preface
It is planned to realize the speech synthesis function, convert text to speech, and support audition and saving functions. After a period of research, it is found that Sogou can be used, with a free quota of 1-2 million words:
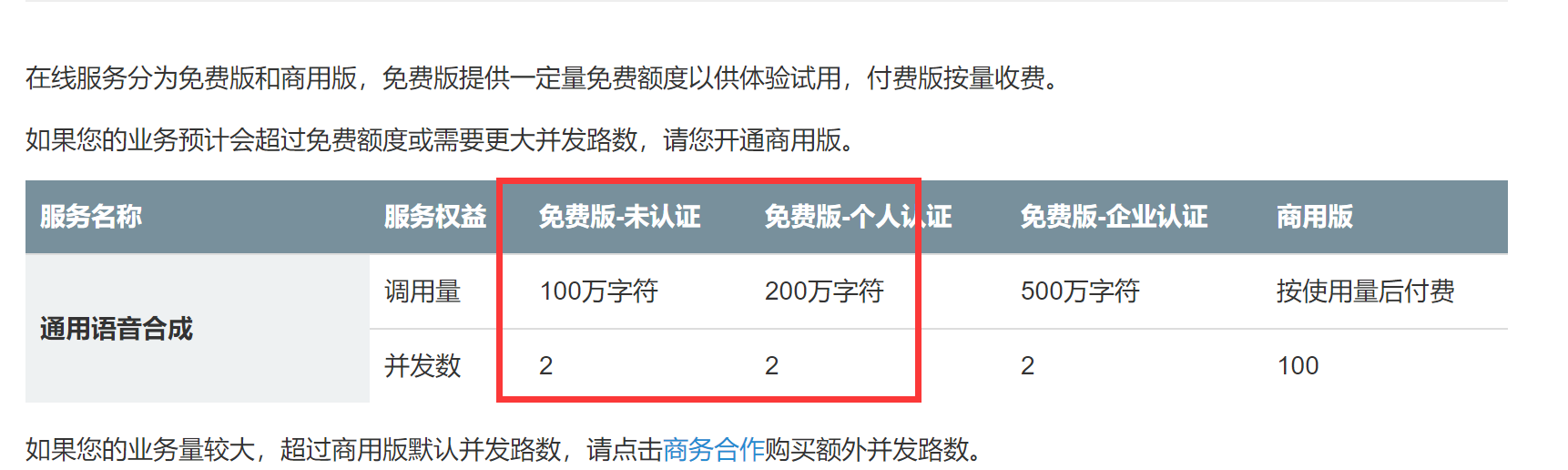
It is decided to connect with Sogou interface to complete these functions.
effect:

preparation
You can refer directly to the official guidelines: https://ai.sogou.com/doc/?url=/docs/content/overview/guides/
Registered account
Go to Sogou development platform( https://ai.sogou.com/ )Operate by yourself. After logging in, click a console button to enter:

Download litjason
There are many on the Internet. They are mainly used for transmission and data analysis. Download them by yourself.
##Get appid and key
Operation steps:
New app > fill in name > fill in description > check voice synthesis > check consent agreement > create app
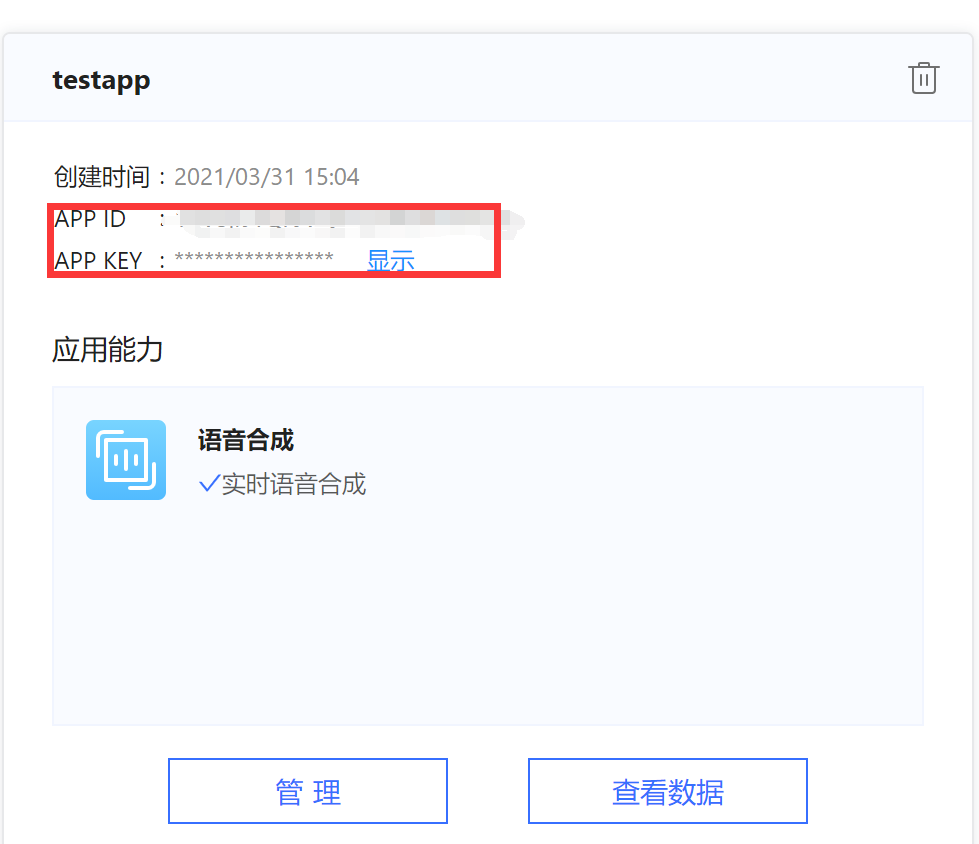
In this way, the appid and key are obtained and the backup is copied.
Function realization
In the previous step, we obtained "appid" and "appkey". When the script is initialized, we record it:
/*----------------------------------------||
|| ||
|| Appkey fill in appkey here||
|| ||
||----------------------------------------*/
string appid = "";
string appkey = "";
Please fill in this step by yourself.
Authentication and authentication
This process is the process of obtaining tokens. The code is as follows:
void GetToken() {
string url = "https://api.zhiyin.sogou.com/apis/auth/v1/create_token";
JsonData ReqParam = new JsonData();
ReqParam["appid"] = appid;
ReqParam["appkey"] = appkey;
ReqParam["exp"] = "3600s";
byte[] postBytes = System.Text.Encoding.Default.GetBytes(ReqParam.ToJson());
StartCoroutine(DoPost(url, postBytes, GetTokenDone));
}
void GetTokenDone(string str)
{
try
{
JsonData data = JsonMapper.ToObject(str);
token = data["token"].ToString();
endDate =DateTime.Parse(data["end_time"].ToString());
TTS();
Debug.Log("Get Token:" + token);
}
catch (Exception e)
{
Debug.LogWarning("GetToken Call exception:" + e);;
}
}
After obtaining the token, record it. Another is the effective time (endDate). After the effective time is exceeded, you need to obtain the token again.
speech synthesis
According to the selected sound, call the speech synthesis interface and pass in the input text, converted sound and other parameters, that is, the request of speech synthesis is completed.
The following is the predefined parameters according to the timbre list given on the official website and the language supported by each timbre, which are used to display the sound options and transmission parameters:
List<string> titles = new List<string>
{
"Kangge(in)", "Jingjing(in)", "Iowa (in)", "Wan Qing(in)",
"Xiyue(in)" , "A Xing(in)", "Qingfeng(in)", "Ruoxi(in)",
"Meng Xuan(in)", "Think(in)", "Handsome(in)", "Brother Bao(in)",
"Wan Zhen(in)", "Xiaoyu(in)", "elegant(in)", "Cuiping(in)",
"Qiang Zi(in)", "just like(in)", "Xiao Zhao(in)", "Yan Yan(in)",
"Xiao Zhi(in)", "Wan Ting(in)", "Yao Yao(in)","Male voice(Britain)",
"Female voice(China, Britain, Japan and South Korea)", "jack(Britain)", "Lily (Britain)"
};
List<string> Values = new List<string>
{
"kangge", "jingjing", "ahua", "wanqing",
"xiyue" , "axing", "qingfeng", "xf5",
"mengxuan", "sisi", "shuaishuai", "shanxi_male",
"sichuan_female", "henan_female", "hubei_female", "dongbei_female",
"guangpu_male", "taipu_female", "zhao", "yanyan",
"xiaozhi", "wanting", "yaoyao","male",
"female", "jack", "lily"
};
Core request code:
void TTS() {
if (string.IsNullOrEmpty(Ipt.text))
{
Debug.LogError("The input content cannot be empty!");
return;
}
string url = "https://api.zhiyin.sogou.com/apis/tts/v1/synthesize";
JsonData ReqParam = new JsonData();
ReqParam["input"] = new JsonData();
ReqParam["input"]["text"] = Ipt.text;
ReqParam["config"] = new JsonData();
ReqParam["config"]["audio_config"] = new JsonData();
ReqParam["config"]["voice_config"] = new JsonData();
ReqParam["config"]["audio_config"]["audio_encoding"] = "MP3";
ReqParam["config"]["audio_config"]["pitch"] = 1;
ReqParam["config"]["audio_config"]["volume"] = 1;
ReqParam["config"]["audio_config"]["speaking_rate"] = 1;
ReqParam["config"]["voice_config"]["language_code"] = "zh-cmn-Hans-CN";
ReqParam["config"]["voice_config"]["speaker"] = Values[VoiceSel.value]+ "-pro";//"male";
byte[] postBytes = System.Text.Encoding.Default.GetBytes(ReqParam.ToJson());
StartCoroutine(DoTTSPost(url, postBytes, TTSDone));
}
void TTSDone(byte[] bytes) {
try
{
//Debug.Log("return Audio:" + str);
VoiceBytes = bytes;
//ac.clip = GetAudioClipByBytes(bytes);
File.WriteAllBytes(VoiceUrl, bytes);
StartCoroutine(DoVioceClip());
OptBtns.SetActive(true);
}
catch (Exception e)
{
Debug.LogWarning("GetToken Call exception:" + e); ;
}
}
The official recommendation is to add "- pro" to the sound parameters. Users are welcome to use the new timbre code (add - pro). The new timbre greatly improves the sound quality and naturalness. At the same time, the original timbre code (without - pro) can still be used.
Select road strength to save
The general idea is to write the byte array according to the selected road strength:
File.WriteAllBytes(path, VoiceBytes);
You can refer to the previous article: Select path saving function
Audition function
This also wrote an article when doing research:
Unity3d C# implements the byte array byte [] of mp3 to AudioClip and plays it (including source code)