Welcome to pay attention "Python black technology" series , continuously updating
Welcome to pay attention "Python black technology" series , continuously updating
Realization effect
Crawling content
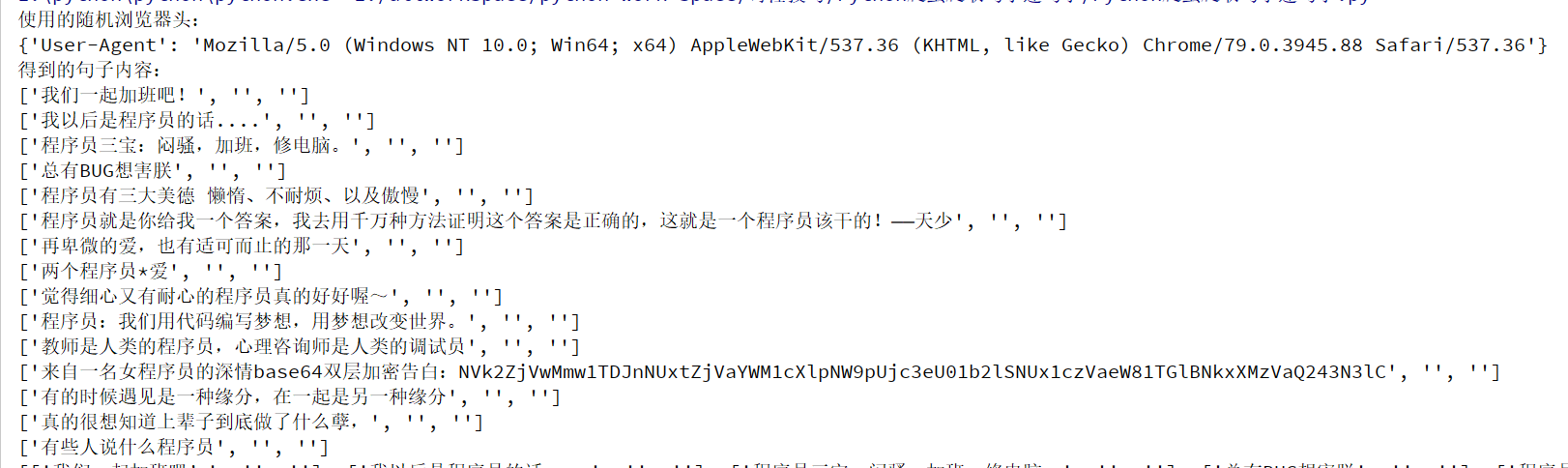
csv file obtained
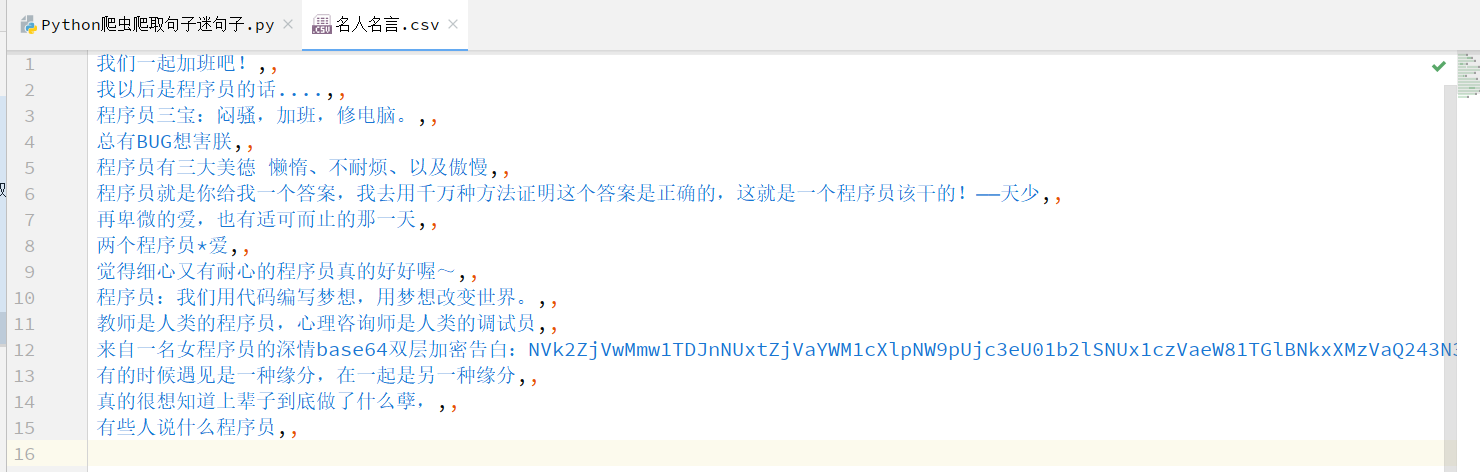
Realization idea
- Import related libraries used
- Analyze and get the url of crawling keywords
- Get a random user_agent (use of headers)
- Visit the web page and crawl the sentence - the author of the sentence - the source of the sentence, and encapsulate these three contents into a two-tier list
- Save the list in csv file and persist it
Import related libraries used
import requests from lxml import etree import csv import random
Analyze and get the url of crawling keywords
We search keyword programmers
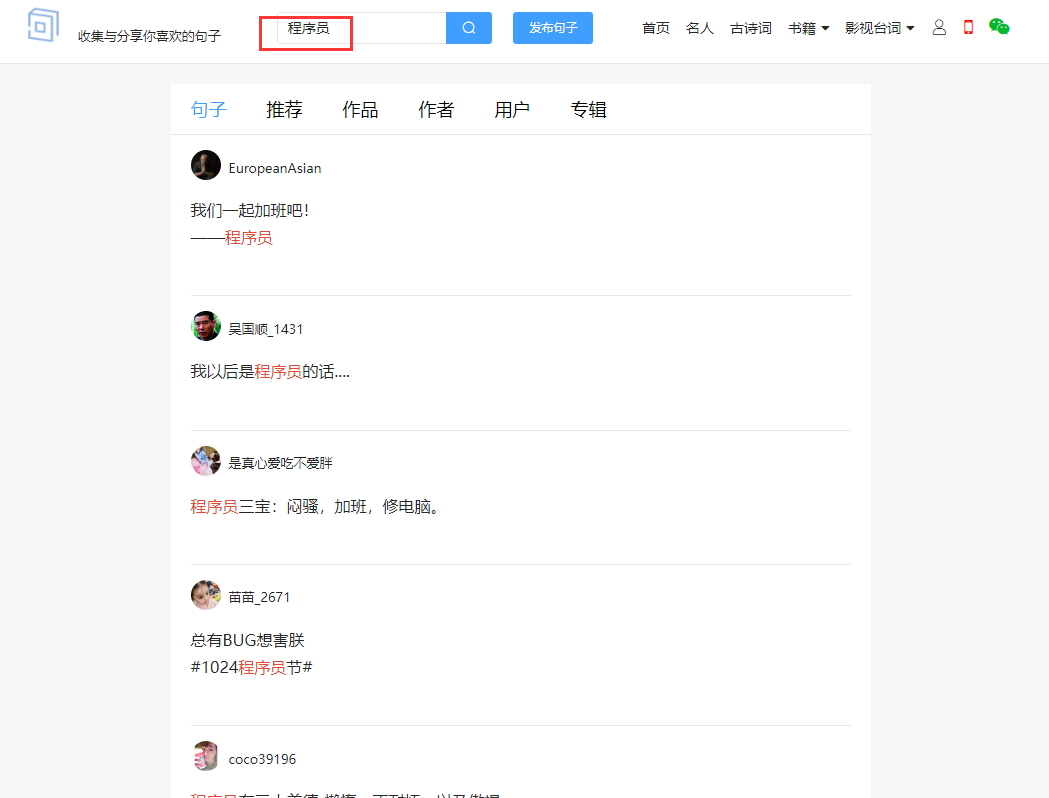
The url obtained is https://www.juzikong.com/s?q= programmer

Try several other keywords. When you know that q = has been modified, the programmer will search for other keywords and find the crawler key of this keyword after analysis
Because of the coding problem, the programmer converted three words into% E7%A8%8B%E5%BA%8F%E5%91%98
#https://www.juzikong.com/s?q= programmer #Because the url code needs to be changed, if you copy and paste it from the browser, it will automatically become the following result - > url = "https://www.juzikong.com/s?q=%E7%A8%8B%E5%BA%8F%E5%91%98"
Get a random user_agent (introducing random headers to reverse crawl)
See another blog post for details:
# Get a random request header
def get_random_user_agent():
user_agent = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5",
"Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"MQQBrowser/26 Mozilla/5.0 (Linux; U; Android 2.3.7; zh-cn; MB200 Build/GRJ22; CyanogenMod-7) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1",
"Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10",
"Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13",
"Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+",
"Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0",
"Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)",
"UCWEB7.0.2.37/28/999",
"NOKIA5700/ UCWEB7.0.2.37/28/999",
"Openwave/ UCWEB7.0.2.37/28/999",
"Mozilla/4.0 (compatible; MSIE 6.0; ) Opera/UCWEB7.0.2.37/28/999",
# iPhone 6:
"Mozilla/6.0 (iPhone; CPU iPhone OS 8_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/8.0 Mobile/10A5376e Safari/8536.25",
]
return random.choice(user_agent)
# headers use
headers = {'User-Agent': get_random_user_agent()}
Visit the web page and crawl the sentence - the author of the sentence - the source of the sentence, and encapsulate these three contents into a two-tier list
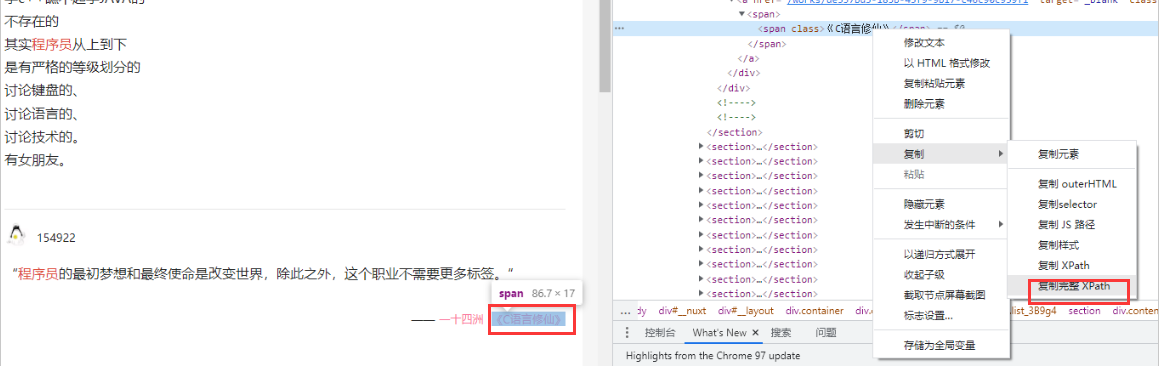
Right click Google browser to check the xpth of the content to be crawled
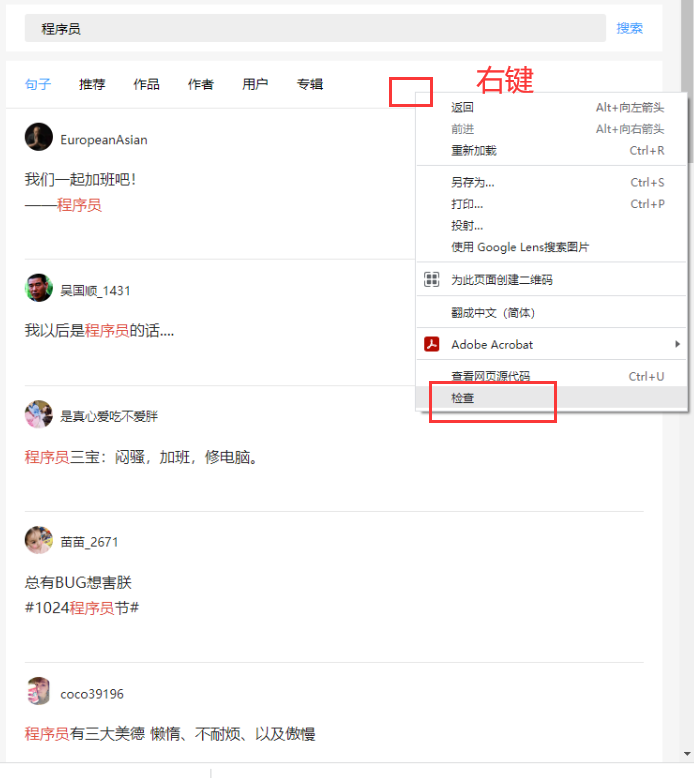
Copy full xpth
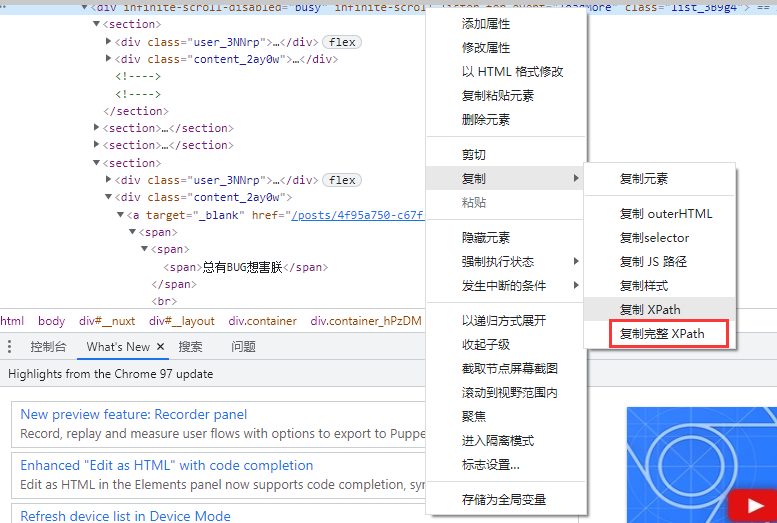
Overall area xpth/html/body/div/div/div/div[3]/main/div[2]
#First get each individual of the whole famous saying to be crawled, and then iterate the message, author and source of each sentence
queto_list = html.xpath('/html/body/div/div/div/div[3]/main/div[2]/section')
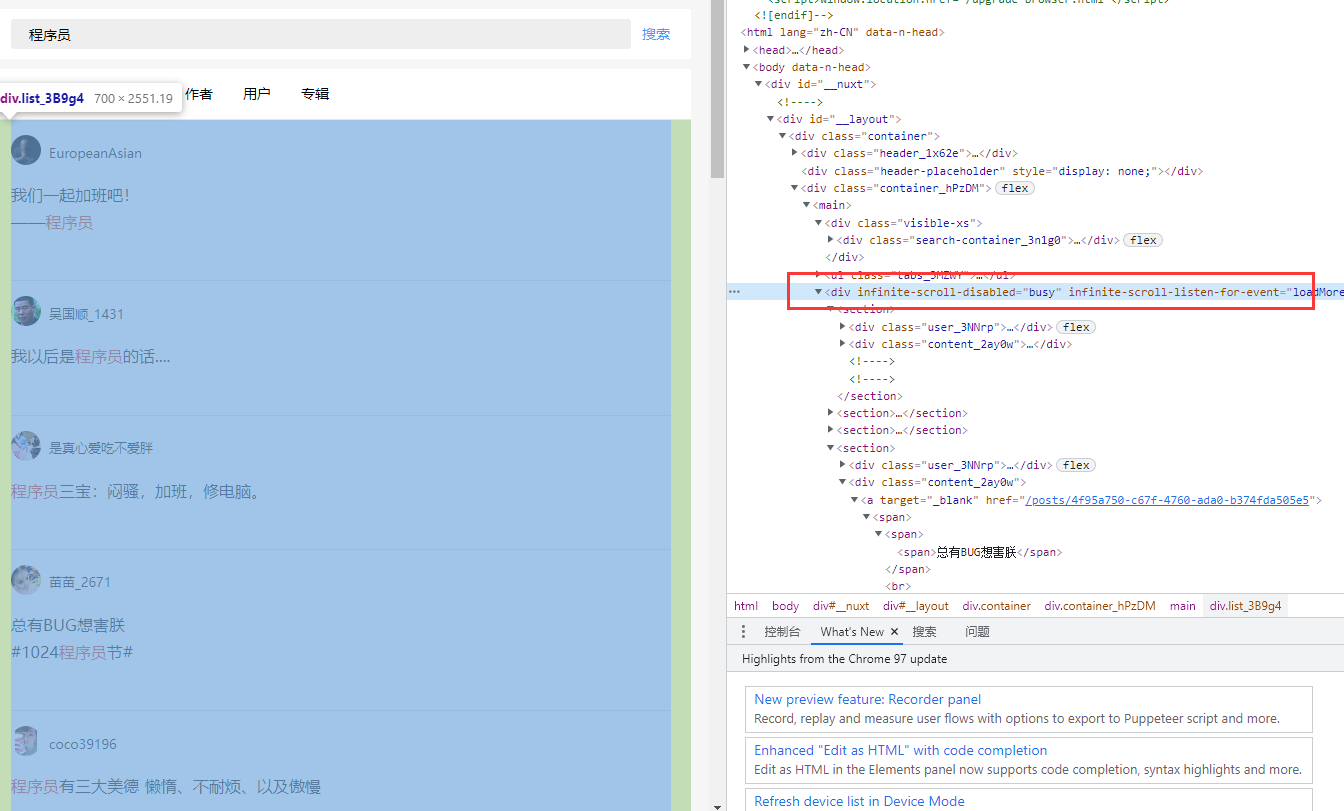
Sentence content xpth /html/body/div[1]/div/div/div[3]/main/div[2]/section[1]/div[2]/a/span[1]/span/span
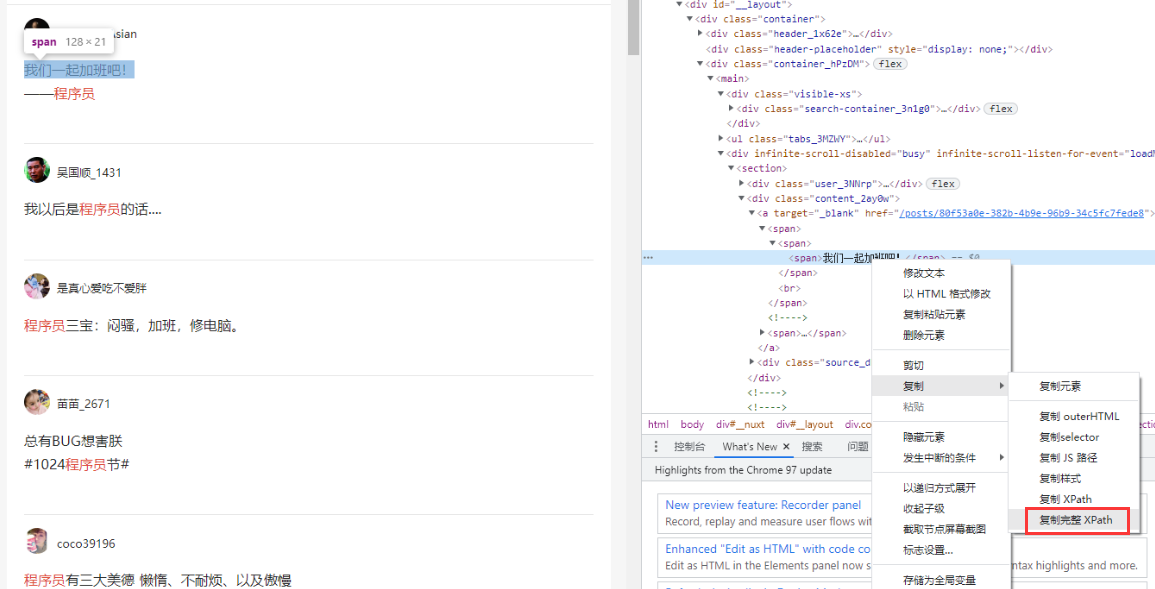
Author content xpth /html/body/div[1]/div/div/div[3]/main/div[2]/section[16]/div[2]/div/span/a/span/span
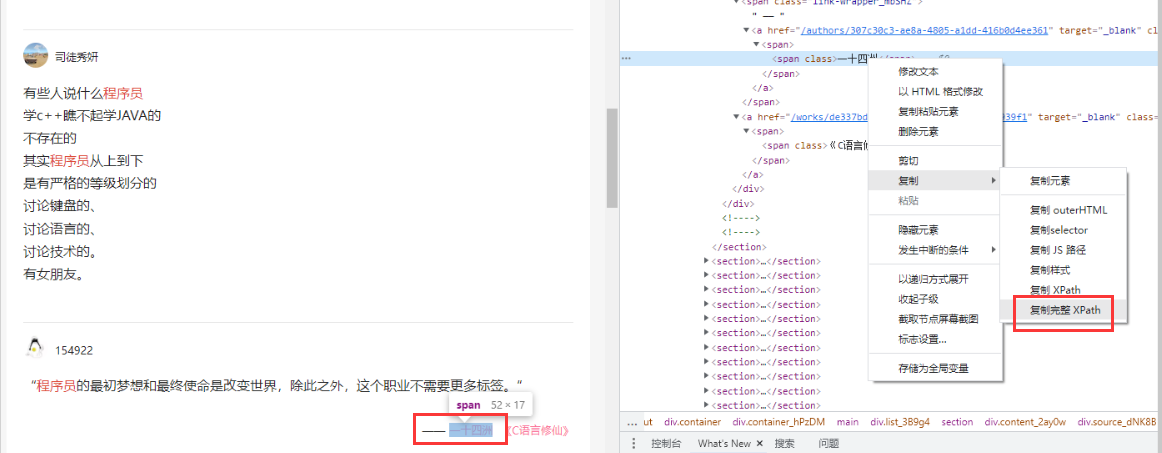
Source content xpth /html/body/div[1]/div/div/div[3]/main/div[2]/section[16]/div[2]/div/a/span/span
This time we will get
# First obtain the whole of the famous saying to be crawled, and then obtain the message, author and source of each famous saying under the whole
queto_list = html.xpath('/html/body/div/div/div/div[3]/main/div[2]/section')
lists = []
print("Sentence content obtained:")
for queto in queto_list:
# Famous quote text / section[1]/div[2]/a/span[1]/span/span
message = queto.xpath('./div[2]/a/span[1]/span/span/text()')
# Author / section[16]/div[2]/div/span/a/span/span not necessarily every sentence has an author
authuor = queto.xpath('./div[2]/div/span/a/span/span/text()')
# Provenance / section[16] / div[2] / div / a / span / span not necessarily every sentence has a provenance
source = queto.xpath('./div[2] / div / a / span / span/text()')
# Add the data into the list and save it
lists.append(message)
lists.append(authuor)
lists.append(source)
But you will find that because of the search for keywords, this website divides the content of our programmers' keywords, so we have to turn the message list into a string, for example:
['I will be', 'programmer', 'Words....']Should be transformed into['If I'm a programmer in the future....']

After modification
# First obtain the whole of the famous saying to be crawled, and then obtain the message, author and source of each famous saying under the whole
queto_list = html.xpath('/html/body/div/div/div/div[3]/main/div[2]/section')
lists = []
print("Sentence content obtained:")
for queto in queto_list:
# Famous quote text / section[1]/div[2]/a/span[1]/span/span
message = queto.xpath('./div[2]/a/span[1]/span/span/text()')
# Author / section[16]/div[2]/div/span/a/span/span not necessarily every sentence has an author
authuor = queto.xpath('./div[2]/div/span/a/span/span/text()')
# Provenance / section[16] / div[2] / div / a / span / span not necessarily every sentence has a provenance
source = queto.xpath('./div[2] / div / a / span / span/text()')
# Add the data into the list and save it
this_list = []
str_message = ''.join(message)
this_list.append(str_message)
str_authuor = ''.join(authuor)
this_list.append(str_authuor)
str_source = ''.join(source)
this_list.append(str_source)
# print(this_list)#Print all the information in this sentence
lists.append(this_list)
#Test output saved data
print(lists)

Save the list into csv file and persist it
with open("./Famous quotes.csv", 'w', encoding='utf-8', newline='\n') as f:
writer = csv.writer(f)
for i in lists:
writer.writerow(i)
Implementation code
Complete implementation code, ready to use
# @Time : 2022/2/1 17:45
# @Author: Nanli
# @FileName: Python crawler crawls sentences py
import requests
from lxml import etree
import csv
import random
# https://www.juzikong.com/s?q= programmer
# Because the url code needs to be changed, you should copy the following results. The three words of the programmer are transformed into% E7%A8%8B%E5%BA%8F%E5%91%98
url = "https://www.juzikong.com/s?q=%E7%A8%8B%E5%BA%8F%E5%91%98"
# Get a random request header
def get_random_user_agent():
user_agent = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
]
return random.choice(user_agent)
# headers use
headers = {'User-Agent': get_random_user_agent()}
print("Random browser header used:")
print(headers)
get_request = requests.get(url=url, headers=headers).text
# html: the html content of the crawled web page
html = etree.HTML(get_request)
# First obtain the whole of the famous saying to be crawled, and then obtain the message, author and source of each famous saying under the whole
queto_list = html.xpath('/html/body/div/div/div/div[3]/main/div[2]/section')
lists = []
print("Sentence content obtained:")
for queto in queto_list:
# Famous quote text / section[1]/div[2]/a/span[1]/span/span
message = queto.xpath('./div[2]/a/span[1]/span/span/text()')
# Author / section[16]/div[2]/div/span/a/span/span not necessarily every sentence has an author
authuor = queto.xpath('./div[2]/div/span/a/span/span/text()')
# Provenance / section[16] / div[2] / div / a / span / span not necessarily every sentence has a provenance
source = queto.xpath('./div[2] / div / a / span / span/text()')
# Add the data into the list and save it
this_list = []
str_message = ''.join(message)
this_list.append(str_message)
str_authuor = ''.join(authuor)
this_list.append(str_authuor)
str_source = ''.join(source)
this_list.append(str_source)
# print(this_list)#Print all the information in this sentence
lists.append(this_list)
# Test output saved data
print(lists)
with open("./Famous quotes.csv", 'w', encoding='utf-8', newline='\n') as f:
writer = csv.writer(f)
for i in lists:
writer.writerow(i)
summary
If you like, give me a 👍, Pay attention! Share more interesting Python black technology!
Copyright notice:
If you find that you are far away from the @mzh original work, you must mark the original link for reprint
Copyright 2022 mzh
Crated: 2022-2-1
Welcome to pay attention "Python black technology" series , continuously updating
Welcome to pay attention "Python black technology" series , continuously updating
[Python installs a third-party library with a one-line command to permanently increase the speed]
[package exe with PyInstaller]
[one click download of Zhihu article pictures without login crawler (nanny graphic + implementation code)]
[lonely programmers chat with AI robot friends to relieve boredom (free interface + nanny level graphics + implementation code comments)]
[draw gif dynamic diagram with a few lines of code (nanny level picture and text + implementation code)]
[several lines of code to realize regular and cyclic screenshots of online class and save important knowledge points (nanny level graphics and text + implementation code)]
[common user_agent browser head crawler simulates users (nanny level graphics + implementation code)]
[more details]