1, Foreword
Write in front: it took a day to sort out the data collected by small codewords. It's helpful for you. One key three times in a row. Ha, thank you!!
HashMap is often encountered in our daily development. The source code and underlying principle of HashMap must be asked in the interview. Therefore, we should master it, which is also a necessary knowledge point as two years of development experience! HashMap is implemented based on the Map interface. Elements are stored in the form of < key, value >, and null keys and null values are allowed. Because keys are not allowed to be repeated, only one key can be null. In addition, HashMap is disordered and thread unsafe.
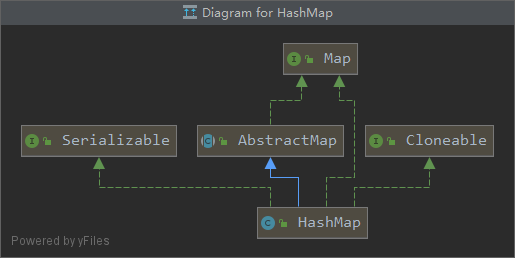
HashMap inherits class diagram shortcut key Ctrl+alt+U
2, Introduction to storage structure
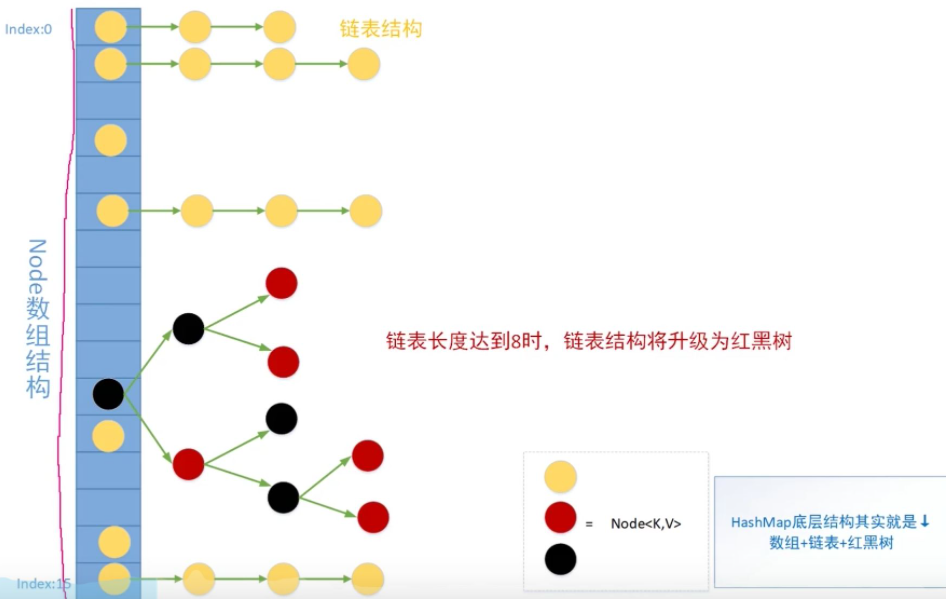
Jdk7. Array + linked list before 0
Jdk8.0 start array + linked list + binary tree
The number of elements in the linked list is more than 8, and the linked list is transformed into a binary tree
The number of elements in the linked list is less than 6, and the binary tree is transformed into a linked list
Red black tree is a self balanced binary search tree, so the time complexity of query can be reduced to O(logn)
When the length of the linked list is very long, the query efficiency will decline sharply, and the time complexity of the query is O(n)
Jdk1.7. Add the new elements of the linked list to the head node of the linked list, first add them to the head node of the linked list, and then move them to the subscript position of the array. Short for header insertion (dead loop may occur during concurrency)
Jdk1.8. Add new elements of the linked list to the tail node of the linked list. Tail insertion method for short (solves the dead cycle of head insertion method)
Bottom structure example diagram
3, Interpretation of common variables in source code analysis
/** * Default initial capacity - must be a power of 2. */ static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 /** * Maximum capacity, if a higher value is implicitly specified by any constructor with parameters. Must be a power of 2 < = 1 < < 30. * It is simply understood as: the maximum capacity is the 30th power of 2, and if it is carried, it will also be converted to the power of 2 */ static final int MAXIMUM_CAPACITY = 1 << 30; /** * The load factor to use when not specified in the constructor. The best value to reduce hash collision is measured by official test */ static final float DEFAULT_LOAD_FACTOR = 0.75f; /** * Use the counting threshold of red black tree. If it exceeds 8, it will be transformed into red black tree */ static final int TREEIFY_THRESHOLD = 8; /** * Use the counting threshold of red black tree. If it is lower than 6, it will be converted into linked list */ static final int UNTREEIFY_THRESHOLD = 6; /** * In addition to the threshold limit, there is another limit for the conversion of linked list into red black tree. The array capacity needs to reach at least 64 before it can be converted into red black tree. * This is to avoid the conflict between array expansion and treelization threshold. */ static final int MIN_TREEIFY_CAPACITY = 64; /** * Initialize on first use and resize as needed. When allocating, the length is always a power of 2. * (We also allow zero length in some operations to allow boot mechanisms that are not currently needed) */ transient Node<K,V>[] table; /** * Save the cached entrySet(), that is, the stored key value pairs */ transient Set<Map.Entry<K,V>> entrySet; /** * The number of key value mappings contained in this mapping is the size of the array */ transient int size; /** * Record the structural changes of the collection and the number of operations (for example, modCount + + for removal). * This field is used to make the iterator on the collection views of HashMap fail quickly. Failure is our common CME * (ConcurrentModificationException)abnormal */ transient int modCount; /** * Size of array expansion * Calculation method capacity * load factor capacity * load factor * @serial */ int threshold; /** * Load factor of hash table. * @serial */ final float loadFactor;
4, Interpretation of the construction method of source code analysis
/**
* Construct a construction method with specified initial capacity and load factor
* This construction method is not recommended. The loading factor is the most efficient after official testing, so it should be kept default for efficiency
*/
public HashMap(int initialCapacity, float loadFactor) {
// If the parameter is negative, an IllegalArgumentException exception will be thrown
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// If the value passed exceeds the maximum value, the default maximum value will be used
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Load factor of hash table.
this.loadFactor = loadFactor;
// If the initialization parameter is not the power of 2 by default, it will be directly converted to the power of 2
// The passed parameter is 11, which will be automatically converted to the value of the nearest power of 2 larger than the parameter, that is, 16.
// We will explain in detail how this method is transformed later
this.threshold = tableSizeFor(initialCapacity);
}
/**
* Construct a method that only specifies the initial capacity
*/
public HashMap(int initialCapacity) {
// We will find that we still call the construction method of the above two parameters to automatically set the loading factor for us
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
/**
* Construct a construction method with default initial capacity (16) and default load factor (0.75)
*/
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
/**
* Specify the map collection and convert it to the construction method of HashMap
*/
public HashMap(Map<? extends K, ? extends V> m) {
// Use default load factor
this.loadFactor = DEFAULT_LOAD_FACTOR;
//Call PutMapEntries() to complete the initialization and assignment process of HashMap
putMapEntries(m, false);
}
/**
* Add all the elements in the incoming sub Map to the HashMap one by one
*/
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
// Get the size of the parameter Map and assign it to s
int s = m.size();
// Determine whether the size is greater than 0
if (s > 0) {
// Prove that there are elements to insert into the HashMap
// Judge whether the table has been initialized. If table=null, it is generally the putMapEntries called by the constructor, or no elements have been left after construction
if (table == null) { // pre-size
// If not initialized, calculate the minimum required capacity of HashMap (that is, the capacity is no greater than the expansion threshold). Here, the size s of the Map is regarded as the capacity expansion threshold of the HashMap, and then the capacity of the corresponding HashMap can be obtained by dividing the size of the incoming Map by the load factor (current m size / load factor = HashMap capacity)
// ((float)s / loadFactor) but this will calculate the decimal, but as the capacity, it must be rounded up, so 1 should be added here. At this time, ft can be regarded as the capacity of HashMap temporarily
float ft = ((float)s / loadFactor) + 1.0F;
// Judge whether ft exceeds the maximum capacity. If it is less than, use ft; if it is greater than, take the maximum capacity
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
// Temporarily expand the size of the array to the power of 2, and recalculate the size of fort to the threshold of fort
if (t > threshold)
threshold = tableSizeFor(t);
}
// If the current map has been initialized and the number of elements in the map is greater than the expansion threshold, it must be expanded
// This is the case of expanding capacity in advance and then put ting elements
else if (s > threshold)
// Expand later
resize();
// Traverse the map and add the key and value in the map to the HashMap
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
// Call the specific implementation method putVal of the put method of HashMap to store the data. The specific details of this method will be explained later
// putVal may also trigger resize
putVal(hash(key), key, value, false, evict);
}
}
}
5, Interpretation of common methods of source code analysis
1. Interpretation of tableSizeFor method
/**
* Returns the power of the given target capacity.
*/
static final int tableSizeFor(int cap) {
// cap = 10
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
// Less than 0 is 1. If it is greater than 0, judge whether it exceeds the maximum capacity, that is, n=15+1 = 16. If it exceeds the maximum capacity
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
Take cap 10 as an example: (shift right rule: shift unsigned bit right)
10 binary: 0000 0000 0000 1010
Execute int n = cap - 1;
Binary result: 0000 0000 0000 1001
Execute n | = n > > > 1; (shift to the right first, and the result is or calculated with the original number [= = if there is 1, then 1 = = =)
0000 0000 0000 0000 0000 0000 0000 1001
0000 0000 0100 n > > 1 Result
----------
0000 1101 n | = n > > 1 Result
Binary result: 0000 0000 0000 1101
Execute n | = n > > > 2;
0000 0000 0000 0000 0000 0000 0000 1101
0000 0000 0011 n > > 2 Result
----------
0000 1111 n | = n > > 2 Result
Binary result: 0000 0000 0000 0000 1111
Execute n | = n > > > 4;
0000 0000 0000 0000 0000 0000 0000 1111
0000 0000 0000 0000 0000 0000 n > > 4 Results
----------
0000 1111 n | = n > > 4 Result
Binary result: 0000 0000 0000 0000 1111
Execute n | = n > > > 8;
0000 0000 0000 0000 0000 0000 0000 1111
0000 0000 0000 0000 0000 0000 n > > 8 results
----------
0000 1111 n | = n > > 8 result
Binary result: 0000 0000 0000 0000 1111
Execute n | = n > > > 16;
0000 0000 0000 0000 0000 0000 0000 1111
0000 0000 0000 0000 0000 n > > 16 result
----------
0000 1111 n | = n > > 16 result
Binary result: 0000 0000 0000 0000 1111
We will find that when the number is small, it will not change when it reaches 4. The value we get is 15, that is, enter 10. After this method, we get 15. When you encounter a large number, it will be obvious. You can find a large number to try, that is, move it to the right first for or operation. Finally, conduct three door operation and + 1 operation. The final result is 16 = 2 ^ 4
2. Interpretation of hash method
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
First judge whether the key is empty. If it is empty, 0 will be returned. As mentioned above, HashMap only supports one key that is null. If it is not empty, first calculate the hashCode value of the key, assign it to h, then shift h to the right by 16 bits, and XOR with the original H (the same is 1, the difference is 0).
Google Translate notes:
Calculate key Hashcode() and propagate (XOR) higher order hash reduction. Because the table uses a quadratic power mask, hash sets that change only above the current mask will always conflict. (a known example is the Float key set that holds consecutive integers in a small table.) Therefore, we apply a transformation to propagate the influence of high bits downward. There is a tradeoff between the speed, practicality and quality of in place expansion. Because many common hash sets have been reasonably distributed (so don't benefit from propagation), and because we use trees to deal with a large number of conflicts in bin, we just XOR some shifted bits in the simplest way to reduce system loss and merge the influence of the highest bit. Otherwise, due to table boundaries, These highest bits will never be used for index calculations.
Conclusion: the simplest way is used to reduce the system loss and hash collision.
3. Interpretation of put method
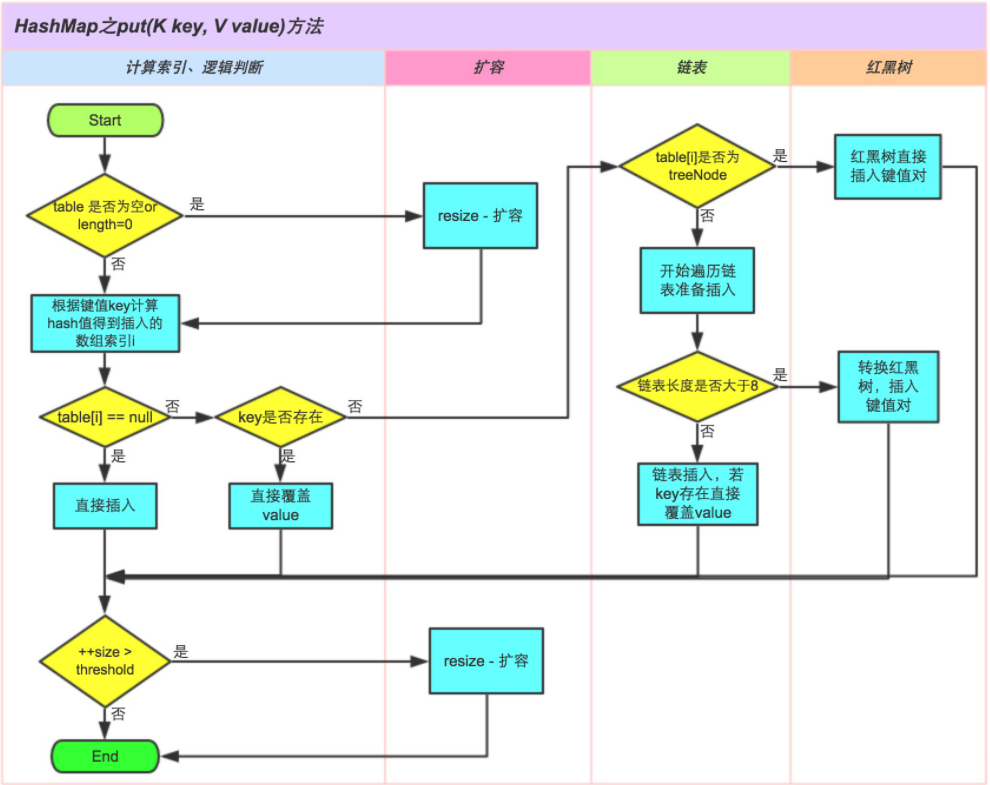
/**
* Associates the specified value with the specified key in this mapping. That is, where the current key should be stored in the array
* If the mapping previously contained a key, replace the old value.
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* This is the real way to save
* @param hash key after hash operation
* @param key key you want to add
* @param value value you want to add
* @param onlyIfAbsent If it is true, do not change the existing value. This time it is FALSE and you can replace the change
* @param evict If false, the table is in create mode. We are true
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// Judge whether the table is empty
if ((tab = table) == null || (n = tab.length) == 0)
// If it is empty, it will call resize to expand the capacity first. Resize will be explained later
n = (tab = resize()).length;
// The value obtained through the hash and the array size - 1 are combined, and this operation can realize the modular operation, and the bit operation has another advantage, that is, the speed is relatively fast.
// Get the node of the array corresponding to the key, then assign the array node to p, and then judge whether there is an element at this position
if ((p = tab[i = (n - 1) & hash]) == null)
// key and value are wrapped as newNode nodes and directly added to this location.
tab[i] = newNode(hash, key, value, null);
// If there are already elements in the index position of the current array, there are three cases.
else {
Node<K,V> e; K k;
// The hash value of the current location element is equal to the passed hash, and their key values are also equal
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// Assign p to e, and then replace the old value with a new value
e = p;
// Come here to explain that the key of this node is different from the original key. It depends on whether the node is a red black tree or a linked list
else if (p instanceof TreeNode)
// If it is a red black tree, save the key value into the red black tree through the red black tree. This method will be explained later
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// Come here to explain that the structure is a linked list. Insert the key value at the end of the linked list using the tail interpolation method.
// jdk1.7 linked list is a header insertion method, which will cause dead loop during concurrent capacity expansion
// jdk1. The head insertion method is replaced by the tail insertion method. Although the efficiency is slightly reduced, there will be no dead cycle
for (int binCount = 0; ; ++binCount) {
// Traverse the linked list and know that the next node is null.
if ((e = p.next) == null) {
// Explain to the tail of the linked list, and then point the next of the tail to the newly generated object
p.next = newNode(hash, key, value, null);
// If the length of the linked list is greater than or equal to 8
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
// Then the linked list is transformed into a red black tree and supplemented later
treeifyBin(tab, hash);
break;
}
// If the same key is found in the linked list, exit the loop directly
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// It indicates that there is a collision. e represents the old value and needs to be replaced with a new value
if (e != null) { // existing mapping for key
V oldValue = e.value;
// Judge whether the old value is allowed to be overwritten and whether the old value is empty
if (!onlyIfAbsent || oldValue == null)
// Replace old value
e.value = value;
// hashmap has no implementation, so we won't consider it first
afterNodeAccess(e);
// Return new value
return oldValue;
}
}
// The fail fast mechanism changes the structure by + 1 every time
++modCount;
// Judge the size of the stored data in the HashMap. If it is greater than the array length * 0.75, expand the capacity
if (++size > threshold)
resize();
// It is also an empty implementation
afterNodeInsertion(evict);
return null;
}
4. Interpretation of resize method
Can't check the original link: HD map link
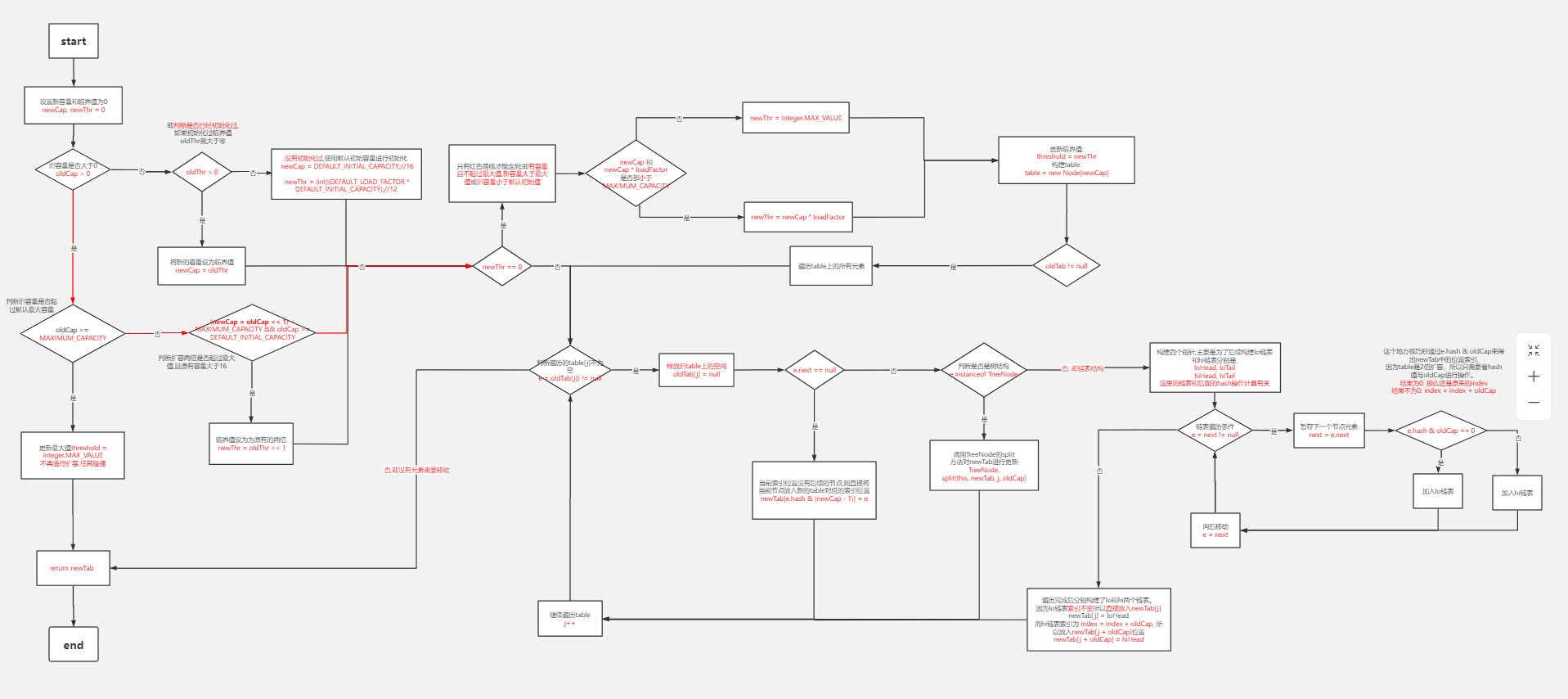
/**
* Initialize by table, or allocate space by table, if it is empty,
* Otherwise, after doubling, the elements in each container either stay at the original index or have a displacement to the power of 2 in the new table
*/
final Node<K,V>[] resize() {
// Original data
Node<K,V>[] oldTab = table;
// Get the original array size
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// The capacity expansion threshold of the old array. Note that the threshold value of the current object is taken here. The second case below will be used.
int oldThr = threshold;
// Initialize the capacity and threshold of the new array
int newCap, newThr = 0;
// 1. When the capacity of the old array is greater than 0, it means that resize must have been called to expand the capacity once before, which will lead to the old capacity not being 0.
if (oldCap > 0) {
// Maximum capacity
if (oldCap >= MAXIMUM_CAPACITY) {
// Set the expansion size to the upper limit
threshold = Integer.MAX_VALUE;
// Directly return to the default original, can not be expanded
return oldTab;
}
// If the old capacity is between 16 and the upper limit
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// The capacity and threshold of the new array are doubled
newThr = oldThr << 1; // double threshold
}
// 2. Here, oldcap < = 0, oldthr (threshold) > 0. This is when the map is initialized,
// The first call to resize
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
// 3. Here, it shows that both oldCap and oldThr are less than or equal to 0. It also shows that our map is created by default parameterless construction
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;// 16
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);// 12
}
// Only after 2 Will enter
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
// If the calculated ft conforms to the size, assign a value of newThr
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
// Finally, get the size to be expanded
threshold = newThr;
// Used to suppress the compiler from generating warning messages
@SuppressWarnings({"rawtypes","unchecked"})
// In the constructor, the array is not created. The array will be created only when the put method is called for the first time, resulting in resize.
// This is to delay loading and improve efficiency.
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
// Judge whether the original array has a value. If not, return the array just created
if (oldTab != null) {
// Convenience old array
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
// Judge whether the current element is empty
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// If the next element of the first element is null, there is only one in the linked list
if (e.next == null)
// Then directly use its hash value and the capacity of the new array to take the module (so that the operation efficiency is high) to get the new subscript position
newTab[e.hash & (newCap - 1)] = e;
// If it's a red black tree
else if (e instanceof TreeNode)
// Then split the red and black trees. This small series doesn't need to study further. If you are interested, you can click in and have a look
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
// Description is a linked list and the length is greater than 1
else { // preserve order
// The head and tail nodes in the old position of the linked list
Node<K,V> loHead = null, loTail = null;
// The head and tail nodes of the new position of the linked list
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// I don't quite understand it here. I can only refer to the explanation of the boss. I'm still a little confused. I'll sort it out again when I have time to understand it
do {
next = e.next;
// If the hash value and oldCap sum operation of the current element are 0, the original position remains unchanged
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
// If it is not 0, move the data to a new location
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
// A linked list whose original position remains unchanged, and the subscript of the array remains unchanged
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
// A linked list moved to a new location. The array subscript is the original subscript plus the capacity of the old array
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
5. Interpretation of get and containsKey methods
/**
* Get the corresponding value according to the key
*/
public V get(Object key) {
Node<K,V> e;
// After calling, get the value of the element and return
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Determine whether the key exists in the map
*/
public boolean containsKey(Object key) {
// The calling method exists and is not null
return getNode(hash(key), key) != null;
}
/**
* We found that getNode works at the bottom
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// Judge that the array cannot be empty, and then get the first element of the subscript position calculated by the current hash value
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// If the hash value and key are equal and not null, then we are looking for the first element
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
// Returns the first element
return first;
// If it's not the first one, keep looking
if ((e = first.next) != null) {
// If it's a red black tree
if (first instanceof TreeNode)
// Then we use the search method of red black tree to obtain the value corresponding to the key we want
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// This description is an ordinary linked list. We can look down in turn
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
// The value corresponding to the key cannot be found. null is returned
return null;
}
6. Interpretation of remove method
/**
* If the key exists, delete the element
*/
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
/**
* Specific implementation of deletion method
* @param hash key after hash operation
* @param key key you want to remove
* @param value value you want to remove
* @param matchValue If it is true, it will be deleted only when the values are equal. We are FALSE. If the key s are the same, it will be deleted
* @param movable If it is false, do not move other nodes during deletion. If it is TRUE, delete and move other nodes
*/
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
// Judge whether the table and linked list are not empty
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e; K k; V v;
// The first node in the array is the node we want to delete
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// node to delete
node = p;
// The first one is not, and there are nodes behind it
else if ((e = p.next) != null) {
// If it's a red black tree
if (p instanceof TreeNode)
// Return found in red black tree
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
// Traversal linked list
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
// Find the node to delete
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
// The node we want to delete has been found
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
// If it is a red black tree, delete it according to the red black tree
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
//What we want to delete is the head node
else if (node == p)
tab[index] = node.next;// Since the first node is deleted, you can directly point the corresponding position of the node array to the second node
//Not the head node, point the current node to the next node of the deleted node
else
p.next = node.next;// The next node of p points to the next node of node to delete node from the linked list
// Operation + 1
++modCount;
// map size - 1
--size;
// Empty implementation
afterNodeRemoval(node);
// Returns the deleted node
return node;
}
}
return null;
}
6, Summary
There are still a lot of bottom layers of Has and Map, and some logic and algorithms used in them are very cowhide and thought-provoking. The talents in oracle are still powerful. If you can't understand it, people can design it and realize it. Really, you and I are all mole ants, just people who move bricks and tools. Ha ha, a self mockery of yourself, ha, encourage!! See here, point a praise, small code words are not easy!! Thank you!!
Some notes are understood from: Reference blog
It's time to promote your website!!!
Click to visit! Welcome to visit, there are many good articles in it!