1, Introduction to hadoop
Hadoop is a distributed system infrastructure developed by the Apache foundation. Users can develop distributed programs without knowing the details of the distributed bottom layer. Make full use of the power of cluster for high-speed computing and storage.
The core design of Hadoop framework is HDFS and MapReduce.
HDFS provides storage for massive amounts of data.
MapReduce provides computing for massive amounts of data.
Hadoop framework includes the following four modules:
Hadoop Common: These are Java libraries and utilities required by other Hadoop modules. These libraries provide file system and operating system level abstractions and contain java files and scripts required to start Hadoop.
Hadoop YARN: This is a framework for job scheduling and cluster resource management.
Hadoop Distributed File System (HDFS): a distributed file system that provides high-throughput access to application data.
Hadoop MapReduce: This is a YARN based system for parallel processing of large data sets.
Block diagram of the whole ecosystem:

2, Stand alone deployment of HDFS distributed file storage system
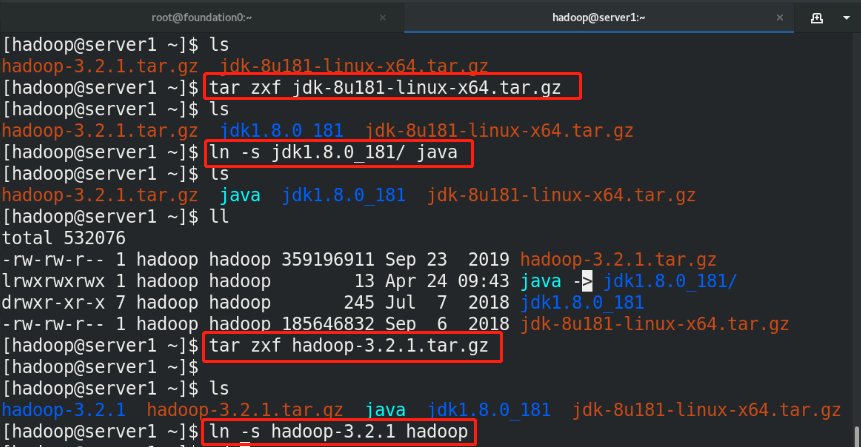
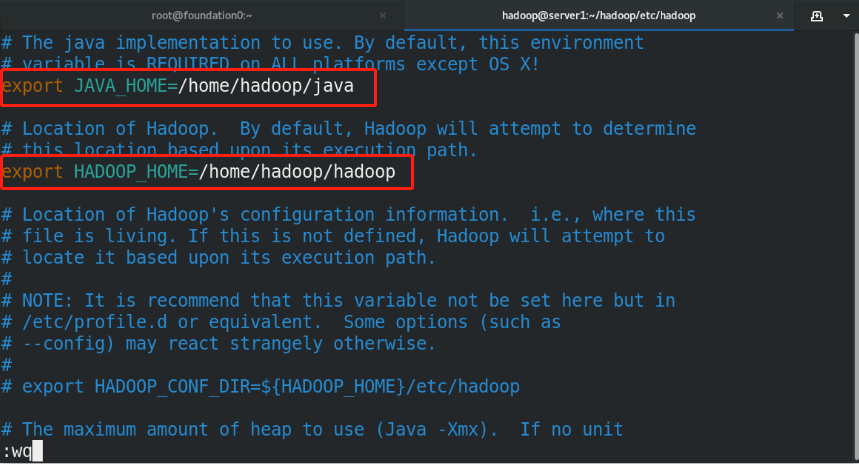
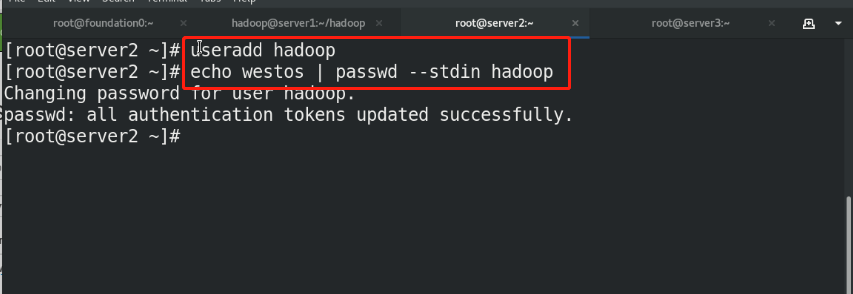
(1)useradd hadoop %First, create an ordinary user, give a password, and run as an ordinary user echo westos | passwd --stdin hadoop (2)Download and unzip relevant resource packages (3)Make soft links for executable binary programs to facilitate subsequent upgrades (4)set up hadoop Global environment variable vim /home/hadoop/hadoop/etc/hadoop/hadoop-env.sh
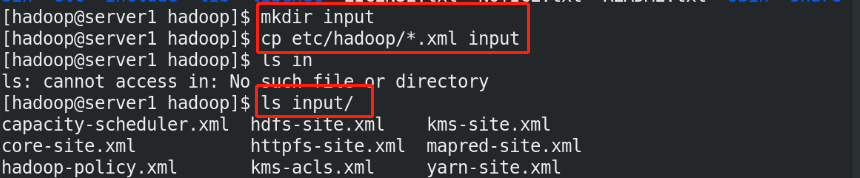
(5)By default, Hadoop Configured to run in non distributed mode as a single Java Process. This is useful for debugging. The following example will unpack conf The directory is copied as input, and then each match of the given regular expression is found and displayed. The output has been written to the given output directory. mkdir input cp etc/hadoop/*.xml input bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar grep input output 'dfs[a-z.]+' %Use system given jar Package testing cat output/* %View output
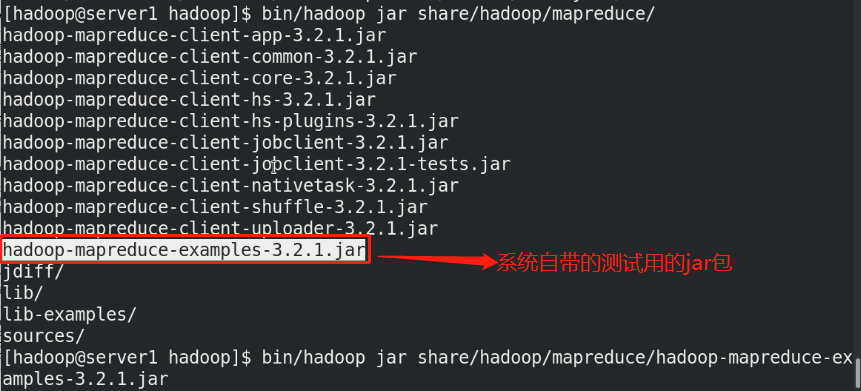
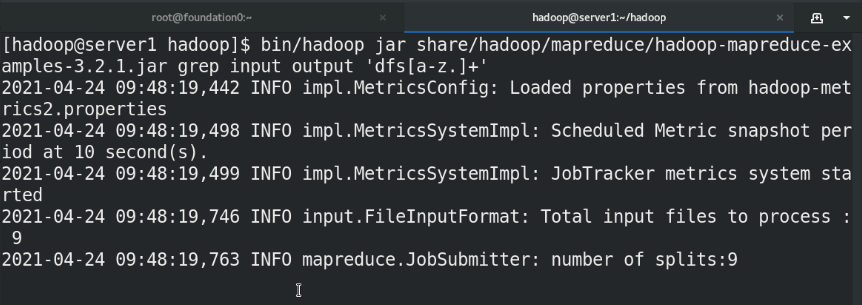
Note: the output directory cannot be created in advance, otherwise an error will be reported. It is created automatically during execution
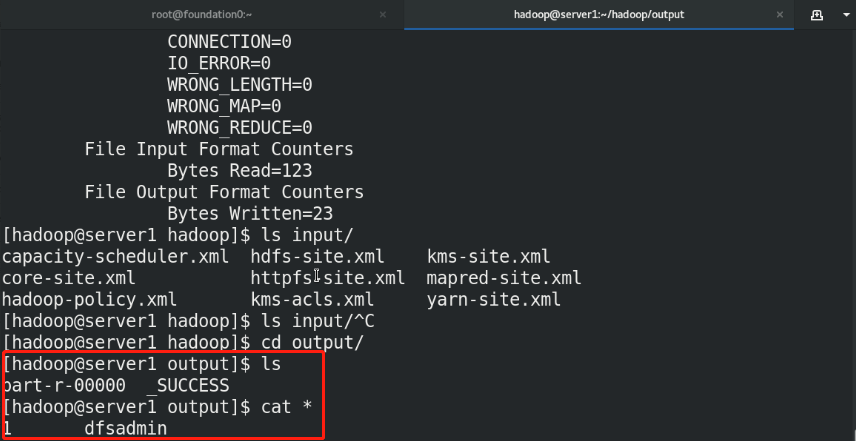
3, Pseudo distributed storage system deployment
Hadoop can also run on a single node in pseudo distributed mode, where each Hadoop daemon runs in a separate Java process.
(1)Edit profile
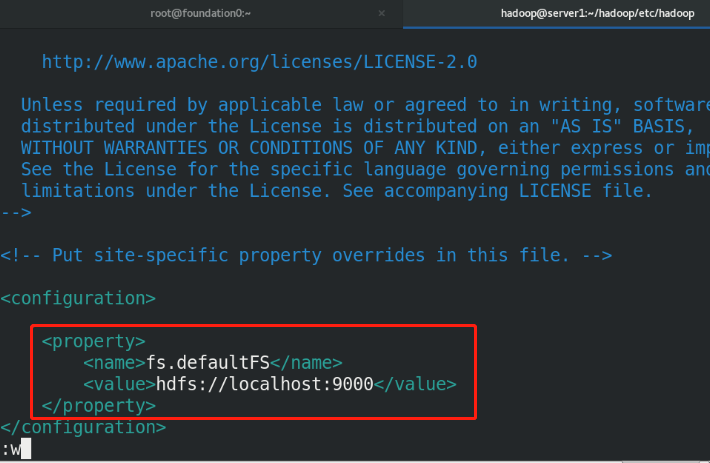
etc/hadoop/core-site.xml:
<configuration>
<property>
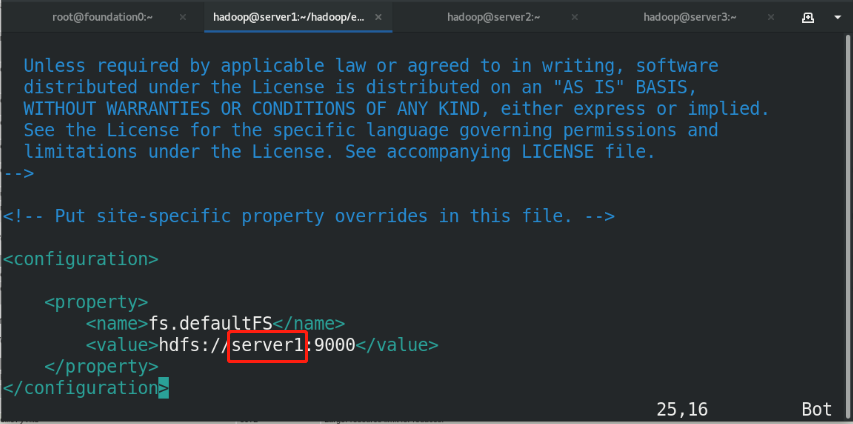
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
etc/hadoop/hdfs-site.xml:
<configuration>
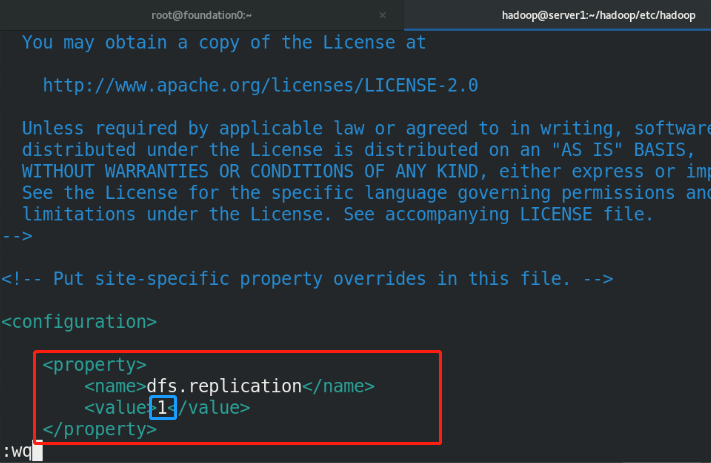
<property>
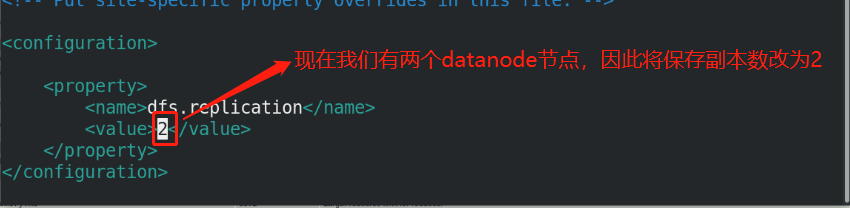
<name>dfs.replication</name>
<value>1</value> %The number of copies stored is three by default. Now we use one node for pseudo distribution, so it is set to one copy
</property>
</configuration>
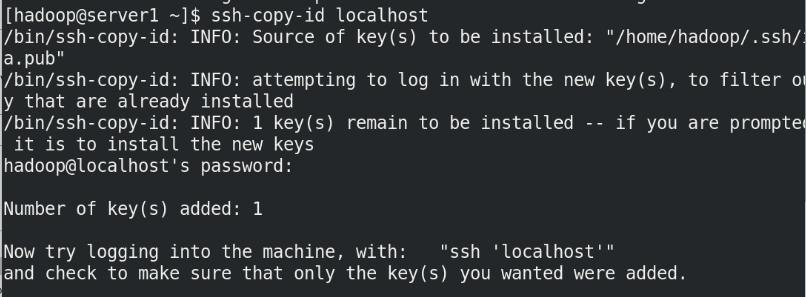
(2)Do local secret free
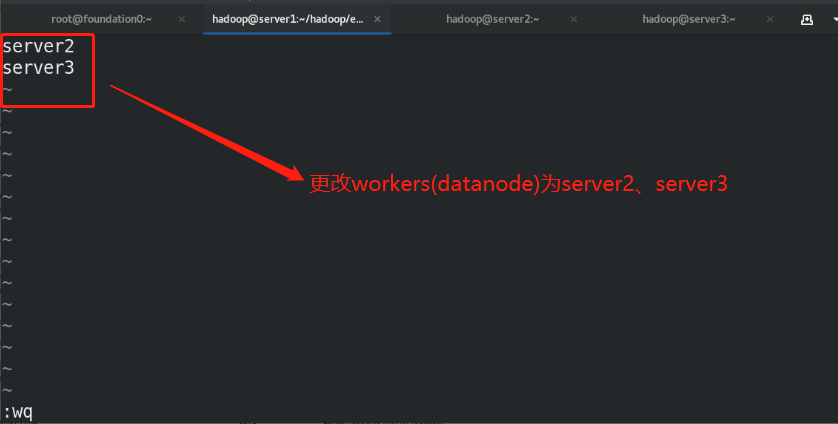
By default, hdfs It will be connected through a secret free connection worker Node (data storage node) to start the corresponding process. stay hadoop/etc/There will be in the directory workers File, which specifies worker node
ssh-keygen
ssh-copy-id localhost
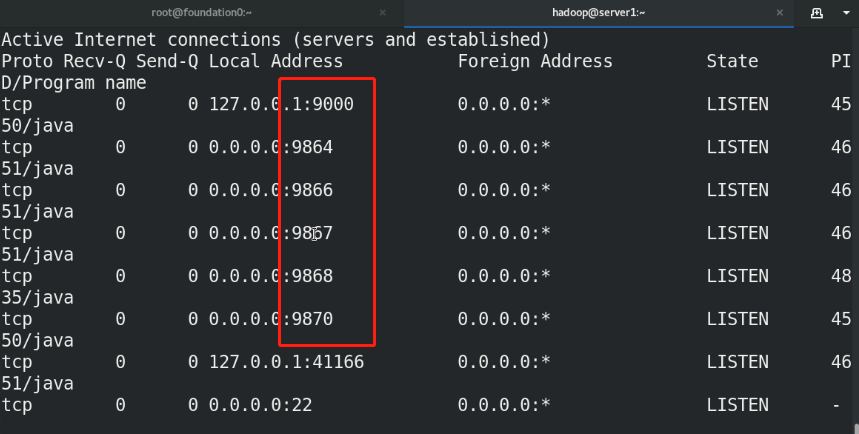
(3)bin/hdfs namenode -format %Format the file system, and the generated data is stored in/tmp/In the directory (4)sbin/start-dfs.sh %start-up NameNode Process and DataNode process namenode The metadata of the entire distributed file system is cached on the node, datanode Real data storage
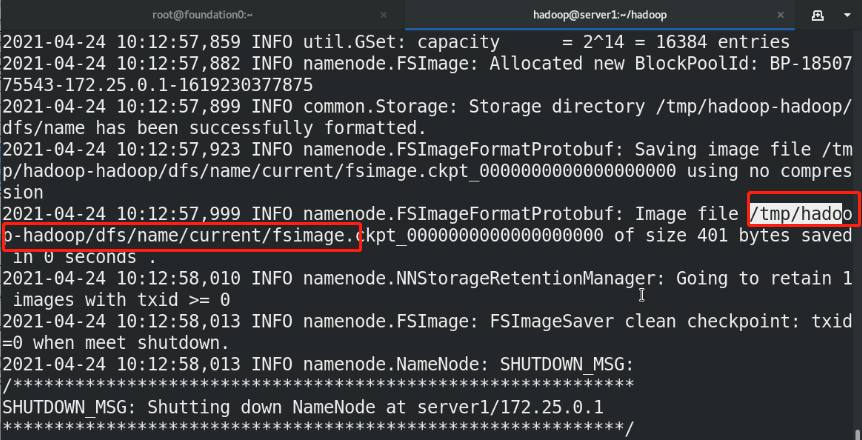
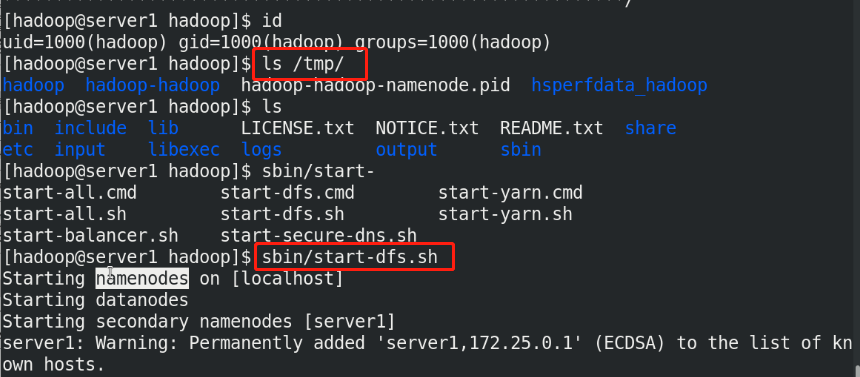

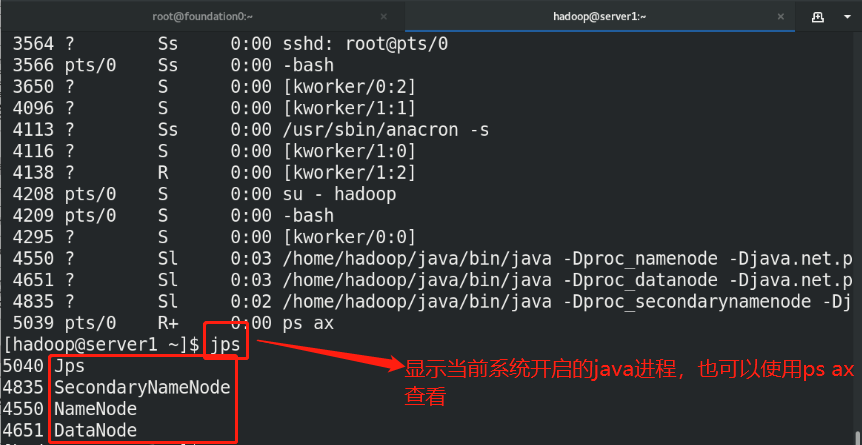
The SecondaryNameNode can be understood as that when the NameNode hangs up, the SecondaryNameNode will take over and help the NameNode clean up periodically and back up the metadata above
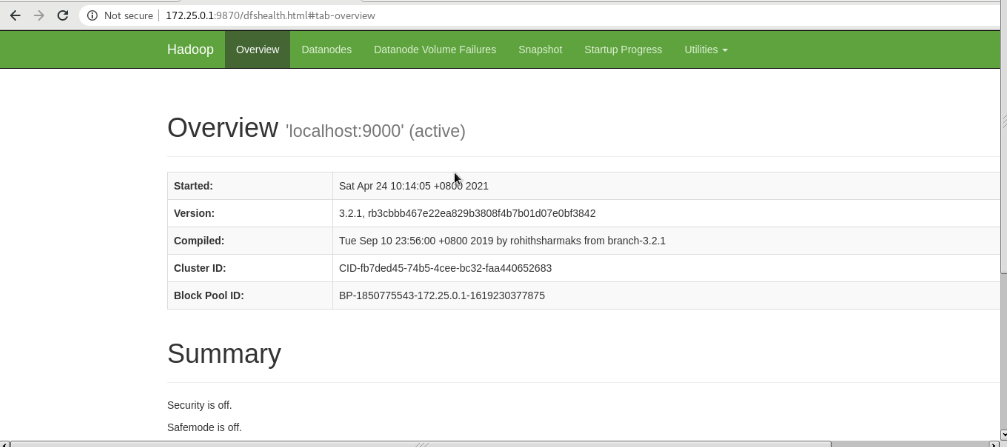
(5)Visit the web page for testing NameNode - http://localhost:9870/
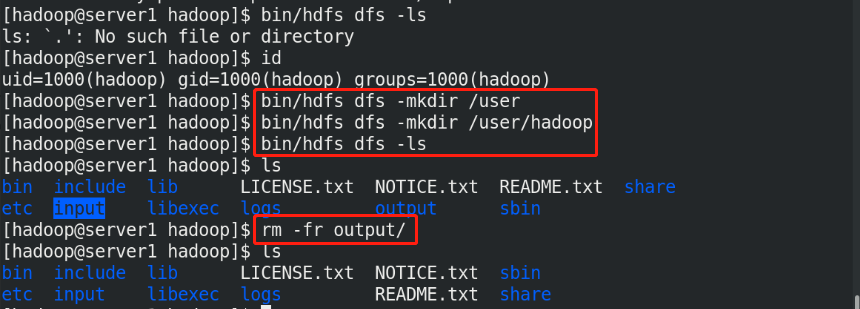
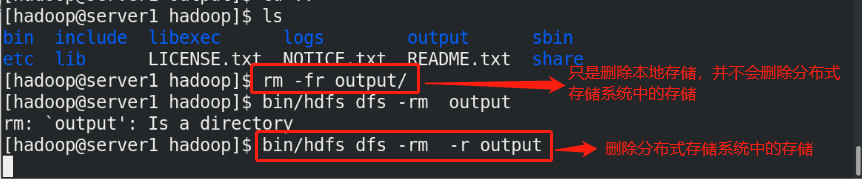
(6)Create a dedicated storage directory bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/<username> %It is equivalent to creating the user's home directory in the distributed file system bin/hdfs dfs -put input %take input The contents of the directory are uploaded to the distributed file storage system

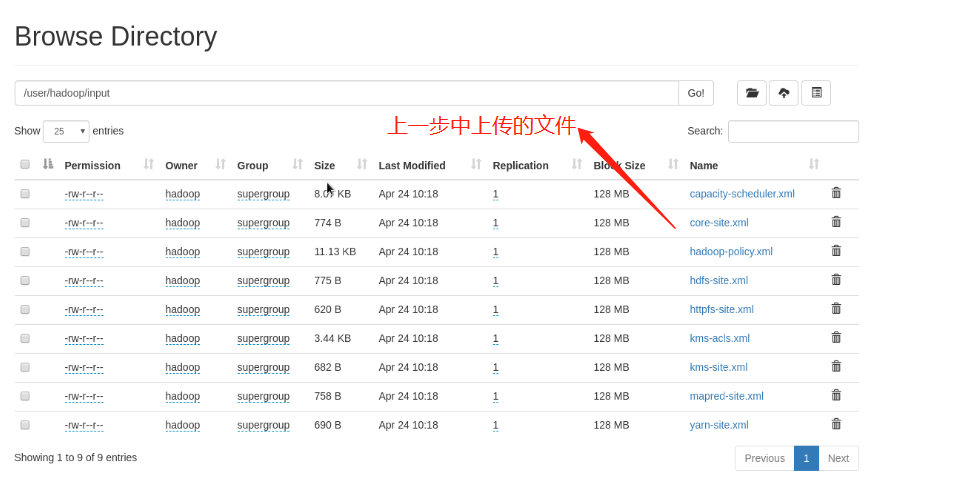
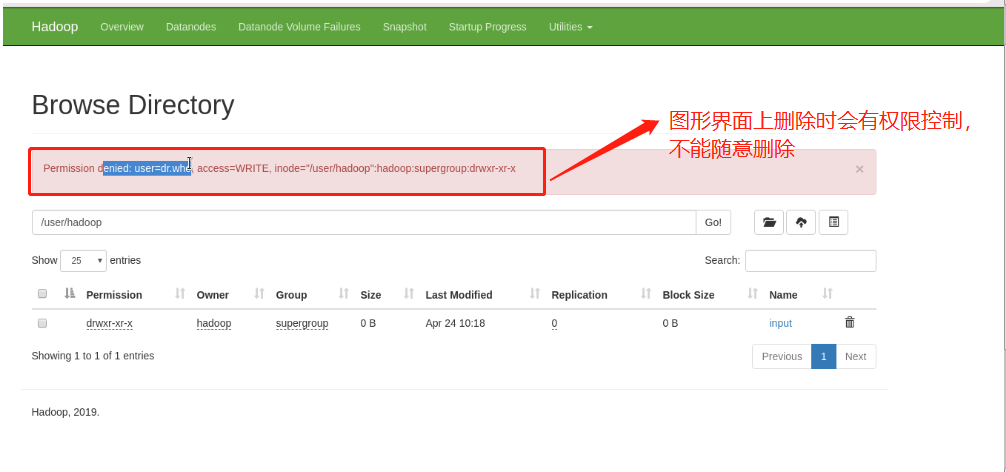
Note: when starting the distributed file system, ensure that the time of all nodes must be synchronized, and there must be parsing, otherwise an error will be reported. Moreover, the output directory cannot be created in advance in the distributed file system, that is, there should be no output directory on the web page
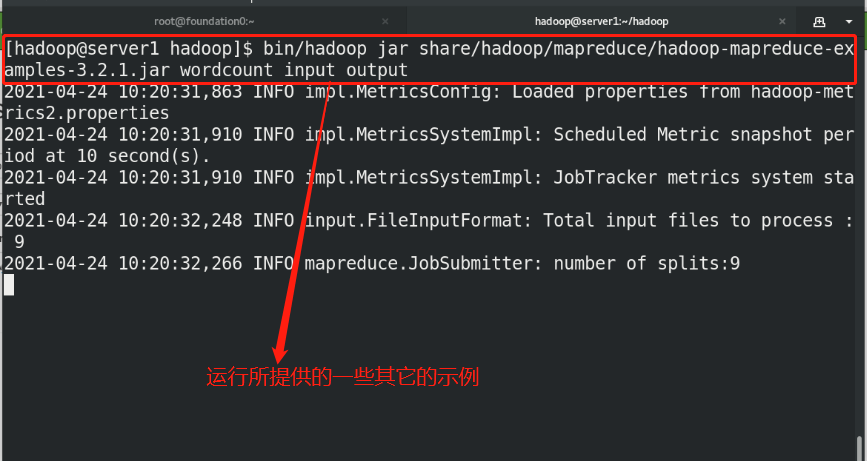
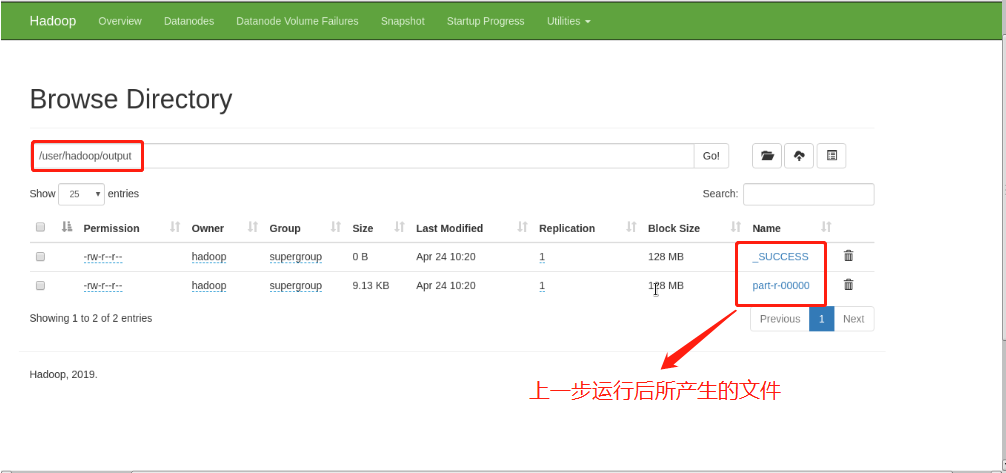
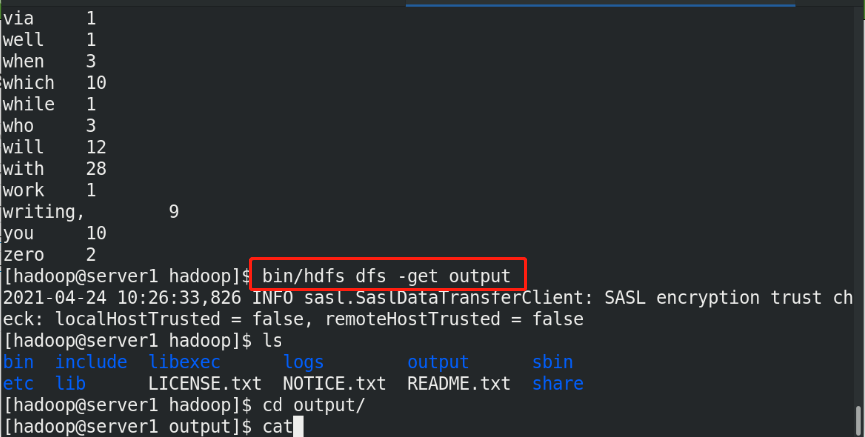
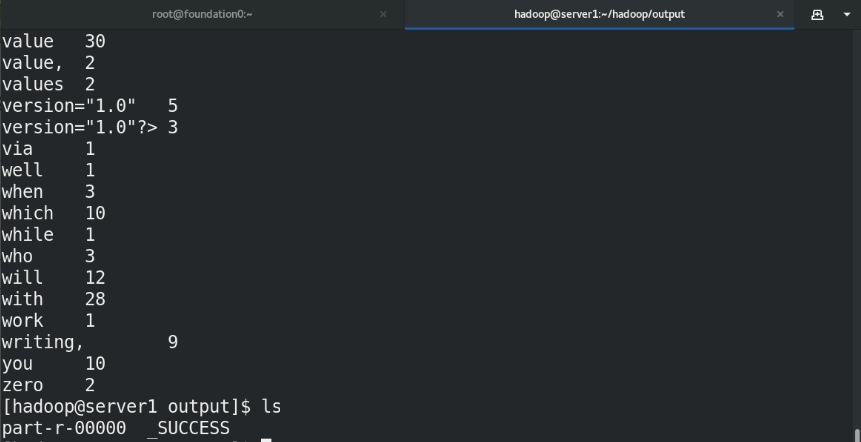
(7)Copy the output files from the distributed file system to the local file system and check them: bin/hdfs dfs -get output output cat output/* Or view the output file on the distributed file system: bin/hdfs dfs -cat output/*
4, Fully distributed storage system deployment
Start two new virtual machines of server2 and server3
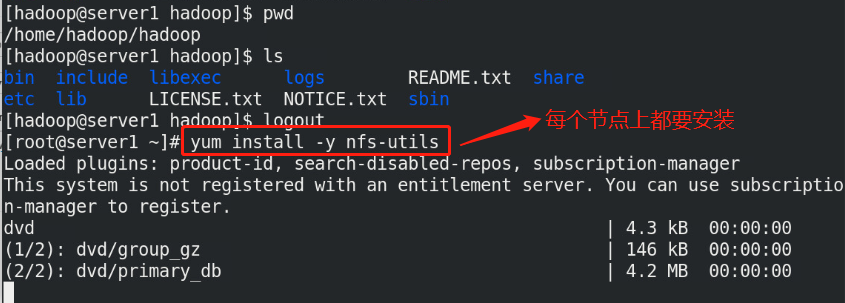
(1)Create the same on the newly opened virtual machine hadoop user (2)server1 Upper hdfs Stop first (3)build nfs File sharing system, server1 by nfs The server (4)server2 and server3 mount server1 of hadoop Directory to the specified directory to achieve data synchronization

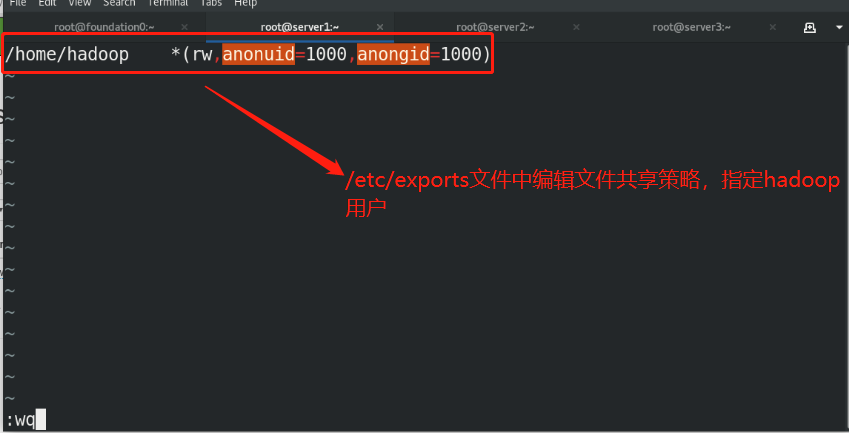
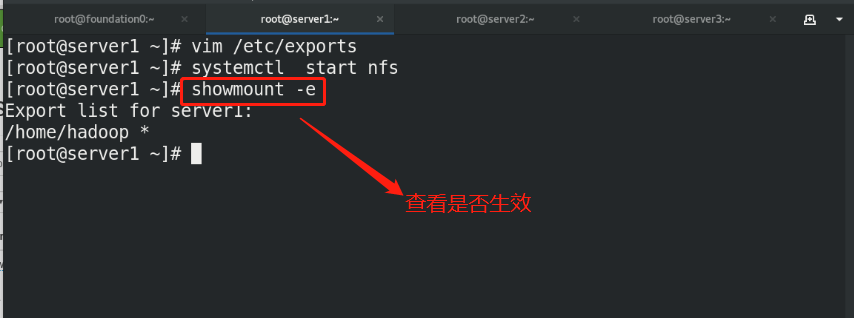
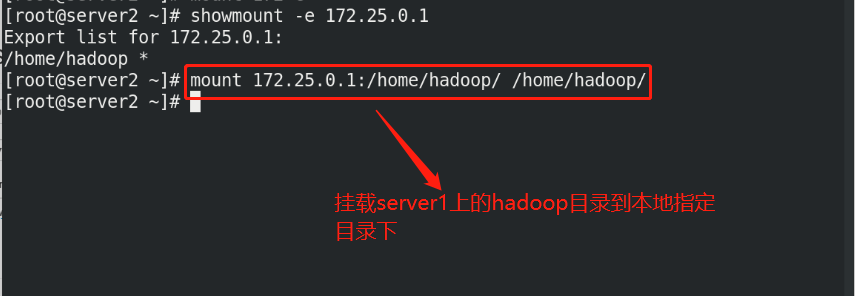
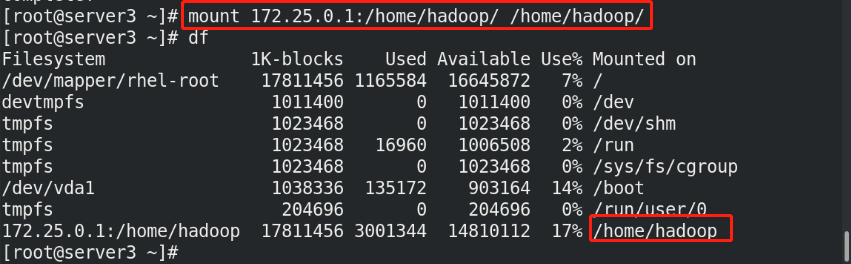
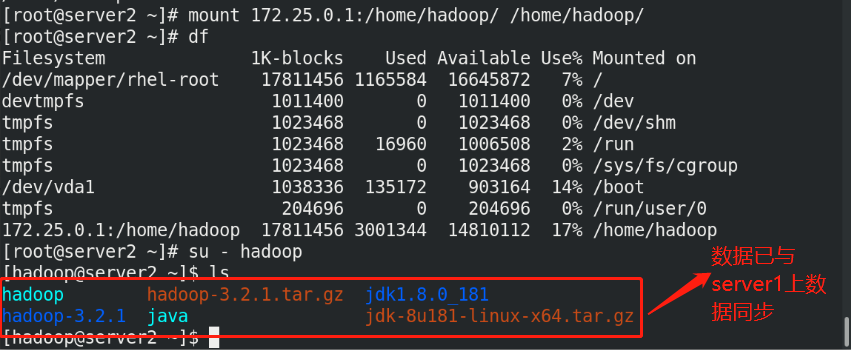
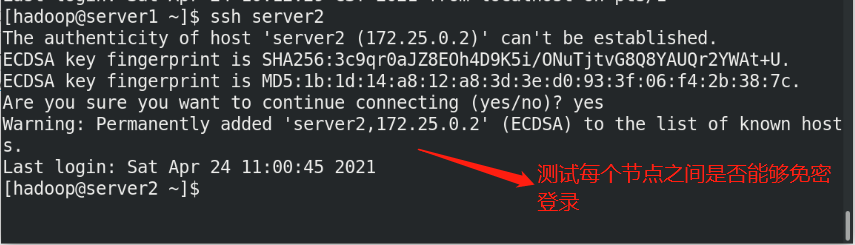
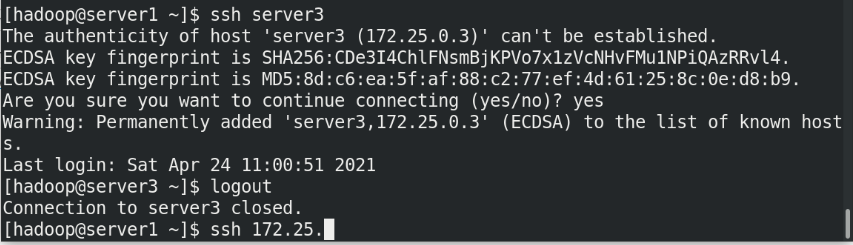
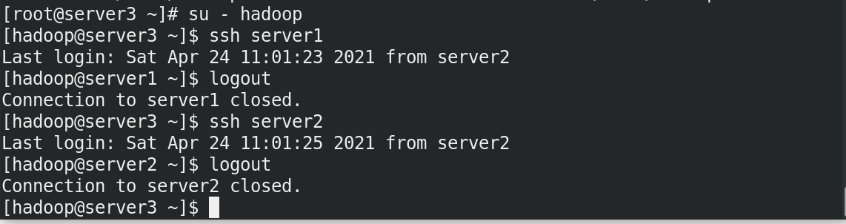
(5)stay server1 Upper modification hadoop Related configuration files, deleting/tmp/The file generated by the last initialization under the directory, and re initialize and start hdfs
core-site.xml:
workers:
hdfs-site.xml:

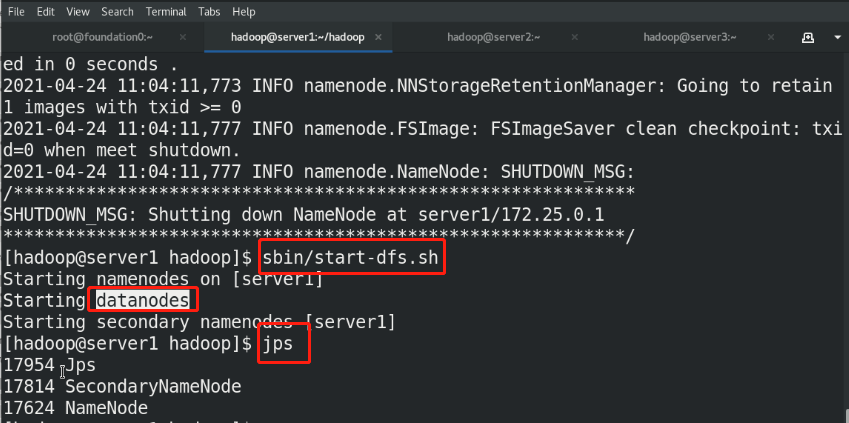

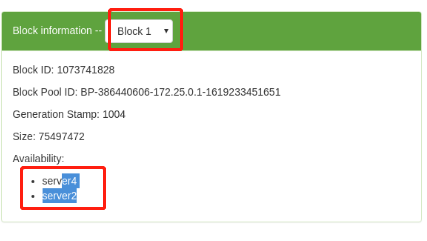
(6)Upload files to the distributed storage system for testing


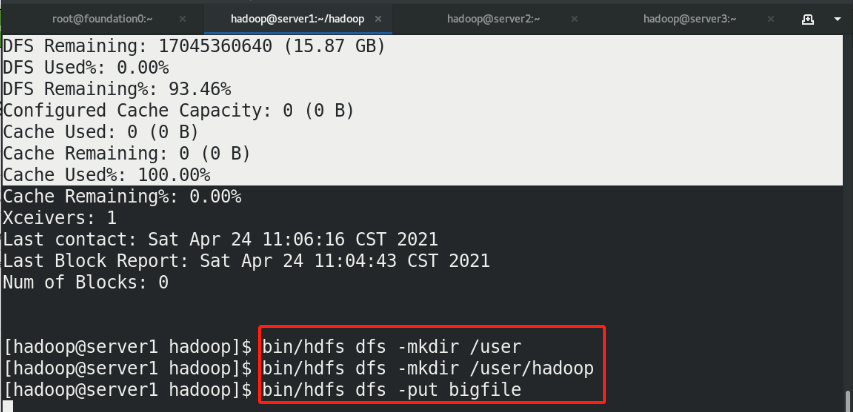
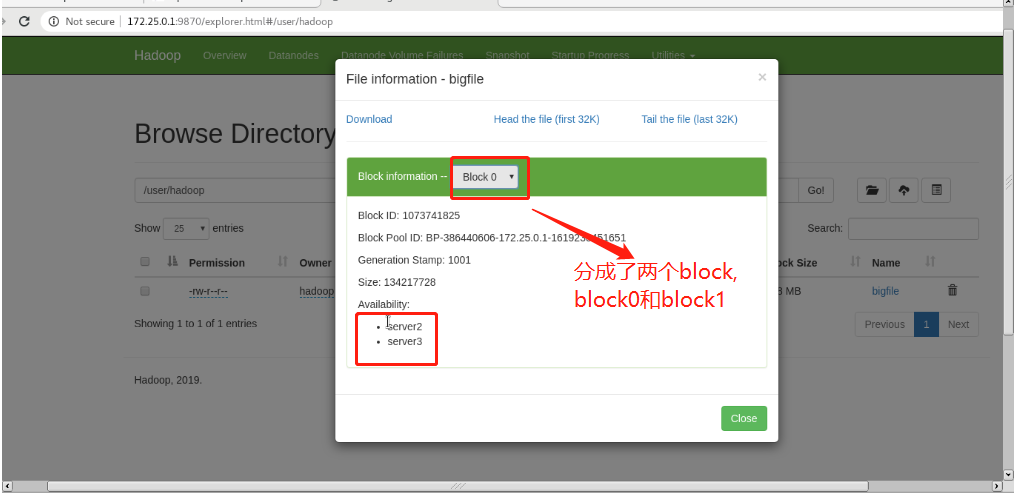
Web view:
(7)Node hot addition
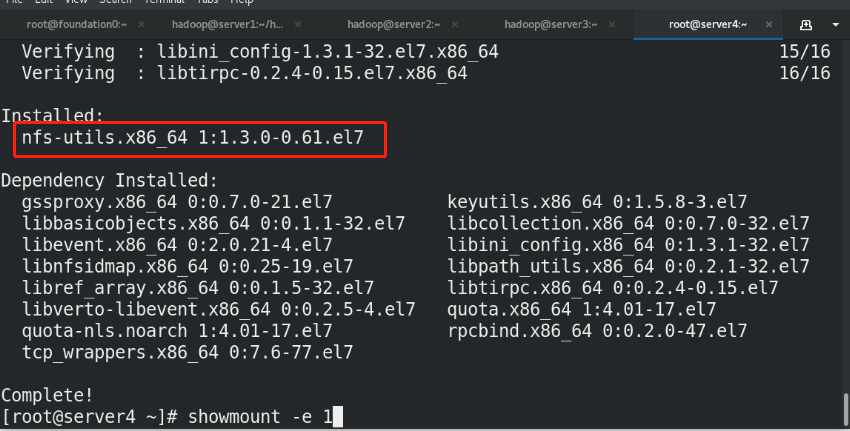
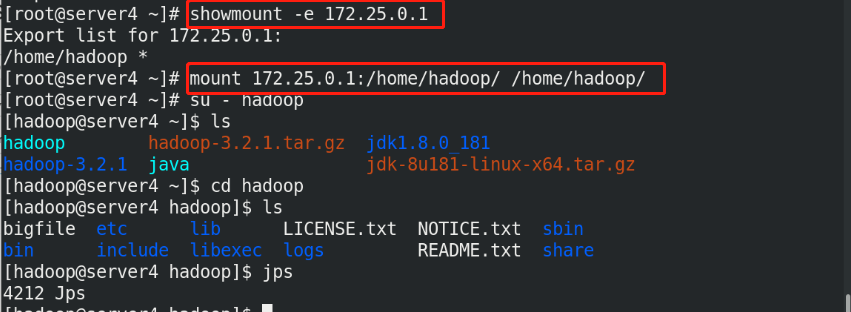
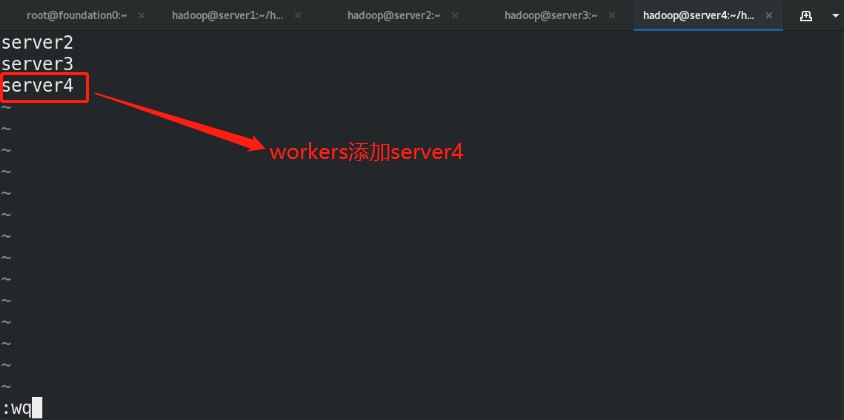

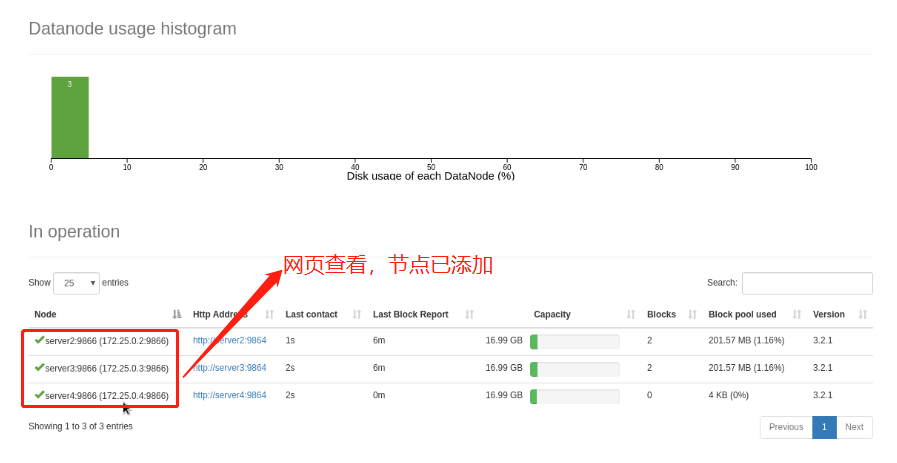
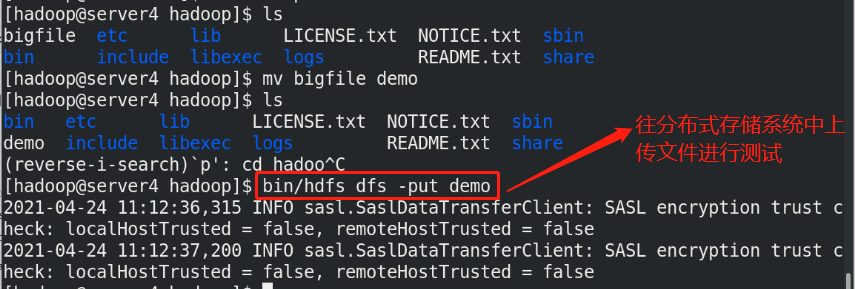
Note: the node on which the uplink will be preferentially assigned to