Elasticsearch installation
Declaration: jdk1 8. Minimum requirements, Elasticsearch client, interface tool!
Java development, the version of elasticsearch and the corresponding Java core jar package after us! Version correspondence! The JDK environment is normal
It must be guaranteed here
download
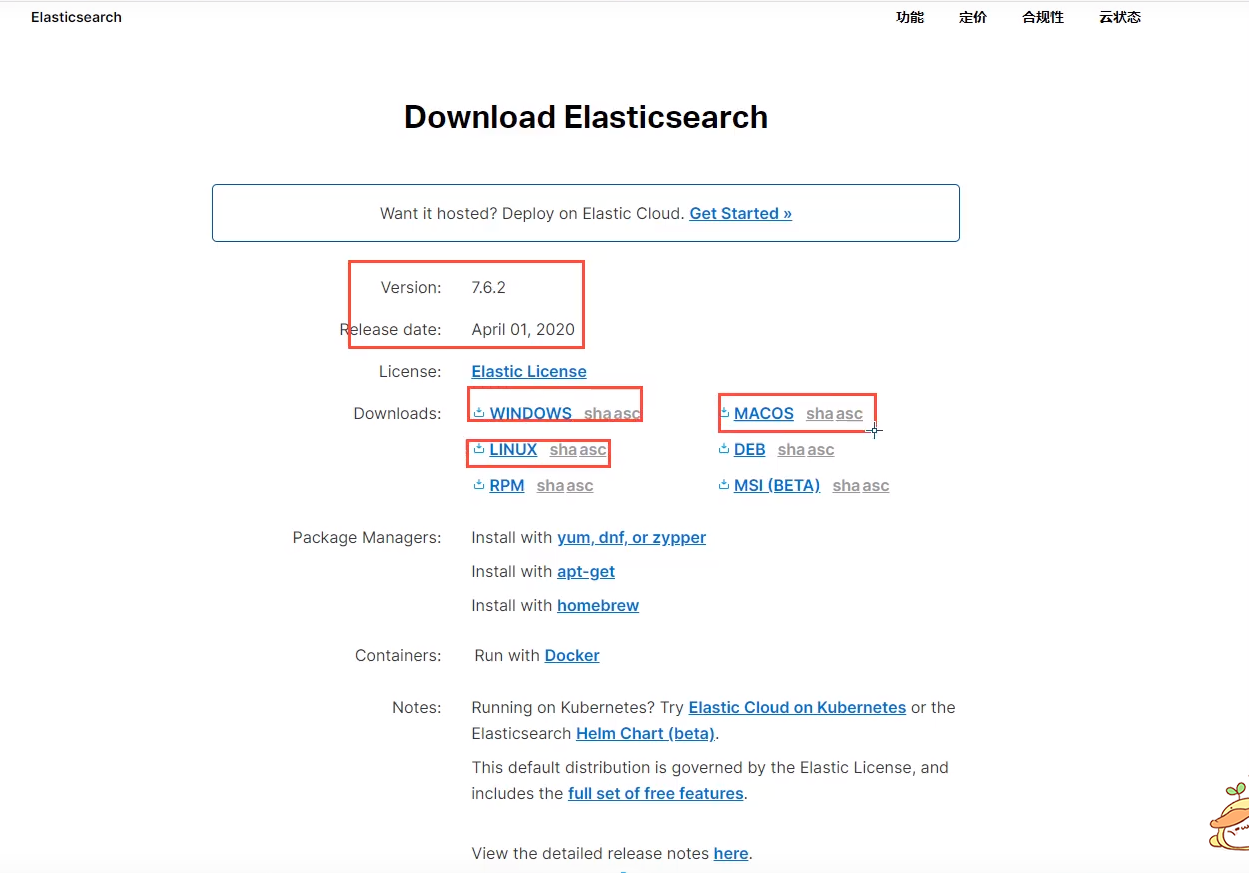
Be sure to build on the server
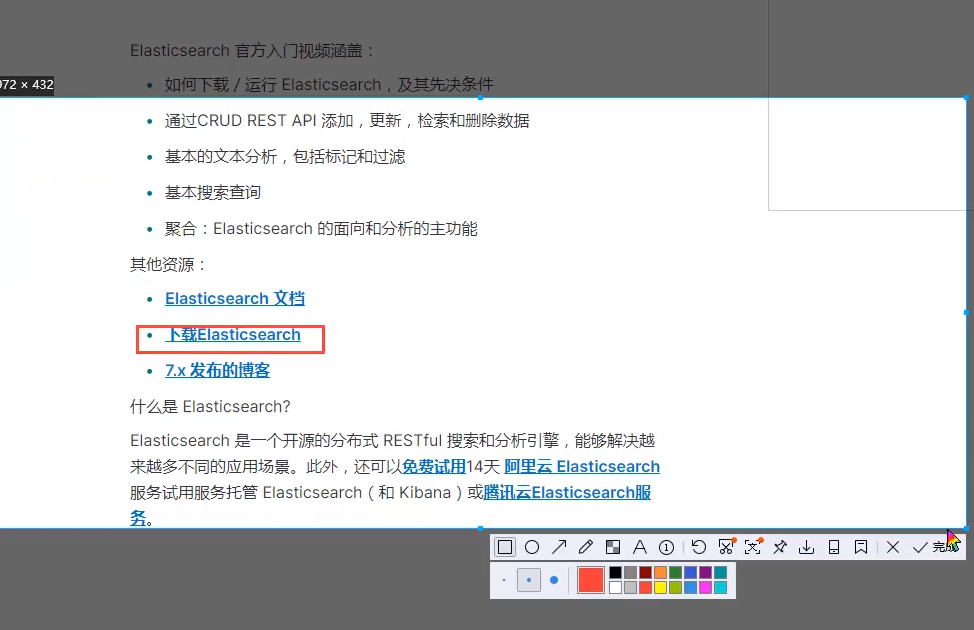
Download address: https://www.elastic.co/cn/downloads/elasticsearch
Download from the official website is extremely slow. Just go over the wall and download from the online disk
Huawei cloud: https://mirrors.huaweicloud.com/elasticsearch/7.6.2/
If we study, we can learn from both window and Linux. Now we study under window
ELK three swordsman, decompress and use! (web project! Front end environment! npm download dependency)
Node.js python2
Install under window s!
elasticSearch
Directly decompress it. Access port: 9200
elasticSearch Head:
After decompression, it can be found in config / elasticsearch Add to YML to solve cross domain problems:
http.cors.enabled: true
http.cors.allow-origin: "*"
cmd in the installation directory: install and start
cnpm install npm run start
Access port: 9100
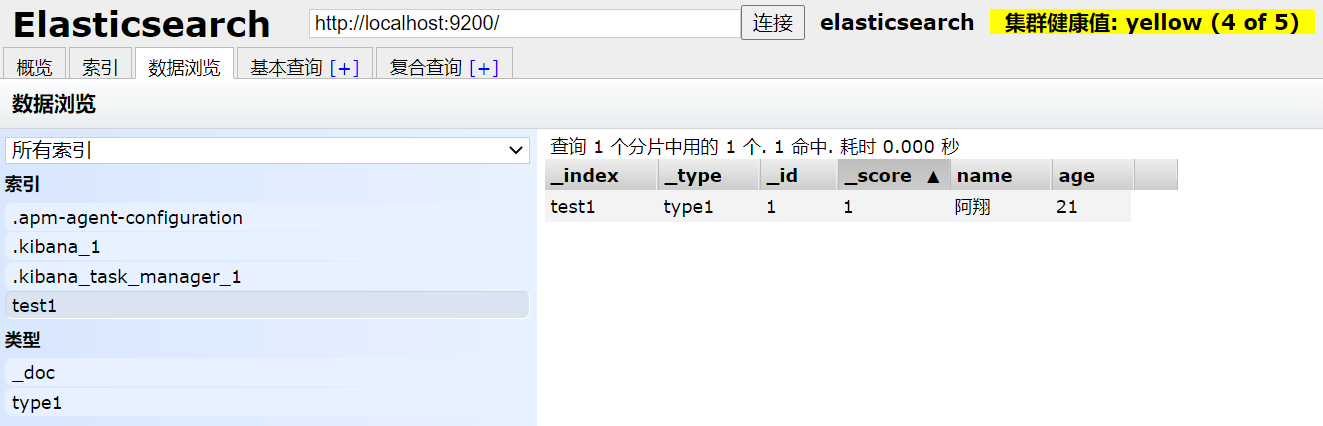
Index - new index - add: take es as a database (index (Library) and document (data in the library!)
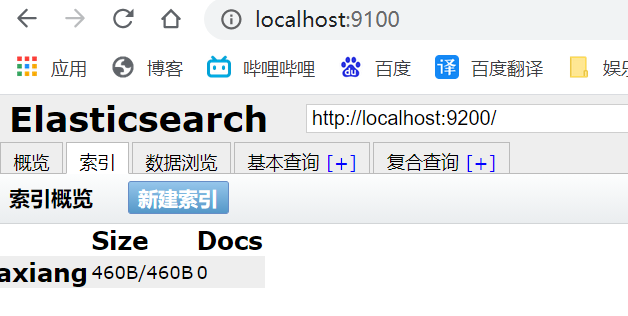
The head uses it as a data presentation tool, followed by kibana for query operations
kibana
Direct decompression
Access port: 5601
All subsequent operations are operated here
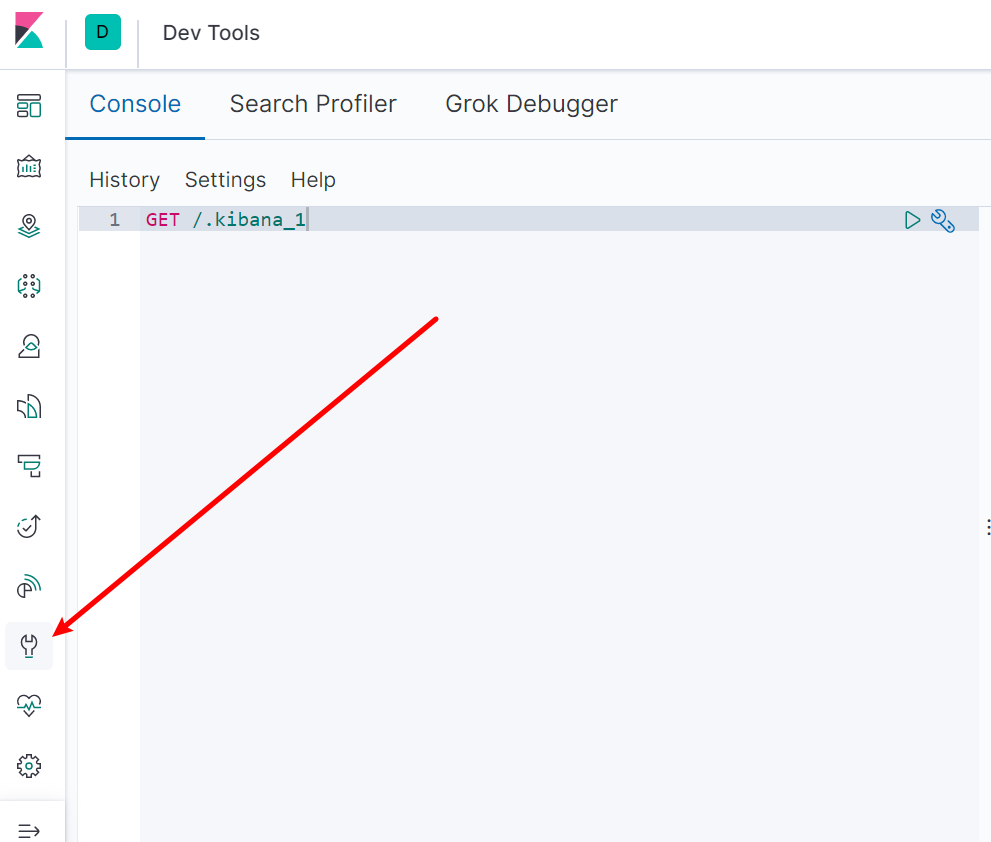
Sinicization

restart
ES core concept understanding
1. Index
2. Field type (mapping)
3. Document
summary
What is the data structure we have installed in ES and how to start the es? Let's talk about Elasticsearch first!
What are clusters, nodes, indexes, types, documents, shards, and mappings
Elasticsearch is document oriented, and the relational row database is objectively compared with elasticsearch! Everything is json
| RelationalDB | Elasticsearch |
|---|---|
| Database | Indexes |
| Tables | types (version 7 and later will be discarded, default _doc) |
| Rows | documents |
| Fields (columns) | fields |
Document oriented document oriented~
An elastic search (cluster) can contain multiple indexes (databases), and each index can contain multiple types (tables). Each type first contains multiple documents (rows), and each document contains multiple fields (columns)
physical design
Elastic search divides each index into multiple slices in the background, and each slice can be migrated between different servers in the cluster
A person is a cluster. The default cluster name is elasticSearch
logic design
An index type contains multiple documents, such as document 1 and document 2 When we index an article, we can find it in this order: index > type
Document id, through this combination, we can index a specific document Note: id doesn't have to be an integer, it's actually a string
| user | name | age |
|---|---|---|
| 1 | zhasna | 18 |
| 2 | kaugshen | 23 |
| 3 |
Previously, elasticsearch is document oriented, and the name is also the name. The smallest unit of indexing and searching data is the document. In elasticsearch, the document has several important attributes:
-
Self contained. A document contains both fields and corresponding values, that is, key:value!
-
It can be hierarchical. A document contains documents. That's how complex logical entities come from!
-
Flexible structure. The document does not depend on the pre-defined schema. We know that in the relational database, the field must be defined in advance before it can be used. In elastic search, the field is very flexible. Sometimes, we can ignore the field or add a new field dynamically
Although we can add or ignore a field at will, the type of each field is very important. For example, an age field type can be either string or integer Because elastic search will save the mapping between fields and types and other settings This mapping is specific to each type of each mapping, which is why types are sometimes called mapping types in elastic search
type
Type is the logical container of document. Just like relational database, table is the container of row The definition of field in type is called mapping. For example, name is mapped to string type We say that documents are modeless. They don't need to have all the fields defined in the mapping, such as adding a new field. What does elasticsearch do?
Elasticsearch will automatically add a new field to the mapping, but if the field is not sure what type it is, elasticsearch will start to guess. If the value is 18, elasticsearch will think it is an integer But elasticsearch may also be wrong. The safest way is to define the required mapping in advance. This is the same as that of relational database. First define the fields and then use them. Don't make any mistakes
Indexes
It's the database
The index is a container of mapping type, and the index in elastic search is a very large collection of documents The index stores the mapping type fields and other settings, and then they are stored on each slice Let's study how the next slice works
Physical design: how nodes and shards work
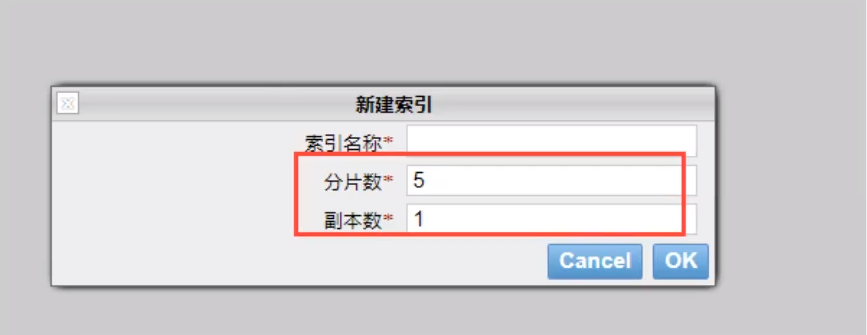
A cluster must have at least one node. A node is an elasticsearch process. A node can have multiple indexes. By default, if you create an index, the index will be composed of five primary shards, and each primary shard will have a replica (replica shard)
Inverted index
Elastic search uses a structure called inverted index, which uses Lucene inverted index as the bottom layer This structure is suitable for fast full-text search. An index consists of all non repeated lists in the document. For each word, there is a document list containing it For example, there are now two documents, each containing the following
In order to create an inverted index, we first need to split each document into independent words (or terms or tokens), then create a sorted list containing all non duplicate terms, and then list the document in which each term appears:
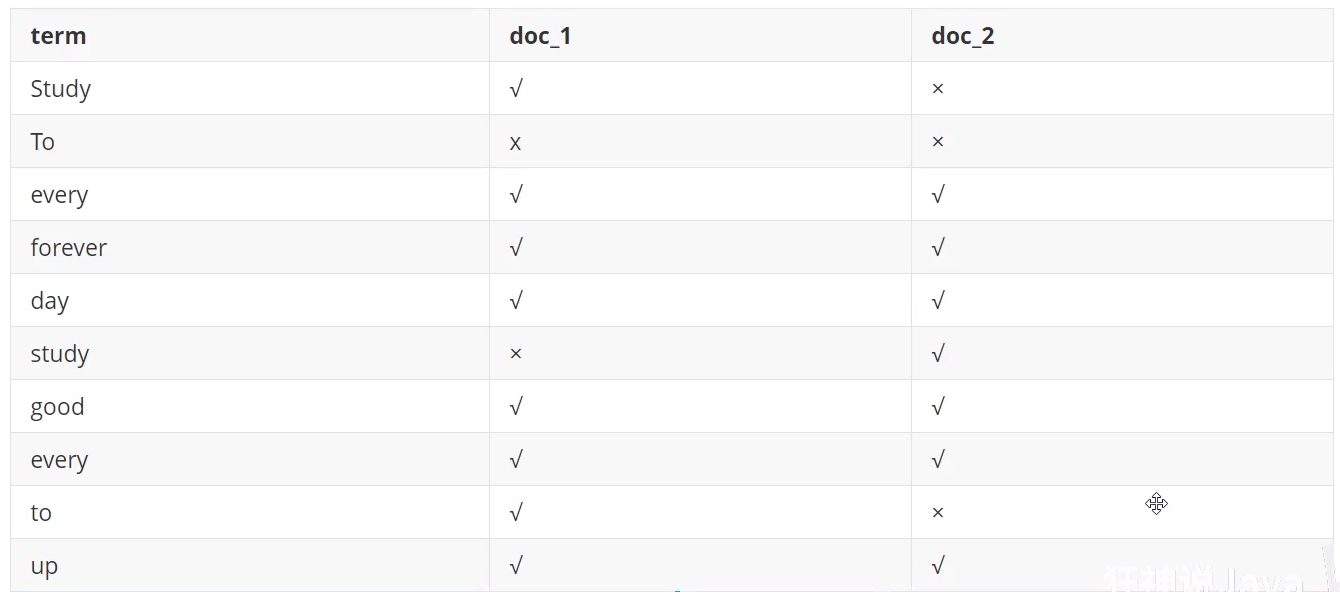
Both documents match, but the first document matches more than the second If there are no other conditions, now both documents containing keywords will be returned
| term | doc_1 | doc_2 |
|---|---|---|
| to | √ | × |
| forever | √ | √ |
| total | 2 | 1 |
Let's take another example. For example, we search blog posts through blog tags Then the inverted index list is such a structure:
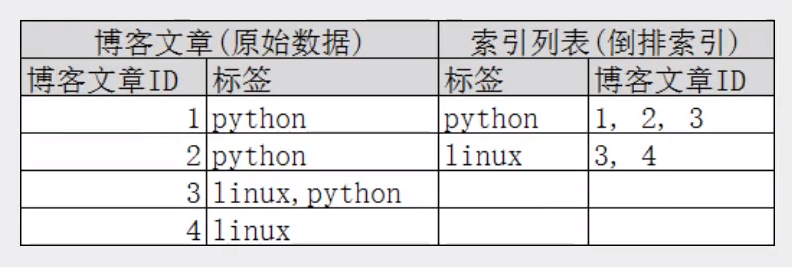
If you want to search for articles with python tags, it will be much faster to find the inverted index data than to find all the original data Just check the tag column and get the relevant article id
IK word breaker plug-in
What is a word splitter

If Chinese is used, ik word splitter is recommended
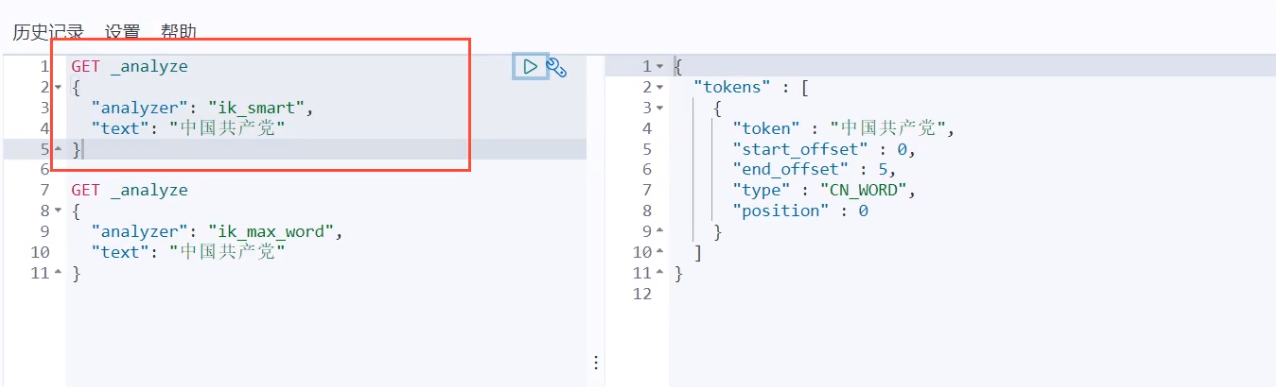
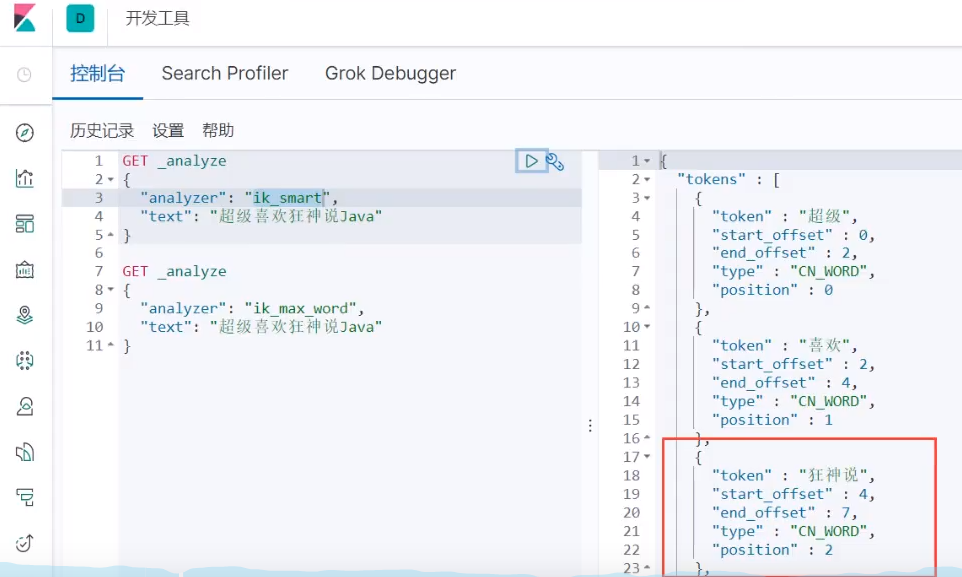
IK body uses two word segmentation algorithms: ik_smart and, where ik_smart is the least( ˉ ▽  ̄ ~) cut ~ ~, ik_max_word is the most fine-grained division! We'll test it later
install
1, https://github.com/medcl/elasticsearch-analysis-ik , the version must correspond to the ElasticSearch version
2. After downloading, put it into our elasticsearch plug-in
2.1 restart and observe ES

2.2. Elasticsearch plugin can use this command to view the loaded plug-ins

2.3. Test with kibana!
See different effects of word splitter
ik word splitter adds our own configuration
This kind of word we need needs needs to be added to our word splitter dictionary!
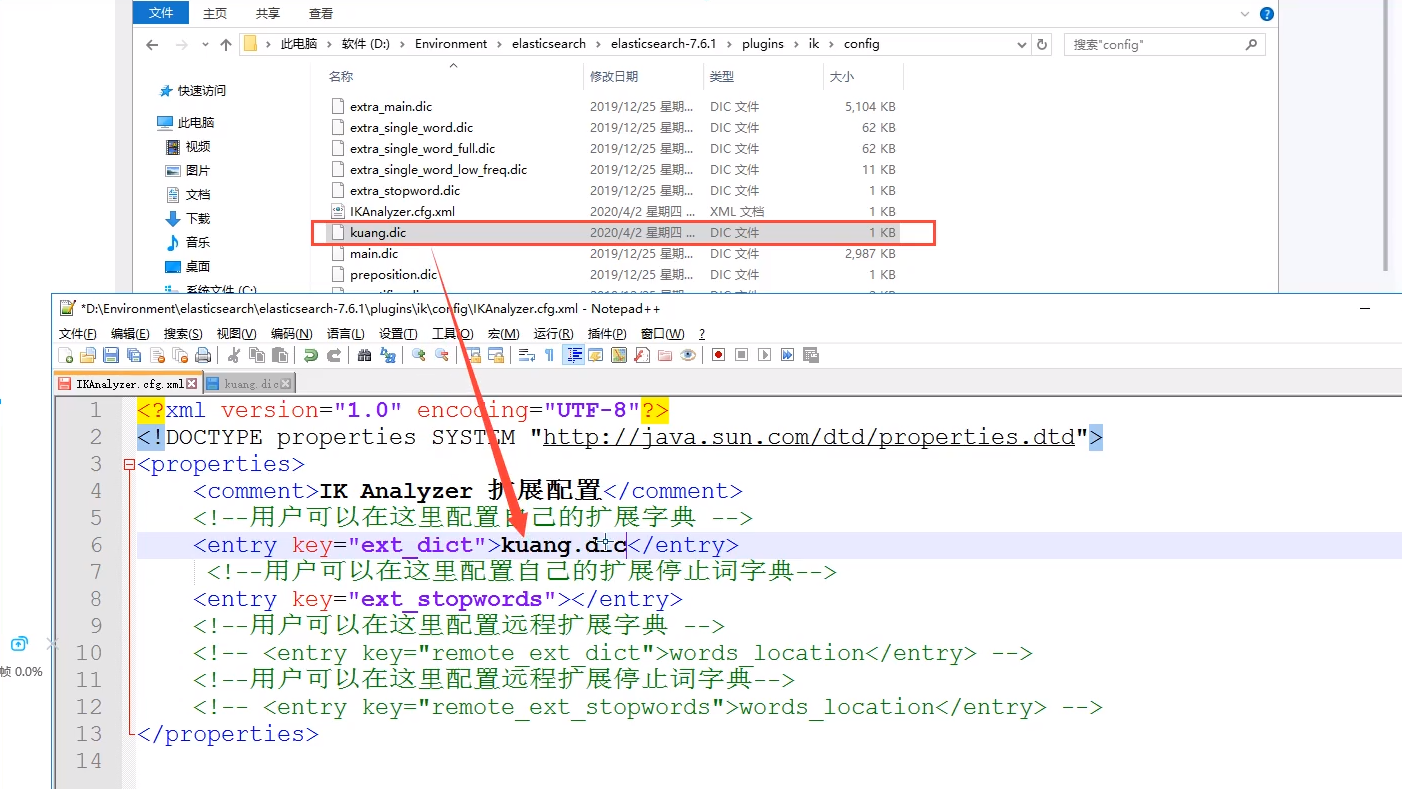
Restart ES and see the details

Test it again, and the madman said,
In the future, we need to configure our own words. We only need to configure them in the customized dic file!
Rest style description
A software architecture style, not a standard, only provides a set of design principles and constraints It is mainly used for client and server interaction software The software designed based on this style can be simpler, more hierarchical and easier to implement caching and other mechanisms
Basic Rest style command description
| method | url address | describe |
|---|---|---|
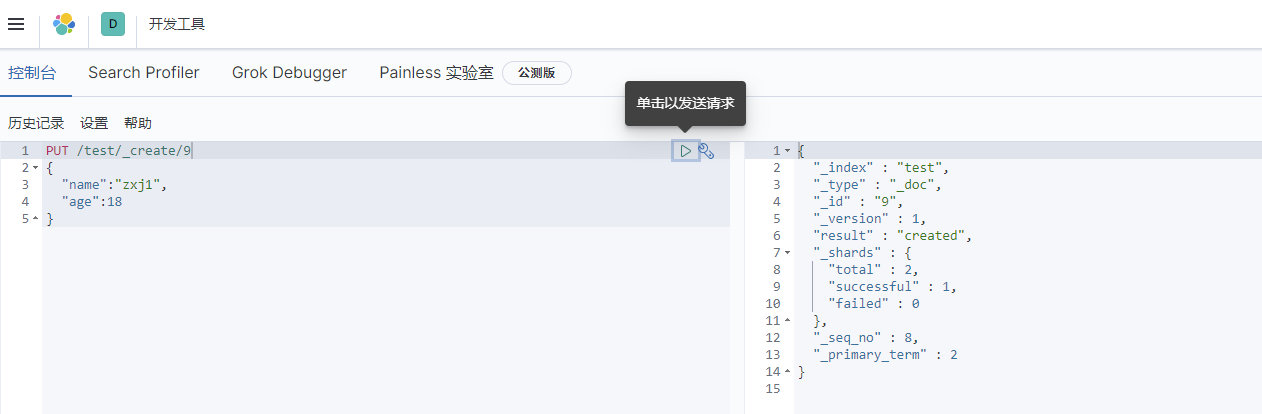
| PUT | localhost:9200 / index name / type name / document id | Create document (specify id) |
| POST | localhost:9200 / index name / type name | Create document (random document id) |
| POST | localhost:9200 / index name / type name / document id/_update | Modify document |
| DELETE | localhost:9200 / index name / type name / document id | Delete index |
| GET | localhost:9200 / index name / type name / document id | Query document by document id |
| POST | localhost:9200 / index name / type name/_ search | Query all data |
Basic test
Basic operation of index
Index indexes
mapping
Do you need to specify the type for the name field? After all, our relational database needs to specify the type mapping
1. Specifies the type of field
Create rule
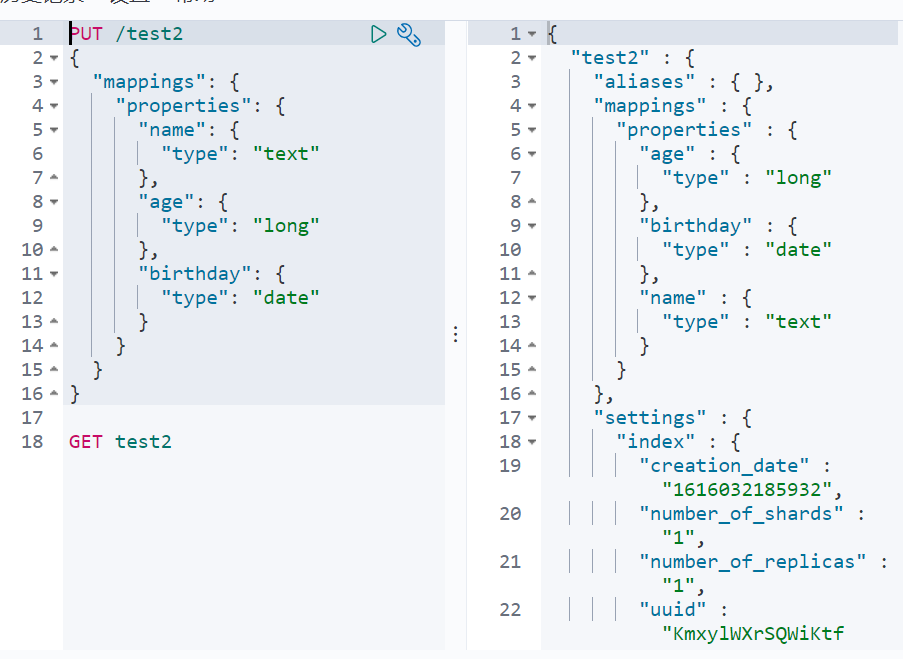
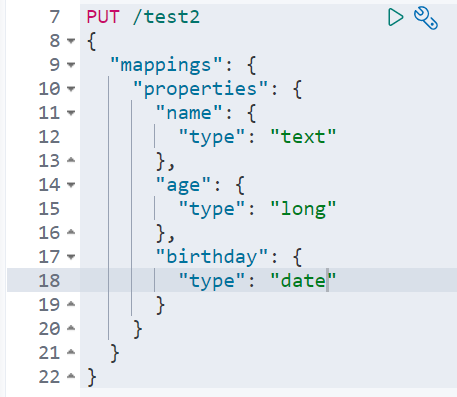
GET this rule! Specific information can be obtained through GET request
2. If mapping is not set for the index, ElasticSearch will match by default; If your document field is not specified, ES will configure the field type for us
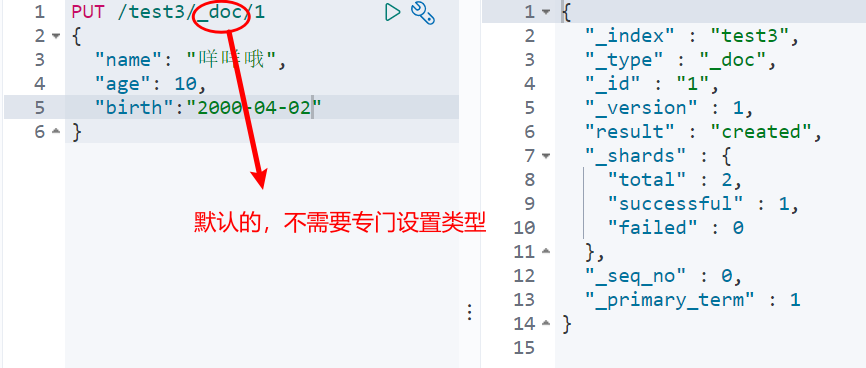
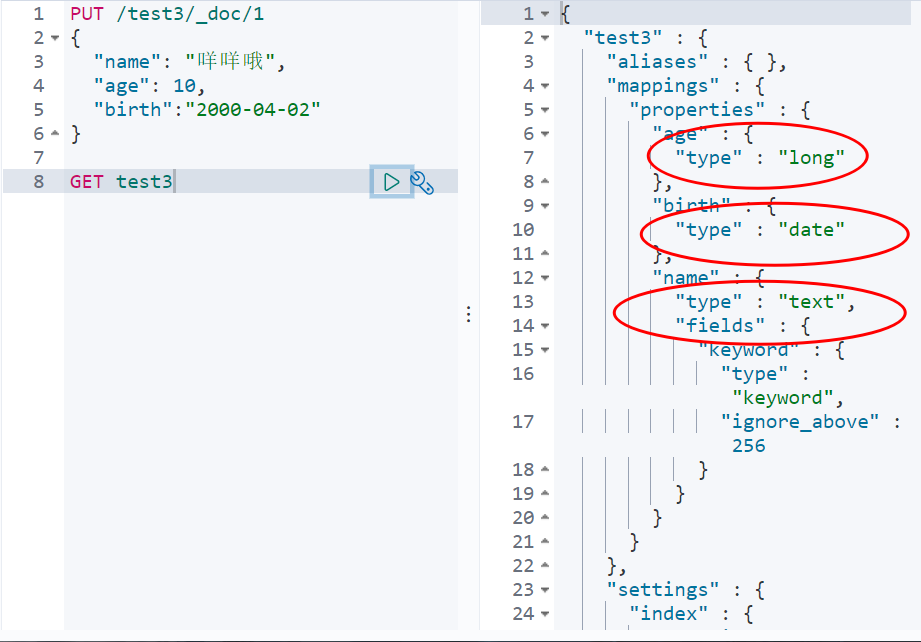
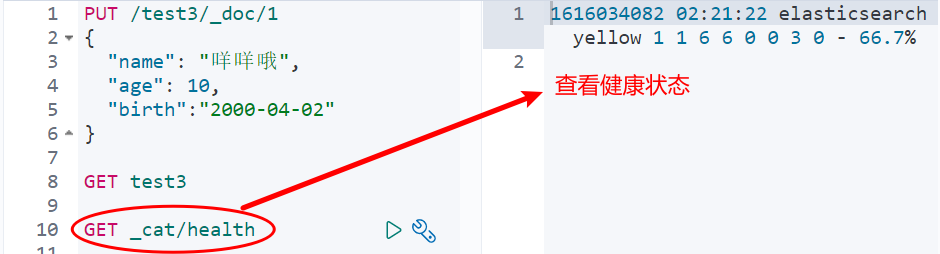
Basic operation of documents
https://www.bilibili.com/video/BV17a4y1x7zq?p=10
basic operation
Add data
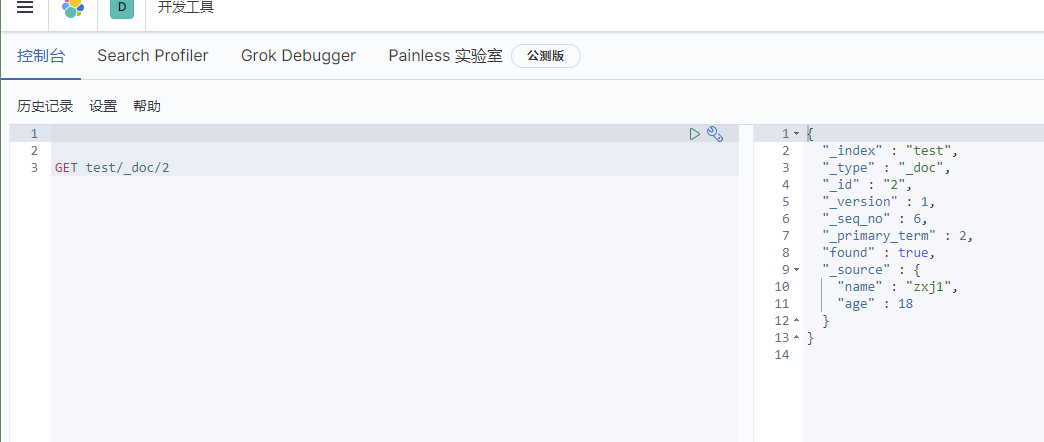
get data
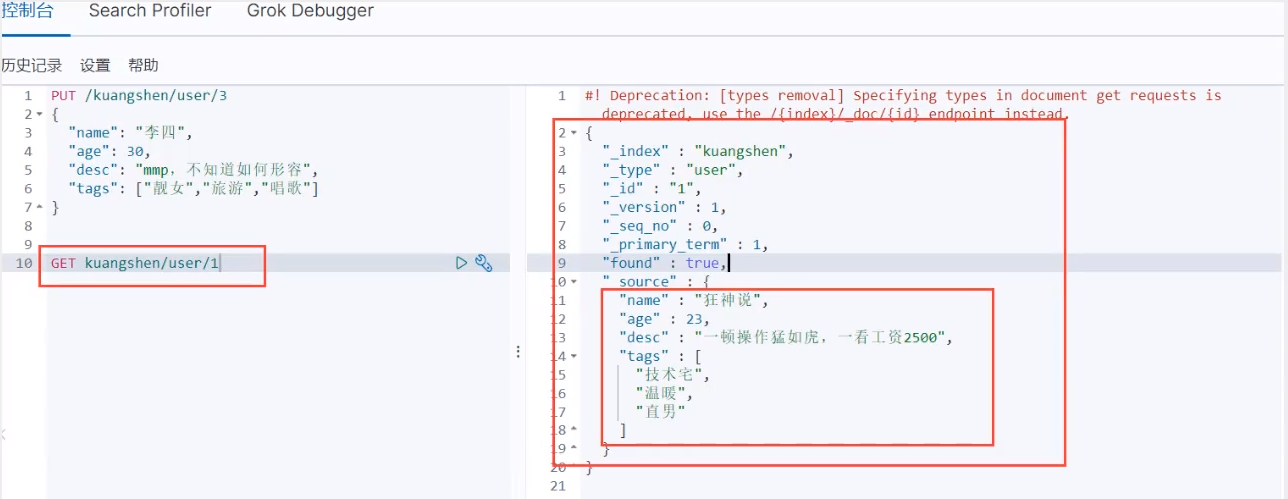
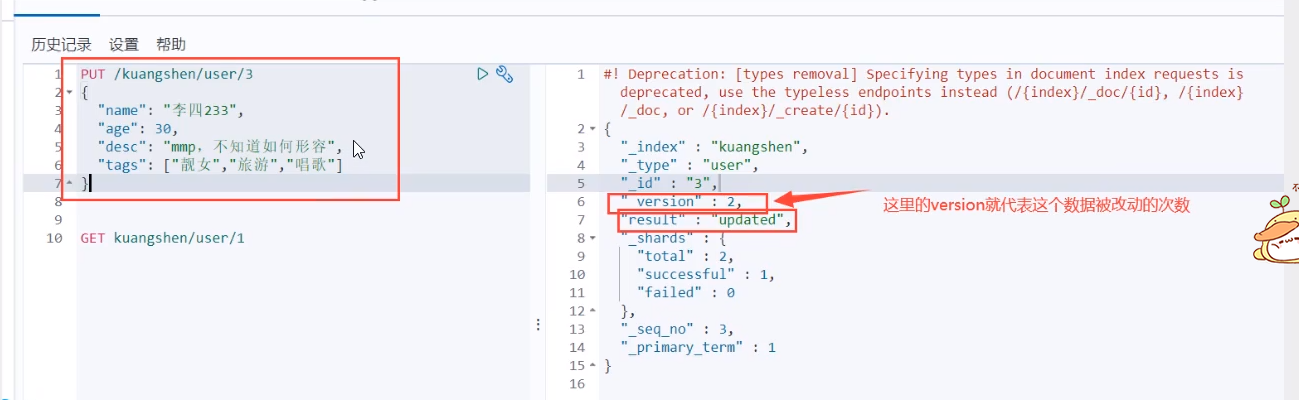
Update the data PUT. When updating, it is an overwrite update. Fields that are not updated will be overwritten and empty!
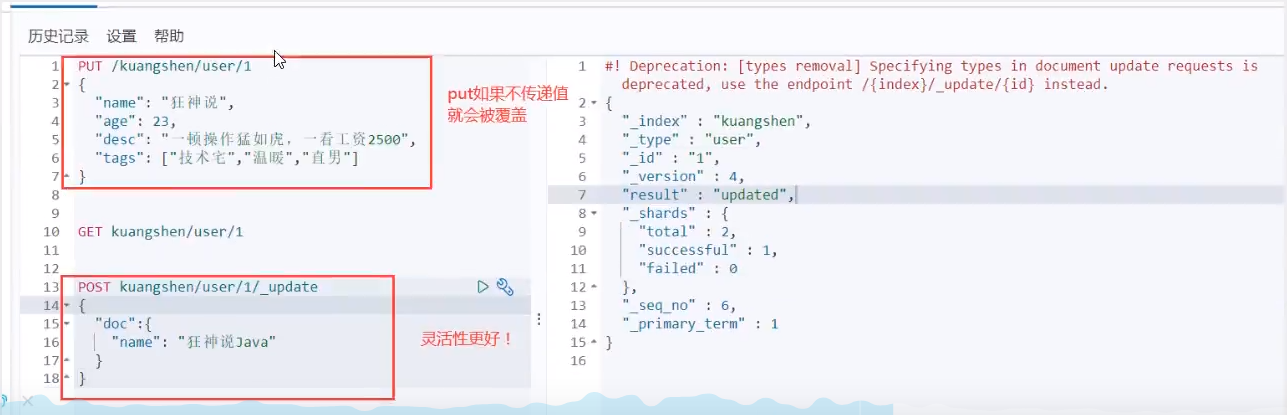
Post _update, this update method is recommended!
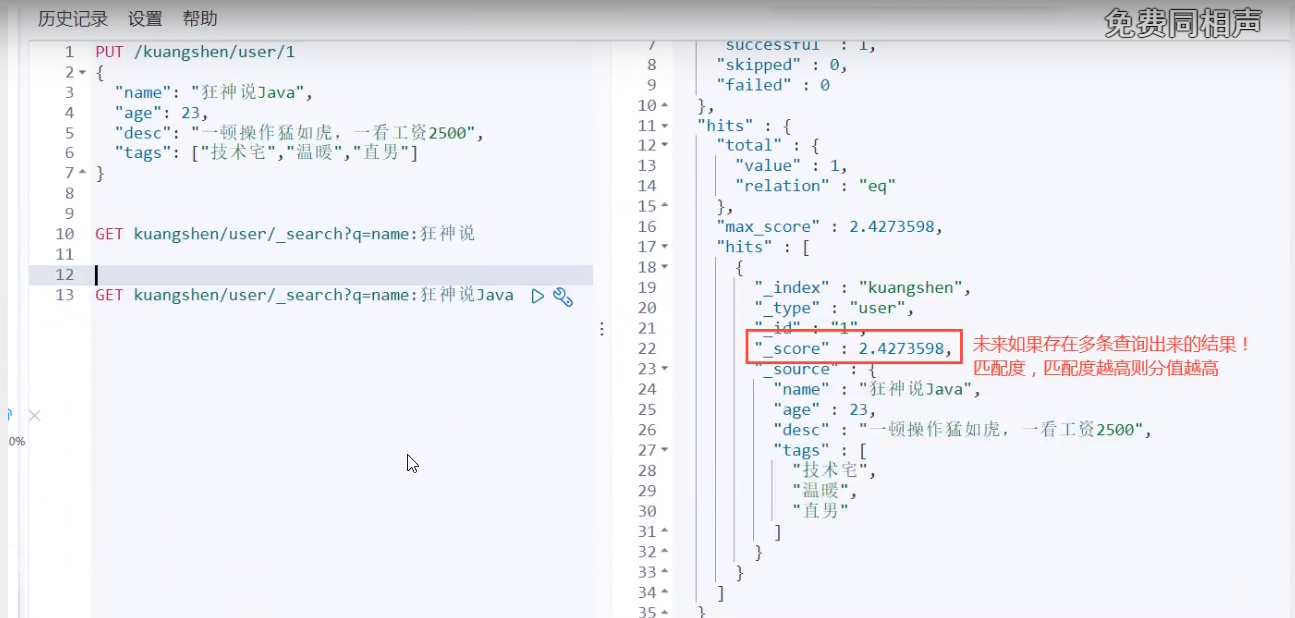
Simple search!
Simple conditional queries can generate basic queries according to the default mapping rules
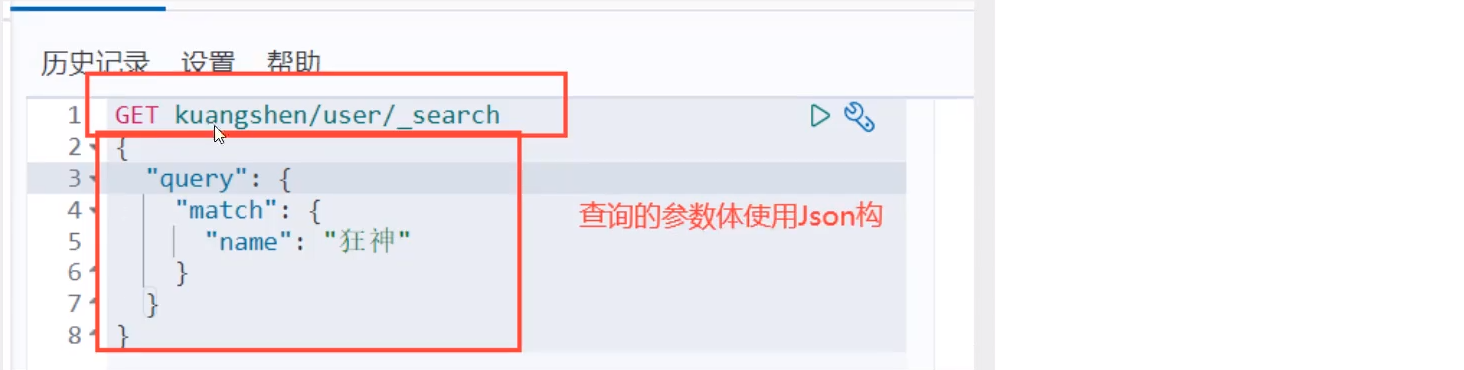
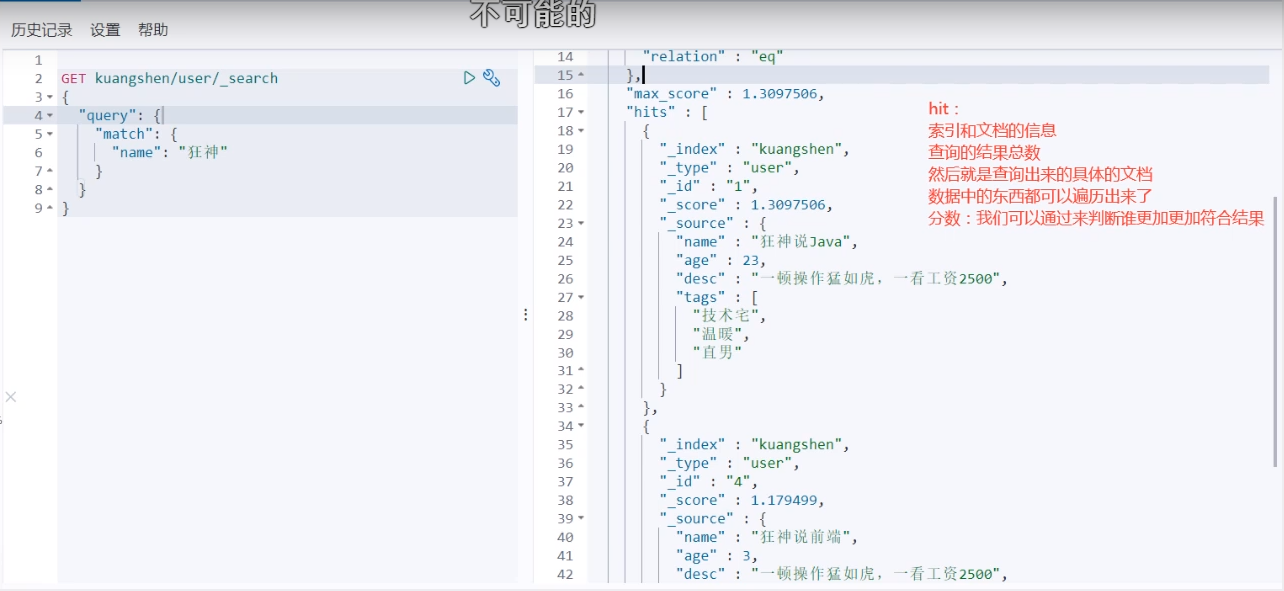
Complex operation search
Select (sorting, paging, highlighting, fuzzy query, accurate query!)
You don't want so many output results, select*
Now it's select name,age
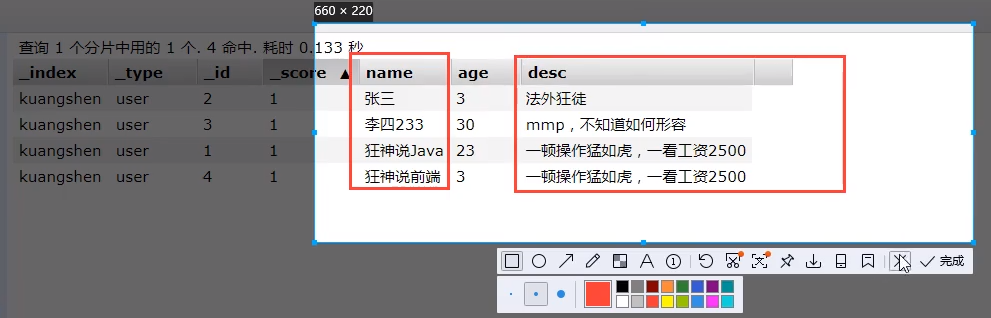
You can specify fields
Filtering of results
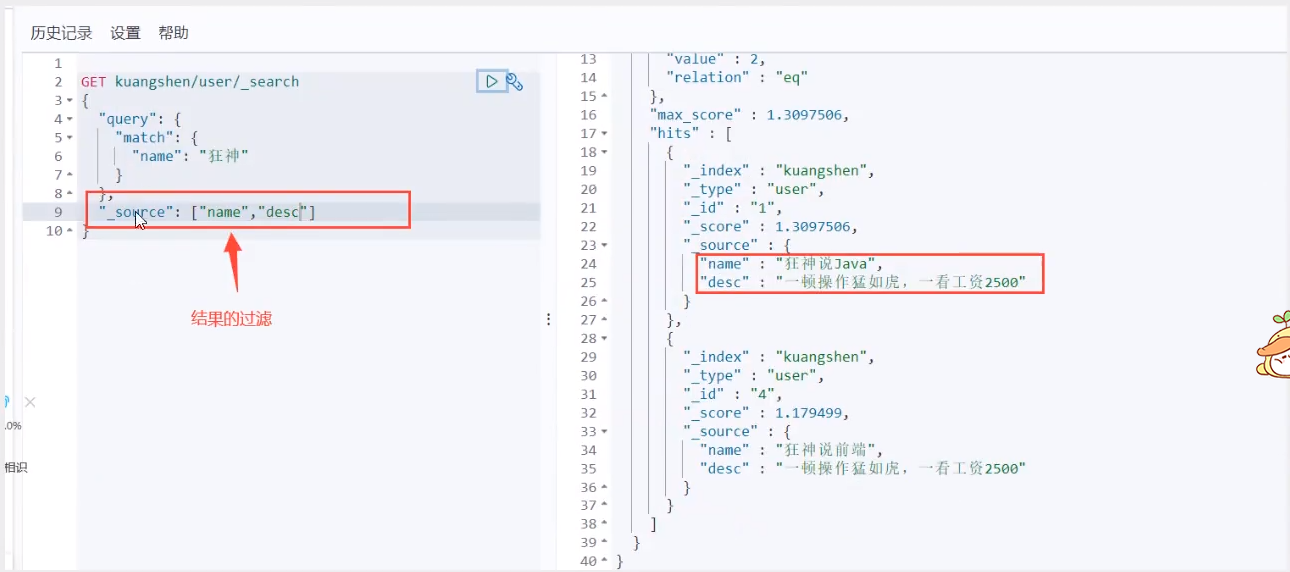
After that, we use Java to operate ES, and all methods and objects are the key s in it!
sort
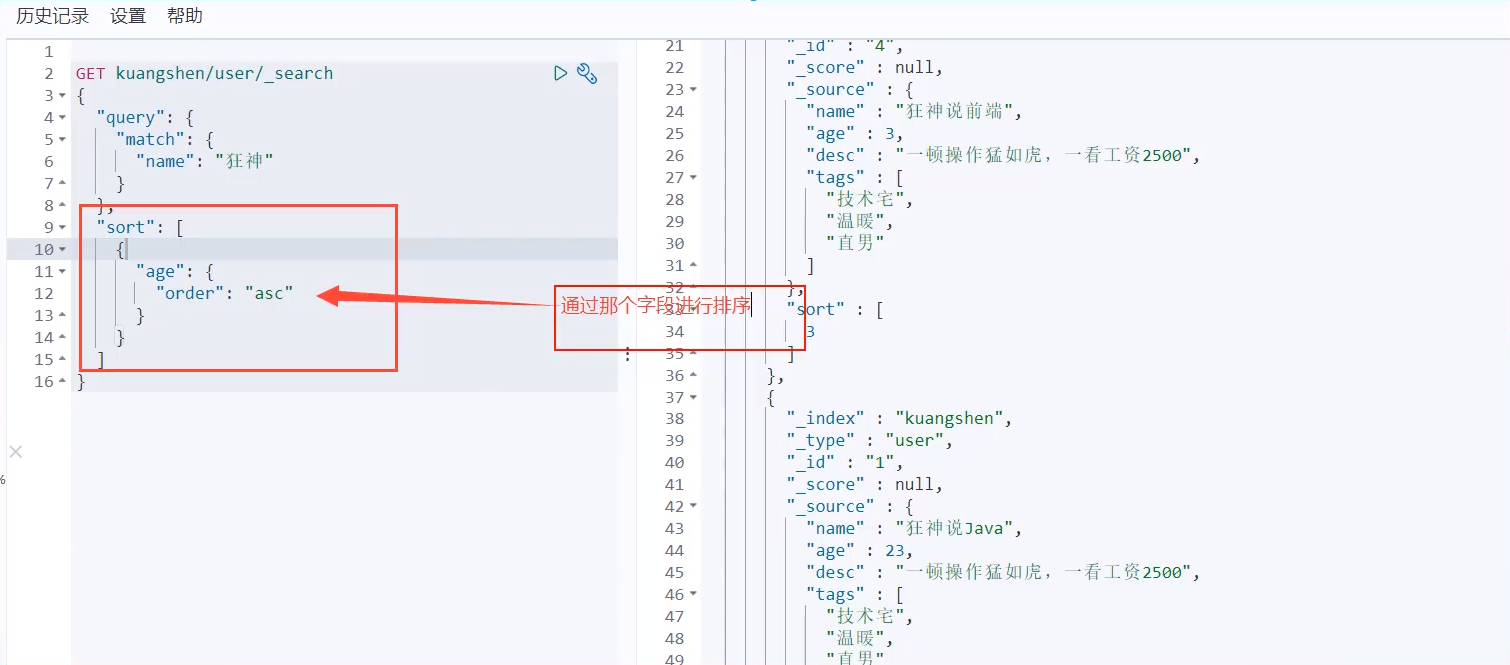
Paging query
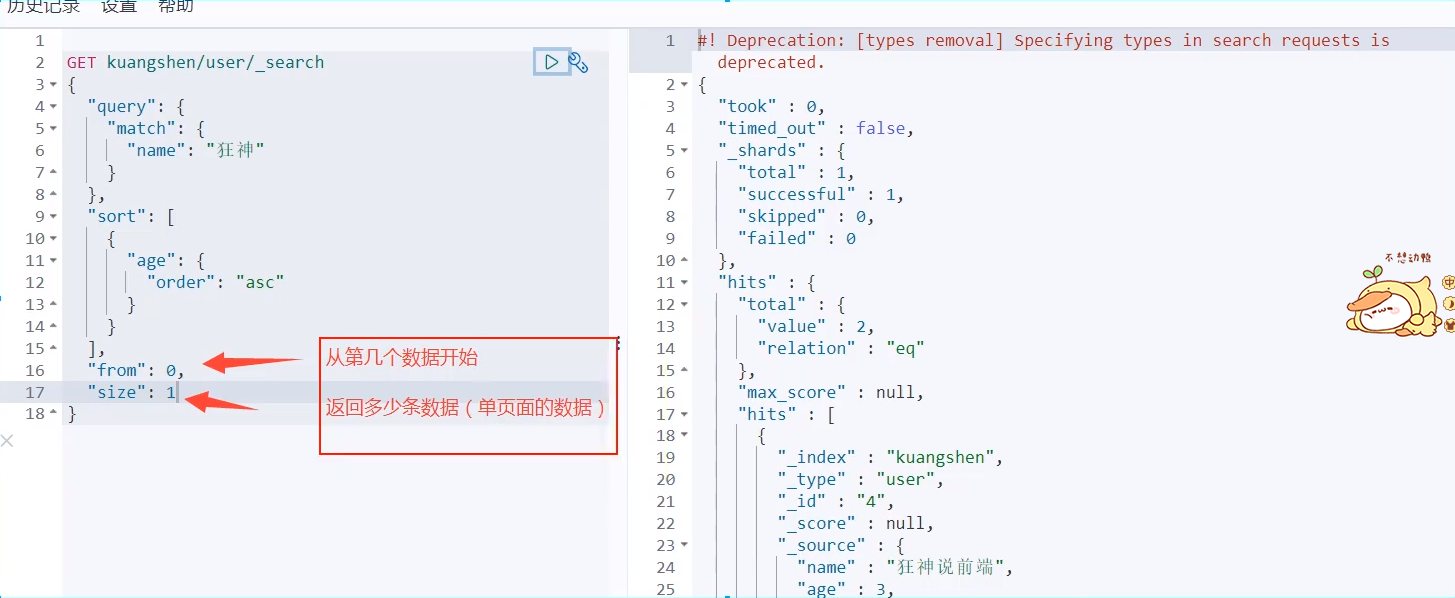
The data subscript starts from 0, which is the same as the data structure learned before!
Boolean query
must(and), all conditions must meet where id=1 and name=xxx
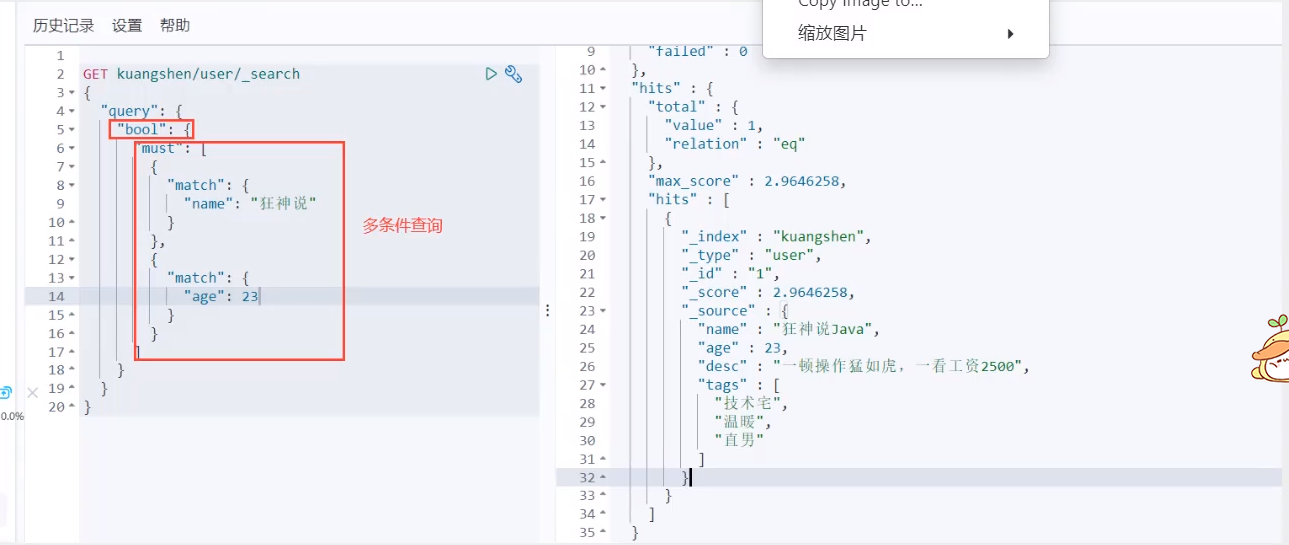
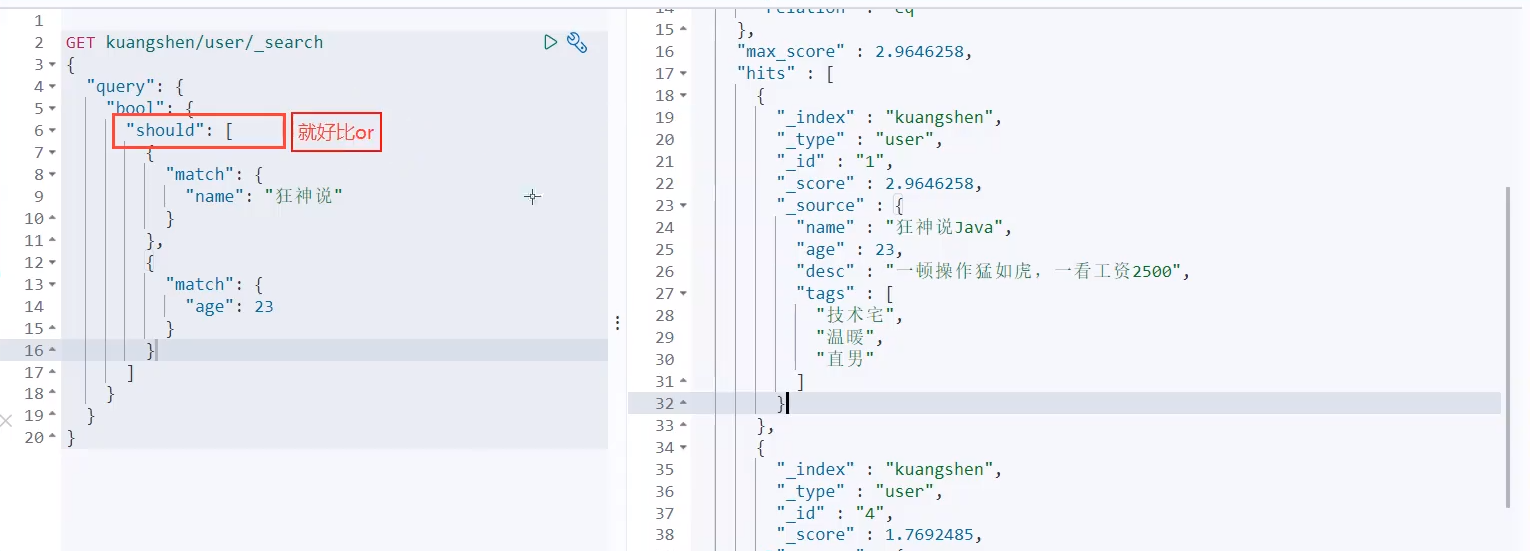
should (or), all conditions must meet where id=1 or name = xxx
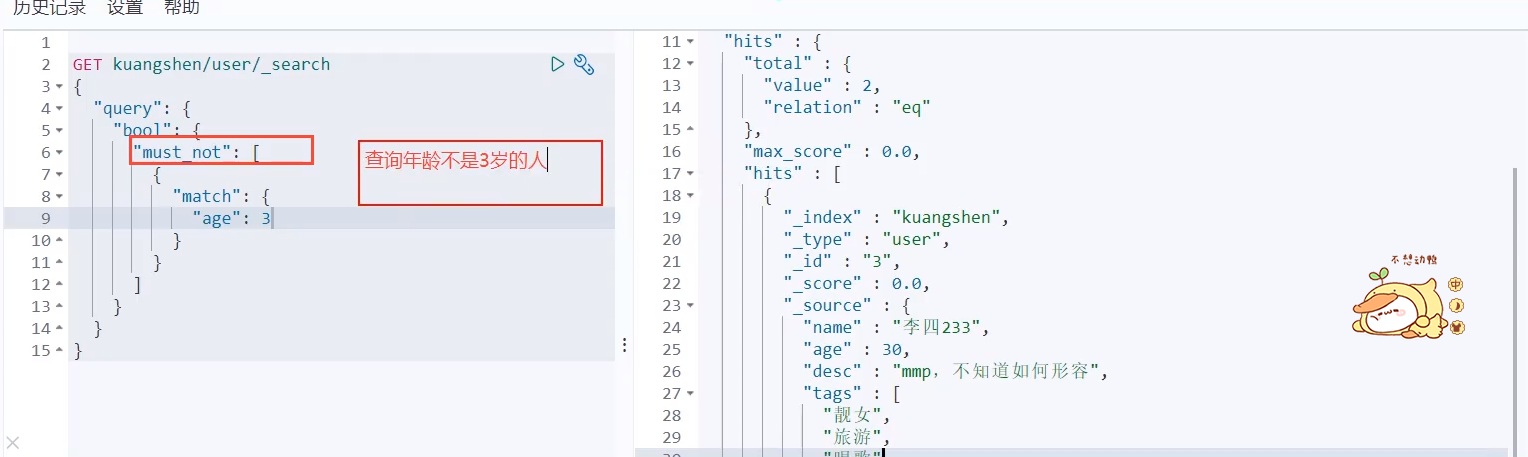
must not (not)
filter
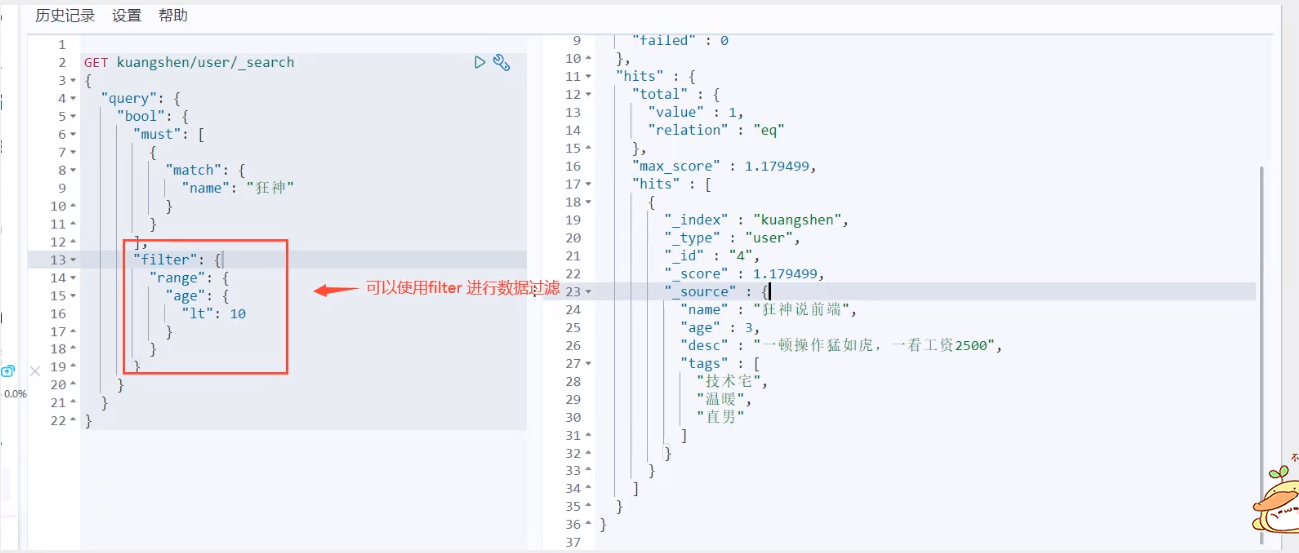
- gt greater than
gte is greater than or equal to
lt less than
lte less than or equal to
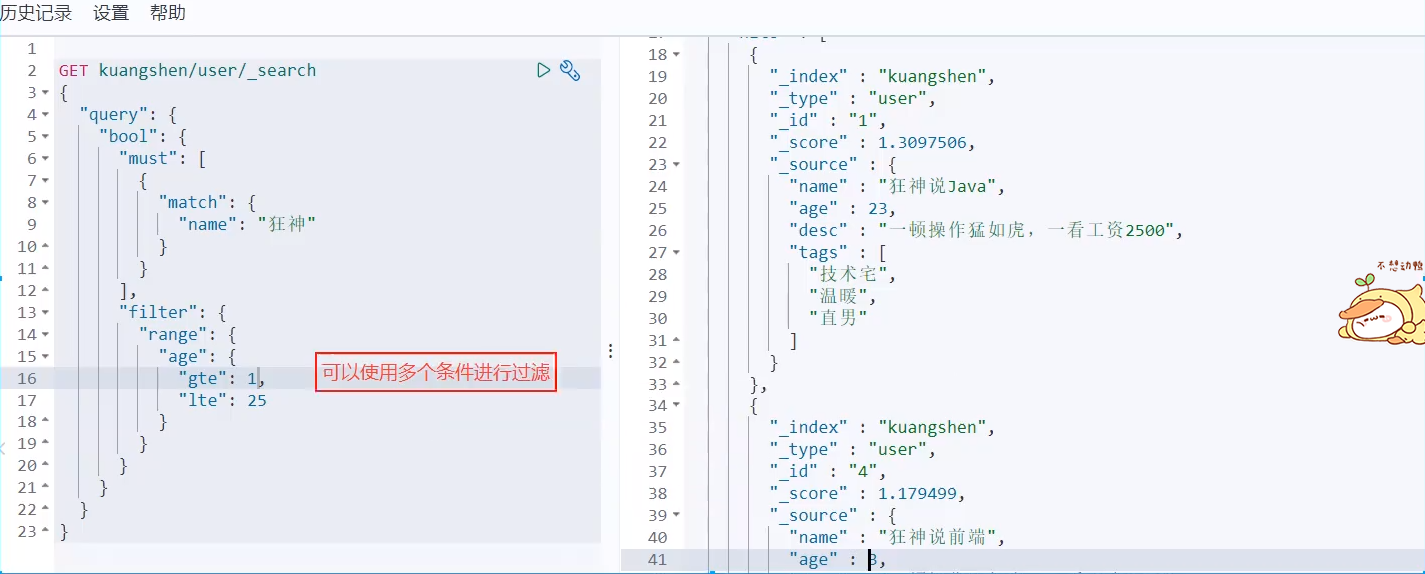
Match multiple criteria
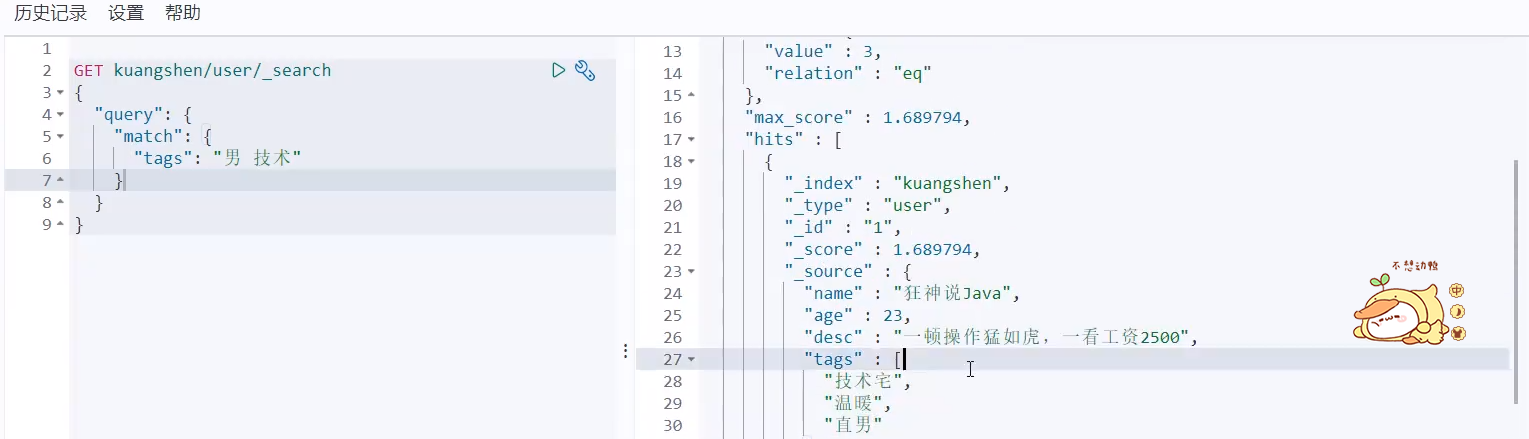
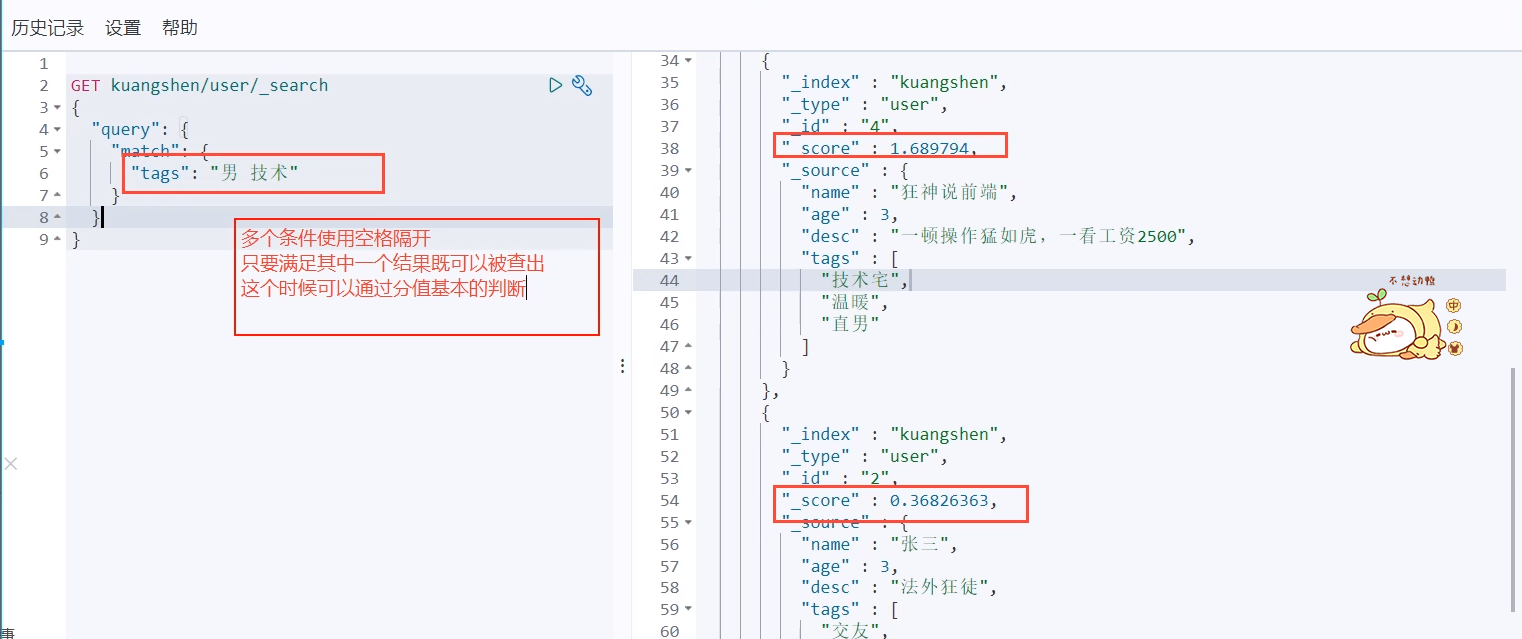
You can also separate them with spaces
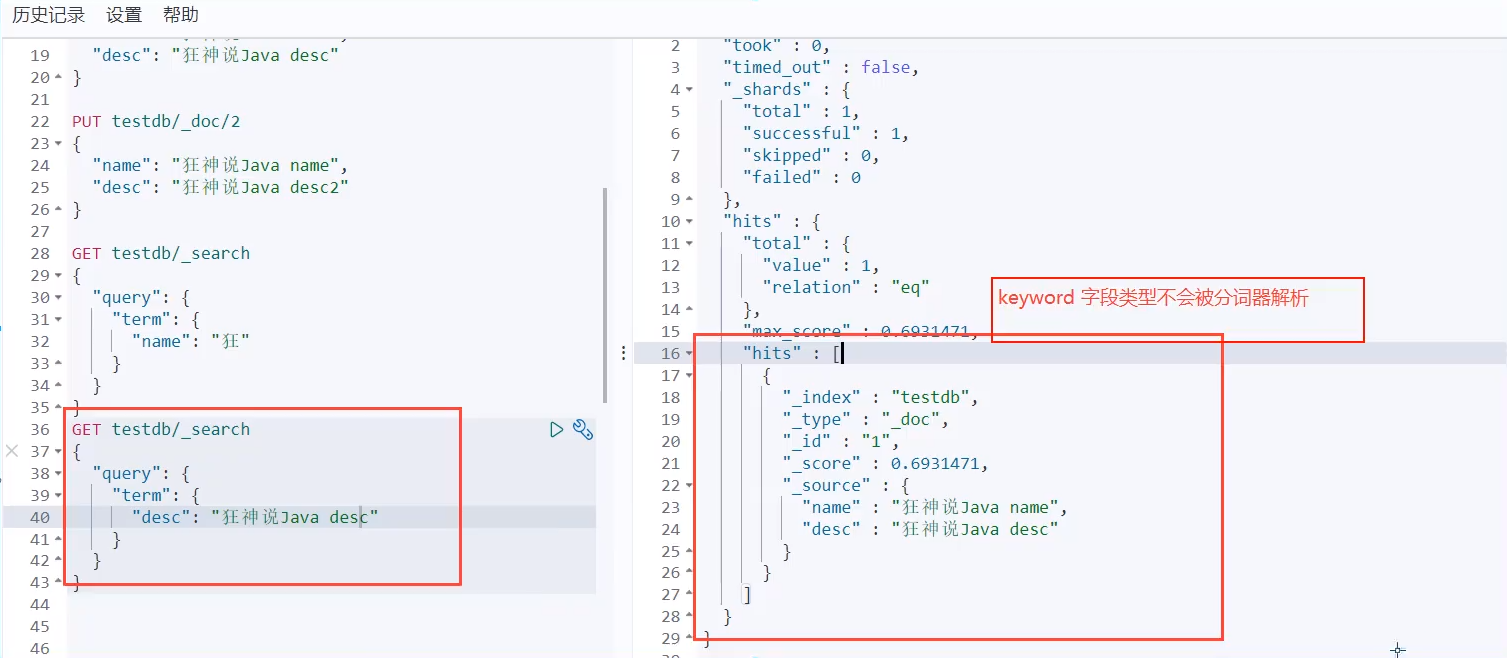
Precise query
term query directly through the inverted index specified by the entry process to accurately find!
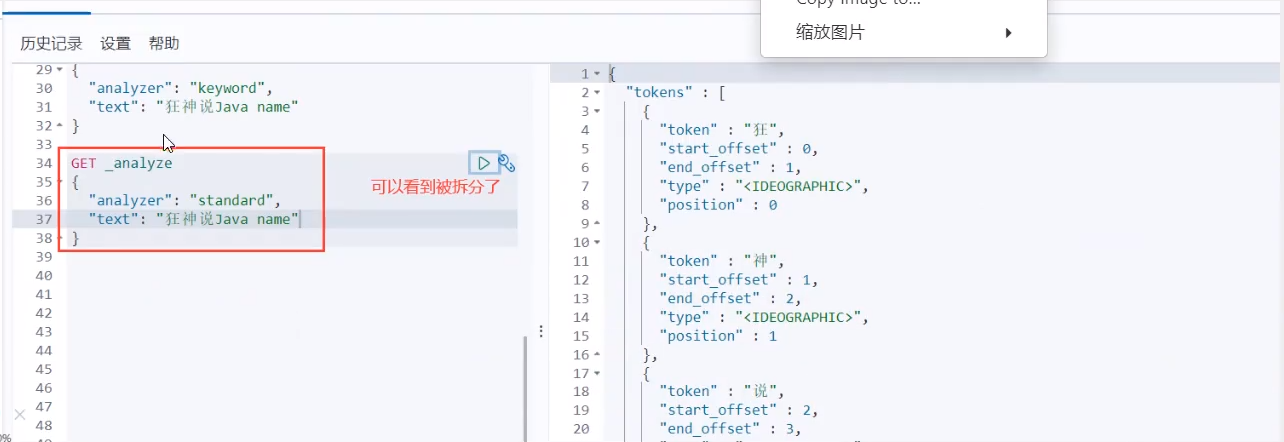
About participle:
term, direct query, accurate
match, can use the word splitter to parse! (analyze the classification first, and then query through the analyzed classification!)
Two types of text keyword
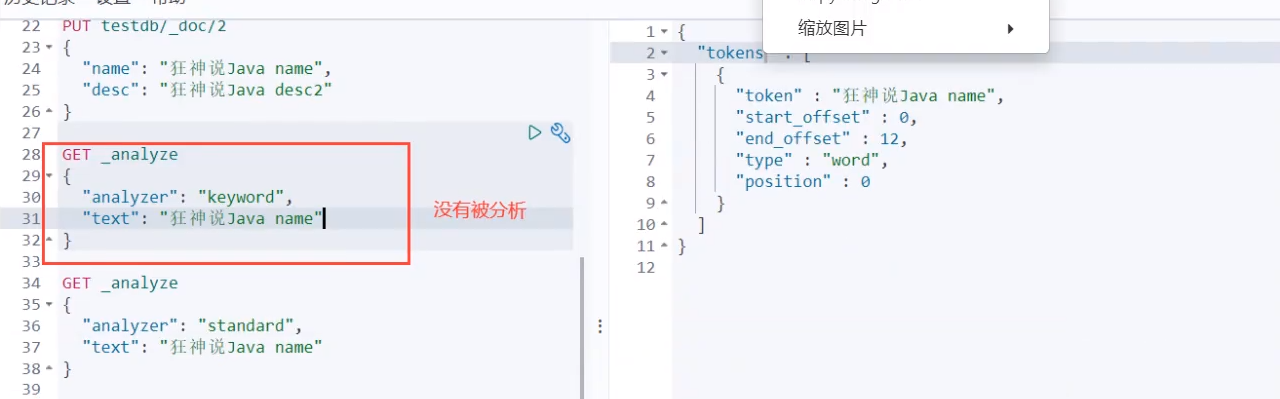
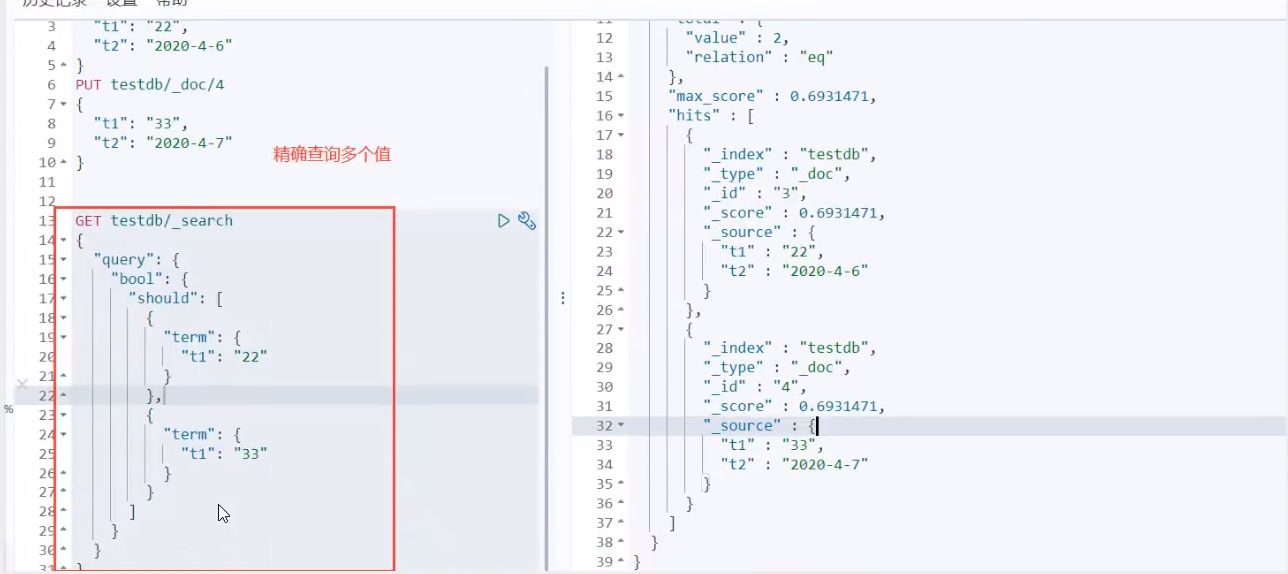
Exact match multiple values
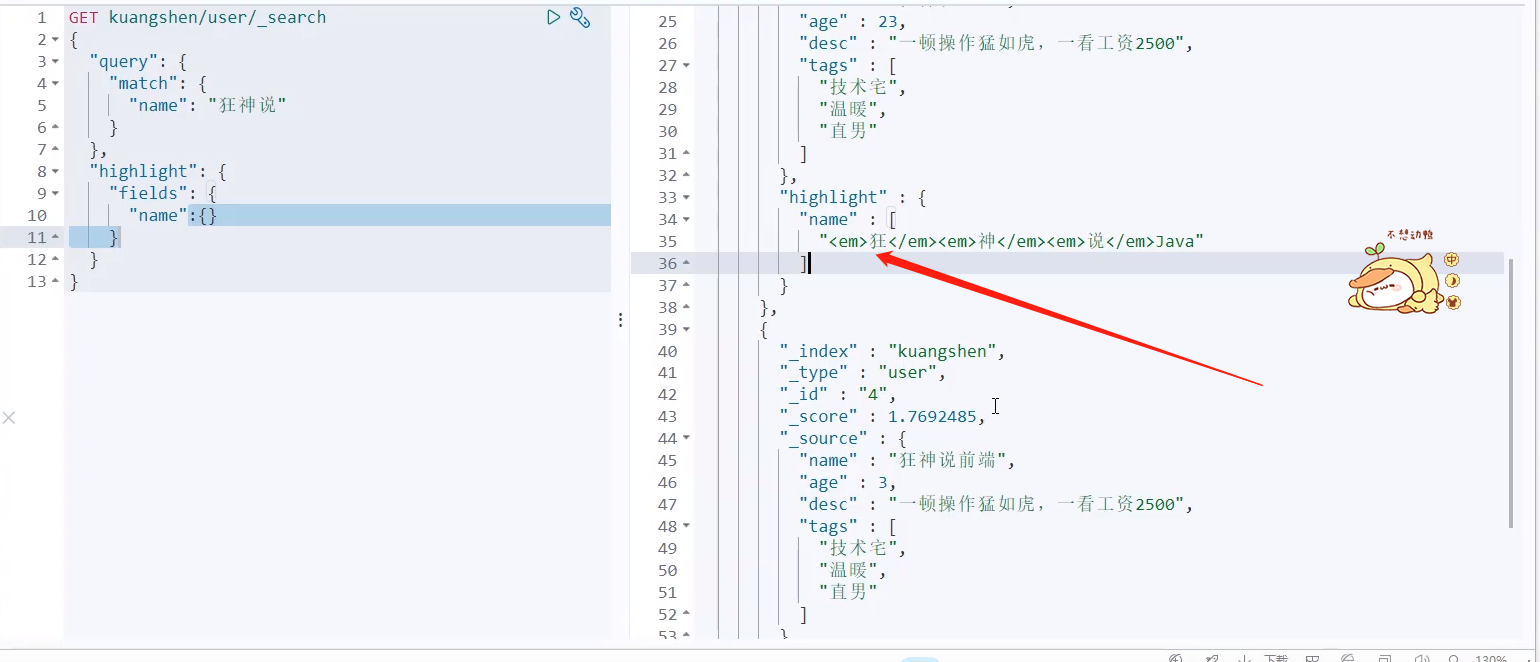
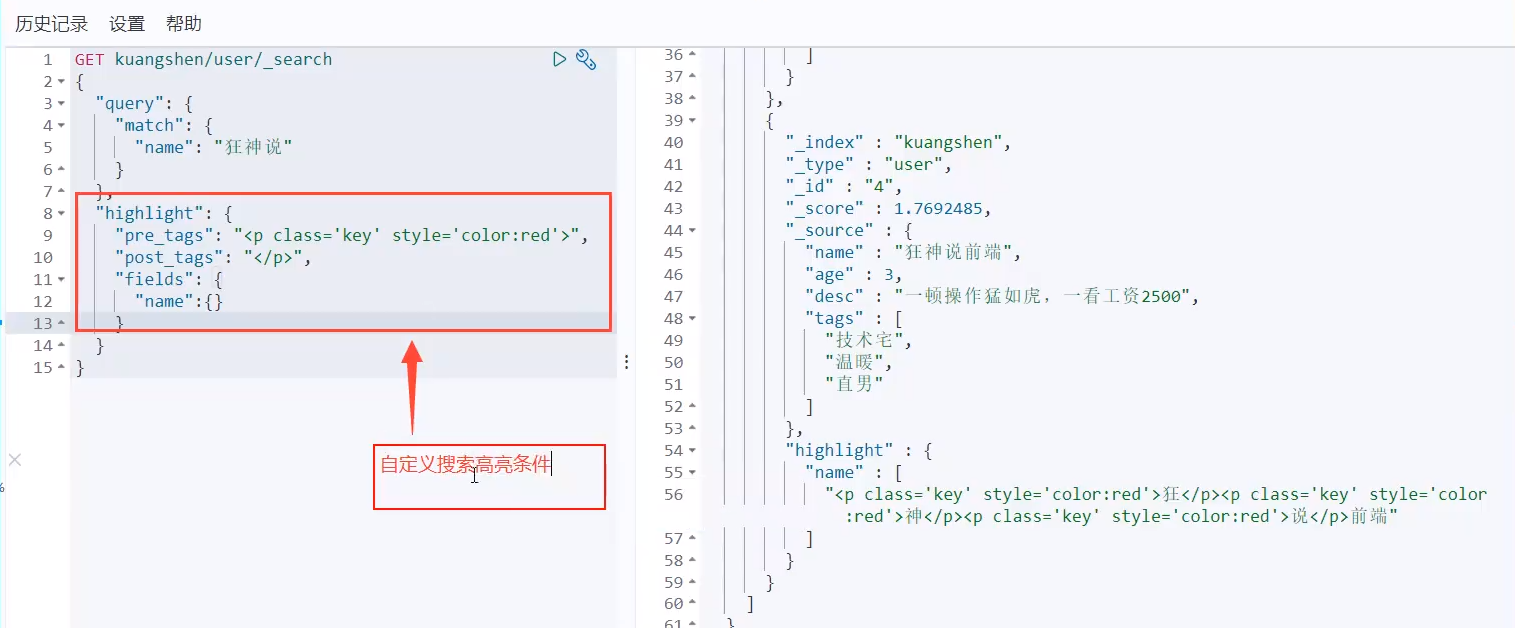
Highlight query!
The highlight conditions of the search will be automatically labeled in HTML
Integrated SpringBoot
Document not found!
https://proxies.app.aidoru.net/-----https://www.elastic.co/guide/index.html
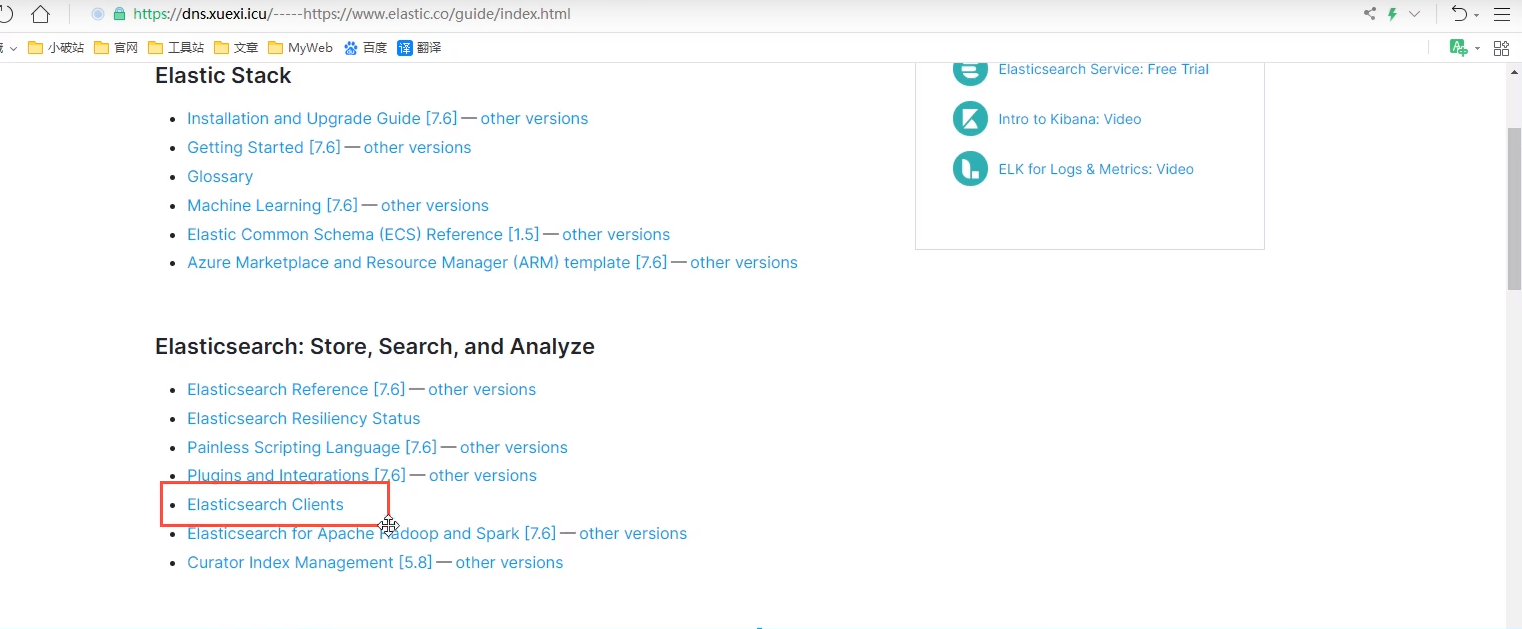
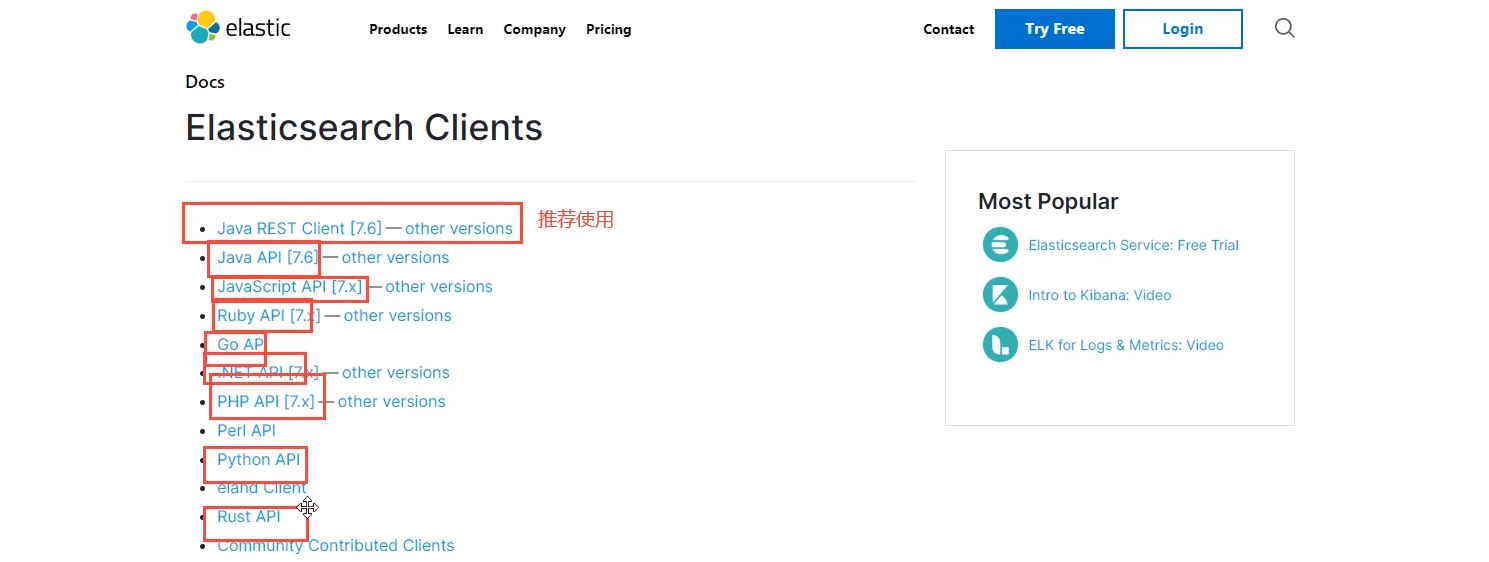
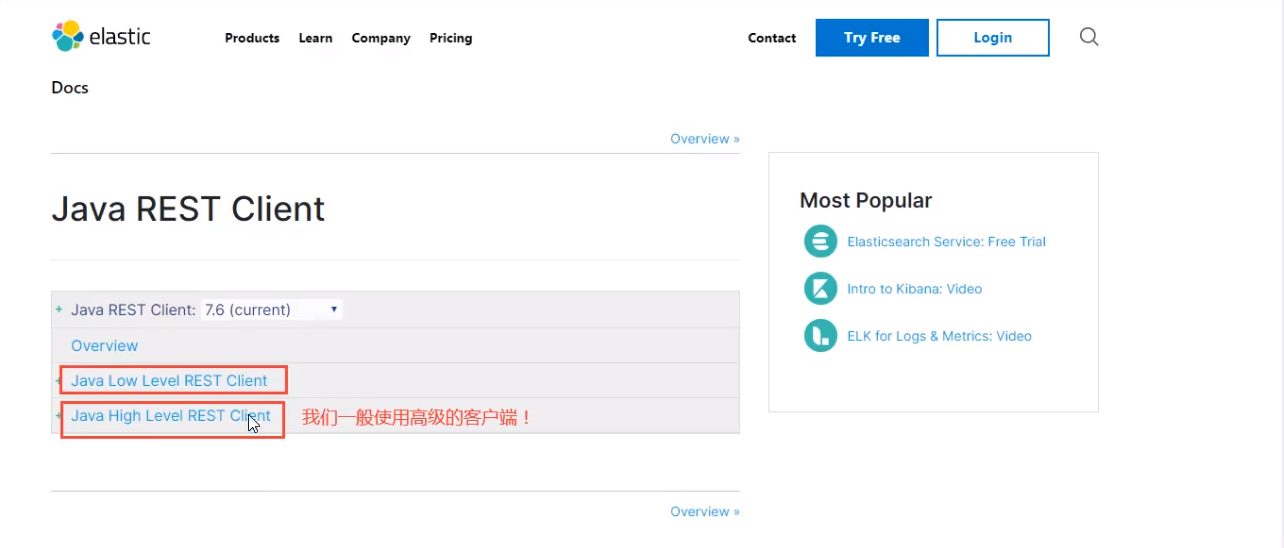
1. Find native dependencies
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>
2. Find object
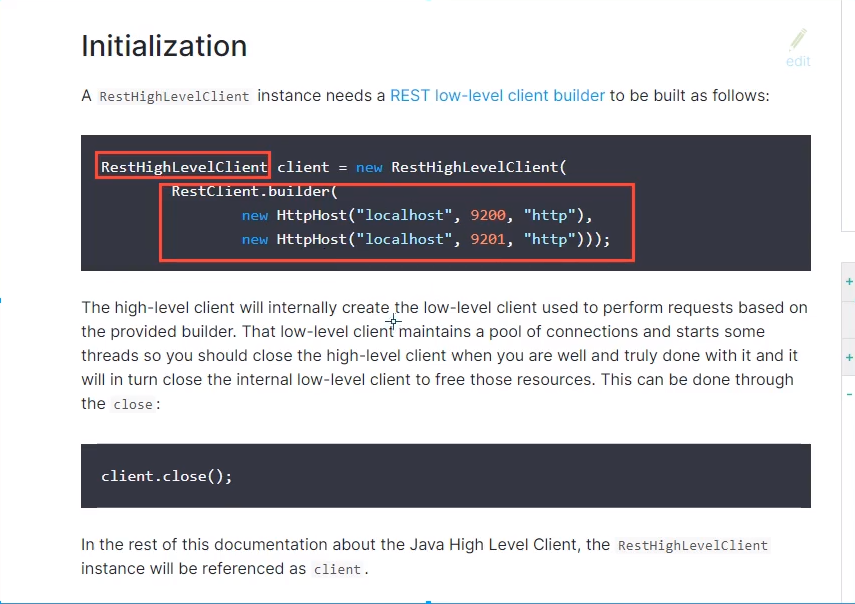
3. Just analyze the methods in this class
Configure basic items
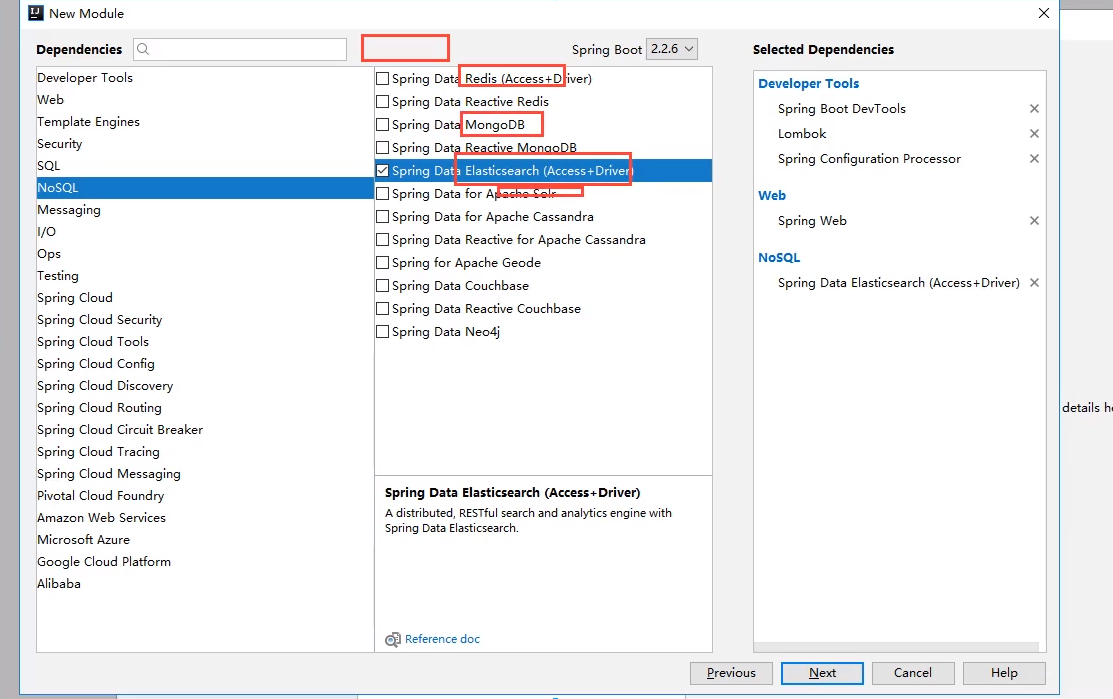
Problem: make sure that the dependencies we import are consistent with our ES version
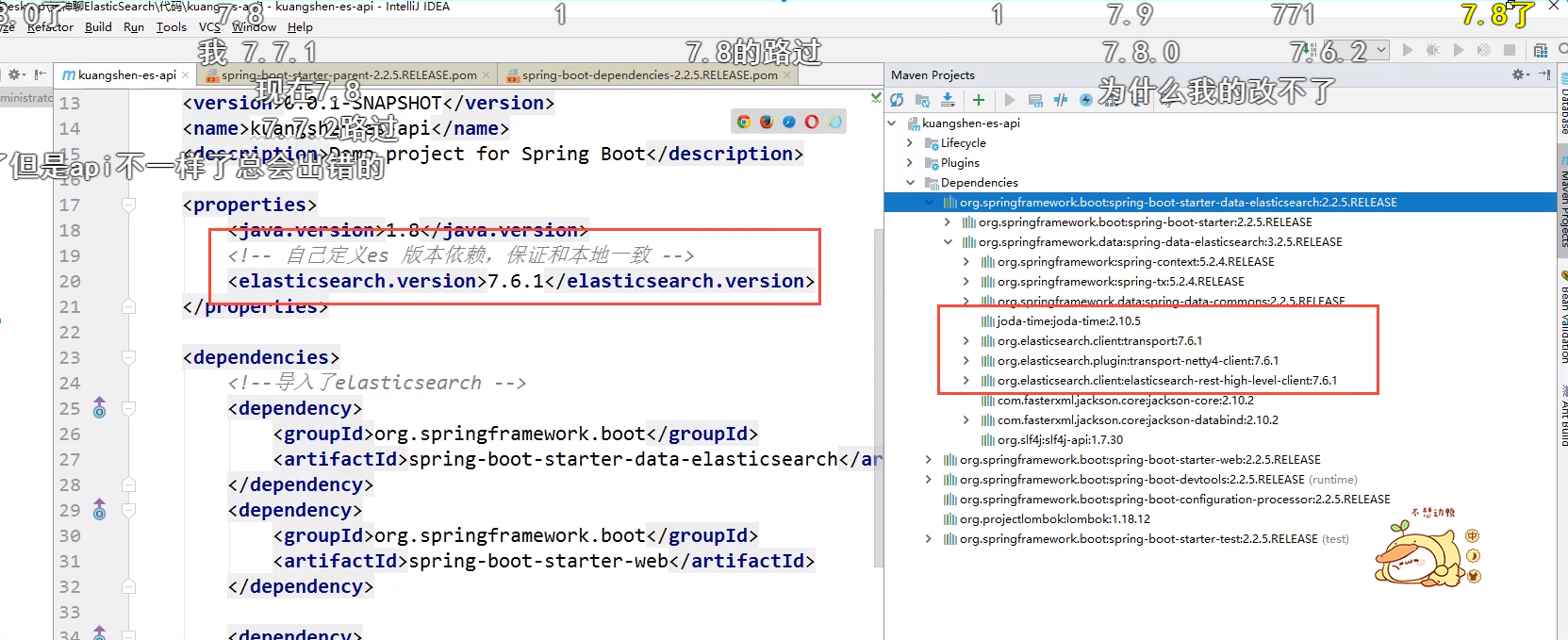
According to the operation of the official website, we need to build an object
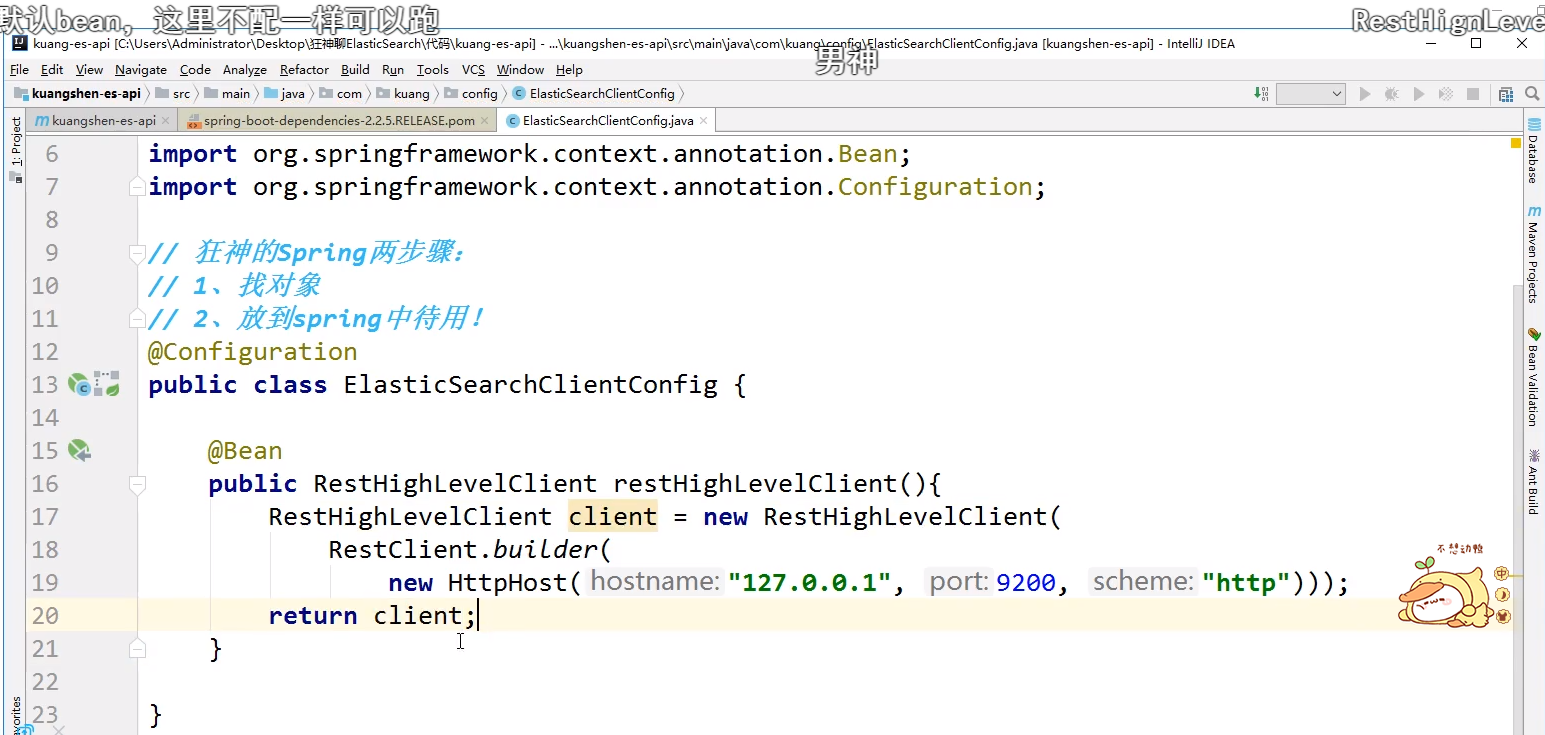
Analysis source code
Crazy God's Spring steps:
1. Find object
2. Put it in spring for use
3. If it is springboot, analyze the source code first
xxxAutoConfiguration,xxxProperties
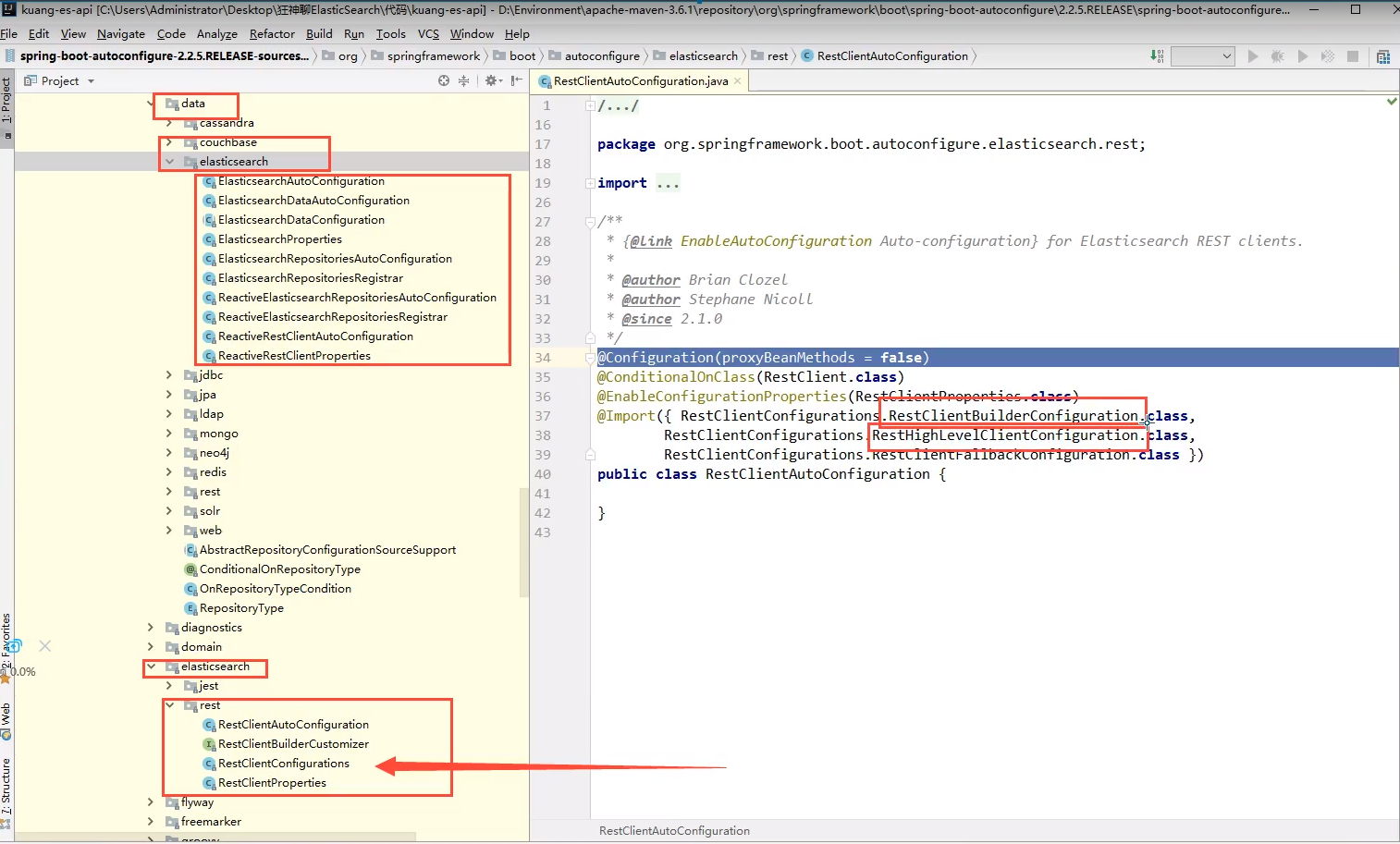
Objects provided in the source code
Although three classes are imported here, including static internal classes and one core class
Detailed explanation of API operation of index
Specific Api test!
restHighLevelClient.indices().xxx()
1. Create index
//Test index creation request put axis_ index
@Test
void testCreateIndex() throws IOException {
//1. Create index request
CreateIndexRequest request = new CreateIndexRequest("axiang_index");
//2. The client executes the request IndicesClient and obtains the corresponding information after the request
CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
2. Determine whether the index exists
//Test get index
@Test
void testExistIndex() throws IOException{
GetIndexRequest request = new GetIndexRequest("axiang_index");
boolean exists = client.indices().exists(request,RequestOptions.DEFAULT);
System.out.println(exists);
}
3. Delete index
//Test delete index
@Test
void testDeleteIndex() throws IOException{
DeleteIndexRequest request = new DeleteIndexRequest("axiang_index");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
Detailed explanation of API operation of the document
1. Create document
//Test add document
@Test
void testAddDocument() throws IOException{
//create object
User user = new User("forceup ", 21);
//Create request
IndexRequest request = new IndexRequest("axiang_index");
//Rule put / axis_ index/doc_ one
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
//Put our data into the request json
request.source(JSON.toJSONString(user), XContentType.JSON);
//client poke request
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
2. Get document
//Get the document and judge whether there is get/index/_doc/1
@Test
void testExists() throws IOException{
GetRequest getRequest = new GetRequest("axiang_index", "1");
//Do not get returned_ source context
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = client.exists(getRequest,RequestOptions.DEFAULT);
System.out.println(exists);
}
3. Get document information
//Get document information
@Test
void testGetDocument() throws IOException{
GetRequest getRequest = new GetRequest("axiang_index", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());//Print document content
System.out.println(getResponse);
}
4. Document update information
//Update document information
//POST /test/_doc/1/update
@Test
void testUpdateRequest() throws IOException{
UpdateRequest updateRequest = new UpdateRequest("axiang_index", "1");
updateRequest.timeout("1s");
User user = new User("Baa Baa oh", 18);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
5. Delete document record
//Delete document record
@Test
void testDeleteRequest() throws IOException{
DeleteRequest request = new DeleteRequest("axiang_index", "1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
6. Batch insert data
//Batch insert data
@Test
void testBulkRequest() throws IOException{
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("aa",3));
userList.add(new User("bb",4));
userList.add(new User("cc",5));
userList.add(new User("dd",6));
userList.add(new User("ee",7));
userList.add(new User("ff",8));
//Batch request
for (int i = 0; i < userList.size();i++){
//For batch update and batch deletion, you can modify the corresponding request here
bulkRequest.add(
new IndexRequest("axiang_index")
.id(""+(i+1))//If it is not set, a random id will be generated
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(bulkRequest,RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());//Whether the execution is successful. Return false to indicate success
}
7. Fancy query
//query
//SearchRequest construct search request
//SearchSourceBuilder constructs search criteria
//HighLightBuilder build highlights
//TermQueryBuilder exact query
//MatchAllQueryBuilder queries all
// xxx QueryBuilder corresponds to the following commands
@Test
void testSearch() throws IOException {
//Construct search request
// SearchRequest searchRequest = new SearchRequest(ESconst.ES_INDEX);// Call in utils
SearchRequest searchRequest = new SearchRequest("axiang_index");
//Construct search criteria
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//Query conditions are implemented with QueryBuilders tool
//Exact query: querybuilders termQuery
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "aa");
//Query all: querybuilders matchAllQuery
// MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
for (SearchHit documentFields : searchResponse.getHits().getHits()){
System.out.println(documentFields.getSourceAsMap());
}
}
actual combat
Crawling data
1. Import static resources
2. Import required dependencies
<dependencies>
<!-- Parsing web pages jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
3. Write a control class to make the page Jump to index html:IndexController. java
@Controller
public class IndexController {
@GetMapping({"/","index"})
public String index(){
return "index";
}
}
4. Encapsulated entity class: content java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Content {
private String title;
private String img;
private String price;
}
5. Package crawling data tool class: htmlparseutil java
@Component
public class HtmlParseUtil {
public List<Content> parseJD(String keywords) throws Exception {
//Get request
String url = "https://search.jd.com/Search?keyword="+keywords;
//Parsing web pages
Document document = Jsoup.parse(new URL(url), 30000);
Element element = document.getElementById("J_goodsList");
//Get all li elements
Elements elements = element.getElementsByTag("li");
ArrayList<Content> goodsList = new ArrayList<>();
//Get the content in the element, where el is each li tag
for (Element el:elements){
String img = el.getElementsByTag("img").eq(0).attr("data-lazy-img");
String price = el.getElementsByClass("p-price").eq(0).text();
String title = el.getElementsByClass("p-name").eq(0).text();
Content content = new Content();
content.setImg(img);
content.setPrice(price);
content.setTitle(title);
goodsList.add(content);
}
return goodsList;
}
}
Business Writing
Configuration class written: elasticsearchclientconfig java
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("127.0.0.1",9200,"http")
)
);
return client;
}
}
Business Writing: contentservice java
//Business Writing
@Service
public class ContentService {
@Autowired
private RestHighLevelClient restHighLevelClient;
//1. Parse data into es index
public Boolean parseContent(String keywords) throws Exception{
List<Content> contents = new HtmlParseUtil().parseJD(keywords);
//Put the queried data into es
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("2m");
for (int i = 0 ; i<contents.size();i++){
bulkRequest.add(
new IndexRequest("jd_goods")
.source(JSON.toJSONString(contents.get(i)), XContentType.JSON));
}
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}
//2. Obtain these data to realize the search function
public List<Map<String,Object>> searchPage(String keyword,int pageNo,int pageSize) throws IOException {
if (pageNo<=1){
pageNo = 1;
}
//Condition search (construct search request, construct search condition)
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//paging
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//Exact match
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//Perform search
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//Analytical results
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit documentFields: searchResponse.getHits().getHits()){
list.add(documentFields.getSourceAsMap());
}
return list;
}
}
Request writing: contentcontroller java
//Request writing
@RestController
public class ContentController {
@Autowired
private ContentService contentService;
@GetMapping("/parse/{keyword}")
public Boolean parse(@PathVariable("keyword") String keyword) throws Exception{
return contentService.parseContent(keyword);
}
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchPage(keyword,pageNo,pageSize);
}
}
Front and rear end interaction
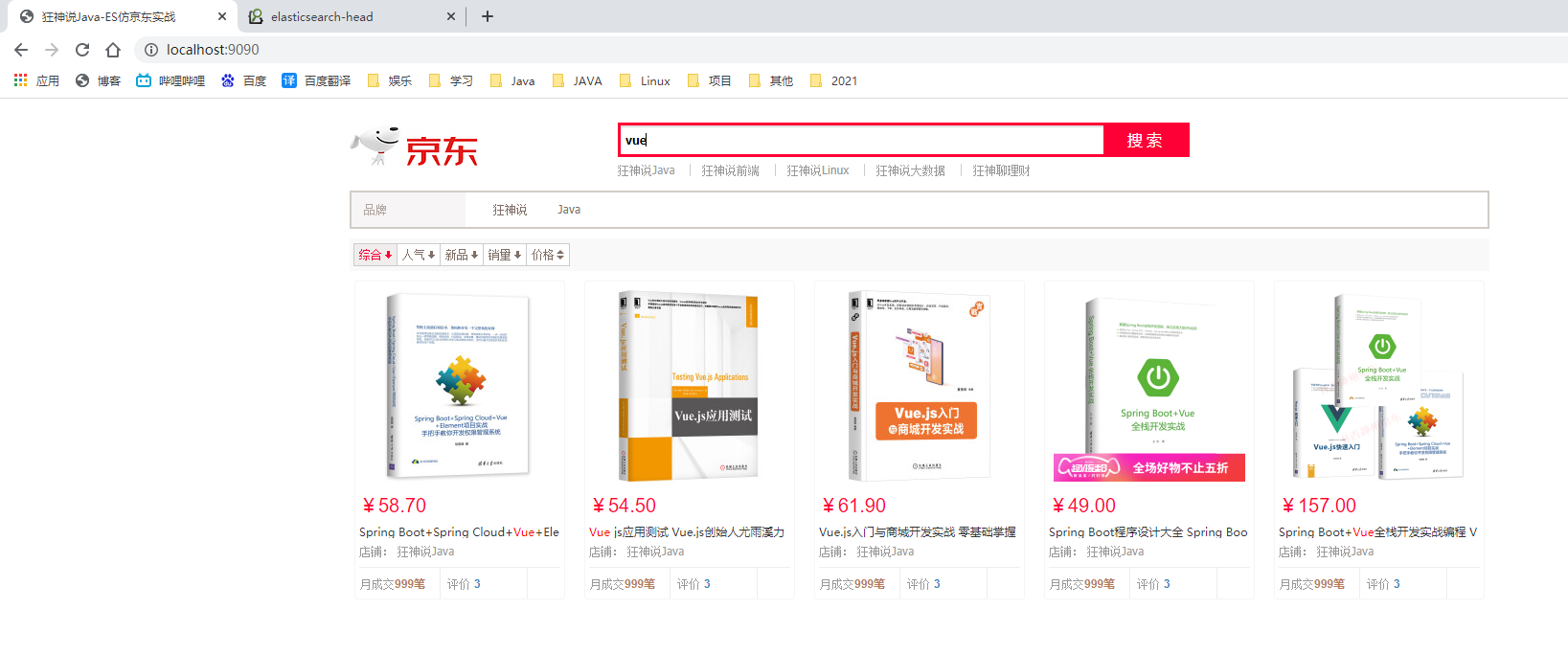
1. Create a folder on the desktop (the file name cannot be Chinese)
2. Enter cmd in the folder and enter the commands: 1. npm init 2. npm install vue 3. npm install axios
3. Enter folder
C:\Users\Administrator\Desktop\a\node_modules\vue\dist and
C:\Users\Administrator\Desktop\a\node_modules\axios\dist
Copy
vue.min.js and Axios min.js
To project
src/main/resources/static/js
4. Delete index HTML jquery js
[the external chain image transfer fails. The source station may have anti-theft chain mechanism. It is recommended to save the image and upload it directly (img-evwpwnfb-1622082347932) (C: \ users \ administrator \ appdata \ roaming \ typora \ user images \ image-20210320114214136. PNG)]
5. Import js of axios and vue
<!--Front end use vue,Achieve front and rear end separation-->
<script th:src="@{/js/axios.min.js}"></script>
<script th:src="@{/js/vue.min.js}"></script>
6. Yes, index HTML to achieve front-end interaction
<!DOCTYPE html>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="utf-8"/>
<title>Madness theory Java-ES Imitation Jingdong actual combat</title>
<link rel="stylesheet" th:href="@{/css/style.css}"/>
</head>
<body class="pg">
<div class="page" id="app">
<div id="mallPage" class=" mallist tmall- page-not-market ">
<!-- Head search -->
<div id="header" class=" header-list-app">
<div class="headerLayout">
<div class="headerCon ">
<!-- Logo-->
<h1 id="mallLogo">
<img th:src="@{/images/jdlogo.png}" alt="">
</h1>
<div class="header-extra">
<!--search-->
<div id="mallSearch" class="mall-search">
<form name="searchTop" class="mallSearch-form clearfix">
<fieldset>
<legend>Tmall search</legend>
<div class="mallSearch-input clearfix">
<div class="s-combobox" id="s-combobox-685">
<div class="s-combobox-input-wrap">
<input v-model="keyword" type="text" autocomplete="off" value="dd" id="mq"
class="s-combobox-input" aria-haspopup="true">
</div>
</div>
<button type="submit" @click.prevent="searchKey" id="searchbtn">search</button>
</div>
</fieldset>
</form>
<ul class="relKeyTop">
<li><a>Madness theory Java</a></li>
<li><a>Crazy God said</a></li>
<li><a>Madness theory Linux</a></li>
<li><a>Crazy God says big data</a></li>
<li><a>Crazy talk about financial management</a></li>
</ul>
</div>
</div>
</div>
</div>
</div>
<!-- Product details page -->
<div id="content">
<div class="main">
<!-- Brand classification -->
<form class="navAttrsForm">
<div class="attrs j_NavAttrs" style="display:block">
<div class="brandAttr j_nav_brand">
<div class="j_Brand attr">
<div class="attrKey">
brand
</div>
<div class="attrValues">
<ul class="av-collapse row-2">
<li><a href="#"> madness said</a></li>
<li><a href="#"> Java </a></li>
</ul>
</div>
</div>
</div>
</div>
</form>
<!-- Sorting rules -->
<div class="filter clearfix">
<a class="fSort fSort-cur">comprehensive<i class="f-ico-arrow-d"></i></a>
<a class="fSort">popularity<i class="f-ico-arrow-d"></i></a>
<a class="fSort">New products<i class="f-ico-arrow-d"></i></a>
<a class="fSort">sales volume<i class="f-ico-arrow-d"></i></a>
<a class="fSort">Price<i class="f-ico-triangle-mt"></i><i class="f-ico-triangle-mb"></i></a>
</div>
<!-- Product details -->
<div class="view grid-nosku">
<div class="product" v-for="result in results">
<div class="product-iWrap">
<!--Product cover-->
<div class="productImg-wrap">
<a class="productImg">
<img :src="result.img">
</a>
</div>
<!--Price-->
<p class="productPrice">
<em>{{result.price}}</em>
</p>
<!--title-->
<p class="productTitle">
<a>{{result.title}}</a>
</p>
<!-- Shop name -->
<div class="productShop">
<span>Shop: Crazy God said Java </span>
</div>
<!-- Transaction information -->
<p class="productStatus">
<span>Monthly transaction<em>999 pen</em></span>
<span>evaluate <a>3</a></span>
</p>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<!--Front end use vue,Achieve front and rear end separation-->
<script th:src="@{/js/axios.min.js}"></script>
<script th:src="@{/js/vue.min.js}"></script>
<script>
new Vue({
el:'#app',
data:{
keyword:'',//Keywords to search
results:[] //Search results
},
methods:{
searchKey(){
var keyword = this.keyword;
console.log(keyword);
//Back end interface
axios.get('search/'+keyword+"/1/20").then(response=>{
console.log(response);
this.results = response.data;//Binding data
})
}
}
})
</script>
</body>
</html>
Achieve highlight
In contentservice Java programming method to realize highlighting
//3. Obtain these data to realize the search highlighting function
public List<Map<String,Object>> searchPageHighlightBuilder(String keyword,int pageNo,int pageSize) throws IOException {
if (pageNo<=1){
pageNo = 1;
}
//Condition search (construct search request, construct search condition)
SearchRequest searchRequest = new SearchRequest("jd_goods");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//paging
sourceBuilder.from(pageNo);
sourceBuilder.size(pageSize);
//Exact match
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", keyword);
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//Build highlight
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);//Multiple highlights
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//Perform search
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//Analytical results
ArrayList<Map<String,Object>> list = new ArrayList<>();
for (SearchHit hit: searchResponse.getHits().getHits()){
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Map<String,Object> sourceAsMap = hit.getSourceAsMap();//Original result
//Analyze the highlighted field and replace the original field with our highlighted field
if (title !=null){
Text[] fragments =title.fragments();
String n_title = "";
for (Text text :fragments){
n_title += text;
}
sourceAsMap.put("title",n_title);//The highlighted field can be replaced with the original content
}
list.add(sourceAsMap);
}
return list;
}
In contentcontroller Java call highlight method
@GetMapping("/search/{keyword}/{pageNo}/{pageSize}")
public List<Map<String,Object>> search(@PathVariable("keyword") String keyword,
@PathVariable("pageNo") int pageNo,
@PathVariable("pageSize") int pageSize) throws IOException {
return contentService.searchPageHighlightBuilder(keyword,pageNo,pageSize);
}
Final result: