catalogue
1. Definition of sub database and sub table
2. Case of sub database and sub table
Sharding JDBC is ShardingSphere One of the products of the ecosystem.
ShardingSphere is an ecosystem composed of a set of open-source distributed database middleware solutions. It is composed of three independent products: sharding JDBC, sharding proxy and sharding sidecar (planned). They all provide standardized data fragmentation, distributed transaction and database governance functions, which can be applied to various application scenarios such as Java isomorphism, heterogeneous language, container, cloud native and so on.
This article refers to the official documents: https://shardingsphere.apache.org/document/legacy/3.x/document/cn/overview/
1. Definition of sub database and sub table
The sub warehouse and sub table includes two parts: sub warehouse and sub table. In production, it usually includes four methods: vertical (vertical) sub table, vertical (vertical) sub warehouse, horizontal sub warehouse and horizontal sub table.
It is well understood that vertical is splitting and horizontal is expanding.
- Vertical table splitting: the fields of a wide table can be divided into multiple tables according to the access frequency and whether they are large fields. This can not only make the business clear, but also improve some performance. After splitting, try to avoid associated queries from a business perspective, otherwise the performance will not pay off.
- Vertical sub database: multiple tables can be classified according to the tightness of business coupling and stored in different libraries. These libraries can be distributed in different servers, so that the access pressure is loaded by multiple servers, greatly improving the performance, and improving the business clarity of the overall architecture. Different business libraries can customize optimization schemes according to their own conditions. But it needs to solve all the complex problems caused by cross library.
- Horizontal sub database: the data of a table (by data row) can be divided into multiple different databases. Each database has only part of the data of the table. These databases can be distributed on different servers, so that the access pressure is loaded by multiple servers, which greatly improves the performance. It not only needs to solve all the complex problems brought by cross database, but also solve the problem of data routing.
- Horizontal sub table: the data of a table (by data row) can be divided into multiple tables in the same database. Each table has only part of the data of this table. This can slightly improve the performance. It is only used as a supplementary optimization of horizontal sub database.
2. Case of sub database and sub table
Now there is a user table t_user, it is planned to adopt horizontal sub database and sub table. According to the database, the data is divided into 2 sheets and stored in the table on average. Self increasing user_id module for routing.
(1) Algorithm analysis: assume 10 data, user_id is 1 ~ 10.
- First, it is divided into two libraries on average, user_ If the result of ID% 2 is 0 or 1, name the two libraries (actually data sources) as ds0 and ds1. The records stored in ds0 are user_ The ID is 2, 4, 6, 8 and 10, and the record stored in ds1 is user_id is 1, 3, 5, 7, 9.
- Then, each database is divided into two tables on average. How? user_id%4: if the result of ds0 is 0 or 2, the two tables can be named t_user0 and t_user2; If the result of ds1 is 1 or 3, the two tables can be named t_user1 and t_user3.
- To sum up, the sub warehouse adopts user_id%2(2 libraries), user is used in the sub table_ ID% 4 (4 tables). The final storage condition is: 4 and 8 are saved to DS0 t_ User0, 2, 6 and 10 are saved to DS0 t_ User2, 1, 5 and 9 are saved to DS1 t_ User1, 3 and 7 are saved to DS1 t_ user3.
Based on this, we establish two libraries and four tables: DS0 t_ user0,ds0.t_user2,ds1.t_user1,ds1.t_user3. Examples are as follows (do not worry about whether it is standard or not)
CREATE TABLE `t_user0` ( `user_id` bigint unsigned NOT NULL COMMENT 'Primary key', `name` varchar(64) NOT NULL COMMENT 'full name', PRIMARY KEY (`user_id`) USING BTREE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='User table'
(2) Create a new Spring Boot project and introduce dependencies
<!-- for spring boot -->
<dependency>
<groupId>io.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>3.1.0</version>
</dependency>(3) Configure properties yml
sharding:
jdbc:
datasource:
names: ds0,ds1
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/ds0
username: root
password: 123456
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/ds1
username: root
password: 123456
config:
sharding:
# Data slicing
default-database-strategy:
inline:
sharding-column: user_id
algorithm-expression: ds$->{user_id % 2}
tables:
t_user:
actual-data-nodes: ds$->{0..1}.t_user$->{0..3}
key-generator-column-name: user_id
# Built in: SNOWFLAKE, UUID
key-generator-class-name: cn.zhh.keygen.AutoIncrementKeyGenerator
table-strategy:
inline:
sharding-column: user_id
algorithm-expression: t_user$->{user_id % (2 * 2)}For the convenience of testing, we just wrote one of the primary key generators (in fact, we can't do this, so we have to adopt the distributed ID scheme).
package cn.zhh.keygen;
import io.shardingsphere.core.keygen.KeyGenerator;
import java.util.concurrent.atomic.AtomicLong;
/**
* Self incrementing primary key generator
*/
public class AutoIncrementKeyGenerator implements KeyGenerator {
private static final AtomicLong KEY_GENERATOR = new AtomicLong(1L);
@Override
public Number generateKey() {
return KEY_GENERATOR.getAndIncrement();
}
}(4) Testing
We directly use the JdbcTemplate operation to insert 10 records and automatically generate their users_ ID is 1 ~ 10.
@Test
public void testInsert() {
for (int i = 0; i < 10; i++) {
String sql = String.format("insert into t_user (name) values ('%s')", UUID.randomUUID().toString());
jdbcTemplate.execute(sql);
}
}The result is as I expected, such as DS0 t_ Data for user0

3. Read write separation case
We set slave0 as the slave Library of ds0 and slave1 as the slave Library of ds1. If you are lazy and save time, you won't build a real master-slave. You can directly use Navicat's data transmission tool to synchronize the structure and data of ds0 and ds1 to slave0 and slave1 respectively, even if it is configured ###.
Modify the properties Configuration of YML
sharding:
jdbc:
datasource:
names: ds0,ds1,slave0,slave1
ds0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/ds0
username: root
password: 123456
ds1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/ds1
username: root
password: 123456
slave0:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/slave0
username: root
password: 123456
slave1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://ip:port/slave1
username: root
password: 123456
config:
sharding:
# Data slicing
default-database-strategy:
inline:
sharding-column: user_id
algorithm-expression: ds$->{user_id % 2}
tables:
t_user:
actual-data-nodes: ds$->{0..1}.t_user$->{0..3}
key-generator-column-name: user_id
# Built in: SNOWFLAKE, UUID
key-generator-class-name: cn.zhh.keygen.AutoIncrementKeyGenerator
table-strategy:
inline:
sharding-column: user_id
algorithm-expression: t_user$->{user_id % (2 * 2)}
# Read write separation
master-slave-rules:
ds0:
master-data-source-name: ds0
slave-data-source-names: slave0
ds1:
master-data-source-name: ds1
slave-data-source-names: slave1In order to see which library to read, we change the name value of the table data from the library
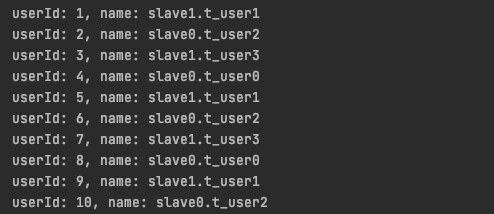
update slave0.t_user0 set name = 'slave0.t_user0'; update slave0.t_user2 set name = 'slave0.t_user2'; update slave1.t_user1 set name = 'slave1.t_user1'; update slave1.t_user3 set name = 'slave1.t_user3';
Test it
@Test
public void testSelect() {
for (int i = 0; i < 10; i++) {
int userId = i + 1;
String sql = String.format("select name from t_user where user_id = %s", userId);
String name = jdbcTemplate.queryForObject(sql, String.class);
System.out.printf("userId: %s, name: %s%n", userId, name);
}
}The result is normal
4. Other issues
Using sub database and sub table, it is inevitable to encounter some problems. Here are a few examples
(1) join, order by, limit: try to avoid / code level processing / some tools support.
(2) Distributed transaction: several schemes with strong consistency / considering final consistency / supported by some tools.
(3) Unique ID
- Snowflake algorithm (sharding JDBC built-in)
- UUID (sharding JDBC built-in)
- Redis generation
- Self augmentation generation of a special database
(4) Query of other conditions
- Mapping method: such as t_ The user needs to query according to the mobile phone number and can create a user_ Mapping table between ID and mobile.
- Redundancy method: such as t_ The user needs to register users every month, and can have a redundant copy of data routed by month.
- NoSQL middleware: full data synchronization, ES, etc.
The article case code has been uploaded to github: https://github.com/zhouhuanghua/sharding-jdbc-demo.git.