Note: please correct any mistakes. This blog is for learning reference only. Come on!
1, First acquaintance with electricsearch
1.1 INTRODUCTION
elasticsearch is a Lucene based search server. It provides a distributed multi-user full-text search engine based on RESTful web interface. Elasticsearch is developed in the Java language and released as an open source under the Apache license terms. It is a popular enterprise search engine. Elasticsearch is used in cloud computing, which can achieve real-time search, stable, reliable, fast and easy to install and use.
elastic search combines kibana, Logstash and Beats, that is, elastic stack (ELK). It is widely used in log data analysis, real-time monitoring and other fields; Elastic search is the core of elastic stack, which is responsible for storing, searching and analyzing data.

the bottom layer of elastic search is implemented based on Lucene. Lucene is a search engine class library of Java language. It is a top-level project of Apache Company. It was developed by DougCutting in 1999. Lucene has the following advantages and disadvantages:
Lucene's advantages:
- Easy to expand
- High performance (based on inverted index)
Disadvantages of Lucene:
- Java language development only
- Steep learning curve (high learning cost)
- Horizontal expansion is not supported
ElasticSearch's advantages over Lucene:
- Support distributed and horizontally scalable
- Restful interface is provided, which can be called by any language
Summary of relevant interview questions:
1) What is elastic search?
- An open source distributed search engine can be used to realize the functions of search, log statistics, analysis, system monitoring and so on.
2) What is elastic stack (ELK)?
- It is a technology stack with elasticsearch as the core, including beats, Logstash, kibana and elasticsearch.
3) What is Lucene?
- It is the open source search engine class library of Apache and provides the core API of search engine.
1.2 inverted index (key)
The concept of inverted index is based on forward indexes such as MySQL.
1.2.1 forward index
So what is a forward index? For example, create an index for the id in the following table (tb_goods):
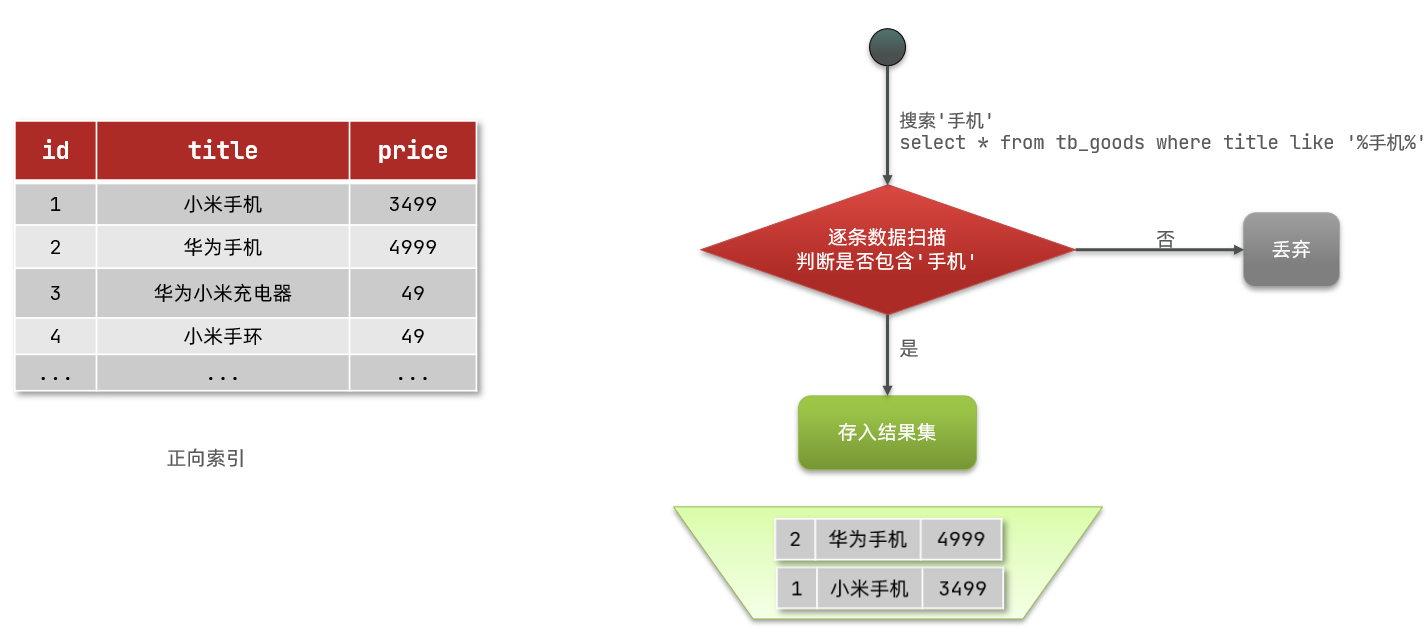
if the query is based on id, the index is directly used, and the query speed is very fast. However, if the fuzzy query is based on the title, the data can only be scanned line by line. The process is as follows:
1) Users search for data if the title meets the "% mobile%"
2) Get data line by line, such as data with id 1
3) Judge whether the title in the data meets the user's search conditions
4) If yes, it will be put into the result set, and if not, it will be discarded. Return to step 1
progressive scanning, that is, full table scanning, will reduce the query efficiency as the amount of data increases. When the amount of data reaches millions, the query efficiency will be very low.
1.2.2 inverted index
There are two very important concepts in inverted index:
- Document: data used to search. Each piece of data is a document. For example, a web page, a product information
- Term: for document data or user search data, use some algorithm to segment words, and the words with meaning are terms. For example, if I am Chinese, I can be divided into several terms: I, yes, Chinese, Chinese and Chinese
Creating inverted index is a special process for forward index. The process is as follows:
- The data of each document is segmented by the algorithm to get each entry
- Create a table, and each row of data includes the entry, the document id where the entry is located, the location and other information
- Because entries are unique, you can create indexes for entries, such as hash table structure index
As shown in the figure:

The search process of inverted index is as follows (take the search of "Huawei mobile phone" as an example):
1) The user enters the condition "Huawei mobile phone" to search.
2) Segment the user's input content to get the entry: Huawei, mobile phone.
3) Take the entry and look it up in the inverted index to get the document id containing the entry: 1, 2 and 3.
4) Take the document id to the forward index to find the specific document.
As shown in the figure:
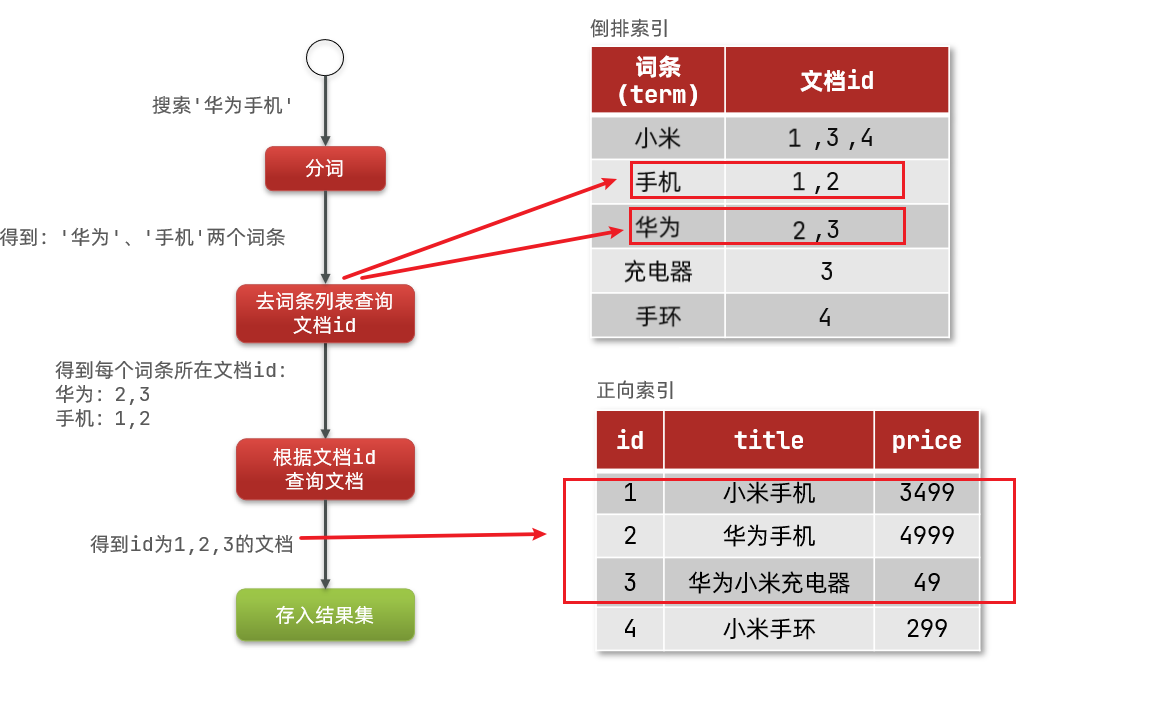
Note: although it is necessary to query the inverted index first and then the forward index, the index is established for both the entry and the document id, and the query speed is very fast! No full table scanning is required.
1.2.3 forward and reverse (comparison)
Comparison of forward index and inverted index:
-
Forward indexing is the most traditional way of indexing according to id. However, when querying according to terms, you must first obtain each document (data of each line) one by one, and then judge whether the document contains the required terms (keywords), which is the process of finding terms according to the document.
-
On the contrary, the inverted index first finds the term that the user wants to search, obtains the id of the document containing the term according to the term, and then obtains the document according to the id. It is the process of finding documents according to entries.
The advantages and disadvantages of the two indexes are as follows:
Advantages of forward indexing:
- Multiple fields can be indexed.
- Searching and sorting according to the index field is very fast.
Disadvantages of forward indexing:
- When searching according to non index fields or some entries in index fields, you can only scan the whole table (the index will fail), and the query speed will slow down when the amount of data is large.
Advantages of inverted index:
- According to the entry search, fuzzy search, the speed is very fast.
Disadvantages of inverted index:
- Only entries can be indexed, not fields.
- Cannot sort by field.
1.3 other concepts of ES
1.3.1 documents and fields
elastic search is Document oriented storage, which can be a piece of commodity data and an order information in the database. The Document data will be serialized into Json format and stored in elasticsearch; Json documents often contain many fields, similar to columns in the database.

1.3.2 indexing and mapping
An Index is a collection of documents of the same type.
For example:
- All user documents can be organized together, which is called user index;
- The documents of all commodities can be organized together, which is called the index of commodities;
- The documents of all orders can be organized together, which is called the order index;

Therefore, we can treat the index as a table in the database (the index in es is also called the index library). An index can be compared to a table in a database.
The database table will have constraint information, which is used to define the table structure, field name, type and other information. Therefore, there is mapping in the index library, which is the field constraint information of the document in the index, similar to the structural constraint of the table. Map the constraint information of the table in the corresponding database.
1.3.3 comparison between MySQL and elasticsearch (key points)
Compare our concepts of search and mysql:
| MySQL | Elasticsearch | explain |
|---|---|---|
| Table | Index | An index is a collection of documents, similar to a database table |
| Row | Document | Document s are pieces of data, similar to rows in a database. All documents are in JSON format |
| Column | Field | A Field is a Field in a JSON document, similar to a Column in a database |
| Schema | Mapping | Mapping is a constraint on documents in the index, such as field type constraints. Table structure constraint (Schema) similar to database |
| SQL | DSL | DSL is a JSON style HTTP request statement provided by elasticsearch, which is used to operate elasticsearch and realize CRUD |
Does it mean that we no longer need mysql after learning elasticsearch?
Not so. They have their own strengths:
- Mysql: good at transaction type operation, which can ensure the security and consistency of data.
- Elastic search: good at searching, analyzing and calculating massive data.
Therefore, in enterprises, the two are often used in combination:
- Write operations that require high security are implemented using mysql.
- For the search requirements with high query performance, elastic search is used.
- The two are based on some way to realize data synchronization and ensure consistency. (e.g. rabbit MQ)
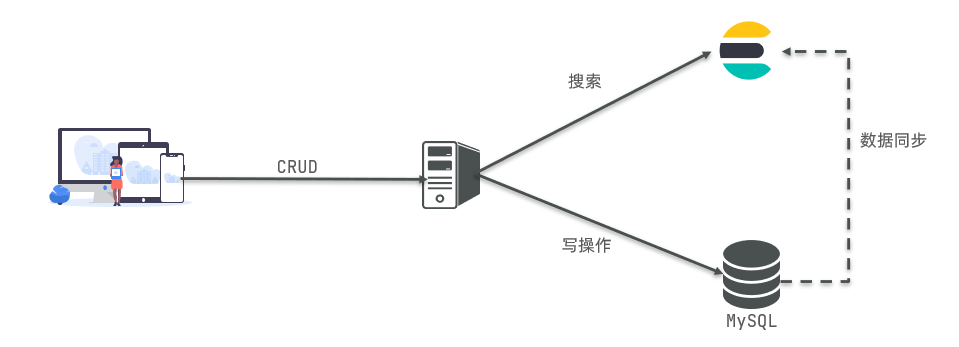
1.4 installation of ES and Kibana
Reference link: Docker installation ES, Kibana
1.5 using kibana
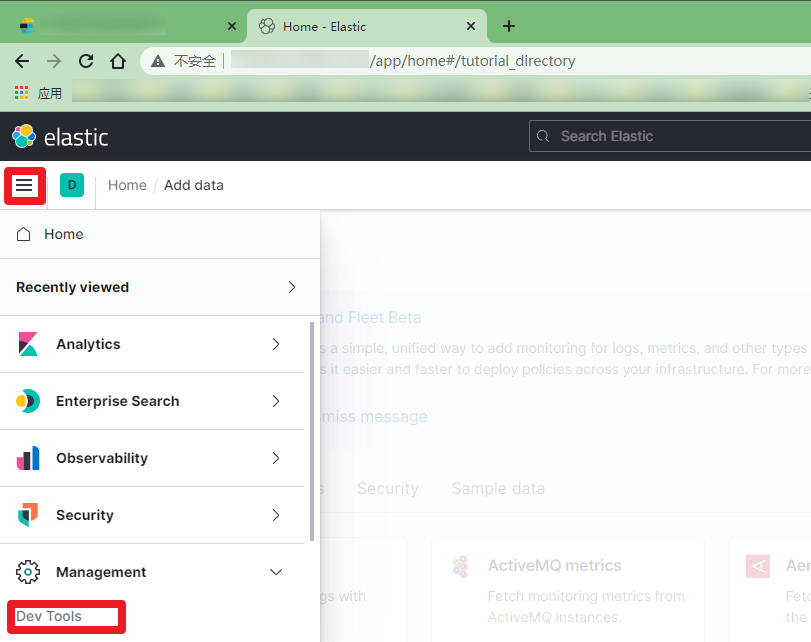
1.5.1 Dev Tools
kibana provides a DevTools interface: pull down and you can see DevTools. In this interface, you can write DSL to operate elasticsearch. It also has the function of automatic completion of DSL statements.
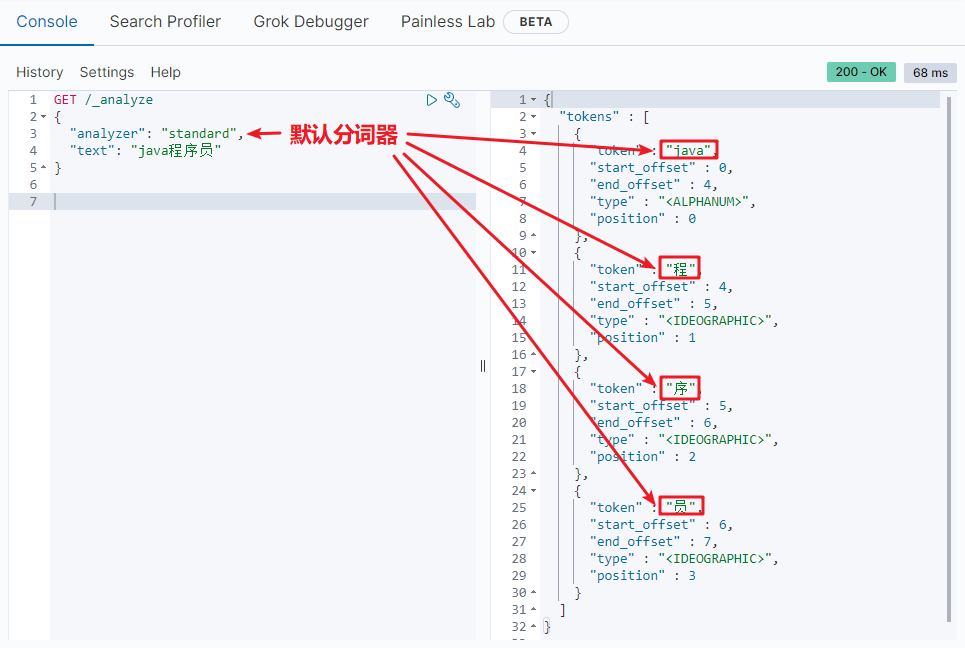
1.5.2 default word splitter standard
The following DSL s are used to test the effect of word segmentation:
Syntax tips:
- GET: request method.
- /_ analyze: the request path is omitted here http://192.168.150.101:9200 , kibana will help us supplement the request parameters in json style.
- analyzer: word breaker type. Here is the default standard word breaker.
- text: the content to be segmented.
1.5.3 IK word splitter
Installation reference: Docker install IK word breaker
The IK word splitter contains two modes:
- ik_smart: minimum segmentation (coarse granularity)
- ik_max_word: thinnest segmentation (fine grain)
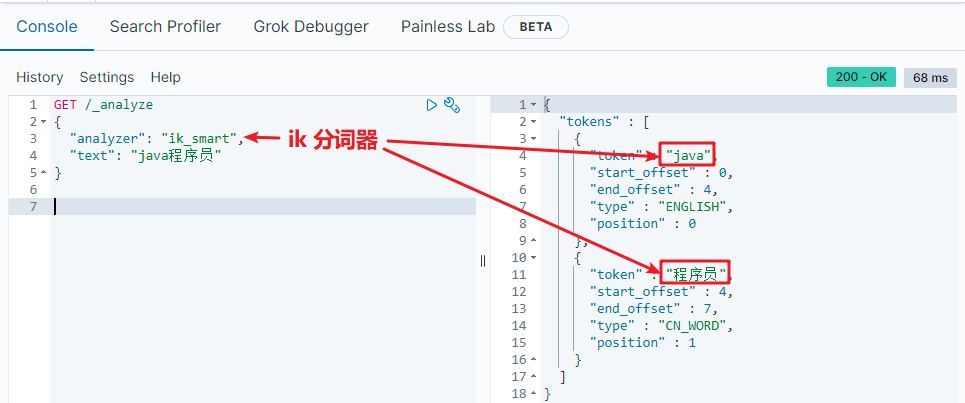
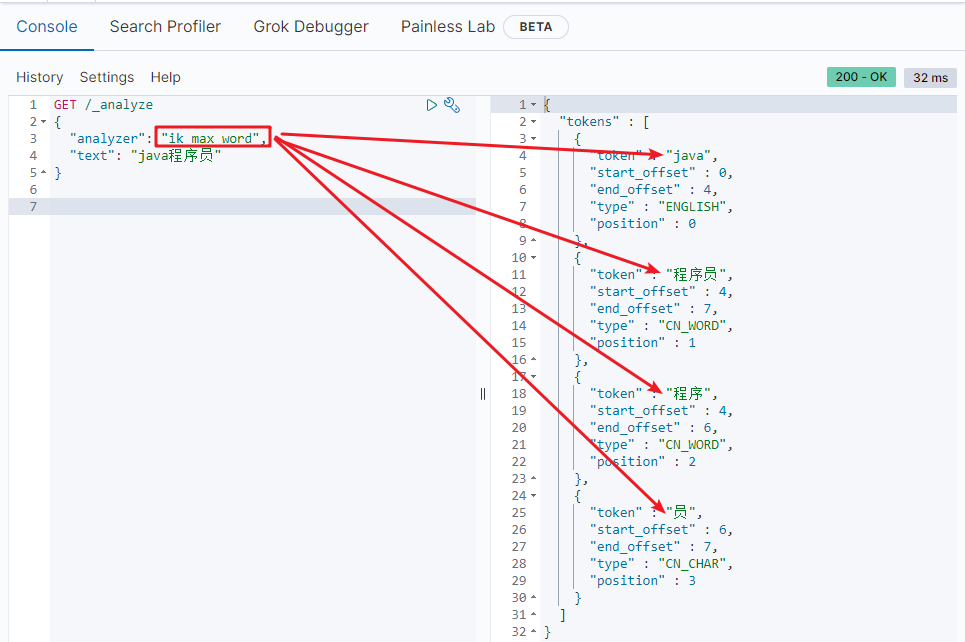
Common interview questions of word splitter:
1) What is the function of the word splitter?
- Word segmentation of documents when creating inverted indexes
- When the user searches, the input content is segmented
2) How many modes does the IK word splitter have?
- ik_smart: intelligent segmentation, coarse granularity
- ik_max_word: the most fine-grained segmentation
3) How does the IK word splitter extend entries? How to deactivate an entry?
- Using ikanalyzer. config directory cfg. Add extended dictionary and deactivate dictionary to XML file
- Add expanded or disabled entries to the dictionary
1.5.4 extended dictionary
with the development of the Internet, "word making movement" is becoming more and more frequent. Many new words have appeared, which do not exist in the original vocabulary list (Dictionary). For example: "aoligai", "brush your face" and so on. You can test text as "Java discipline, Aoli!" Word segmentation effect.
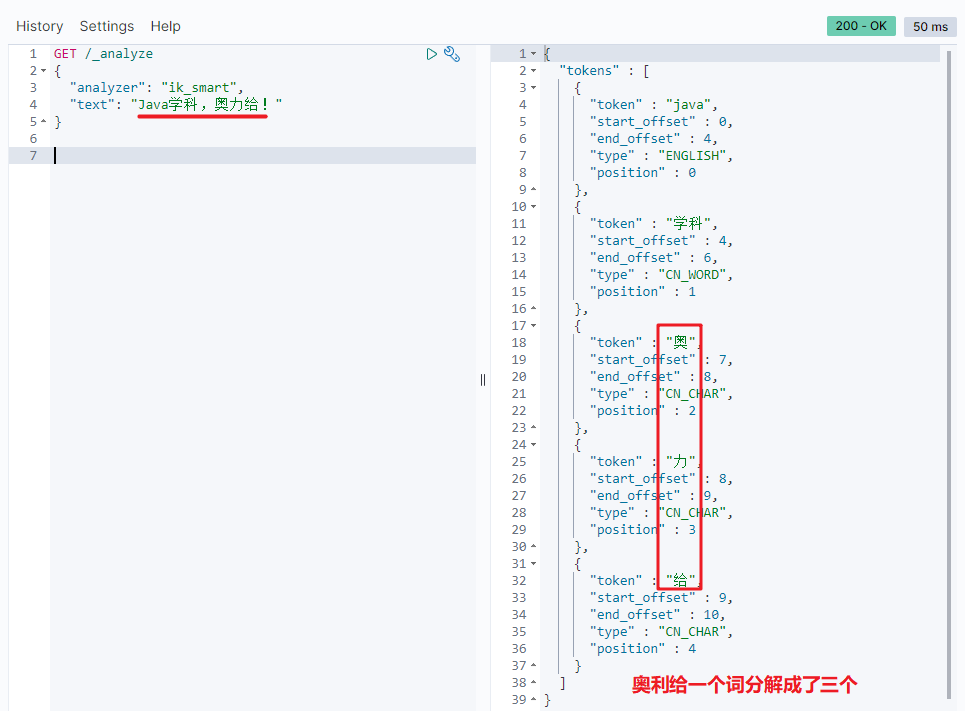
Therefore, the thesaurus of the word splitter also needs to be constantly updated. IK word splitter provides the function of expanding the thesaurus.
1) Open the config directory of IK word splitter: (the mounting of data volume is used here)
[root@VM-16-16-centos ~]# cd ../var/lib/docker/volumes/es-config/_data/analysis-ik [root@VM-16-16-centos analysis-ik]# ll total 8260 -rw-rw---- 1 lighthouse root 5225922 Feb 15 09:21 extra_main.dic -rw-rw---- 1 lighthouse root 63188 Feb 15 09:21 extra_single_word.dic -rw-rw---- 1 lighthouse root 63188 Feb 15 09:21 extra_single_word_full.dic -rw-rw---- 1 lighthouse root 10855 Feb 15 09:21 extra_single_word_low_freq.dic -rw-rw---- 1 lighthouse root 156 Feb 15 09:21 extra_stopword.dic -rw-rw---- 1 lighthouse root 625 Feb 15 09:21 IKAnalyzer.cfg.xml -rw-rw---- 1 lighthouse root 3058510 Feb 15 09:21 main.dic -rw-rw---- 1 lighthouse root 123 Feb 15 09:21 preposition.dic -rw-rw---- 1 lighthouse root 1824 Feb 15 09:21 quantifier.dic -rw-rw---- 1 lighthouse root 164 Feb 15 09:21 stopword.dic -rw-rw---- 1 lighthouse root 192 Feb 15 09:21 suffix.dic -rw-rw---- 1 lighthouse root 752 Feb 15 09:21 surname.dic
2) At ikanalyzer cfg. XML configuration file content addition: (save and exit)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here -->
<entry key="ext_dict">ext.dic</entry>
<!--Users can configure their own extended stop word dictionary here-->
<entry key="ext_stopwords"></entry>
<!--Users can configure the remote extension dictionary here -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--Users can configure the remote extended stop word dictionary here-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3) Create a new ext.dic. You can copy a configuration file under the config directory for modification
awesome face swiping
4) Restart es
#Restart es container docker restart es # View log (optional) docker logs -f es
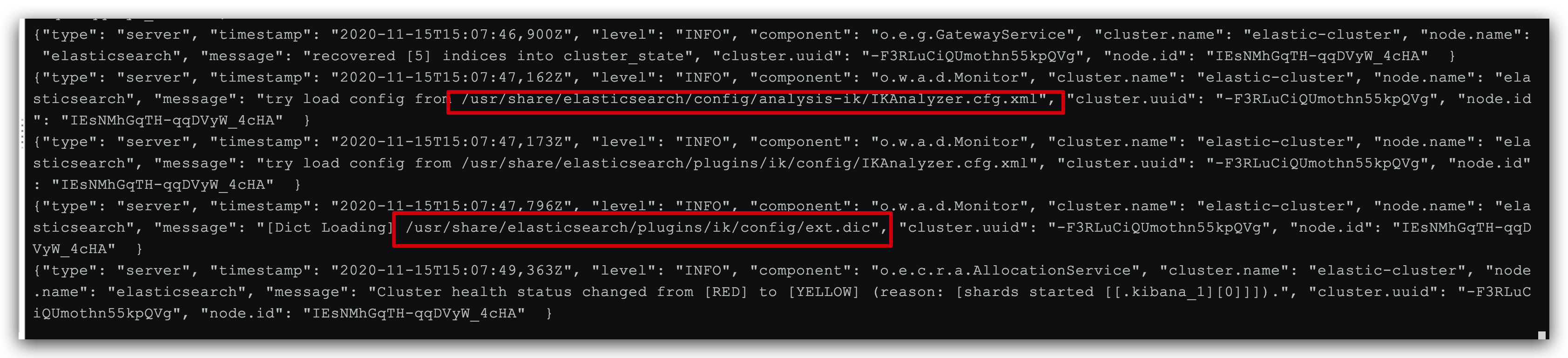
Ikanalyzer has been successfully loaded in the log cfg. XML configuration file, which loads the ext.dic file.
5) Test effect:
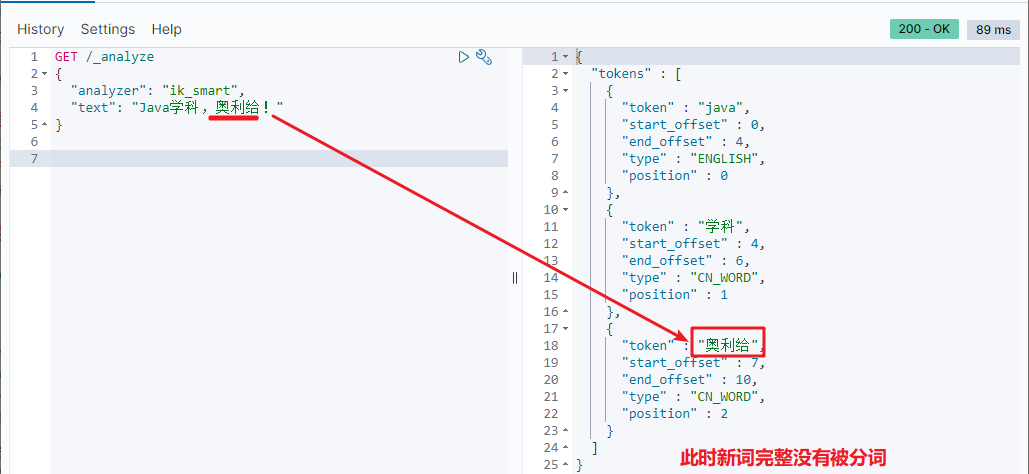
Note that the encoding of the current file must be in UTF-8 format. It is strictly prohibited to edit it with Windows Notepad
1.5.5 Dictionary of stop words
in Internet projects, the transmission speed between networks is very fast, so many languages are not allowed to be transmitted on the network, such as sensitive words such as religion and politics, so we should also ignore the current words when searching.
The IK word splitter also provides a powerful stop word function, allowing us to directly ignore the contents of the current stop vocabulary when indexing.
1)IKAnalyzer.cfg.xml configuration file content addition:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer Extended configuration</comment>
<!--Users can configure their own extended dictionary here -->
<entry key="ext_dict">ext.dic</entry>
<!--Users can configure their own extended stop word dictionary here-->
<entry key="ext_stopwords">stopword.dic</entry>
<!--Users can configure the remote extension dictionary here -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--Users can configure the remote extended stop word dictionary here-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
3) In stopword DIC add stop words (create files without files)
violence
4) Restart elasticsearch
# Restart service docker restart es docker restart kibana # View log docker logs -f es
Stopword.com has been successfully loaded in the log DIC configuration file.
5) Test effect:
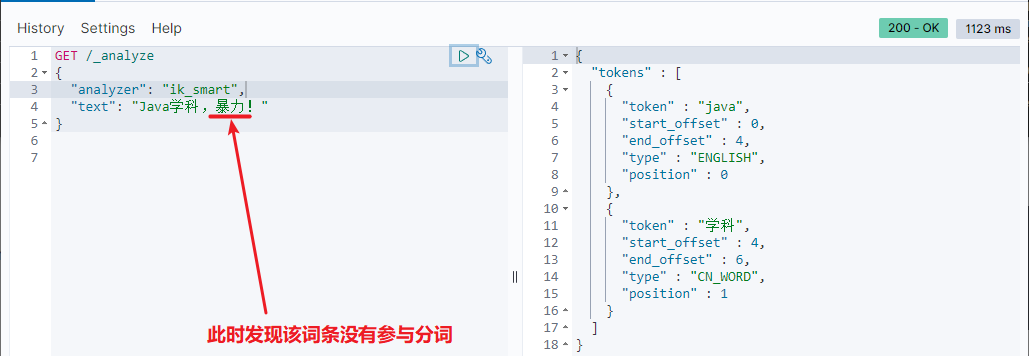
Note that the encoding of the current file must be in UTF-8 format. It is strictly prohibited to edit it with Windows Notepad
2, Index library operation
[there are multiple json documents (equivalent to records in the table) in the index library (equivalent to tables)]
2.1 mapping attribute
Mapping is a constraint on documents in the index library. Common mapping attributes include:
| attribute | explain |
|---|---|
| type | Field data types. Common simple types are: - String: text (separable text), keyword (exact value, such as brand, country, ip address) - numeric values: long, integer, short, byte, double, float - boolean - date: - object: object |
| index | Whether to create inverted index. The default value is true |
| analyzer | What kind of participle do you use |
| properties | Subfield of this field |
For example, the following json document:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "Java Lecturer, Ollie!",
"email": "cb@ccbx.cn",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "cloud",
"lastName": "Zhao"
}
}
mapping of each corresponding field: (key understanding)
- age: type is integer; Participate in the search, so the index needs to be true; No word splitter required
- weight: type is float; Participate in the search, so the index needs to be true; No word splitter required
- isMarried: type is boolean; Participate in the search, so the index needs to be true; No word splitter required
- info: the type is string and word segmentation is required, so it is text; Participate in the search, so the index needs to be true; The word splitter can use ik_smart
- email: the type is string, but word segmentation is not required, so it is keyword; Does not participate in the search, so the index needs to be false; No word splitter required
- score: although it is an array, we only look at the type of element. The type is float; Participate in the search, so the index needs to be true; No word splitter required
- name: the type is object, and multiple sub attributes need to be defined
- name.firstName; The type is string, but word segmentation is not required, so it is keyword; Participate in the search, so the index needs to be true; No word splitter required
- name.lastName; The type is string, but word segmentation is not required, so it is keyword; Participate in the search, so the index needs to be true; No word splitter required
Index of CRUD library 2.2
Here, we uniformly use Kibana to write DSL for demonstration.
What are the operations of the index library?
- Create index library: PUT / index library name
- Query index library: GET / index library name
- DELETE index library: DELETE / index library name
- Add field: PUT / index library name/_ mapping
2.2.1 creating index library and mapping
Basic syntax:
- Request method: PUT
- Request path: / index library name, which can be customized
- Request parameters: mapping
Format:
// Create index libraries and mappings
PUT /Index library name
{
"mappings": {
"properties": {
"Field name":{
"type": "text",
"analyzer": "ik_smart"
},
"Field name 2":{
"type": "keyword",
"index": false
},
"Field name 3":{
"properties": {
"Subfield": {
"type": "keyword"
}
}
},
// ... slightly
}
}
}
Example:
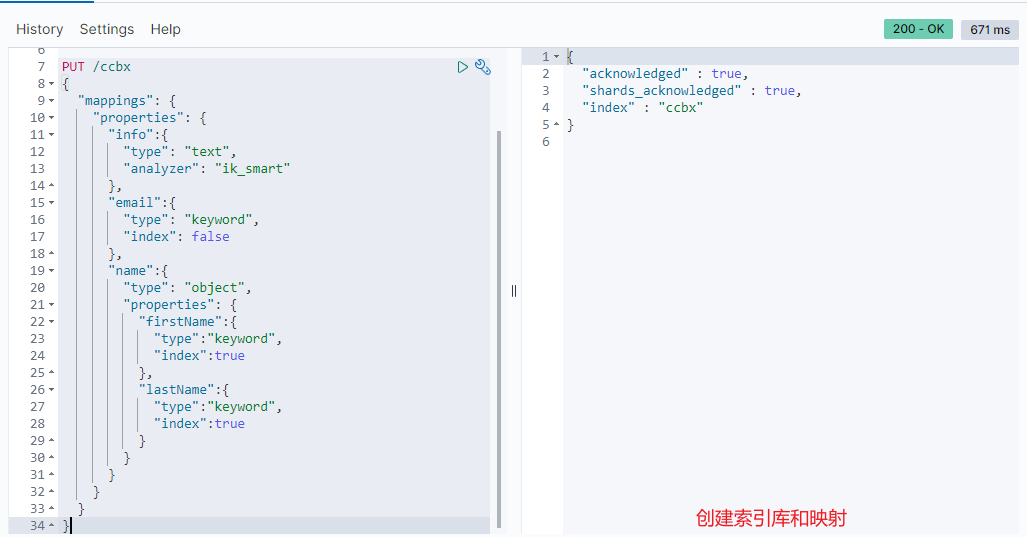
PUT /ccbx
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": false
},
"name":{
"type": "object",
"properties": {
"firstName":{
"type":"keyword",
"index":true
},
"lastName":{
"type":"keyword",
"index":true
}
}
}
}
}
}
The results are as follows:
2.2.2 query index library
Basic syntax:
- Request method: GET
- Request path: / index library name
- Request parameters: None
Format:
//Query index library GET /Index library name
Example:
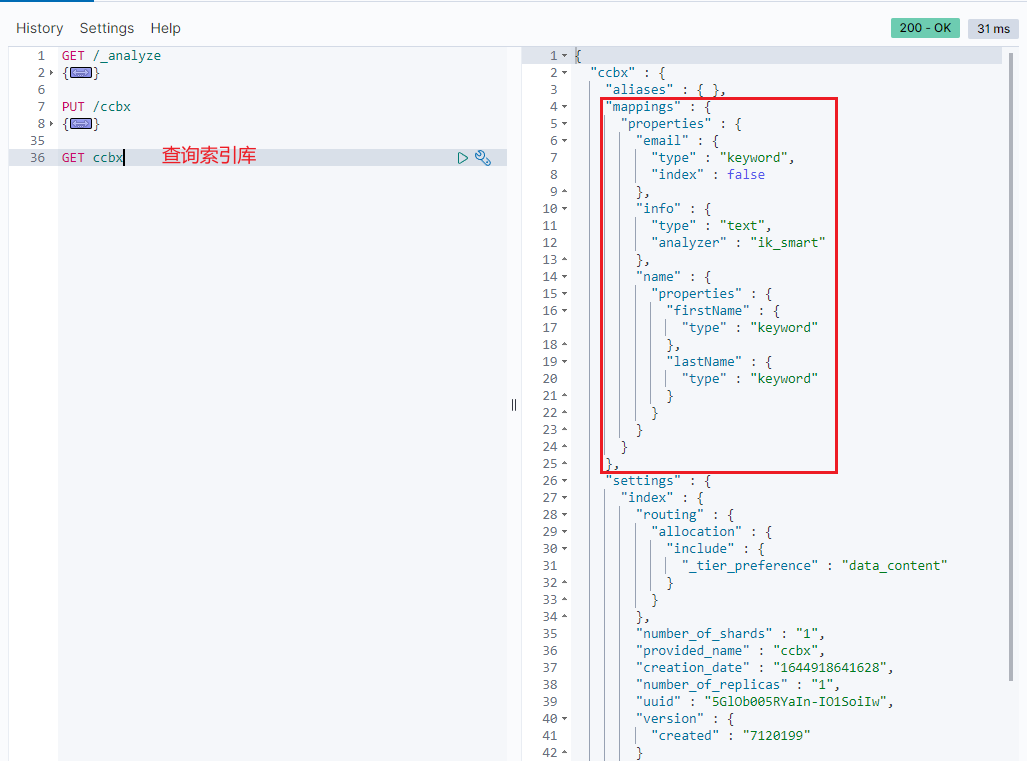
2.2.3 modify index library
although the inverted index structure is not complex, once the data structure changes (such as changing the word splitter), it is necessary to re create the inverted index, which is a disaster. Therefore, once the index library is created, mapping cannot be modified.
although the existing fields in mapping cannot be modified, it is allowed to add new fields to mapping because it will not affect the inverted index.
Syntax description:
PUT /Index library name/_mapping
{
"properties": {
"new field name":{
"type": "Specified type"
}
}
}
Example:
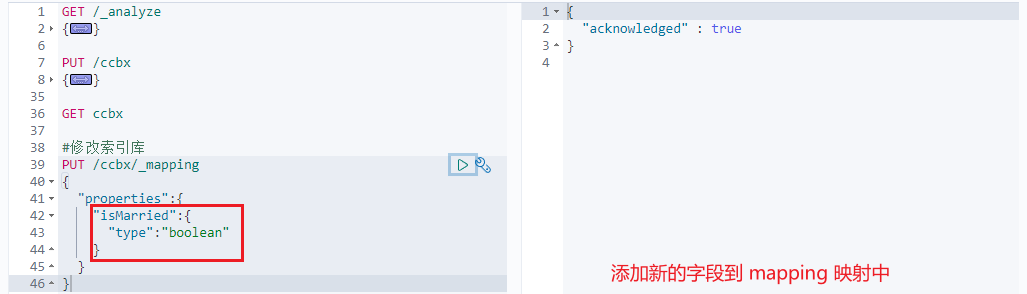
2.2.4 delete index library
Syntax:
-
Request method: DELETE
-
Request path: / index library name
-
Request parameters: None
Format:
//Delete index library DELETE /Index library name
Test in kibana:
#Create an index library and map
PUT /test-01
{
"mappings": {
"properties": {
"name":{
"type": "text",
"analyzer": "ik_smart"
}
}
}
}
#Query index library
GET test-01
#Delete index library
DELETE /test-01
3, Document operation
This is similar to adding data records to tables in a MySQL database.
What are the document operations?
- Create document: POST / {index library name}/_ doc / document ID {JSON document}
- GET library name: {query /}/_ doc / document id
- DELETE document: DELETE / {index library name}/_ doc / document id
- Modify document:
- Full modification: PUT / {index library name}/_ doc / document ID {JSON document}
- Incremental modification: POST / {index library name}/_ update / document ID {"Doc": {field}}
3.1 new documents
Syntax:
//New document
POST /Index library name/_doc/file id
{
"Field 1": "Value 1",
"Field 2": "Value 2",
"Field 3": {
"Sub attribute 1": "Value 3",
"Sub attribute 2": "Value 4"
},
// ...
}
Example:
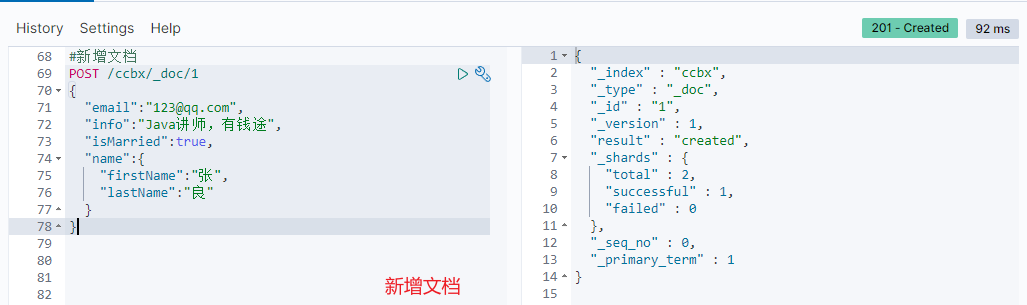
// New document
POST /ccbx/_doc/1
{
"email":"123@qq.com",
"info":"Java Lecturer, rich way",
"isMarried":true,
"name":{
"firstName":"Zhang",
"lastName":"good"
}
}
Response:
3.2 query documents
According to the rest style, the new is post, and the query should be get. However, the query generally requires conditions. Here we bring the document id.
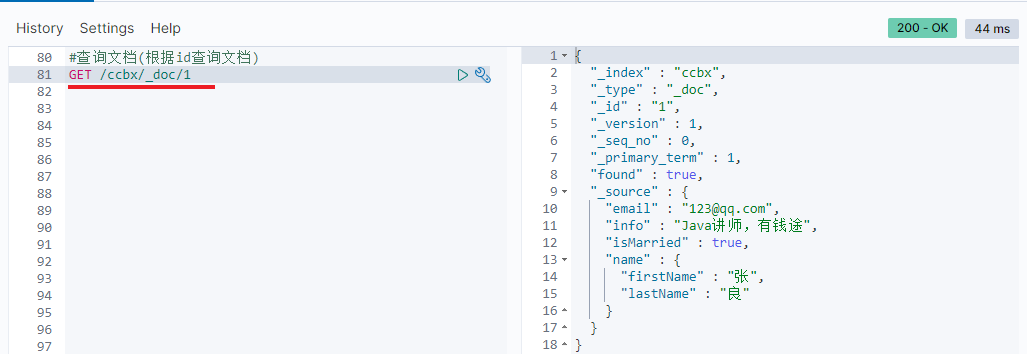
3.2.1 query documents by Id
Syntax:
GET /{Index library name}/_doc/{id}
View data via kibana:
GET /ccbx/_doc/1
View results:
3.2.2 query all documents
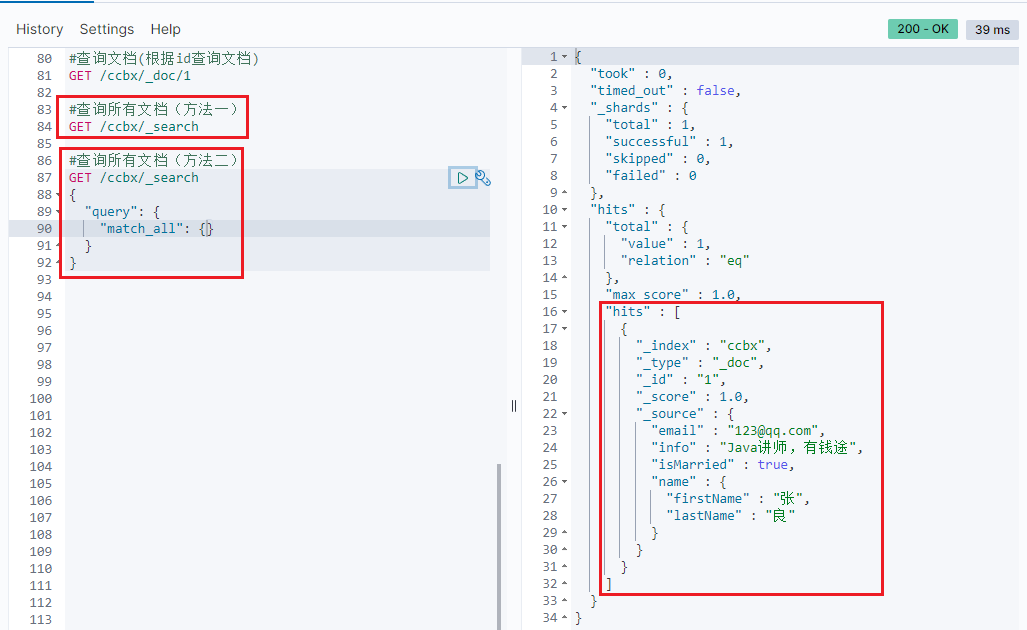
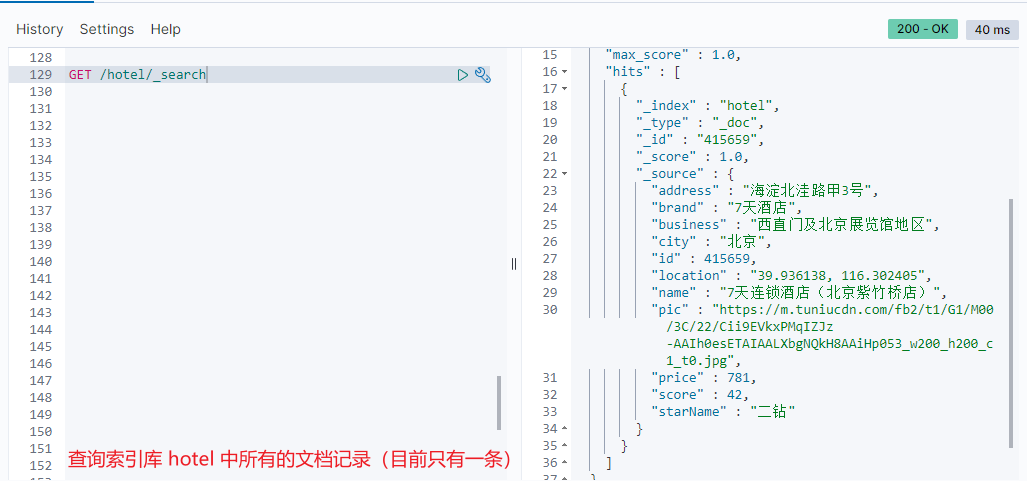
Syntax 1: GET / {index library name}/_ search
Syntax 2:
GET /{Index library name}/_search
{
"query": {
"match_all": {}
}
}
demonstration:
3.3 deleting documents
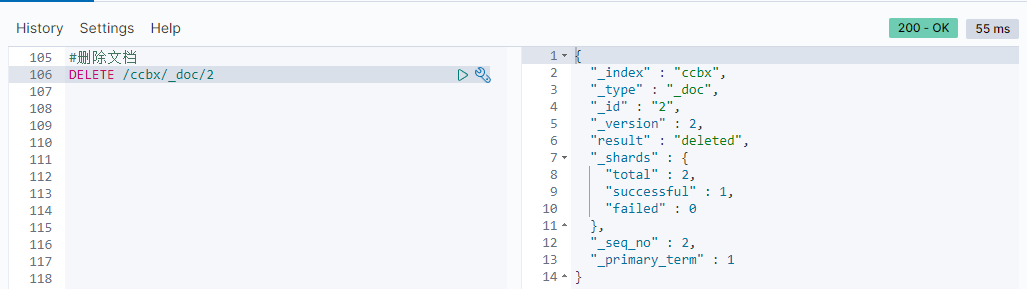
To DELETE a DELETE request, you need to DELETE it according to the id:
Syntax: DELETE / {index library name}/_ doc/id value
Example:
3.4 modifying documents
There are two ways to modify:
- Full modification: directly overwrite the original document
- Incremental modification: modify some fields in the document
3.4.1 full volume modification
Full modification is to overwrite the original document. Its essence is:
- Deletes the document according to the specified id
- Add a document with the same id
Note: if the id does not exist when it is deleted according to the id, the addition in the second step will also be executed, which will change from modification to addition.
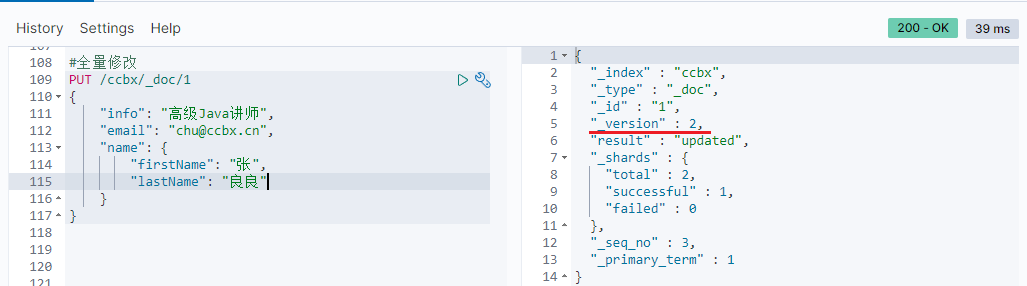
Syntax:
PUT /{Index library name}/_doc/file id
{
"Field 1": "Value 1",
"Field 2": "Value 2",
// ... slightly
}
Example:
PUT /ccbx/_doc/1
{
"info": "senior Java lecturer",
"email": "chu@ccbx.cn",
"name": {
"firstName": "Zhang",
"lastName": "Liangliang"
}
}
3.4.2 incremental modification
Incremental modification is to modify only some fields in the document with matching specified id.
Syntax:
POST /{Index library name}/_update/file id
{
"doc": {
"Field name": "New value",
}
}
Example:
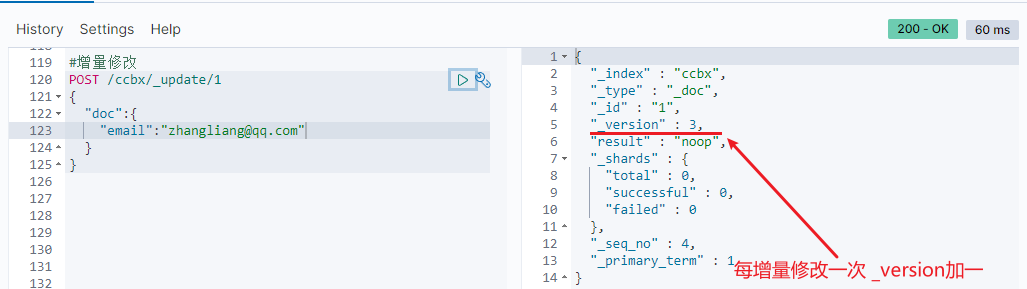
#Incremental modification
POST /ccbx/_update/1
{
"doc":{
"email":"zhangliang@qq.com"
}
}
4, RestAPI (case demonstration)
ES officially provides clients in different languages to operate ES. The essence of these clients is to assemble DSL statements and send them to ES through http request. Official document address: Rest Client
The Java Rest Client includes two types:
- Java Low Level Rest Client
- Java High Level Rest Client (version used in this study)
4.1 Demo project
Rest API small case download link
4.1.1 import data
1) First, create the database and select the character set utf8mb4.
2) Import the database data provided by the download materials: tb_hotel.sql file, whose data structure is as follows:
CREATE TABLE `tb_hotel` ( `id` bigint(20) NOT NULL COMMENT 'hotel id', `name` varchar(255) NOT NULL COMMENT 'Hotel name; Example: 7 Days Hotel', `address` varchar(255) NOT NULL COMMENT 'hotel's address; Example: hangtou Road', `price` int(10) NOT NULL COMMENT 'Hotel price; Example: 329', `score` int(2) NOT NULL COMMENT 'Hotel rating; Example: 45 is 4.5 branch', `brand` varchar(32) NOT NULL COMMENT 'Hotel brand; Example: home like', `city` varchar(32) NOT NULL COMMENT 'City; Example: Shanghai', `star_name` varchar(16) DEFAULT NULL COMMENT 'Hotel stars, from low to high, are: 1 star to 5 stars, 1 drill to 5 drill', `business` varchar(255) DEFAULT NULL COMMENT 'Business district; Example: Hongqiao', `latitude` varchar(32) NOT NULL COMMENT 'Latitude; Example: 31.2497', `longitude` varchar(32) NOT NULL COMMENT 'Longitude; Example: 120.3925', `pic` varchar(255) DEFAULT NULL COMMENT 'Hotel Pictures; example:/img/1.jpg', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
4.1.2 import project
3) Import the downloaded project: Hotel demo. The project structure is as follows:
Note: the location of maven configuration file should be replaced with its own local one!!!
4.1.3 mapping analysis
The key to creating an index library is mapping, and the information to be considered in mapping includes:
- Field name
- Field data type
- Participate in search
- Whether word segmentation is required
- If word segmentation, what is the word splitter?
Of which:
- Field name and field data type. You can refer to the name and type of data table structure
- Whether to participate in the search needs to be judged by analyzing the business. For example, the image address does not need to participate in the search
- Whether to segment words depends on the content. If the content is a whole, there is no need to segment words. On the contrary, it is necessary to segment words
- Word splitter, we can use IK uniformly_ max_ word
Index library structure of hotel data:
PUT /hotel
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword",
"copy_to": "all"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
Description of several special fields:
- location: geographic coordinates, including precision and latitude.
- all: a combined field whose purpose is to use copy for the values of multiple fields_ To merge and provide users with search.
- copy_to: field copy; Copies the value of the current field to the specified field.
Description of geographical coordinates:

4.1.4 initialize RestClient
in the API provided by elasticsearch, all interactions with elasticsearch are encapsulated in a named resthighlevelclient In Java classes, you must initialize this object and establish a connection with elasticsearch.
There are three steps:
1) RestHighLevelClient dependency introduced into es:
<!-- introduce elasticsearch rely on -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2) Because the default ES version of SpringBoot is 7.6.2, we need to overwrite the default ES version:
<properties>
<java.version>1.8</java.version>
<!-- Override default version number -->
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3) Initialize RestHighLevelClient. The initialization code is as follows:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.92.66:9200")
));
For the convenience of unit testing, we create a test class hotelindextest Java, and then write the initialization code in the @ BeforeEach method:
public class HotelIndexTest {
private RestHighLevelClient client;
//You can only use junit5 dependencies, which are executed before all crud test methods
@BeforeEach
void setUp() {
//Replace the IP address with the IP and port number of your own server
this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://192.168.92.66:9200")));
}
//The tearDown method is used to release resources and is executed after all crud test methods
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
4.2 create index library
The API for creating index library is as follows:
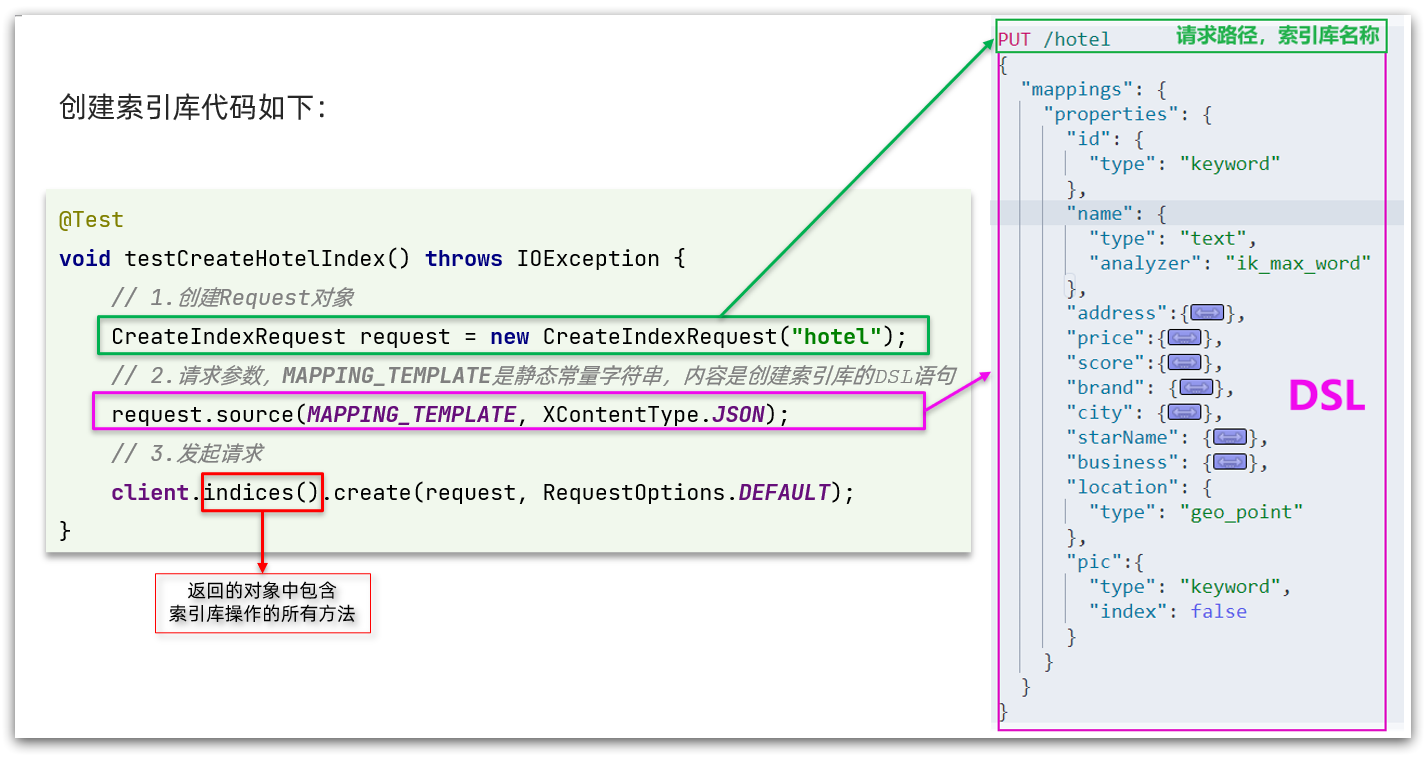
The code is divided into three steps:
- 1. Create a Request object. Because it is an operation to create an index library, Request is CreateIndexRequest.
- 2. Adding request parameters is actually the JSON parameter part of DSL. Because the JSON string is very long, the static string constant mapping is defined here_ Template, which makes the code look more elegant.
- 3. Send request, client The return value of the indices () method is the IndicesClient type, which encapsulates all methods related to the operation of the index library.
on Hotel demo's com softeem. hotel. Under the constants package, create a class to define the JSON string constant of mapping mapping:
package com.softeem.hotel.constants;
/**
* @Description Define JSON string constants for Mapping.
* @Author cb
* @Date 2022-02-15 22:11
**/
public class HotelConstants {
public static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"starName\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\": \"geo_point\"\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
In the HotelIndexTest test test class in the hotel demo, write a unit test to create an index:
@Test
void createHotelIndex() throws IOException {
// 1. Create a Request object (hotel is the name of the index library)
CreateIndexRequest request = new CreateIndexRequest("hotel");
// 2. Prepare the requested parameters: DSL statement (the following static import of the constant MAPPING_TEMPLATE)
//be careful:
// Normal import declarations import classes from packages, so you can use them without package references.
// Similarly, a static import declaration imports static members from a class and allows them to be used without a class reference.
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3. Send request
client.indices().create(request, RequestOptions.DEFAULT);
}
Static import constant: import static com softeem. hotel. constants. HotelConstants. MAPPING_ TEMPLATE;
4.3 delete index library
The DSL statement to delete the index library is very simple:
//Delete index library hotel DELETE /hotel
Compared to creating an index library:
- Request mode changed from PUT to DELTE
- Request path unchanged
- No request parameters
Therefore, the code difference should be reflected in the Request object. There are still three steps:
- 1) Create a Request object. This is the DeleteIndexRequest object
- 2) Prepare parameters. Here is no reference
- 3) Send request. Use the delete method instead
In the HotelIndexTest test test class in the hotel demo, write a unit test to delete the index:
@Test
void testDeleteHotelIndex() throws IOException {
// 1. Create Request object
DeleteIndexRequest request = new DeleteIndexRequest("hotel");
// 2. Send request
client.indices().delete(request, RequestOptions.DEFAULT);
}
4.4 judge whether the index library exists
Judging whether the index library exists is essentially a query. The corresponding DSL is:
// Query index library hotel GET /hotel
Therefore, it is similar to the deleted Java code flow. There are still three steps:
- 1) Create a Request object. This is the GetIndexRequest object
- 2) Prepare parameters. Here is no reference
- 3) Send request. Use the exists method instead
@Test
void testExistsHotelIndex() throws IOException {
// 1. Create Request object
GetIndexRequest request = new GetIndexRequest("hotel");
// 2. Send request
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3. Output
System.err.println(exists ? "Index library already exists!" : "Index library does not exist!");
}
4.5 summary
The process of JavaRestClient operating elasticsearch is basically similar. The core is client The indexes () method to get the operation object of the index library.
Basic steps of index library operation:
- Initialize RestHighLevelClient
- Create an XxxIndexRequest. XXX is create, Get and Delete
- Prepare DSL (required when creating, and no parameter at other times)
- Send request. Call resthighlevelclient indices(). xxx () method, xxx is create, exists and delete.
5, RestClient operation document
In order to separate from the index library operation, we participate in a test class again and do two things:
- Initialize RestHighLevelClient
- Our hotel data is in the database and needs to be queried by IHotelService, so we inject this interface
@SpringBootTest
public class HotelDocumentTest {
@Autowired
private IHotelService hotelService;
private RestHighLevelClient client;
//You can only use junit5 dependencies, which are executed before all crud test methods
@BeforeEach
void setUp() {
this.client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://http://192.168.92.66:9200")));
}
//The tearDown method is used to release resources and is executed after all crud test methods
@AfterEach
void tearDown() throws IOException {
this.client.close();
}
}
5.1 new documents
We need to query the hotel data in the database and write it into elasticsearch.
5.1.1 index library entity class
The result of database query is an object of Hotel type. The structure is as follows:
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}
There are differences with our index library structure:
- longitude and latitude need to be merged into location
Therefore, we need to define a new type, which is consistent with the index library structure:
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
//Build a HotelDoc object from the second by passing in a Hotel object
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
5.1.2 syntax description
The DSL statement of the new document is as follows:
POST /{Index library name}/_doc/1
{
"name": "Jack",
"age": 21
}
The corresponding java code is shown in the figure below:

You can see that similar to creating an index library, there are three steps:
- 1) Create Request object
- 2) Prepare request parameters, that is, JSON documents in DSL
- 3) Send request
The change is that the client is directly used here The API of XXX () no longer requires client Indices().
5.1.3 complete code
We import hotel data in the same basic process, but we need to consider several changes:
- The hotel data comes from the database. We need to query it first to get the hotel object
- The hotel object needs to be converted to a HotelDoc object
- HotelDoc needs to be serialized into json format
Therefore, the overall steps of the code are as follows:
- 1) Query Hotel data according to id
- 2) Encapsulate Hotel as HotelDoc
- 3) Serialize HotelDoc to JSON
- 4) Create an IndexRequest and specify the name and id of the index library
- 5) Prepare request parameters, that is, JSON documents
- 6) Send request
In the HotelDocumentTest test test class of hotel demo, write a unit test:
@Test
void testAddDocument() throws IOException {
// 1. Query node data according to id
Hotel hotel = hotelService.getById(415659L);
// 2. Convert to document type
HotelDoc hotelDoc = new HotelDoc(hotel);
// 3. Convert HotelDoc to json format
String jsonData = JSON.toJSONString(hotelDoc);
// 1. Prepare the Request object
IndexRequest request = new IndexRequest("hotel").id(hotelDoc.getId().toString());
// 2. Prepare Json documents
request.source(jsonData, XContentType.JSON);
// 3. Send request
client.index(request, RequestOptions.DEFAULT);
}
5.2 query documents
5.2.1 syntax description
The DSL statement of query is as follows:
GET /hotel/_doc/{id}
Very simple, so the code is roughly divided into two steps:
- Prepare Request object
- Send request
However, the purpose of query is to get the result and parse it into HotelDoc, so the difficulty is the result parsing. The complete code is as follows:

as you can see, the result is a JSON in which the document is placed in a_ source attribute, so parsing is to get_ source, which can be deserialized as a Java object.
Similar to before, there are three steps:
- 1) Prepare the Request object. This is a query, so it's GetRequest
- 2) Send the request and get the result. Because it is a query, call client Get() method
- 3) The result of parsing is to deserialize JSON
5.2.2 complete code
In the HotelDocumentTest test test class of hotel demo, write a unit test:
@Test
void testGetDocumentById() throws IOException {
// 1. Prepare the Request
GetRequest request = new GetRequest("hotel", "415659");
// 2. Send a request and get a response
GetResponse response = client.get(request, RequestOptions.DEFAULT);
// 3. Analyze the response results
String json = response.getSourceAsString();
System.out.println(json);
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
System.out.println(hotelDoc);
}

5.3. remove document
The deleted DSL is as follows:
DELETE /hotel/_doc/{id}
Compared with query, only the request mode changes from DELETE to GET. It is conceivable that Java code should still follow three steps:
- 1) Prepare the Request object because it is deleted. This time, it is the DeleteRequest object. To specify the index library name and id
- 2) Prepare parameters, no parameters
- 3) Send request. Because it is deleted, it is client Delete() method
In the HotelDocumentTest test test class of hotel demo, write a unit test:
@Test
void testDeleteDocument() throws IOException {
// 1. Prepare the Request
DeleteRequest request = new DeleteRequest("hotel", "415659");
// 2. Send request
client.delete(request, RequestOptions.DEFAULT);
}
5.4 modifying documents
5.4.1 syntax description
There are two ways to modify:
- Modify in full: the essence is to delete according to the id and then add.
- Incremental modification: modify the specified field value in the document.
In the API of RestClient, the total modification is completely consistent with the newly added API. The judgment basis is ID:
- If the ID already exists when adding, it can be modified
- If the ID does not exist when adding, add
We will not repeat here. We mainly focus on incremental modification.
Example of incremental code modification is shown in the figure below:
Similar to before, there are three steps:
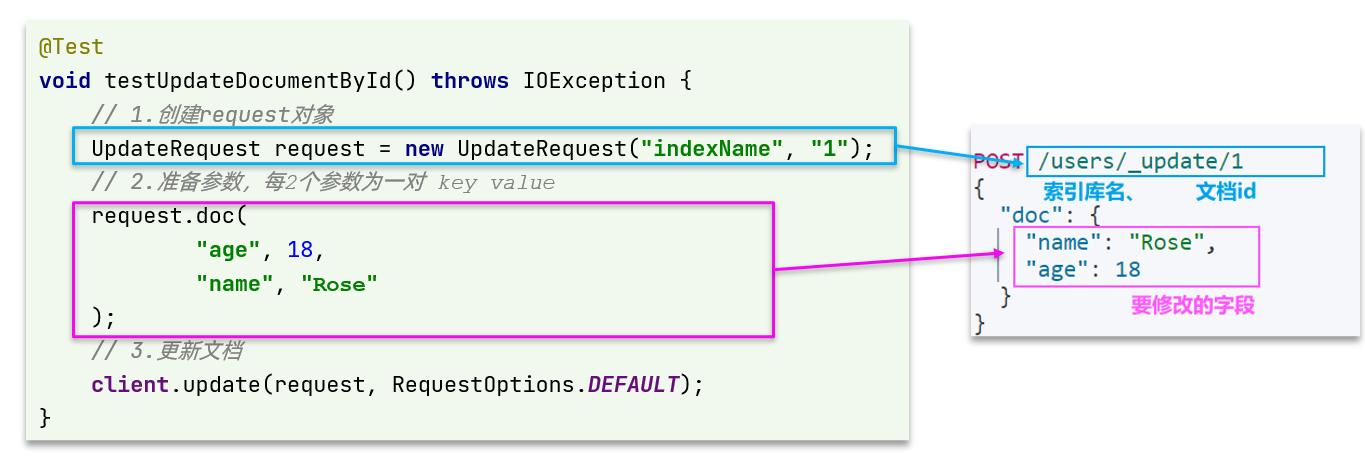
- 1) Prepare the Request object. This is a modification, so it is an UpdateRequest
- 2) Prepare parameters. That is, the JSON document, which contains the fields to be modified
- 3) Update the document. Here, call client Update() method
5.4.2. Complete code
In the HotelDocumentTest test test class of hotel demo, write a unit test:
@Test
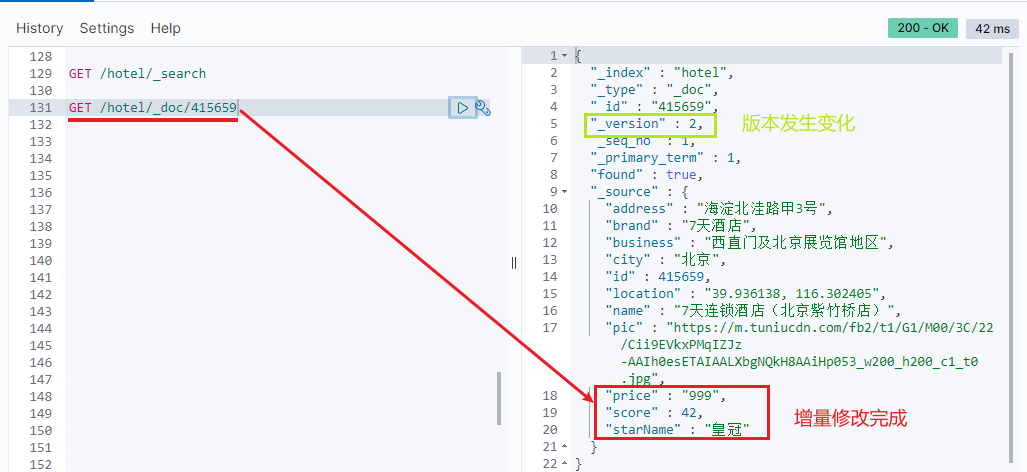
void testUpdateDocument() throws IOException {
// 1. Prepare the Request
UpdateRequest request = new UpdateRequest("hotel", "415659");
// 2. Prepare request parameters
request.doc(
"price", "999",
"starName", "an crown"
);
// 3. Send request
client.update(request, RequestOptions.DEFAULT);
}
5.5 batch import documents
Case requirements: use BulkRequest to import database data into the index library in batches.
The steps are as follows:
- Using mybatis plus to query hotel data
- Convert the queried Hotel data (Hotel) into document type data (HotelDoc)
- Using BulkRequest batch processing in JavaRestClient to realize batch addition of documents
5.5.1. Syntax description
The essence of bulk request processing is to send multiple ordinary CRUD requests together.
An add method is provided to add other requests:
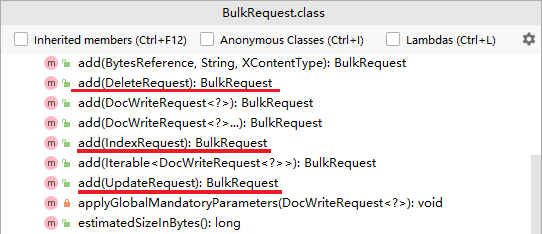
You can see that the requests that can be added include:
- IndexRequest, i.e. new
- UpdateRequest, that is, modify
- DeleteRequest, that is, delete
Therefore, adding multiple indexrequests to Bulk is a new function in batch. In fact, there are three steps:
- 1) Create a Request object. This is BulkRequest
- 2) Prepare parameters. The parameters of batch processing are other Request objects. Here are multiple indexrequests
- 3) Initiate a request. This is batch processing, and the called method is client Bulk() method
Example:
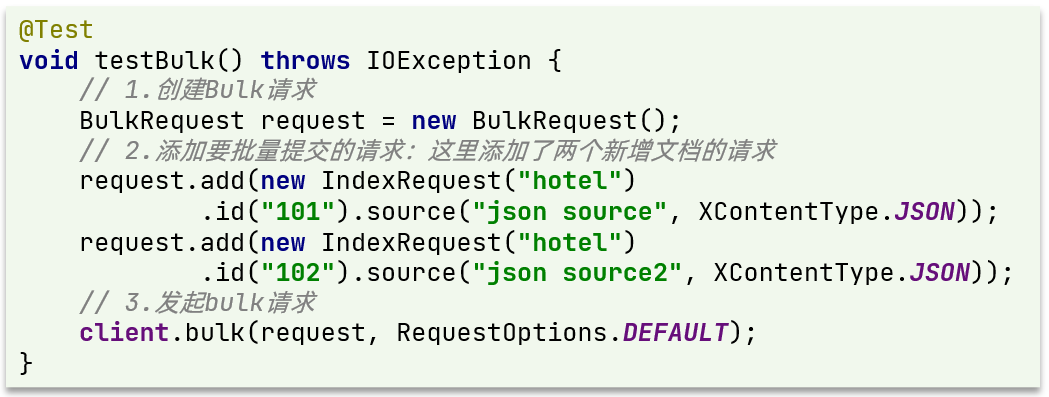
When importing hotel data, we can transform the above code into a for loop.
5.5.2 complete code
In the HotelDocumentTest test test class of hotel demo, write a unit test:
@Test
void testBulkRequest() throws IOException{
//Batch query of hotel data
List<Hotel> hotelList = hotelService.list();
// 1. Create a Bulk request
BulkRequest request = new BulkRequest();
// 2. Add requests to be submitted in batch: two requests for adding new documents are added here;
for (Hotel hotel : hotelList) {
//2.1 converting to document type HotelDoc
HotelDoc hotelDoc = new HotelDoc(hotel);
//2.2 create a Request object for a new document
request.add(new IndexRequest("hotel").id(hotelDoc.getId().toString()).source(JSON.toJSON(hotelDoc),XContentType.JSON));
}
// 3. Initiate bulk request
client.bulk(request,RequestOptions.DEFAULT);
}
es server view:
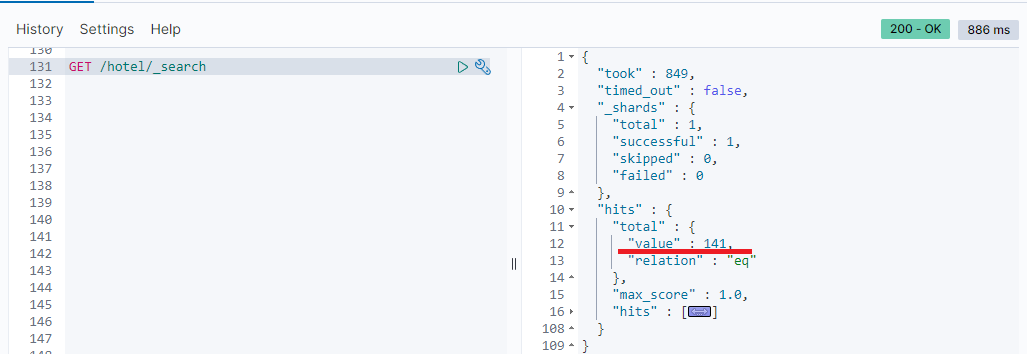
5.6. Summary
Basic steps of document operation:
- Initialize RestHighLevelClient
- Create an XxxRequest. XXX is Index, Get, Update, Delete and Bulk
- Prepare parameters (required for Index, Update and Bulk)
- Send request. Call resthighlevelclient xxx () method, xxx is index, get, update, delete, bulk
- Parsing results (required for Get)