preface
This paper mainly records my thinking process of implementing recursive insertion operation, as well as the problems encountered and combing the operation process. However, this recursive implementation has a big problem, because it is not a tail recursive implementation, it will cause stack overflow!!! Therefore, this article is just a memorial to my turn, but it also combs various operation processes, and then uses non recursive implementation in subsequent articles.
1, Realization idea
The general idea flow chart I made:
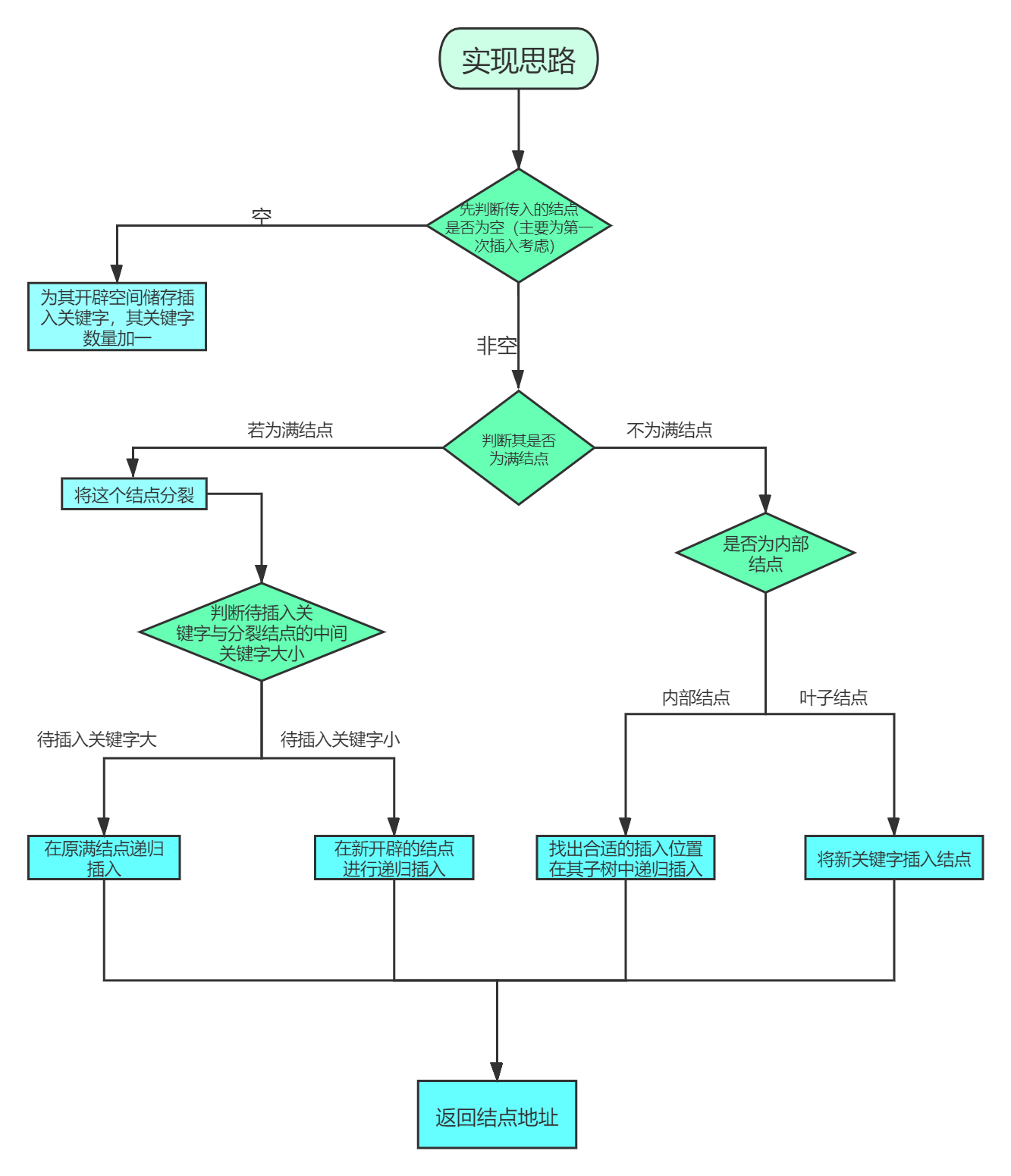
2, Train of thought combing
1. Problems I need to solve
Q1: what functions do I need to insert?
A: Split nodes, cut and insert a keyword into the appropriate position in a node keyword array, and insert a son into the appropriate position in a node pointer array to locate the keyword position.
Q2: how to split nodes?
A: If there is a parent node, pass the intermediate keyword of the node to be split to its parent node, then delete it, and then cut the keyword after the intermediate keyword and its son to the new node, so that the parent pointer of the new node points to the parent node of the node to be split; If there is no parent node (indicating that the node to be split is the root node) to open up a new node, the first keyword is the intermediate keyword of the node to be split, and the two sons are the node to be split and the new node. Similarly, cut the keyword and son after the intermediate keyword to the new node, and then make the newly opened parent node become the father of the node to be split and the new node.
Q3: how to judge the insertion direction after splitting the full node?
A: Compare the keyword to be inserted with the intermediate keyword of the original node. If it is larger than it, it will be inserted recursively in the new node. On the contrary, it will be inserted recursively in the original full node.
Q4: how to insert a new keyword into the appropriate position in the keyword array?
A: In this process, I used the technique of marking variables. Because the keyword array is arranged in non descending order, I just need to find the position where the elements in the keyword array are larger than the new keyword for the first time, and that position is the appropriate position of the new keyword. First create an intermediate array of keywords with a size of 2T-1, then declare a flag variable and initialize it to 1 and two variables to record the subscripts. Each cycle assigns the elements of the original array to the intermediate array, and the two subscripts are added automatically. When flag=1 and the first keyword is larger than the new keyword, set flag to 0, and then record the subscript of the intermediate array to store the new keyword. After the loop ends, judge whether the flag is 1. If it is 1, it means that the new keyword is larger than the keywords in the keyword array. Insert a new keyword at the end of the array. Finally, the middle array can cover the original array as a whole. The implementation of inserting a new son into the pointer array is similar.
Q5: how to realize the function of cutting?
A: This function is mainly used when cutting the data after the middle keyword of the full node to the new node after splitting the node. Declare two variables, the first is initialized to T, the second is initialized to 0, set the middle keyword of the original full node to 0 (connected with the previous operation), then assign the data of the full node to the new node in a circular way, and then empty its data, After that, release the sons at the end of the original full node (the number of sons is more than the number of keywords), and then make the two nodes point to the same father.
Q6: how to locate keyword location?
A: The basic idea is similar to inserting a keyword and inserting a son. The flag variable is used for positioning, but the judgment conditions are different. When the array is larger or equal to the keyword to be located for the first time, the subscript is recorded. If it is equal, it indicates that the keyword is in this node, otherwise it indicates that it is in the subtree of this subscript, If the flag is still equal to 1 after the end of the loop, it indicates that this keyword is in the end subtree.
2. Specific function implementation
Node declaration:
typedef int KeyType;
const int T=3;
typedef struct Btreenode{
KeyType key[2*T-1]={0}; //Keyword array
bool leaf=true; //The default leaf node is true
int n=0; //Number of nodes
struct Btreenode* son[2*T]={nullptr}; //Child node array
struct Btreenode* father=nullptr; //Parent pointer
}Btreenode;
typedef Btreenode* B_tree;
1. Positioning Keywords:
int Find_position(B_tree p,KeyType x){
int i=0,position=0,flag=1; //flag=1 indicates that the keyword position has not been located
for(;i<p->n;i++){
if(flag&&(x<p->key[i]||x==p->key[i])){
position=i;
flag=0; //Indicates that it has been positioned
}
}
if(flag) position=i; //This indicates that it is larger than the keyword in this node
return position;
}
2. Insert a new keyword into the node:
void Sortkey(B_tree p,KeyType newkey){
KeyType temp[2*T-1]={0};
int i=0,j=0,flag=1; //flag=1 means that the new keyword is not inserted
for(;i<p->n;i++,j++){
if(flag&&p->key[i]>newkey){
temp[j]=newkey;
temp[++j]=p->key[i];
flag=0;
}else if(p->key[i]==newkey){
cout<<"The key youo have input."<<endl;
return;
}else temp[j]=p->key[i];
}
if(flag) temp[j]=newkey;
for(i=0;i<=j;i++) p->key[i]=temp[i];
p->n++;
}
3. Insert a new son into the son pointer array:
void Sortson(B_tree father,B_tree newson){
B_tree temp[2*T]={nullptr};
int i=0,j=0,flag=1; //flag=1 represents that the new son is not inserted into the son array of the parent node
for(;father->son[i];i++,j++){
if(flag&&father->son[i]->key[0]>newson->key[0]){
temp[j]=newson;
temp[++j]=father->son[i];
flag=0;
}else temp[j]=father->son[i];
}
if(flag) temp[j]=newson;
for(i=0;i<2*T&&temp[i];i++) father->son[i]=temp[i];
}
4. Cut the second half of the full node to the new node:
void Cat(B_tree first,B_tree second){
int i=T,j=0;
first->key[T-1]=0; //Because this keyword has been passed to the parent node
for(;i<2*T-1;i++,j++){
second->key[j]=first->key[i];
first->key[i]=0;
second->son[j]=first->son[i];
first->son[i]=nullptr;
}
second->son[j]=first->son[i]; //Because there are more nodes than keywords
first->son[i]=nullptr;
second->n=first->n=T-1;
second->leaf=first->leaf;
second->father=first->father;
}
5. Split full node:
void Split(B_tree p){
B_tree newson=new Btreenode;
KeyType new_father_key=p->key[T-1];
Cat(p,newson);
if(p->father){ //p has a parent node
Sortkey(p->father,new_father_key);
Sortson(p->father,newson);
}else{ //If there is no parent node, the node to be split is the root node
B_tree newfather=new Btreenode;
p->father=newfather;
newson->father=newfather;
newfather->son[0]=p;
newfather->key[0]=new_father_key;
newfather->son[1]=newson; //Because newson inherits the right half of the original node, which is larger than the original node
newfather->leaf=false;
}
}
6. Insert function:
(after insertion, you need to check whether the root node has a parent node, because after splitting, the original root node is not a root node. After each insertion, you need to check. If the root node has a parent node, its parent node becomes a new root node)
B_tree Insert(B_tree root,KeyType newkey){
if(root==nullptr){
root=new Btreenode;
root->key[0]=newkey;
root->n++;
}else{
if(root->n==2*T-1){ //Full node
KeyType temp=root->key[T-1];
Split(root);
int position=Find_position(root->father,temp);
if(newkey<temp) return Insert(root,newkey);
else return Insert(root->father->son[position+1],newkey);
}else{
if(root->leaf==false){ //internal node
int position=Find_position(root,newkey);
return Insert(root->son[position],newkey);
}else{ //leaf node
Sortkey(root,newkey);
}
}
}
return root;
}