the old one will be replaced by it, so that the latest changes can be retrieved.
The inverted index cannot be changed after it is written to disk: it will never be modified.
- No lock required. If you never update the index, you don't need to worry about multiple processes modifying data at the same time.
- Once the index is read into the kernel's file system cache, it will stay there because of its invariance. As long as there is enough space in the file system cache, most read requests will directly request memory instead of hitting the disk. This provides a significant performance improvement.
- Other caches (such as filter cache) are always valid throughout the life cycle of the index. They do not need to be reconstructed every time the data changes because the data does not change.
Writing a single large inverted index allows data to be compressed, reducing the use of disk IO and indexes that need to be cached in memory.
Of course, a constant index also has some disadvantages. The main fact is that it is immutable! You can't modify it. If you need to make a new document searchable, you need to rebuild the entire index. This either limits the amount of data an index can contain, or limits the frequency with which the index can be updated.
Segmented storage
The index data will be divided into multiple sub files, and each sub file is called segment. And the segment is not changeable. Once the index data is written to the hard disk, it cannot be modified
Why is there segmented storage?
Because all files exist in a large inverted index and the amount of data is increasing, when we need to update the current inverted index file in full, this will make the data update timeliness very poor and consume a lot of resources.
A submission point will be generated after the segment is written to the hard disk. The submission point means that a file used to record all segment information has been generated. Once the submission point is owned, it means that the segment loses the write permission.
New data
To add data, just add a segment in the current document and write data.
Delete data
Deleting data will not delete the data from the segment, but add a new one del file, which will record the segment information of these deleted documents. The document marked for deletion can still be matched by the query, but it will pass before the final result is returned del file to remove it from the result set.
Update data
Due to the immutability of the segment, the update operation of the segment becomes two operations, that is, delete first and then add. ElasticSearch will remove old documents from del file, and then index the new version of the document into a new segment. When querying data, each version of data will be queried, but its final result will pass del file to remove it from the result set.
The main disadvantage of segment immutability is that it takes up a large amount of storage space. When deleting data, the old data will not be deleted immediately, but in del file is marked for deletion. The old data can only be removed when the segment is updated, which will lead to a waste of storage space. In particular, if the data is updated frequently, each update adds new data to the segment and marks the data in the old segment, which will waste more storage space.
In addition, all result sets will be included in the query results. Therefore, the master node needs to exclude the old data marked for deletion, which will bring the burden of query.
Delayed write strategy
In ES, the process of index writing to disk is asynchronous. In order to improve the write performance, ES does not add a segment to the disk every time a new piece of data is added, but adopts the delayed write strategy. The execution process is as follows: whenever a new data is written, it is written into the JVM memory first. When the default time is reached or the amount of data in the memory reaches a certain amount, a refresh operation will be triggered. The refresh operation generates the data in memory on a new segment and caches it to the file cache system. Later, it refreshes it to disk and generates a commit point.
In order to prevent data loss, ES introduces transaction log.
- The new document index is written into memory first. In order to prevent data loss, ES will append a copy of data to the transaction log.
- New documents are continuously written into memory and recorded in the transaction log. At this time, the data cannot be retrieved.
- When the default refresh time is reached or the amount of data in memory reaches a certain amount, ElasticSearch will trigger a refresh to refresh the data in memory to the file cache system in the form of a new segment and empty the memory. At this time, although the new segment has not been submitted to the disk, it can already submit the document retrieval function and cannot be modified.
- As the new document index is continuously written, when the log data size exceeds a certain value or exceeds a certain time, ES will trigger a Flush. At this time, the data in memory is written to a new segment and written to the file cache system. The data of the file cache system is refreshed to the disk through Fsync to generate a submission point. The log file is deleted and an empty log file is created.
Segment merging
In the ES automatic refresh process, a new segment is created every second. This will naturally lead to a sharp increase in a short period of time, and when there is too much data in the period, it will lead to greater resource consumption, such as the consumption of file handle, memory and CPU. In the content search stage, because the search request needs to check each segment and then merge the query results, the more segments, the slower the search speed.
To this end, ES introduces segment merging. Segment merging is performed regularly in the background. Small segments are merged into large segments, and then these large segments are merged into larger segments. During the merging process, the old deleted documents will be deleted from the file system.
Optimistic lock
ES introduces optimistic lock to solve the conflict problem. Each data is for a version. When the version changes when modifying the data, the action will be repeated.
Consistency of copies
Through the replica control protocol, the distributed system allows users to read the data of each replica in the distributed system through a certain method. These data are the same under certain constraints, that is, the consistency of replicas. Replica data consistency is for each node of the distributed system, not for the replica of a node.
In distributed systems, consistency is divided into strong consistency, weak consistency, session consistency and final consistency.
Strong consistency requires that users can read the last successfully updated copy data at any time. Weak consistency means that after the data is updated, the user cannot read the value of the most value of the data within a certain time, so it is rarely used in practice.
Session consistency means that once a user reads a certain version of data in a session, he will not read older data. Final consistency means that the data of each replica in the cluster can finally reach a completely consistent state.
From the perspective of replica, strong consistency is the best. However, in CAP theory, once CP is selected, the application availability will be lost in a short time, because distributed applications will have delay in synchronizing data. In consideration of the overall performance, availability and scalability, it is selected according to the service.
How replica data is distributed
The distribution of data mainly includes hash distribution, distribution according to data range, distribution according to data volume, consistent hash method and so on.
- The hash distribution is the simplest, which takes the hash of the keyword directly and then takes the module with the data of the machine, but the disadvantages are also obvious. On the one hand, the scalability is not strong. Once the data needs to be expanded, all data needs to be distributed according to hash value again; On the other hand, hash can easily lead to uneven data distribution in storage space.
- Distribution by data range is common. Generally speaking, different intervals are divided according to data eigenvalues, so that different servers in the cluster can process data in different intervals. This method can avoid the uneven distribution of storage space data caused by hash value.
- The distribution by data volume is close to the distribution by data range. Generally, the data is increased as a sequence, and the data set is divided into several data blocks according to a relatively fixed size, and different data blocks are distributed to different servers.
- The consistency hash has a hash ring, and the data will be distributed to the nearest node (Extended) according to the hash value.