1: Collection overview
What is the difference between a set and an array?
Array is also a data structure in java. The length of data is fixed and the storage mode is linear. And it can store basic data types and objects. Basic data objects can be processed and stored according to the packing of basic types. Our array is of reference data type.
Collection is another data i structure in java, which is more flexible than array. In terms of implementation methods, the collection has various implementation methods and a wide range of applications. The array adopts the way of continuous space allocation and storage.
In addition, the set adopts the form of class and interface, which has the three characteristics of java object-oriented. The comparison array more clearly reflects the object-oriented logical thinking.
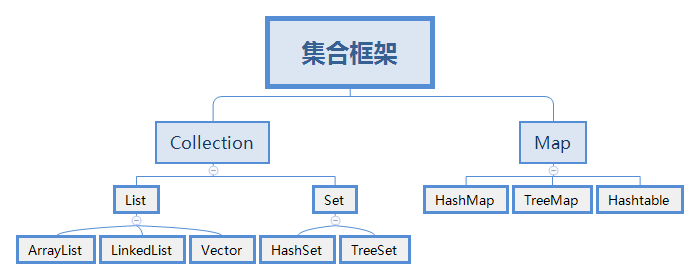
Collections in java are divided into single column collections and double column collections. Collection is the top-level interface of single column collections and Map is the top-level interface of double column collections. In terms of basic storage, the data stored in a single column only contains the data itself, while the double column contains keys and values, that is, the double column stores not only the data itself, but also the corresponding index. This article mainly introduces the single column collection and some of its sub interfaces.
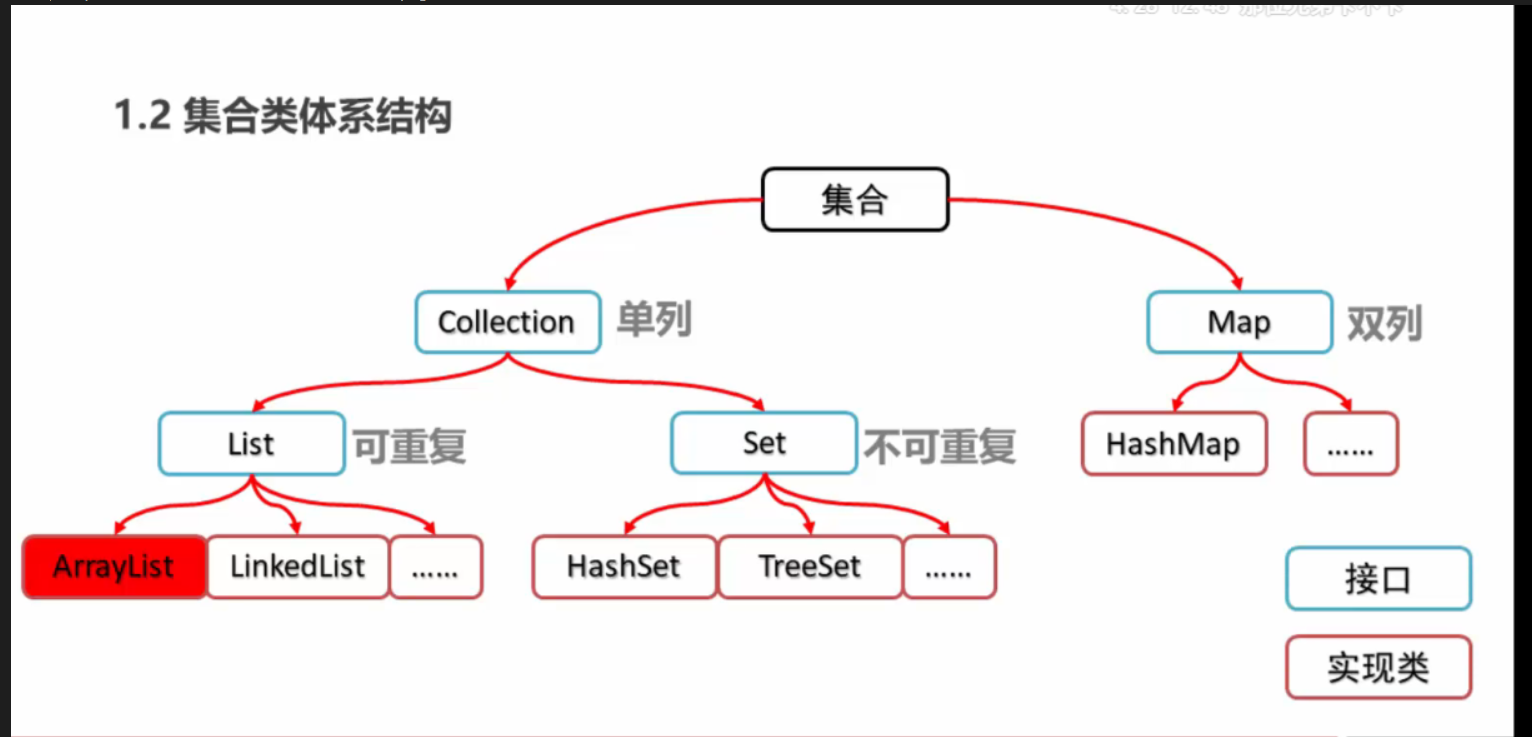
Generally, we will learn these two basic lists and sets, but in fact, there is another one. This article describes all three interface implementation classes of Collection.
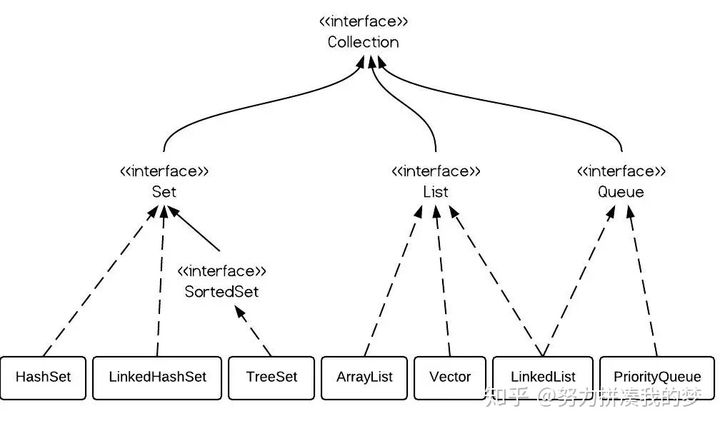
2: Collection resolution
Our JDK API outlines Collection in this way.
The root interface in the collection hierarchy. A collection represents a Set of objects, which are also called elements of a collection. Some elements of collection are not allowed to be repeated, while others are not allowed. Some collections are ordered, while others are disordered. JDK does not provide any direct implementation of this interface: it provides more specific implementation of sub interfaces (such as Set and List). This interface is typically used to pass collections and manipulate them where the greatest universality is required.
A bag or multiset (an unordered collection that may contain duplicate elements) should implement this interface directly.
All general Collection implementation classes (usually indirectly implement Collection through one of its sub interfaces) should provide two "standard" construction methods: one is void (no parameter) construction method, which is used to create an empty Collection; The other is a construction method with a single parameter of Collection type, which is used to create a new Collection with the same elements as its parameters. In fact, the latter allows users to copy any Collection to generate an equivalent Collection of the desired implementation type. Although this Convention cannot be enforced (because interfaces cannot contain constructors), all common Collection implementations in the Java platform library comply with it.
**
Its specific implementation interface classes, set and list, are mentioned here.
In addition, the document also professionally explains the following points that need to be paid attention to
Many methods in the Collections Framework interface are defined based on the equals method. For example, the specification of the contains(Object o) method declares: "if and only if this collection contains at least one (onull? Enull) 😮. "equals(e)), returns true." This specification should not be interpreted as implying a call to a collection with a non null parameter o The contains method causes the o.equals(e) method to be called for any e element. You can optimize various implementations at will, as long as you avoid calling equals, for example, by first comparing the hash codes of two elements. (the Object.hashCode() specification guarantees that two objects with unequal hash codes will not be equal). More commonly, the implementation of various Collections Framework interfaces can arbitrarily use the specified behavior of the underlying Object method, regardless of whether the implementation program thinks it is appropriate or not.
It is embodied in its implementation interface class, which will be described in detail later in the article
The Collection itself provides some of its own methods
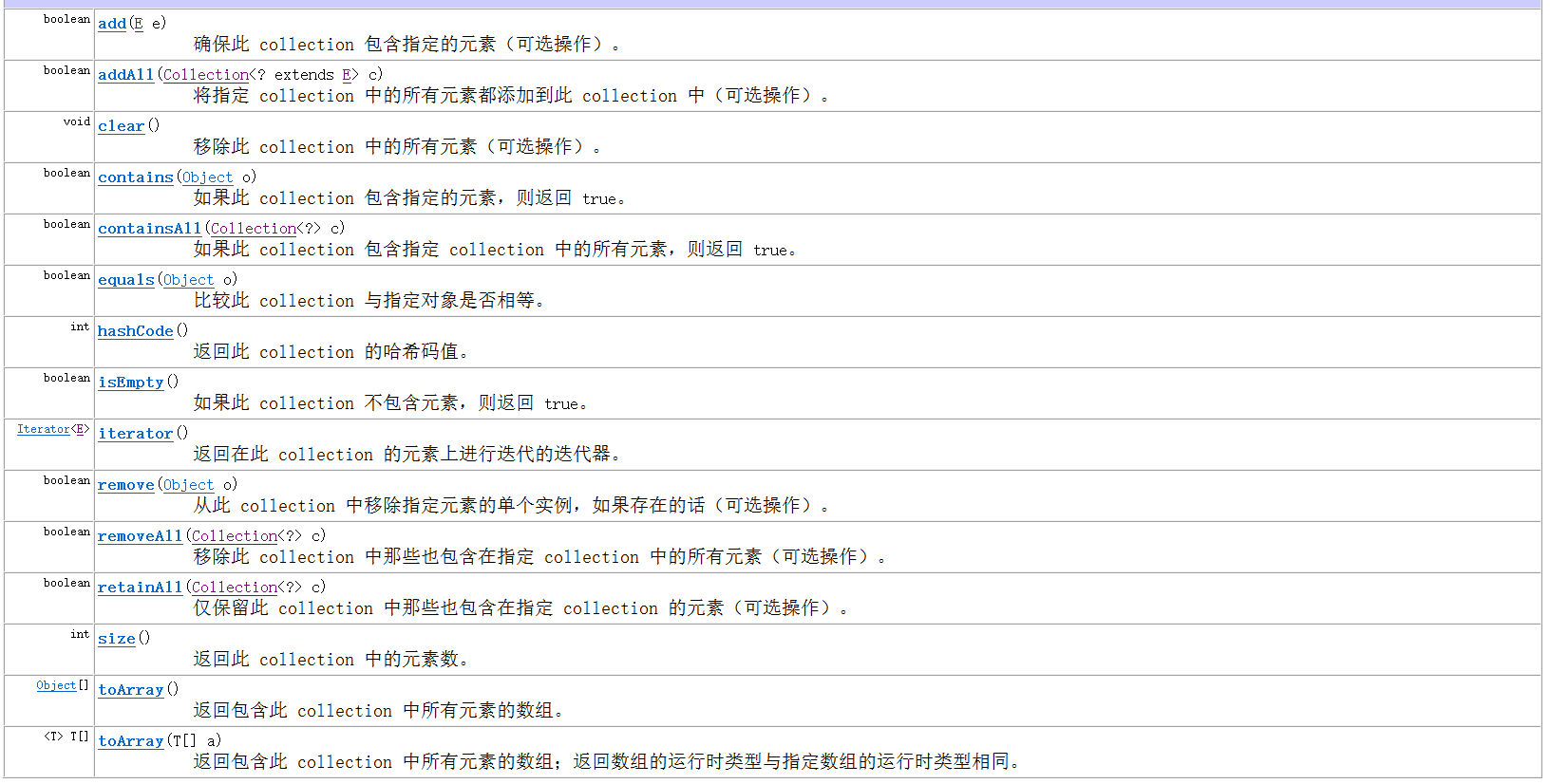
Extract common methods
1. Add function
boolean add(E e)
Add an element
boolean addAll(Collection c)
Add a batch of elements
2. Delete function
boolean remove(Object o)
Delete an element
3. Judgment function
boolean contains(Object o)
Determines whether the collection contains the specified element
boolean isEmpty()
Judge whether the set is empty(There are no elements in the collection)
4. Get function
int size()
Gets the length of the collection
5. Conversion function
Object[] toArray()
Convert a set to an array
3: List collection
List set is a kind of single column set, and its stored elements can be repeated. List is a method that directly implements the Collection interface class. The complete list interface class is defined as follows.
public interface List<E>extends Collection<E>
E refers to generics, which describe class properties.
Unlike set s, lists usually allow duplicate elements. More specifically, the list usually allows e1 The element pairs of equals (e2) are e1 and e2, and they usually allow multiple null elements if the list itself allows null elements.
The List interface adds some other conventions to the agreements of iterator, add, remove, equals and hashCode methods, which exceed the conventions specified in the Collection interface. For convenience, declarations of other inheritance methods are also included.
The List interface provides four access methods for locating (indexing) List elements. Lists (like Java arrays) are based on 0. Note that these operations may be performed in a time proportional to the index value of some implementations, such as the LinkedList class. Therefore, if the caller does not know the implementation, iterating over List elements is usually better than traversing the List with an index.
The List interface provides a special Iterator called ListIterator. In addition to the normal operation provided by the Iterator interface, the Iterator also allows element insertion and replacement, as well as two-way access. A method is also provided to get a List Iterator starting at a specified location in the List.
The List interface provides two methods to efficiently insert and remove multiple elements anywhere in the List.
Since it is an interface, it is necessary to implement classes. We usually need to know two kinds: ArrayList and LinkedList.
1: Implementation class ArrayList
<1> Method description
Note that ArrayList only implements List, but does not inherit the List interface
public class ArrayList<E>extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, Serializable
It can be seen that ArrayList inherits from AbstractList, and then we look at the class definition of AbstractList
Querying the JDK API description, we can see the complete definition of AbstractList
public abstract class AbstractList<E>extends AbstractCollection<E>implements List<E>
Trace the source
public abstract class AbstractCollection<E>extends Object implements Collection<E>
You can understand the root of an Object if you don't have any questions.
ArrayList data structure is array. Through the characteristics of array, we can understand that the query of array is relatively fast, but the addition and deletion is relatively slow.
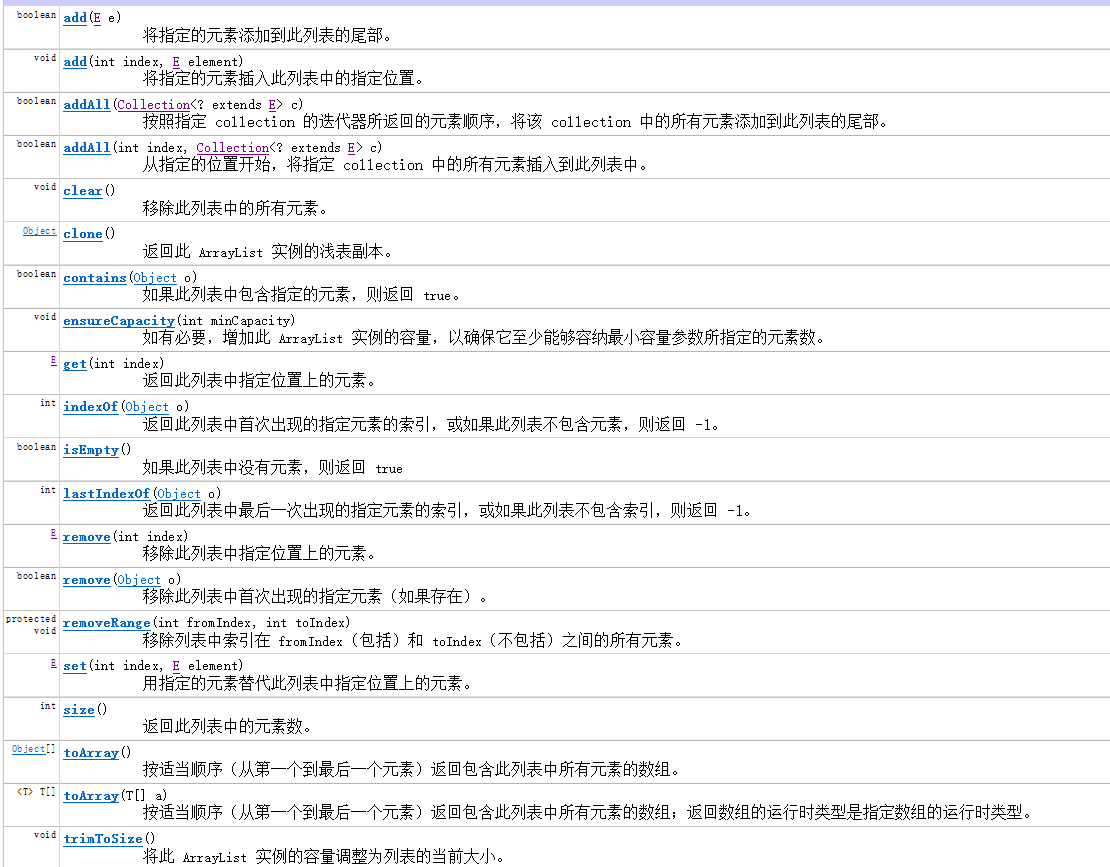
Let's look at some common methods of ArrayList.

Most methods were tested
//1: Adds the specified element to the end of this list.
List l = new ArrayList<>();
//ArrayList L = new ArrayList<>();
l.add("Hello");//Only one element can be inserted at a time
System.out.println(l);
// 2: add(int index, E element)
l.add(0,"jgdabc");
System.out.println(l);
ArrayList l1 = new ArrayList<>();
l1.add("jgdabc01");
l1.add(20);
System.out.println(l1);
//3:add() method, the entire collection is added
l.add(l1);
l.addAll(1,l1);
System.out.println(l);
//4:addAll(Collection<? extends E> c)
l.addAll(l1);
System.out.println(l);
//5:addAll(int index, Collection<? extends E> c)
//Inserts all elements in the specified collection into this list, starting at the specified location.
l.add(1,l1);
System.out.println(l);
//6:clear()
//Remove all elements from this list.
l.clear();
System.out.println(l);
//7:contains(Object o)
//Returns true if the list contains the specified element.
boolean flag = l1.contains("jgdabc");
System.out.println(flag);
//8:get(int index)
//Returns the element at the specified location in this list. If the collection is empty, an exception will be reported.
l.add("jgdabc");
String s = (String) l.get(0);
System.out.println(s);
//9: indexOf(Object o)
//Returns the index of the specified element that first appears in this list, or - 1 if the list does not contain an element.
int x = l.indexOf("jgdabc");
System.out.println(x);
//10:isEmpty()
//Returns true if there are no elements in this list
boolean flag_1 = l.isEmpty();
System.out.println(flag_1);
//11:lastIndexOf(Object o)
//Returns the index of the last occurrence of the specified element in this list, or - 1 if the list does not contain an index.
int flag_2 = l.lastIndexOf("jgdabc");
System.out.println(flag_2);
//12:remove(int index)
l.remove(0);
System.out.println(l);
//13:removeRange(int fromIndex, int toIndex)
//Remove all elements in the list whose indexes are between fromIndex (included) and toIndex (excluded).
// The removehange() method is protected and is only available for subclasses
l.add("jgdabc");
l.add("jgdabc01");
ArrayList ll = new ArrayList<>();
ArrayList ll2 = ll;
//14:set(int index, E element)
//Replaces the element at the specified location in this list with the specified element.
l.set(0, "zhan");
System.out.println(l);
// 15:toArray()
//Returns an array containing all the elements in this list in the appropriate order (from the first to the last element)
l.toArray();
System.out.println(l);
// 17:trimToSize()
//Adjust the capacity of this ArrayList instance to the current size of the list.
((ArrayList<Object>) l).trimToSize();
System.out.println(l.size());
Note that there are two methods, one is removehange (). Although this method is provided in ArrayList, it is protected and can only be used by subclasses. That is to write an inheritance class.
There is another method that may not be commonly used. In fact, it involves optimization. That's the trimToSize() method
The interior of ArrayList uses array to store elements. When the array will be full, a new array will be created, and its capacity is 1.5 times that of the current array.
At the same time, all elements will be moved to the new array. Assuming that the internal array is full, and we now add another element, the capacity of ArrayList will expand in the same proportion (i.e. 1.5 times that of the previous array).
In this case, there will be some unallocated space in the internal array.
At this time, the trimToSize() method can delete the unallocated space and change the capacity of the ArrayList to equal the number of elements in the ArrayList.
<2> Concurrent modification exception
Let's start with a code
package java_practice;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListDemo {
public static void main(String args[]) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("java");
Iterator<String> it = list.iterator();
while(it.hasNext()) {
String s = it.next();
if(s.equals("world"))
{
list.add("javaee");
}
}
// for(int i=0;i<list.size();i++)
// {
// String s = list.get(i);
// if(s.equals("world"))
// {
// list.add("javaee");
// }
//
// }
System.out.println(list);
}
}

Obviously, why did you throw an exception here?
The following is an excerpt of the abnormal information
Exception in thread "main" java.util.ConcurrentModificationException at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:907) at java.util.ArrayList$Itr.next(ArrayList.java:857) at java_practice.ListDemo.main(ListDemo.java:16)
We follow up the source code step by step according to checkForComodification
The following is the key source code information after follow-up and traceability
public interface List<E>{
Iterator<E> iterator();
boolean add(E e)
}
public abstract class AbstractList<E>
{
protected transient int modCount = 0;
}
public class ArrayList<E> extends AbstractList<E>implements List<E>
{
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!// Each call to add() causes modcount++
elementData[size++] = e;
return true;
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int expectedModCount = modCount;
//modCount is the number of times the collection was actually modified
//expectedModCount is the number of times the collection is expected to be modified
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
final void checkForComodification() {
if (modCount != expectedModCount)
//modCount is the number of times the set is modified, and exceptedModCount is the number of times the set is expected to be modified
throw new ConcurrentModificationException();
}
}
/**
}
The source code is very clear, and I have made some comments, which can be stroked by myself. The reason is that when we use the iterator, the iterator will have an expected number of iterations. If we call the add() method while iterating, it will modCount + + (actual number of iterations), but the expectedModCount (expected number of iterations) is not synchronized, resulting in inconsistent data, which is also explained in the source code, If not, an exception will be thrown.
Propose a solution to avoid data inconsistency, such as for loop.
package java_practice;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class ListDemo {
public static void main(String args[]) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("java");
Iterator<String> it = list.iterator();
// while(it.hasNext()) {
// String s = it.next();
// if(s.equals("world"))
// {
// list.add("javaee");
// }
//
//}
for(int i=0;i<list.size();i++)
{
String s = list.get(i);
if(s.equals("world"))
{
list.add("javaee");
}
}
System.out.println(list);
}
}

Maybe you have a question here. Don't you also have add() on both sides of get()? Why not report exceptions. The above source code is also extracted. The reason is that we call the add () method of the set, which will actually increase the actual number of iterations by one, but there is no actual and expected judgment in the get () function, and naturally no exception will be thrown. You can refer to the appeal source code for clarity.
<3> Listiterator (list iterator)
List collection specific iterators
Complete definition of interface
public interface ListIterator<E>extends Iterator<E>
JDK API description
The series table iterator allows the programmer to traverse the list in any direction, modify the list during iteration, and obtain the current position of the iterator in the list.
Demonstrate a use
package java_practice;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.ListIterator;
public class ListDemo {
public static void main(String args[]) {
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("java");
Iterator<String> it = list.iterator();
// while(it.hasNext()) {
// String s = it.next();
// if(s.equals("world"))
// {
// list.add("javaee");
// }
//
//}
//
ListIterator<String> lit = list.listIterator();
while(lit.hasNext())
{
String s = lit.next();
if(s.equals("world"))
{
lit.add("javaee");
}
}
System.out.println(list);
}
}

One question is why the ListIterator does not report an exception?
We still trace the source code and finally sort it out as follows
public interface List<E>{
Iterator<E> iterator();
ListIterator<E> listIterator();
boolean add(E e)
}
public abstract class AbstractList<E>
{
protected transient int modCount = 0;
}
public class ArrayList<E> extends AbstractList<E>implements List<E>
{
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!// Each call to add() causes modcount++
elementData[size++] = e;
return true;
}
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
public ListIterator<E> listIterator() {
return new ListItr(0);
}
}
private class ListItr extends Itr implements ListIterator<E> {
ListItr(int index) {
super();
cursor = index;
}
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
@SuppressWarnings("unchecked")
public E previous() {
checkForComodification();
int i = cursor - 1;
if (i < 0)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i;
return (E) elementData[lastRet = i];
}
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
public void add(E e) {
checkForComodification();
try {
int i = cursor;
ArrayList.this.add(i, e);
cursor = i + 1;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
}
The root cause of the prosecution is the add() method of ListItr. Through the source code analysis, we can see that the add() method here will re assign the expected variable after use, so it will unify the expectation and the actual, so there will be no exceptions.
<4> Enhanced for loop
Or find data from JDK API and start from Collection
public interface Collection<E>extends Iterable<E>
Retroactive Iterable, reasonable.
public interface Iterable<T>Implementing this interface allows objects to become "foreach" The target of the statement.
And Iterable gives its available iterators
Iterator iterator()
Returns an iterator that iterates over a set of elements of type T.
Therefore, you can learn to enhance the for loop and simplify the traversal of arrays and Collection collections. Classes that implement Iterable allow their objects to be the target of enhanced for loop statements. After JDK5, the internal implementation principle is Iterator iterator.
The format used is as follows:

Example demonstration
int[] arr = {1,2,3,4,5};
for(int i:arr)
{
System.out.println(i);
}

List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("java");
for(String s :list)
{
System.out.println(s);
}
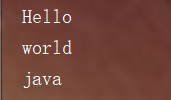
Verify the internal implementation principle
How to verify the internal implementation principle is the Iterator iterator, which is verified by the characteristics of concurrent modification exceptions in the iterative addition process of the Iterator iterator
List<String> list = new ArrayList<String>();
list.add("Hello");
list.add("world");
list.add("java");
for(String s :list)
{
if(s.equals("java")){
list.add("javaee");
}
System.out.println(s);
}

Extract of abnormal information:
Exception in thread "main" java.util.ConcurrentModificationException
at java.util.ArrayList
I
t
r
.
c
h
e
c
k
F
o
r
C
o
m
o
d
i
f
i
c
a
t
i
o
n
(
A
r
r
a
y
L
i
s
t
.
j
a
v
a
:
907
)
a
t
j
a
v
a
.
u
t
i
l
.
A
r
r
a
y
L
i
s
t
Itr.checkForComodification(ArrayList.java:907) at java.util.ArrayList
Itr.checkForComodification(ArrayList.java:907)atjava.util.ArrayListItr.next(ArrayList.java:857)
at java_practice.ListDemo.main(ListDemo.java:15)
The exceptions here are the same as those modified concurrently, so it can be verified that the internal implementation principle is Iterator iterator. It can also be verified by tracing the source code of the exception.
2: Implementation class LinkedList
In the basic inheritance relationship, like ArrayList, it does not directly inherit the List interface, but an implementation class.
We should clarify its inheritance and implementation relationship
public class LinkedList<E>extends AbstractSequentialList<E>implements List<E>, Deque<E>, Cloneable, Serializable
The underlying implementation of LinkedList is linked list, and it is a two-way linked list.
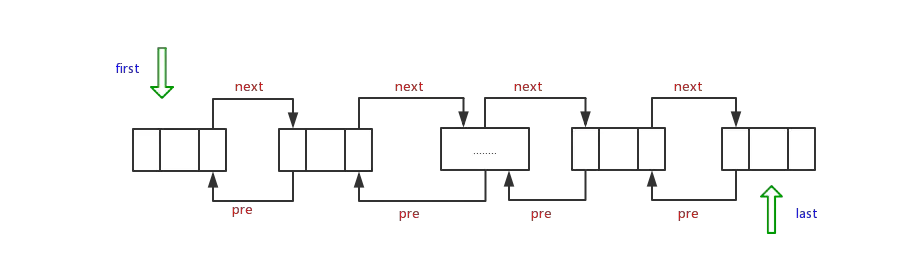
Compared with ArrayList, the basic implementation of ArrayList is array, which is convenient for searching, while the basic implementation of LinkedList is bidirectional linked list, which is convenient for addition, deletion and modification, but it is not very suitable for random query. Compared to arrays, of course. The sequential search efficiency of this two-way linked list is still relatively high, because it is a two-way linked list! Each node has a direct predecessor and a direct successor. Precursors and successors can be regarded as pointers (the soul in C language).
< method description >
Let's look at the method description. In fact, many methods are the same as those of ArrayList.
add() addAll,clear(),clone(),contains(),get(),indexof(),lastIndexof(),remove(),set(),toArray(). Basically, these methods are the same as ArrayList.
See some new methods specifically. Let's explain separately
1: removeLastOccurrence(Object o)
Removes the last occurrence of the specified element from this list (when traversing the list from head to tail).
LinkedList link = new LinkedList<>();
link.add("jgdabc");
link.add("jink");
link.add("jgdabc");
System.out.println(link);
link.removeLastOccurrence("jgdabc");
System.out.println(link);
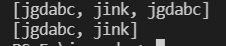
The corresponding reason is the same
2: removeFirstOccurrence(Object o)
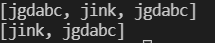
Removes the first occurrence of the specified element from this list (when traversing the list from head to tail).
LinkedList link = new LinkedList<>();
link.add("jgdabc");
link.add("jink");
link.add("jgdabc");
System.out.println(link);
link.removeFirstOccurrence("jgdabc");
System.out.println(link);
3: removeLast()
Removes and returns the last element of this list. The modified method will return the removed element when it is removed.
link.removeFirstOccurrence("jgdabc");
System.out.println(link);
String s_s = (String) link.removeLast();
System.out.println("Collection after element removal:"+link);
System.out.println("Removed element:"+s_s);

Again,
4: removeFirst()
Removes and returns the first element of this list. No more examples
5: push(E e)
Push the element into the stack represented by this list. This method is the operation of pressing stack.
The effect of this method is equivalent to addFirst()
Also corresponding
6:pop(E e)
Out of stack, this method is equivalent to removeFirst()
link.push("jgdabc");
System.out.println(link);
link.pop();
System.out.println(link);

7:pollLast()
Get and remove the last element of this list; If this list is empty, null is returned
8:pollFirst()
Get and remove the first element of this list; If this list is empty, null is returned.
9: poll()
Gets and removes the header (first element) of this list
String s_ = (String) link.pollLast();
System.out.println(s);
String s_1 = (String) link.pollFirst();
System.out.println(s_1);
String s_2 = (String) link.poll();
System.out.print(s_2);

10: peekLast()
Gets but does not remove the last element of the list; If this list is empty, null is returned.
11: peekFirst()
Gets but does not remove the first element of this list; null if the list is empty.
12:peek()
Gets but does not remove the header (first element) of this list.
String s_3 = (String) link.peekFirst();
System.out.println(s_3);
String s_4 = (String) link.peekLast();
System.out.println(s_4);
String s_5 = (String) link.peek();
System.out.println(s_5);
13:offerLast(E e)
Inserts the specified element at the end of this list.
14:offerFirst(E e)
Inserts the specified element at the beginning of this list.
15:offer(E e)
Adds the specified element to the end of this list (the last element).
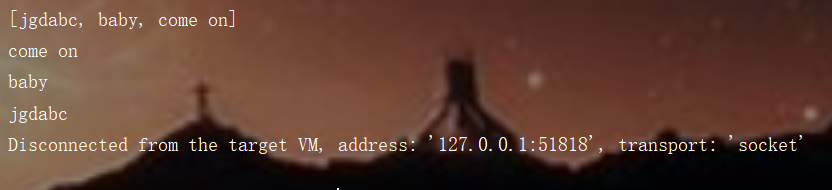
boolean flag_f= link.offerFirst("jgdabc");
System.out.println(flag_f);
System.out.println(link);
boolean baby = link.offerLast("baby");
System.out.println(baby);
System.out.println(link);
boolean come_on = link.offer("come on");
System.out.println(come_on);
System.out.println(link);

14: Iterator descendingIterator()
Returns an iterator that iterates over the elements of this two ended queue in reverse order.
Let's take an example to see the use of this reverse iterator, and then summarize the iterative method
Iterator iterator = link.descendingIterator();
while(iterator.hasNext())
{
System.out.println(iterator.next());
}
vector has been abandoned and will not be described. As for why I don't use it now, I will write a special detailed introduction later
4: Set set
Let's take a look at the jdk API's overview of Set sets
A collection that does not contain duplicate elements. To be more precise, set does not contain e1 Equals (e2) has element pairs e1 and e2 and contains at most one null element.
Other provisions have been added to the Set interface on the protocols of all construction methods and add, equals and hashCode methods, which exceed those inherited from the Collection interface. For convenience, it also includes declarations of other inheritance methods (the specifications of these declarations have been specially modified for the Set interface, but do not contain any other provisions).
The other rule for these constructors is (not surprisingly) that all constructors must create a set that does not contain duplicate elements (as defined above).
Set set full definition
public interface Set extends Collection
Set sets are not allowed to duplicate elements, and the access order is not guaranteed to be consistent.
1: Implementation class HashSet
On hash value
The hash value is an int type value calculated by Jdk according to the address or string or number of the object.
The Object class has a method to get the hash value of the Object
Or do you need to use the JDK API to find it
int hashCode()
Returns the hash code value of the object.
Code example
TreeSet<Student> ts = new TreeSet<Student>();
Student s1 = new Student(29, "Xi Shi");
Student s2 = new Student(28, "Wang Zhaojun");
Student s3 = new Student(30, "army officer's hat ornaments");
Student s4 = new Student(33, "Yang Yuhuan");
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
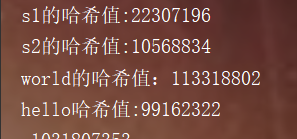
System.out.println("s1 Hash value of:"+s1.hashCode());
System.out.println("s2 Hash value:"+s2.hashCode());
System.out.println("world Hash value of:"+"world".hashCode());
System.out.println("hello Hash value:"+"hello".hashCode());
< 1 data structure of HashSet
The data structure of HashSet is implemented in jdk1 Before 8, hash table = array + linked list, jdk1 After 8, red and black trees were added. About red and black trees, another article will be written later.
Let's look at the complete class definition of HashSet
public class HashSet<E>extends AbstractSet<E>implements Set<E>, Cloneable, Serializable
Let's look at the description of this class in JDK API
This class implements the set interface and is supported by a hash table (actually a HashMap instance). It does not guarantee the iterative order of set; In particular, it does not guarantee that the order remains unchanged. This class allows null elements.
This class provides stable performance for basic operations, including add, remove, contains, and size, assuming that the hash function correctly distributes these elements in the bucket. The time required to iterate over this set is proportional to the sum of the size of the HashSet instance (number of elements) and the "capacity" of the underlying HashMap instance (number of buckets). Therefore, if iteration performance is important, do not set the initial capacity too high (or the load factor too low).
Implementation of HashSet underlying
After looking at the source code, it turns out that the underlying implementation is Map
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and the specified load factor.
*
* @param initialCapacity the initial capacity of the hash map
* @param loadFactor the load factor of the hash map
* @throws IllegalArgumentException if the initial capacity is less
* than zero, or if the load factor is nonpositive
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* the specified initial capacity and default load factor (0.75).
*
* @param initialCapacity the initial capacity of the hash table
* @throws IllegalArgumentException if the initial capacity is less
* than zero
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
/**
HashSet should ensure that there are no duplicate elements. It may be such a feature that we need to point genes from the Map..
<2> Method description
API gives several methods of summary
add(),clear(),clone(),contains(),isEmpty(),iterator(),remove() these methods are the same as above.
< 1 no duplicate storage
For a brief demonstration, let's take a look at a piece of code
HashSet s = new HashSet();
s.add("jgdabc");
s.add("hello");
s.add("jgdabc");
System.out.println(s);

It can be seen that it ensures the non repetition of elements.
But many times we operate on objects. If we add the object from new() and the internal properties of the object still have the same value, can HashSet ensure its non repeatability? Example to verify
package java_practice;
import java.util.HashSet;
public class HashSetDemo2 {
private String name;
private int age;
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public HashSetDemo2(String name, int age) {
this.name = name;
this.age = age;
}
public static void main(String args[])
{
HashSet<HashSetDemo2> s = new HashSet<HashSetDemo2>();
HashSetDemo2 ha = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha1 = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha2 = new HashSetDemo2("li",20);
s.add(ha);
s.add(ha1);
s.add(ha2);
for(HashSetDemo2 ss : s )
{
System.out.println(ss.getName()+ss.getAge());
}
// s.add("jgdabc");
// s.add("hello");
// s.add("jgdabc");
// System.out.println(s);
}
}
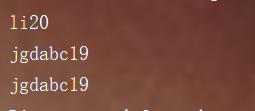
You can see that although the name and age are the same, they have been added. Why?
The reason is that what we add is an object, and the address of the object is different. Here we can lead to the source code analysis of how HashSet determines the uniqueness of elements
It's easy to trace the source all the way from the add() method
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
Put is called again on the add side, so let's look at put (the put of HashMap)
OK, I found it
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
put calls the putVal method. Go on. coming
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
It should be noted that the hashcode value is first compared to make a judgment, and then the equals() method is compared.
Specific comparison process
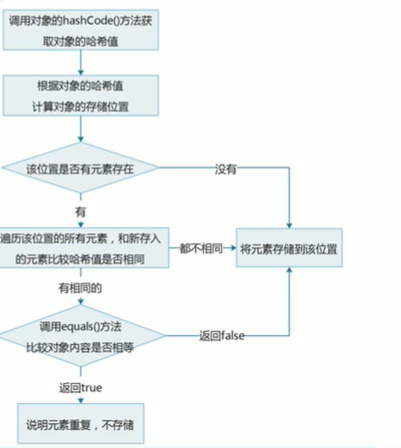
In fact, the first thing to compare is the address. The address of each new object above is different, so it is stored directly. No longer compare values. So how to ensure that the same students are not stored according to the value? To do so, override the HashCode and equals() methods. Now let's modify the above code to ensure the uniqueness of storage.
package java_practice;
import java.util.HashSet;
import java.util.Objects;
public class HashSetDemo2 {
private String name;
private int age;
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public HashSetDemo2(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
HashSetDemo2 that = (HashSetDemo2) o;
return age == that.age &&
Objects.equals(name, that.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public static void main(String args[])
{
HashSet<HashSetDemo2> s = new HashSet<HashSetDemo2>();
HashSetDemo2 ha = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha1 = new HashSetDemo2("jgdabc",19);
HashSetDemo2 ha2 = new HashSetDemo2("li",20);
s.add(ha);
s.add(ha1);
s.add(ha2);
for(HashSetDemo2 ss : s )
{
System.out.println(ss.getName()+ss.getAge());
}
// s.add("jgdabc");
// s.add("hello");
// s.add("jgdabc");
// System.out.println(s);
}
}
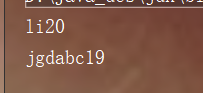
< 2 output does not guarantee disorder
Not necessarily, the output is disordered in any case. No, we can refer to this big man's article, which is very detailed.
In depth analysis - is HashSet really out of order? (JDK8)
To tell you the truth, this article is more exploratory. I took a look at this article here and didn't see it to the end. At present, I see too many things and am a little upset. In fact, when we delve into the standardization, we will come to the memory, data bit operation, and operation, as well as the optimization principle, and even some functions. We also need to consider the storage mechanism of memory.
There is nothing special about Hashset's other methods.
<3> On hash table
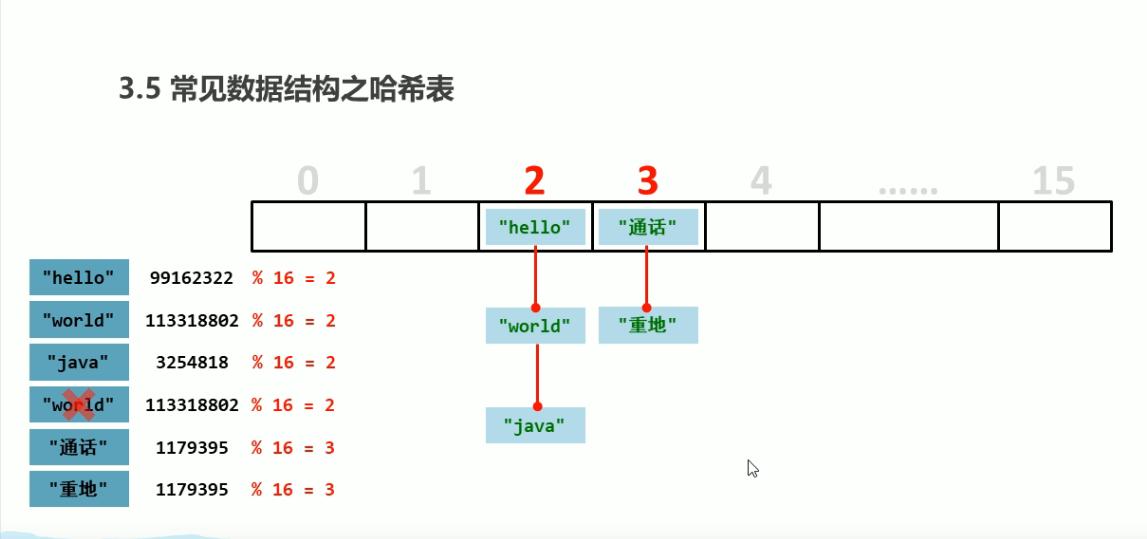
We logically understand this storage structure in the simplest way
HashSet is realized through linked list and array.
Then we give 16 locations with indexes of 0-15. The hash value calculated each time is relatively large, so it is impossible for us to use the hash value as the index subscript. Therefore, modulo is adopted, that is to take the remainder of 16, and the remainder will be stored in that location. However, judgment will be made before storage. The judgment method has been described and will not be repeated. If it is stored in the same position of the array, it will be chain stored in this position later. As shown above.
The default construction method of HashSet. The default initial capacity of HashSet is 16
Construction method summary
HashSet()
Construct a new empty set. The default initial capacity of the underlying HashMap instance is 16 and the loading factor is 0.75
2: Implementation class LinkedHashSet
Complete class definition
public class LinkedHashSetextends HashSetimplements Set, Cloneable, Serializable
Through the class definition, we can find that LinkedHashSet is the inheritance class of HashSet. And implements the Set class.
LinkedHashSet is implemented through a two-way linked list. We know that the access elements of HashSet are disordered. LinkedHashSet adopts two-way linked list, which is continuous in logical storage, so LinkedHashSet is stored in order.
JDKAPI also has a detailed description
Let's look at some instructions
Hash table and link list implementation of set interface with predictable iteration order. The difference between this implementation and HashSet is that the latter maintains a double linked list running on all items. This linked list defines the iterative order, that is, the order in which the elements are inserted into the set (insertion order). Note that the insertion order is not affected by the elements reinserted in the set. (if s.add(e) is called immediately after s.contains(e) returns true, the element e will be reinserted into set s.)
<1> Method description
JDK API provides specific inheritance methods
From class java util. HashSet inherited methods
add, clear, clone, contains, isEmpty, iterator, remove, size
From class java util. Abstractset inherited method
equals, hashCode, removeAll
From class java util. Methods inherited by abstractcollection
addAll, containsAll, retainAll, toArray, toArray, toString
From class java Methods inherited from lang.Object
finalize, getClass, notify, notifyAll, wait, wait, wait
Slave interface java util. Set inherited method
add, addAll, clear, contains, containsAll, equals, hashCode, isEmpty, iterator, remove, removeAll, retainAll, size, toArray, toArray
Verify that the element output is ordered and unique
package java_practice;
import java.util.LinkedHashSet;
public class LinkedHashSet_Demo {
public static void main(String args[]){
LinkedHashSet<String> lhs = new LinkedHashSet<String>();
lhs.add("Hello");
lhs.add("world");
lhs.add("Hello");
lhs.add("every body");
System.out.println(lhs);
}
}

Note: the common methods have been mentioned. More in-depth, which will be used later. For example, finalize() still has a lot of knowledge.
3: Implementation class TreeSet
Although the class definition does not point out the implementation of Set set Set, direct traceability can still be regarded as a kind of Set set
Let's look at the complete class definition
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
//Traceability from AbstractSet
public abstract class AbstractSet<E> extends AbstractCollection<E> implements Set<E> {
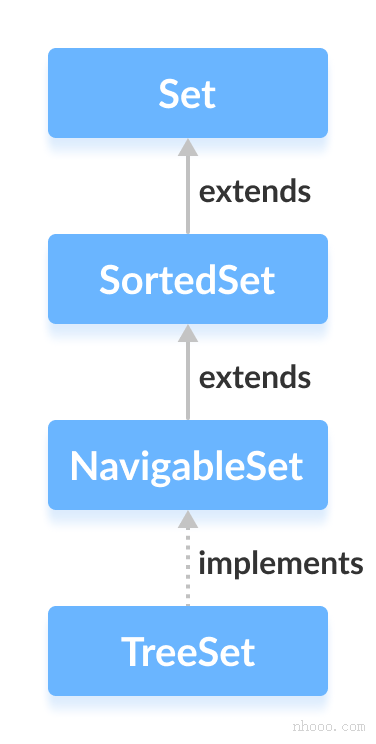
Therefore, we can also think that TreeSet implements the Set set
JDK API gives some descriptions of TreeSet
Tregableset based implementation. The elements are sorted by the natural order of the elements, or by the Comparator provided when creating the set, depending on the construction method used.
Of course, there are other contents, but the words are too cohesive to understand.
The underlying data structure is implemented as a red black tree, so the data stored in TreeSet is sequential.
The elements of the TreeSet set are ordered and sorted according to certain rules. The specific sorting method depends on the constructor used, and the number is not allowed to be repeated.
<1> Method description
<1> Default natural sort (default call to parameterless constructor)
For example, go directly to the code
TreeSet<Integer> in = new TreeSet<>();
in.add(10);
in.add(20);
in.add(30);
in.add(5);
in.add(4);
//Traversal set
for(Integer i :in)
{
System.out.println(i);
}
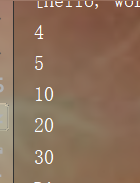
<2> Use of natural sorting Comparable
Can I use TreeSet to sort a class successfully now?
package java_practice;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String args[])
{
TreeSet<Student> ts = new TreeSet<Student>();
Student s1 = new Student(29, "Xi Shi");
Student s2 = new Student(28, "Wang Zhaojun");
Student s3 = new Student(30, "army officer's hat ornaments");
Student s4 = new Student(33, "Yang Yuhuan");
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
for(Student s : ts)
{
System.out.println(s.getName()+""+s.getAge());
}
}
}
It feels OK to write code, but there is something wrong with running

Extract it
Exception in thread "main" java.lang.ClassCastException: java_practice.Student cannot be cast to java.lang.Comparable at java.util.TreeMap.compare(TreeMap.java:1294) at java.util.TreeMap.put(TreeMap.java:538) at java.util.TreeSet.add(TreeSet.java:255) at java_practice.TreeSetDemo.main(TreeSetDemo.java:13)
A key sentence
Exception in thread "main" java.lang.ClassCastException: java_practice.Student cannot be cast to java.lang.Comparable
It shows that the student class cannot be converted to the Comparable interface. Why not?
Let's check the description of the Comparable interface again
public interface Comparable this interface forcibly sorts the objects of each class that implements it as a whole. This sort is called the natural sort of class, and the compareTo method of class is called its natural comparison method.
Then our Student class needs to implement it
//Student class
package java_practice;
public class Student implements Comparable<Student>{
private int age;
private String name;
public Student(int age, String name) {
this.age = age;
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
@Override
public int compareTo(Student s) {
int num = this.age -s.age;
return num;
//return 0;
}
}
//Test class
package java_practice;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String args[])
{
TreeSet<Student> ts = new TreeSet<Student>();
Student s1 = new Student(29, "Xi Shi");
Student s2 = new Student(28, "Wang Zhaojun");
Student s3 = new Student(30, "army officer's hat ornaments");
Student s4 = new Student(33, "Yang Yuhuan");
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
for(Student s : ts)
{
System.out.println(s.getName()+""+s.getAge());
}
}
}
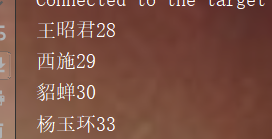
public int compareTo(Student s) {
int num = this.age -s.age;
return num;
//return 0;
}
The return value, this in front is in ascending order, and this in back is in descending order. If you return the number 1 directly, it will be output in sequence. If 0 is returned, only one element can be output. You can test it yourself.
However, another problem is that if the age is the same, if you want to add elements to the collection, subsequent objects with the same age data as the previous objects will not be output, so we can add conditions.
The specific operation is the CompareTo method. Change it a little.
public int compareTo(Student s) {
int num = this.age -s.age;
int num2 = num == 0?this.name.compareTo(s.name):num;
return num2;
}
That's it.
Then you may wonder why the Integer type above can realize comparison? Because Integer itself implements the CompareTo method, and strings also implement this method.
<3> Use of Comparator
We can use the comparator to achieve the same effect as natural sorting.
Reference source: JDK API
TreeSet(Comparator<? super E> comparator)
Construct a new empty TreeSet that sorts according to the specified comparator.
Specific examples through the code
//Student class
package java_practice;
public class Student {
private int age;
private String name;
public Student(int age, String name) {
this.age = age;
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public String getName() {
return name;
}
// @Override
// public int compareTo(Student s) {
// int num = this.age -s.age;
// int num2 = num == 0?this.name.compareTo(s.name):num;
// return num2;
}
//Test class
package java_practice;
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSetDemo1 {
public static void main(String args[]) {
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
int num = s1.getAge() - s2.getAge();
int num2 = num == 0 ? s1.getName().compareTo(s2.getName()) : num;
return num2;
}
});
Student s1 = new Student(29, "Xi Shi");
Student s2 = new Student(28, "Wang Zhaojun");
Student s3 = new Student(30, "army officer's hat ornaments");
Student s4 = new Student(33, "Yang Yuhuan");
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
for (Student s : ts) {
System.out.println(s.getName() + "" + s.getAge());
}
}
}
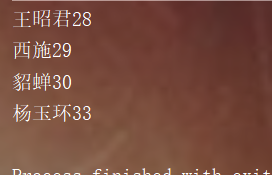
The comparator is implemented here through anonymous inner classes.
Many conventional methods of TreeSet are included in the above collection, so I won't repeat them.
Postscript: the relevant summary of the single column collection comes partly from your own attempts to consult API methods, and partly from course notes. There are many foundations as learning records. There are a lot of knowledge that has not been written in, if you think of it. Will be added.
The article is 30000 words, and the content may be messy. I hope to correct anything wrong. The article has been updated and dynamically transformed. The significance of recording lies in thinking summary and subsequent viewing, also for sharing, that's all.