🅼🆈🆂🆀🅻
🅳🅰 🅹🅸🅰 🅷🅰🅾,🅸'🅼 🅗🅞🅤 🅧🅘🅐🅞🅙🅘🅤ʚʕ̯•͡˔•̯᷅ʔɞ
🌹꧔ꦿ🆆🅴🅻🅲🅾🅼🅴☀️ 🆃🅾✨ 🅼🆈 ❤️🅱🅻🅾🅶🌹꧔ꦿ
⍨⃝ focus is not lost. Bloggers are still making efforts to prepare more wonderful content~ ☝ ʚʕ̯•͡˔•̯ ᷅ ʔɞ
Xiao Joo is here to thank you for your support!
✨ 🅲🅼🅳 entry and exit 🅼🆈🆂🆀🅻
🌹 Connect to local database
mysql -uroot -p
.
Exit mysql
exit;
or
quit;
✨ data type
ʚʕ̯•͡˔•̯ ᷅ ʔɞ value type
🍷 Integer type
| Integer type | Default signed range | Default unsigned range |
|---|---|---|
| TINYINT[(size)] | -128~127 | 0~255 |
| SMALLINT[(size)] | -32768~32767 | 0~65535 |
| MEDIUMINT[(size)] | -8388608~8388607 | -8388608~8388607 0~16777215 |
| INT[(size)] | -2147483648~2147483647 | 0~4294967295 |
| BIGINT[(size)] | -9223372036854775808~9223372036854775807 | 0~18446744073709551615 |
Bool and Boolean are synonymous with TINYINT(1).
INTEGER[(size)] is a synonym for INT[(size)]
🍷 Decimal type
mysql uses floating-point numbers and fixed-point numbers to store decimals
🍹 Float & double
float is a single precision floating-point number and double is a double precision floating-point number.
-
It takes up 4 bytes in the machine, and the representation range is: - 3.40E+38 ~ +3.40E+38. The CPU processes float faster than double.
Representation range of single precision floating-point number: - 2 ^ 128 ~ + 2 ^ 128 (the index range of float is - 127 ~ 128) -
double has high precision. double consumes twice as much memory as float,
Double is a double precision floating-point number with 8 bytes of memory. The range of representation is -1.79E+ 308~-1.79E+308.
| Decimal type | describe |
|---|---|
| FLOAT | A small number with a floating decimal point. Specify the maximum number of digits in parentheses. Specify the maximum number of digits to the right of the decimal point in the d parameter. |
| DOUBLE | Large number with floating decimal point. Specify the maximum number of digits in parentheses. Specify the maximum number of digits to the right of the decimal point in the d parameter. |
- Parameters can also be set for float type and double type (non-standard syntax is allowed): float(size,d), double(size,d),
size is the precision, the total number of significant digits, and d is the scale. The precision from 0 to 23 corresponds to the 4-byte single precision of the FLOAT column. The precision of 24 to 53 corresponds to the 8-byte DOUBLE precision of the DOUBLE column.
However, starting from MySQL 8.0.17, non-standard FLOAT(M,D) and DOUBLE(M,D) syntax are not supported, and will not be supported in future MySQL versions. So there's no more entanglement here.
When it is necessary to use approximate numerical data value storage, FLOAT or DOUBLE shall be used without specifying precision or number of digits.
🍹 Fixed point number DECIMAL
| Decimal type | describe |
|---|---|
| DECIMAL(size,d) | Floating point number of normal size. DOUBLE type stored as a string, allowing fixed decimal points. |
The effective value range is determined by size and d.
-
size is the precision, which is the total length of the data. d is the scale, which indicates the length after the decimal point. The decimal method is rounding.
-
For example, 42532.5245 cannot be stored in DECIMAL(6,2) data type. If it is written, an error will be reported, because there are two digits after the decimal point, five digits before the preceding decimal point, a total of seven digits, while DECIMAL(6,2) can only store six digits.
-
DECIMAL(M) is equivalent to DECIMAL(M,0). Similarly, the syntax DECIMAL is equivalent to DECIMAL(M,0), and the value of M can be determined by calculation.
-
The maximum possible value range of DECIMAL is the same as DOUBLE, but its effective value range is determined by the values of M and D.
ʚʕ̯•͡˔•̯ ᷅ ʔɞ String type
| String type | Byte size | difference |
|---|---|---|
| CHAR(M) | 0-255 | Regardless of the actual length, CHAR(M) always stores a string that occupies m bytes of storage space, and M is the upper limit of the length of the stored string (unit: bytes). If the storage length is less than m, MySQL will make up with a space character on its right. |
| VARCHAR(M) | 0-65535 | VARCHAR stores a variable length string. The storage space occupied by the string is the actual length + 1 byte, and M is the upper limit of the length of the stored string (unit: byte) |
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Date type
| data type | describe | format | supplement |
|---|---|---|---|
| DATE | Date. | YYYY-MM-DD. | The supported range is from '1000-01-01' to '9999-12-31' |
| DATETIME | Combination of date and time. | YYYY-MM-DD HH:MM:SS. | The supported range is from '1000-01-01 00:00:00' to '9999-12-31 23:59:59' |
| TIME | Time. | HH:MM:SS | The supported range is from '- 838:59:59' to '838:59:59' |
| YEAR | Year in 2-digit or 4-digit format. | 4-bit format: 1901 to 2155. 2-bit format: 70 to 69, indicating from 1970 to 2069 | nothing |
| TIMESTAMP | Timestamp. | Format: YYYY-MM-DD HH:MM:SS. | The supported range is from '1970-01-01 00:00:01' UTC to '2038-01-09 03:14:07' UTC |
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Enumeration type
-
ENUM, enumeration of 1-255 members requires 1 byte storage; For 255 ~ 65535 members, 2 bytes of storage are required. A maximum of 65535 members are allowed.
-
Creation method: enum("A", "B", "C", "D"); The number of parameters is the number of enumerations. There can be multiple parameters.
-
Enumeration types are not case sensitive
✨ MySQL function
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Aggregate function
| function | describe | parameter |
|---|---|---|
| COUNT() | count | The parameter is the field name, which returns the number of rows with non null value of the target field; If the parameter is *, that is, count(*), the total number of all records in the table will be returned. |
| SUM() | Sum | field |
| AVG() | Average | field |
| MAX() | Maximum | field |
| MIN() | minimum value | field |
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Mathematical function
| function | describe | parameter |
|---|---|---|
| ABS() | abs(x) returns the absolute value of X | The parameter can be a number or a field. |
| FLOOR() | floor(x) returns the largest integer less than or equal to X | The parameter can be a number or a field. |
| RAND() | rand() returns a random number between 0 and 1. | The parameter can be empty or a number (the number is meaningless). A parameter can also be a field |
| TRUNCATE() | truncate(x,y) returns the value of X after y decimal places. | x and y can be either a number or a field. |
| SQRT() | sqrt(x) find the square root of parameter x, | x can be a number or a field. |
ʚʕ̯•͡˔•̯ ᷅ ʔɞ String function
Parameter Description: for the parameters of the above functions, all str, str1, str2 and other string types can be passed in either a single string or a field with a value of string type. All x, y and n can be passed in either numeric values of integer type or fields of integer type.
The description of "from X characters to y characters" is no longer an index starting from 0, but a number starting from 1 and containing the starting value [x,x+y).
| function | describe |
|---|---|
| CONCAT(str1,str2,...,strn) | Returns the result of concatenating multiple strings into a complete string |
| INSERT(str1,x,y,str2) | Replace the string str1 with the string str2 starting from the x character and substring of y string lengths |
| UPPER(str) | Capitalizes all letters in the string str |
| LOWER(str) | Turns all letters in the string str to lowercase |
| LEFT(str,x) | Returns the leftmost x characters of a string |
| RIGHT(str,x) | Returns the rightmost x characters of a string |
| LTRIM(str) | Remove the space to the left of str |
| RTRIM(str) | Remove the space to the right of str |
| LPAD(str1,n,str2) | Use string str2 to fill the leftmost part of string str1 until the length is n characters |
| RPAD(str1,n,str2) | Use string str2 to fill the rightmost part of string str1 until the length is n characters |
| REPEAT(str,x) | Returns the result of string str repeated x times |
| REPLACE(str,a,b) | Replace all occurrences of string a in string str with string b |
| STRCMP(str1,str2) | Compare the strings str1 and str2. If they are the same, they will return 0, and if they are different, they will return - 1. |
| TRIM(str) | Remove the spaces at the beginning and end of the line of the string |
| SUBSTRING(str,x,y) | Returns a string of y string lengths from position x in string str |
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Date and time functions
| function | describe |
|---|---|
| NOW() | Returns the current time in the format of YYYY-MM-DD HH:MM:SS, and the data type of the returned value is DATETIME |
| DATE(DATETIME) | The parameter is data or field of DATETIME type, the return value format is YYYY-MM-DD, and the return value data type is DATE type |
| TIME(DATETIME) | The parameter is data or field of DATETIME type, the return value format is HH:MM:SS, and the return value data type is TIME type |
| YEAR(DATETIME) | The parameter is data or field of DATETIME type. Returns a numeric value, a year. This value can be directly taken to participate in the calculation. |
| MONTH(DATETIME) | The parameter is data or field of DATETIME type. Returns a numeric value, a month. This value can be directly taken to participate in the calculation. |
| DAY(DATETIME) | The parameter is data or field of DATETIME type. Returns a numeric value, a day. This value can be directly taken to participate in the calculation. |
| ------------------------ | -------------- |
| CURRENT_DATE() | No parameter, return the current date, YYYY-MM-DD format, equivalent to DATE(NOW()) |
| CURRENT_TIME() | No parameter, return the current time, HH:MM:SS format, equivalent to TIME(NOW()) |
| CURRENT_TIMESTAMP() | No parameter, equivalent to now() |
| ------------------------ | ------------- |
| ADDTIME(t1,t2) | Returns the sum of the two times. The parameters T1 and T2 are values or fields of DATETIME type. If the result is greater than 24 hours, will it jump to the next day and there will be a result of 25:00:00. |
| DATE_ADD(t1,T) | Returns the result of a value or field of DATETIME type after a certain time delay. The result is DATETIME type. See the following example for the format of T |
| DATE_SUB(t1,T) | Returns the result of a numeric value or field of DATETIME type that is ahead of a certain time. The result is DATETIME type. The usage is the same as above |
| DATEDIFF(t1,t2) | Returns the number of days (t1-t2) that t1 lags behind t2. The parameter can be YYYY-MM-DD HH:MM:SS, YYYY-MM-DD, or a format between them (there must be DD) |
DATE_ADD(t1,T) and DATE_SUB(t1,T) example
SELECT DATE_ADD(now(),interval 1 DAY);
SELECT DATE_ADD(now(),interval 1 MONTH);
SELECT DATE_ADD(now(),interval 1 YEAR);
SELECT DATE_ADD(now(),interval 1 hour);
SELECT DATE_ADD(now(),interval 1 minute);
SELECT DATE_ADD(now(),interval 1 second);
SELECT DATE_SUB(now(),interval 1 DAY);
SELECT DATE_SUB(now(),interval 1 MONTH);
SELECT DATE_SUB(now(),interval 1 YEAR);
SELECT DATE_SUB(now(),interval 1 hour);
SELECT DATE_SUB(now(),interval 1 minute);
SELECT DATE_SUB(now(),interval 1 second);
SELECT DATEDIFF('2022-02-07','2021-12-01');
SELECT DATEDIFF('2022-02-07 12:00','2021-12-01 12:00');
SELECT DATEDIFF(DATE_ADD(now(),interval 1 day),now())
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Other functions
| function | describe |
|---|---|
| IF(expr,μ1,μ2) | The conditional judgment function is executed if expr is true μ 1. Otherwise, execute μ two |
| IFNULL(μ1,μ2) | If μ If 1 is not empty, return μ 1, otherwise return μ two |
| VERSION() | Get MySQL version number |
Examples
select if(score>85,'excellent','ordinary') from table1;
✨ SQL statement
ʚʕ̯•͡˔•̯ ᷅ ʔɞ notes
Annotation writing method in sql statement: two "-" symbols plus a space.
-- xxxxxxxxxxxxxxx
ʚʕ̯•͡˔•̯ ᷅ ʔɞ About database
🍷 ꧔ view all databases
show databases;
🍷 ꧔ create a database
create database database_name;
🍷 ꧔ create a database and judge whether it exists first:
If you create a database with the name of an existing database, an error will be reported.
You can use the following command to solve the problem. If it exists, it will no longer be created. If it does not exist, it will be created.
create database if not exists database_name;
🍷 ꧔ create a database whose name contains special characters
If the name of the database contains special characters other than numbers, letters and underscores, it shall be marked with ` ` on both sides of the name.
`The symbol is above the tab key, not a quotation mark.
Take the short horizontal line - as an example:
create database `database1-name`;
🍷 Delete database
drop database `database1-name`
🍷 ꧔ select a database
After selecting a database, you can execute the command about the data table in the database without declaring the database.
use database_name;
🍷 ꧔ view the currently used database
select database()
ʚʕ̯•͡˔•̯ ᷅ ʔɞ About data sheets
After executing the select database command:
🍷 ꧔ view all tables
show tables;
🍷 ꧔ create a data table
When creating a data table, you need to specify at least one field and its data type.
(specify the field id here as an example, and the type is int):
create table table_name(id int);
Fill in the field attributes in the brackets in the data table. The rule is to write the field name first, then write the data type of the field value in an empty space, and then write the following series of attributes:
| attribute | Abbreviation | describe |
|---|---|---|
| primary key | PK | Primary key |
| not null | NN | Non empty |
| unique | UQ | unique index |
| binary | BIN | binary data |
| unsigned | UN | Unsigned (non negative) |
| zero fill | ZF | Fill in 0 (i.e. 2 is displayed as 00002 in int(5)) |
| auto increment | AI | Self increasing |
| Generated Column | G | |
| Default/Experession | nothing | Default value |
Separate different fields with English commas.
Take creating a table called "students" as an example
The field id is of type int and is not empty. It is a primary key and self incremented;
The field name is of varchar type, and the maximum length is 30 bytes;
The field age is tinyint type and non negative. The default value is 18;
The field high is of decimal type, with a total length of 5 digits and two decimal places reserved;
The field gender is an enumeration type. The values you can select include 'male', 'female', 'confidential'. And it is confidential by default.
Field cls_id is of type int.
The sql code is as follows:
create table students(
id int not null primary key auto_increment,
name varchar(30),
age tinyint unsigned default 18,
high decimal(5,2),
gender enum('male','female','secrecy') default 'secrecy',
cls_id int
);
No order is required between non empty and auto increment attributes. Its abbreviated form cannot be used in code.
When operating in MySQL WorkBench, if it is created manually, you can also check the abbreviations in the above table.
🍷 View table structure
desc students;
or
describe students;
The properties of each field in the table are displayed.
🍷 ꧔ add table fields
- alter table data table name add field name field type
Take adding a field named birthday in the students table as an example. The field type is DATE type:
alter table students add birthday DATE;
🍷 Modify table fields
① Only the data type and constraint of the field can be modified, but the field name cannot be modified:
- alter table table name modify field name field type constraint
For example, change the default value of birthday field to '1900-01-01':
alter table students modify birthday DATE default '1900-01-01';
② Modify field name and others
- alter table table name change old field name new field name field type constraint
Take the example of modifying the field birthday to my bdy and modifying the default value to '1912-01-01':
alter table students change birthday bdy DATE default '1912-01-01';
🍷 ꧔ delete field
- alter table data table name drop field name;
Take deleting the field high as an example.
alter table students drop high;
🍷 ꧔ add a piece of data
In the current students table, after the above operations, the remaining fields are as follows:
| id | name | age | gender | cls_id | bdy |
|---|
When one piece of data is added in sequence, the default value cannot be written. Must correspond one by one.
insert into students values(1,'Zhang San',20,'male',5,'2002-01-01');
🍷 ꧔ add multiple pieces of data
That is, on the basis of adding a piece of data:
- insert into students values(),(),()
The parentheses of each row of data are separated by commas.
🍷 ꧔ add specified field data
To add only name and CLS_ Take two fields of ID as an example:
insert into students (name,cls_id) values ('Zhu Yuanzhang',3);
When adding a specified field, the field name must be enclosed in parentheses.
Use commas to separate parentheses when adding data for multiple rows of specified fields:,
insert into students (name,cls_id) values ('xx',3),('xx',4);
🍷 ꧔ add enumeration type data through subscript
When adding enumeration type data, you can add it directly or through subscript
Take the add field gender as an example. The field is of enumeration type, and the values are "male, female and confidential":
insert into students (name,gender) values ('judy',1);
Subscripts count from 1.
🍷 ꧔ modify data
To convert CLS_ The ID is changed to 8 as an example:
update students set cls_id=8;
CLS with name Zhang San_ Change ID to 9:
update students set cls_id =8 where name='Zhang San';
When modifying data and executing these two lines of commands, you may encounter an error:
- Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column. To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect.
That is to say, in the safe updates mode of mysql, if there is no where or where is not followed by the primary key, it is not allowed to modify the data in this way, which is too unsafe.
You can exit safe modification mode with the following statement:
SET SQL_SAFE_UPDATES = 0;
You can also change the where constraint to: where name = "Zhang San" and ID > = 1.
If you want to modify more than one field, use the CLS whose name is Zhang San_ Change ID to 1 and gender to 'female', for example:
update students set cls_id =1,gender='female' where name='Zhang San';
🍷 Delete data
If there is no where constraint, all data will be deleted. It is not recommended to try easily.
delete from students;
Delete the data whose name is Zhang San.
delete from students where name='Zhang San';
🍷 ꧔ logical deletion
The deleted data above is physical deletion, which may cause data disorder and affect the data association with other tables.
Generally, logical deletion is better than physical deletion.
That is, add a new field, mark the field value you want to delete as 0, and mark the reserved field value as 1
To add an is_del field as an example, the default is 1:
alter table students add is_del INT DEFAULT 1;
Is whose name is' Zhu Yuanzhang '_ Del is marked as 0.
update students set is_del=0 where name='Zhu Yuanzhang';
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Query statement
🍷 Query all data in the table
*Indicates all, and from is followed by an indication.
select * from students;
🍷 Query the specified field
The fields are separated by English commas.
select name,age from students;
🍷 ꧔ field rename
Renaming fields during query can facilitate display
select name as 'full name',gender as 'Gender' from students;
🍷 Table renaming
This writing method will be used in multi table query.
select s.gender from students as s;
🍷 De duplication during query
🍹 To duplicate a field:
select distinct field name from table name;
select distinct name from students;
🍹 Duplicate multiple fields
De duplication of multiple fields refers to de duplication only when the target fields of a whole row are the same, rather than separate de duplication.
select distinct name,age from students;
🍷 ꧔ where clause and logical operator
| Logical operator | meaning | Symbol |
|---|---|---|
| and | Logic and | && |
| or | Logical or | || |
| not | Logical non | ! |
-- from students Table query id It's 1 name select name from students where cls_id=1; -- from students Table query cls_id>3 of name and age select name,age from students where cls_id>3; -- from students Table query cls_id>3 And age>18 of name and age select name,age from students where cls_id>3 and age>18; -- from students Table query name It's not Zhang San's name,age and cls_id select name,age,cls_id from students where name!='Zhang San'; -- from students Table query name Not Zhang Sanyi gender(Enumeration type field)Is the value of its first index name,age and cls_id select name,age,cls_id from students where not name='Zhang San' and gender=1;
🍷 Fuzzy query
%Any number of characters
One_ (underscore) indicates a character
Query data whose name starts with "Zhang"
select * from students where name like 'Zhang%';
Query the data with the character "Zhang" in name
select * from students where name like '%Zhang%';
Query data with only two characters of name
select * from students where name like '__';
Query data with at least three characters of name
select * from students where name like '___%';
🍷 Range query
Query data with id 1, 2 and 4
select * from students where id in (1,2,4);
Query data whose ages are not 18 and 20
select * from students where age not in (18,20)
Data with query id of 3-5 (including both ends)
select * from students where id between 3 and 5;
Query the data whose id is 3-5 and whose gender is "male" (the first index value of the enumeration type field)
select * from students where (id between 3 and 5) and (gender=1);
Query data aged 18 to 20
select * from students where (age not between 18 and 20);
🍷 Empty judgment
Query CLS_ Data with empty ID
select * from students where cls_id is null;
Query CLS_ Data whose ID is not empty
select * from students where cls_id is not null;
🍷 Aggregate function application
Total number of query data records
select count(*) from students ;
Query the number of data records whose gender is male (the first index value of the enumeration type field)
select count(*) from students where gender=1;
Maximum query age
select max(age) from students ;
🍷 Group query
group by
Query the number of different categories of gender
-- Query only select count(*) from students group by gender; -- Categories are also displayed select gender,count(*) from students group by gender; -- Displays the category and renames its field name as Can be omitted select gender'Gender',count(*) from students group by gender;
🍹group_concat
-- At the same time, the detailed information of a field grouping is displayed to name take as an example select gender'Gender',group_concat(name),count(*) from students group by gender;
Effect example:
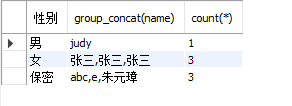
Query an attribute of the data in the group. Take the age corresponding to each name as an example. You can query the data in the group_ Multiple fields are placed in parentheses after concat, separated by commas:
select gender'Gender',group_concat(name,': ',age),count(*) from students group by gender;

🍹 Show totals on the last line after grouping with rollup
select gender'Gender',count(*)'Number of people' from students group by gender with rollup;
The results are shown in the figure below:
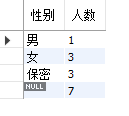
So the last value of gender is null. In order to be more intuitive, it is often filled:
Fill in empty values with totals:
select ifnull(gender,'total') as 'Gender',count(*) from students group by gender with rollup;
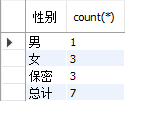
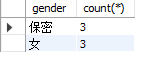
🍷 Filtering the result set
The constraint condition of where is based on the original data, while the constraint of non original data needs to use having
Take the count of more than 2 in gender as an example,
That is, the counts of "male", "female" and "confidential" obtained after gender grouping are constrained,
Filter out the with value greater than 2. At this time, if you use where, an error will be reported. You need to replace where with having.
select gender,count(*) from students group by gender having count(*)>2;
Examples of results are as follows:
Query the gender and name of "male" or "female" with average age greater than 18
select gender,avg(age),group_concat(name) from students group by gender having avg(age)>18 and (gender=1 or gender=2);
🍷 order by sort query
Query the data whose age is between 18-26 and gender is "female", and arrange it from small to large by age
You can also add the keyword asc after the field, which is omitted here. Because the default is ascending from small to large.
select * from students where (age between 18 and 26) and gender=2 order by age;
Descending order (from large to small):
Use keyword desc
select * from students where (age between 18 and 26) and gender=2 order by age desc;
You can also add multiple fields after order by. The function is to sort by the latter field when the current field is the same
select * from students order by age desc,cls_id desc;

🍷꧔ꦿlimit
- limit [start,] count
Where, start is the starting value, counting from 0, and the default is 0
Take the first three data
select * from students limit 3;
Take 4 data from the third data
select * from students limit 2,3;
- limit can only be written at the end.
- limt cannot contain mathematical expressions. For example, limit 1+1,5 is unqualified.
ʚʕ̯•͡˔•̯ ᷅ ʔɞ Table join query
Prepare the data, create a table1 and a table2, and write some data
-- establish table1
create table table1(
id int not null primary key auto_increment,
name varchar(30),
age tinyint unsigned default 18,
high decimal(5,2),
gender enum('male','female'),
cls_id int
);
-- establish table2
create table table2(
num int not null primary key auto_increment,
name varchar(30),
score int
);
-- Write data
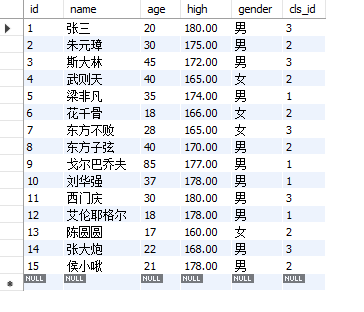
insert into table1 values
(1,'Zhang San',20,180,'male',3),
(2,'Zhu Yuanzhang',30,175,'male',2),
(3,'Stalin',45,172,'male',3),
(4,'Wu Zetian',40,165,'female',2),
(5,'Liang Feifan',35,174,'male',1),
(6,'Hua Qian'gu',18,166,'female',2),
(7,'invincible eastern',28,165,'female',3),
(8,'Oriental Zixian',40,170,'male',2),
(9,'Gorbachev',85,177,'male',1),
(10,'Hua Qiang Liu',37,178,'male',1)
(11,'ximen qing',30,180,'male',3),
(12,'Ellen Yeager',18,178,'male',1),
(13,'Yuan Yuan Chen',17,160,'female',2),
(14,'Da Pao Zhang',22,168,'male',3),
(15,'Hou xiaojoo',21,178,'male',2)
;
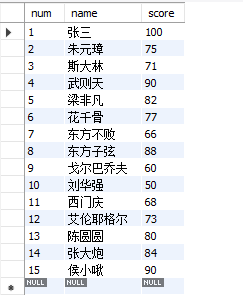
insert into table2 values
(1,'Zhang San',100),
(2,'Zhu Yuanzhang',75),
(3,'Stalin',71),
(4,'Wu Zetian',90),
(5,'Liang Feifan',82),
(6,'Hua Qian'gu',77),
(7,'invincible eastern',66),
(8,'Oriental Zixian',88),
(9,'Gorbachev',60),
(10,'Hua Qiang Liu',50)
(11,'ximen qing',68),
(12,'Ellen Yeager',73),
(13,'Yuan Yuan Chen',80),
(14,'Da Pao Zhang',84),
(15,'Hou xiaojoo',90)
;
Data ready:
Start the following operations~
🍷 Internal connection
🍹 Basic grammar
select * from table 1 inner join table 2 on table 1 Column a = Table 2 Column B
That is, table 1 and table 2 are matched according to column A in Table 1 and column B in Table 2.
Take the internal connection between table1 and table2 as an example, based on the id in table1 and the num in table2.
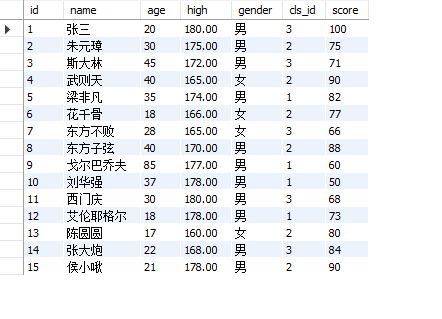
SELECT * FROM table1 inner join table2 on table1.id=table2.num;
As shown in the figure, the preliminary internal connection of the two tables is realized.

🍹 Table rename
Abbreviate table1 to a and table2 to b. Connect a and b inside.
select * from table1 a inner join table2 b on a.id=b.num;
-- Match only table1 of name,age and table2 Score of select a.name,a.age,b.score from table1 a inner join table2 b on a.id=b.num;
Connection result presentation:

-- display table1 All information and of the table table2 Tabular score select a.*,b.score from table1 a inner join table2 b on a.id=b.num;
Connection result presentation:
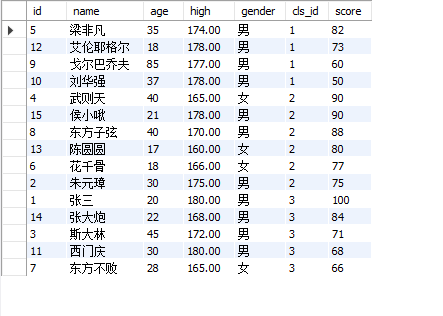
More complicated,
Press CLS after connecting_ ID ascending sort, CLS_ Those with the same ID are sorted in descending order by score,
select a.*,b.score from table1 a inner join table2 b on a.id=b.num order by cls_id,score desc;
🍷 External connection
The external connection is divided into left connection and right connection.
If it is a left connection, it is mainly table1 on the left. If it is a right connection, it is mainly table2 on the right,
Left join: the query result is the data matched by the two tables. The data held in the left table remains unchanged. The data not in the right table is filled with null.
On the contrary, the data held in the right table remains unchanged, and the data not in the left table is filled with null.
(there is no Null value in this data, which can be adjusted and tested by yourself)
-- Left connection select * from table1 a left join table2 b on a.id=b.num; -- Right connection select * from table1 a right join table2 b on a.id=b.num; -- Left join query age>30 And score>80 Data select * from table1 a left join table2 b on a.id=b.num where a.age>30 and b.score>80;
🍷 ꧔ sub query
In some cases, when querying, the required condition is the result of another select statement. At this time, sub query is used.
-- query gender The data in "male" is, high The largest data (note that the demand is one line of data, not one data) select * from table1 where high=(select max(high) from table1 where gender=1); -- query high higher than high Average data select * from table1 where high>(select avg(high) from table1);
🍷 ꧔ auto correlation
That is, you can connect with yourself to query,
It is usually used when a table contains multiple levels of fields, such as provincial, municipal and district fields. Each province has multiple cities and each city has multiple districts
Prepare a set of data:
create table table4( num int not null, id int not null, name varchar(30) ); insert into table4 values (1,0,'China'), (2,1,'Hebei'), (3,1,'Henan'), (4,1,'Anhui'), (5,2,'Shijiazhuang City '), (6,2,'Cangzhou City'), (7,2,'Baoding City'), (8,3,'Luoyang City'), (9,3,'Shangqiu City'), (10,3,'Nanyang City'), (11,4,'Hefei'), (12,4,'Huangshan City'), (13,4,'Lu'an City')
Data presentation:
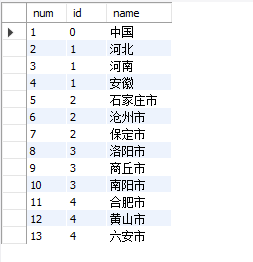
This set of data features meets the requirement that the id of each city is equal to the num of its corresponding province.
Example of auto correlation query:
-- All data of cities under Hebei Province in the query table select * from table4 a inner join table4 b on a.id=b.num having b.name='Hebei';
