Originally, I wanted to make a voice to text, but I found that many blogs didn't say what I wanted. The reasons are as follows: 1. Because the voice supported by Baidu interface is pcm format, and my own is mp3 format file.
2. Baidu only supports the file format within 60s, and what it wants is a long file, and hopes to cut it into 60s to meet the requirements of Baidu speech recognition.
3. The file can be generated srt file format, which is exactly what you want. So it took several days to find a perfect blog and share it with you. The blog address is as follows:
This blog is aimed at converting mp3 files into The text of the srt file is shown to you first
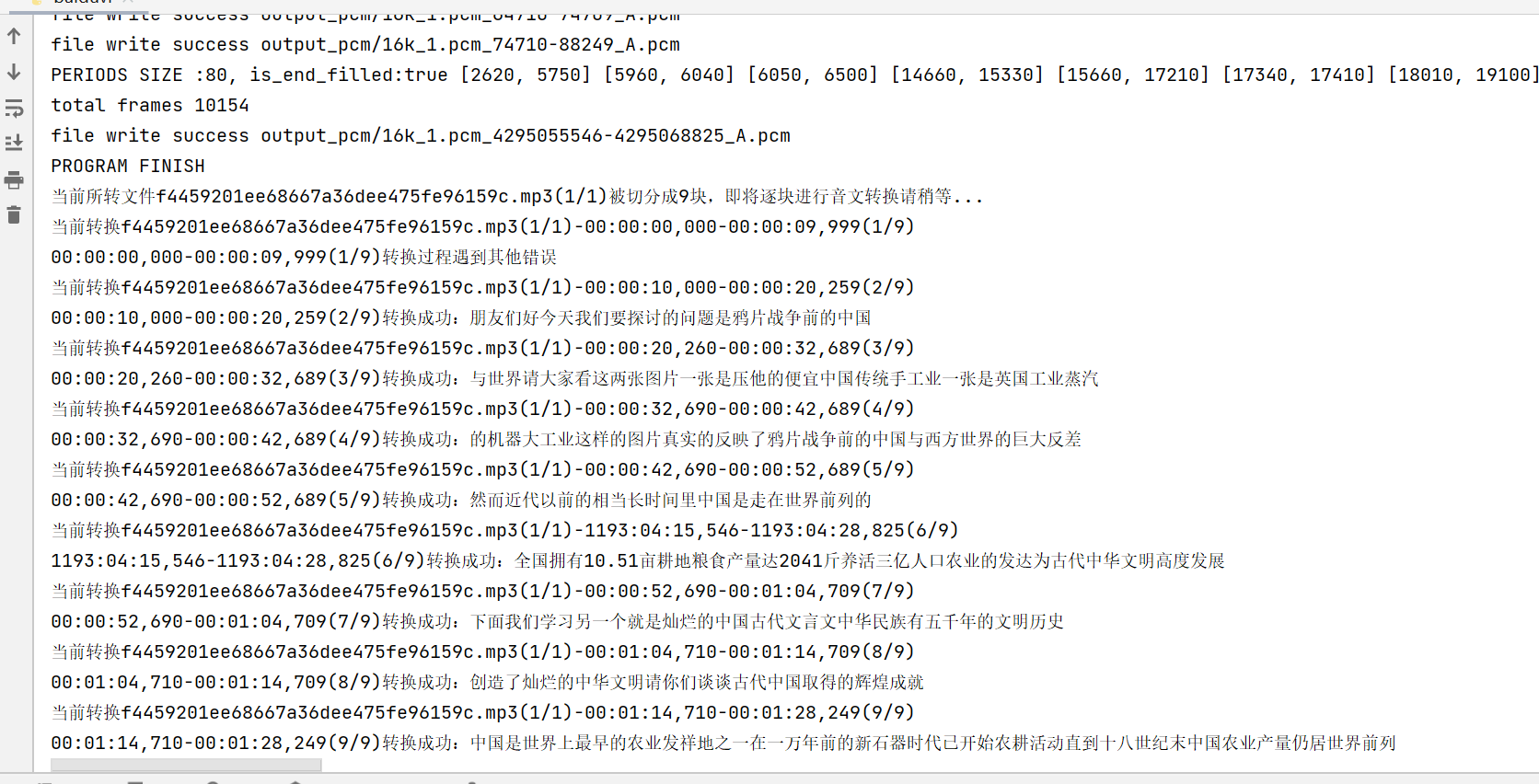

If you want to convert through video files, you can convert the video files into mp3 files. The address can see my last blog Convert video files into voice files using Python_ A blog of learning slag who doesn't want to learn - CSDN blog
For Baidu's APPID and KEY_ID, etc. you can refer to the console on the address page below for registration
https://ai.baidu.com/ai-doc/SPEECH/Bk4o0bmt3
After registration, you can click the voice technology on the following page. Then create the task and fill in the relevant information. The second chapter will get the final page. Then you can use the code for speech recognition,
Note: this Baidu interface is not free. It needs money in the later stage..
The main codes are as follows:
import base64
import json
import os
import time
import shutil
import requests
class BaiduVoiceToTxt():
# Initialization function
def __init__(self):
# Define the location of the pcm file to be cut. Speech VAD demo fixed, no choice
self.pcm_path = ".\\speech-vad-demo\\pcm\\16k_1.pcm"
# Define the directory to which the pcm file is output after being cut. Speech VAD demo fixed, no choice
self.output_pcm_path = ".\\speech-vad-demo\\output_pcm\\"
# Baidu AI interface only accepts pcm format, so it needs to convert the format
# This function is used to convert the mp3 file to be recognized into PCM format and output it as \speech-vad-demo\pcmk_1.pcm
def change_file_format(self,filepath):
file_name = filepath
# If \speech-vad-demo\pcm\16k_ 1. If the PCM file already exists, delete it first
if os.path.isfile(f"{self.pcm_path}"):
os.remove(f"{self.pcm_path}")
# Call the system command to convert the file into PCM format and output it as \speech-vad-demo\pcmk_1.pcm
change_file_format_command = f".\\ffmpeg\\bin\\ffmpeg.exe -y -i {file_name} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {self.pcm_path}"
os.system(change_file_format_command)
# Baidu AI interface can only accept audio and video for 60 seconds at most, so it needs to be cut
# This function is used to convert \speech-vad-demo\pcmk_1.pcm cutting
def devide_video(self):
# If cutting the output directory \speech-vad-demo\output_pcm \ already exists. It is likely that there are files in it. Empty it first
# The files in the empty directory are deleted first and then created
if os.path.isdir(f"{self.output_pcm_path}"):
shutil.rmtree(f"{self.output_pcm_path}")
time.sleep(1)
os.mkdir(f"{self.output_pcm_path}")
# vad-demo.exe uses relative paths \pcm and \output_pcm, so first switch the current working directory to \Speech VAD demo Exe cannot find the file
os.chdir(".\\speech-vad-demo\\")
# Direct execution \vad-demo.exe, which defaults to \pcm\16k_ 1. The PCM file is cut and output to \output_pcm directory
devide_video_command = ".\\vad-demo.exe"
os.system(devide_video_command)
# Switch back to working directory
os.chdir("..\\")
# This function is used to convert \speech-vad-demo\output_ The time of the file name of the file under PCM \ is formatted as 0:00:00000
def format_time(self, msecs):
# Milliseconds per hour
hour_msecs = 60 * 60 * 1000
# Milliseconds per minute
minute_msecs = 60 * 1000
# Milliseconds per second
second_msecs = 1000
# The time of the file name is milliseconds and needs to be converted to seconds first+ 500 is for rounding and / / is for division
# msecs = (msecs + 500) // 1000
# hour
hour = msecs // hour_msecs
if hour < 10:
hour = f"0{hour}"
# Milliseconds left after deducting hours
hour_left_msecs = msecs % hour_msecs
# minute
minute = hour_left_msecs // minute_msecs
# If it is less than 10 minutes, fill 0 in front of it to form a two digit format
if minute < 10:
minute = f"0{minute}"
# Milliseconds left after minutes
minute_left_msecs = hour_left_msecs % minute_msecs
# second
second = minute_left_msecs // second_msecs
# If the number of seconds is less than 10 seconds, fill 0 in front of it to make up for the two digit format
if second < 10:
second = f"0{second}"
# Milliseconds left after seconds
second_left_msecs = minute_left_msecs % second_msecs
# If it is less than 10 milliseconds or 100 milliseconds, fill 0 in front of it to make up for the three digit format
if second_left_msecs < 10:
second_left_msecs = f"00{second_left_msecs}"
elif second_left_msecs < 100:
second_left_msecs = f"0{second_left_msecs}"
# Formatted as 00:00:00000 and returned
time_format = f"{hour}:{minute}:{second},{second_left_msecs}"
return time_format
# This function is used to request access to the ai interface_ token
def get_access_token(self):
# This variable is assigned the value of its own API Key
client_id = 'f3wT23Otc8jXlDZ4HGtS4jfT'
# This variable is assigned the value of its own Secret Key
client_secret = 'YPPjW3E0VGPUOfZwhjNGVn7LTu3hwssj'
auth_url = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret
response_at = requests.get(auth_url)
# Read the response result in json format
json_result = json.loads(response_at.text)
# Get access_token
access_token = json_result['access_token']
return access_token
# This function is used to convert \speech-vad-demo\output_ A single file under PCM \ is converted from voice to file
def transfer_voice_to_srt(self,access_token,filepath):
# Baidu speech recognition interface
url_voice_ident = "http://vop.baidu.com/server_api"
# Interface specification, post data in json format
headers = {
'Content-Type': 'application/json'
}
# Open the pcm file and read the contents of the file
pcm_obj = open(filepath,'rb')
pcm_content_base64 = base64.b64encode(pcm_obj.read())
pcm_obj.close()
# Get pcm file size
pcm_content_len = os.path.getsize(filepath)
# For the interface specification, see the official document for the body function. It is worth noting the writing method of cuid and speech parameters
post_data = {
"format": "pcm",
"rate": 16000,
"dev_pid": 1737,
"channel": 1,
"token": access_token,
"cuid": "1111111111",
"len": pcm_content_len,
"speech": pcm_content_base64.decode(),
}
proxies = {
'http':"127.0.0.1:8080"
}
# Call the interface for voice text conversion
response = requests.post(url_voice_ident, headers=headers, data=json.dumps(post_data))
# response = requests.post(url_voice_ident,headers=headers,data=json.dumps(post_data),proxies=proxies)
return response.text
if __name__ == "__main__":
# instantiation
baidu_voice_to_srt_obj = BaiduVoiceToTxt()
# The folder where the audio and video files to be converted are stored
video_dir = ".\\video\\"
all_video_file =[]
all_file = os.listdir(video_dir)
subtitle_format = "{\\fscx75\\fscy75}"
# Only accept mp3 format file. Because other formats have not studied how to convert to pcm, it meets the interface requirements
for filename in all_file:
if ".mp3" in filename:
all_video_file.append(filename)
all_video_file.sort()
i = 0
video_file_num = len(all_video_file)
print(f"Current common{video_file_num}Audio files need to be converted and will be processed soon. Please wait...")
# The for loop of this layer is processed one mp3 file by one
for video_file_name in all_video_file:
i += 1
print(f"Current conversion{video_file_name}({i}/{video_file_num})")
# Output the content translated into audio and video to the same directory with the same name txt file
video_file_srt_path = f".\\video\\{video_file_name[:-4]}.srt"
# Open as overlay txt file
video_file_srt_obj = open(video_file_srt_path,'w+')
filepath = os.path.join(video_dir, video_file_name)
# Call change_file_format Convert mp3 to pcm format
baidu_voice_to_srt_obj.change_file_format(filepath)
# Cut the converted pcm file into multiple pcm files less than 60 seconds
baidu_voice_to_srt_obj.devide_video()
# Get token
access_token = baidu_voice_to_srt_obj.get_access_token()
# obtain. \speech-vad-demo\output_ List of files in PCM \ directory
file_dir = baidu_voice_to_srt_obj.output_pcm_path
all_pcm_file = os.listdir(file_dir)
all_pcm_file.sort()
j = 0
pcm_file_num = len(all_pcm_file)
print(f"Currently transferred files{video_file_name}({i}/{video_file_num})Be cut into{pcm_file_num}Block, the audio text conversion will be carried out block by block. Please wait a moment...")
# This layer is for \speech-vad-demo\output_ All files in PCM \ directory are converted one by one
for filename in all_pcm_file:
j += 1
filepath = os.path.join(file_dir, filename)
if (os.path.isfile(filepath)):
# Gets the time on the file name
time_str = filename[10:-6]
time_str_dict = time_str.split("-")
time_start_str = baidu_voice_to_srt_obj.format_time(int(time_str_dict[0]))
time_end_str = baidu_voice_to_srt_obj.format_time(int(time_str_dict[1]))
print(f"Current conversion{video_file_name}({i}/{video_file_num})-{time_start_str}-{time_end_str}({j}/{pcm_file_num})")
response_text = baidu_voice_to_srt_obj.transfer_voice_to_srt(access_token, filepath)
# Read the returned result in json
json_result = json.loads(response_text)
# Write the audio text conversion result into the srt file
video_file_srt_obj.writelines(f"{j}\r\n")
video_file_srt_obj.writelines(f"{time_start_str} --> {time_end_str}\r\n")
if json_result['err_no'] == 0:
print(f"{time_start_str}-{time_end_str}({j}/{pcm_file_num})Conversion succeeded:{json_result['result'][0]}")
video_file_srt_obj.writelines(f"{subtitle_format}{json_result['result'][0]}\r\n")
elif json_result['err_no'] == 3301:
print(f"{time_start_str}-{time_end_str}({j}/{pcm_file_num})The audio quality is too poor to be recognized")
video_file_srt_obj.writelines(f"{subtitle_format}The audio quality is too poor to be recognized\r\n")
else:
print(f"{time_start_str}-{time_end_str}({j}/{pcm_file_num})Other errors were encountered during the conversion")
video_file_srt_obj.writelines(f"{subtitle_format}Other errors were encountered during the conversion\r\n")
video_file_srt_obj.writelines(f"\r\n")
video_file_srt_obj.close()Finally, I hope you can make progress together and succeed in your studies!