browser
How browser works
- user interface
- network
- UI backend
- data storage
- Browser engine
- rendering engine
- js interpreter
Mainstream browser
Mainstream browsers: IE, Firefox, Safari, Google Chrome, Opera
Four cores: Trident, Gecko, webkit and Blink
Introduce your understanding of the browser kernel
It is mainly divided into two parts: rendering engine and JS engine
Rendering engine:
Be responsible for obtaining the content of the web page (HTML, XML, images, etc.), sorting out the information (such as adding CSS, etc.), and calculating the display mode of the web page, and then output it to the display or printer. The syntax interpretation of web pages will be different due to different browser cores, so the rendering effect is also different. All web browsers, e-mail clients and other applications that need to edit and display network content need a kernel
JS engine:
Parse and execute javascript to achieve the dynamic effect of web pages. At first, there was no clear distinction between rendering engine and JS engine. Later, JS engine became more and more independent, and the kernel tended to only refer to rendering engine
computer network
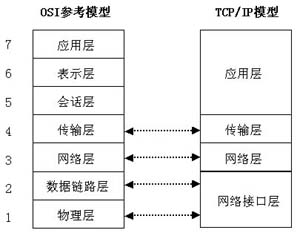
OSI seven layer network reference model and TCP/IP model
The seven layers of OSI from bottom to top are: physical layer, data link layer, network layer, transport layer, session layer, presentation layer and application layer
TCP/IP model is a seven layer network model referring to OSI. It can be considered as a simplified version of OSI and has become a de facto international standard
What happens to a page from entering the URL to the completion of page loading and display?
- DNS resolution
- Initiate TCP connection
- Send HTTP request
- The server processes the request and returns the HTTP message
- Browser parsing rendered pages
- End of connection
DNS resolution process
Browser cache - > system cache (Hosts file) - > router cache - > ISP DNS cache - > root domain name server
DNS load balancing
When you visit a website, you don't respond to the same server every time (different IP addresses). Generally, large companies have hundreds of servers to support access. DNS can return an appropriate machine IP to the user. For example, according to the load of each machine, the geographical distance of the machine user, etc., this process is DNS load balancing.
TCP connection
TCP (Transmission Control Protocol) is a connection oriented, reliable and byte stream based transport layer communication protocol
UDP(User Datagram Protocol) is a connectionless transport layer protocol in OSI (Open System Interconnection) reference model, which provides transaction oriented simple and unreliable information transmission service
Difference between UDP and TCP
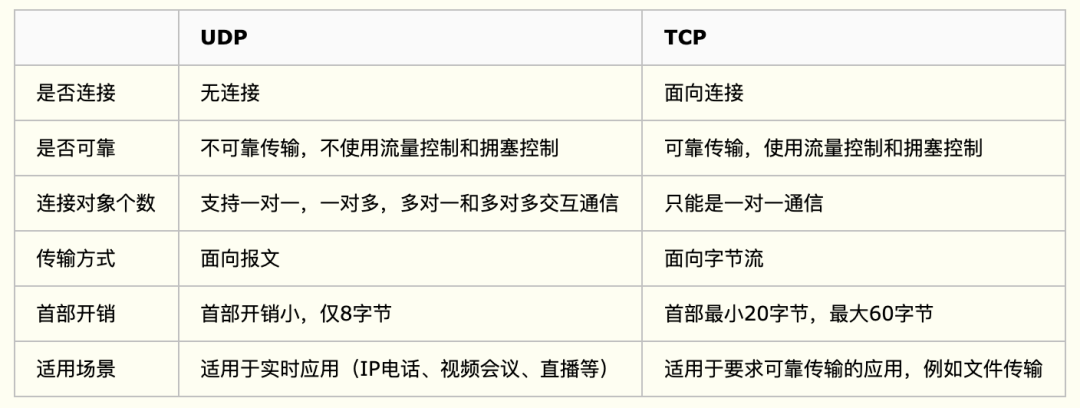
Summary
- TCP provides connection oriented reliable services to the upper layer, and UDP provides connectionless and unreliable services to the upper layer
- UDP is not as reliable as TCP transmission, but it can make a difference in places with high real-time requirements
- TCP can be selected for those with high data accuracy and relatively slow speed
Three handshakes
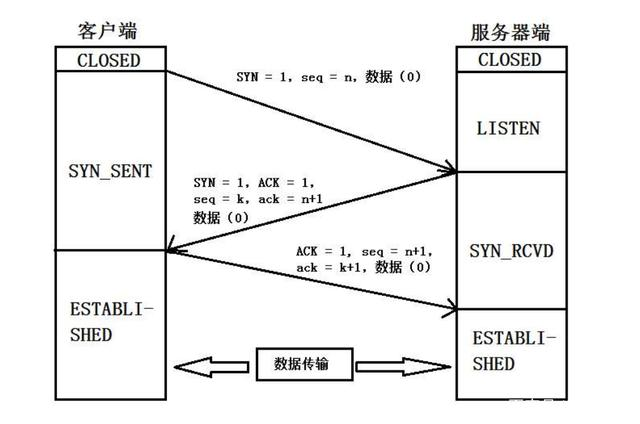
TCP connection is a connection oriented, safe and reliable transmission protocol in the transmission layer. The three-time handshake system is to ensure that a safe and reliable connection can be established.
First handshake:
Client - > server
Send a message. The syn position in the message is 1. When the client receives it, it will know that the client wants to initiate a connection to me
Second handshake:
Server - > client
Send a confirmation message packet in which the ACK position is 1; After the above two handshakes, the client already knows that the client can not only receive the request sent by the server, but also send messages to the server. But at this time, the server does not know whether the client can receive its own message, so there is a third handshake.
Third Handshake:
Client - > server
The client sends a confirmation message packet of ACK location 1 to the server
Through the above three connections, the client and server know each other, and both sides can receive and send messages to each other
Four waves
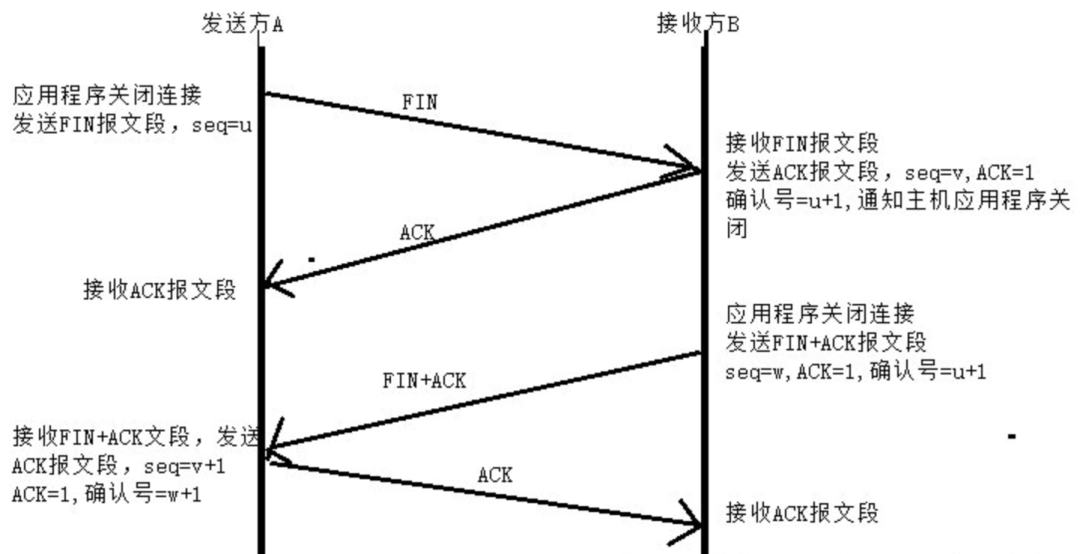
First wave:
Client - > server
The client sends a message to the server. FIN position 1 of the message indicates that it wants to disconnect from the server
Second wave:
Server - > client
When the server receives the message at FIN position 1, it knows that the client wants to disconnect; However, at this time, the server may not be ready to disconnect, so send a confirmation packet, ACK position 1, indicating that the client has received the message that the client wants to disconnect
Third wave:
Server - > client
When the server is ready to disconnect, it will send a confirmation packet at FIN position 1 to the client, indicating that the server can disconnect from the client at this time
Fourth wave:
Client - > server
The client sends the message confirmation packet of ACK location 1 to the server, indicating that the disconnection request of the server has been received
After these four waves, both the server and the client are ready to disconnect. At this time, you can disconnect
HTTP request
HTTP request process:
- DNS resolution
- Establish TCP connection
- Send HTTP request
- The server responds to HTTP requests
- Parse HTML code and request resources in HTML code (such as js, css, pictures, etc.)
- The browser renders the page to the user
HTTP request principle:
HTTP protocol is an application layer protocol and a C/S architecture service. It communicates based on TCP/IP protocol and listens on port 80 of TCP. HTTP protocol realizes that the client can obtain web resources from the server
HTTP 1.1 and HTTP 2.0
http 1.1
Persistent connection
Pipelining request
Add cache processing (new fields such as cache control)
Add Host field, support breakpoint transmission, etc
http 2.0
Binary framing
Multiplexing
Head compression
Server push
The difference between HTTP and HTTPS
- HTTPS protocol needs to apply for certificate from CA. generally, there are few free certificates, so it needs a certain fee
- HTTP is a hypertext transmission protocol, information is plaintext transmission, and HTTPS is a secure SSL encrypted transmission protocol
- HTTP and HTTPS use completely different connection modes and different ports. The former is 80 and the latter is 443
- HTTP connection is simple and stateless; HTTPS protocol is a network protocol constructed by SSL+HTTP protocol, which can carry out encrypted transmission and identity authentication. It is safer than HTTP protocol
HTTPS encryption process
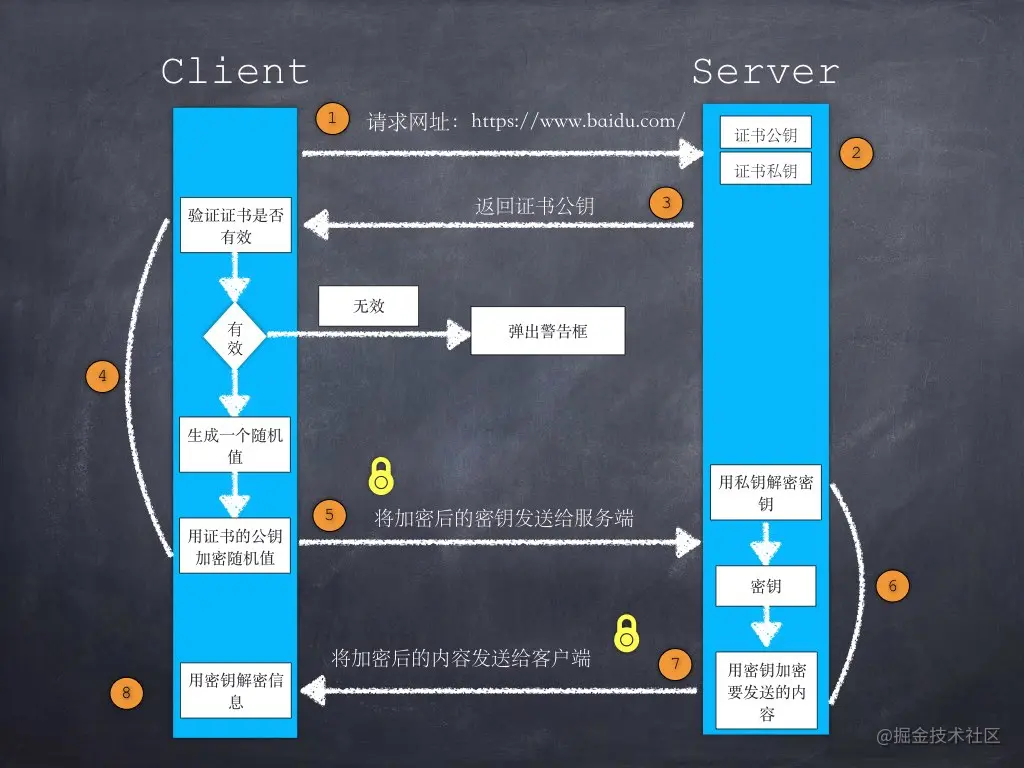
What are the common status codes?
1xx: in request processing, the request has been accepted and is being processed (when HTTP is upgraded to WebSocket, if the server agrees to the change, it will send the status code 101)
2xx: the request is successful, and the request is processed successfully
3xx: redirection. The completion request must be further processed (301 permanent redirection 302 temporary redirection 304. This status code will be returned when the negotiation cache hits)
4xx: client error, illegal request (403 Forbidden 404 not found 405 request method not allowed by server)
5xx: server side error, service unavailable, etc. (the function requested by 501 client is not supported yet, 502 server itself is normal, access error is unknown, 503 server is currently busy and unable to respond to the service temporarily)
HTTP cache
Browser - > Website
Need to load resources HTML, CSS, JS, IMG
After the first time, use the caching strategy to cache resources -- > speed up the opening of web pages
HTTP negotiation cache
Negotiation caching is a server-side caching strategy
The server returns the resource and resource ID, and saves the resource in the local cache; When the client communicates with the server again, simultaneous interpreting the resource identifier to the server, the server will determine whether the resource identifier returned by the browser is the same as the resource identity that the server wants to send. If the same, the browser will directly look for resources from the local cache.
Resource identification
Last modified: the time when the resource was last modified
Etag: the unique string corresponding to the resource
HTTP forced caching
When the client communicates with the server, if the server feels that the currently returned data should be cached, it will add a cache control in the response header headers and set the time of caching resources by setting Max age; Max age (s) is not expired, and the corresponding resources are directly taken from the cache.
The difference between Session and Cookie
The session is on the server side and the cookie is on the client side (browser)
The session is stored in a file on the server by default (not in memory)
The running of the session depends on the session id, which is stored in the cookie. That is, if the browser disables the cookie, the session will also become invalid (but it can be implemented in other ways, such as passing the session_id in the url)
session is usually used for user authentication
Web Performance Optimization Technology
- DNS query optimization
- Client cache
- Optimize TCP connections
- Avoid redirects
- Network edge caching
- Conditional cache
- Compression and code simplification
- Picture optimization
What is XSS attack?
XSS concept
XSS, namely Cross Site Scripting, is called Cross Site Scripting attack in Chinese. The focus of XSS is not on executing scripts across sites.
Principle of XSS:
Malicious attackers will insert some malicious script code into web pages. When the user browses the page, the script code embedded in the web page will execute, so it will achieve the purpose of malicious attack on the user.
XSS classification:
Storage type
Attack steps of storage XSS:
- The attacker submits malicious code to the database of the target website.
- When the user opens the target website, the website server takes the malicious code out of the database, splices it in HTML and returns it to the browser.
- After receiving the response, the user browser parses and executes, and the malicious code mixed in it is also executed.
- Malicious code steals user data and sends it to the attacker's website, or impersonates the behavior of the user and calls the interface of the target website to perform the operation specified by the attacker.
Reflex type
The malicious code of reflective XSS exists in the URL, which is parsed by the browser and executed. It calls the interface of the target website to perform the operation specified by the attacker
DOM type
The difference between DOM XSS and the first two XSS: in DOM XSS attack, the extraction and execution of malicious code is completed by the browser, which belongs to the security vulnerability of the front-end JavaScript itself, while the other two XSS belong to the security vulnerability of the server
XSS attack prevention
HttpOnly: after the HttpOnly attribute is set in the cookie, the js script will not be able to read the cookie information.
Input filtering: it is generally used to check the input format, such as email, phone number, user name, password, etc. input according to the specified format. Not only the front end is responsible, but also the back end should do the same filtering check. Because the attacker can bypass the normal input process and directly send settings to the server using the relevant interface.
Escape HTML: if it is necessary to splice HTML, you need to escape quotation marks, angle brackets and slashes, but this is not very perfect If you want to fully escape the insertion points of HTML template, you need to use an appropriate escape library
Whitelist: for displaying rich text, you can't escape all characters through the above method, because it will filter out the required format. In this case, the method of white list filtering is usually adopted. Of course, it can also be filtered through blacklist. However, considering that there are too many tags and tag attributes to be filtered, the method of white list is more recommended
CSRF attack
Cross Site Request Forgery is an attack way to coerce users to perform unintentional operations on the currently logged in web application. Compared with cross site scripting, XSS uses the user's trust in the specified website, and CSRF uses the website's trust in the user's web browser.
Cross site request attack, in short, is that the attacker deceives the user's browser through some technical means to visit a website he has authenticated and perform some operations (such as sending e-mail, sending messages, and even property operations, such as transferring money and purchasing goods). Because the browser has been authenticated, the visited website will be considered as a real user operation. This takes advantage of a loophole in user authentication in the web: simple authentication can only ensure that the request is sent from a user's browser, but it can not guarantee that the request itself is sent by user resources.
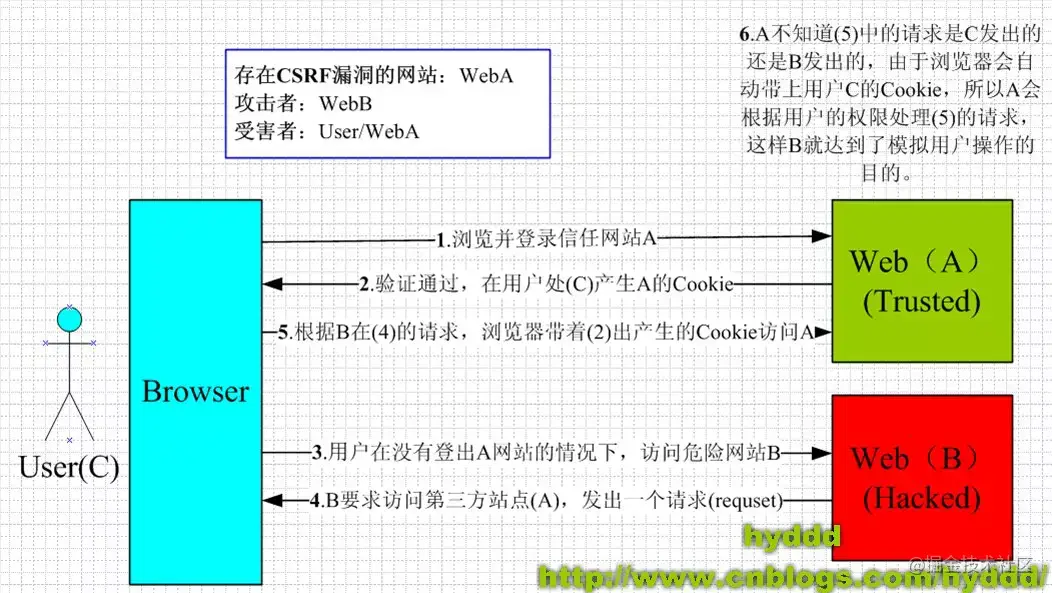
Prevention of CSRF attack
Verification Code: force the user to interact with the application to complete the final request. This method can well curb csrf, but the user experience is poor.
Referer check: the request source is limited. This method has the lowest cost, but it can not guarantee 100% effectiveness, because the server can not get referers at any time, and there is a risk of forgery of referers in lower version browsers.
Token: the CSRF defense mechanism verified by token is recognized as the most appropriate scheme (for details, see the detailed description of token in the front-end authentication of this series). If the website also has XSS vulnerabilities, this method is also empty talk
CSS
BFS
What is BFC
BFC(Block Formatting Context) formatting context is the css rendering mode of box model layout in web pages. It refers to an independent rendering area or an isolated independent container.
Conditions for forming BFC
- Floating elements, float values other than none
- position (absolute, fixed)
- display is one of the following: inline block, table cell, table caption, flex
- overflow is one of the following: hidden, scroll, auto
Characteristics of BFC
- The inner boxes will be placed one by one in the vertical direction
- The distance in the vertical direction is determined by margin
- The area of bfc does not overlap with the element area of float
- When calculating the height of bfc, floating elements also participate in the calculation
- bfc is an independent container on the page. The child elements in the container will not affect the outside
flex layout
flex attribute values can be 1, 2, 3 and keyword attributes
A value
If there is only one attribute value of flex, for example, if flex: 1, this 1 indicates flex growth. At this time, both flex shrink and flex basis use the default values, which are 1 and auto respectively. If it is a length value, such as flex: 100px, then this 100px obviously refers to flex basis, because only the attribute value of flex basis among the three abbreviated css attributes is a length value. At this point, both flex grow and flex shrink use default values of 0 and 1, respectively
Two values
If the attribute value of flex has two values, the first value must refer to flex grow, and the second value represents different CSS attributes according to the type of value. The specific rules are as follows: if the second value is a value, such as flex: 1 2, then this 2 represents flex shrink, and flex basis uses the default value auto. If the second value is the length value, for example, flex: 1 100px, then this 100px refers to flex basis. At this time, flex shrink uses the default value of 0
Three values
If the attribute value of flex has three values, these three values represent flex grow th, flex shrink and flex basis respectively. Growth is amplification, shrink is contraction, and basis is benchmark
Display: none / visibility: Hidden / opacity: 0
display : none
- DOM structure: the browser will not render elements whose display attribute is none, which does not occupy space;
- Event monitoring: event monitoring cannot be performed
- Performance: changing this property dynamically will cause rearrangement and poor performance
- Inheritance: it will not be inherited by child elements. After all, subclasses will not be rendered
- Transition: transition does not support display
visibility : hidden
- DOM structure: elements are hidden, but will be rendered and will not disappear, occupying space;
- Event listening: DOM event listening cannot be performed
- Performance: changing this property dynamically will cause redrawing, with high performance
- Inheritance: it will be inherited by child elements. Child elements can be unhidden by setting visibility: visible
- transition: visibility will be displayed immediately and delayed when hidden
opacity : 0
- DOM structure: transparency is 100%, elements are hidden and occupy space
- Event listening: DOM event listening can be performed
- Performance: promoted to composite layer, no redrawing will be triggered, with high performance
- Inheritance: it will be inherited by child elements, and child elements cannot be unhidden through opacity: 1;
- transition: opacity can be displayed and hidden with delay
How to center a box horizontally and vertically
Use positioning (common methods, recommended)
Using margin:auto
Use display: Flex; Set vertical and horizontal center
Using transform
How to realize the Holy Grail (double wings) layout
How to center an img label vertically
#container {
display : table-cell;
text-align: center;
vertical-align : center;
}
Make a triangle with CSS
.triangle{
width: 0;
height: 0;
border: 30px solid transparent;
border-top-color: #ccc
}
Differences between px, em, rem and vh in CSS units
px
px Pixel is a unit of relative length. px Pixel is relative to the resolution of the display screen
rem
Rem is that the entire length is relative to the root element < html > element. The usual approach is to set a font size for html elements, and then the length unit of other elements is rem
em
If the element is em, it is relative to the font size of the element
vw/vh
The full names are Viewport Width and Viewport Height. The width and height of the window are equivalent to 1% of the screen width and height. However, the% unit is more appropriate when dealing with width, and the vh unit is better when dealing with height
Mobile terminal adaptation scheme
1. rem adaptation scheme
1rem length is equal to the font size length of html tag
Implementation of flexible
function setRemUnit(){
var rem = docEl.clientWidth / 10
docEl.style.fontSize = rem + 'px'
}
setRemUnit()
2. vw, vh scheme
vh and vw schemes, i.e. visual viewport width window Innerwidth and visual viewport height window Innerheight is equally divided into 100 copies; However, in today's engineering, when webpack parses css, there is a postcss px to viewport with postcss loader, which can automatically convert px to vw
3. px is the main, vx and vxxx (vw/vh/vmax/vmin) are the auxiliary, and some flex (recommended)
This scheme is recommended because we need to consider the needs of users. Users buy large screen mobile phones not to see larger words, but to see more content. In this way, px is the wisest scheme to use directly. It is understandable to use vw, REM and other layout means. However, flex is popular today, If you still use this traditional thinking to think about problems, there are obviously two reasons (I think px is the best, there may be a big man who can write a delicate layout with vw or rem, but I'm not sure):
1. In order to be lazy, I don't want to do the fitness of every mobile phone
2. Unwilling to learn new layout methods, let flex and other advanced layouts pass you by
JavaScript
data type
Basic data types: Number, String, Boolean, undefined, null, symbol
Reference data types: Array, function, Object, Date, RegExp
Judge basic data type = = > typeof
typeof cannot be used to determine null
typeof 'seymoe' // 'string'
typeof true // 'boolean'
typeof 10 // 'number'
typeof Symbol() // 'symbol'
typeof null // 'object' cannot determine whether it is null
typeof undefined // 'undefined'
typeof {} // 'object'
typeof [] // 'object'
typeof(() => {}) // 'function'
The instanceof operator is used to detect whether the prototype attribute of the constructor appears on the prototype chain of an instance object
console.log([] instanceof Array); // true
console.log({} instanceof Object); // true
Judge the reference data type = = > object prototype. toString. call()
Handwritten function judging data type
function typeOf(object) {
return Object.prototype.toString.call(object).slice(8, -1);
}
// console.log(Object.prototype.toString.call([]))
// console.log(Object.prototype.toString.call({}))
// console.log(Object.prototype.toString.call(99))
console.log(typeOf([])) // Array
console.log(typeOf({})) // Object
console.log(typeOf(99)) // Number
How to judge null
- ===
- Object.prototype.toString.call()
let re = null console.log(re === null); //true console.log(Object.prototype.toString.call(null)); // object Null
Method of judging array
instanceof
instanceof is mainly used to judge whether an instance belongs to an object
arr instanceof Array
Object.prototype.toString.call()
Object.prototype.toString.call(arr) // [object Array]
Array.isArray()
Array.isArray(arr) // true
constructor
arr.constructor //Array
How to compare two objects in JavaScript
- Using JSON Stringify converts an object into a string for = = = comparison
let obj1 = {
name: "smy",
age: 23,
team:"HII"
}
let obj2 = {
name: "smy",
age: 23,
team:"HII"
}
function isObjEqual(obj1,obj2) {
return JSON.stringify(obj1) === JSON.stringify(obj2)
}
console.log(isObjEqual(obj1, obj2)) //true
- Compare objects one by one
function diff(obj1,obj2) {
let ty1 = obj1 instanceof Object;
let ty2 = obj2 instanceof Object;
if (!ty1 || !ty2) {
return false;
}
if (Object.keys(obj1).length !== Object.keys(obj2).length) {
return false;
}
for (let key in obj1) {
let key1 = obj1[key] instanceof Object;
let key2 = obj2[key] instanceof Object;
if (key1 && key2) {
diff(obj1[key],obj2[key])
} else if (obj1[key] !== obj2[key]) {
return false;
}
}
return true;
}
Detect an empty object
Object.getOwnPropertyName gets the property name in the object and stores it in an array
Object.keys(obj) gets a string array of all enumerable properties of a given object
hasOwnProperty checks whether the property exists in the object instance (enumerable property). If it exists, it returns true. If it does not exist, it returns false
(1) Through object The keys () method obtains the key, and the length is empty
let obj = {
name: "smy",
age: 23,
team:"HII"
};
console.log(Object.keys(newObj).length ===0);
(2) Through json Convert stringify to json string
let obj = {}
let b = JSON.stringify(obj)
console.log(b === '{}') // true
(3) Through the method of object getOwnPropertyNames
const res = Object.getOwnPropertyNames(obj); console.log(res.length === 0); // true indicates an empty object
(4) Judging by the for loop
function test(obj) {
for (let key in obj) {
return false;
}
return true;
}
Pseudo array to real array
Method I: add traversal to a new array
var newArr = []; // Create an empty array first
for(var i = 0; i < arr.length; i++){ // Loop through pseudo array
newArr.push(arr[i]);; // Take out the data of the pseudo array and put it in the real array one by one
}
newArr.push("hello");
console.log(newArr); // hello
Method II: arr.push Apply (arr, pseudo array)
let newArr = [] newArr.push.apply(newArr,arr)
Method III: array from()
let newArr = Array.from(arr)
Method IV: use the slice method, use the slice method of the Array prototype object and apply to point this in the slice to the pseudo Array
let newArr = Array.prototype.slice.apply(arr)
undefined
undefined is both an original data type and an original value data
An attribute window. On the undefined global object undefined
Not writable
window.undefined = 1 console.log(window.undefined) // undefined
Not configurable
delete window.undefined console.log(window.undefined)
countless
for(var k in window){
if(k === undefined){
console.log(k)
}
}
Cannot be redefined
Object.defineProperty(window,'undefined')
undefined is not a reserved word or keyword
// Define global variables
var undefined = 1;
console.log(undefined); // undefined
// Define local variables
function test() {
var undefined = 1;
console.log(undefined); // 1
}
test();
The return value of void() expression is undefined
var a, b, c; a = void ((b = 1), (c = 1)); console.log(a, b, c);
Common methods of array
graph LR A[Common methods of array] ---> B[Operation method] A ---> C[Sorting method] A ---> D[Conversion method] A ---> E[Iterative method]
The basic operations of an array can be summarized as adding, deleting, modifying, and querying. You should pay attention to which methods will affect the original array and which methods will not
Operation method
increase
The first three methods below are the addition methods that affect the original array, while the fourth method will not affect the original array
push()
Method receives any number of parameters, adds them to the end of the array, and returns the latest length of the array
unshift()
Add any number of values at the beginning of the array, and then return the new array length
splice()
Pass in three parameters: start position, 0 (number of elements to be deleted) and inserted elements, and return an empty array
let colors = ["red", "green", "blue"]; let removed = colors.splice(1, 0, "yellow", "orange") console.log(colors) // red,yellow,orange,green,blue console.log(removed) // []
concat()
First, a copy of the current array will be created, then its parameters will be added to the end of the copy, and finally the newly constructed array will be returned without affecting the original array
let colors = ["red", "green", "blue"];
let colors2 = colors.concat("yellow", ["black", "brown"]);
console.log(colors); // ["red", "green","blue"]
console.log(colors2); // ["red", "green", "blue", "yellow", "black", "brown"]
Delete
The following three will affect the original array, and the last item will not affect the original array:
pop()
Method is used to delete the last item of the array, reduce the length value of the array, and return the deleted item
let colors = ["red", "green"] let item = colors.pop(); // Get the last item console.log(item) // green console.log(colors.length) // 1
shift()
The shift() method is used to delete the first item of the array, reduce the length value of the array, and return the deleted item
let colors = ["red", "green"] let item = colors.shift(); // Get the first item console.log(item) // red console.log(colors.length) // 1
splice()
Pass in two parameters: the start position, the number of deleted elements, and return the array containing the deleted elements
let colors = ["red", "green", "blue"]; let removed = colors.splice(0,1); // Delete the first item console.log(colors); // green,blue console.log(removed); // red, an array with only one element
slice()
slice() does not affect one or more elements in the original array
let colors = ["red", "green", "blue", "yellow", "purple"]; let colors2 = colors.slice(1); let colors3 = colors.slice(1, 4); console.log(colors) // red,green,blue,yellow,purple concole.log(colors2); // green,blue,yellow,purple concole.log(colors3); // green,blue,yellow
change
That is, modify the contents of the original array, commonly used splice
splice()
Pass in three parameters: the start position, the number of elements to be deleted, any number of elements to be inserted, and return the array of deleted elements, which will have an impact on the original array
let colors = ["red", "green", "blue"]; let removed = colors.splice(1, 1, "red", "purple"); // Insert two values and delete an element console.log(colors); // red,red,purple,blue console.log(removed); // green, an array with only one element
check
That is to find elements and return element coordinates or element values
indexOf()
Returns the position of the element to be found in the array. If it is not found, it returns - 1
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; numbers.indexOf(4) // 3
includes()
Returns the position of the element to be found in the array. If found, it returns true. Otherwise, it returns false
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; numbers.includes(4) // true
find()
Returns the first matching element
let person = [
{
name: "smy",
age:22,
},
{
name: "wy",
age:19
}
]
let result = person.find((item, index, arr) => item.age > 20)
console.log(result)
Sorting method
Array has two methods to reorder elements
reverse()
As the name suggests, array elements are arranged in the same direction
let values = [1, 2, 3, 4, 5]; values.reverse(); alert(values); // 5,4,3,2,1
sort()
The sort() method accepts a comparison function to determine which value should come first
function compare(value1, value2) {
if (value1 < value2) {
return -1;
} else if (value1 > value2) {
return 1;
} else {
return 0;
}
}
let values = [0, 1, 5, 10, 15];
values.sort(compare);
alert(values); // 0,1,5,10,15
Conversion method
Common conversion methods include:
join()
The join() method takes a parameter, the string separator, and returns a string containing all items
let colors = ["red", "green", "blue"];
alert(colors.join(",")); // red,green,blue
alert(colors.join("||")); // red||green||blue
Iterative method
The methods commonly used to iterate algebraic groups (without changing the original array) are as follows:
some()
The some() method tests whether at least one element in the array passes the provided function test. It returns a value of type Boolean
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let result = numbers.some((item, index, arry) => item > 2) console.log(result)
every()
Run the passed in function for each item of the array. If the function returns true for each item, this method returns true
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let result = numbers.every((item, index, array) => item > 2) console.log(result) //false
forEach()
Run the passed in function on each item of the array without returning a value
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1];
numbers.forEach((item, index, array) => {
// Perform some actions
});
filter()
Run the passed in function for each item of the array, and the items that return true will form an array and then return
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let result = numbers.filter((item, index, array) => item > 2) console.log(result)
map()
Run the passed in function on each item of the array and return the array composed of the results of each function call
let numbers = [1, 2, 3, 4, 5, 4, 3, 2, 1]; let result = numbers.map((item, index, array) => item * 2) console.log(result)
What is a pseudo array? How to convert an array?
Pseudo array:
- With length attribute
- Store data by index
- push/pop and other methods without array
Pseudo array to real array:
- Array. From() --- > new method in ES6
let lis = document.querySelectorAll("li");
Array.from(lis).forEach((item) => {
console.log(item);
});
- []. slice. Call (elearray) or array prototype. slice.call(eleArr)
[].slice.call(lis).forEach((item) => {
console.log(item);
});
reduce method
Common methods of string
graph LR A[Common methods of string] --->B[Operation method] A---> C[Conversion method] A ---> D[Template matching method]
Operation method
We can also summarize the common operation methods of string into addition, deletion, modification and query
increase
The meaning of adding here is not to add content directly, but to create a copy of the string and then operate
In addition to string splicing with + and ${}, concat can also be used
concat
Used to splice one or more strings into a new string
let stringValue = "hello ";
let result = stringValue.concat("world");
console.log(result); // "hello world"
console.log(stringValue); // "hello"
Delete
Delete here does not mean to delete the contents of the original string, but to create a copy of the string and then operate
Common are:
- slice()
- substr()
- substring()
All three methods return a substring of the string that called them, and all receive one or two parameters
let stringValue = "hello world"; console.log(stringValue.slice(3)); // "lo world" console.log(stringValue.substring(3)); // "lo world" console.log(stringValue.substr(3)); // "lo world" console.log(stringValue.slice(3, 7)); // "lo w" console.log(stringValue.substring(3,7)); // "lo w" console.log(stringValue.substr(3, 7)); // "lo worl"
change
The meaning of changing here is not to change the original string, but to create a copy of the string and then operate
Common are:
trim(),trimLeft(),trimRight()
Delete all space characters before, after, or before and after, and then return a new string
let stringValue = " hello world "; let trimmedStringValue = stringValue.trim(); console.log(stringValue); // " hello world " console.log(trimmedStringValue); // "hello world"
repeat()
Receive an integer parameter indicating how many times to copy the string, and then return the result after splicing all copies
let stringValue = "na "; let copyResult = stringValue.repeat(2) // na na
padEnd()
Copy the string. If it is less than the specified length, fill in characters on the corresponding side until the length condition is met
let stringValue = "foo"; console.log(stringValue.padStart(6)); // " foo" console.log(stringValue.padStart(9, ".")); // "......foo"
toLowerCase(), toUpperCase()
Case conversion
let stringValue = "hello world"; console.log(stringValue.toUpperCase()); // "HELLO WORLD" console.log(stringValue.toLowerCase()); // "hello world"
check
In addition to obtaining the value of the string by index, you can also use:
- chatAt()
- indexOf()
- startWith()
- includes()
charAt()
Returns the character of the given index position, specified by the integer parameter passed to the method
let message = "abcde"; console.log(message.charAt(2)); // "c"
indexOf()
Search the incoming string from the beginning of the string and return the position (if not found, return - 1)
let stringValue = "hello world";
console.log(stringValue.indexOf("o")); // 4
startWith(),includes()
let message = "foobarbaz";
console.log(message.startsWith("foo")); // true
console.log(message.startsWith("bar")); // false
console.log(message.includes("bar")); // true
console.log(message.includes("qux")); // false
Conversion method
split
Splits the string into each item in the array according to the specified delimiter
let str = "12+23+34"
let arr = str.split("+") // [12,23,34]
Template matching method
For regular expressions, several methods are designed for Strings:
- match()
- search()
- replace()
match()
Receive a parameter, which can be a regular expression string or a RegExp object, and return an array
let text = "cat, bat, sat, fat"; let pattern = /.at/; //. match everything let matches = text.match(pattern); console.log(matches[0]); // "cat"
search()
Receive a parameter, which can be a regular expression string or a RegExp object. If it is found, the matching index will be returned, otherwise - 1 will be returned
let text = "cat, bat, sat, fat"; let pos = text.search(/at/); console.log(pos); // 1
replace()
Receive two parameters, the first parameter is the matching content, and the second parameter is the replaced element (available function)
let text = "cat, bat, sat, fat";
let result = text.replace("at", "ond");
console.log(result); // "cond, bat, sat, fat"
Type conversion mechanism
graph LR A[Type conversion mechanism]----> B[summary] A---->C[Display conversion] A---->D[Implicit conversion]
Display conversion
Display transformation, that is, we can clearly see the type transformation here. The common methods are:
- Number()
- parseInt()
- String()
- Boolean()
Number() converts any type of value to a numeric value
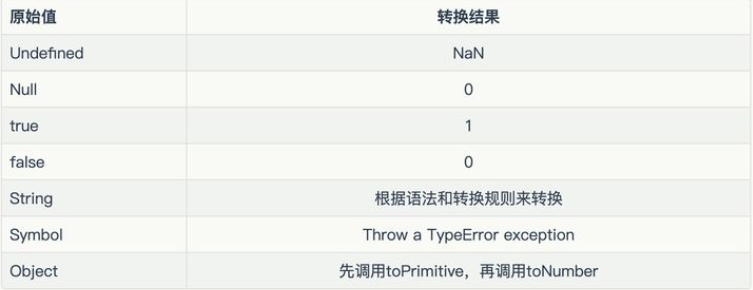
Number(324) // 324
// String: if it can be parsed into a numerical value, it will be converted to the corresponding numerical value
Number('324') // 324
// String: if it cannot be parsed into a numeric value, NaN is returned
Number('324abc') // NaN
// Empty string to 0
Number('') // 0
// Boolean value: true to 1, false to 0
Number(true) // 1
Number(false) // 0
// undefined: converted to NaN
Number(undefined) // NaN
// null: convert to 0
Number(null) // 0
// Object: usually converted to Nan (except for arrays containing only a single value)
Number({a: 1}) // NaN
Number([1, 2, 3]) // NaN
Number([5]) // 5
As can be seen from the above, the Number conversion is very strict. As long as one character cannot be converted to a value, the whole string will be converted to NaN
parseInt()
ParseInt is less strict than Number. The parseInt function parses characters one by one and stops when it encounters characters that cannot be converted
parseInt('32a3') //32
String()
You can convert any type of value to a string
Give the conversion rule diagram:
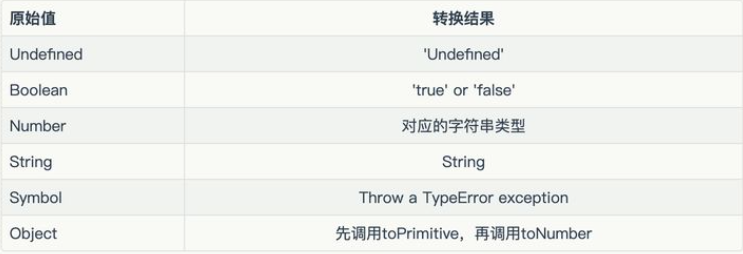
// Numeric value: converted to the corresponding string
String(1) // "1"
//String: the original value after conversion
String("a") // "a"
//Boolean value: true to string "true", false to string "false"
String(true) // "true"
//Undefined: converted to string "undefined"
String(undefined) // "undefined"
//Null: converted to string "null"
String(null) // "null"
//object
String({a: 1}) // "[object Object]"
String([1, 2, 3]) // "1,2,3"
Boolean()
Any type of value can be converted to Boolean value. The conversion rules are as follows:

Boolean(undefined) // false
Boolean(null) // false
Boolean(0) // false
Boolean(NaN) // false
Boolean('') // false
Boolean({}) // true
Boolean([]) // true
Boolean(new Boolean(false)) // true
Implicit conversion
Here we can summarize it into two scenarios where implicit conversion occurs:
- Where Boolean values are required for comparison operations (= =,! =, >, <), if and while
- Arithmetic operation (+, -, *, /,%)
In addition to the above scenario, it is also required that the operands on both sides of the operator are not of the same type
Automatically convert to Boolean
Where Boolean values are needed, non Boolean parameters will be automatically converted to Boolean values, and Boolean functions will be called inside the system
A summary can be drawn:
- undefined
- null
- false
- +0
- -0
- NaN
- ""
In addition to the above, they will be converted to false, and others will be converted to true
Automatically convert to string
Where a string is expected, the non string value is automatically converted to a string
The specific rules are: first convert the value of the composite type to the value of the original type, and then convert the value of the original type to a string
It often occurs in the + operation. Once there is a string, the string splicing operation will be carried out
'5' + 1 // '51'
'5' + true // "5true"
'5' + false // "5false"
'5' + {} // "5[object Object]"
'5' + [] // "5"
'5' + function (){} // "5function (){}"
'5' + undefined // "5undefined"
'5' + null // "5null"
Automatic conversion to value
Except that + may convert the operator to a string, other operators will automatically convert the operator to a numeric value
'5' - '2' // 3 '5' * '2' // 10 true - 1 // 0 false - 1 // -1 '1' - 1 // 0 '5' * [] // 0 false / '5' // 0 'abc' - 1 // NaN null + 1 // 1 undefined + 1 // NaN
null`When converted to a value, the value is`0` . `undefined`When converted to a value, the value is`NaN
JSON.parse() (JSON string to JS object)
The conversion can only be completed in the case of 'package'
const json = '{"name":"smy","age":23,"team":"HII"}'
let js = JSON.parse(json);
console.log(js)
Disadvantages:
An error will be reported when json changes to "package"
const str = "{'name':'smy','age':23,'team':'HII'}"
let json = JSON.parse(str);
console.log(str)
Query string & & JS object & & JSON string conversion
Stack memory and heap memory
Variables in JavaScript are divided into basic types and reference types
The basic type is a simple data segment stored in the stack memory. Their values have a fixed size. They are stored in the stack space, accessed by value, and automatically allocated and released by the system. The advantage of this is that the memory can be recycled in time, which makes it easier to manage the memory space than the heap. Boolean, Null, Undefined, Number, String and Symbol in JavaScript are all basic types
Reference types (such as objects, arrays, functions, etc.) are objects stored in heap memory. The value size is not fixed. The access address of the object stored in stack memory points to the object in heap memory. JavaScript does not allow direct access to the location in heap memory. Therefore, when operating an object, the reference of the actual operation object. Object, Array, Function, RegExp and Date in JavaScript are reference types.
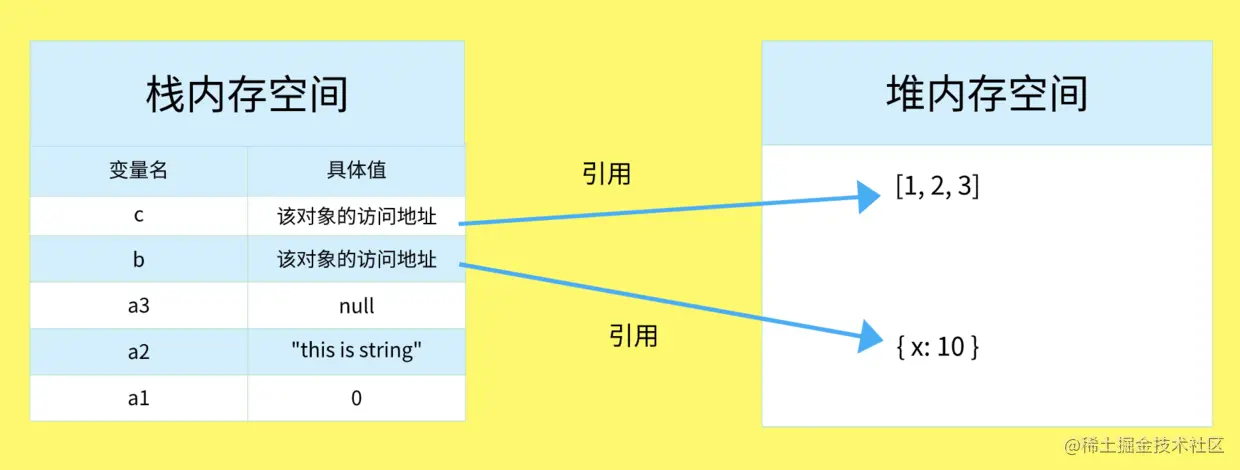
Deep copy and shallow copy
graph LR A[Shallow copy and deep copy]---->B[Data type storage] A---->C[Shallow copy] A---->D[Deep copy] A---->E[difference]
Data type storage
There are two major data types in JavaScript:
- Basic type
- reference type
The basic type data is saved in stack memory
The reference type data is stored in the heap memory. The variable of the reference data type is a reference to the actual object in the heap memory, which is stored in the stack
Shallow copy
Shallow copy refers to the creation of new data, which has an accurate copy of the attribute value of the original data
If the attribute is a basic type, the value of the basic type is copied. If the attribute is a reference type, the memory address is copied
That is, a shallow copy is a copy layer, and a deep reference type is a shared memory address
Here is a simple implementation of a shallow copy
function shalowClone(obj){
const newObj = {};
for(let prop in obj){
if(obj.hasOwnProperty(prop)){
newObj[prop] = obj[prop]
}
}
return newObj;
}
In JavaScript, the phenomena of shallow copy include:
- Object.assign
- Array.prototype.slice(), Array.prototype.concat()
- Replication using extension operators
Object.assign()
// object.assign()
var obj = {
age: 18,
nature: ['smart', 'good'],
names: {
name1: 'fx',
name2: 'xka'
},
love: function () {
console.log('fx is a great girl')
}
}
let newObj = Object.assign({}, obj);
slice()
slice(0) returns a new array starting from index 0
const fxArr = ["One", "Two", "Three"] const fxArrs = fxArr.slice(0) console.log(fxArrs) // ["One", "Two", "Three"]
concat()
const fxArr = ["One", "Two", "Three"] const fxArrs = fxArr.concat() console.log(fxArrs) // ["One", "Two", "Three"]
Extension operator
const fxArr = ["One", "Two", "Three"] const fxArrs = [...fxArr] console.log(fxArrs) // ["One", "Two", "Three"]
Deep copy
Deep copy opens up a new stack. The properties of two objects are the same, but corresponding to two different addresses. Modifying the properties of one object will not change the properties of the other object
Common deep copy methods include:
- _.cloneDeep()
- jQuery.extend()
- JSON.stringify()
- Handwriting loop recursion
_.cloneDeep()
const _ = require("lodash")
const obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
const obj2 = _.cloneDeep(obj1)
console.log(obj1.b.f === obj2.b.f);// false
jQuery.extend()
const $ = require('jquery');
const obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
const obj2 = $.extend(true, {}, obj1);
console.log(obj1.b.f === obj2.b.f); // false
JSON.stringify()
const obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
const obj2 = JSON.parse(JSON.stringify(obj1));
However, this method has disadvantages, and undefined, symbol and function are ignored
Circular recursion
function deepClone(newObj,obj) {
for (let key in obj) {
if (obj[key] instanceof Array) {
newObj[key] = [];
deepClone(newObj[key],obj[key])
} else if (obj[key] instanceof Object) {
newObj[key] = {};
deepClone(newObj[key],obj[key])
} else {
newObj[key] = obj[key]
}
}
return newObj
}
Iteratable object
iteration: array string map set arguments typearray ----- > for... of traversal can be used
Iterator object: it can be traversed by means of for... Of
What is the difference between traversal and iteration?
Iteration: extract data one by one from the target source
Target source: 1 Orderly; 2. Continuous
The difference between Set and Map
SET
Members cannot be duplicate
Only key value without name
Can traverse
Set attribute and method: size() add() delete() has() clear()
Map
It is essentially a set of key value pairs, similar to a set
Can traverse
It can be converted with various data formats
Map properties and methods: map set() map. get()
Map can be traversed with for... Of instead of for... in
What is the difference between the array of each and the array of fore map?
Similarities:
Loop through each item in the array
difference:
The map method returns a new array. The elements in the array do not have the value processed by the original array call function
The map method does not detect an empty array, and the map method does not change the original array
The forEach method is used to call each element of the array and pass the element to the callback function
forEach will not call the callback function for an empty array. Whether arr is an empty array or not, forEach returns undefined
prototype
JavaScript is a language that implements inheritance through prototypes. It is different from other high-level languages, such as java and C# is common
JavaScript is a dynamic and weakly typed language. In short, it can be considered that all objects in JavaScript are objects. In JavaScript, the prototype is also an object, and the attribute inheritance of objects can be realized through the prototype,
JavaScript objects contain an internal attribute of "prototype", which corresponds to the prototype of the object.
Prototype chain
When we access the attribute of an object, if the attribute does not exist inside the object, he will go to the prototype to find the attribute, and the prototype will have its own prototype, so we keep looking, that is, the concept of prototype chain
The relationship among constructor, instance and prototype object
Member lookup mechanism of JavaScript
- When accessing the properties (including methods) of an object, first find out whether the object itself has the property
- If not, find its prototype (that is, the prototype object pointed to by _proto _)
- If not, find the prototype of the prototype Object (the prototype Object of the Object)
- And so on until the Object is found (null)
Inheritance in JS
Six inheritance methods in JS: prototype chain inheritance, borrowing constructor inheritance, combinatorial inheritance, type inheritance, parasitic inheritance, parasitic combinatorial inheritance
Prototype chain inheritance
The basic idea of JavaScript inheritance is to inherit the properties and methods of one reference type from another through prototype
function Animal() {
this.color = ['black', 'pink', 'white'];
}
Animal.prototype.getColor = function () {
return this.color;
}
function Dog() {
}
Dog.prototype = new Animal();
let dog1 = new Dog();
console.log(dog1.color);
Problems in prototype chain inheritance:
- Question 1: the reference type attribute contained in the prototype will be shared by all instances;
- Problem 2: subclasses cannot pass parameters to the parent constructor when instantiating
Constructor inheritance
The basic idea of JavaScript inheritance: call the super type constructor inside the subclass constructor. The constructor can be executed on the newly created subclass object by using the apply() and call() methods
function Animal(name) {
this.name = "Dog"
this.getName = function () {
return this.name;
}
}
function Dog(name) {
Animal.call(this, name);
}
Dog.prototype = new Animal();
let dog1 = new Dog();
console.log(dog1.name);
solve:
Using constructor to implement inheritance solves two problems of prototype chain inheritance: reference type sharing and parameter passing. However, because the method must be defined in the constructor, the method will be created every time a subclass instance is created.
class implementation inheritance
class Animal{
constructor(name){
this.name = name;
}
getName() {
return this.name;
}
}
class Dog extends Animal{
constructor(name, age) {
super(name);
this.age = age;
}
}
What exactly does the new operator do?
- An empty object is created, and this variable is introduced into the object. At the same time, it also inherits the prototype of the function
- Set the prototype chain, and the empty object points to the prototype object of the constructor
- Execute the function body, modify the constructor, point to the null object with this pointer, and execute the function body
- Judge the return value, and use the returned object. If not, create an object
function objectFactory() {
var obj = new Object() // Create an empty object
Constructor = [].shift.call(arguments) // Set prototype chain
obj.__proto__ = Constructor.prototype
var ret = Constructor.apply(obj, arguments) // Set this to point to the incoming arguments instantiation object
return typeof ret === 'object' ? ret || obj:obj // Judge the return value. The returned object is returned immediately. If not, the new object is returned
}
this
this is a keyword of JavaScript
A property of the current environment runtime context object
this behaves differently in different environments and under different effects
The direction of this
- When called as a function, this is always window
- Called as a method, this is the object that calls the method
- When called as a constructor, this is an instantiated object
- When using call and apply calls, this is the specified object
- Arrow function: this of the arrow function is this of the internal arrow function. If not, it is window
- Special case: in general, the this pointer points to the object that finally calls it. One thing to note here is that if the return value is an object, this refers to the returned object. If the return value is not an object, this still points to the instance of the function
Promise
Asynchronous problems are executed synchronously
Generator&iterator
Loop & traversal & iteration
Loop: syntax at the language level - > scheme of repeatedly executing a program
Traversal: business level approach - > an approach to observe or obtain elements in a collection
Iteration: the concept at the implementation level - > the underlying scheme of implementation traversal is actually iteration
Iteratable object
The prototype object prototype has symbol Iterator, iterator object
for... The in statement iterates over the enumerable properties of an object in any order
for... The of statement traverses the iteratable object and defines the data to be iterated
Generator - > return iterator
function* generator(arr) {
for (let v in arr) {
yield v;
}
}
const res = generator(arr);
console.log(res.next()); //{value: '0', done: false}
console.log(res.next()); // {value: '1', done: false}
console.log(res.next()); // {value: '2', done: false}
console.log(res.next()); // {value: undefined, done: true}
Handwriting iterator
function generator(arr) {
let nextIndex = 0;
return {
next() {
return nextIndex < arr.length
? { value: arr[nextIndex++], done: false }
: { value: undefined, done: true };
},
};
}
const res = generator(arr);
console.log(res.next());
console.log(res.next());
console.log(res.next());
console.log(res.next());
JavaScript garbage collection mechanism
What is JavaScript garbage collection
JS garbage collection mechanism is to prevent memory leakage. Memory leakage means that a piece of memory still exists when it is no longer needed. Garbage collection mechanism is to intermittently and irregularly find variables that are no longer used and release the memory they point to
A common garbage collection method in JavaScript: mark removal
Working principle: when the variable enters the environment, mark the variable as "entering the environment". When a variable leaves the environment, it is marked as "leaving the environment".
Mark "out of environment" to reclaim memory
Code question
Deep copy
cloneDeep
const _ = require('lodash');
const obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
const obj2 = _.cloneDeep(obj1);
console.log(obj1.b.f === obj2.b.f); // false
JSON.stringify
const obj1 = {
a: 1,
b: { f: { g: 1 } },
c: [1, 2, 3]
};
const obj2 = JSON.parse(JSON.stringify(obj1));
console.log(obj2);
recursion
function deepClone(newObj,obj){
for (let key in obj) {
if (obj[key] instanceof Array) {
newObj[key] = []
deepClone(newObj[key],obj[key])
} else if (obj[key] instanceof Object) {
newObj[key] = {}
deepClone(newObj[key],obj[key])
} else {
newObj[key] = obj[key]
}
}
return newObj
}
How does the arrow function use arguments
let func = (...rest)=>{
console.log(rest)
}
Judge data type
function typeOf(obj) {
return Object.prototype.toString.call(obj).slice(8, -1);
}
Array de duplication
indexOf method
function deDulp(arr) {
let newArr = []
arr.forEach(item => {
if (newArr.indexOf(item) === -1) {
newArr.push(item)
}
})
return newArr
}
sort method
function deDulp(arr) {
let newArr = [arr[0]]
arr.sort((a, b) => a - b)
for (let i = 1; i < arr.length; i++){
if(arr[i] !== arr[i-1]) newArr.push(arr[i])
}
return newArr
}
includes method
function deDulp(arr) {
let newArr = []
arr.forEach(item => {
if(!newArr.includes(item)) newArr.push(item)
})
return newArr
}
ES6 set data structure
function deDulp(arr) {
return arr.forEach(item => [...new Set(item)])
}
Implementation of array flattening
recursion
Implementation method:
- If you encounter an array, continue calling flat() recursion
- If it is not an array, put it into the result
function deepFlatten(arr) {
let result = [];
for (let i = 0; i < arr.length; i++){
if (Array.isArray(arr[i])) {
result = result.concat(deepFlatten(arr[i]));
} else {
result.push(arr[i]);
}
}
return result;
}
reduce
Arrow function writing
function flatten(arr){
return arr.reduce((acc,curr) => acc.concat(Array.isArray(curr)? flatten(curr):curr) ,[])
}
ES6 extension operator
function deepFlatten(arr) {
while (arr.some(item => Array.isArray(item))) {
arr = [].concat(...arr);
}
return arr;
}
The number of layers the array is nested
function deepFlat(arr) {
let count = 0;
while (arr.some((item) => Array.isArray(item))) {
arr = [].concat(...arr);
count++;
}
return count;
}
Resolve URL
Please write a JS program to extract each GET parameter in the URL (the parameter name and number are uncertain) and return it to a json structure in the form of key value, such as {A: "1", b: "2", c: "", d: "xxx", e: undefined}
function serilizeUrl(url) {
let urlObject = {}
let reg = /\?/
if (reg.test(url)) { // Is there a matching url?
let urlString = url.substring(url.indexOf("?")+1)
let urlArray = urlString.split("&")
for (let i = 0; i < urlArray.length; i++){
let item = urlArray[i].split("=") // [a,1] [b,2] [c,] [d,xxx] [e]
urlObject[item[0]] = item[1]
}
return urlObject
}
return null
}
Hump conversion
function shiftT(foo) {
let arr = foo.split("-") // ['get','element','by','id']
for (let i = 1; i < arr.length; i++){
arr[i] = arr[i].charAt(0).toUpperCase() + arr[i].substring(1)
}
return arr.join("")
}
Is the number of elements in the array the same
function ifSame(arr) {
let map = {}
for (let num of arr) {
if (!map[num]) map[num] = 1;
else map[num]++
}
let count = Object.values(map)
count = count.sort((a, b) => a - b)
for (let i = 1; i < count.length; i++){
if(count[i] === count[i-1]) return true
}
return false
}
Find the most frequent letter in the string
function find(str) {
let obj = {};
for (let i = 0; i < str.length; i++){
if(!obj[str[i]]) obj[str[i]] = 1;
else obj[str[i]]++;
// console.log(str[i]) // h,e,l,l,o
}
// Compare size
let s = str.charAt(0) // It is assumed that the first character in the string has the largest number of occurrences
let max = obj[s];
for(let key in obj){
if(key === s) continue
if(obj[key] > max){
max = obj[key]
s = key
}
}
return [s,max]
}
Manually implement the reverse method of the array
function rever(arr) {
let i = 0;
let j= arr.length - 1;
while(i<=j){
let temp = arr[i]
arr[i] = arr[j]
arr[j] = temp
i++
j--
}
return arr
}
Anti shake
Re timing
If a program is scheduled to be triggered after the specified time, if this event is triggered again within the specified time, it should be timed again to ensure that the code in the event is executed only once.
Realization of anti shake
let debounce = (fn, wait) => {
let timer = null;
return function () {
clearTimeout(timer)
timer = setTimeout(() => {
fn.apply(this,arguments)
},wait)
}
}
throttle
Control times
After the event is triggered, the code is executed only once within the agreed time.
Realization of throttling
const throttle = (func, delay) => {
let timer = null;
return function () {
if (timer) {
return;
}
timer = setTimeout(() => {
func.apply(this, arguments);
timer = null;
},delay)
}
}
inherit
Prototype chain inheritance
Set the prototype object of another constructor to the instantiation object of one constructor
function Animal() {
this.color = ['white','brown']
}
Animal.prototype.getColor = function () {
return this.color
}
function Dog() { }
Dog.prototype = new Animal()
let dog1 = new Dog()
dog1.color.push('black')
let dog2 = new Dog()
console.log(dog1.getColor())
Problems in prototype chain inheritance:
- The reference type properties contained in the prototype will be shared by all instances
- Subclasses cannot pass arguments to the parent constructor when instantiating
Constructor inheritance
function Animal(name) {
this.name = name
this.getName = function () {
return this.name
}
}
function Dog(name) {
Animal.call(this,name)
}
Dog.prototype = new Animal()
Borrowing constructor to implement inheritance solves two problems of prototype chain inheritance:
- Reference type sharing and parameter passing
- However, because the method must be defined in the constructor, the method will be created every time a subclass instance is created
Combinatorial inheritance
Combinatorial inheritance combines the prototype chain and the embezzlement of constructor, and integrates the advantages of both. The basic idea is to use the prototype chain to inherit the properties and methods on the prototype, and inherit the instance properties by stealing the constructor. In this way, the method can be defined on the prototype to realize reuse, and each instance can have its own properties
function Animal(name) {
this.name = name
this.color = ['black','while']
}
Animal.prototype.getName = function () {
return this.name
}
function Dog(name,age) {
Animal.call(this, name)
this.age = age
}
Dog.prototype = new Animal()
Dog.prototype.constructor = Dog // The prototype object constructor points to the constructor
let dog1 = new Dog('haha', 1)
console.log(dog1) // Dog { name: 'haha', color: [ 'black', 'while' ], age: 1 }
Composite inheritance has been relatively perfect, but there are still problems. Its problem is to call the parent constructor twice
- The first time was in new Animal()
- The second time was in animal Call () here
Parasitic combinatorial inheritance
The code based on composite inheritance is changed to the simplest parasitic composite inheritance
function Animal(name) {
this.name = name
this.color = ['black','white']
}
function Dog(name,age) {
Animal.call(this, name)
this.age = age
}
Dog.prototype = Object.create(Animal.prototype)
Dog.prototype.constructor = Dog
let dog1 = new Dog('xixi',2)
console.log(dog1)
class implementation inheritance
Use class to construct a parent class, use class to construct a subclass, and use extensions to implement inheritance. super points to the prototype object of the parent class
class Animal{
constructor(name){
this.name = name
}
getName() {
return this.name
}
}
class Dog extends Animal{
constructor(name, age) {
super(name)
this.age = age
}
}
Array method
Implement forEach method
Array.prototype.forEach2 = function(callback,thisArgs) {
if (this === null) {
throw new Error("this is null or not defined")
}
if (typeof callback !== 'function') {
throw new Error(callback+"is not a function")
}
let o = Object(this) // this represents an array
let len = o.length >>> 0 // unsigned right shift
let k = 0
while (k < len) {
if (k in o) {
callback.call(thisArgs,o[k],k,o)
}
k++
}
}
o. What is length > > > 0? It's an unsigned right shift of 0 bits. What's the point? This is to ensure that the converted value is a positive integer
In fact, the bottom layer has two layers of conversion. The first is to convert non number into number type, and the second is to convert number into Uint32 type
Implement map Method
Returns a new array according to the callback function
Array.prototype.map2 = function(callback,thisArgs) {
if (this === null) {
throw new Error("this is null or not defined")
}
if (typeof callback !== 'function') {
throw new Error(callback +"is not a function")
}
const o = Object(this) // this represents an array
let len = o.length >>> 0 // unsigned right shift
let k = 0
let res = []
while (k < len) {
if (k in o) {
res[k] = callback.call(thisArgs,o[k],k,o)
}
k++
}
return res
}
The returned result of map is a new array, so the last return is res; In the parameters of map, the last formal parameter represents the array itself, so the formal parameter value is o
Implement some method
The some method of the array returns true as long as one of the values in the array meets the conditions; Otherwise, false is returned
Array.prototype.some2 = function(callback,thisArgs) {
if (this === null) {
throw new Error("this is null or not defined")
}
if (typeof callback !== 'function') {
throw new Error(callback+"is not a function")
}
const o = Object(this) // this represents an array
const len = o.length >>> 0 // unsigned right shift
let k = 0
while (k < len) {
if (k in o) {
if (callback.call(thisArgs,o[k],k,o)) return true
}
k++
}
return false
}
Implement filter method
filter method of array: put the qualified values into a new array and return
Array.prototype.filter2 = function(callback,thisArgs) {
if (this === null) {
throw new Error("this is null or not defined")
}
if (typeof callback !== 'function') {
throw new Error(callback+"is not a function")
}
const o = Object(this) // this represents an array
const len = o.length >>> 0
let k = 0 , res = []
while (k < len) {
if (k in o) {
if (callback.call(thisArgs,o[k],k,o)) {
res.push(o[k])
}
}
k++
}
return res
}
Method of realizing function prototype
Implement bind method
Implement the new keyword
The new operator is used to create instances of user-defined object types or built-in objects with constructors
- An empty object is created, and this variable is introduced into the object. At the same time, it also inherits the prototype of the function
- Set the prototype chain, and the empty object points to the prototype object of the constructor
- Execute the function body, modify the constructor, point to the null object with this pointer, and execute the function body
- Judge the return value and create an object if the returned object does not have one
function objectFactory() {
var obj = new Object() // Create an empty object
Constructor = [].shift.call(arguments)
obj._proto_ = Constructor.prototype // Set prototype chain
var ret = Constructor.apply(this, arguments) // Modify the constructor this pointer to point to an empty object and execute the function body
return typeof ret === 'object' ? ret || obj:obj // Judge the return value and use the object to return the object. If not, create an object
}
Implement the instanceof keyword
instanceof is to judge whether the prototype attribute of the constructor appears on the prototype chain of the instance
function instanceOf(left,right) {
let proto = left._proto_
while (true) {
if (proto === null) return false
if (proto === right.prototype) return true
let proto = proto._proto_
}
}
Promise
Realize promise by handwriting Race() method
Promise.race returns a new instance wrapped by the first fully or rejected instance of all iteratable instances
Promise.race = function(promiseArr) {
return new Promise((resolve, reject) => {
promiseArr.forEach(p => {
Promise.resolve(p).then(val => {
resolve(val)
}, err => {
rejecte(err)
})
})
})
}
Handwritten quick typesetting
Divide and conquer thought
function quickSort(arr) {
if (arr.length <= 1) return arr;
const pivot = arr[arr.length - 1];
let leftArr = [];
let rightArr = [];
for (let el of arr.slice(0, arr.length - 1)) {
el < pivot ? leftArr.push(el) : rightArr.push(el);
}
return [...quickSort(leftArr), pivot, ...quickSort(rightArr)];
}
Structure of tree structured data
Organize the flattened array into a tree structure
const data = [
{
id: 2,
pid: 0,
path: "/course",
name: "Course",
title:"course management"
},
{
id: 3,
name: "CourseOperate",
path: "operate",
linke: "/course/operate",
pid: 2,
title:"Course operation"
},
{
id: 4,
name: "CourseInfoData",
path: "info_data",
link:"/course/operate/info_data",
pid: 3,
title:"Course data"
},
{
id: 5,
name: "CourseAdd",
path: "add",
link: "/course/add",
pid:2,
title:"Add courses"
},
{
id: 6,
pid: 0,
path: '/student',
name: "Student",
title: "Student management",
},
{
id: 7,
name:"StudentOperate",
path: "operate",
link: "/student/operate",
pid: 6,
title:"Student operation"
},
{
id: 8,
name: "StudentAdd",
path: "add",
link: "/student/add",
pid: 6,
title:"Increase students"
}
]
Converted data format:
const data = [
{
id: 2,
pid: 0,
path: "/course",
name: "Course",
title:"course management",
children:[
{
id: 3,
name: "CourseOperate",
path: "operate",
linke: "/course/operate",
pid: 2,
title:"Course operation",
children:[
{
id: 4,
name: "CourseInfoData",
path: "info_data",
link:"/course/operate/info_data",
pid: 3,
title:"Course data"
},
]
},
{
id: 5,
name: "CourseAdd",
path: "add",
link: "/course/add",
pid:2,
title:"Add courses"
},
]
},
{
id: 6,
pid: 0,
path: '/student',
name: "Student",
title: "Student management",
children:[
{
id: 7,
name:"StudentOperate",
path: "operate",
link: "/student/operate",
pid: 6,
title:"Student operation"
},
{
id: 8,
name: "StudentAdd",
path: "add",
link: "/student/add",
pid: 6,
title:"Increase students"
}
]
},
]
Conversion ideas:
- Distinguish between parents and children elements
- Traverse to find the element of c.pid === p.id
- Recursively find c.pid === p.id in children
function formDataTree(data) {
// Separated parent-child structure
let parents = data.filter(p => p.pid === 0)
let children = data.filter(c => c.pid !== 0)
let dataToTree = (parents, children) => {
parents.map(p => {
children.map((c,i) => {
if (p.id === c.pid) {
// Process the first layer
if (p.children) {
p.children.push(c)
} else {
p.children = [c]
}
// Recursive processing
let _children = JSON.parse(JSON.stringify(children)) // Deep copy
_children.splice(i,1) // Remove the c current parents from the children
dataToTree([c], _children)
}
})
})
}
// Processing structure
dataToTree(parents, children)
return parents
}
The second solution: non flattening
function formDataTree(data) {
const _data = JSON.parse(JSON.stringify(data))
return _data.filter(p => {
const _arr = _data.filter(c => c.pid === p.id)
if (_arr.length) p.children = _arr
return p.pid === 0 // The return value is the outermost object
})
}
Convert tree structure to array
function treeToData(tree) {
if (!Array.isArray(tree)) throw new Error("Please do not pass in an empty tree")
if (!tree.length) return tree
return tree.reduce((sum, item) => {
if (!item.children || !item.children.length) {
sum.push(item)
} else {
// Recursive children
const mid = treeToData(item.children)
delete item.children
sum.push(item,...mid)
}
return sum
},[])
}
Implement a tree structure filtering function. The format of the tree structure is as follows:
tree = [
{ name: 'A' },
{
name: 'B',
children: [
{ name: "A" },
{name:"AA",children:[...]}
]
},
{name:'C'}
]
Output:
// 1. If str I entered is A, the result returned after filtering is
[
{ name: "A"},
{
name: 'B', children: [name : 'bcde']
{name:'A'}
]}
]
// 2. Assuming that the str I entered is AA, the result returned after filtering is
[
{
name: 'B', children: [
{name:'AA',children:[...]}
]}
]
Problem solving ideas:
function transTree(data,filterName) {
if (!data) return []
// Store return data
let treeData = []
data.filter(item => {
const _item = JSON.parse(JSON.stringify(item))
if (_item.name === filterName) treeData.push(_item)
const children = transTree(_item.children, filterName)
if (children.length) {
_item.children = children
treeData.push(_item)
}
})
return treeData
}
Binary tree
Preorder traversal of binary tree
var preorderTraversal = function(root) {
const res = [];
const preorder = (root) => {
if(!root) return;
res.push(root.val);
preorder(root.left);
preorder(root.right);
}
preorder(root);
return res;
};
Middle order traversal of binary tree
var inorderTraversal = function(root) {
const res = [];
const inorder = (root) =>{
if(!root) return;
inorder(root.left);
res.push(root.val);
inorder(root.right);
}
inorder(root)
return res;
};
Binary Tree Postorder Traversal
var postorderTraversal = function(root) {
const res = [];
const postorder = (root) =>{
if(!root) return;
postorder(root.left);
postorder(root.right);
res.push(root.val);
}
postorder(root);
return res;
};
Sequence traversal of binary tree
var levelOrder = function(root) {
if(!root) return [];
const queue = [root];
const levels = [];
while(queue.length){
const len = queue.length;
const currLevel = [];
for(let i=0;i<len;i++){
const current = queue.shift();
if(current.left){
queue.push(current.left);
}
if(current.right){
queue.push(current.right);
}
currLevel.push(current.val);
}
levels.push(currLevel);
}
return levels;
};
Maximum depth of binary tree
Maximum width of binary tree
Git
What is Git?
git, a distributed version control software, was originally designed to better manage Linux kernel development
The client of distributed version control system not only extracts the file snapshot of the latest version, but also completely mirrors the code warehouse. In this way, if any server for collaborative work fails, it can be recovered with any mirrored local warehouse
Therefore, when implementing team collaboration, as long as a computer acts as a server, everyone else will clone a copy from the "server" warehouse to their own computer, push their own submissions to the server warehouse, and also pull others' submissions from the server warehouse
Git status
Corresponding to the file status, files in different states are in different working areas in Git, which is mainly divided into four parts:
- Work area: it is equivalent to the area where code is written locally. For example, git clone a project to the local, which is equivalent to cloning a copy of the remote warehouse project locally
- Staging area: the staging area is a file that holds the list of files to be submitted next time. It is generally in the Git warehouse directory
- Local warehouse: submit the update, find the files in the staging area, and permanently store the snapshot in Git local warehouse
- Remote warehouse: remote warehouse, such as github
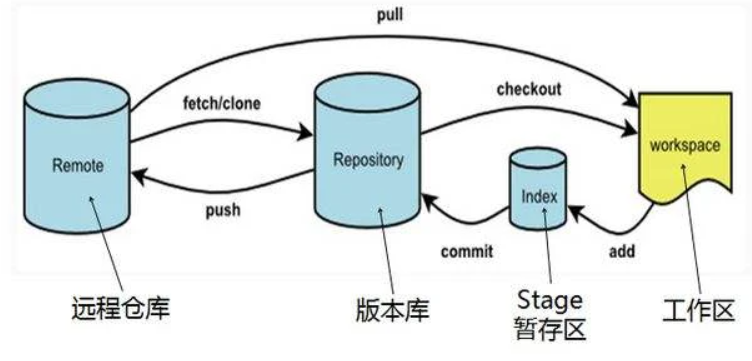
Git command
- add
- commit
- push
- pull
- clone
- checkout
Usage scenarios in git work
The two branches are master and dev
Project start execution process
View all branches git branch -a
Clone address git clone address
Pull the latest code of online master git pull origin master
Switch to the development branch git checkout dev
Merge master local branch git merge master
Start development
End development
View the current file change status git status
Put all the changed code into the cache git add
View the current file change status git status
Add cache contents to the warehouse git commit -m 'comment on this change'
Transfer the code to gitLab git push origin dev
If the code reaches the online standard, merge the code to the master and switch to the master: git checkout master
Pull the latest branch of Master: git pull origin master
Merge branch codes to master git push origin master
After the code goes online, mark the release node with tag tag (naming rule: prod_ + version + online date) git tag - a prod_ V2. 1.8_ twenty million two hundred and eleven thousand and nine
git rebase & git merge
Ajax
What is the implementation process of Ajax?
- To create an XMLHTTPRequest object is to create an asynchronous call object
- Create a new HTTP request and specify the method, URL and authentication information of the HTTP request
- Set the function to respond to the status change of HTTP request
- Send HTTP request
- Get the data returned by asynchronous call
- Local refresh using JavaScript and DOM
What are the data types received by Ajax and how to deal with the data?
Type of data received:
JS object, JSON string
How to process data:
- String to object
(1) eval()
const str = '{"name":"smy","age":23,"team":"HII"}'
console.log(eval('(' + str + ')'))
(2) JSON.parse()
JSON. The difference between parse() and eval()
The eval() method does not check whether the given string conforms to the JSON format
If js code exists in the given string, eval() will also be executed
- Object to string
JSON.stringify()
The difference between Get and Post
difference:
- GET uses URL or Cookie to pass parameters, while POST puts data in the Body
- The URL of GET is limited in length, while the data of POST can be very large
- POST is safer than GET because the data is not visible in the address bar
The most essential difference
GET is usually used to GET data from the server, while POST is usually used to pass data to the server
GET/POST usage scenario
Using the post method:
- The result of the request has a continuous function, such as adding a new data row to the database
- If you use the get method, the data collected on the form may make the URL too long
- The data to be transmitted is not ASCII encoded
Use the GET method:
- The request is to find resources, and the HTML form data is only used for searching
- The request result has no persistent side effects
- The total length of the collected data and the name of the input field in the htm form shall not exceed 1024 characters
What is cross domain request
The so-called cross domain request refers to when the domain initiating the request is inconsistent with the domain of the resource pointed to by the request. All domains here are the total of protocol, domain name and port number. The same domain is the same protocol, domain name and port number. Any difference is cross domain.
What are cross domain requests
Homologous strategy
Homology policy is the core security policy of the browser. In order to defend against illegal attacks, homology means that the domain name, port and protocol of the browser are the same.
Why cross domain requests
With the emergence of specialization, many professional information service providers provide various interfaces for front-end developers. In this case, cross domain requests are required. Many of these front-end interface services use cors methods to solve cross domain problems.
Another kind of situation is that in projects with front-end and back-end separation, the front-end and back-end belong to different services. The cross domain problem exists when this architecture is adopted. And now many projects adopt this way of separation. Many of these projects will use the way of reverse proxy to solve cross domain problems.
Cross domain request solution
Modify browser security settings (not recommended)
JSONP
JSONP is a usage mode of JSON, which can be used to solve the problem of cross domain data access of mainstream browsers
Principle: the src attribute of script tag is not limited by the homology policy. All the attributes of the server are not restricted by the same source server href and src.
Steps:
(1) Create a script tag
(2) The src property of script sets the interface address
(3) Interface parameters must have a user-defined function name, otherwise the background cannot return data
(4) Receive the background return data by defining the function name
<script>
window.callback = function (data) {
console.log("data", data);
};
</script>
<script src="http://localhost:8000/jsonp.js"></script>
callback({
name:"smy"
})
Cross origin resource sharing (CORS)
CORS is the new W3C standard
Principle: after the server sets the access control allow origin HTTP response header, the browser will allow cross domain requests
Limitation: the browser needs to support HTML5, POST, PUT and other methods. It is compatible with ie9 and needs to be set in the background
Access-Control-Allow-Origin: * // Allow access to all domain names Access-Control-Allow-Origin: HTTP://a.com / / only allow access to all domain names
Advantages and disadvantages compared with jsonp:
CORS has obvious advantages compared with jsonp. Jsonp only supports GET, which has many limitations, and jsonp does not conform to the normal process of processing business. Using CORS, the front-end coding is no different from normal non cross domain requests. At present, many services use CORS to solve cross domain problems
iframe (not recommended)
Reverse proxy
Since cross domain requests cannot be made, we can not cross domain requests. By deploying a service before the request arrives at the service, the interface request is forwarded, which is called reverse proxy. Through certain forwarding rules, the front-end requests can be forwarded to other services. Take Nginx as an example
server {
listen 9999
server_name localhost
# Forward all requests starting with localhost:9999/api
location ^~/api{
proxy_pass http://localhost:3000;
}
}
Through reverse proxy, we unify the front-end and back-end projects to provide external services through reverse proxy, so that the front-end looks like there is no cross domain
The trouble with reverse proxy lies in the original configuration of reverse proxy services such as Nginx. At present, many projects with front and back-end separation adopt this method.
What is axios?
axios is a promise based http library that can be used in browsers and node JS
What are the features of axios?
- Create XMLHttpRequests from the browser
- From node JS create http request
- Promise API supported
- Intercept requests and responses
- Convert request data and response data
- Cancel request
- Automatically convert JSON data
- XSRF client support
Concurrent parallel synchronous asynchronous
Concurrency & parallelism
It means that the computer can perform multiple tasks at the same time. There are many different forms of how the computer can achieve "concurrency";
Concurrent
For example, for a single core processor, the computer can allocate time slices; Let one task run an event, and then switch another task to run for a period of time. Different tasks will be executed alternately and repeatedly. This process is also called context switching for processes or threads
parallel
For multi-core processors, we can actually execute tasks in parallel on different cores without allocating time slices. This situation is called parallelism
Synchronous & asynchronous
synchronization
The synchronization representative must wait until the previous task is executed before proceeding to the next task; Therefore, there is no concept of concurrency and parallelism in synchronization
asynchronous
Different tasks do not wait for each other. When executing task a, they do not wait until the end of a's execution before executing B. A typical way to realize asynchrony is to create multiple threads and start them through multi-threaded programming. In a multi-core environment, each thread will be assigned to an independent core to run, so as to realize real parallelism;
Concurrency in JavaScript
JavaScript itself does not have the concept of multithreading, but it can still achieve "concurrency" of single thread through its function callback mechanism. For example, multiple network resources can be accessed simultaneously through fetch(). When the fetch function is executed, the thread will not wait, but continue to execute downward. It will be displayed only after the request result is returned.
**Note: * * although the main program and callback function seem to be performed at the same time, they still exist in only one main thread
**Asynchronous tasks: * * WebSocket, setTimeout, setInterval, XMLHttpRequest, fetch, Promise, async function, queueMicrotask
Multithreaded programming vs asynchronous programming
**Asynchronous programming: * * I/O-Intensive applications, such as web applications, often perform network operations and database access
**Multithreaded programming: * * computing intensive applications, such as video image processing, scientific computing and so on
ES6 modularization
Benefits of modularity
Modularity can avoid the problem of naming conflicts
Everyone follows the same modular specification to write code, which reduces the cost of communication and greatly facilitates the mutual call between various modules
You only need to care about the function development of the current module itself. When you need the support of other modules, you can call the target module in the module
Specification definition of ES6 modularization
Each js file is a separate module
Export keyword for export module
Import keyword is used to import other modules (import and export can only be at the top of the code and cannot be written in the code)
Promise
Promise is a solution to asynchronous programming. It expresses asynchronous operations in the process of synchronous operations, avoiding nested callback functions. It is generated to solve the problem of asynchronous processing callback hell (that is, circular nesting)
The promise constructor contains a parameter and a callback with two parameters resolve and reject. Perform some operations in the callback. If everything is normal, use resolve, otherwise call reject. Promise. Can be called for the promise object that has been instantiated then() method, passing the resolve and reject methods as callbacks. The then() method accepts two parameters: onResolve and onReject, which respectively represent the success or failure of the current promise object
Callback hell
In JS or node, a large number of callback functions are used for asynchronous operations, and the time when asynchronous operations return results is uncontrollable. If we want several asynchronous requests to be executed in order, we need to nest these asynchronous operations. There are many layers of nesting, which will form a callback hell or horizontal pyramid.
Write a promise
let p = new Promise((resolve, reject) => {
if (operation failed) {
reject(err);
} else {
resolve(data);
}
})
p.then(res => {
console.log(res);
}).catch(err => {
console.log(err);
})
Whether the Promise constructor is executed synchronously or asynchronously, what about the then method?
The promise constructor is executed synchronously, and the then method is executed asynchronously
What is the difference between reject and catch in Promise
reject is used to throw exceptions and catch is used to handle exceptions
reject is the Promise method, and catch is the Promise instance method
After reject, it will enter the second callback in then. If there is no second callback in then, it will enter catch
Network exceptions (such as network disconnection) will directly enter the catch instead of the second callback of then
Three states of promise
In the initial state, the result of promise is undefined
When resolve(value) is called, one of the final states is reached, and the result value can be obtained at this time
When reject(value) is called, it reaches one of the final states, and rejected can get the error information
When the final completed or rejected result is reached, the state of promise will not change any more
Chain call of then method
The string returned in the previous then will be received by the next then method
The promise object returned from the previous then, and the data is passed when calling resolve, and the data will be received by the next then
If resolve is not called in the previous then, the subsequent then will not receive any value
import fs from "fs";
function readFiles(path) {
return new Promise((resolve, reject) => {
fs.readFile(path,'utf-8' ,(err, data) => {
err ? reject(err) : resolve(data);
})
})
}
let p1 = readFiles('./file/a.txt');
let p2 = readFiles("./file/b.txt")
let p3 = readFiles("./file/c.txt");
p1.then(r1 => {
console.log(r1);
return p2;
}).then(r2 => {
console.log(r2);
return p3;
}).then(r3 => {
console.log(r3);
})
Promise method
graph LR A[Promise] --->B[promise.all] A ---> C[promise.race] A ---> D[promise.any]
Promise.all
Promise.all can wrap multiple promise instances into a new promise instance. At the same time, the return values of success and failure are different. When successful, it returns a result array, while when failed, it returns the value of the first reject ed failure state
In case of failure, the value of the first reject ed failure status is returned
let p1 = Promise.resolve('aaa')
let p2 = Promise.resolve('bbb')
let p3 = Promise.reject('ccc')
let p4 = Promise.resolve('ddd')
Promise.all([p1, p2, p3, p4]).then(res => {
console.log(res); //Return array
}).catch(err => {
console.log(err);
})
ccc
When the array succeeds, it returns a result
let p1 = Promise.resolve('aaa')
let p2 = Promise.resolve('bbb')
let p3 = Promise.resolve('ccc')
let p4 = Promise.resolve('ddd')
Promise.all([p1, p2, p3, p4]).then(res => {
console.log(res); //Return array
}).catch(err => {
console.log(err);
})
[ 'aaa', 'bbb', 'ccc', 'ddd' ]
Promise.race
Promise.race means race, which means promise The results in race ([P1, P2, P3, P4]) will be returned as soon as they are obtained, regardless of whether the result itself is successful or failed
let p1 = Promise.resolve('aaa')
let p2 = Promise.resolve('bbb')
let p3 = Promise.resolve('ccc')
let p4 = Promise.resolve('ddd')
Promise.race([p1, p2, p3, p4]).then(res => {
console.log(res);
}).catch(err => {
console.log(err);
})
Promise.any
Promise.any() receives a promise iteratable object. As long as one of the promises is successful, it will return the successful promise
async and await
await and async keywords can return the result of asynchronous request to us in the form of return value
async returns a promise. If promise does not return, it will be automatically wrapped in a promise with its value in resolve
Await operator is used to wait for promise and can only be used in async block; The keyword await causes JavaScript to wait until promise returns a result. It should be noted that it only makes the async function block wait, not the whole program execution
async and await are mainly used to avoid promise Then chained expression
graph LR A[async Three cases]--->B[async + promise object] A--->C[async + num] A--->D[async + The return value is promise Function of object]
Executing async function returns promise objects
async function test1() {
return 1;
}
function test2() {
return Promise.resolve(2);
}
const result1 = test1();
const result2 = test2();
console.log("result1", result1);
console.log("result2", result2);
promise.then success corresponds to await
async function test3() {
const p3 = Promise.resolve(3);
p3.then((res) => {
console.log("res" + res);
})
const data = await p3;
console.log("data" + data);
}
test3()
await num can be automatically encapsulated into promise resolve(num)
async function test4() {
const data4 = await 4; // Promise.resolve(4)
console.log("data4", data4);
}
test4();
await can be followed by async function
async function test1() {
return 1;
}
async function test5() {
const data5 = await test1(); //The return value of test1() is a promise object
console.log("data5", data cvbx5);
}
test5(); //The output is 1
Promise. The exception of catch corresponds to try... Catch
async function test6() {
const p6 = Promise.reject(6);
try {
const data6 = await p6;
} catch (e) {
console.log("error", e);
}
}
test6();
Sequential execution of asynchronous functions
(1)
async function test1() {
console.log('test1 begin'); //2
const result = await test2(); //3. Execute test2 () on the right first - > test2
console.log("result",result); //4 the test2() function has no return, so the return value is undefined
console.log("test1 end"); // 5
}
async function test2(){
console.log("test2");
}
console.log("script begin"); //1
test1(); //2
console.log("script end"); //3
analysis
await ===> Promise. Then () is a micro task. After await is executed, it directly jumps out of async function and executes other code. After other code is executed, it returns to async function to execute the remaining code, and then registers the code behind await in the micro task queue.
result
script begin test1 begin test2 script end result undefined test1 end
(2)
console.log('script start')
async function async1() {
await async2()
console.log('async1 end')
}
async function async2() {
console.log('async2 end')
}
async1()
setTimeout(function() {
console.log('setTimeout')
}, 0)
new Promise(resolve => {
console.log('Promise')
resolve()
})
.then(function() {
console.log('promise1')
})
.then(function() {
console.log('promise2')
})
console.log('script end')
analysis
Execute the code and output script start.
Executing async1() will call async2() and then output async2 end. At this time, the context of async1 function will be preserved, and then the async1 function will jump out.
When setTimeout is encountered, a macro task is generated
Execute Promise and output Promise. Encounter then and generate the first micro task
Continue to execute the code and output script end
After the code logic is executed (the current macro task is executed), start to execute the micro task queue generated by the current macro task and output promise 1. The micro task encounters then and generates a new micro task
Execute the generated micro task and output promise2. The current micro task queue is completed. Executive power back to async1
Executing await will actually produce a promise return, that is
let promise_ = new Promise((resolve,reject){ resolve(undefined)})
result
script start async2 end Promise script end async1 end promise1 promise2 setTimeout
Event Loop
JavaScript is a single threaded language. Its synchronous and asynchronous operations are realized through event loop
All synchronized tasks will be executed on the main thread to form an execution stack, call stack, put macros into task Queue and micro tasks into Microtask Queue; When the call stack is empty, check the event loop in the Queue, first check the Microtask Queue, and then check the task Queue; If the callback queue is empty, continue to check; When the callback queue is not empty, take out the first task and put it into the call stack for execution; This cycle.
Macro task and micro task
Micro tasks are executed earlier than macro tasks
Macro task: setTimeout, setInterval, DOM event, AJAX request (script, setTimeout, setInterval, setImmediate, I/O, UI rendering)
Micro task: Promise, async/await (promise, Object.observe, MutationObserversda)
Event Loop interview questions
console.log(1)
setTimeout(function() {
console.log(2)
}, 0)
const p = new Promise((resolve, reject) => {
resolve(1000)
})
p.then(data => {
console.log(data)
})
console.log(3)
result
1 3 1000 2
2
console.log(1)
setTimeout(function() {
console.log(2)
new Promise(function(resolve) {
console.log(3)
resolve()
}).then(function() {
console.log(4)
})
})
new Promise(function(resolve) {
console.log(5)
resolve()
}).then(function() {
console.log(6)
})
setTimeout(function() {
console.log(7)
new Promise(function(resolve) {
console.log(8)
resolve()
}).then(function() {
console.log(9)
})
})
console.log(10)
result
1 5 10 6 2 3 4 7 8 9
3
console.log(1)
setTimeout(function() {
console.log(2)
}, 0)
const p = new Promise((resolve, reject) => {
console.log(3)
resolve(1000) // Mark as successful
console.log(4)
})
p.then(data => {
console.log(data)
})
console.log(5)
result
1 3 4 5 1000 2
4
new Promise((resolve, reject) => {
resolve(1)
new Promise((resolve, reject) => {
resolve(2)
}).then(data => {
console.log(data)
})
}).then(data => {
console.log(data)
})
console.log(3)
result
Analyze: nested Promise executes the inside first
3 2 1
5
setTimeout(() => {
console.log(1)
}, 0)
new Promise((resolve, reject) => {
console.log(2)
resolve('p1')
new Promise((resolve, reject) => {
console.log(3)
setTimeout(() => {
resolve('setTimeout2')
console.log(4)
}, 0)
resolve('p2')
}).then(data => {
console.log(data)
})
setTimeout(() => {
resolve('setTimeout1')
console.log(5)
}, 0)
}).then(data => {
console.log(data)
})
console.log(6)
result
Execute from top to bottom, and setTimeout is a macro task, which is queued in the task queue; Nested relation, execute the nested relation first
2 3 6 p2 p1 1 4 5
6
<script>
console.log(1);
async function fnOne() {
console.log(2);
await fnTwo(); // The right combination executes the code on the right first, and then waits
console.log(3);
}
async function fnTwo() {
console.log(4);
}
fnOne();
setTimeout(() => {
console.log(5);
}, 2000);
let p = new Promise((resolve, reject) => { // The function in new Promise() will execute all code immediately
console.log(6);
resolve();
console.log(7);
})
setTimeout(() => {
console.log(8)
}, 0)
p.then(() => {
console.log(9);
})
console.log(10);
</script>
<script>
console.log(11);
setTimeout(() => {
console.log(12);
let p = new Promise((resolve) => {
resolve(13);
})
p.then(res => {
console.log(res);
})
console.log(15);
}, 0)
console.log(14);
</script>
analysis:
First cycle: 1 2 6 7 10 macro task: script timer 2 timer 0 micro task: 3 9
End of the first cycle: 1 2 6 7 10 3 9
Second cycle (script): 11 14 macro task timer 2 timer 0 timer 0 micro task:
Third cycle (first timer 0): 8
Fourth cycle (second timer 0): 12 15 13
Fifth cycle (timer 2): 5
result
1 2 6 7 10 3 9 11 14 8 12 15 13 5
be careful:
- Function does not call or execute
- await === then belongs to micro task
Front end Engineering
What is front end engineering?
Front end engineering refers to standardizing and standardizing the tools, technologies, processes and experience required for front-end development in the development of enterprise level front-end projects
Characteristics of front-end engineering
Modularization (js modularization, css modularization, resource modularization)
Componentization (reuse existing UI structure, style and behavior)
Standardization (division of directory structure, coding standardization, interface standardization, document planning standard, Git Branch Management)
Automation (automated build, automated deployment, automated testing)
What is Babel's principle
Babel's main work is to translate the code (solve compatibility, parse and execute part of the code)
let a = 1 + 1 => var a = 2
Translation is divided into three stages:
- Parse: parse the code to generate an abstract syntax tree AST, that is, the process of lexical analysis and syntax analysis
- Transform, a series of operations on the transformation of the syntax tree. Through Babel traverse, traverse and add, update, delete and other operations
- Generate: convert the transformed AST into js code through Babel generator
Webpack
What is webpack?
webpack is a specific solution for front-end project engineering
It provides friendly front-end modular development support, as well as powerful functions such as code compression and confusion, handling browser-side JavaScript compatibility, performance optimization and so on.
Advantages of webpack
Let programmers focus on the realization of specific functions, which improves the efficiency of front-end development and the maintainability of the project.
What is the construction process of webpack?
- Initialization parameters: combine parameters from shell parameters and configuration files to get the final parameters
- Start compilation: initialize the compiler object from the parameters obtained in the previous step, load all loader plug-ins, and perform compilation through the run method
- Determine entry: find all entry files according to the entry of the configuration file
- Compiling module: starting from the entry file, call all configured loader s to translate the module into compilation, then recurse all dependent modules, and then recompile. Get the final translated content of each module and the dependencies between them
- Output resources: according to the dependency between entries and modules, assemble chunks containing multiple modules, and then convert the chunks into an independent file to be added to the output list. This is the last chance to modify the output content
- Output completion: after determining the output content, determine the output path and file name according to the configuration, and write the content of the file to the file system.
Hot update principle of webpack
- Basic definition: the hot update of webpack is also called hot module replacement, abbreviated as HMR. This mechanism can replace the old module with the new one without refreshing the browser.
- Core definition
The core of HMR is that the client pulls the updated file from the server. In fact, a websocket is maintained between WDS and the browser. When the local resource changes, WDS will push the update to the browser and bring the hash during construction to compare the client with the last resource
After comparing the differences, the client will send an Ajax request to WDS to obtain the changed contents (file list and hash), so that the client can send a JSON request to WDS to obtain the incremental update of the chunk with the help of this information
The subsequent part is completed by HotModulePlugin, which provides relevant APIs for developers to deal with their own scenarios. For example, react hot loader and Vue loader use these APIs to realize HMR
How to use webpack to optimize front-end performance
- Compressed code, uglifyJsPlugin compressed js code, mini css extract plugin compressed css code
- Using CDN acceleration, modify the referenced static resources to the corresponding path on the CDN. You can use the output parameter of webpack and the publicpath parameter of loader to modify the resource path
- To delete the dead code tree shaking, css needs to use purify css
- Extract public code, remove Commons chunkplugin from webpack4, and use optimization Splitchunks and optimization Runtimechunk instead
Vue interview questions
Advantages and disadvantages of Vue
advantage
- vue has two characteristics: responsive programming and componentization
- vue's advantages: lightweight framework, easy to learn, two-way data binding, componentization, separation of data and structure, virtual DOM and fast running speed
- vue is a single page application, which makes the page refresh locally. It doesn't need to request all data and dom every time you jump to the page, which greatly speeds up the access speed and improves the user experience. Moreover, its third-party ui library saves a lot of development time
Disadvantages:
- Vue does not lack introductory tutorials, but it lacks high-level tutorials and documents
- Vue does not support IE8
- The ecological environment is not as good as react and angular
- Small community
Use Vue to realize style binding. You can use class or inline style, and write at least 2?
<!-- First binding class -->
<div :class="['classA','classB']"></div>
<!-- Second binding class -->
<div :class="{'classA' : true, 'classB' : false}"></div>
<!-- First binding style -->
<div :style="{fontSize : '16px', color : 'red' }"></div>
<!-- Second binding style -->
<div :style="[{fontSize : '16px' , color : 'red' }]"></div>
Routing implementation of Vue
It is realized through the hook function of Vue router
How many navigation hooks does Vue router have?
- Global guard router beforeEach
- Global resolution guard: router beforeResolve
- Global post hook: router afterEach
- Route exclusive guard: beforeEnter
- Guards in components: beforerouteenter / beforerouteupdate (new in 2.2) / beforeRouteLeave
What are the hook functions of Vue router?
Hook functions in Vue router are mainly divided into three categories:
-
Global hook function beforeEach
The three parameters of beforeEach are:
To - the routing object that the router is about to enter
from - the route that the current navigation is about to leave
next - function, a hook in the pipeline. If the execution is completed, the navigation status is confirmed. Otherwise, it is FALSE, and the navigation is terminated
-
Individual routing and exclusive components
beforeEnter
-
Component inner hook
beforeRouterEnter
beforeRouterUpdate
beforeRouterLeave
Vue.route and Vue What's the difference between router?
$router is an instance of $vueroter. It is a routing operation object. It only writes objects. If you want to navigate to different URL s, use router Push method
$route refers to the jump object, routing information object and read-only object of the current route, which can obtain name,path,query,params, etc
Execution sequence of parent-child component creation and destruction in Vue
Load Render Pass
father beforeCreate -> father created -> father beforeMount -> son beforeCreate -> son created -> son beforeMount -> son mounted -> father mounted
Sub component update process
father beforeUpdate -> son beforeUpdate -> son updated -> father updated
Parent component update process
father beforeUpdate -> father updated
Destruction process
father beforeDestroy -> son beforeDestroy -> son destroyed -> father destroyed
The difference between front-end routing and back-end routing
What is routing?
Routing is to display different contents or pages according to different url addresses;
Front end routing
A very important point is that the page is not refreshed. The front-end routing is to hand over the tasks of different content or pages corresponding to different routes to the front-end. Each hop to a different url uses the anchor routing of the front-end
advantage
- The user experience is good. It has nothing to do with the background network speed. You don't need to get it all from the server every time and quickly show it to users
- You can specify the url and routing address you want to access in the browser
- It realizes the separation of front and rear ends, which is convenient for development
shortcoming
- When using the forward and backward keys of the browser, the request will be sent again, and the cache is not used reasonably
- A single page cannot remember the previous scrolling position, and cannot remember the scrolling position when moving forward and backward
Back end routing
When the browser switches different URLs in the address bar, it sends a request to the background server every time. The server responds to the request, splices HTML files in the background, transmits them to the front-end display, and returns different pages, which means that the browser will refresh the page. If the Internet speed is too slow, there may be new content on the screen. Another big problem with back-end routing is that the front and back ends are not separated
advantage:
- It shares the pressure of the front end. The splicing of HTML and data is completed by the server
Disadvantages:
- When the project is very large, it increases the pressure on the server side. At the same time, the specified url path cannot be entered in the browser section to access the specified module. The other is that if the current network speed is too slow, it will delay the loading of the page, which is not very friendly to the user experience
Usage of $refs and $el
ref has three uses:
- Add ref to ordinary elements and use this$ Ref.name gets the dom element
- ref is added to the sub component and this is used$ ref.name obtains the component instance and can use all methods of the component
- How to use v-for and ref to get a set of arrays or dom nodes
<ul>
<li v-for = "item in people" ref = "refContent">{{ item }}</li>
</ul>
<script>
data:{
people:['smy', 'lje', 'wy', 'zsy', 'zx']
},
created : function(){
this.$nextTick(()=>{
console.log(this.$refs.reContent)
})
}
</script>
vm.$el
Get the DOM element associated with the Vue instance;
For example, if you want to get the custom component tabControl and its OffsetTop, you need to get the component first
Set the attribute ref = 'a name (tabControl2)' in the component, and then this$ refs. Tabcontrol2, you get the component
To obtain the OffsetTop, the component is not a DOM element, and there is no OffsetTop. It cannot be obtained through OffsetTop, so you need to obtain the DOM element in the component through $el:
this.tabOffsetTop = this.$refs.tabControl2.$el.offsetTop
Common modifiers for vue
. stop - used to prevent event bubbling
. prvent - block default behavior
. once - the event handler executes only once
keydown.enter - identifies whether the user has pressed enter
keydown.esc - identifies whether the user has pressed the esc key
Differences between v-if and v-show in vue and their usage scenarios
difference
- Means: v-if controls the display and hiding of elements by controlling the existence of DOM nodes; v-show sets the display style of DOM elements. block is displayed and none is hidden;
- Compilation process: v-if switching has a local compilation / unloading process. In the switching process, the internal event monitoring and sub components are properly destroyed and rebuilt; v-show is just a simple css based switch;
- Compilation condition: v-if is inert. If the initial condition is false, do nothing; Local compilation starts only when the condition becomes true for the first time; v-show is compiled under any condition (whether the first condition is true or not) and then cached, and the DOM elements are retained
- Performance consumption: v-if has higher switching consumption; v-show has higher initial rendering consumption;
Usage scenario
Based on the above differences, it is better to use v-show if you need to switch very frequently; If the conditions rarely change at run time, it is better to use v-if
Why avoid using v-if and v-for together
v-if and v-for are used together. The priority of v-for is higher than that of v-if. Cycle first and then control the display and hiding
- To filter items in a list (e.g. v-for = "user in users" v-if = "user.isActive"). In this case, replace users with a calculated attribute (such as activeUsers) to return the filtered list.
- To avoid rendering lists that should have been hidden (such as v-for = "user in users" v-if = "shouldShowUsers"). In this case, move the v-if to the container element (such as ul, ol)
What is the reason why the data value of the variable in Vue data changes and the interface is not updated (the two-way binding of Vue data fails)
There are no attributes and values in the data object, and the getter/setter function cannot monitor the data changes of attribute values, which will lead to such problems.
Solution: this$ set(obj,key,value)
How do Vue components transfer values
Parent to child - > props definition variable - > parent in use component passes value to props variable with attribute
The child triggers the parent's event to the parent - > $emit - > the parent is using the method of @ custom event name = parent (the child brings out the value)
Sibling component value transfer:
- Introduce a third-party new Vue and define it as eventBus
import Vue from 'vue' const eventBus = new Vue() export default eventBus
- Subscribe to the method eventbus. created in the component$ On ('custom event name ', method name in methods)
<script>
import eventBus from "./event-bus"
methods:{
add(){
eventBus.$emit('addItem',this.title)
}
}
</script>
- Write a function in the methods of another sibling component, and publish the method eventBus.com of eventBus subscription in the function$ Emit ('custom event name ')
<script>
import eventBus from "./event-bus"
export default{
methods:{
handleAddTitle(title){
console.log('title',title)
}
}
mounted(){
eventBus.$on('addItem',this.handleAddTitle)
}
}
</script>
- Bind events (such as click) in the template of the component
Why must Vue component data be a function
-
Each component is an instance of vue
-
Components share data attributes. When the value of data is the value of the same reference type, changing one of them will affect others
-
Each component will create a copy of data in the form of data, which is similar to the data of each instance in the component definition space. In this way, each component will return a copy of data in the form of data. If it is simply written in the form of an object, all component instances share a copy of data, which will cause a change and all will become results.
What is virtual DOM?
Virtual DOM is actually a tree based on JavaScript objects (VNode nodes), which uses object attributes to describe nodes. In fact, it is just a layer of abstraction of real dom. Finally, the tree can be mapped to the real DOM through a series of operations.
Real DOM mapping to virtual DOM example
Real DOM
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>
Virtual DOM
var element = {
tagName: 'ul', // Node label name
props: { // DOM properties, using an object to store key value pairs
id: 'list'
},
children: [ // Child nodes of this node
{tagName: 'li', props: {class: 'item'}, children: ["Item 1"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 2"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 3"]},
]
}
Why do I need virtual DOM
Cross platform
Because the virtual DOM is based on JavaScript objects and does not depend on the real platform environment, it has the ability of cross platform, such as browser platform, Node, etc
We can put DOM comparison operation in JS layer to improve efficiency. Because the execution speed of DOM operations is far less than that of Javascript, a large number of DOM operations are carried into Javascript, and the patching algorithm is used to calculate the nodes that really need to be updated, so as to minimize DOM operations and significantly improve performance.
Improve rendering performance
The advantage of virtual DOM is not a single operation, but that it can update the view reasonably and efficiently under a large number of frequent data updates
Diff algorithm
When the old and new virtual DOM S change, diff algorithm is used to compare them
diff algorithm in Vue
- Only compare the same layer without cross layer comparison
- When there are different tag names, delete them directly and do not continue to compare
- If the tag name is the same and the key is the same, it is considered to be the same node and no depth comparison is performed
This greatly improves the performance. When there are n nodes, only n comparisons are made, and the time complexity is O(n)
key in Vue
- key will be used in the virtual DOM algorithm (diff algorithm) to identify old and new nodes
- When there is no key, the change of elements will be minimized, and the same elements will be used as much as possible (local reuse)
- When the keys are multiplexed, they will be arranged based on the same key
- The key can also trigger the transition effect and trigger the life cycle of components
Vue2.x responsive principle (data bidirectional binding principle)
Vue.js adopts data hijacking combined with publisher subscriber mode through object Defineproperty () hijacks setter s and getter s of various properties, publishes messages to subscribers when data changes, and triggers corresponding listening callbacks.
How to realize bidirectional data binding
let obj = {};
Object.defineProperty(obj, "name", {
set(newVal) {
// The function automatically called when we set the name attribute
// And the latest value of the attribute will be passed in as an argument
console.log("The new value of the object name property is", newVal);
},
get() {
// The method automatically called when we access the name attribute
// And the return value of the get function is the value you get
console.log("You just visited obj of name attribute");
return "pink";
},
});
Solve the linkage problem between get and set
Use intermediate variables
let obj = {};
let _name = "smy";
Object.defineProperty(obj, "name", {
set(newVal) {
console.log("The new value of the object name property is", newVal);
_name = newVal;
},
get() {
console.log("You just visited obj of name attribute");
return _name;
},
});
Hijacking and conversion of object (set every attribute in the object to responsive)
// You can access the properties of each variable
let obj = {
name: "smy",
age: 23,
team: "HII",
location: "Shanghai",
};
Object.keys(obj).forEach((key) => {
console.log(key, obj[key]);
// Individual functions become responsive
observe(obj, key, obj[key]); // obj[key] represents the value in the object
});
function observe(obj, key, value) {
Object.defineProperty(obj, key, {
set(newValue) {
console.log("obj The properties of have been modified");
value = newValue;
},
get() {
console.log("obj The properties of are accessed");
return value;
},
});
}
Responsive summary
- The so-called response is actually to intercept the access and setting of data and insert some things we want to do
- There are two ways to implement responsive interception in JavaScript, object Defineproperty method and Proxy object Proxy
- vue2. As long as the data configuration item in X is put into the data, no matter how deep the level is, no matter whether it will be used in the end, the data will be processed recursively and responsively. Therefore, we are required not to add too much redundant data to the data as much as possible
- Need to know vue3 In X, the unprovoked performance consumption of data responsive processing in 2 is solved. The method used is Proxy hijacking object as a whole + inert processing (responsive conversion is carried out only when it is used)
Object. The difference between defineproperty and Proxy
Advantages of Proxy:
- Proxy can listen directly to objects rather than properties
- Proxy can directly monitor the changes of the array
- Proxy has up to 13 interception methods
- Proxy returns a new object. We can only operate on the new object to achieve the purpose, but object Defineproperty can only traverse object properties and modify them directly
- As a new standard, Proxy will be continuously optimized by browser manufacturers, that is, the performance bonus of the legendary new standard
Object. Advantages of defineproperty
- It has good compatibility and supports IE9. However, the Proxy has browser compatibility problems and cannot be polished with polyfill
What is Vuex
vuex is specifically designed for Vue JS provides a state management mode, which adopts centralized storage and management of the state and data of all components, which is convenient to use
What are the five core attributes of Vue?
state/mutations/actions/getters/modules
- state
State is a single state tree, similar to data, where variables that can be accessed by all components are defined
- mutations
The only way to change the state in the store is to submit mutation. The modified syntax is: this$ store. Commit ('variable name '), and there are synchronization operations in mutations
- actions
Action can submit mutation, and store can be executed in action Commit, and there can be any action in the action
The asynchronous operation of the. If we want to use this action in the page, we need to execute store dispatch
- getters
Getters are a bit like Vue JS. When we need to derive some states from the state of the store, that
Then we need to use getter. Getter will receive state as the first parameter, and the return value of getter will be cached according to its dependency. It will be recalculated only when the dependency value in getter (a value in state that needs to derive state) changes
- modules
In fact, module only solves the problem that when the state is very complex and bulky, module can divide the store into modules, and each module has its own state, mutation, action and getter
What problems did Vuex solve
It mainly solves two problems:
- When multiple components depend on the same state, the parameter transfer of multi-layer nested components will be very cumbersome
- Behaviors from different components need to change the same state
What is the difference between Vuex's Mutation and Action
Changes: focus on the modification of state. Theoretically, it is the only way to modify the state value. Must be executed synchronously;
Actions: business code, asynchronous request
Briefly describe the data transfer process of Vuex
-
Via new vuex Store() creates a warehouse. State is the public state. State - > components renders the page
-
Inside the component through this$ store. State attribute to call the state of the public state to render the page
-
When a component needs to modify data, it must follow a one-way data flow through this$ store. Dispatch to trigger the methods in actions
-
Each method in actions will accept an object, which has a commit method to trigger the method in changes
-
The methods in changes are used to modify the data in state. The methods in changes will receive two parameters, one is the state in store, and the other is the parameter to be passed
-
When the method in the changes is executed, the state will change. Because the data of vuex is responsive, the state of the component will also change
How does Vue implement cross domain
- When using Vue cli scaffolding to build projects, proxyTable solves cross domain problems
Open config / index JS add the following code to proxyTable:
proxyTable:{
'/api': { //Use "/ api" instead“ http://f.apiplus.c "
target: 'http://f.apiplus.cn ', / / source address
changeOrigin: true, //change source
pathRewrite: { '^/api': 'http://f.apiplus.cn '/ / path rewriting
}
- Using CORS (cross domain resource sharing)
(1) Front end settings: vue sets axios to allow cross domain carrying of cookies (no cookies by default)
axios.defaults.withCredentials = true;
(2) Backend settings:
- Set in the response header after cross domain request
- Access control allow origin / / is the host address of the request
- Access control allow credentials. When it is set to true, cross domain cookie s are allowed, but access control allow origin cannot be a wildcard*
- Access control allow headers to set the allowed request headers for cross domain requests
- Access control allow methods, which allows cross domain requests
What is the principle of Vue's nextTick?
- Why nextTick
Vue modifies the DOM asynchronously and does not encourage developers to contact the DOM directly, but sometimes the business needs to change the data - the refreshed DOM will be processed accordingly. At this time, Vue can be used Nexttick (callback) is the api
this.$nextTick(()=>{
// The functions here will be executed after the DOM asynchronous update is completed
})
- Preparation before understanding the principle
First of all, we need to know the two concepts of macro task and micro task in event loop:
(1) Common macro tasks include script, setTimeout, setinterval, setimmediate, I / O, and UI rendering
(2) Common micro tasks are: process nextTick(nodejs), Promise. then(), MutationObserver
- Understand the principle of nextTick
It is the way vue controls DOM update and nextTick callback function to execute successively through asynchronous queue
Life cycle of Vue
Life cycle: the whole process of vue instance from creation to destruction
Hook function is a vue built-in function, which is automatically executed with the life cycle stage of the component. Hook functions include initialization, mount, update and destroy
In what lifecycle are ajax requests typically used
After the component is created, you can initiate an Ajax request in the created lifecycle function to initialize the data
Life cycle process
initialization
- new Vue() - Vue instantiation (the component is also a small Vue instance)
- Init events & lifecycle - initialize events and lifecycle functions
- beforeCreate - the lifecycle hook function is executed
- Init injections & reactivity - Vue adds data and methods internally
- Created - the life cycle hook function is executed and the instance is created
- The next step is the compile template phase - start analysis
- Has el option? - Is there an EL option - check where to hang
No, call the $mount() method
Yes, continue to check the template option
Question
What hook functions do Vue instances perform from creation to compilation of templates? beforeCreate / created
Can the created function trigger get data? Data can be obtained, but real DOM cannot be obtained
[the external chain picture transfer fails. The source station may have an anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-9od1dyx3-164510523018)( https://cn.vuejs.org/images/lifecycle.png )]
mount
- template option check
Yes - compile the template and return the render rendering function
None - the label corresponding to the compile el option is used as the template
- Before the virtual DOM is mounted into the real DOM
- beforeMount - the lifecycle hook function is executed
- Create... - hang the virtual DOM and the rendered data on the real DOM
- The real DOM is mounted
- mounted - the lifecycle hook function is executed
Question
What hook functions have Vue instances gone through from creation to display?
beforeCreate / created / beforeMount / mounted
Can I get the real DOM in the created function? Cannot get real DOM
In what hook function can I get the real DOM? mounted
to update
- When the data in data changes, before updating DOM
- beforeUpdated - the lifecycle hook function is executed
- Virtual DOM... - re render the virtual DOM and patch it to the real DOM
- updated - the lifecycle hook function is executed
- When data changes - repeat this cycle
Question
When does the updated hook function execute?
When the data changes and the page is updated
Where can I get the updated DOM
In the updated hook function
Destroy
- When $destroy() is called - for example, the component DOM is removed (example v-if)
- beforeDestroy - the lifecycle hook function is executed
- Remove the data monitor, subcomponents, and event listeners
- After the instance is destroyed, a hook function is triggered at last
- destroyed - the lifecycle hook function is executed
Question
What do you usually do in beforeDestroy/destroyed?
Manually eliminate timer / timer / global events
Asynchronous component
Components are rendered on demand. When a component is required to be displayed, asynchronous components are introduced
During component registration, the component is introduced in the form of arrow function
<script>
components:{
TestL: ()=> import("./componnet/Test")
}
</script>
Through this introduction method, on-demand introduction can be realized
Vue2.0 and vue3 Difference between 0
- The change of responsive principle api
Vue2 uses defineProperty as the response principle, while vue3 uses proxy. The former is the permission label for modifying object properties, and the latter is the proxy for the whole object. Proxy will be better in performance
- diff algorithm, rendering algorithm changes
Vue3 optimizes the diff algorithm. Instead of comparing all DOMS like vue2, the method of block tree is adopted. In addition, the re rendering algorithm is also improved, using closures for caching. This makes vue3 six times faster than vue2
- Create data
Here is the biggest difference between Vue2 and Vue3 - Vue2 uses the option type API to compare with Vue3 Composition API. The old option API divides different properties in the code: data, calculated properties, methods, etc. The new composite API allows us to use methods (function s) to split, compared with the old API using attributes to group, so that the code will be simpler and cleaner.
Vue2. Which version of IE is 0 compatible with or above?
It does not support ie8 and below. It is partially compatible with ie9 and fully compatible with more than 10, because the response principle of vue is based on the object of es5 Defineproperty(), which does not support ie8 and below
mixin in Vue
Save the reusable functions or methods in vue project to mixin to realize the function of code reproduction
<script>
import mixin from "./mixin"
export default {
mixins : [mixin]
}
</script>
Benefits of using mixin:
Easier to maintain code
Differences between Vue2 and Vue3 life cycles
Life cycle function of Vue3
<script>
beforeCreate(){
}
created(){
}
beforeMount(){
}
mounted(){
}
beforeUpdate(){
}
beforeUnmount(){
}
unmounted(){
}
</script>
What are the solutions for Vue project optimization?
- Use the mini css extract plugin plug-in to extract css
- Configure optimization to extract the common js code
- Processing file compression through webpack
- The framework and library files are not packaged, but are imported through cdn
- Use base64 for small pictures
- Configuration project file lazy loading
- UI library loading on demand
- Turn on Gzip compression
Tell me about your understanding of SPA single page. What are its advantages and disadvantages?
Single page web application (SPA) is a special web application. It limits all activities to one web page and only loads the corresponding HTML, JavaScript and CSS when the web page is initialized. Once the page is loaded, spa will not reload or jump the page due to the user's operation. Instead, JavaScript is used to dynamically transform the content of HTML, so as to realize the interaction between UI and users. Because the reload of the page is avoided, spa can provide a smoother user experience. Thanks to ajax, we can achieve no jump refresh. Thanks to the browser's history mechanism, we can use hash changes to promote interface changes. So as to simulate the single page switching effect of the client.
Advantages and disadvantages of SPA
advantage
- No refresh interface, giving users the feeling of native application
- Save the development cost of native (Android & IOS) app
- Improve development efficiency without installing update packages every time
- It is easy to use other well-known platforms, which is more conducive to marketing and promotion
- Comply with web2 Trend of 0
shortcoming
- There is a big gap between the effect and performance of the original
- The version compatibility of each browser is different
- Business increases with the increase of code volume, which is not conducive to the first screen optimization
- Some platforms are biased against hash, and some don't even support pushstate
- Not conducive to search engine capture
Design mode
MVVM
What is MVVM mode?
The first M is the model layer, which is responsible for data storage and business logic; The second V is the view layer, which is responsible for displaying the data in the model; The third VM is the view model layer, which is responsible for connecting the model layer and the view layer. It has the function of two-way data binding and automatic view update
MVC
What is MVC mode?
Model View Controller model View Controller refers to the page business logic. The purpose of using MVC is to separate the codes of M and V. MVC is one-way communication, that is, View and model, which must be connected through Controller.
MVP
MVP refers to the Model View Presenter, but the view in MVP cannot directly use the model. Instead, it provides an interface for the presenter to update the model, and then updates the view through the observer mode.
Project introduction
Project introduction:
Mobile IT information sharing platform, similar to CSDN, blog park; The main functions include: tab switching, channel management, article details, attention function, like function, comment function, search function, login function, personal center, editing data and automatic customer service
Technology stack
vuex stores the token when the user logs in, and refreshToken sets the cache in the browser's localStorage
Realizing lazy loading of route by Vue router
axios implements three-tier encapsulation of interfaces, including axios request interceptor and axios response interceptor
vant component library for page building
socket. IO client realizes customer service function
Amfe flexible mobile terminal adaptation
Project difficulties
Secondary packaging of axios
When the base interface is imported, the destination address can be set directly
axios request interceptor
Scenario:
Before initiating the request, modify the request configuration object to be sent
For example, if there is a token locally, it is carried in the request header to the background
In all api interfaces, you don't need to carry headers + tokens in the future
service.interceptors.request.use(config => {
return config;
}, error => {
Promise.reject(error);
});
axios response interceptor
After the response comes back, execute the response interceptor function immediately
For example: judge whether it is wrong 401, and judge the permission uniformly
axios.interceptors.response.use(function(response)){
//Do something about the response data
return response;
},function(error){
// Do something about response errors
return Promise.reject(error)
}
Channel switching list
It is realized by monitoring the change of activeId; Set a listener for activeId. When it changes, call the interface again to initiate a new request
Pull up to load more
principle
- Detect when the bottom is touched
- When the bottom is reached, send a request to obtain the data of the next page
- Merge old data and new data
Detect when to bottom (native)
window.onscroll = function(){
// The variable scrollTop is the distance from the top of the scroll bar when scrolling
var scrollTop = document.documentElement.scrollTop||document.body.scrollTop;
// The variable windowHeight is the height of the viewable area
var windowHeight = document.documentElement.clientHeight || document.body.clientHeight;
// The variable scrollHeight is the total height of the scroll bar
var scrollHeight = document.documentElement.scrollHeight||document.body.scrollHeight;
// Scroll bar bottom condition
if(scrollTop+windowHeight==scrollHeight){
console.log("From top"+scrollTop+"Visual area height"+windowHeight+"Total height of scroll bar"+scrollHeight);
}
}
Add onscroll scrolling event to window
Scroll bar distance from top
document.documentElement.scrollTop
Height of visual area
document.documentElement.clientHeight
Total height of scroll bar
document.documentElement.scrollHeight
Vant component library
Whether the v-model is in the loading state, and the load event is not triggered during the loading process
Whether the finished has been loaded, and the load event will not be triggered after loading
The load event is triggered when the distance between the offset scroll bar and the bottom is less than offset
Pull down refresh
principle
- Drag a box
Touchstart + touchmove
transform: translateY()
- Pull out a certain distance
Send a request to get new data / replace the previous old data
Channel management - switching channels
Add a click event to obtain the activeId of the channel, and assign the activeId of the clicked channel to the activeId in the page component
Automatic reply
http protocol review
http composition = request message + response message
HTTP message consists of four parts: request line, request header, blank line and request body
The HTTP response message consists of four parts: status line, response header, blank line and response body
Disadvantages of http protocol
The server can only passively respond to the request of the client, and cannot actively send messages to the client. Only one request can correspond to one response
Instant messaging WebSocket
HTML5 has a new protocol called WebSocket, which can realize the effect of instant messaging on a TCP/lP link
Need front-end support + need back-end support
Summary
What is instant messaging?
The server can actively send messages to the client, not limited to one request and one response at a time
Can ajax realize instant messaging?
It can only simulate and use polling mode, but it consumes resources
How to realize instant messaging?
The front end adopts websocket protocol, which is also a new class
The back end should also provide the address of websocket interface to establish the connection
Through socket IO package
Socket in the back end io
Connect socket server with io() function
If the code is deployed to the online server, the localhost should be replaced with the online ip address
Because this web page requests to view on the local browser, you still want to use localhost. Isn't that a local request?
Route lazy loading
Implementation mode
Then, after the Webpack is compiled and packaged, the code of each routing component will be divided into a js file. These js files will not be loaded during initialization. The corresponding js file will be loaded only when the routing component is activated. Here, no matter how the Webpack divides the code according to the routing component, just how to load the corresponding routing component js file on demand after the Webpack is compiled
In the routing configuration file, the original method of directly introducing components is replaced by the method of arrow function
const home = () => import('@/views/Home/home.vue')
In short, the sub modules referenced through import() will be separated and packaged into a separate file (the packaged file is called chunk)
When the project is packaged through webpack, resources will be integrated, that is, JS, CSS and other files in the project will be merged according to certain rules, which has achieved the purpose of reducing resource requests
Routing global guard
Users can access the page only after logging in
method
1. Route pre guard judgment
router.beforeEach((to,from,next) => {
// There is a token. You can't go to the login page
// There is no token, and the user's "permission" is required to go to the login page
if(store.state.token.length < 0 && to.path === '/login'){
//Prove that the token has logged in
next(false)
}else{
next()
}
})
Component cache
To avoid the frequent creation and destruction of components, keep alive is used to cache components
Lazy loading of pictures
Problems encountered
Encapsulated custom focus instruction
The custom instruction will take effect only when you click once, and click the same command the second time
reason:
The inserted() function is triggered only once
How to solve
Encapsulated custom focus instruction
Set Vue The custom instructions encapsulated in directive are placed in the updated attribute
Renewal of token
When the token expires 401, use refresh_ The token refreshes a new token without perception. While replacing the old token, it continues the last outstanding request. The user experience is good
Steps:
- Define the interface method of refreshing token
- At the response interceptor 401, the interface of re requesting token is called and synchronized to vuex and local
refreshToken expired
- Clear the local token and refreshToken (in the request interceptor)
- Force jump to login page
How to handle browser disconnection
Disconnection event offline and networking event online
The browser has two events: "online" and "offline" These two events will be emitted by the < body > of the page when the browser switches between online mode and offline mode
Events bubble in the following order: document body -> document -> window.
Events cannot be cancelled (developers cannot manually change the code to online or offline. Developers can use developer tools during development)
Several ways to register online and offline events
The most recommended combination of window+addEventListener
- Through window or document or document Body and addeventlistener (chrome 80 is only valid for window)
- Is document or document Body Online or The online offline property sets a js function. (note that there will be compatibility problems when using window.online and window.online offline)
- You can also register events through tags < body online = "onlinecb" onlinecb "></body>
acm input / output mode
1. One line input, two parameters, with spaces in the middle
1 5 10 20
while(line = readline()) {
let arr = line.split(" ").map(item => parseInt(item));
print(add(arr[0], arr[1]));
}
2. The first line is the number of input lines, followed by test numbers, separated by spaces
2 1 5 10 20
let len = parseInt(readline())
for(let i=0;i<len;i++){
let arr = readline().split(' ').map(item => parseInt(item))
print(add(arr[0],arr[1]))
}
3.
1 5 10 20 0 0
while(line = readline()){
let arr = line.split(' ').map(item => parseInt(item))
if(arr[0] === 0 && arr[1] ===0) break
print(add(arr[0],arr[1]))
}
4.
// input 4 1 2 3 4 5 1 2 3 4 5 0
//output 10 15
while(line = readline()){
let arr = line.split(' ').map(item => parseInt(item))
let len = arr[0]
if(arr[0] === 0) break
let sum = 0
for(let i=1;i<=len;i++){
sum += arr[i]
}
print(sum)
}
5.
2 4 1 2 3 4 5 1 2 3 4 5
10 15
let count = parseInt(readline())
for(let i=0;i<count;i++){
let arr = readline().split(' ').map(item => parseInt(item))
let len = arr[0]
let sum = 0
for(let i=1;i<=len;i++){
sum += arr[i]
}
print(sum)
}
6.
// input 4 1 2 3 4 5 1 2 3 4 5
// output 10 15
while(line = readline()){
let arr = line.split(' ').map(item => parseInt(item))
let len = arr[0]
let sum = 0
for(let i=1;i<=len;i++){
sum += arr[i]
}
print(sum)
}
7.
//input 1 2 3 4 5 0 0 0 0 0
// output 6 9 0
while(line = readline()){
let arr = line.split(' ').map(item => parseInt(item))
let sum = 0
for(let i=0;i<arr.length;i++){
sum += arr[i]
}
print(sum)
}
8.
// input 5 c d a bb e
// output a bb c d e
let line = readline()
let arr = readline().split(' ')
arr.sort()
print(arr.join(' '))
9.
// input a c bb f dddd nowcoder
// output a bb c dddd f nowcoder
function format(arr){
return arr.sort().join(' ')
}
while(line = readline()){
let arr = line.split(' ')
print(format(arr))
}
10.
// input a,c,bb f,dddd nowcoder
// output a,bb,c dddd,f nowcoder
while(line = readline()){
let arr = line.split(',').sort().join(',')
print(arr)
}
Pen classics
shopee approved in advance
The method of Array instance does not include
copyWithin
length
reverse
toString
length is an attribute, not a method
The following description is correct
A thread can improve the concurrent execution of programs and improve the efficiency of the system
B one thread can create multiple threads
C system supports threads and user level threads, and both need the support of the kernel to complete the switching
Semaphores can be used between D threads to achieve synchronization
Correct : ABD
Cache control is used to implement the caching mechanism by specifying instructions in http requests and responses. Which of the following statements is wrong?
A if the max age value is specified as 0, each request needs to be re sent to the server
B if no cache is set, it means that for each request, the cache will send the request to the server to verify whether it has expired. If it has not expired, the cache will use the local cache copy
The C public instruction indicates that the response can be cached by any middleman, even if it is usually not cacheable
The d must revalidate instruction indicates that even if the max age is not exceeded, the cache must be revalidated with the server before it can be used
Tell me the execution order of the code
setImmediate(() => {
console.log(1);
Promise.resolve().then(() => {
console.log(2);
});
}, 0);
new Promise((resolve) => {
console.log(3);
resolve();
}).then(() => {
console.log(4);
process.nextTick(() => {
console.log(5)
});
setTimeout(() => {
console.log(6);
}, 0);
}).then(() => {
console.log(7);
});
console.log(8);
output
3 8 4 7 5 1 2 6