This article mainly introduces the example of Python crawling Jingdong Laptop Data Based on scratch and simple processing and analysis, so as to help you better understand and learn to use python. Interested friends can understand
1, Environmental preparation
- python3.8.3
- pycharm
- Third party packages required for the project
pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple
1.1 creating a virtual environment
Switch to the specified directory to create
virtualenv .venv
Remember to activate the virtual environment after creation
1.2 create project
scrapy startproject entry name
1.3 open the project with pycharm and configure the created virtual environment into the project
1.4 create JD spider
scrapy genspider Reptile name url
1.5 modify the domain name allowed to access and delete https:
2, Problem analysis
The idea of crawling data is to obtain the basic information of the home page first, and then obtain the detailed information of goods on the details page; When crawling Jingdong data, only 40 pieces of data are returned. Here, the author uses selenium to write the downloader Middleware in the scratch framework to return all the data on the page.
The crawling fields are:
- commodity price
- Commodity rating
- Commodity store
- Product SKU (jd.com can directly search for the corresponding products)
- Product title
- Product details
3, spider
import re
import scrapy
from lianjia.items import jd_detailItem
class JiComputerDetailSpider(scrapy.Spider):
name = 'ji_computer_detail'
allowed_domains = ['search.jd.com', 'item.jd.com']
start_urls = [
'https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&suggest=1.def.0.base&wq=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&page=1&s=1&click=0']
def parse(self, response):
lls = response.xpath('//ul[@class="gl-warp clearfix"]/li')
for ll in lls:
item = jd_detailItem()
computer_price = ll.xpath('.//div[@class="p-price"]/strong/i/text()').extract_first()
computer_commit = ll.xpath('.//div[@class="p-commit"]/strong/a/text()').extract_first()
computer_p_shop = ll.xpath('.//div[@class="p-shop"]/span/a/text()').extract_first()
item['computer_price'] = computer_price
item['computer_commit'] = computer_commit
item['computer_p_shop'] = computer_p_shop
meta = {
'item': item
}
shop_detail_url = ll.xpath('.//div[@class="p-img"]/a/@href').extract_first()
shop_detail_url = 'https:' + shop_detail_url
yield scrapy.Request(url=shop_detail_url, callback=self.detail_parse, meta=meta)
for i in range(2, 200, 2):
next_page_url = f'https://search.jd.com/Search?keyword=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&suggest=1.def.0.base&wq=%E7%AC%94%E8%AE%B0%E6%9C%AC%E7%94%B5%E8%84%91&page={i}&s=116&click=0'
yield scrapy.Request(url=next_page_url, callback=self.parse)
def detail_parse(self, response):
item = response.meta.get('item')
computer_sku = response.xpath('//a[@class="notice J-notify-sale"]/@data-sku').extract_first()
item['computer_sku'] = computer_sku
computer_title = response.xpath('//div[@class="sku-name"]/text()').extract_first().strip()
computer_title = ''.join(re.findall('\S', computer_title))
item['computer_title'] = computer_title
computer_detail = response.xpath('string(//ul[@class="parameter2 p-parameter-list"])').extract_first().strip()
computer_detail = ''.join(re.findall('\S', computer_detail))
item['computer_detail'] = computer_detail
yield item
4, item
class jd_detailItem(scrapy.Item):
# define the fields for your item here like:
computer_sku = scrapy.Field()
computer_price = scrapy.Field()
computer_title = scrapy.Field()
computer_commit = scrapy.Field()
computer_p_shop = scrapy.Field()
computer_detail = scrapy.Field()
5, setting
import random
from fake_useragent import UserAgent
ua = UserAgent()
USER_AGENT = ua.random
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = random.uniform(0.5, 1)
DOWNLOADER_MIDDLEWARES = {
'lianjia.middlewares.jdDownloaderMiddleware': 543
}
ITEM_PIPELINES = {
'lianjia.pipelines.jd_csv_Pipeline': 300
}
6, pipelines
class jd_csv_Pipeline:
# def process_item(self, item, spider):
# return item
def open_spider(self, spider):
self.fp = open('./jd_computer_message.xlsx', mode='w+', encoding='utf-8')
self.fp.write('computer_sku\tcomputer_title\tcomputer_p_shop\tcomputer_price\tcomputer_commit\tcomputer_detail\n')
def process_item(self, item, spider):
# write file
try:
line = '\t'.join(list(item.values())) + '\n'
self.fp.write(line)
return item
except:
pass
def close_spider(self, spider):
# Close file
self.fp.close()
7, Middlewars
class jdDownloaderMiddleware:
def process_request(self, request, spider):
# Judge whether it is ji_computer_detail crawler
# Determine whether it is the home page
if spider.name == 'ji_computer_detail' and re.findall(f'.*(item.jd.com).*', request.url) == []:
options = ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(options=options)
driver.get(request.url)
for i in range(0, 15000, 5000):
driver.execute_script(f'window.scrollTo(0, {i})')
time.sleep(0.5)
body = driver.page_source.encode()
time.sleep(1)
return HtmlResponse(url=request.url, body=body, request=request)
return None
8, Simple processing and analysis using jupyter
Other documents: Baidu disabled thesaurus and simplified Chinese documents
Download third-party packages
!pip install seaborn jieba wordcloud PIL -i https://pypi.douban.com/simple
8.1 importing third-party packages
import re import os import jieba import wordcloud import pandas as pd import numpy as np from PIL import Image import seaborn as sns from docx import Document from docx.shared import Inches import matplotlib.pyplot as plt from pandas import DataFrame,Series
8.2 set the default font of visualization and the style of seaborn
sns.set_style('darkgrid')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
8.3 reading data
df_jp = pd.read_excel('./jd_shop.xlsx')
8.4 filtering Inteli5, i7 and i9 processor data
def convert_one(s):
if re.findall(f'.*?(i5).*', str(s)) != []:
return re.findall(f'.*?(i5).*', str(s))[0]
elif re.findall(f'.*?(i7).*', str(s)) != []:
return re.findall(f'.*?(i7).*', str(s))[0]
elif re.findall(f'.*?(i9).*', str(s)) != []:
return re.findall(f'.*?(i9).*', str(s))[0]
df_jp['computer_intel'] = df_jp['computer_detail'].map(convert_one)
8.5 screen size range for screening laptops
def convert_two(s):
if re.findall(f'.*?(\d+\.\d+inch-\d+\.\d+inch).*', str(s)) != []:
return re.findall(f'.*?(\d+\.\d+inch-\d+\.\d+inch).*', str(s))[0]
df_jp['computer_in'] = df_jp['computer_detail'].map(convert_two)
8.6 convert comments to shaping
def convert_three(s):
if re.findall(f'(\d+)ten thousand+', str(s)) != []:
number = int(re.findall(f'(\d+)ten thousand+', str(s))[0]) * 10000
return number
elif re.findall(f'(\d+)+', str(s)) != []:
number = re.findall(f'(\d+)+', str(s))[0]
return number
df_jp['computer_commit'] = df_jp['computer_commit'].map(convert_three)
8.7 select the brands to be analyzed
def find_computer(name, s):
sr = re.findall(f'.*({name}).*', str(s))[0]
return sr
def convert(s):
if re.findall(f'.*(association).*', str(s)) != []:
return find_computer('association', s)
elif re.findall(f'.*(HP).*', str(s)) != []:
return find_computer('HP', s)
elif re.findall(f'.*(Huawei).*', str(s)) != []:
return find_computer('Huawei', s)
elif re.findall(f'.*(Dale).*', str(s)) != []:
return find_computer('Dale', s)
elif re.findall(f'.*(ASUS).*', str(s)) != []:
return find_computer('ASUS', s)
elif re.findall(f'.*(millet).*', str(s)) != []:
return find_computer('millet', s)
elif re.findall(f'.*(glory).*', str(s)) != []:
return find_computer('glory', s)
elif re.findall(f'.*(Shenzhou).*', str(s)) != []:
return find_computer('Shenzhou', s)
elif re.findall(f'.*(alien).*', str(s)) != []:
return find_computer('alien', s)
df_jp['computer_p_shop'] = df_jp['computer_p_shop'].map(convert)
8.8 delete the data whose specified field is null
for n in ['computer_price', 'computer_commit', 'computer_p_shop', 'computer_sku', 'computer_detail', 'computer_intel', 'computer_in']:
index_ls = df_jp[df_jp[[n]].isnull().any(axis=1)==True].index
df_jp.drop(index=index_ls, inplace=True)
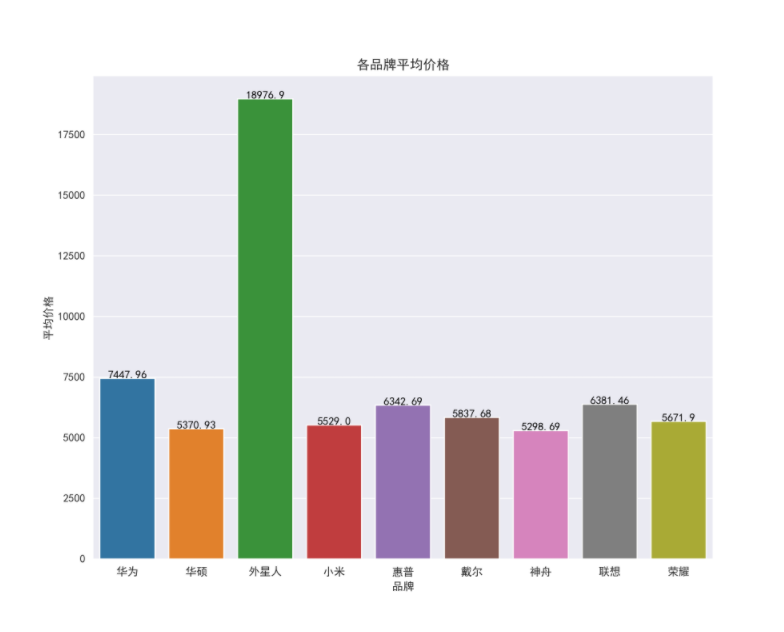
8.9 check the average price of each brand
plt.figure(figsize=(10, 8), dpi=100)
ax = sns.barplot(x='computer_p_shop', y='computer_price', data=df_jp.groupby(by='computer_p_shop')[['computer_price']].mean().reset_index())
for index,row in df_jp.groupby(by='computer_p_shop')[['computer_price']].mean().reset_index().iterrows():
ax.text(row.name,row['computer_price'] + 2,round(row['computer_price'],2),color="black",ha="center")
ax.set_xlabel('brand')
ax.set_ylabel('average price')
ax.set_title('Average price of each brand')
boxplot_fig = ax.get_figure()
boxplot_fig.savefig('Average price of each brand.png', dpi=400)
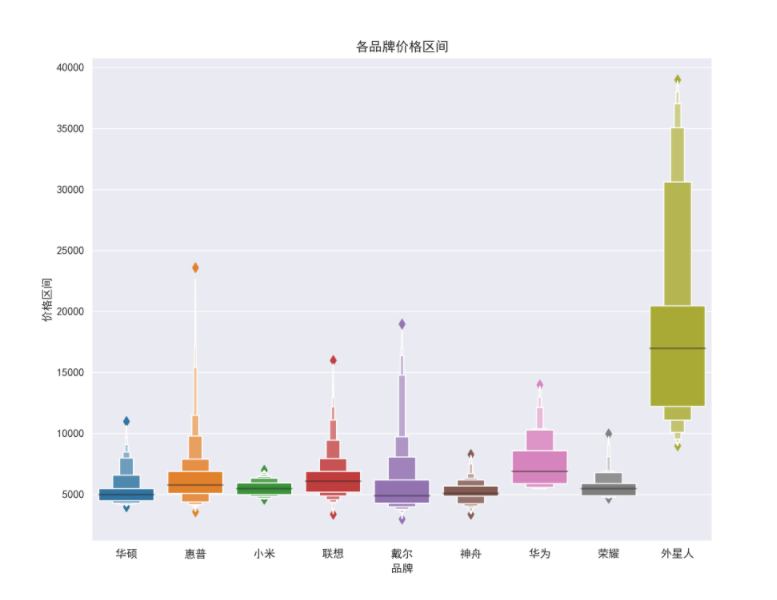
8.10 check the price range of each brand
plt.figure(figsize=(10, 8), dpi=100)
ax = sns.boxenplot(x='computer_p_shop', y='computer_price', data=df_jp.query('computer_price>500'))
ax.set_xlabel('brand')
ax.set_ylabel('Price range')
ax.set_title('Price range of each brand')
boxplot_fig = ax.get_figure()
boxplot_fig.savefig('Price range of each brand.png', dpi=400)
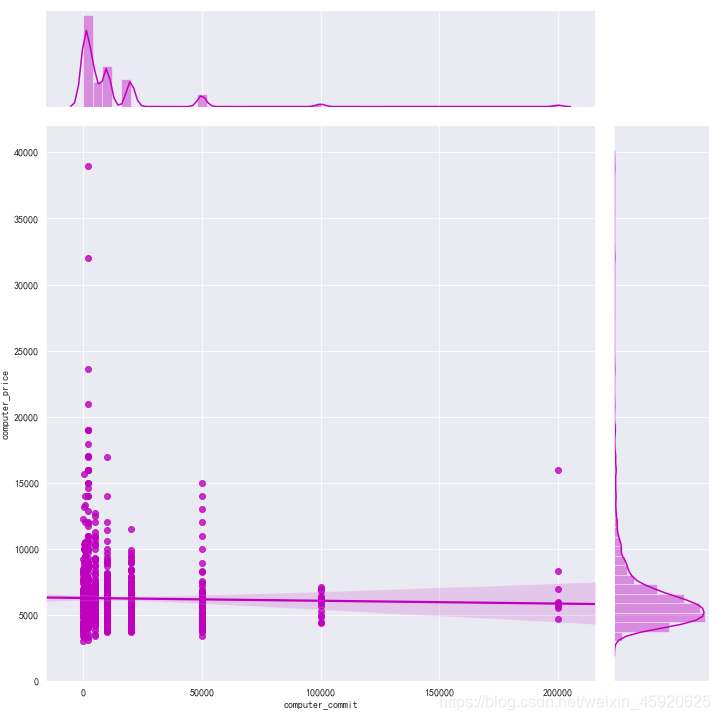
8.11 check the relationship between price and number of comments
df_jp['computer_commit'] = df_jp['computer_commit'].astype('int64')
ax = sns.jointplot(x="computer_commit", y="computer_price", data=df_jp, kind="reg", truncate=False,color="m", height=10)
ax.fig.savefig('Relationship between comments and price.png')
8.12 check the keywords in the product title
import imageio
# Convert list to feature
ls = df_jp['computer_title'].to_list()
# Replace non Chinese and English characters
feature_points = [re.sub(r'[^a-zA-Z\u4E00-\u9FA5]+',' ',str(feature)) for feature in ls]
# Read stop words
stop_world = list(pd.read_csv('./Baidu stop list.txt', engine='python', encoding='utf-8', names=['stopwords'])['stopwords'])
feature_points2 = []
for feature in feature_points: # Traverse each comment
words = jieba.lcut(feature) # Precise mode, no redundancy jieba participle each comment
ind1 = np.array([len(word) > 1 for word in words]) # Judge whether the length of each participle is greater than 1
ser1 = pd.Series(words)
ser2 = ser1[ind1] # Filter word segmentation with length greater than 1
ind2 = ~ser2.isin(stop_world) # Note the negative sign
ser3 = ser2[ind2].unique() # Screen out the participle that is not in the stop word list and leave it, and remove the duplicate
if len(ser3) > 0:
feature_points2.append(list(ser3))
# Store all participles in one list
wordlist = [word for feature in feature_points2 for word in feature]
# Splice all participles in the list into a string
feature_str = ' '.join(wordlist)
# Title Analysis
font_path = r'./simhei.ttf'
shoes_box_jpg = imageio.imread('./home.jpg')
wc=wordcloud.WordCloud(
background_color='black',
mask=shoes_box_jpg,
font_path = font_path,
min_font_size=5,
max_font_size=50,
width=260,
height=260,
)
wc.generate(feature_str)
plt.figure(figsize=(10, 8), dpi=100)
plt.imshow(wc)
plt.axis('off')
plt.savefig('Title Extraction keyword')

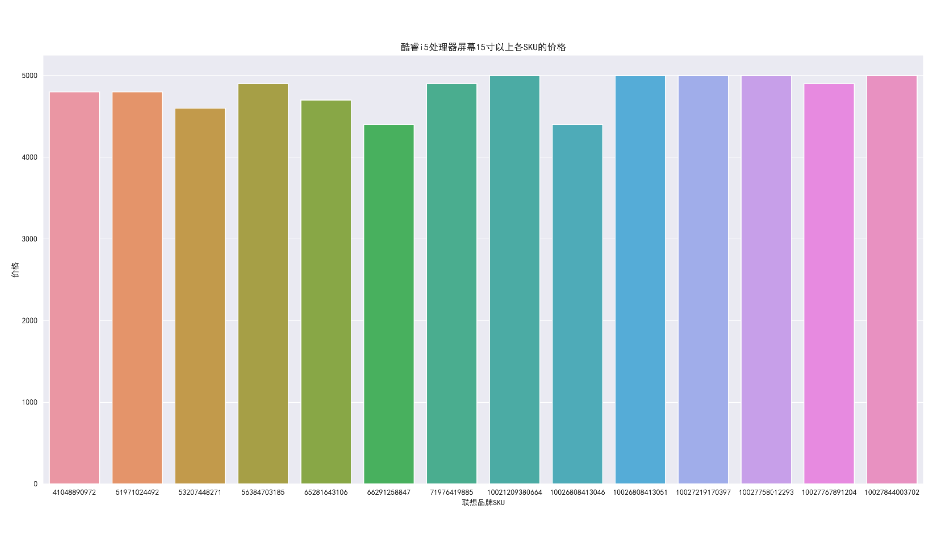
8.13 filter the data with the price between 4000 and 5000, Lenovo brand, processor i5 and screen size above 15 inches, and check the price
df_jd_query = df_jp.loc[(df_jp['computer_price'] <=5000) & (df_jp['computer_price']>=4000) & (df_jp['computer_p_shop']=="association") & (df_jp['computer_intel']=="i5") & (df_jp['computer_in']=="15.0 inch-15.9 inch"), :].copy()
plt.figure(figsize=(20, 10), dpi=100)
ax = sns.barplot(x='computer_sku', y='computer_price', data=df_jd_query)
ax.set_xlabel('Lenovo brand SKU')
ax.set_ylabel('Price')
ax.set_title('CoRE i5 Processor screen more than 15 inches SKU Price of')
boxplot_fig = ax.get_figure()
boxplot_fig.savefig('CoRE i5 Processor screen more than 15 inches SKU Price of.png', dpi=400)
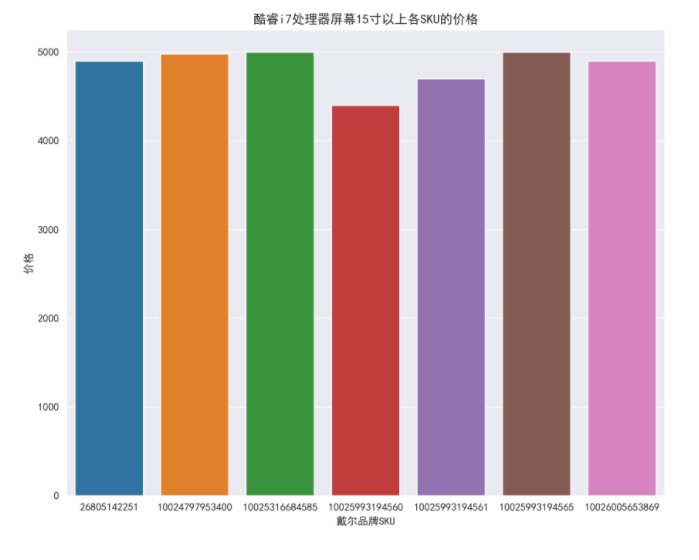
8.14 filter the data with the price ranging from 4000 to 5000, Dell brand, i7 processor and screen size of more than 15 inches, and check the price
df_jp_daier = df_jp.loc[(df_jp['computer_price'] <=5000) & (df_jp['computer_price']>=4000) & (df_jp['computer_p_shop']=="Dale") & (df_jp['computer_intel']=="i7") & (df_jp['computer_in']=="15.0 inch-15.9 inch"), :].copy()
plt.figure(figsize=(10, 8), dpi=100)
ax = sns.barplot(x='computer_sku', y='computer_price', data=df_jp_daier)
ax.set_xlabel('Dell brand SKU')
ax.set_ylabel('Price')
ax.set_title('CoRE i7 Processor screen more than 15 inches SKU Price of')
boxplot_fig = ax.get_figure()
boxplot_fig.savefig('CoRE i7 Processor screen more than 15 inches SKU Price of.png', dpi=400)
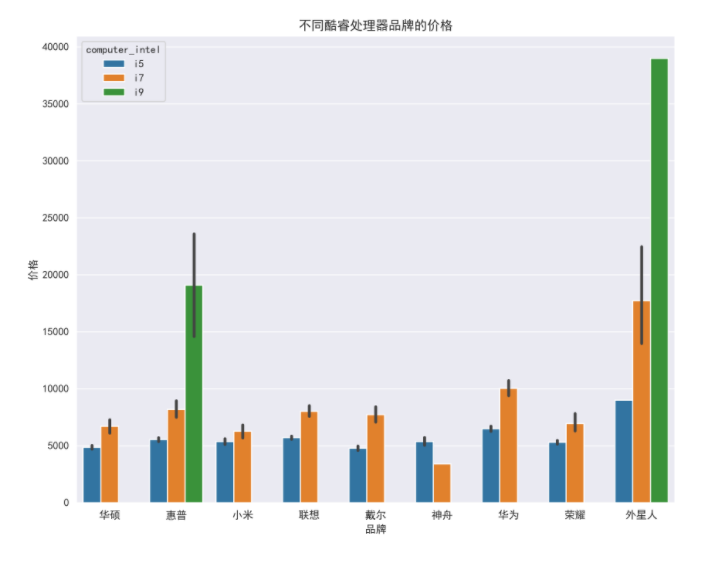
8.15 price of different Intel processor brands
plt.figure(figsize=(10, 8), dpi=100)
ax = sns.barplot(x='computer_p_shop', y='computer_price', data=df_jp, hue='computer_intel')
ax.set_xlabel('brand')
ax.set_ylabel('Price')
ax.set_title('Prices of different core processor brands')
boxplot_fig = ax.get_figure()
boxplot_fig.savefig('Prices of different core processor brands.png', dpi=400)
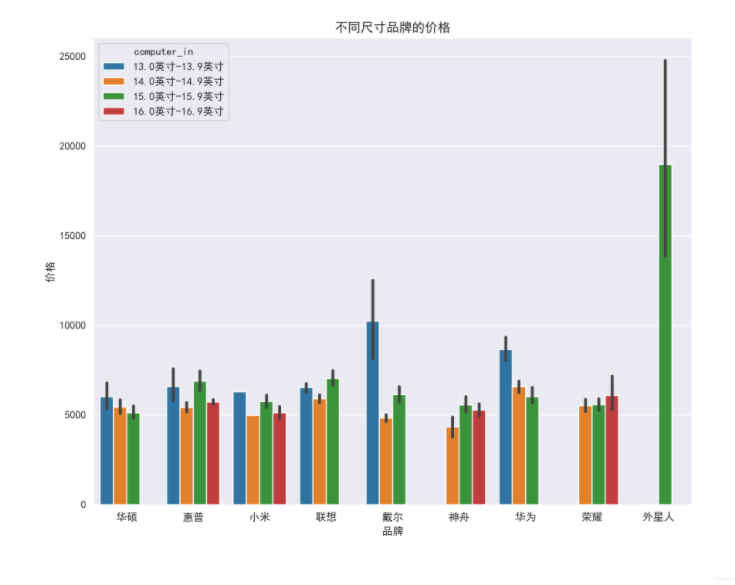
8.16 prices of brands of different sizes
plt.figure(figsize=(10, 8), dpi=100)
ax = sns.barplot(x='computer_p_shop', y='computer_price', data=df_jp, hue='computer_in')
ax.set_xlabel('brand')
ax.set_ylabel('Price')
ax.set_title('Prices of brands in different sizes')
boxplot_fig = ax.get_figure()
boxplot_fig.savefig('Prices of brands in different sizes.png', dpi=400)
Disclaimer: the content of this article comes from the Internet, and the copyright of this article belongs to the original author. It is intended to spread relevant technical knowledge & industry trends for everyone to learn and exchange. If the copyright of the work is involved, please contact for deletion or authorization.