background

When I drive slowly on the highway, the spacious road is very crowded! At this time, I like to let Baidu navigation Xiaodu tell me jokes, but she is a little weak and can only tell one at a time.
Baidu claims to develop AI and become a leading enterprise in AI in China. But in terms of small IQ and understanding ability, I doubt it very much.
So we simply use Python to develop a robot that can tell jokes. We can customize the functions freely. If we want to tell a few jokes, we can tell a few jokes.
Technology used
The following technologies are used in this paper:
- Crawler - grab joke
- Database - save jokes with sqlite
- Object oriented encapsulating joke objects
- Module - code is divided into modules and placed in multiple files
- Voice recognition - recognize the voice input by the user and convert the joke into voice
- GUI - develop a simple user interface
- Package - package a program into an executable file
Main process
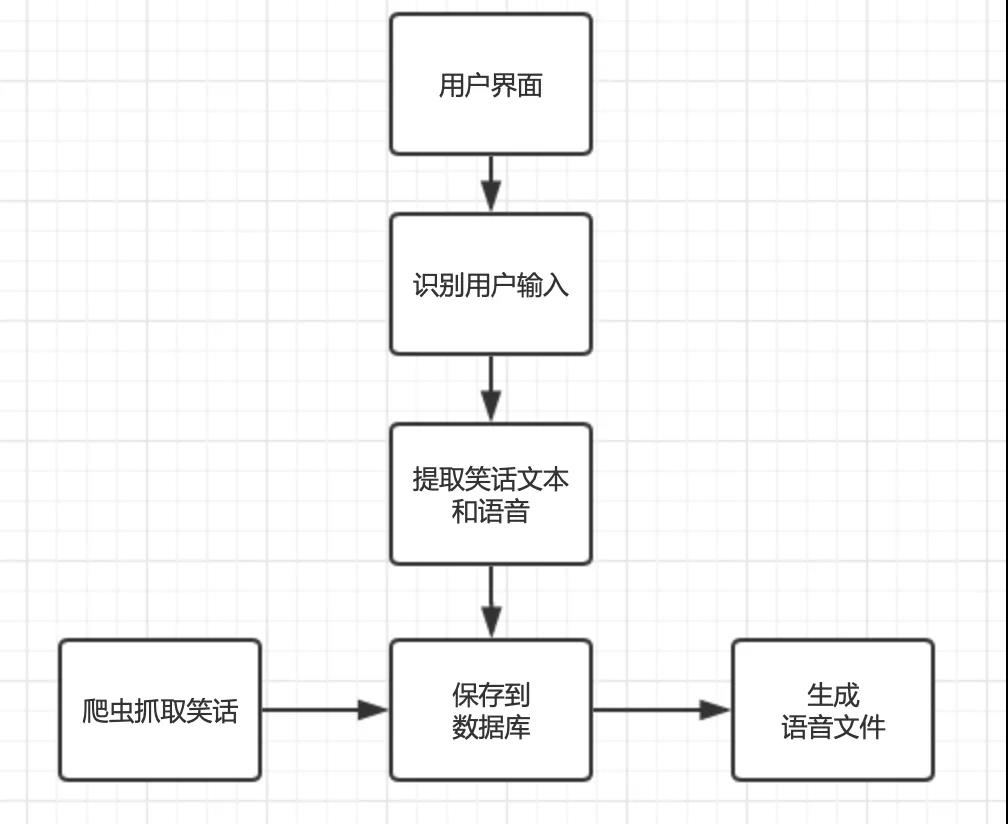
Code module
In order to make the code structure clear and easy to maintain, we put the code into multiple py files, and each file performs its own duties.
This program includes the following code modules:
- joke.py - joke object, shared by multiple modules
- joke_crawler.py - joke crawler
- joke_db.py - handle database related, save jokes, query jokes, etc
- joke_ui.py - user interface module
- joke_audio.py - handles voice related tasks and 2 non code structures:
- joke_audio - folder where voice files are stored
- jokeDB.db - sqlite3 database file
Now start writing code. Please create a folder first. It is recommended to name it myjoke. All the following codes are in this folder.
Joke object
We use object-oriented programming ideas to create a class called Joke to represent a Joke.
With the Joke class, the code is clearer and the data transmission is more convenient. The Joke class will be used by all other modules.
Create a file named joke Py file
The code is as follows:
class Joke:
'''
A joke.
among title It's a joke title, detail It's a joke
url Is the collection website of jokes, through url Determine whether the joke is repeated to prevent saving repeated jokes
id Is the unique identifier generated by the database. There is no joke just collected id Yes, so id Can be empty
'''
def __init__(self, title, detail, url, id=None):
self.title = title
self.detail = detail
self.url = url
self.id = id
def __str__(self):
'''
With this method, print(joke)The joke will be printed as a string in the following format, otherwise only the memory address of the object will be printed
'''
return f'{id}-{title}\n{detail}\n{url}'
There are only two magic methods in this class. One is the constructor__ init__, One is__ str__.
Reptile grabbing joke
Analyze web page structure
The website we want to capture is this: http://xiaohua.zol.com.cn/detail1/1.html There are three data points we need to grasp:
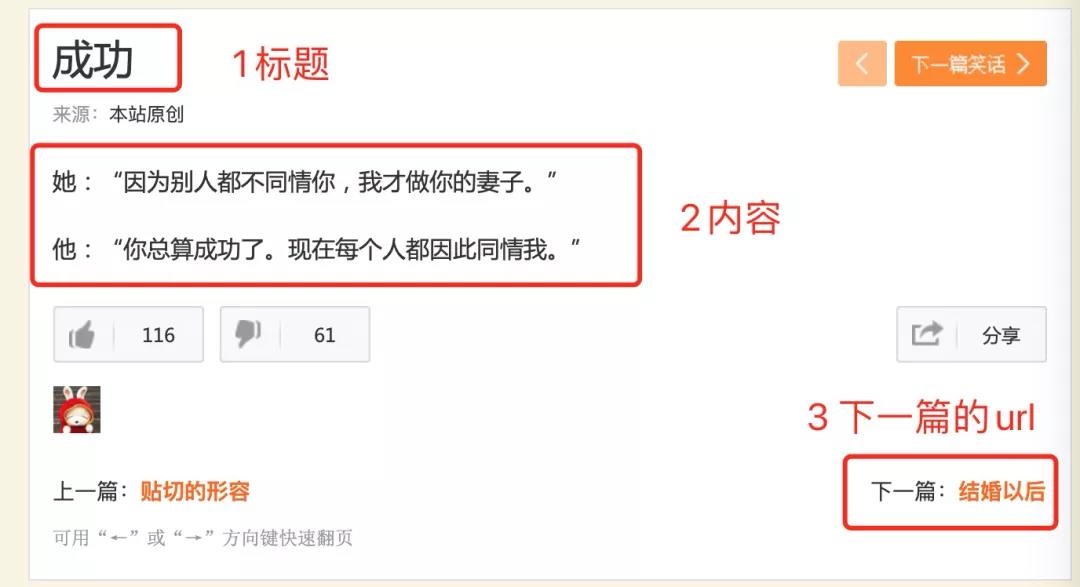
Right click Check in Google browser to see the code structure of the web page below:
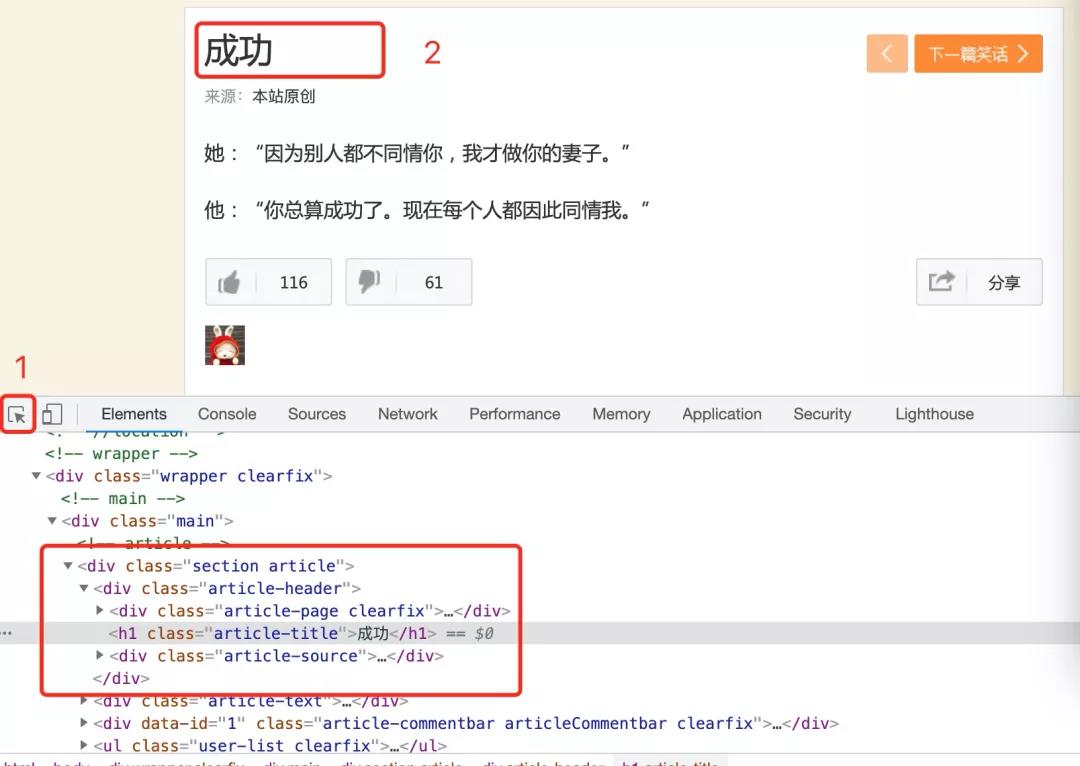
- 1. Click the button of 1 with the mouse
- 2. Then move the mouse to 2
- 3. You can see the structure of success in the web page.
By analyzing this structure, we can conclude that the word "success" is in an h1 structure, and the class of h1 is article title, because this feature can be used to extract the content (example code):
title = html.select_one('h1.article-title').getText()
In the same way, you can analyze the characteristics of the joke content and the URL of the next page.
Analyzing web page structure requires basic knowledge of HTML and CSS. If you don't understand it at all, you can directly imitate my code first, and then slowly understand the relevant knowledge.
code implementation
Now let's look at the complete code.
Create a new one named joke_crawler.py file.
import requests
import bs4
import time
import random
#Comment out the code related to the database first, and then you need to de comment it back
#import joke_db
from joke import Joke
#Start URL
url = 'http://xiaohua.zol.com.cn/detail1/1.html'
#The domain name address of the website is used to splice the complete address
host = 'http://xiaohua.zol.com.cn'
def craw_joke(url):
'''
Grab the specified URL,Return a Joke Object, and the next one to grab URL
If the capture fails, return None, None
Must be set User-Agent header,Otherwise, it is easy to be sealed
'''
print(f'Crawling:{url}')
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
html = requests.get(url, headers=headers).text
soup = bs4.BeautifulSoup(html, 'lxml')
try:
#Use css selector to extract title, detail and next respectively_ url
title = soup.select_one('h1.article-title').getText()
detail = soup.select_one('div.article-text').getText().strip()
next_url = soup.select_one('span.next > a')['href']
return Joke(title, detail, url), next_url
except Exception as e:
print('Error:', e)
print(html)
return None, None
# Grab jokes for the purpose of learning. It is recommended not to grab too many. Only 10 jokes are captured in this example
count = 0
for i in range(0, 10):
joke, next_url = craw_joke(url)
if joke:
#Comment out the code related to the database first, and then you need to de comment it back
#joke_db.save(joke)
print(joke)
url = host + next_url
print('Take a break and catch it later!')
time.sleep(random.randint(1, 5))
print('Finish the work!')
Some comments have been added to the code, and the basic ones should be understandable.
There are two points to note:
1. In crawl_ In the joke function, the user agent header must be added, otherwise it will be blocked soon.
2. The code related to the database has been commented out in the code, and now just print out the joke. After the database module is written, the relevant code should be back annotated.
3. There is a random pause of 1 to 5 seconds in the middle of the capture. One is to prevent being blocked, and the other is to be polite and do not put too much pressure on the server.
Save to sqlite database
The captured jokes can be saved in the file, but it is not convenient to retrieve and judge whether the jokes are repeated.
So the better way is to save the jokes to the database. Here, choose sqlite as the database. The reasons are as follows:
1.sqlite is a file database, and there is no need to install additional database server
2.python supports sqlite database by default, without any additional installation and configuration
But if you want to catch all the jokes in the world and there is a large amount of data, it is recommended to use a more formal database, such as MySQL
Create a new one named joke_db.py file
The code is as follows:
import sqlite3
from joke import Joke
def setup():
'''
Create databases and tables. If they already exist, they will not be created repeatedly
'''
con = sqlite3.connect('jokeDB.db')
with con:
con.execute('''CREATE TABLE IF NOT EXISTS jokes
(id INTEGER PRIMARY KEY,
title varchar(256) NOT NULL,
detail varchar(1024) NOT NULL,
url varchar(1024) NOT NULL)''')
def save(joke):
'''
Save jokes to database
according to url Judge whether there is this joke. If so, it will not be saved
'''
con = sqlite3.connect('jokeDB.db')
with con:
cur = con.cursor()
cur.execute(
'SELECT * FROM jokes WHERE (url = ?)', [(joke.url)])
has_joke = cur.fetchone()
if has_joke:
print('Repeat, no more insertion')
else:
con.execute('INSERT INTO jokes(title, detail, url) VALUES (?,?,?)', (joke.title, joke.detail, joke.url))
print('Jokes saved successfully')
def get_jokes():
'''
Returns a list of all jokes
'''
print('loading jokes...')
con = sqlite3.connect('jokeDB.db')
jokes = []
with con:
for row in con.execute('SELECT * FROM jokes'):
joke = Joke(row[1], row[2], row[3], row[0])
jokes.append(joke)
return jokes
# Call the top code
setup()
# Test code. When this module is introduced by other modules, the following code will not be executed
if __name__ == '__main__':
save(Joke('joke Test', 'Joke content test', 'https://www.joke.com/1.html'))
save(Joke('joke Test2', 'Joke content test', 'https://www.joke.com/2.html'))
print('========Print out all the jokes======')
for joke in get_jokes():
print(joke)
print()
More comments have been added to the code. Please look at the code first. Here is an additional supplement:
1. To use sqlite, you need to introduce sqlite3 module
2. use sqlite to first get links using connect() method, then call execute() method to execute SQL statement.
Run the above code and you will find that there is an additional folder named jokedb DB file, which is the database file automatically created by the program, and the jokes are saved in it. Here are only two jokes tested:
> python joke_db.py Jokes saved successfully Jokes saved successfully ========Print out all the jokes====== loading jokes... 1-joke Test Joke content test https://www.joke.com/1.html 2-joke Test2 Joke content test https://www.joke.com/2.html
This part requires some database knowledge, but you can also do the functions first and then strengthen the relevant knowledge.
Grab the joke and save it to the database
Now back to joke_crawler.py, remove about joke_ Comment code for DB
The first is at the beginning of the file:
#Comment out the code related to the database first, and then you need to de comment it back #import joke_db
The second is at the bottom of the file:
for i in range(0, 10):
joke, next_url = craw_joke(url)
if joke:
#Comment out the code related to the database first, and then you need to de comment it back
#joke_db.save(joke)
print(joke)
url = host + next_url
print('Take a break and catch it later!')
time.sleep(random.randint(1, 5))
print('Finish the work!')
After removing the comments, run joke again_ crawler. Py, the joke will be saved in the database.
To verify whether the save is successful, you can run joke_db.py, because this file will print out all the jokes at the end:
========Print out all the jokes====== loading jokes... 1-joke Test Joke content test https://www.joke.com/1.html 2-joke Test2 Joke content test https://www.joke.com/2.html 3-success She said, "I'm your wife because others don't care for you." He: "you finally succeeded. Now everyone sympathizes with me." http://xiaohua.zol.com.cn/detail1/1.html 4-After marriage Woman: "why did you obey me in the past, but you quarreled with me for two days after you were married for only three days?" Man: "because my patience is limited." http://xiaohua.zol.com.cn/detail1/2.html 5-ours When Yan'er got married, the bride said to the bridegroom, "we are not interested in talking in the future'my'Yes, I have to say'ours'. "The groom went to take a bath and didn't come out for a long time. The bride asked, "what are you doing?" "Honey, I'm shaving our beard." http://xiaohua.zol.com.cn/detail1/3.html 6-entertain imaginary or groundless fears His wife was seriously ill and the doctor declared that there was no way to recover. The wife said to her husband, "I hope you can swear now." "Take what oath." "If you remarry, don't give my clothes to your new wife." The husband suddenly realized, "I can swear that. To be honest, you don't have to worry at all, because I don't want to find a fat wife like you anymore." http://xiaohua.zol.com.cn/detail1/5.html 7-Well reasoned Judge: "what is the reason for divorce?" Bride: "he snores." Judge: "how long have you been married?" Bride: "three days." Judge: "there are good reasons for divorce. Three days of marriage is not the time to snore." http://xiaohua.zol.com.cn/detail1/6.html 8-Smart husband A couple passed in the street. A pigeon flew across the sky. A bubble of pigeon dung happened to fall on the wife's shoulder. The wife was anxious and hurriedly asked her husband to take the paper. The husband looked up and saw that the pigeon didn't pay attention to hygiene and shit everywhere, but he didn't know what his wife told him to take the paper. He said, "what can I do to catch up and wipe his ass!" http://xiaohua.zol.com.cn/detail1/8.html 9-Accidents and disasters A lady asked her husband, "honey, can you tell me'accident'And'disaster'Is there any difference between the two words? " "It's simple." The husband replied seriously, "for example, if you fall into the water, it's called'accident';If people catch you as a fish again, this is'disaster'It's too late. " http://xiaohua.zol.com.cn/detail1/13.html 10-The result of a quarrel The couple quarreled. When the husband came home from work, he found that his wife was not at home. Only one note was left on the table, which read: "lunch is on page 215 of the cookbook; dinner is on page 317." http://xiaohua.zol.com.cn/detail1/14.html 11-Insurance The wife didn't understand the truth of insurance and thought it was a waste to pay the insurance premium. The husband quickly explained, "insurance is for you and your children. In case I die, you also have a guarantee!" The wife retorted, "what if you don't die?" http://xiaohua.zol.com.cn/detail1/16.html 12-Make up for deficiency Wife: "I know you married me because I have money." Husband: "no, it's because I don't have money." http://xiaohua.zol.com.cn/detail1/17.html
About Python technology reserve
It's good to learn Python well, whether in employment or sideline, but to learn python, you still need to have a learning plan. Finally, let's share a full set of Python learning materials to help those who want to learn Python!
1, Python learning routes in all directions
All directions of Python is to sort out the commonly used technical points of Python and form a summary of knowledge points in various fields. Its purpose is that you can find corresponding learning resources according to the above knowledge points to ensure that you learn more comprehensively.
2, Learning software
If a worker wants to do well, he must sharpen his tools first. The commonly used development software for learning Python is here, which saves you a lot of time.
3, Getting started video
When we watch videos, we can't just move our eyes and brain without hands. The more scientific learning method is to use them after understanding. At this time, the hand training project is very suitable.
4, Actual combat cases
Optical theory is useless. We should learn to knock together and practice, so as to apply what we have learned to practice. At this time, we can make some practical cases to learn.
5, Interview materials
We must learn Python in order to find a high paying job. The following interview questions are the latest interview materials from front-line Internet manufacturers such as Alibaba, Tencent and byte, and Alibaba boss has given authoritative answers. After brushing this set of interview materials, I believe everyone can find a satisfactory job.
This complete set of Python learning materials has been uploaded to CSDN. Friends can scan the official authentication QR code of CSDN below on wechat and get it for free [guaranteed to be 100% free]
