Hello, I'm brother Manon Feige. Thank you for reading this article. Welcome to one click three times.
😁 1. Take a stroll around the community. There are benefits and surprises every week. Manon Feige community, leap plan
💪🏻 2. Python basic column. You can't buy it for 9.9 yuan, and you can't be fooled. Python from introduction to mastery
❤️ 3. Python crawler column, systematically learn the knowledge points of crawlers. 9.9 yuan can't afford to suffer losses and be cheated. It's constantly updating. python crawler beginner level
❤️ 4. Ceph has everything from principle to actual combat. Ceph actual combat
❤️ 5. Introduction to Java high concurrency programming, punch in and learn java high concurrency. Introduction to Java high concurrency programming
preface
This article will introduce how to use the sketch framework to quickly crawl the pictures of cars on a website and save the crawled pictures locally.
Create a scene project
The command to create a scratch project will not be repeated here. If you are not clear, you can see the following: Quick start to the Scrapy framework, taking the embarrassing encyclopedia as an example [advanced introduction to python crawler] (16)
Create a BBA with the following command_ img_ Demo and create a spider named bba3.
scrapy startproject bba_img_demo cd bba_img_demo scrapy genspider bba3 "car.com.cn"
Crawl picture bba3Spider
Here we still use xpath to crawl page elements. Crawl page elements in bba3Spider to get imgDemoItem and return it to Pipelines.
class bba3Spider(scrapy.Spider):
name = 'bba3'
allowed_domains = ['car.com.cn']
start_urls = ['https://car.com.cn/pic/series/66.html#pvareaid=2042214']
def parse(self, response):
# Get all categories
uiboxs = response.xpath("//div[@class='uibox']")[1:]
for uibox in uiboxs:
# Gets the name of a category
category = uibox.xpath(".//div[@class='uibox-title']/a/text()").get()
# Get picture link
org_urls = uibox.xpath(".//ul/li/a/img/@src").getall()
urls = []
for url in org_urls:
# Splice the picture address with the domain name
url = response.urljoin(url)
urls.append(url)
imgDemoItem = bbaImgDemoItem(category=category, urls=urls)
yield imgDemoItem
What needs to be explained here is org_ The results obtained by URLs are:
['//car2.cn/cardfs/product/g27/M0B/8C/16/480x360_0_q95_c42_autohomecar__ChxkmWGegTyACi-kAC3FbBHMbU0705.jpg', '//car3.cn/cardfs/product/g28/M04/89/E4/480x360_0_q95_c42_autohomecar__ChxkmmGegTuAMP6mABxWnAoC-D4144.jpg', '//car3.cn/cardfs/product/g28/M03/89/E4/480x360_0_q95_c42_autohomecar__ChxkmmGegTmAcgvzABhIjSB7-9g758.jpg', '//car3.cn/cardfs/product/g28/M00/89/E4/480x360_0_q95_c42_autohomecar__ChxkmmGegTmAERL1ACm2BVXLZ6Y692.jpg', '//car3.cn/cardfs/product/g27/M04/8C/16/480x360_0_q95_c42_autohomecar__ChxkmWGegTiAXmudADZcJBeHRXE488.jpg', '//car3.cn/cardfs/product/g27/M0A/AE/14/480x360_0_q95_c42_autohomecar__ChwFkWGegTeAU296ACGsSse0_UY335.jpg', '//car3.cn/cardfs/product/g27/M01/8C/16/480x360_0_q95_c42_autohomecar__ChxkmWGegTaAJjHFACpeMVzBTpk896.jpg', '//car2.cn/cardfs/product/g27/M01/AE/14/480x360_0_q95_c42_autohomecar__ChwFkWGegTWAGp1RACY4LcxwCrk373.jpg']
Therefore, you need to splice in front of the crawled image address: HTTPS:, here you can use either url='https:'+url or response urljoin(url).
Save picture bbaImgDemoPipeline
Receive imgDemoItem returned by bba3Spider in bbaImgDemoPipeline. And save the picture to BBA_ img_ The images directory of the demo project. And save the image data under each category by category in the images directory.
import os
from urllib import request
import ssl
from urllib.request import HTTPSHandler
context = ssl._create_unverified_context()
https_handler = HTTPSHandler(context=context)
opener = request.build_opener(https_handler)
request.install_opener(opener)
class bbaImgDemoPipeline:
def __init__(self):
self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'image')
if not os.path.exists(self.path):
os.mkdir(self.path)
def process_item(self, item, spider):
category = item['category']
urls = item['urls']
category_path = os.path.join(self.path, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
for url in urls:
# Pass__ To get the file name
image_name = url.split('__')[-1]
request.urlretrieve(url, os.path.join(category_path, image_name))
return item
The result after running is:
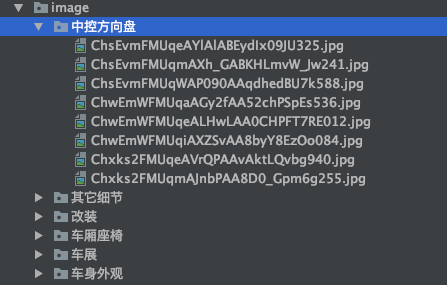
This method can achieve the effect we want. However, it is not elegant enough, does not use multithreading, and is not concise enough.
Scratch provides a reusable item pipeline for downloading the files contained in Item (for example, when crawling to the product, you also want to save the corresponding pictures). These pipelines have a common method and structure (we call them media pipelines). Generally speaking, you will use Files Pipeline or Images Pipeline
Using the method of downloading files built-in in scratch has the following advantages:
- Avoid downloading data that has been downloaded recently
- You can easily specify the path of file storage.
- You can convert the downloaded pictures into a common format, such as png or jpg.
- Thumbnails can be easily generated.
- It is convenient to detect the width and height of pictures to ensure that they meet the minimum limit.
- Asynchronous download, very efficient.
Steps for using Files Pipeline:
- Define an item, and then define two attributes in the item, namely file_url and files. file_urls is used to store url links of files to be downloaded. What is needed is a list.
- After the file download is completed, the relevant information of the file download will be stored in the files attribute in items, such as the download path, the url of the download and the verification code of the file.
- In the configuration file settings Configure files in PY_ Store, this configuration is used to set the path to download files.
- Start pipeline: in item_ Set 'scratch. In piplines pipelines. files. FilePipeline':1.
Steps for using Images Pipeline:
When downloading files using Image Pipeline, follow the following steps:
- Define an item, and then define two attributes in the item, namely image_urls and images. image_url is the url link used to store the pictures to be downloaded. You need to give a list.
- After the image download is completed, the relevant information of the image download will be stored in the imags attribute of item, such as the download path, the url of the download and the check code of the image.
- When the configuration file settings Configure images in PY_ Store, this configuration is used to set the path of image download.
- Start pipeline: in item_ Set 'scratch' in pipelines pipelines. images. ImagesPipeline':1.
Next, we will use Image Pipeline to realize this function. The detailed steps are as follows:
1. Modify bbaImgDemoItem class
class bbaImgDemoItem(scrapy.Item):
category = scrapy.Field()
image_urls = scrapy.Field()
images = scrapy.Field()
Define image in bbaImgDemoItem class_ URLs and images.
2. Modify bba3Spider class and put the downloaded image path into image_urls.
class bba3Spider(scrapy.Spider):
name = 'bba3'
allowed_domains = ['car.com.cn']
start_urls = ['https://car.com.cn/pic/series/66.html#pvareaid=2042214']
def parse(self, response):
# Get all categories
uiboxs = response.xpath("//div[@class='uibox']")[1:]
for uibox in uiboxs:
# Gets the name of a category
category = uibox.xpath(".//div[@class='uibox-title']/a/text()").get()
# Get picture link
org_urls = uibox.xpath(".//ul/li/a/img/@src").getall()
urls = list(map(lambda url: response.urljoin(url), org_urls))
imgDemoItem = bbaImgDemoItem(category=category, image_urls=urls)
yield imgDemoItem
3. Modify settings py
In settings Py file configuration IMAGES_STORE. Specify the path to save the picture.
import os IMAGES_STORE= os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
4. Specify the pipeline to start
Specify the pipeline to be started as scratch pipelines. images. ImagesPipeline
ITEM_PIPELINES = {
# 'bba_img_demo.pipelines.bbaImgDemoPipeline': 300,
'scrapy.pipelines.images.ImagesPipeline':1
}
After this setting, the original bbaImgDemoPipeline will not be started. Because there is only one pipeline, the priority can be set at will.
After these four steps, the setting is almost the same. However, if you run it directly at this time, you probably won't get the desired effect. This is because the imagespipline class needs to introduce the PIL package during initialization. If it is not installed, an error will be reported directly.
5. Install the pilot library
pip install Pillow
After the above five steps, you can run correctly. After running, the result is:
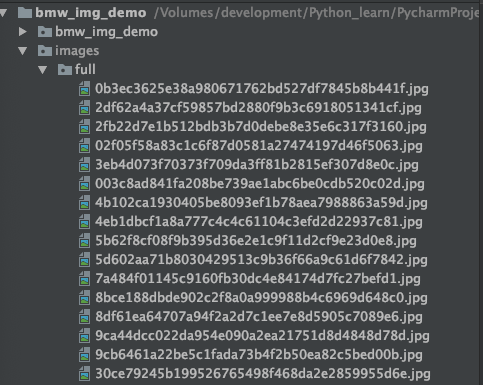
You can see that all the pictures have been saved to the full folder under the images directory. This is clearly not the result we expected. Therefore, we still need to inherit the imagespipline class and then override its saving logic. Check the source code of imagespipline to know that the method to save the picture to the full folder is file_path. So we just need to override this method to return the path we want.
Specify the path we need to save
In pipelines Py file, customize a class named bbaImagesPipeline, and let this class inherit from ImagesPipeline.
- Rewrite get_media_requests method
get_ media_ The requests method is called before sending the download request. The main function of the method is to get image_. Picture links in URLs and spliced into download requests.
Get of imagespipline class_ media_ Requests method, you can see that what is returned is a list of Request objects.
def get_media_requests(self, item, info):
urls = ItemAdapter(item).get(self.images_urls_field, [])
return [Request(u) for u in urls]
Rewritten get_media_requests method. First call the image of the parent class_ URLs method, and then set item to request_obj.
def get_media_requests(self, item, info):
request_objs = super(bbaImagesPipeline, self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
- Rewrite file_path method
File of parent class_ The path method mainly consists of two steps. The first step is to hash the address of the picture link to get the name of the picture, and then return the relative path of the picture storage full / {image_guid} jpg.
def file_path(self, request, response=None, info=None, *, item=None):
image_guid = hashlib.sha1(to_bytes(request.url)).hexdigest()
return f'full/{image_guid}.jpg'
So rewrite file_ The path method only needs to replace the returned relative path with the expected relative path.
def file_path(self, request, response=None, info=None, *, item=None):
path = super(bbaImagesPipeline, self).file_path(request, response, info)
category = request.item.get('category')
img_name = path.replace('full/', '')
image_path = os.path.join(category, img_name)
return image_path
Call the file of the parent class_ The path method gets the returned full / {image_guid} jpg. Then get the category attribute in item.
Then replace full / to get the picture name. Finally, the classification and picture name are spliced into a relative path to return.
Crawl high-definition pictures (multiple web pages crawl at the same time)
1. Analyze link characteristics
- Address of body appearance: https://car.com.cn/pic/series/66-1-p2.html
- Address of central control steering wheel: https://car.com.cn/pic/series/66-10.html#pvareaid=2042223
A simple analysis of the link can be obtained https://car.com.cn/pic/series/66 This part is exactly the same, and the later part can match any character.
So the regular expression that matches the link address is https://car.com.cn/pic/series/66. +.
2. Write crawler code
Here is a custom class named bba3Spider, which inherits from CrawlSpider.
# Define crawling strategy
rules = (
Rule(LinkExtractor(allow=r"https://car.com.cn/pic/series/66.+"), callback="parse_page", follow=True),
)
Callback specifies that the callback function called is parse_page method. When you click on the next page, you continue down.
Callback method parse_page, which crawls the address of classification and picture.
def parse_page(self, response):
category = response.xpath("//div[@class='uibox']/div/text()").get()
srcs = response.xpath('//div[contains(@class,"uibox-con")]/ul/li/a/img/@src').getall()
urls = list(map(lambda x: response.urljoin(x), srcs))
yield bbaImgDemoItem(category=category, image_urls=urls)
summary
Taking a website as an example, this paper explains how to use the sketch framework to efficiently crawl the pictures in the website.
Exclusive benefits for fans
Soft test materials: Practical soft test materials
Interview questions: 5G Java interview questions
Learning materials: 50G various learning materials
Secret script of withdrawal: reply to [withdrawal]
Concurrent programming: reply to [concurrent programming]
👇🏻 The verification code can be obtained by searching the official account below.👇🏻