preface
Detailed explanation of awk variables, common built-in variables, user-defined variables, built-in variables NR, NF, FNR, RS, ORS, FILENAME, ARGC and ARGV
awk variable
"Variables" are divided into "built-in variables" and "custom variables". "Input separator FS" and "output separator OFS" are built-in variables.
Built in variables are pre-defined and built-in variables in awk, and user-defined variables are user-defined variables.
Common built-in variables
The commonly used built-in variables of awk and their functions are as follows
FS: Enter the field separator, which defaults to blank characters OFS: The output field separator is blank by default RS: Enter record separator(Enter line feed), Specifies the newline character when entering ORS: Output record separator (output newline character). When outputting, replace the newline character with the specified symbol NF: number of Field,Number of fields in the current row(That is, the current line is divided into several columns),Number of fields NR: Line number: the line number of the currently processed text line. FNR: Line number of each document counted separately FILENAME: Current file name ARGC: Number of command line parameters ARGV: Array, which saves the parameters given by the command line
For example, the input field separator FS, the output field separator OFS and the number of fields NF explained in the previous section.
Built in variable NR NF
Built in variable NR: indicates the line number of each line
Built in variable NF: indicates how many columns there are in each row.
There are three lines of text in the file, separated by spaces. The first line has three columns, the second line has three columns, and the third line has two columns
[root@node1 awkdir]# cat awktxt zaishu mysql qq xasdf xxx sdfsadf dd xx
[root@node1 awkdir]# awk '{print NR,NF}' awktxt
1 3 //First row 3 columns
2 3
3 2
Print out the whole line with $0.
[root@node1 awkdir]# awk '{print NR,$0}' awktxt
1 zaishu mysql qq
2 xasdf xxx sdfsadf
3 dd xx
Neither built-in variables nor custom variables use "$" like the shell, but directly use the variable name.
Built in variable FNR
- NR process multiple files
When awk processes multiple files, if NR is used to display line numbers, all lines of multiple files will be sorted in order.
[root@node1 awkdir]# cat awktxt zaishu mysql qq xasdf xxx sdfsadf dd xx
[root@node1 awkdir]# cat awktxt2 abc#123#efg#hij 9ijdd#sdf#asdf#bnm
[root@node1 awkdir]# awk '{print NR,$0}' awktxt awktxt2
1 zaishu mysql qq
2 xasdf xxx sdfsadf
3 dd xx
4 abc#123#efg#hij
5 9ijdd#sdf#asdf#bnm
- FNR processes multiple files
To display the line numbers of two files separately, you can use the built-in variable FNR.
[root@node1 awkdir]# awk '{print FNR,$0}' awktxt awktxt2
1 zaishu mysql qq
2 xasdf xxx sdfsadf
3 dd xx
1 abc#123#efg#hij
2 9ijdd#sdf#asdf#bnm
Its function is to count the number of lines of each file when awk processes multiple files.
Built in variable RS
RS is the input line separator. If it is not specified, the default "line separator" is "carriage return and line feed".
Instead of using the default "carriage return and line feed" as the "line separator", we want to use spaces as the so-called line separator, that is, we want awk to think that every time we encounter a space, we will wrap the line. In other words, we want awk to think that every time we encounter a space, we will create a new line. Examples are as follows.
[root@node1 awkdir]# cat awktxt3 asdf wer uoiou sdfl 123 ljk3 9xds sdf 0knm 8hjlk
- Default line break
[root@node1 awkdir]# awk '{print NR,$0}' awktxt
1 zaishu mysql qq
2 xasdf xxx sdfsadf
3 dd xx
- Use spaces as line breaks
[root@node1 awkdir]# awk -v RS=" " '{print NR,$0}' awktxt3
1 asdf
2 wer
3 uoiou
4 sdfl
123 ## For awk, this is one line, all the fourth line
5 ljk3
6 9xds
sdf
7 0knm
8 8hjlk
When specifying the use of space as the "line separator", when awk parses the text, whenever a space is encountered, awk considers the encountered space as a line feed, so awk wraps the text. At this time, the previous "carriage return line feed" is not a so-called line feed for awk, so the phenomenon of lines 4 and 6 in the above figure appears, but in awk, it is a line.
Built in variable ORS
By default, "carriage return and line feed" is used as the output line separator,
Now, let awk think that "+ +" is the real output line separator, as shown in the following figure
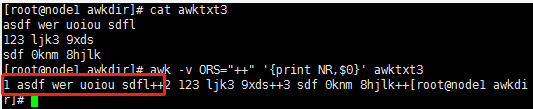
At this time, the output newline character is replaced with + +.
- Use "input newline character" and "output newline character" at the same time to see what effect it is. An example is as follows.
[root@node1 awkdir]# awk -v RS=" " -v ORS="++" '{print NR,$0}' awktxt3
1 asdf++2 wer++3 uoiou++4 sdfl
123++5 ljk3++6 9xds
sdf++7 0knm++8 8hjlk
++[root@node1 awkdir]#
A space encountered represents a line. When outputting, the newline character is changed to++
Built in variable FILENAME
FILENAME, a built-in variable, displays the file name
[root@node1 awkdir]# awk '{print FILENAME,FNR,$0}' awktxt awktxt2
awktxt 1 zaishu mysql qq
awktxt 2 xasdf xxx sdfsadf
awktxt 3 dd xx
awktxt2 1 abc#123#efg#hij
awktxt2 2 9ijdd#sdf#asdf#bnm
Built in variables ARGC and ARGV
ARGC built-in variable: indicates the number of command line parameters.
ARGV built-in variable: represents an array that holds the parameters given by the command line.
[root@node1 awkdir]# awk 'BEGIN{print "aa"}' awktxt awktxt2
aa
[root@node1 awkdir]# awk 'BEGIN{print "aa",ARGV[1]}' awktxt awktxt2
aa awktxt
[root@node1 awkdir]# awk 'BEGIN{print "aa",ARGV[1],ARGV[2]}' awktxt awktxt2
aa awktxt awktxt2
Use BEGIN mode to output a string "aa", and then pass in the file names of two files as parameters. BEGIN mode normally performs the printing operation, outputs the "aa" string, and prints the values of the second and third elements in the ARGV array.
ARGV built-in variable represents an array. Since it is an array, you need to use the subscript in the above figure to refer to the value of the corresponding element. Because the index of the array starts from 0, ARGV[1] refers to the value of the second element in ARGV array and the value of ARGV[2]. It is found that the value corresponding to ARGV[2] is awktxt2, The RGV built-in variable represents an array composed of all parameters.
ARGV[0] corresponds to the first parameter, that is, the awk command itself. Awk specifies that 'pattern {action}' is not regarded as a parameter, and awk is regarded as a parameter.
[root@node1 awkdir]# awk 'BEGIN{print "aa",ARGV[0],ARGV[1],ARGV[2]}' awktxt awktxt2
aa awk awktxt awktxt2
In the example just now, there should be three parameters, awk, awktxt1 and awktxt2. These three parameters are stored in ARGV as the elements of the array. Now, ARGC represents the number of parameters, which can also be understood as the length of the ARGV array. Examples are as follows
[root@node1 awkdir]# awk 'BEGIN{print "aa",ARGV[0],ARGV[1],ARGC}' awktxt awktxt2
aa awk awktxt 3
Custom variable
Custom variables, as the name suggests, are user-defined variables. There are two ways to customize variables.
Method 1: - v varname=value variable names are case sensitive.
Method 2: directly define in the program.
- Method 1: custom variables.
[root@node1 awkdir]# awk -v myVar="testVar" 'BEGIN{print myVar}'
testVar
This method has another advantage. When you need to reference variables in the shell in awk, you can indirectly reference them through method 1. as follows
[root@node1 awkdir]# var=6666
[root@node1 awkdir]# awk -v myvar=$var 'BEGIN{print myvar}'
6666
- Use method 2 to define custom variables directly in the program
Note: semicolon ";" is required between variable definition and action separate.
[root@node1 awkdir]# awk 'BEGIN{ myVar="testVar"; print myVar}'
testVar
Define multiple variables at once
[root@node1 awkdir]# awk 'BEGIN{ myVar1="Var1"; myVar2="Var2"; print myVar1,myVar2}'
Var1 Var2
summary
Detailed explanation of awk variables, common built-in variables, user-defined variables, built-in variables NR, NF, FNR, RS, ORS, FILENAME, ARGC and ARGV