In data science, you may waste a lot of time coding and waiting for the computer to run something. So I chose some Python libraries that can help you save valuable time.
1,Optuna
Optuna is an open source hyperparametric optimization framework, which can automatically find the best hyperparameters for machine learning models.
The most basic (and possibly well-known) alternative is sklearn's GridSearchCV, which will try a variety of super parameter combinations and choose the best combination based on cross validation.
The GridSearchCV will attempt to combine within a previously defined space. For example, for a random forest classifier, you might want to test the maximum depth of several different trees. GridSearchCV provides all possible values for each super parameter and looks at all combinations.
Optuna will use the history of its own attempts in the defined search space to determine the value to be tried next. The method it uses is a Bayesian optimization algorithm called "tree structured Parzen estimator".
This different approach means that instead of trying every value pointlessly, it looks for the best candidate before trying, which can save time, otherwise it will spend trying hopeless alternatives (and may also produce better results).
Finally, it's framework independent, which means you can use it with TensorFlow, Keras, PyTorch, or any other ML framework.
2,ITMO_FS
ITMO_FS is a feature selection library, which can select features for ML models. The fewer observations you have, the more you need to handle too many features carefully to avoid over fitting. The so-called "caution" means that your model should be standardized. Usually a simpler model (fewer features) is easier to understand and explain.
ITMO_FS algorithm is divided into six different categories: supervised filter, unsupervised filter, wrapper, hybrid, embedded and integrated (although it mainly focuses on supervised filter).
A simple example of the supervised filter algorithm is to select features based on their correlation with the target variable. "backward selection", you can try to delete features one by one and confirm how these features affect the prediction ability of the model.
This is a question about how to use ITMO_ Common examples of FS and its impact on model scores:
>>> from sklearn.linear_model import SGDClassifier >>> from ITMO_FS.embedded import MOS >>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2) >>> sel = MOS() >>> trX = sel.fit_transform(X, y, smote=False) >>> cl1 = SGDClassifier() >>> cl1.fit(X, y) >>> cl1.score(X, y) 0.9033333333333333 >>> cl2 = SGDClassifier() >>> cl2.fit(trX, y) >>> cl2.score(trX, y) 0.9433333333333334
ITMO_FS is a relatively new library, so it's still a little unstable, but I still suggest giving it a try.
3,shap-hypetune
So far, we have seen libraries for feature selection and superparameter adjustment, but why not use both at the same time? This is the function of shap hypetune.
Let's start by understanding what "shake" is:
"SHAP(SHapley Additive exPlanations)It is a game theory method used to explain the output of any machine learning model. "
SHAP is one of the most widely used libraries for interpreting models. It works by generating the importance of each feature to the final prediction of the model.
On the other hand, shap hypertune benefits from this method to select the best features and the best super parameters. Why did you merge? Because the interaction between them is not considered, selecting features and adjusting super parameters independently may lead to suboptimal selection. The simultaneous execution of these two items not only takes this into account, but also saves some coding time (although the running time may be increased due to the increase of search space).
Search can be done in three ways: grid search, random search or Bayesian search (in addition, it can be parallelized).
However, shap hypertune is only applicable to the gradient lifting model!
4,PyCaret
PyCaret is an open source, low code machine learning library that automates machine learning workflows. It covers exploratory data analysis, preprocessing, modeling (including interpretability) and MLOps.
Let's look at some practical examples on their website to see how it works:
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes')
# init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable')
# compare models
best = compare_models()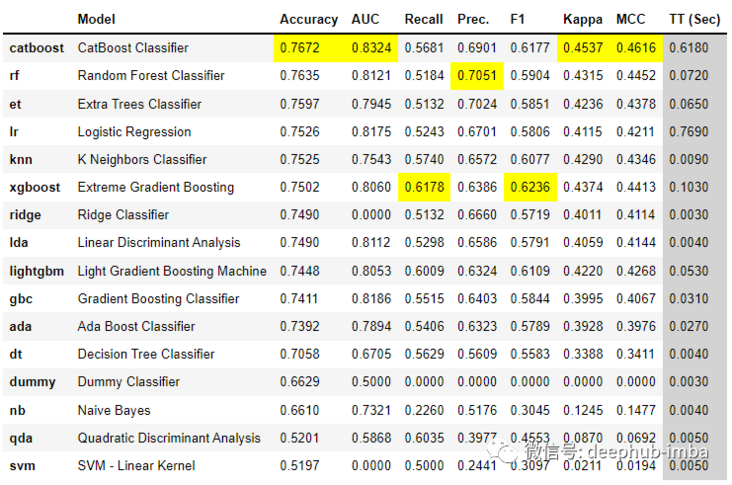
With just a few lines of code, you can try multiple models and compare them across the main classification indicators.
It also allows you to create a basic application to interact with the model:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_app(lr)Finally, you can easily create API and Docker files for the model:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_api(lr, 'lr_api')
create_docker('lr_api')Nothing is easier than that, right?
PyCaret is a very complete library, which is difficult to cover all the contents here. It is recommended that you download it now and start using it to understand some of its abilities in practice.
5,floWeaver
FloWeaver can generate sangi diagrams from stream datasets. If you don't know what sankitus is, here's an example:
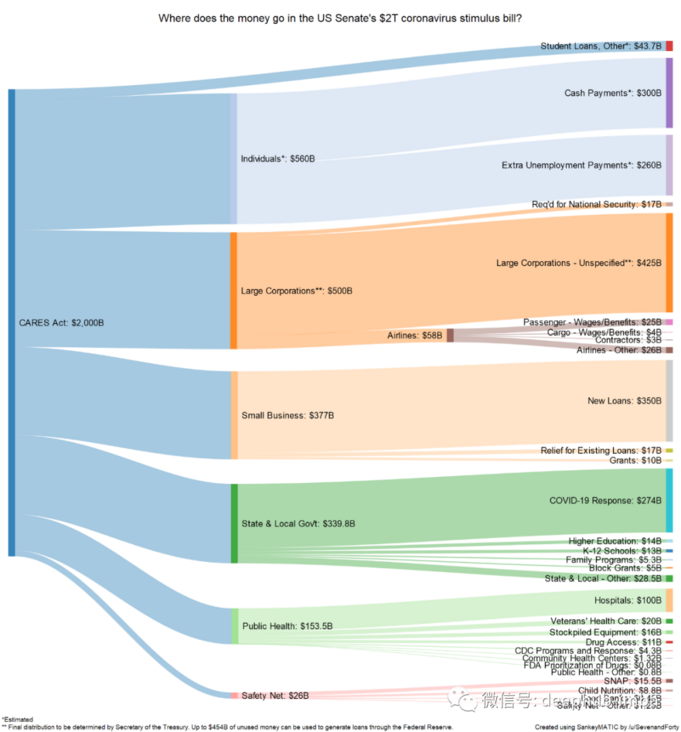
They are useful when displaying data on conversion funnels, marketing journeys, or budget allocations (example above). The entry data should be in the following format: "source x target x value". This kind of diagram can be created with only one line of code (very specific, but also very intuitive).
6,Gradio
If you read data science, you will know how helpful it is to have a front-end interface that allows end users to interact with data from the beginning of the project. Generally speaking, the most commonly used in Python is Flask, but it is not very friendly to beginners. It requires multiple files and some knowledge of html, css and so on.
Gradio allows you to create a simple interface by setting input types (text, check boxes, etc.), functions, and outputs. Although it doesn't seem as customizable as flash, it's more intuitive.
Since Gradio has now joined Huggingface, it can permanently host the Gradio model on the Internet, and it is free!
7,Terality
The best way to understand territy is to think of it as "Pandas, but faster". This does not mean that Pandas is completely replaced, and you must relearn how to use df: territy, which has exactly the same syntax as Pandas. In fact, they even suggested "import terrain as PD" and continue coding in the usual way.
How fast is it? Sometimes they say it 10 times faster.
Another important thing is that Terality allows parallelization and it does not run locally, which means that your 8GB RAM laptop will no longer have MemoryErrors!
But how does it work behind it? A good metaphor for understanding Terality is that they can think of the Pandas compatible syntax they use locally and compile it into Spark computing operations, and use Spark for back-end computing. So computing is not running locally, but submitting computing tasks to their platform.
What's the problem? At most 1TB of data can be processed free of charge every month. If you need more, you must pay at least $49 a month. 1TB / month may be more than enough for testing tools and personal projects, but if you need it to be used by the actual company, you must pay.
8,torch-handle
If you are a user of pytoch, you can try this library.
Torchhandle is an auxiliary framework of PyTorch. It abstracts the tedious and repetitive training code of PyTorch, enabling data scientists to focus on data processing, model creation and parameter optimization, rather than writing repetitive training loop code. Using torchhandle can make your code more concise and readable, and make your development tasks more efficient.
torchhandle abstracts and extracts the training and reasoning process of pytorch. As long as a few lines of code are used, the deep learning pipeline of pytorch can be realized. It can generate complete training reports and integrate tensorboard for visualization.
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseContext
class Net(torch.nn.Module):
def __init__(self, ):
super().__init__()
self.layer = torch.nn.Sequential(OrderedDict([
('l1', torch.nn.Linear(10, 20)),
('a1', torch.nn.ReLU()),
('l2', torch.nn.Linear(20, 10)),
('a2', torch.nn.ReLU()),
('l3', torch.nn.Linear(10, 1))
]))
def forward(self, x):
x = self.layer(x)
return x
num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam,
"args": {"lr": 0.1},
"params": {"layer.l1.weight": {"lr": 0.01},
"layer.l1.bias": {"lr": 0.02}}
}
scheduler = {"fn": torch.optim.lr_scheduler.StepLR,
"args": {"step_size": 2, "gamma": 0.9}
}
c = BaseContext(model=model,
criterion=criterion,
optimizer=optimizer,
scheduler=scheduler,
context_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)Define a model, set up a data set, configure the optimizer and loss function, and you can train automatically. Is it similar to TF.
https://www.overfit.cn/post/c333c3f3a2b2409dae03fea56c1daae3
By Arthur Mello