Abstract: This paper introduces the practice of Flink CDC using Kafka for CDC multi-source merger and downstream synchronous update. The contents include:
- preface
- environment
- View document
- Create a DataStream project for FlinkCDC
- Custom serialization class
- Bus kafka
- Dinky development and submission job
- View results
- summary
1, Foreword
This paper mainly aims at the problem that Flink SQL cannot realize multi-source consolidation of multi database and multi table by using Flink CDC, and how to update the downstream Kafka synchronously after multi-source consolidation, because at present, Flink SQL can only carry out the job operation of single table Flink CDC, which will lead to too many connections of database CDC.
However, the DataStream API of Flink CDC can synchronize multiple databases and tables. This paper hopes to use the DataStream API of Flink CDC to import a bus kafka after multi-source merging. The downstream only needs to connect the bus kafka to realize the multi-source merging of Flink SQL and resource reuse.
2, Environment
edition
assembly | edition |
|---|---|
Flink | 1.13.3 |
Flink CDC | 2.0 |
Kafka | 2.13 |
Java | 1.8 |
Dinky | 0.5.0 |
CDC Preview
Let's print the default serialization JSON format of Flink CDC as follows:
SourceRecord{sourcePartition={server=mysql_binlog_source}, sourceOffset={ts_sec=1643273051, file=mysql_bin.000002, pos=5348135, row=1, server_id=1, event=2}}
ConnectRecord{topic='mysql_binlog_source.gmall.spu_info', kafkaPartition=null, key=Struct{id=12}, keySchema=Schema{mysql_binlog_source.gmall.spu_info.Key:STRUCT}, value=Struct{before=Struct{id=12,spu_name=Huawei smart screen 14222 K1 Full screen smart TV,description=Huawei smart screen 4 K Full screen smart TV,category3_id=86,tm_id=3},after=Struct{id=12,spu_name=Huawei smart screen 2 K Full screen smart TV,description=Huawei smart screen 4 K Full screen smart TV,category3_id=86,tm_id=3},source=Struct{version=1.4.1.Final,connector=mysql,name=mysql_binlog_source,ts_ms=1643273051000,db=gmall,table=spu_info,server_id=1,file=mysql_bin.000002,pos=5348268,row=0,thread=3742},op=u,ts_ms=1643272979401}, valueSchema=Schema{mysql_binlog_source.gmall.spu_info.Envelope:STRUCT}, timestamp=null, headers=ConnectHeaders(headers=)}It can be seen that there are great problems in transmitting JSON in this format to the downstream. To realize multi-source merging and synchronous update, we need to solve the following two problems.
① The json transmitted from the bus Kafka cannot identify the source library and source table for specific table creation operations, because it is not a fixed json format, and the specific library and table cannot be specified in the table creation with configuration.
② How does the json from the bus kafka synchronize the kafka stream with events such as CRUD, especially Delete, and how does the downstream kafka perceive to update the ChangeLog.
3, View document
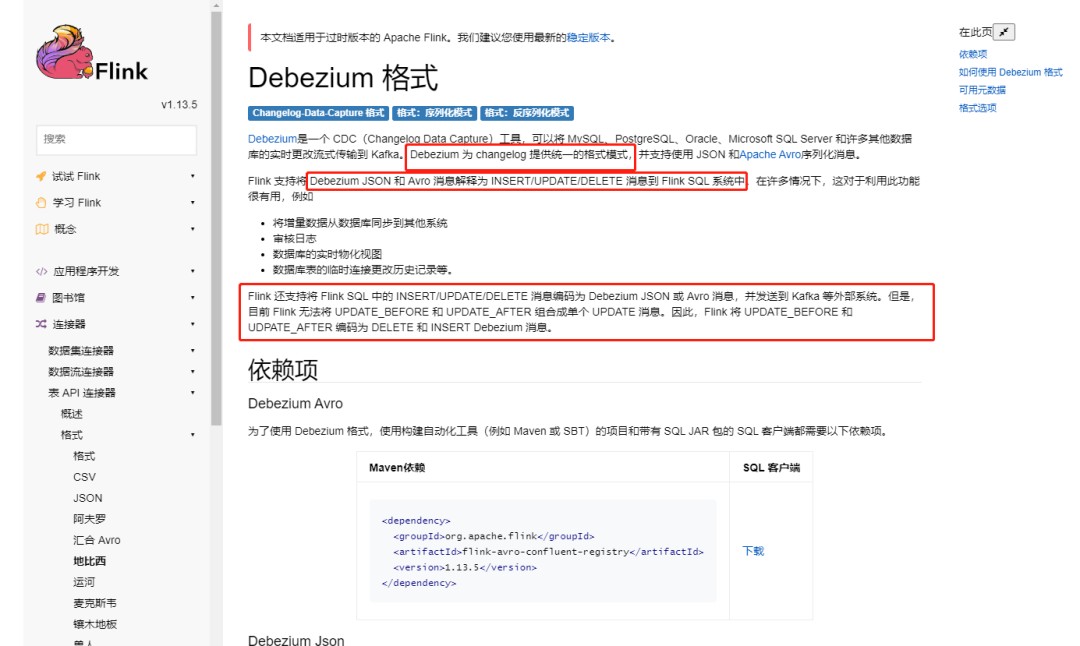
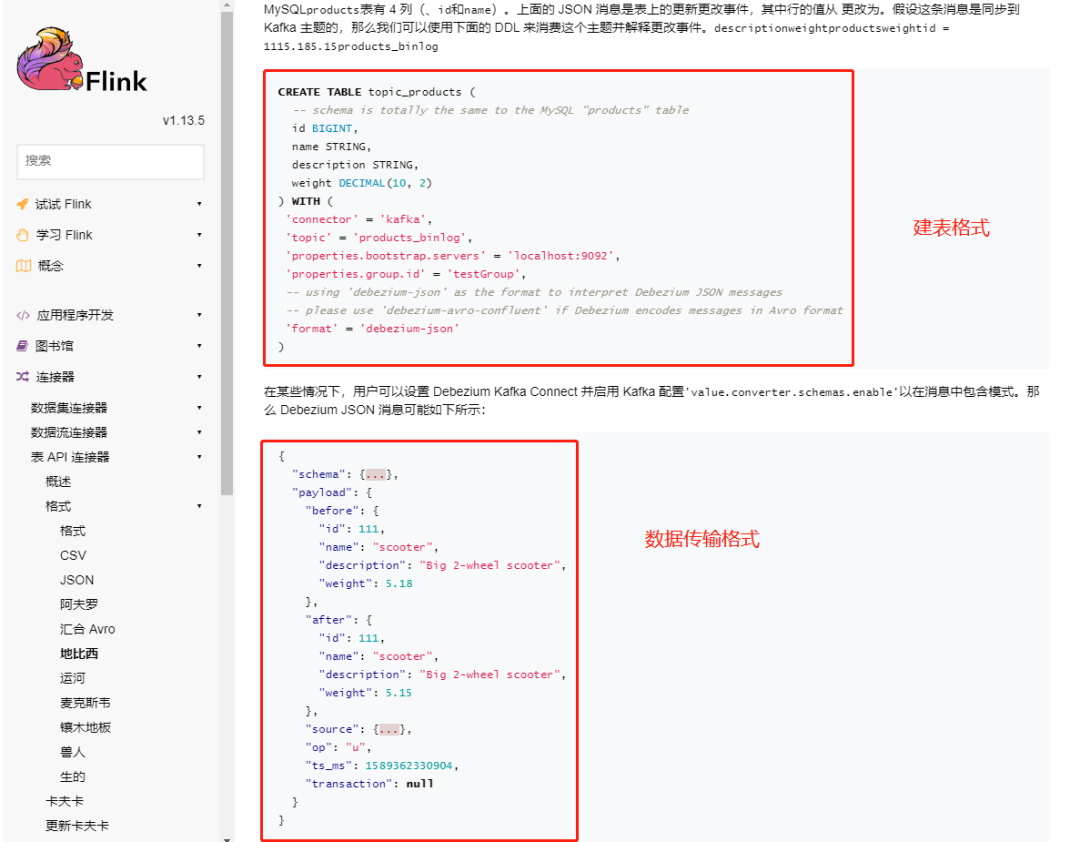
We can see in the red box that json based on Debezium format can realize CRUD synchronization of tables in Kafka connector. As long as the json format of the bus Kafka conforms to this mode, the CRUD of the downstream Kafka can be synchronously updated. Just as Flink CDC is also based on Debezium.
Then the problem has been solved here.
The remaining problem ① is how to solve the problem of identifying the specified table and library with the multi database and multi table. After all, the table creation statement does not set the parameters of where.
Turn down the document:
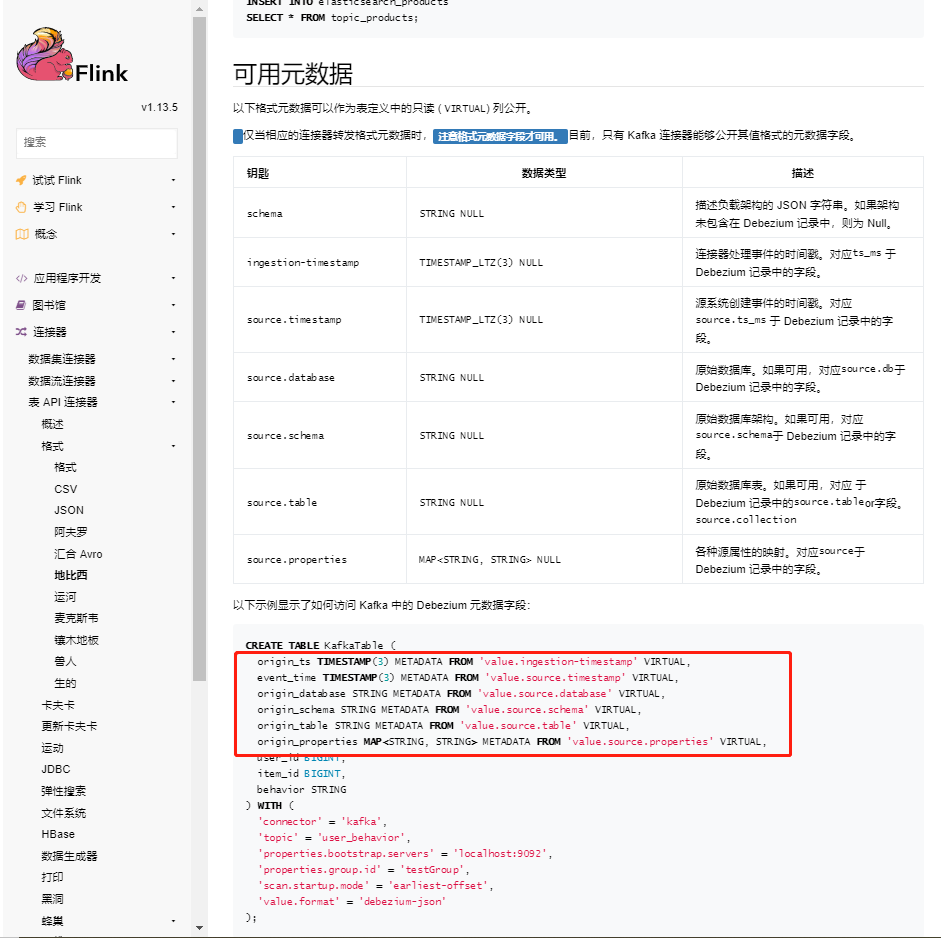
You can see that based on the debezium json format, the metadata of the json format defined in the above schema can be taken out and placed in the field.
For example, I put the table and database in the table creation statement, so I can filter the database and table in the select statement.
As follows:
CREATE TABLE Kafka_Table (
origin_database STRING METADATA FROM 'value.source.database' VIRTUAL, //Metadata fields in json defined by schema
origin_table STRING METADATA FROM 'value.source.table' VIRTUAL,
`id` INT,
`spu_name` STRING,
`description` STRING,
`category3_id` INT,
`tm_id` INT
) WITH (
'connector' = 'kafka',
'topic' = 'input_kafka4',
'properties.group.id' = '57',
'properties.bootstrap.servers' = '10.1.64.156:9092',
'scan.startup.mode' = 'latest-offset',
'debezium-json.ignore-parse-errors' = 'true',
'format' = 'debezium-json'
);
select * from Kafka_Table where origin_database='gmall' and origin_table = 'spu_info'; //Here, the filtering operation of the specified library and table is realizedThen the problem ② will be solved. Then we need to do two things now:
① Write a DataStream project of Flink CDC for multi database and multi table synchronization and transfer it to bus Kafka.
② Customize the json format of bus Kafka.
4, Create a DataStream project for FlinkCDC
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1. Obtain execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//1.1 set CK & status backend
//slightly
//2. Build SourceFunction and read data through FlinkCDC
DebeziumSourceFunction<String> sourceFunction = MySQLSource.<String>builder()
.hostname("10.1.64.157")
.port(3306)
.username("root")
.password("123456")
.databaseList("gmall") //This annotation is multi database synchronization
//. tableList("gmall.spu_info") / / this comment is multi table synchronization
.deserializer(new CustomerDeserialization()) //You need to customize the serialization format here
//. deserializer(new StringDebeziumDeserializationSchema()) / / the default is this serialization format
.startupOptions(StartupOptions.latest())
.build();
DataStreamSource<String> streamSource = env.addSource(sourceFunction);
//3. Print data and write data to Kafka
streamSource.print();
String sinkTopic = "input_kafka4";
streamSource.addSink(getKafkaProducer("10.1.64.156:9092",sinkTopic));
//4. Start the task
env.execute("FlinkCDC");
}
//kafka producer
public static FlinkKafkaProducer<String> getKafkaProducer(String brokers,String topic) {
return new FlinkKafkaProducer<String>(brokers,
topic,
new SimpleStringSchema());
}
}5, Custom serialization class
import com.alibaba.fastjson.JSONObject;
import com.alibaba.ververica.cdc.debezium.DebeziumDeserializationSchema;
import io.debezium.data.Envelope;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.util.Collector;
import org.apache.kafka.connect.data.Field;
import org.apache.kafka.connect.data.Schema;
import org.apache.kafka.connect.data.Struct;
import org.apache.kafka.connect.source.SourceRecord;
import java.util.ArrayList;
import java.util.List;
public class CustomerDeserialization implements DebeziumDeserializationSchema<String> {
@Override
public void deserialize(SourceRecord sourceRecord, Collector<String> collector) throws Exception {
//1. Create a JSON object to store the final data
JSONObject result = new JSONObject();
//2. Get the database name & table name and put it into source
String topic = sourceRecord.topic();
String[] fields = topic.split("\\.");
String database = fields[1];
String tableName = fields[2];
JSONObject source = new JSONObject();
source.put("database",database);
source.put("table",tableName);
Struct value = (Struct) sourceRecord.value();
//3. Get "before" data
Struct before = value.getStruct("before");
JSONObject beforeJson = new JSONObject();
if (before != null) {
Schema beforeSchema = before.schema();
List<Field> beforeFields = beforeSchema.fields();
for (Field field : beforeFields) {
Object beforeValue = before.get(field);
beforeJson.put(field.name(), beforeValue);
}
}
//4. Obtain "after" data
Struct after = value.getStruct("after");
JSONObject afterJson = new JSONObject();
if (after != null) {
Schema afterSchema = after.schema();
List<Field> afterFields = afterSchema.fields();
for (Field field : afterFields) {
Object afterValue = after.get(field);
afterJson.put(field.name(), afterValue);
}
}
//5. Obtain the letter of debezium OP compliant operation type CREATE UPDATE DELETE
Envelope.Operation operation = Envelope.operationFor(sourceRecord);
String type = operation.toString().toLowerCase();
if ("insert".equals(type)) {
type = "c";
}
if ("update".equals(type)) {
type = "u";
}
if ("delete".equals(type)) {
type = "d";
}
if ("create".equals(type)) {
type = "c";
}
//6. Write fields to JSON objects
result.put("source", source);
result.put("before", beforeJson);
result.put("after", afterJson);
result.put("op", type);
//7. Output data
collector.collect(result.toJSONString());
}
@Override
public TypeInformation<String> getProducedType() {
return BasicTypeInfo.STRING_TYPE_INFO;
}
}OK, run the flinkCDC project, insert a record into the synchronized database table, and get the JSON with the following custom format:
{
"op": "u",
"before": {
"spu_name": "Chanel( Chanel)Lady perfume 5 perfume powder meets tender Eau De Toilette EDT ",
"tm_id": 11,
"description": "Chanel( Chanel)Lady perfume 5 perfume powder meets tender Eau De Toilette EDT 111",
"id": 11,
"category3_id": 473
},
"source": {
"database": "gmall",
"table": "spu_info"
},
"after": {
"spu_name": "Chanel( Chanel)Lady perfume 5 perfume powder meets tender Eau De Toilette EDTss ",
"tm_id": 11,
"description": "Chanel( Chanel)Lady perfume 5 perfume powder meets tender Eau De Toilette EDT 111",
"id": 11,
"category3_id": 473
}
}PS: I didn't put the schema {} object. I read the document and said that adding recognition would affect efficiency.
6, Bus Kafka
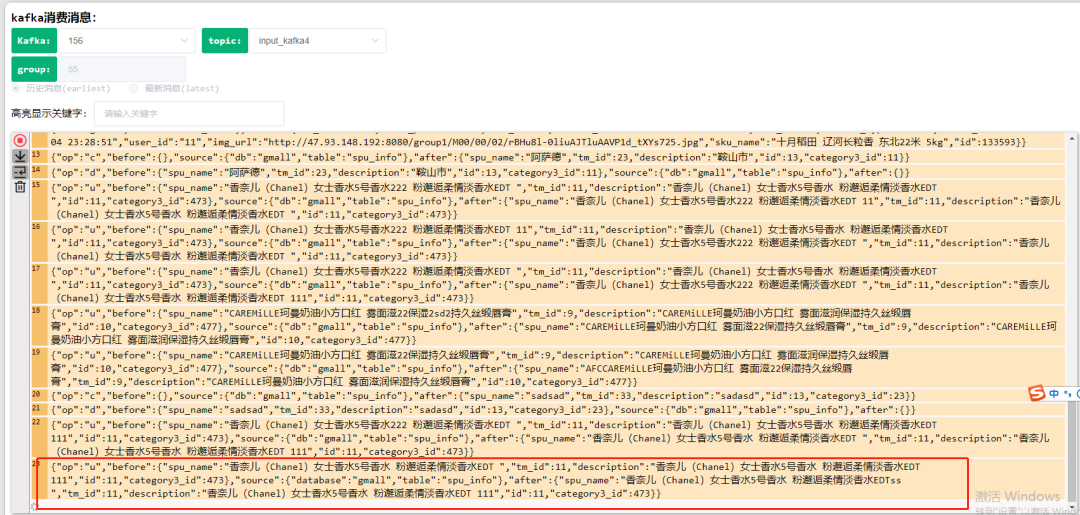
7, Dinky development and submission
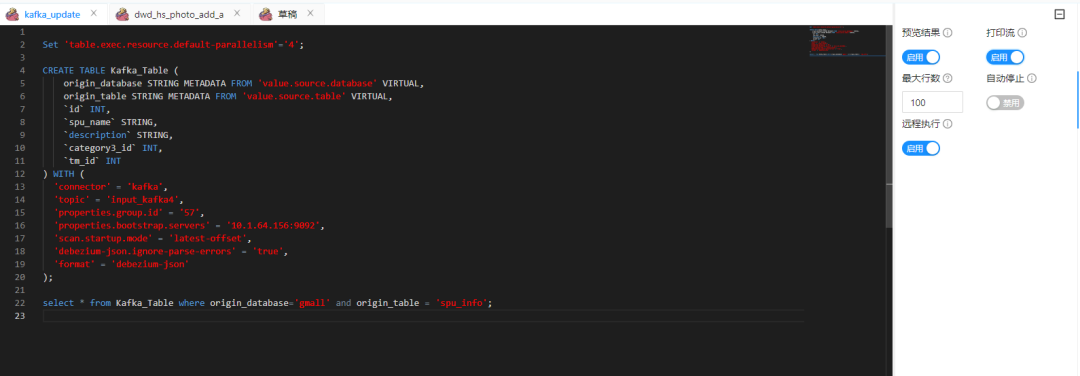
PS: yarn session mode, remember to turn on the preview result and print stream, otherwise the data changelog cannot be observed
8, View results
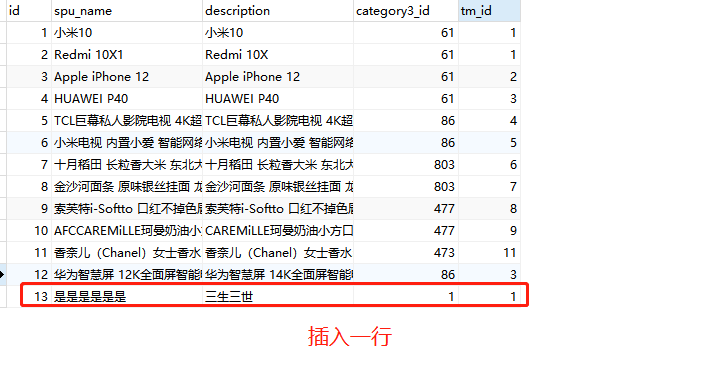
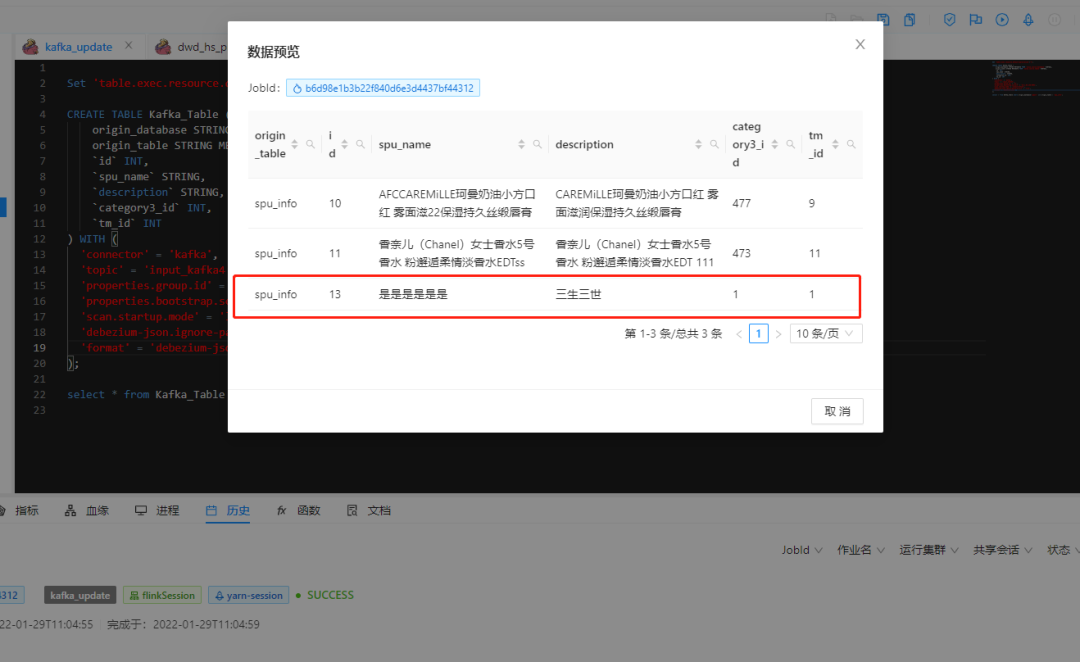
You can see that a new piece of data is added to the specified database and table, and the synchronous update is realized in the downstream kafka job. Then try to delete the records of the table in the database. The results are as follows:
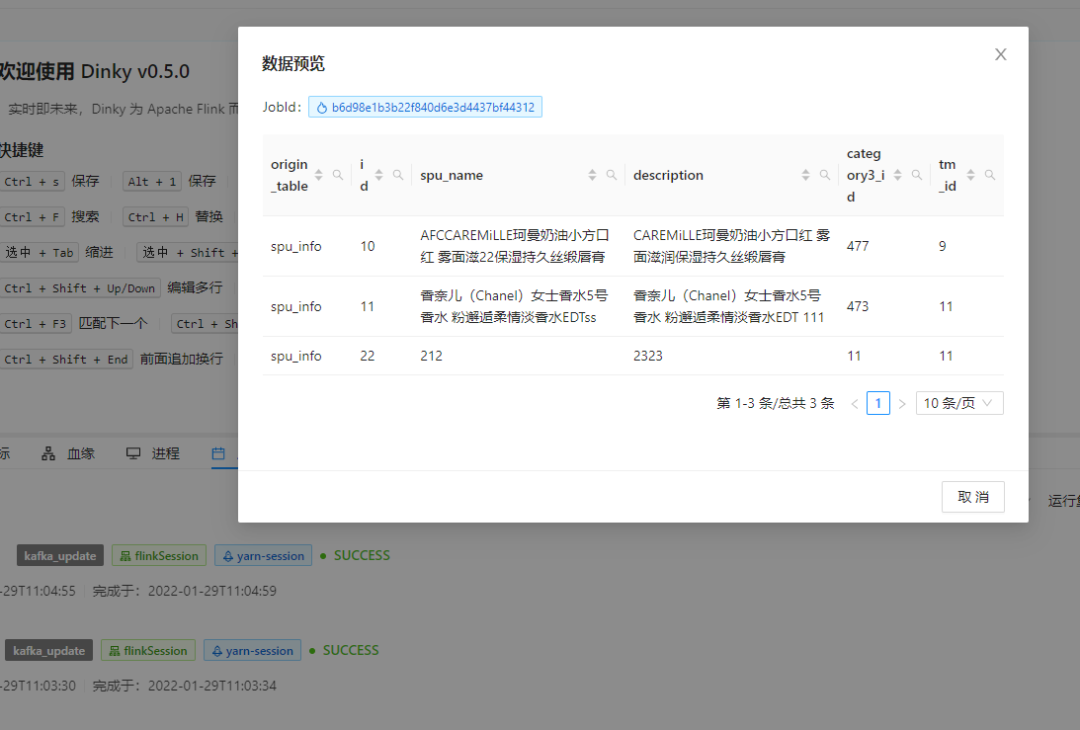
You can see "yes..." This record was deleted synchronously.
At this time, the record of Flink CDC is as follows:

The principle is mainly that OP desynchronizes the op in the changeLog of downstream kafka.
Let's browse changeLog: (Dinky can select the print stream)
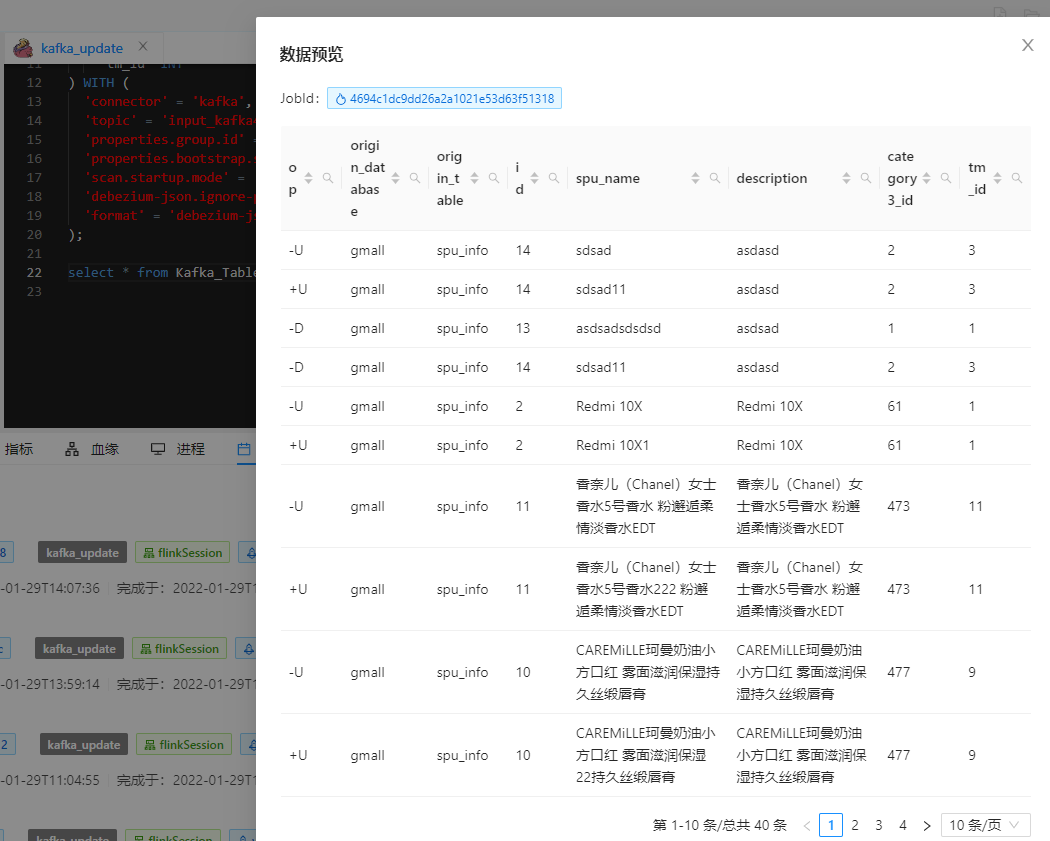
It can be seen that the op automatically recognizes that the JSON sent by the bus kafka has been synchronized to record the operation.
Later, we can insert the upsert Kafka table for specific table operations.
Done! In this way, you only need to build a bus jar of DataStream and submit it in Dinky. For subsequent downstream operations, you only need kafka to connect to the bus. kafka can carry out multi-source consolidation and synchronous update of Flink CDC in Flink SQL.
9, Summary
The inspiration and code come from Shang Silicon Valley. Please support Dinky monk Silicon Valley. In addition, it is carried out in the test environment, and the production environment tuning is solved by yourself. If there is better practice, you are welcome to supplement the document. Thank you!