#Cloud application system development technology test center (related to interview questions)
1. CAP theory
Overview: a distributed system can only meet two of the three requirements at most: Consistency, Availability and Partition tolerance.
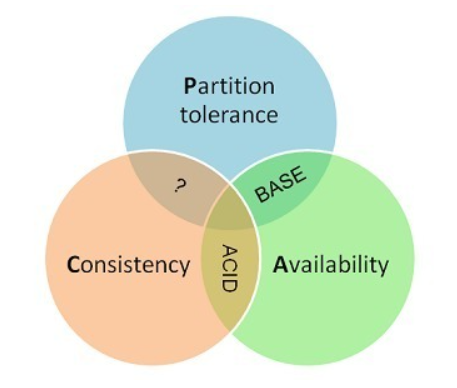
Consistency consistency
Consistency refers to "all nodes see the same data at the same time", that is, the data of all nodes at the same time is completely consistent.
Consistency is due to the problem of concurrent reading and writing under multiple data copies. Therefore, when understanding, we must pay attention to considering the scenario of concurrent reading and writing under multiple data copies.
For consistency, it can be divided into two different perspectives: client and server.
- client
From the perspective of the client, consistency mainly refers to how to obtain the updated data during multiple concurrent accesses.
- Server
From the server side, it is how to distribute the updates to the whole system to ensure the final consistency of data.
For consistency, it can be divided into three categories: strong / weak / final consistency
From the perspective of client, when multiple processes access concurrently, the different strategies of how to obtain the updated data in different processes determine the different consistency.
- Strong consistency
For relational databases, it is required that the updated data can be seen by subsequent access, which is a strong consistency.
- Weak consistency
If it can tolerate that some or all of the subsequent accesses cannot be accessed, it is weak consistency.
- Final consistency
If the updated data is required to be accessible after a period of time, it is the final consistency.
Availability availability
Availability refers to "reads and writes always succeeded", that is, the service is always available within the normal response time.
Good usability mainly means that the system can serve users well without bad user experience such as user operation failure or access timeout. Availability in general, availability is closely related to distributed data redundancy, load balancing, etc.
Partition Tolerance
Partition fault tolerance refers to "the system continues to operate destroy arbitrary message loss or failure of part of the system", that is, when a distributed system encounters a node or network partition failure, it can still provide services that meet consistency or availability.
2. Concept and principle of interprocess communication (IPC)
Concept:
Concurrent execution processes in the operating system can be independent or cooperative:
- If a process cannot affect or be affected by other processes, the process is independent, in other words, the process that does not share data with any other process is independent;
- If a process can affect or be affected by other processes, the process is collaborative. In other words, a process that shares data with other processes is a collaborative process.
There are many reasons to provide an environment that allows processes to collaborate:
- Information sharing: since multiple users may be interested in the same information (such as sharing files), an environment should be provided to allow concurrent access to this information.
- Computational acceleration: if you want a specific task to run quickly, you should divide it into subtasks, and each subtask can be executed in parallel with other subtasks. Note that to achieve such acceleration, the computer needs to have multiple processing cores.
- Modularization: it may be necessary to construct the system in a modular way, that is, the system functions are divided into independent processes or threads.
- Convenience: even a single user can perform many tasks at the same time. For example, users can edit, listen to music and compile in parallel.
Collaborative processes need an inter process communication mechanism (IPC) to allow processes to exchange data and information with each other. There are two basic models of interprocess communication: shared memory and message passing (message queuing):
- The shared memory model will establish a memory area for cooperative processes to share. Processes exchange information by reading or writing data to this shared area.
- The message passing model realizes communication by exchanging messages between cooperative processes.
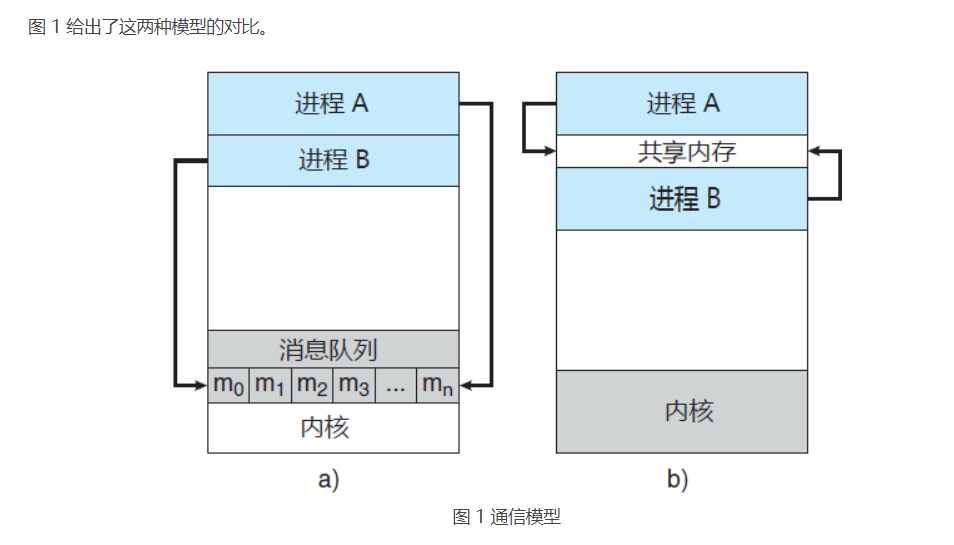
Shared memory system
**Inter process communication using shared memory requires the communication process to establish a shared memory area** Typically, shared memory regions reside in the address space of the process that created the shared memory segment. Other processes that want to use this shared memory segment for communication should attach it to their own address space.
Messaging system (message queue)
Previously, I explained how collaboration processes can communicate through shared memory. This scheme requires these processes to share a memory area, and application developers need to write explicit code to access and operate the shared memory. Another way to achieve the same effect is that the operating system provides a mechanism for collaborative processes to communicate through messaging.
Messaging provides a mechanism to allow processes to communicate and synchronize without having to share an address space. This is particularly useful for distributed environments where communication processes may be located on different computers connected through a network.
3. Concept of Socket API
socket concept
socket is an abstract layer between application layer and transport layer. It abstracts the complex operation of TCP/IP layer into several simple interfaces. The supply layer calls the implemented processes to communicate in the network.
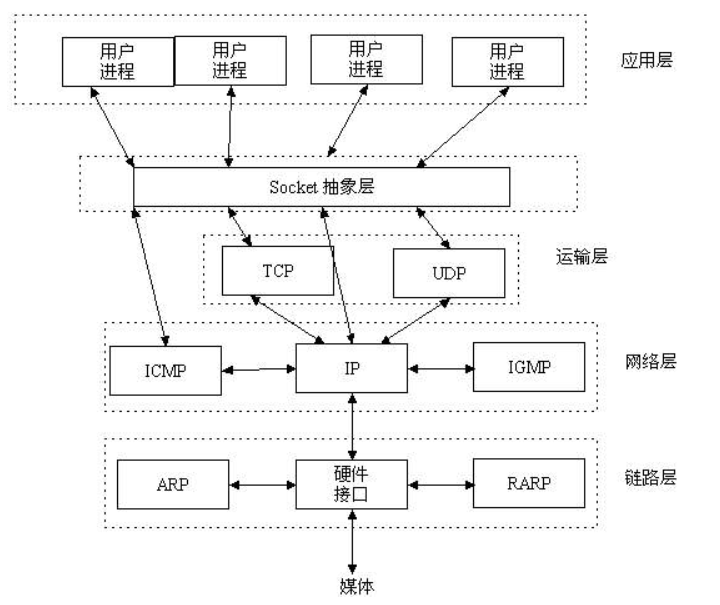
Socket originated from UNIX. Under the idea that everything in UNIX is a file philosophy, socket is an implementation of "open read / write close" mode. The server and client maintain a "file" respectively. After establishing a connection and opening, they can write content to their own file for the other party to read or read the other party's content, and close the file at the end of communication.
Socket communication process
Socket can be understood as a special file, which maintains a file on the server and client respectively, and uses socket API functions to operate the file. After the connection is established and opened, you can write content to each file for the other party to read or read the other party's content, and close the file at the end of communication. In UNIX philosophy, "everything is a file". The operation mode of the file is basically three steps of "open read write close". Socket is actually an implementation of this mode.
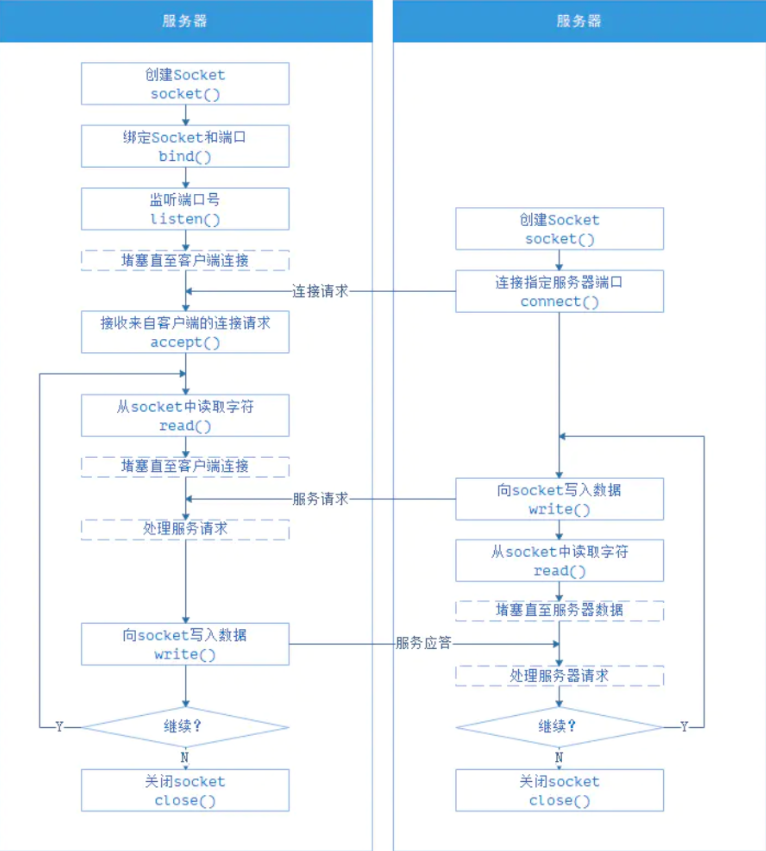
socket API
API concept
API, full English name of Application Programming Interface, translated as "Application Programming Interface". Are predefined functions designed to provide applications and developers with the ability to access a set of routines based on some software or hardware without accessing the source code or understanding the details of the internal working mechanism.
Socket API concept
That is, the network communication interface (each pair of communication socket interfaces) carries out inter process communication access in the form of IP address + port.
Socket is the endpoint of communication. Each pair of processes communicating over the network needs to use a pair of sockets.
Socket composition: IP address + port number
Socket adopts client server architecture.
The server waits for client requests by listening to the specified port.
Servers implementing specific services listen to well-known ports:
- telent server port, 23
- ftp server listening port, 21
- web or http server, 80
All ports below 1024 are well known.
4. HTTP protocol and common status codes, session mechanism and technical principles, HTTPS protocol and usage scenarios
agreement
Hypertext Transfer Protocol (HTTP) is a communication protocol that allows hypertext markup language (HTML) documents to be transmitted from the Web server to the browser of the client.
HTTP protocol
Hypertext transfer protocol. It is a data transmission protocol that specifies the rules of communication between browser and World Wide Web (WWW = World Wide Web) server and transmits World Wide Web documents through the Internet.
HTTP protocol is a transfer protocol used to transfer hypertext from WWW server to local browser. It can make the browser more efficient and reduce network transmission. It not only ensures that the computer transmits hypertext documents correctly and quickly, but also determines which part of the transmitted document and which part of the content is displayed first (for example, text precedes graphics).
HTTP is an application layer protocol, which is composed of request and response. It is a standard client server model. HTTP is a stateless protocol.
In the Internet, all transmission is through TCP/IP. HTTP protocol, as the application layer protocol in TCP/IP model, is no exception.
Common status code:
| Status code | category | Reason Phrase |
|---|---|---|
| 1XX | Informational (informational status code) | The accepted request is being processed |
| 2XX | Success (success status code) | The request is processed normally |
| 3XX | Redirection (redirection status code) | Additional actions are required to complete the request |
| 4XX | Client Error (Client Error status code) | The server cannot process the request |
| 5XX | Server Error (Server Error status code) | Server processing request error |
-
200 OK: the request has been processed normally.
-
204 No Content: the request is processed successfully, but no resources can be returned to the client. Generally, it is used when only the information needs to be sent from the client to the server, and the client does not need to send new information content.
-
206 Partial Content: a request for a part of a resource. This status code indicates that the client made a range request and the server successfully executed this part of the GET request. The response message contains the entity content within the range specified by the content range.
-
301 Moved Permanently: the URI of the resource has been updated. Please update your bookmark reference. Permanent redirection, the requested resource has been assigned a new URI, and the URI referred to by the resource should be used in the future.
-
302 Found: the URI of the resource has been temporarily located in another location. You already know this. Temporary redirection. Similar to 301, but the resource represented by 302 is not permanently moved, but only temporary. In other words, the URI corresponding to the moved resource may change in the future.
-
303 See Other: the URI of the resource has been updated. Can you access it temporarily according to the new URI. This status code indicates that since there is another URL for the resource corresponding to the request, the GET method should be used to obtain the requested resource. 303 status code and 302 status code have the same function, but 303 status code clearly indicates that the client should use the GET method to obtain resources, which is different from 302 status code.
-
When the 301302303 response status code returns, almost all browsers will change POST to GET and delete the body in the request message, and then the request will be sent again automatically.
-
304 Not Modified: the resource was found but did not meet the requirements. This status code indicates that when the client sends a conditional request (the request message using the GET method includes any header of if match, if modified since, if none match, if range and if unmodified since), the server allows the request to access resources, but after the request fails to meet the conditions, it directly returns 304.
-
307 Temporary Redirect: temporary redirect. Has the same meaning as 302.
-
400 Bad Request: the server cannot understand the request sent by the client, and there may be syntax errors in the request message.
-
401 Unauthorized: this status code indicates that the sent request needs authentication information that has passed HTTP authentication (BASIC authentication, DIGEST authentication).
-
403 Forbidden: access to that resource is not allowed. This status code indicates that access to the requested resource was denied by the server. (permissions, unauthorized IP, etc.)
-
404 Not Found: there is no requested resource on the server. Path error, etc.
-
500 Internal Server Error: it seems that the internal resource has failed. This status code indicates that an error occurred when the server executed the request. There may also be a bug or some temporary failure in the web application.
-
503 Service Unavailable: sorry, I'm busy right now. This status code indicates that the server is temporarily overloaded or is being shut down for maintenance and cannot process the request now.
HTTP protocol is usually hosted on TCP protocol, and sometimes on TLS or SSL protocol layer. At this time, it has become what we often call HTTPS.
Conversation mechanism
Concept: a technique commonly used in Web applications to track a user's entire Session. The commonly used Session tracking technologies are Cookie and Session. Cookies determine the user's identity by recording information on the client, and Session determines the user's identity by recording information on the server.
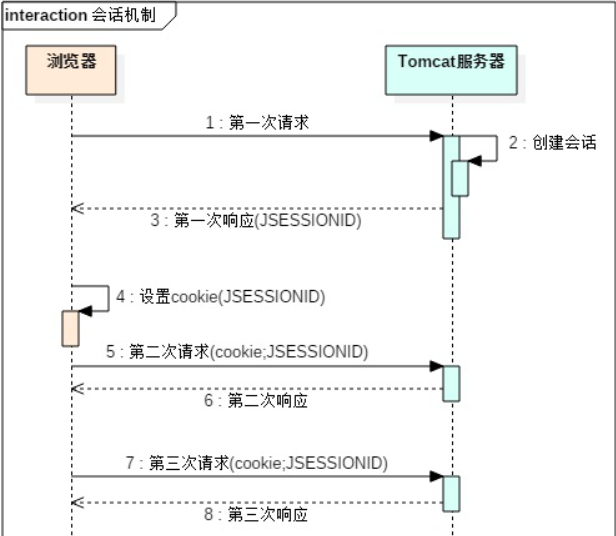
(1) When the browser accesses the Tomcat server for the first time, the Tomcat server will create a session object on the server and store it in the map key is the ID of the session and value is the session object itself
(2) In response, the session id will be written to the client browser through a cookie
(3) The browser will write the session id into the local cookie in the local directory
(4) In subsequent requests, the contents of the local cookie will be automatically read and the corresponding cookie will be brought when requesting
(5) The server will directly find the corresponding session object according to the passed cookie
5. Technical principles of CGI and Java Servlet
CGI concept
CGI is a protocol between a Web server and an independent process. It will set the Header of HTTP Request request as the environment variable of the process, the Body body of HTTP Request as the standard input of the process, and the standard output of the process as HTTP Response, including Header and Body.
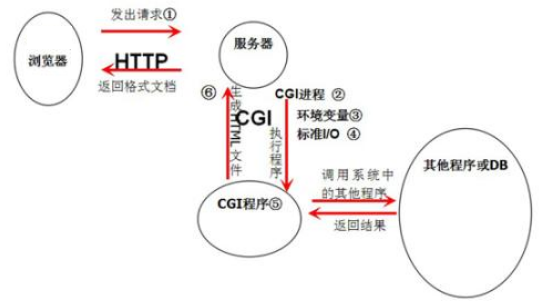
CGI function and processing steps
Most CGI programs are used to interpret and process the input information from the form, generate the corresponding processing in the server, or feed back the corresponding information to the browser. CGI program makes web pages interactive.
CGI processing steps:
(1) send the user request to the server through the Internet.
(2) the server receives the user's request and gives it to the CGI program for processing.
(3) the CGI program transmits the processing results to the server.
(4) the server sends the results back to the user.
Servlet definition
Servlet is a Java application that runs on the server side and is used to process and respond to client requests.
Characteristics of Servlet
(1) The Servlet object is created by the Servlet container (Tomcat).
(2) Servlet is an interface: located in javax Servlet package.
(3) The service method is used to receive the user's request and return a response.
(4) It is executed many times when users visit (you can count the number of visits to the website).
Servlet principle
Servlet multithreading architecture is based on Java multithreading mechanism, and its life cycle is responsible by the Web container.
When the client requests a Servlet for the first time, the Servlet container will The Servlet class is instantiated by the XML configuration file and stored in memory at this time.. When a new client requests the Servlet, the Servlet class will not be instantiated, that is, multiple threads are using the instance. In this way, when two or more threads access the same Servlet at the same time, multiple threads may access the same resource at the same time, and the data may become inconsistent. Therefore, we should pay attention to thread safety when building Web applications with servlets. Every request is a thread, not a process. Therefore, the performance of Servlet in processing requests is very high.
For Servlet, it is designed to be multi-threaded (if it is single threaded, you can imagine that when 1000 people request a web page at the same time, the other 999 people are waiting depressed before the first person obtains the request result). If a new thread object is created for each user's request to run, The system will spend a lot of overhead on creating and destroying threads, which greatly reduces the efficiency of the system.
Therefore, there is a thread pool behind the Servlet multithreading mechanism. The thread pool creates a certain number of Thread objects at the initial stage of initialization. By improving the utilization of these objects, we can avoid creating objects frequently, so as to improve the efficiency of the program. (threads are used to execute the service method of servlets. Servlets exist in the singleton mode in Tomcat. The thread safety problem of servlets only appears when there are a large number of concurrent accesses and is difficult to find. Therefore, special attention should be paid to when writing Servlet programs. Thread safety problems are mainly caused by instance variables, so the use of instance variables in servlets should be avoided . If the application design cannot avoid using instance variables, use synchronization to protect the instance variables to be used, but in order to ensure the best performance of the system, the code path with the least availability should be synchronized)
The Action of struts 2 is a prototype, not a single instance; An Action instance will be generated for each request to process.
Solutions to servlet thread safety: synchronize the operation of shared data, Synchronized (this) {...}, and avoid using instance variables
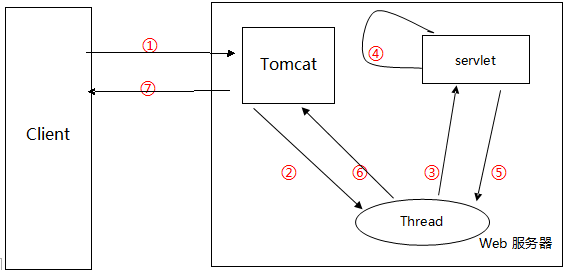
① The client sends a request to the server;
② This process is important. At this time, Tomcat will create two objects: HttpServletResponse and HttpServletRequest. And pass their references (note that references) to the newly allocated thread;
③ The thread starts to contact the servlet;
④ The servlet calls doGet() and doPost() methods to process according to GET and POST;
⑤ And ⑥ the servlet sends the processed results back to Tomcat through the thread, and then destroys or returns the thread to the thread pool;
⑦ Tomcat turns the processed result into an HTTP response and sends it back to the client, so that the client can accept the processed result.
6. Technical principles and concepts of P2P
P2P concept
P2P is called "peer-to-peer". "Peer-to-peer" technology is a new network technology, which depends on the computing power and bandwidth of participants in the network, rather than concentrating the dependence on a few servers. P2P is also the abbreviation of Point to Point in English. It is a download term, which means that while you download, your computer will continue to upload the host. This download method, the more people, the faster, but the disadvantage is that it will cause great damage to the hard disk (you have to read while writing, and the previous thunderbolt download mode is the P2P mode). It also occupies more memory and affects the speed of the whole machine.
P2P development process
(1) Decentralization
In P2P network, resources and services are scattered on all nodes. The transmission of information and the realization of services can be completed directly between nodes without the intervention of servers. The decentralization of P2P is the embodiment of the marginal development of modern network, and also brings advantages to its scalability and robustness.
(2) Scalability
In P2P network, with the participation of users, not only the demand for services increases, but also the overall resources and service capacity of the system are improved. In theory, the scalability of P2P network is unlimited, so the system can always meet the needs of users. For example, in the traditional C/S mode of file download, when the number of users accepted by the server increases, the file download speed will slow down; In P2P system, on the contrary, the more user nodes are added, the more resources in the network, and the download speed is accelerated.
(3) Robustness
Because the resources and services in P2P network are scattered among nodes, when some nodes and networks are damaged, other nodes can also be used as a supplement, so it has strong attack resistance and fault tolerance. Generally, P2P networks are self-organized, allowing nodes to join and exit freely. Therefore, when some nodes of P2P network fail, it can automatically adjust the network topology and maintain the connectivity with surrounding nodes.
(4) High cost performance
In enterprise applications, profit is the most concerned. The traditional C/S mode makes enterprises spend a lot of money on the renewal and maintenance of the central server, which increases the product cost of enterprises. However, with the rapid development of hardware technology in accordance with Moore's law, personal computing power and storage capacity are constantly improving. With the advent of the mobile Internet era, various mobile devices use computing everywhere, which makes the distribution of resources more decentralized. Using P2P technology to make full use of the idle resources of many computing nodes and complete the tasks of high-performance computing and mass storage is the development trend of the Internet in the future. The use of P2P technology reduces the cost of enterprise maintenance center server and purchasing a large number of network equipment. At present, it is mainly used in the academic research of massive information such as genetics and astronomy. Once it is mature, it can be popularized in enterprises.
(5) Privacy protection
In P2P network, the transmission of information and services is scattered among network nodes. There is no need to go through centralized links, and the possibility of users' private information being eavesdropped and leaked is greatly reduced. Usually, the privacy problem on the Internet mainly adopts the way of relay forwarding, so as to hide the communication participants in many network entities. In the traditional C/S mode, the relay server node is often used to realize the flexibility and reliability of anonymity, which can better protect privacy.
(6) Load balancing
In the traditional C/S mode, due to the limitation of the computing and storage capacity of the server, the number of users connected to the server is controlled to a certain extent. If the limit is exceeded, there may be a danger of machine failure. In P2P network, nodes are the combination of server and client. Computing and storage tasks are allocated to each node, which alleviates the pressure of the central server and is more conducive to the load balancing of the network.
Principles of P2P technology
In P2P network, each node can not only get services from other nodes, but also provide services to other nodes. In this way, the huge terminal resources are used to solve the two disadvantages of C/S mode.
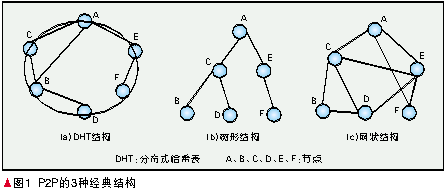
P2P network has three popular organizational structures, which are applied in different P2P applications.
(1)DHT structure
Distributed hash table (DHT)[1] is a powerful tool. Its proposal has aroused an upsurge of DHT research in academic circles. Although DHT has various implementation methods, it has a common feature, that is, it is a ring topology. In this structure, each node has a unique node ID, and the node ID is a 128 bit hash value. Each node saves the IDs of other predecessor and successor nodes in the routing table. As shown in Figure 1(a). Through these routing information, other nodes can be easily found. This structure is mostly used for file sharing and streaming media as the underlying structure transmission[2].
(2) Tree structure
The tree structure of P2P network is shown in Figure 1(b). In this structure, all nodes are organized in a tree. The tree root has only child nodes, the leaves have only parent nodes, and other nodes have both child nodes and parent nodes. The flow of information flows along the branches. The original tree structure is mostly used for P2P Live Streaming [3-4].
(3) Reticular structure
The reticular structure is shown in Figure 1 © It is also called unstructured. As the name suggests, in this structure, all nodes are connected together irregularly, and there is no stable relationship or parent-child relationship. Mesh structure [5] provides P2P with maximum tolerance and dynamic adaptability, and has achieved great success in streaming media live broadcast and on-demand applications. When the network becomes large, the concept of super node is often introduced. Super node can be combined with any of the above structures to form a new structure, such as KaZaA[6].
7. java Web application (CounterWebApp), JSP operation principle, deployment of War package
Java web Application
A web application is a complete application running on the web server, which is composed of a group of servlets, HTML pages, classes, and other resources. It exists in the form of a structured and hierarchical directory.
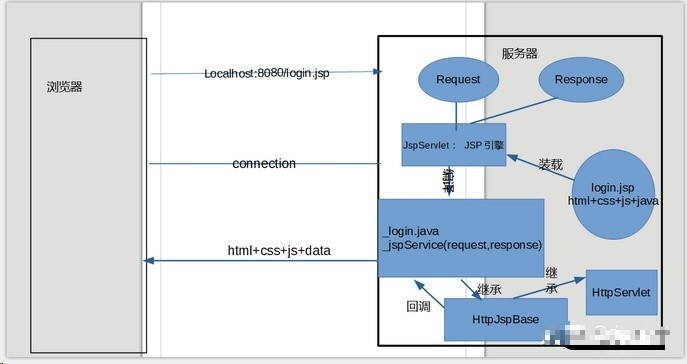
Operation principle of JSP
(1) When a WEB container requests access to a JSP page, it will submit the access request to the JSP engine for processing. The JSP engine in Tomcat is a Servlet program, which is responsible for interpreting and executing JSP pages.
(2) When each JSP page is accessed for the first time, the JSP engine first translates it into a Servlet source program, then compiles the Servlet source program into a Servlet class file, and then the WEB container loads and interprets and executes the Servlet program translated by the JSP page in the same way as calling the ordinary Servlet program.
(3) Tomcat 5 places the Servlet source file and class file created for the JSP page in the "apache-tomcat-5.5.26 \ work \ Catalina \ localhost < application name > \" directory. The package name of the Servlet translated by Tomcat into the JSP page is org apache. JSP (i.e. under apache-tomcat-5.5.26\work\Catalina\localhost\org\apache\jsp \ file)
8. Concept of unit test / integration test / Test Driven Development
Unit test.
Unit test is also called module test. The test object is the program module, software component or object-oriented class that can be compiled independently. Its purpose is to check that each module can correctly realize its designed function, performance, interface and other design constraints. Unit testing is usually completed by module developers themselves, that is, developers code to implement a functional module, and also complete the coding of unit testing and pass the test. The developer shall complete the submission when writing the specific implementation code of the function module. It can be white box test (i.e. the internal processing process can be seen) or black box test. This is also the most basic test to ensure that the basic function module can work normally.
Unit test cases
Build IntOperations
package com.example.math;
/**
* Integer arithmetical operations.
*
* @author bobyuan
*/
public class IntOperations {
/**
* Get the name of this class.
* @return A string name.
*/
public static final String getName() {
return "IntOperations";
}
/**
* Add 2 integers.
* @param a The first integer value.
* @param b The second integer value.
* @return The result of a add b.
*/
public int add(int a, int b) {
return a + b;
}
/**
* Subtract 2 integers.
* @param a The first integer value.
* @param b The second integer value.
* @return The result of a subtract b.
*/
public int subtract(int a, int b) {
return a - b;
}
/**
* Calculate the average value of 2 integers.
* @param a The first integer value.
* @param b The second integer value.
* @return The average of the 2 input integers.
*/
public double average(int a, int b) {
//return (a + b) / 2.0; //may cause overflow!
return (a / 2.0) + (b / 2.0);
}
}
Build IntOperationsTest
package com.example.math;
import junit.framework.Assert;
import junit.framework.TestCase;
/**
* Unit test for IntOperations using JUnit3.
*
* Integer.MAX_VALUE = 2147483647
* Integer.MIN_VALUE = -2147483648
*
* @author bobyuan
*/
public class IntOperationsTest extends TestCase {
/**
* Default constructor.
*/
public IntOperationsTest() {
super();
}
/**
* Constructor.
* @param name The name of this test case.
*/
public IntOperationsTest(String name) {
super(name);
}
/* (non-Javadoc)
* @see junit.framework.TestCase#setUp()
*/
// @Override
// protected void setUp() throws Exception {
// //System.out.println("Set up");
// }
/* (non-Javadoc)
* @see junit.framework.TestCase#tearDown()
*/
@Override
protected void tearDown() throws Exception {
//System.out.println("Tear down");
}
/**
* Example of testing the static method.
*/
public void test_getName() {
Assert.assertEquals("IntOperations", IntOperations.getName());
}
/**
* Test case for add(a, b) method.
*/
// public void test_add() {
// IntOperations io = new IntOperations();
// Assert.assertEquals(0, io.add(0, 0));
// Assert.assertEquals(1, io.add(0, 1));
// Assert.assertEquals(1, io.add(1, 0));
//
// Assert.assertEquals(4, io.add(1, 3));
// Assert.assertEquals(0, io.add(-3, 3));
//
// Assert.assertEquals(Integer.MIN_VALUE, io.add(Integer.MIN_VALUE + 1, -1));
// Assert.assertEquals(Integer.MAX_VALUE, io.add(Integer.MAX_VALUE - 1, 1));
// }
/**
* Test case for subtract(a, b) method.
*/
public void test_subtract() {
IntOperations io = new IntOperations();
Assert.assertEquals(0, io.subtract(0, 0));
Assert.assertEquals(-1, io.subtract(0, 1));
Assert.assertEquals(-2, io.subtract(1, 3));
Assert.assertEquals(2, io.subtract(3, 1));
Assert.assertEquals(Integer.MIN_VALUE, io.subtract(Integer.MIN_VALUE + 1, 1));
Assert.assertEquals(Integer.MAX_VALUE, io.subtract(Integer.MAX_VALUE - 1, -1));
}
/**
* Test case for average(a, b) method.
*/
public void test_average() {
IntOperations io = new IntOperations();
Assert.assertEquals(0.0, io.average(0, 0));
Assert.assertEquals(2.0, io.average(1, 3));
Assert.assertEquals(2.5, io.average(2, 3));
Assert.assertEquals(Integer.MIN_VALUE / 2.0, io.average(Integer.MIN_VALUE, 0));
Assert.assertEquals(Integer.MIN_VALUE / 2.0, io.average(0, Integer.MIN_VALUE));
Assert.assertEquals(Integer.MAX_VALUE / 2.0, io.average(Integer.MAX_VALUE, 0));
Assert.assertEquals(Integer.MAX_VALUE / 2.0, io.average(0, Integer.MAX_VALUE));
Assert.assertEquals(Integer.MIN_VALUE + 0.0, io.average(Integer.MIN_VALUE, Integer.MIN_VALUE));
Assert.assertEquals(Integer.MAX_VALUE + 0.0, io.average(Integer.MAX_VALUE, Integer.MAX_VALUE));
}
}
Unit test directory structure:
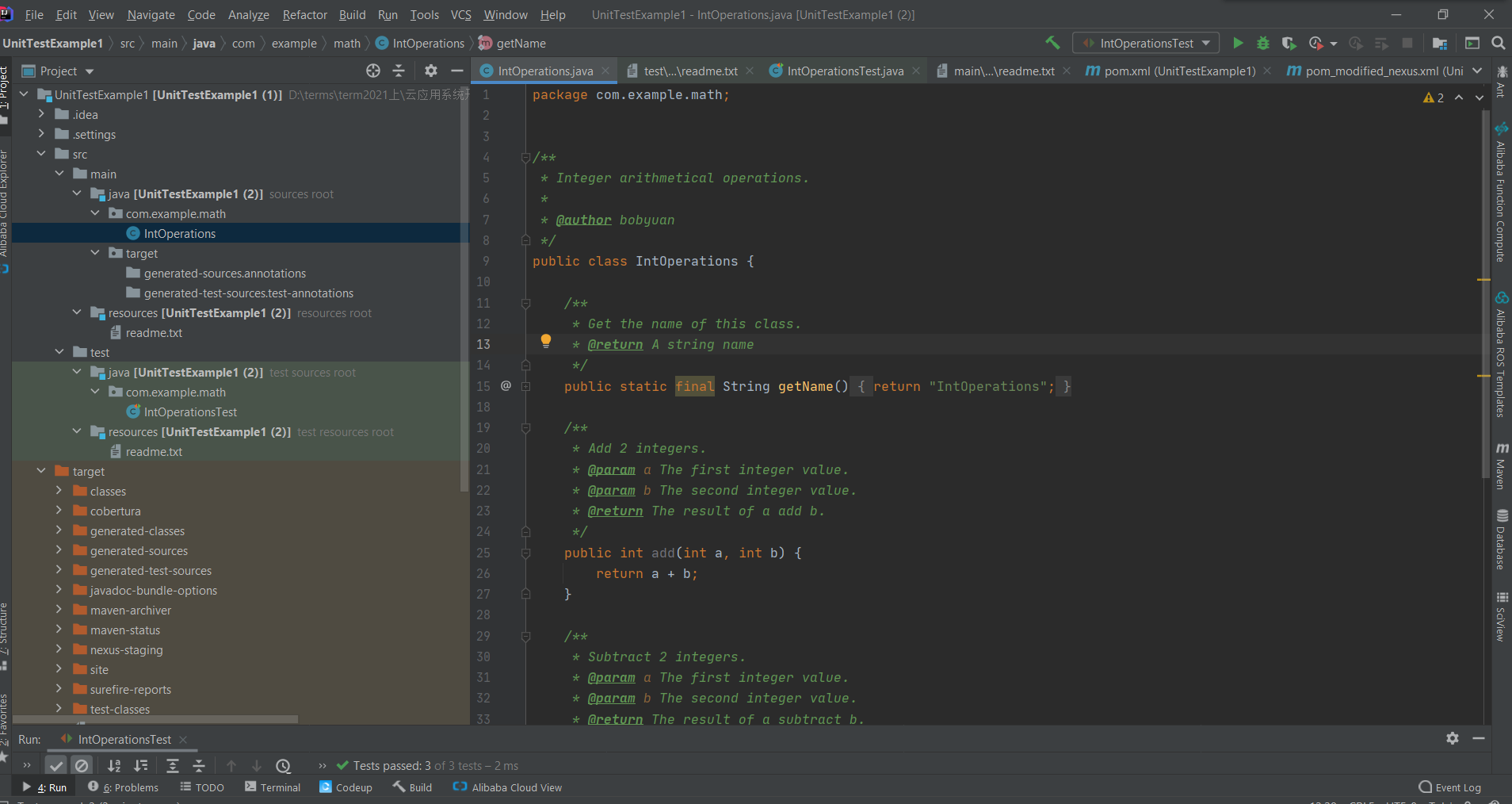
Reference link address https://cloudappdev.netlify.app/book/content.html#_5-1-%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95
Integration testing.
The so-called integration is to assemble each functional module into a relatively independent application, and verify the function from the overall perspective to see whether it meets the design goal. The purpose of integration test is to check the interface relationship between modules and between modules and integrated software, and verify whether the integrated software meets the design requirements. Before the integration test, these modules should have passed the unit test. Integration testing is black box testing, which can be completed by developers or special testing teams (some are called Quality Assurance team or QA team).
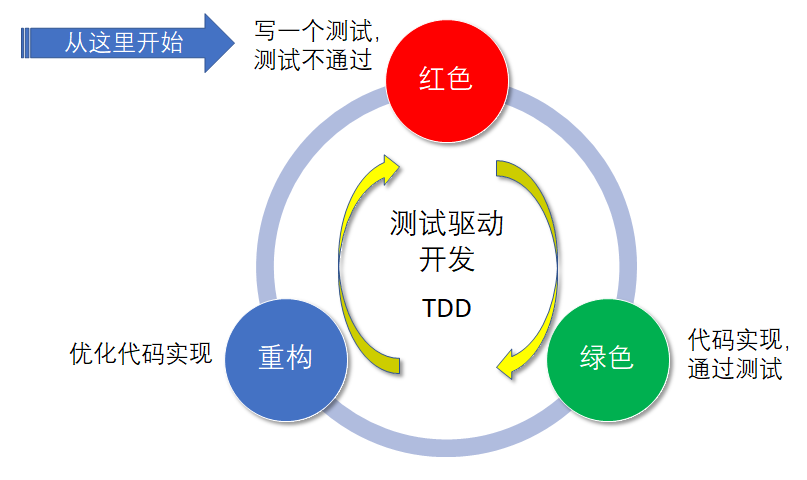
Test Driven Development (TDD)
It is a new development method different from the traditional software development process. The traditional software development process is to develop first and then test, while test driven development requires to write the code of test cases before writing and realizing a certain function, and then only write the function code that makes the test pass (i.e. minimize the implementation), so as to promote the whole development through testing. This helps to write concise, usable and high-quality code and speed up the development process.
The basic process of test driven development is as follows:
- The input and output of a unit to be tested are clearly defined from the perspective of requirements and expected results.
- Run all unit tests (sometimes only one or part of them need to be run), and find that the new unit test cannot pass (or even compile). Usually, the test in the integrated development environment displays red after execution, indicating that it fails.
- Write the implementation code quickly and let the unit test run through as soon as possible. Therefore, some unreasonable "fast" implementation methods can be used in the program. Usually, the green color is displayed after the test is executed in the integrated development environment, indicating that it passes.
- Refactoring. On the premise that all unit tests pass, optimize the design and implementation of the code.
9. Continue to integrate / deliver / deploy, build the tools and software used (Jenkins, Git, Maven, Tomcat, etc.) for debugging and use
Continuous integration
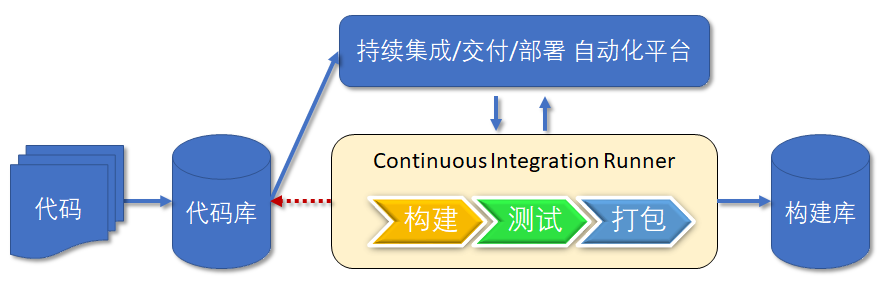
Continuous integration is a software development practice, that is, the software code developed by teamwork is integrated at least once or more every day. Each integration is verified through automated construction (including compilation, automated testing, packaging and distribution, etc.), so as to find integration errors as soon as possible.
Continuous integration is to integrate the code written by multiple developers into the same branch, and then save the program to the Artifact Repository after compilation, testing and packaging. It emphasizes that developers should immediately build and (unit) test new code after submitting it. According to the test results, we can determine whether the new code and the original code can be correctly integrated. As shown in the figure below:
If the scale of project development is relatively small, such as a person's project, if it has little dependence on external systems, software integration is not a problem. With the increasing complexity of software projects, higher requirements will be put forward to ensure that all components can work together after integration. Early integration, frequent integration and frequent integration can help the project find quality problems in the early stage. If these problems are found in the later stage, the cost of solving the problems will be very high, which is likely to lead to project delay or project failure.
For Martin Fowler's original text on Continuous Integration, please refer to Continuous Integration (website: https://www.martinfowler.com/articles/continuousIntegration.html ), please refer to Teng Yun's Chinese translation http://www.cnblogs.com/CloudTeng/archive/2012/02/25/2367565.html .
Well known continuous integration software include:
- Jenkins (website: https://jenkins.io/ )It is open source software with rich functions, which is enough for individuals and small teams to use.
- TeamCity (the website is https://www.jetbrains.com/teamcity )It is commercial software, and the free "Professional Server License" is enough for individuals and small teams.
Continuous delivery
Continuous delivery is to regularly and automatically deploy the latest programs from the Artifact Repository to the test environment. Continuous delivery is based on continuous integration, which deploys the integrated code to "production like environments" closer to the real running environment. For example, after completing the unit test, we can deploy the code to the Staging environment connected to the database for more tests. If there is no problem with the code, you can continue to manually deploy to the production environment. As shown in the figure below:
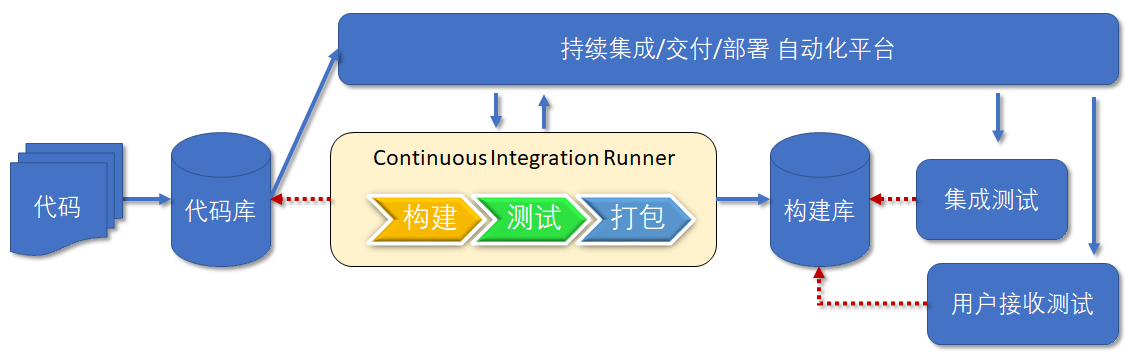
Figure 7.2.1 continuous delivery
For Continuous Delivery, please refer to Continuous Delivery at https://www.thoughtworks.com/continuous-delivery ), which mentioned a book "Continuous Delivery" published by Addison Wesley in 2010. The Chinese translation of the book "Continuous Delivery: a systematic method for publishing reliable software" was published by the people's post and Telecommunications Publishing House in 2011.
Well known continuous delivery software include:
- Jenkins (website: https://jenkins.io/ )It is open source software with rich functions, which is enough for individuals and small teams to use.
- GoCD (website is https://www.gocd.org/ )It is an open source software originally developed, initiated and funded by ThoughtWorks.
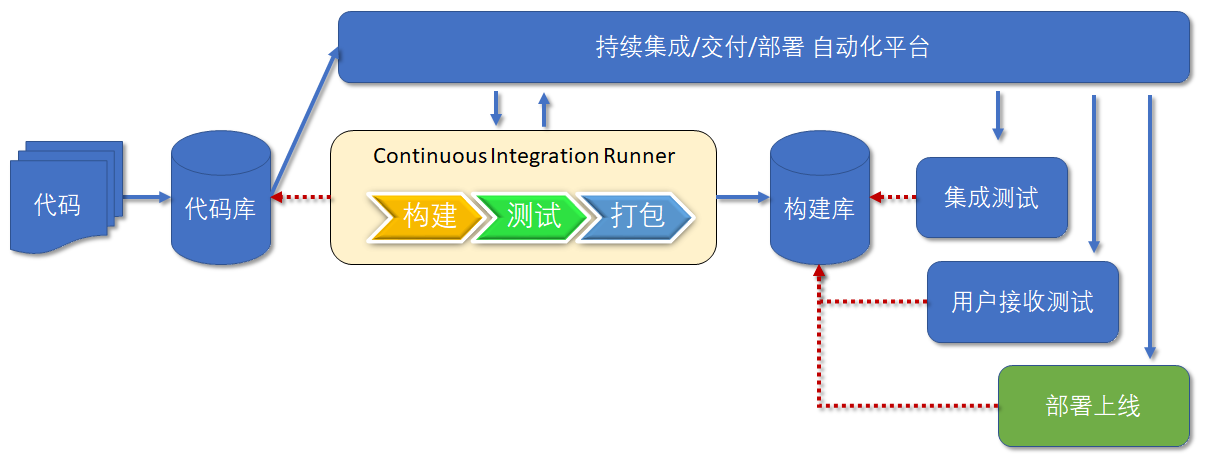
Continuous deployment
Continuous deployment is to regularly and automatically deploy a stable release to the production environment. Continuous deployment is to automate the process of deploying to the production environment on the basis of continuous delivery. As shown in the figure below:
Jenkins use
Installing and using Jenkins commands for Ubuntu
//Get download package wget -q -O - https://pkg.jenkins.io/debian/jenkins.io.key | sudo apt-key add - sudo sh -c 'echo deb http://pkg.jenkins.io/debian-stable binary/ > /etc/apt/sources.list.d/jenkins.list' //Update apt software sudo apt-get update //Install Jenkins sudo apt-get install jenkins //View Jenkins status sudo systemctl status jenkins # stop Jenkins service. sudo systemctl stop jenkins # change from "HTTP_PORT=8080" to "HTTP_PORT=9090" in this file. sudo vi /etc/default/jenkins # restart Jenkins service. sudo systemctl start jenkins # check service status, should be active now. sudo systemctl status jenkins
Git use
git installation
//Install openJDK for Ubuntu sudo apt install openjdk-11-jdk //View the openJDK installation path which java # update system to latest. sudo apt update -y sudo apt upgrade -y # install OpenJDK 8. sudo apt install openjdk-8-jdk # list the installed JDKs. sudo update-java-alternatives --list # set to use the specific JDK from the list. sudo update-java-alternatives --set java-1.8.0-openjdk-amd64 //Add global variables and modify / ect/profile # added by nick_jackson. export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export PATH=$JAVA_HOME/bin:$PATH
git common commands
Check the answers to the 12 questions below
maven use
Ubuntu is installed using apt command
# install apache-maven package. sudo apt install maven # Find maven download package path which mvn #View maven version mvn --version
Download the unzipped package for Ubuntu installation
# move to the target directory. cd /usr/local # extract the release package. sudo tar zxf ~/apache-maven-3.6.1-bin.tar.gz # create symbolic link to the real installation. sudo ln -s apache-maven-3.6.1 apache-maven #Modify the / etc/profile file with root. As shown in the following example, M2 is added_ Home environment variable, and modify the environment variable PATH to m2_ Add home / bin to the PATH. # added by nick_jackson. export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 export JRE_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre export M2_HOME=/usr/local/apache-maven export PATH=$JAVA_HOME/bin:$M2_HOME/bin:$PATH # Find maven download package path which mvn #View maven version mvn --version
mvn common commands
mvn compile take src/main/java Compile the file under as class File output to target Under the directory mvn clean clean yes maven Cleaning order of the project, execution clean Will delete target Contents and contents mvn test test yes maven Test order of the project mvn test,Will execute src/test/java Unit test class under mvn package package yes maven Packaging commands for projects java Project execution package become involved jar Package, for web Engineering success war package mvn install install yes maven Installation order and execution of the project install take mave become involved jar Package or war Publish package to local warehouse
10. Concept and technical principle of DevOps
DevOps (a combination of Development and Operations in English) is a method or practice that emphasizes the communication and cooperation between software Development, technical operation and quality assurance (QA) departments to jointly promote the automation of software change and delivery process, so as to make the construction, testing and distribution online faster, more frequent and reliable.
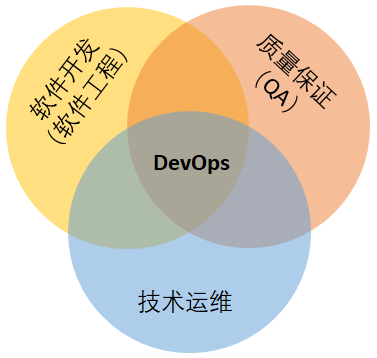
DevOps principle
DevOps integrates cultural concepts, practices and tools, which can improve the ability of organizations to quickly deliver applications and services. Compared with traditional software development and infrastructure management processes, DevOps can help organizations develop and improve products faster. This speed enables organizations to better serve their customers and compete more efficiently in the market.
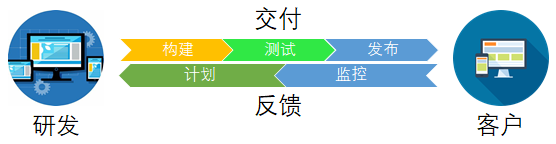
In DevOps mode, the development team and operation team are no longer "isolated" teams. Sometimes, the two teams converge into one team, and their engineers will cooperate with each other throughout the application life cycle (from development and testing to deployment to operation) to develop a series of skills that are not limited to a single function.
In some DevOps modes, the quality assurance and security team will also be more closely combined with the development and operation team, throughout the entire life cycle of the application. When security is the focus of all DevOps team members, this is sometimes referred to as "devosops".
These teams use practical experience to automate the slow process of previous manual operations. They use technical systems and tools that can help them operate and develop applications quickly and reliably. These tools can also help engineers independently complete tasks that usually need the cooperation of other teams (such as deploying code or preset infrastructure), so as to further improve the work efficiency of the team.
In a word, the key of DevOps is process automation - let the code complete the manual operation in the past, so as to greatly save cost and improve efficiency. It should be noted that in the real world, DevOps is more applied to large enterprises, because the cooperation of small enterprises is relatively easy, the product line is unstable, and the input-output advantage of introducing DevOps is not obvious.
11. Principle of container Docker and common operation commands (list images, list containers, port mapping, etc.)
Docker principle
The essence of Docker container is a virtual environment. The container contains a single application and all the dependent environments it needs, which is equivalent to a minimized virtual machine. Its state will not affect the host, and conversely, the state of the host will not affect the container. Only the ports and storage volumes preset by the container can communicate with the external environment. In addition, for the outside world, the container is a black box, and the outside world can't see its inside and don't need to care.
The deployment of Docker is relatively simple. The Container is created from the Image, and the Image contains all the required dependent environments, so that an Image can be deployed directly without modifying the system configuration of the server. Note that the Docker Image is stateless, while the Container is stateful. The data generated by the Container during operation is saved in the Container, which means that the temporary files generated by the process in the Container are still stored in the Container, and will be deleted when the whole Container is deleted. If the generated file contains important data, you need to point the corresponding generated directory to the host directory or data volume Container. Data volume containers are no different from ordinary containers, except that they do not contain application processes and exist only to save data. Do not save important data in the Container (except the mounted data volume location), that is, the internal state of the Container should be unimportant. The Container can be deleted and created at any time. The configuration file shall not be saved inside the Container, but the configuration file confirmed by commissioning shall be removed from the Container and properly saved.
Each container of Docker only runs a single application and completes the most basic services, such as simple MySQL database service and simple Redis cache service. To realize a product function, multiple basic services are often required to work together. That is, it usually requires multiple containers to work together to form a fully functional application and realize product functions.
The operation of Docker involves three basic components:
- A client that runs the docker command (Docker Client)
- A host that runs a Docker Image in the form of a Docker Container
- A Docker Image repository (Registry)
The Docker Client communicates with the "Docker daemon" running on the Docker Host. The client and the host can run on the same machine. The default Registry is Docker Hub https://hub.docker.com/ ), it is a SaaS service that shares and manages images. You can register a free account. Free users can only publish public images.
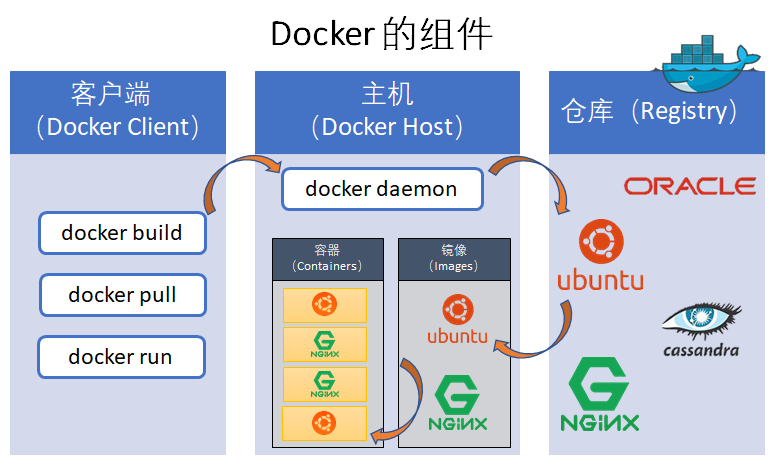
Docker uses the following operating system functions to improve the technical efficiency of containers:
- Namespaces act as the first level of isolation. Ensure that a process is running in a container and that other processes outside the container cannot be seen or affected.
- Control Groups is an important part of LXC and has the key functions of resource accounting and restriction.
- The UnionFS file system acts as the building block of the container. In order to support the lightweight and fast features of Docker, it creates a user layer.
Using Docker to run any application requires two steps:
- Build an image;
- Run the container.
docker common commands
# remove the old version of Docker installed. sudo apt-get remove docker docker-engine docker.io # update the apt package list. sudo apt-get update -y # install Docker's package dependencies. sudo apt-get install apt-transport-https ca-certificates \ curl software-properties-common # download and add Docker's official public PGP key. curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - # verify the fingerprint. sudo apt-key fingerprint 0EBFCD88 # add the `stable` channel's Docker upstream repository. # Select stable version # if you want to live on the edge, you can change "stable" below to "test" or # "nightly". I highly recommend sticking with stable! sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" # update the apt package list (for the new apt repo). sudo apt-get update -y # install the latest version of Docker CE. sudo apt-get install -y docker-ce # allow your user to access the Docker CLI without needing root access. # Add the current user (here $USER=bobyuan) to the "docker" user group. This user group was established when Docker CE was installed. sudo usermod -aG docker $USER # You need to exit the current user and log in again to take effect. Check that the "docker" user group has appeared. groups # Run "Hello world" to check. docker run hello-world # check the docker service status. systemctl status docker # print help information. docker help # print help information for "run" command. docker run --help # show the Docker version information. docker version # display system-wide information. docker info # list running containers. docker ps # list all containers, including stopped ones. docker ps --all # Create a daemon Docker container and run the latest Ubuntu. Note the parameter - itd, which is the simplest abbreviation of the three options -- interactive --tty --detach. It can also be written separately as - i -t -d. docker run -itd ubuntu /bin/bash # View the list of all locally downloaded images docker images -a # start the already stopped container, attach and interactive. docker start -ai <container> # launch the Bash shell into the container. docker exec -it <container> /bin/bash # display the running processes of a container docker top <container> # kill specified container. docker kill <container> # kill all running containers. docker kill $(docker ps -q) # remove specified container. docker rm <container> # remove all running containers (kill before remove). docker rm $(docker ps -a -q) # remove specified image. docker rmi <image> # remove all existing images. docker rmi $(docker images -a -q) # Find mirror docker search <image-name> # View the historical version of the mirror docker history <image_name> # Use the push command to upload the image to the Docker registry docker push <image_name> ###=============Run the docker command================= # login "ubuntuvm1" VM as bobyuan. cd ~ # git clone the CounterWebApp. mkdir -p scm/gitlab cd scm/gitlab git clone https://gitlab.com/bobyuan/20190224_cloudappdev_code.git cd 20190224_cloudappdev_code/spring_maven_webapp/CounterWebApp # build the release package mvn package # download and run "tomcatserver" container (Apache Tomcat/8.5.32). docker run -it --name tomcatserver -p 80:8080 tomcat /bin/bash # Note: in case you have the container existed, just start it as below. # docker start -ai tomcatserver # start Tomcat server ($CATALINA_HOME=/usr/local/tomcat) cd $CATALINA_HOME/bin ./catalina.sh run # we can now access the Tomcat server via link: http://<ubuntuvm1>:80 # press Ctrl+C to stop Tomcat server. # change directory to CounterWebApp project home. cd scm/gitlab cd 20190224_cloudappdev_code/spring_maven_webapp/CounterWebApp # check the "war" file exists. ls -l target/CounterWebApp.war # copy the "war" file to Tomcat in the Container. docker cp target/CounterWebApp.war tomcatserver:/usr/local/tomcat/webapps/
12. Distributed version management tool Git, branch concept and usage scenario, conflict and conflict resolution
Git branch concept and usage scenario
Branch concept
This is one of the most important and commonly used concepts and functions in Git. The branch function solves the conflict between the stability of the version under development and the online version. During the use of Git, our default branch is generally the Master. Of course, this can be modified. We complete a development in the Master and generate a stable version, Then, when we need to add new functions or make modifications, we only need to create a new branch, then develop on the branch, and merge it into the main branch after completion.
There are several concepts in the branch:
(1) Branch: a branch is a line formed by connecting the points created each time.
(2) master branch: after the version library is created, a default branch will be generated. This branch is called the main branch, also known as the master branch. All branches expand around this branch.
(3) Sub branch: a branch created on the basis of the master branch. The development of the sub branch is independent of the main branch.
(4) Pointer: in each branch, there will be a pointer to this branch, which points to the submitted version used in the current version library, that is, to the specified point on the branch line. The master branch has a master pointer, which is similar to the pointers of other branches.
(5) HEAD pointer: refers to the branch pointer used by the current version library.
Usage scenario
(1) Delete unwanted branches.
(2) Modify the underlying code without affecting the main function update of the current version
(3) Simultaneous construction of multiple functions
(4) bug fix, version fallback, etc.
git common commands
git remote add origin git@github.com:yeszao/dofiler.git # Configure remote git version Library git pull origin master # Download code and quick merge git push origin master # Upload code and quick merge git fetch origin # Get code from remote library git branch # Show all branches git checkout master # Switch to the master branch git checkout -b dev # Create and switch to dev branch git commit -m "first version" # Submit git status # View status git log # View submission history git config --global core.editor vim # Set the default editor to vim (git uses nano by default) git config core.ignorecase false # Set case sensitivity git config --global user.name "YOUR NAME" # Set user name git config --global user.email "YOUR EMAIL ADDRESS" # Set mailbox //alias git config --global alias.br="branch" # Create / view local branches git config --global alias.co="checkout" # Switch branch git config --global alias.cb="checkout -b" # Create and switch to a new branch git config --global alias.cm="commit -m" # Submit git config --global alias.st="status" # View status git config --global alias.pullm="pull origin master" # Pull branch git config --global alias.pushm="push origin master" # Submit branch git config --global alias.log="git log --oneline --graph --decorate --color=always" # Single line and color display records git config --global alias.logg="git log --graph --all --format=format:'%C(bold blue)%h%C(reset) - %C(bold green)(%ar)%C(reset) %C(white)%s%C(reset) %C(bold white)— %an%C(reset)%C(bold yellow)%d%C(reset)' --abbrev-commit --date=relative" # Complex display //Create version Library git clone <url> # Clone remote version Library git init # Initialize local version Library //Modification and submission git status # View status git diff # View changes git add . # Track all changed files git add # Track specified files git mv # files renaming git rm # Delete file git rm --cached # Stop tracking files without deleting them git commit -m "commit message" # Submit all updated documents git commit --amend # Modify last submission //View history git log # View submission history git log -p # View the submission history of the specified file git blame # View the submission history of the specified file in a list //revoke git reset --hard HEAD # Undo the changes of all uncommitted files in the working directory git reset --hard # Undo to a specific version git checkout HEAD # Undo the changes of the specified uncommitted file git checkout -- # Ditto previous command git revert # Undo the specified commit branch and label //Branches and labels git branch # Show all local branches git checkout # Switch to the specified branch or label git branch # Create new branch git branch -d # Delete local branch git tag # List all local labels git tag # Create a label based on the latest submission git tag -a "v1.0" -m "Some notes" # -a specifies the label name and -m specifies the label description git tag -d # delete a tap git checkout dev # Merge specific commit to dev branch git cherry-pick 62ecb3 //Remote and local merge git init # Initialize local code warehouse git add . # Add local code git commit -m "add local source" # Submit local code git pull origin master # Download remote code git merge master # Merge master branches git push -u origin master # Upload code
13. Basic Ubuntu Linux operating commands, JDK8 installation
Basic operating commands for Ubuntu Linux
# cd into folder cd Enter your car home folder cd ~ Go back to your own home folder cd .current directory cd .. upper story cd - Last directory # ls view current directory file ls -a View all files, including hidden files ls -l View the current file as a list, excluding hiding ls -al View all files in the current directory, including hidden files, and display them as a list ls -hl More humanized display file pwd View your current folder path # mkdir create folder mkdir Folder name/Folder name/.......... Create a folder under a folder # touch create file touch file name.file extension # rm delete command rm -i file name.file extension Ask whether to delete yes / no rm -f file name.The file suffix is deleted without asking rm -r file name.File suffix recursive delete folder delete all files and folders do not ask rm -ri file name.File suffix recursively delete folder delete all files ask whether to delete yes /no # clear screen clear # cat open view file cat file name.Suffix view current directory file cat File name 1.suffix > File name 2.Suffix opens file 1 and writes the contents of file 1 to file 2,If there is no file 2, create file 2,If there is content in file 2, the original content is overwritten # cp copy files to the specified folder cp file name.Suffix copied folder path # mv move files mv File move path # Tree relation tree tree Folder displays the relationship tree view of the folder # tar packaging command tar -c create package –x Release package -v Show command process –z Represents a compressed package tar –cvf benet.tar /home/benet hold/home/benet Catalog packaging tar –zcvf benet.tar.gz /mnt Package and compress the directory tar –zxvf benet.tar.gz File decompression and recovery of compressed package tar –jxvf benet.tar.bz2 decompression # make compilation make compile make install Install the compiled source package # apt command apt-cache search package Search package apt-cache show package Get package related information, such as description, size, version, etc sudo apt-get install package Installation package sudo apt-get install package - - reinstall Reinstall package sudo apt-get -f install Repair installation-f = –fix-missing" sudo apt-get remove package Delete package sudo apt-get remove package - - purge Delete package, including deleting configuration file, etc sudo apt-get update Update source sudo apt-get upgrade Update installed packages sudo apt-get dist-upgrade Upgrade system sudo apt-get dselect-upgrade use dselect upgrade apt-cache depends package Understanding usage dependencies apt-cache rdepends package Yes to view which packages the package depends on sudo apt-get build-dep package Install the relevant compilation environment apt-get source package Download the source code of the package sudo apt-get clean && sudo apt-get autoclean Clean up useless packages sudo apt-get check Check for damaged dependencies sudo apt-get clean Clean up all software caches (i.e. cache)/var/cache/apt/archives In the catalog deb (package) # View PCI devices lspci # View USB devices lsusb # View network card status sudo ethtool eth0 # View CPU Information cat /proc/cpuinfo # Display current hardware information lshw #Hard disk view partition of hard disk sudo fdisk -l
Reference address: https://www.jb51.net/os/Ubuntu/56362.html
JDK8 installation
apt installation
// Install jdk sudo apt install openjdk-8-jdk-headless // Verify that the installation was successful java -version javac java java -v
Compressed package installation
// After downloading and playing the compressed package, enter the compressed package directory and unzip it tar -zxvf jdk-8u121-linux-x64.tar.gz // Open the profile file and configure the environment variables sudo gedit /etc/profile // Add the following #set Java environment export JAVA_HOME=/Pathname/jdk1.8.0_56(The path is flexible. Can you understand it o(* ̄▽ ̄*)ブ) export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
14. Concepts and technical principles of Web Services, SOAP and REST (RESTful API)
relationship
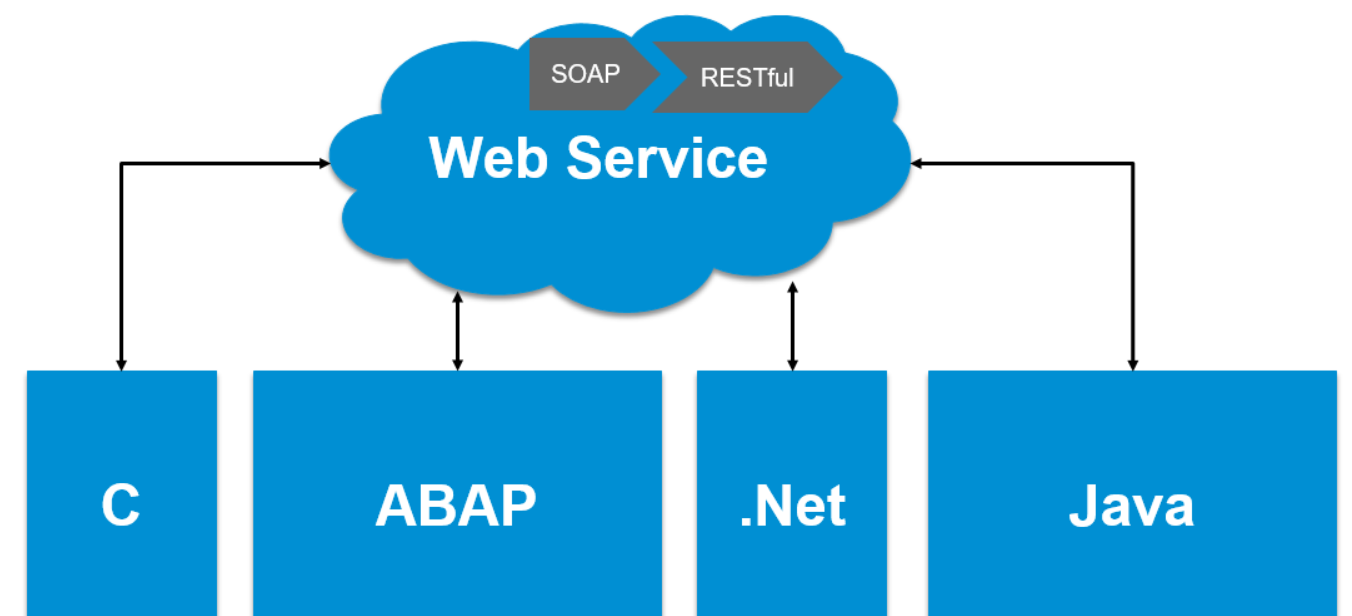
Web Service: a remote calling technology across programming languages and operating system platforms. It is well understood that web service can mainly realize the communication between different systems. Taking SAP system as an example, communication between two different SAP systems or between SAP system and other third-party systems (for example, applications on. Net or Java platform) can be realized through web service.
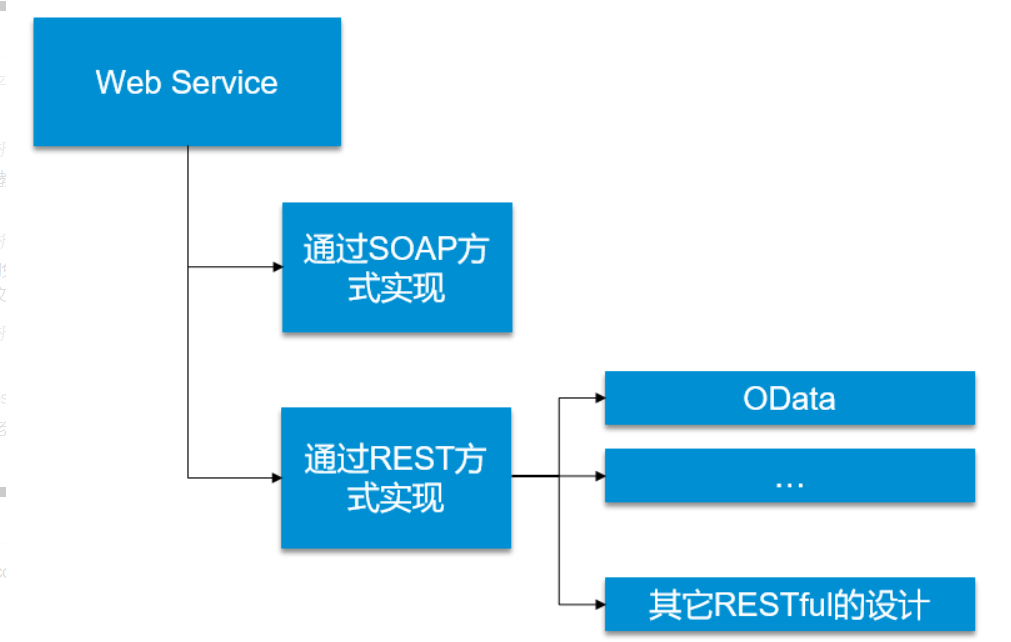
There are two ways to implement Web Service, one is SOAP protocol and the other is REST.
REST is a set of architectural constraints and principles that describe a way to access / use HTTP services. (if an architecture conforms to the constraints and principles of REST, we call it RESTful architecture.)
OData is an implementation of REST design style. OData and other Restful web services are that OData provides a unified way to describe data and data model. Therefore, OData is not a new communication technology, and OData also belongs to web service.
SOAP based Web Service
SOAP is a relatively complete implementation scheme of Web Service (WS).
In the Web Service implemented by SOAP, SOAP protocol and WSDL constitute the structural unit of Web Service.
SOAP is also known as "Simple Object Access Protocol". We know that Web Services send and receive data through HTTP protocol. Some specific HTTP message headers are added to the SOAP protocol to explain the content format of HTTP messages. The client can call the service located on the remote system through Web Service according to the format of SOAP.
WSDL is also known as "Web Service description language". Clients can understand the functions provided by this Web Service through WSDL, and describe the functions provided in the Web Service, the input parameters and return values of the functions. Concepts, application steps and basic operations of platform and Alibaba cloud platform
REST Web Service - OData
REST is also known as "Representational State Transfer". REST is a design style of HTTP services and describes a set of principles on how to design and access HTTP services.
Therefore, compared with SOAP, REST is not a protocol, but a design style with no mandatory binding force.
Different designers can design REST style web services according to their own actual projects and needs. It is precisely because of this "separate" web service implementation method that the performance and availability of REST style web services are usually better than those published according to SOAP, but because there are not many constraints on details, its unity is not as good as SOAP.
OData is an implementation of REST design style. OData and other Restful web services are that OData provides a unified way to describe data and data model.
Understanding reference https://segmentfault.com/a/1190000017777211
https://blog.csdn.net/nkGavinGuo/article/details/105225997
Technical principle
Web Service is also called XML Web Service. Web Service is a lightweight and independent communication technology that can receive requests from other systems on the Internet or Intranet. Yes: the software services provided on the web through SOAP are described with WSDL files and registered through UDDI. Web Service can use XML based SOAP to represent data and call requests, and transmit these data in XML format through HTTP protocol.
The biggest advantage of web service is to realize the interoperability between heterogeneous platforms, which is also one of the main reasons for using web service. Any two applications can communicate with each other as long as they can read and write XML.
1. Web service deployment is more convenient
2. The preparation of web service is similar to that of ordinary class
3. Of course, there is another advantage: platform independent. C #, ws written in Java can call each other
4. Make distributed system
XML: (Extensible Markup Language) extensible markup language. Short term oriented temporary data processing and World Wide Web oriented are the basis of Soap.
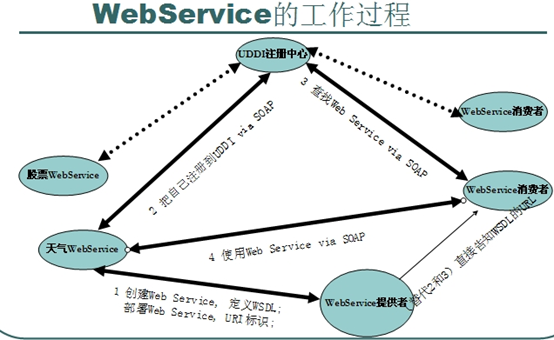
SOAP: (Simple Object Access Protocol) simple object access protocol. Is the communication protocol of XML Web Service. When the user finds your WSDL description document through UDDI, he can call one or more operations in the web service you established through SOAP. The underlying specification can be called in the form of HTTP(S) or different forms of SMTP (s).
WSDL: (Web service description language) a WSDL file is an XML document that describes a set of SOAP messages and how they are exchanged. In most cases, it is automatically generated and used by software.
UDDI (Universal Description, Discovery, and Integration) is a new project mainly aimed at Web service providers and consumers. Before users can call Web services, they must determine which business methods are included in the service, find the interface definition to be called, and prepare software on the server. UDDI is a mechanism to guide the system to find corresponding services according to the description documents. UDDI uses SOAP message mechanism (standard XML/HTTP) to publish, edit, browse and find registration information. It uses XML format to encapsulate various types of data, and sends it to the registry or the registry returns the required data.
15. Concepts, application steps and basic operations of AWS cloud platform and Alibaba cloud platform
AWS cloud platform
AWS, the full name of Amazon Web Service (Amazon Web Service), is a cloud computing service platform of Amazon, which provides a complete set of infrastructure and cloud solutions for customers in all countries and regions around the world.
AWS provides users with a complete set of cloud computing services including elastic computing, storage, database and Internet of things to help enterprises reduce IT investment and maintenance costs and go to the cloud easily
Conceptually, AWS provides a series of managed products to help us normally complete various requirements in software development without physical servers, which is what we often call cloud services.
Alibaba cloud platform
Alibaba cloud, the cloud computing brand of Alibaba group and the world's outstanding cloud computing technology and service provider, is Global Leading cloud computing and artificial intelligence science and technology company , committed to online public service of mode , provide security , reliable computing and data processing capabilities make computing and artificial intelligence inclusive science and technology.
AWS usage
aws registration
rails c
aws is known as the cloud platform with the most complete cloud services in the world, and its functions are also diverse. However, if new users want to use aws cloud server for free, they need visa foreign credit card, and domestic application may be troublesome.
Alibaba cloud usage
Ali cloud registered, registered in Alipay or other ways.
After registration, log in and enter the home page to see many services
rails c
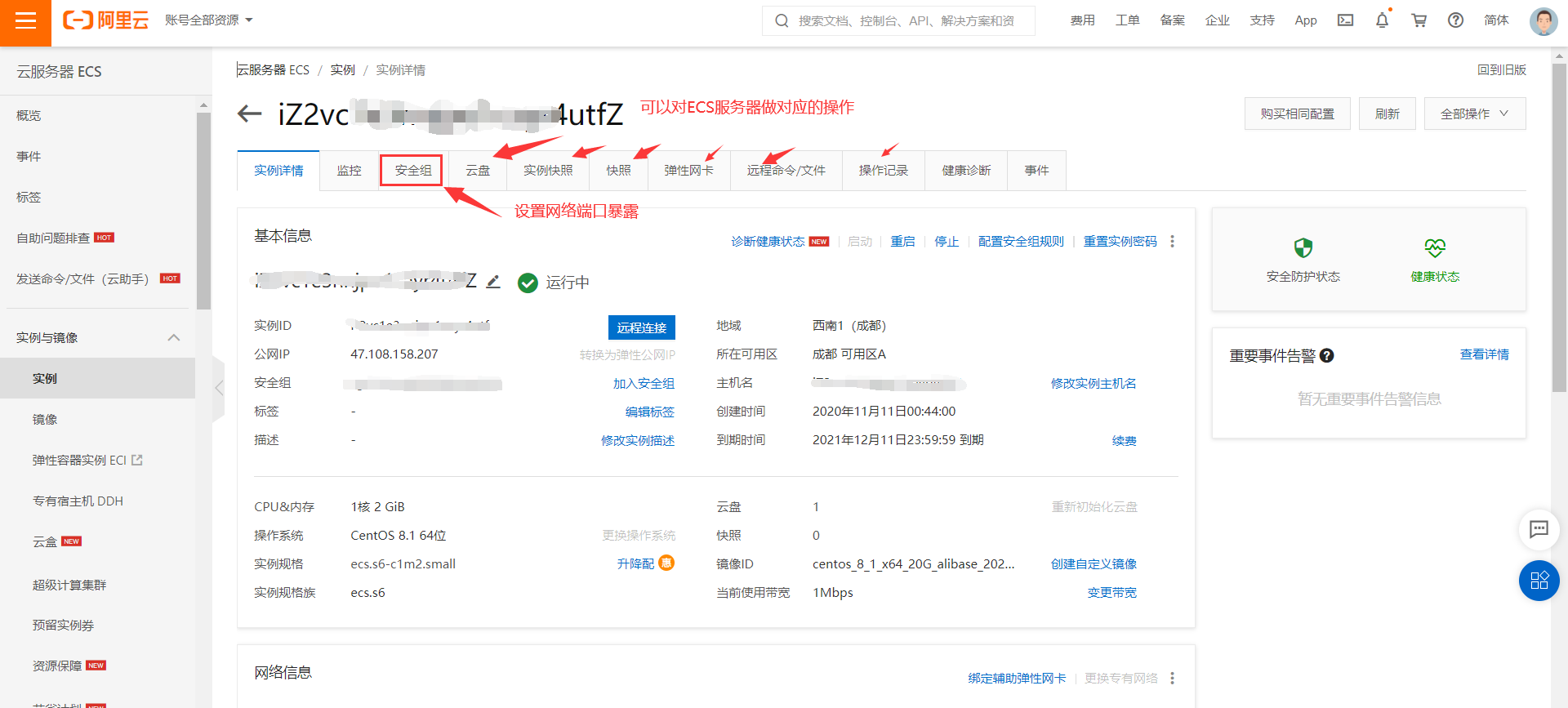
The console can be operated accordingly
16. Other basic technical concepts used in cloud applications, such as Queue, multiple identity authentication and so on.
Queue
Queue is the destination of message storage. Queue can be divided into ordinary queue and delay queue. If the message delay is not specified when sending a message, the message sent to the ordinary queue can be consumed immediately, while the message sent to the delay queue can be consumed only after the set delay time.
QueueURL
- Format: http: / / $accountid mns.< Region>. aliyuncs. com/queues/$QueueName.
- mns.< Region>. aliyuncs. COM: MNS access domain name. Region is the region where MNS is deployed. You can choose different regions according to your application needs.
- AccountId: the account ID of the queue owner.
- QueueName: queue name. The queue name of the same AccountId in the same region cannot be duplicate.
Reference address: https://help.aliyun.com/document_detail/27476.html
Multiple identity authentication
Concept: multiple authentication provides strong authentication through a series of simple authentication options, including telephone, SMS or mobile application notification. Users can choose the method according to their preferences.
Example: Azure multiple identity authentication
17. Classification of cloud services (IaaS, PaaS, SaaS), testing and selection criteria of cloud platforms
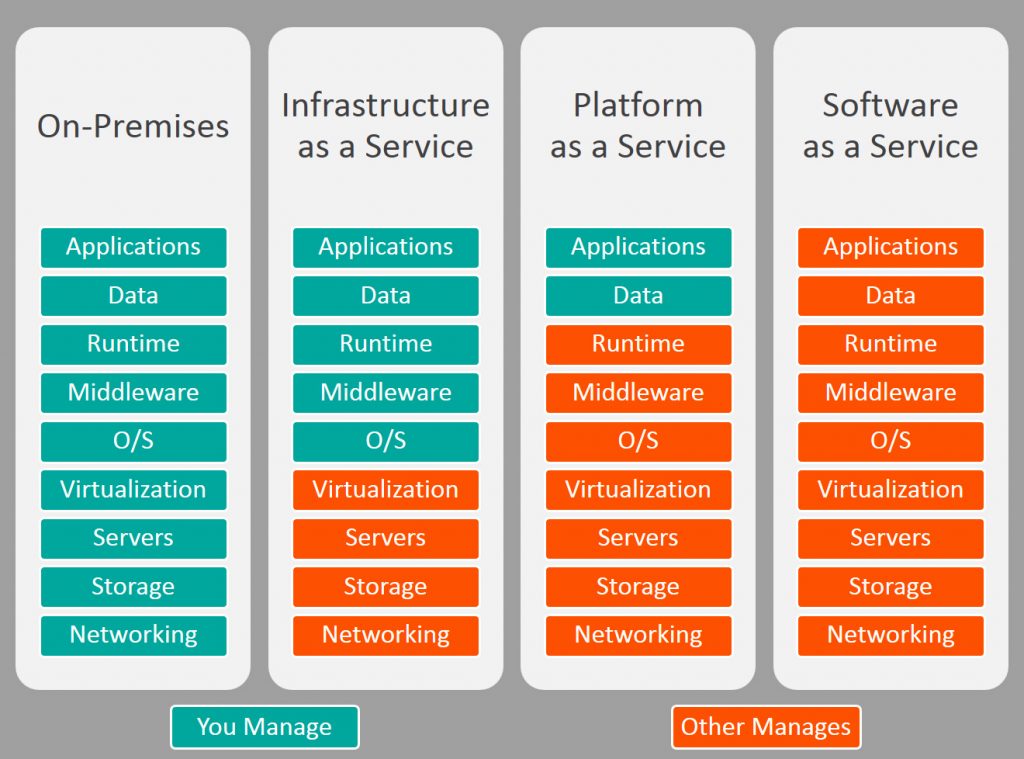
Cloud service classification
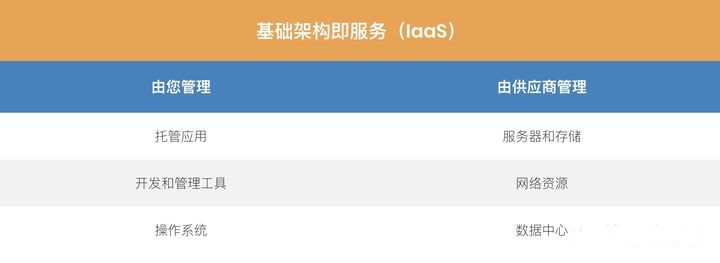
Cloud services are mainly divided into three categories: IAAs (infrastructure as a service), PAAS (platform as a service) and SaaS (software and services)
- Local IT infrastructure is like owning a car. When buying a car, you should be responsible for the maintenance of the car, and upgrading means buying a new car.
- IaaS is like renting a car. When you rent a car, you can choose the car you want and drive it as you like, but that car is not yours. Want to upgrade? Then rent a different car.
- PaaS is like taking a taxi. You don't have to drive a taxi yourself, just tell the driver you need to go to a place in the back seat to relax.
- SaaS is like going by bus. The bus has been allocated routes to share the journey with other passengers.
Software as a service (SaaS)
SaaS allows people to use cloud based Web applications.

In fact, e-mail services (such as Gmail and Hotmail) are examples of cloud based SaaS services. Other examples of SaaS services include office tools (Office 365 and Google Docs), customer relationship management software (Salesforce), event management software (Planning Pod), etc.
SaaS services are usually provided in a pay as you go (i.e. subscription) pricing model. All software and hardware are provided and managed by the supplier, so there is no need to install or configure anything. Once you have a login and password, you can start using the application.
Platform as a service (PaaS)
PaaS refers to a cloud platform that provides a runtime environment for developing, testing and managing applications.
With PaaS solution, software developers can deploy applications from simple to complex without all relevant infrastructure (server, database, operating system, development tools, etc.). Examples of PaaS services include Heroku and Google App Engine.
PaaS vendors provide a complete infrastructure for application development, while developers are responsible for the code.
Like SaaS, platform as a service solution provides a pay as you go pricing model.

Infrastructure as a service (IaaS)
IaaS is a cloud service that provides basic computing infrastructure: servers, storage and network resources. In other words, IaaS is a virtual data center.
IaaS services can be used for a variety of purposes, from hosting websites to analyzing big data. Customers can install and use any operating system and tools they like on the infrastructure they get. IaaS's main providers include Amazon Web Services, Microsoft Azure and Google Compute Engine.
Like SaaS and PaaS, IaaS services can be used for a fee on demand.
As you can see, each cloud service (IaaS, PaaS and SaaS) is tailored to the business needs of its target audience. From a technical point of view, IaaS can provide you with the greatest control, but requires extensive expertise to manage the computing infrastructure, while SaaS allows you to use cloud based applications without managing the infrastructure. Therefore, cloud services can be described as pyramids:
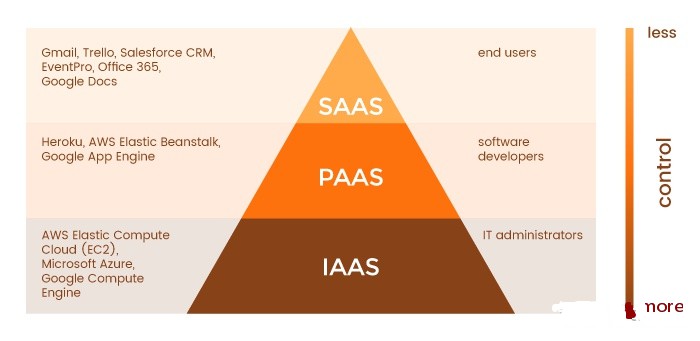
Reference
Cloud application development technology https://cloudappdev.netlify.app/book/content.html
Relationship among web service, soap, rest and OData https://blog.csdn.net/nkGavinGuo/article/details/105225997
Zhihu cloud service classification https://zhuanlan.zhihu.com/p/357877662