
Transformer has made great progress in computer vision tasks. The transformer in transformer (TNT) architecture utilizes internal and external transformers to extract local and global representations. In this work, a new TNT Baseline is proposed by introducing two advanced designs:
- Pyramid Architecture
- Convolutional Stem
The new level of "pyrt" is significantly improved by "tndt". PyramidTNT has better performance than the previous most advanced Vision Transformer, such as swing transformer.
1 Introduction
Vision Transformer provides a new solution for computer vision. Starting from ViT, a series of work to improve the architecture of Vision Transformer are proposed.
- PVT introduces the pyramid network architecture of Vision Transformer
- T2T-ViT-14 recursively aggregates adjacent tokens into one Token to extract local structure and reduce the number of tokens
- TNT uses inner Transformer and outer Transformer to model the visual representation of word level and sense level
- Swin Transformer proposes a hierarchical Transformer, whose representation is calculated by Shifted windows
With the research progress in recent years, the performance of Vision Transformer has been better than convolutional neural network (CNN). This work of this paper is to establish an improved Vision Transformer Baseline based on TNT framework. Two major architecture modifications are introduced here:
- Pyramid Architecture: gradually reduce the resolution and extract multi-scale representation
- Revolutionary Stem: repair Stem and stability training
Here, the author also uses several other techniques to further improve efficiency. The new Transformer is named PyramidTNT.
Experiments on image classification and target detection prove the superiority of pyramid detection. Specifically, PyramidTNT-S achieved an ImageNet classification accuracy of 82.0% when there were only 3.3B FLOPs, which was significantly better than the original TNT-S and swing-t.
For COCO detection, PyramidTNT-S realizes 42.0 mAP at less computational cost than the existing Transformer and MLP detection models.
2. This method
2.1 Convolutional Stem
Given an input image X\in R^{H × W} Firstly, TNT model divides the image into multiple patches, and further regards each patch as a sub patch sequence. Then the linear layer is applied to project the sub patch to the visual word vector (also known as token). These visual words are spliced together and converted into a visual sense vector.
Schoo et al. Found that using multiple convolutions as Stem in ViT can improve optimization stability and performance. On this basis, this paper constructs a convolution Stem of pyramid. Utilization 3 × 3 convolution stack generates visual word vector Y\in R^{H/2 × W/2 × C} Where C is the dimension of visual word vector. Visual sense vector Z \ in R ^ {H / 8 can also be obtained × W/8 × D} Where D is the dimension of visual sense vector. Word level and sense level location codes are added to visual words and senses respectively, just like the original TNT.
class Stem(nn.Module):
"""
Image to Visual Word Embedding
"""
def __init__(self, img_size=224, in_chans=3, outer_dim=768, inner_dim=24):
super().__init__()
img_size = to_2tuple(img_size)
self.img_size = img_size
self.inner_dim = inner_dim
self.num_patches = img_size[0] // 8 * img_size[1] // 8
self.num_words = 16
self.common_conv = nn.Sequential(
nn.Conv2d(in_chans, inner_dim*2, 3, stride=2, padding=1),
nn.BatchNorm2d(inner_dim*2),
nn.ReLU(inplace=True),
)
# Using inner Transformer to model word level
self.inner_convs = nn.Sequential(
nn.Conv2d(inner_dim*2, inner_dim, 3, stride=1, padding=1),
nn.BatchNorm2d(inner_dim),
nn.ReLU(inplace=False),
)
# Using outer Transformer to model the visual representation of sense level
self.outer_convs = nn.Sequential(
nn.Conv2d(inner_dim*2, inner_dim*4, 3, stride=2, padding=1),
nn.BatchNorm2d(inner_dim*4),
nn.ReLU(inplace=True),
nn.Conv2d(inner_dim*4, inner_dim*8, 3, stride=2, padding=1),
nn.BatchNorm2d(inner_dim*8),
nn.ReLU(inplace=True),
nn.Conv2d(inner_dim*8, outer_dim, 3, stride=1, padding=1),
nn.BatchNorm2d(outer_dim),
nn.ReLU(inplace=False),
)
self.unfold = nn.Unfold(kernel_size=4, padding=0, stride=4)
def forward(self, x):
B, C, H, W = x.shape
H_out, W_out = H // 8, W // 8
H_in, W_in = 4, 4
x = self.common_conv(x)
# inner_tokens modeling and word level representation
inner_tokens = self.inner_convs(x) # B, C, H, W
inner_tokens = self.unfold(inner_tokens).transpose(1, 2) # B, N, Ck2
inner_tokens = inner_tokens.reshape(B * H_out * W_out, self.inner_dim, H_in*W_in).transpose(1, 2) # B*N, C, 4*4
# outer_tokens modeling and sense level representation
outer_tokens = self.outer_convs(x) # B, C, H_out, W_out
outer_tokens = outer_tokens.permute(0, 2, 3, 1).reshape(B, H_out * W_out, -1)
return inner_tokens, outer_tokens, (H_out, W_out), (H_in, W_in)
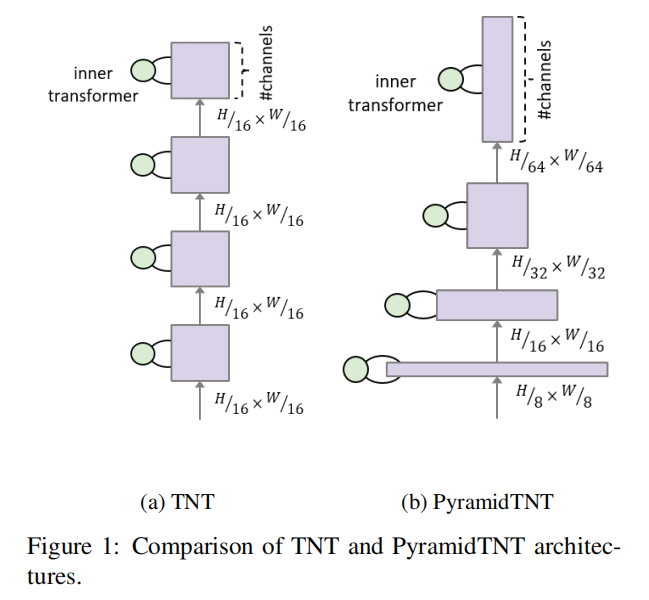
2.2 Pyramid Architecture
The original TNT network maintains the same number of token s in each block after ViT. The number of visual words and visual senses remains the same from bottom to top.
Inspired by PVT, this paper constructs four different number of Token stages for TNT, as shown in Figure 1(b). It is shown that in these four stages, the spatial shape of visual words is set to H/2 respectively × W/2,H/4 × W/4,H/8 × W/8,H/16 × W/16; The spatial shape of visual senses is set to h / 8 respectively × W/8,H/16 × W/16,H/32 × W/32,H/64 × W/64. The down sampling operation is realized by convolution of stripe = 2. Each stage consists of several TNT blocks, which operate on word level and sense level features. Finally, using the global average pooling operation, the output visual senses are fused into a vector as the image representation.
class SentenceAggregation(nn.Module):
"""
Sentence Aggregation
"""
def __init__(self, dim_in, dim_out, stride=2, act_layer=nn.GELU):
super().__init__()
self.stride = stride
self.norm = nn.LayerNorm(dim_in)
self.conv = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=2*stride-1, padding=stride-1, stride=stride),
)
def forward(self, x, H, W):
B, N, C = x.shape # B, N, C
x = self.norm(x)
x = x.transpose(1, 2).reshape(B, C, H, W)
x = self.conv(x)
H, W = math.ceil(H / self.stride), math.ceil(W / self.stride)
x = x.reshape(B, -1, H * W).transpose(1, 2)
return x, H, W
class WordAggregation(nn.Module):
"""
Word Aggregation
"""
def __init__(self, dim_in, dim_out, stride=2, act_layer=nn.GELU):
super().__init__()
self.stride = stride
self.dim_out = dim_out
self.norm = nn.LayerNorm(dim_in)
self.conv = nn.Sequential(
nn.Conv2d(dim_in, dim_out, kernel_size=2*stride-1, padding=stride-1, stride=stride),
)
def forward(self, x, H_out, W_out, H_in, W_in):
B_N, M, C = x.shape # B*N, M, C
x = self.norm(x)
x = x.reshape(-1, H_out, W_out, H_in, W_in, C)
# padding to fit (1333, 800) in detection.
pad_input = (H_out % 2 == 1) or (W_out % 2 == 1)
if pad_input:
x = F.pad(x.permute(0, 3, 4, 5, 1, 2), (0, W_out % 2, 0, H_out % 2))
x = x.permute(0, 4, 5, 1, 2, 3)
# patch merge
x1 = x[:, 0::2, 0::2, :, :, :] # B, H/2, W/2, H_in, W_in, C
x2 = x[:, 1::2, 0::2, :, :, :]
x3 = x[:, 0::2, 1::2, :, :, :]
x4 = x[:, 1::2, 1::2, :, :, :]
x = torch.cat([torch.cat([x1, x2], 3), torch.cat([x3, x4], 3)], 4) # B, H/2, W/2, 2*H_in, 2*W_in, C
x = x.reshape(-1, 2*H_in, 2*W_in, C).permute(0, 3, 1, 2) # B_N/4, C, 2*H_in, 2*W_in
x = self.conv(x) # B_N/4, C, H_in, W_in
x = x.reshape(-1, self.dim_out, M).transpose(1, 2)
return x
class Stage(nn.Module):
"""
PyramidTNT stage
"""
def __init__(self, num_blocks, outer_dim, inner_dim, outer_head, inner_head, num_patches, num_words, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, se=0, sr_ratio=1):
super().__init__()
blocks = []
drop_path = drop_path if isinstance(drop_path, list) else [drop_path] * num_blocks
for j in range(num_blocks):
if j == 0:
_inner_dim = inner_dim
elif j == 1 and num_blocks > 6:
_inner_dim = inner_dim
else:
_inner_dim = -1
blocks.append(Block(
outer_dim, _inner_dim, outer_head=outer_head, inner_head=inner_head,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop,
attn_drop=attn_drop, drop_path=drop_path[j], act_layer=act_layer, norm_layer=norm_layer,
se=se, sr_ratio=sr_ratio))
self.blocks = nn.ModuleList(blocks)
self.relative_pos = nn.Parameter(torch.randn(1, outer_head, num_patches, num_patches // sr_ratio // sr_ratio))
def forward(self, inner_tokens, outer_tokens, H_out, W_out, H_in, W_in):
for blk in self.blocks:
inner_tokens, outer_tokens = blk(inner_tokens, outer_tokens, H_out, W_out, H_in, W_in, self.relative_pos)
return inner_tokens, outer_tokens
class PyramidTNT(nn.Module):
"""
PyramidTNT
"""
def __init__(self, configs=None, img_size=224, in_chans=3, num_classes=1000, mlp_ratio=4., qkv_bias=False,
qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm, se=0):
super().__init__()
self.num_classes = num_classes
depths = configs['depths']
outer_dims = configs['outer_dims']
inner_dims = configs['inner_dims']
outer_heads = configs['outer_heads']
inner_heads = configs['inner_heads']
sr_ratios = [4, 2, 1, 1]
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
self.num_features = outer_dims[-1] # num_features for consistency with other models
self.patch_embed = Stem(
img_size=img_size, in_chans=in_chans, outer_dim=outer_dims[0], inner_dim=inner_dims[0])
num_patches = self.patch_embed.num_patches
num_words = self.patch_embed.num_words
self.outer_pos = nn.Parameter(torch.zeros(1, num_patches, outer_dims[0]))
self.inner_pos = nn.Parameter(torch.zeros(1, num_words, inner_dims[0]))
self.pos_drop = nn.Dropout(p=drop_rate)
depth = 0
self.word_merges = nn.ModuleList([])
self.sentence_merges = nn.ModuleList([])
self.stages = nn.ModuleList([])
# 4 stages required for building pyromidtnt
for i in range(4):
if i > 0:
self.word_merges.append(WordAggregation(inner_dims[i-1], inner_dims[i], stride=2))
self.sentence_merges.append(SentenceAggregation(outer_dims[i-1], outer_dims[i], stride=2))
self.stages.append(Stage(depths[i], outer_dim=outer_dims[i], inner_dim=inner_dims[i],
outer_head=outer_heads[i], inner_head=inner_heads[i],
num_patches=num_patches // (2 ** i) // (2 ** i), num_words=num_words, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[depth:depth+depths[i]], norm_layer=norm_layer, se=se, sr_ratio=sr_ratios[i])
)
depth += depths[i]
self.norm = norm_layer(outer_dims[-1])
# Classifier head
self.head = nn.Linear(outer_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
inner_tokens, outer_tokens, (H_out, W_out), (H_in, W_in) = self.patch_embed(x)
inner_tokens = inner_tokens + self.inner_pos # B*N, 8*8, C
outer_tokens = outer_tokens + self.pos_drop(self.outer_pos) # B, N, D
for i in range(4):
if i > 0:
inner_tokens = self.word_merges[i-1](inner_tokens, H_out, W_out, H_in, W_in)
outer_tokens, H_out, W_out = self.sentence_merges[i-1](outer_tokens, H_out, W_out)
inner_tokens, outer_tokens = self.stages[i](inner_tokens, outer_tokens, H_out, W_out, H_in, W_in)
outer_tokens = self.norm(outer_tokens)
return outer_tokens.mean(dim=1)
def forward(self, x):
# The feature extraction layer can be used as a Backbone for downstream tasks
x = self.forward_features(x)
# Classification layer
x = self.head(x)
return x
2.3 other Tricks
In addition to modifying the network architecture, several advanced techniques of Vision Transformer are adopted.
- Add relative position coding on the self attention module to better represent the relative position between tokens.
- The first two stages use Linear spatial reduction attention(LSRA) to reduce the computational complexity of long sequence self attention.
3 experiment
3.1 classification
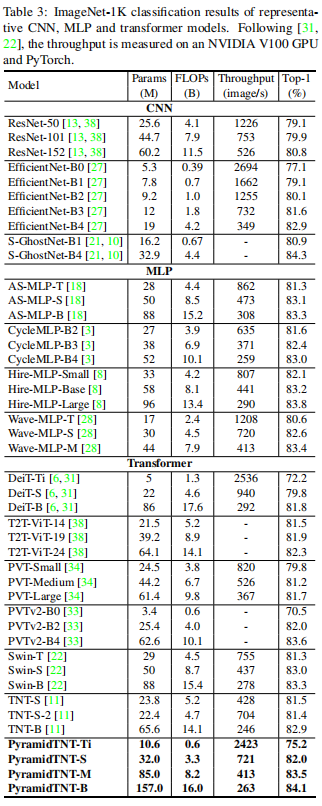
Table 3 shows the ImageNet-1K classification results. Compared with the original TNT, PyramidTNT achieves better image classification accuracy. For example, compared with TNT-S, the Top-1 accuracy of TNT-S with 1.9B less is 0.5% higher. PyramidTNT is also compared with other representative CNN, MLP and Transformer based models. From the results, we can see that PyramidTNT is the most advanced Vision Transformer.
3.2 target detection
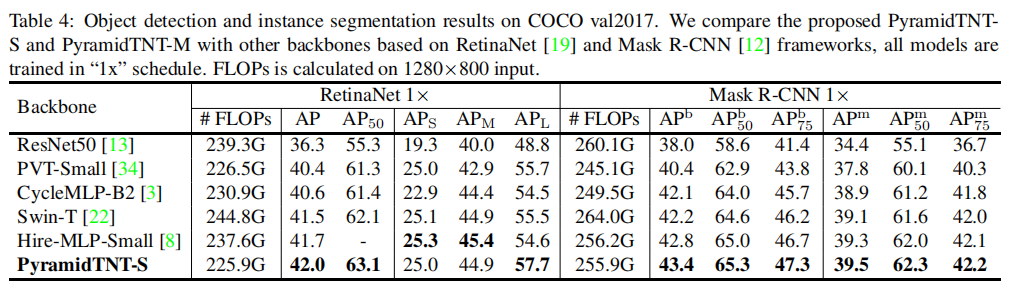
Table 4 reports the results of target detection and instance segmentation under the "1x" training plan. PyramidTNT-S is significantly better than other backbones on one stage and two stage detectors, and the calculation cost is similar. For example, RetinaNet based on PyramidTNT-S achieves 42.0 AP and 57.7 ap-l, which are 0.5 AP and 2.2 APL higher than the models using swin transformer, respectively.
These results show that the PyramidTNT architecture can better capture the global information of large objects. The simple upsampling strategy and small spatial shape of the pyramid make AP-S from a large-scale generalization.
3.3 instance segmentation
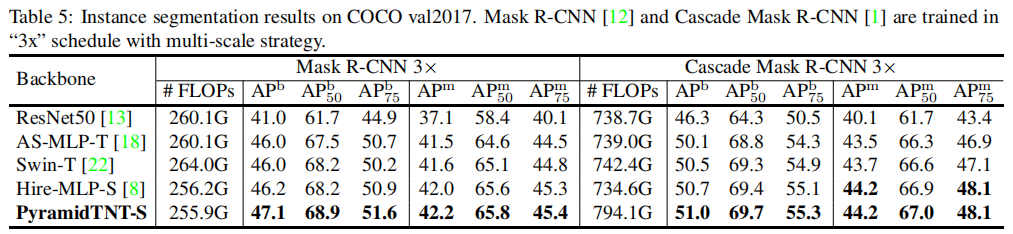
The AP-m of PyramidTNT-S on Mask R-CNN and Cascade Mask R-CNN can obtain better AP-b and AP-m, showing better feature representation ability. For example, on the ParamidTNN constraint, MaskR-CNN-S exceeds 0.9AP-b of hire MLPs.
4 reference
[1].PyramidTNT:Improved Transformer-in-Transformer Baselines with Pyramid Architecture