catalogue
I C + + header file and namespace
1. Naming method of header file and source file
(1) When including self defined header files
(2) When a standard library is included
3. Space problem of string input
4. Referenced application scenarios
(1) Function parameter passing (copy can be prevented)
(2) Function return value (increase the use of lvalues)
5.auto type (auto inference type)
(1) How to define variables with auto
1. Introverted thought (inline keyword)
I C + + header file and namespace
1. Naming method of header file and source file
Use h name the header file with cpp named source file
2. Inclusion method
(1) When including self defined header files
At this time, it is the same as C language. For example, we write a header file called "Tool". We can: #include "Tool.h"
(2) When a standard library is included
If it is a standard library containing C language, it can be written in C language, for example: #include < stdio h> It can also be removed Add C before h, like: #include < cstdio >.
3. Introduction of namespace
(1) Create namespace
namespace Space name
{
}(2) Role of namespace
In C language, the same identifier cannot be used in the same scope. For example, if you define a variable a, you can only use a variable called a in this scope. In C + +, the introduction of namespaces can increase the utilization of identifiers, that is, in the same scope, there can be two variables named a, but these two variables must come from different namespaces.
namespace A
{
int a = 0;
}
namespace B
{
int a = 1;
}
int main()
{
int b = A::a; //It is equivalent to assigning a to b, that is, b=0
int c = B::a; //Also assign a to a variable c, c=1
//A is assigned to a variable, but a comes from a different namespace
}(3) Namespace access
I How to access———— The scope identifier "::" is used here. Through the scope identifier, you can access the functions in the corresponding space and the variables in the corresponding space.
namespace Space name
{
int a = 0;
void print()
{
printf("hello");
}
}
int main()
{
Space name::a = 1001;
Space name::print();
}The print () function here is implemented in space. C + + supports declaration in space, and the specific functions of the function are implemented outside space. At this time, the function needs to indicate which namespace it is. The implementation method is as follows:
namespace Space name
{
int a = 0;
void print();
}
void Space name::print()
{
printf("hello");
}In addition, the scope identifier can also be used to identify global variables. When the variable names of global variables and local variables are the same, it can be distinguished by "::" because in C language, if you define a variable with the same name as the global variable locally, the locally defined variable will override the global by default and cannot be distinguished, while C + + can. The details are as follows:
int x = 1;
namespace Space name
{
int x = 2;
printf("%d", x); //What is printed here is the local variable, i.e. x = 2
printf("%d", ::x); //What is printed here is the global variable, i.e. x = 1;
}II using syntax
using namespace Space name;
After using, you can omit the prefix when using, but it has a scope. You can omit it only under this using , statement. The above cannot be used (and should be in the same brace). The details are as follows:
namespace Space name
{
int x = 2;
}
using namespace Space name;
int main()
{
x = 2;
}The ^ x ^ is the ^ X of the space name, but this practice may cause ambiguity, for example:
namespace A
{
int x = 2;
}
namespace B
{
int x = 1;
}
using namespace A;
using namespace B;
int main()
{
x = 2;//I don't know whose x is here, because both A and B have it, and VS will prompt "x is not clear"
}The space name can also be accessed nested. In short, it is three words - peel the onion! The details are as follows:
namespace A
{
int a = 2;
namespace B
{
int b = 1;
}
}
int main()
{
A::a = 1000;
A::B::b = 1001;
//You can do the same
using namespace A::B;
b = 1002;
}II Basic output input
The header file "iostream" containing the C + + standard input / output stream is required. The commonly used namespace is "std". It is generally written as follows:
#include <iostream> using namespace std;
1. Output
cout << Output content;
You can also print multiple, as follows:
#include <iostream>
using namespace std;
int main()
{
int a = 1;
char str[] = "I Love C++";
cout << a << str <<"\n";
}Line feed can also be implemented with "endl"
#include <iostream>
using namespace std;
int main()
{
cout << "\n";
cout << endl;
//Can realize line feed
}Forced type conversion can also be used for output. Note that the format of C language is a little different from that of C + +, but C + + can be compatible with the format of C language.
int main()
{
float a = 1.0f;
cout << int(a); //Writing method of C + +
cout << (int)a; //Writing method of C language
}2. Input
cin >> Input content;
Like output, you can also input multiple:
int main()
{
int a;
float b;
cin >> a >> b;
}3. Space problem of string input
In C + +, spaces are used as data intervals by default. It may not be understood here. Let's analyze the following cases:
#include <iostream>
using namespace std;
int main()
{
char str[10] = "";
cin >> str;
cout << str;
}When we input the string "I Love C + +", the output we want does not appear, but the following output (the first line is input and the second line is output):
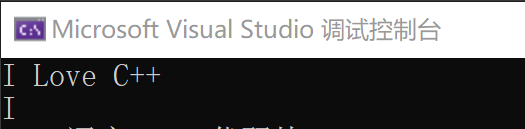
Another example:
int main()
{
char str[10] = "";
cin >> str;
cout << str;
char c;
cin >> c;
cout << c;
}Originally, we expected two inputs and outputs, but only once. This time, we still input the string "I Love C + +", but the result is still not what we expected. The details are as follows (the first line input and the second line output):

Analysis: Question 1: why only one 'I' is output in the first case?
Question 2: why is there no second input in the second case, but direct output?
Question 1:
I remember saying at the beginning that in C + +, spaces are used as data intervals by default. Therefore, in the "I Love C + +" we input, "I" is followed by a space, so "I" and "Love C + +" are different data, not the same string, so only "I" is saved in str, and naturally only "I" is output.
Question 2:
After understanding question 1, let's look at question 2. When the first round of input is completed, there is still a section of "Love C + +" in the buffer. Therefore, when the second cin, the first character "L" in the remaining section in the buffer is stored in character c, so there is no second section input, only output.
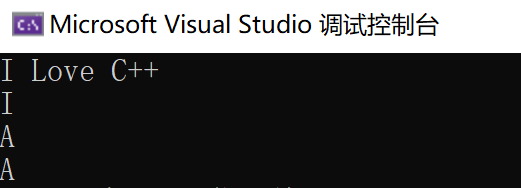
Therefore, after we know the cause of the problem, we can use the previous C language method to avoid the problem of "string or character input before input". The following is a case test (the first three behavior inputs and the second four behavior outputs).
int main()
{
char str[10] = "";
cin >> str;
cout << str;
while (getchar() != '\n');
char c;
cin >> c;
cout << c;
}
There are also solutions in C + +, but I'm just getting started and I'm not sure. I still need to continue to study hard!
How do we complete the input with spaces? C + + functions can be used, as follows:
int main()
{
char str[11] = "";
cin.getline(str, 11);
cout << str;
}Here are the inputs and outputs:

You can see that this is normal!
III New data type
1.bool type
I Occupy one byte.
II As long as it is non-zero, it means true, and only 0 or when the pointer is empty, it means false.
III Application scenario: it generally acts as a return value and a switch.
IV You can assign values with true and false.
bool a = true; a = false;
V Normal printing can only print 0 and 1, but it can also print with true and false.
bool a = true; cout << a <<endl; cout << boolalpha << a;
Print as follows:

2. Null pointer nullptr
int* p = nullptr;
C language uses NULL to express, C + + can both, but NULL can also express 0. In some cases (such as function parameter passing), problems may occur. nullptr# can be said to be "special people do special things".
3. Reference type
Here, it is better to understand the reference type as "alias", not as a pointer.
(1) Basic reference
type& alias = Something that needs an alias; //for example int a = 1; int& b = a;
Note: basic references can only give aliases to things already defined, and cannot easily give aliases to constant areas.
int& a = 1;//In this way, the compiler will report an error
So we can do this:
const int& a = 1;
In this way, the compiler will not report errors. In fact, C + + has a special way to reference "R-value", which is to be introduced next. As for the difference from the above, first press the table below and then analyze it.
(2) Often cited
Often referred to, also known as "right value reference".
type&& alias = The right value of the alias to be used; int&& a = 1;
Since it is called an R-value reference, you can only alias the R-value, and ordinary variables will report an error.
int a = 1; int&& b = a; //Compilation error
4. Referenced application scenarios
(1) Function parameter passing (copy can be prevented)
All function parameters in C language can be understood as assignment. Here are some examples:
void modifyA(int a)
{
a = 1001;
}Through learning C language, we know that calling this function can not modify the value of the passed in argument. In fact, it is because what is passed in is not the value, but the "copy" of the value. What is modified in the function is only its copy, which can not really affect the actual parameters. In fact, it is the same reason to modify the pointer, which is to pass the "copy", Copy into an address, and then modify the value corresponding to this address in the function to achieve the purpose.
What about the quote? Let's look at the following example:
void modifyB(int& a)
{
a = 1001;
}What is passed in at this time is the alias of a parameter, and the alias is itself, so it can be understood as passing an argument.
Another example here will be easier to understand. The purpose of the following function is to realize "modify pointer pointing":
int num = 1;
void modifyPointA(int* p)
{
p = #
}Obviously, we can't achieve this goal. Similarly, from the perspective of assignment, what we pass in is the "copy" of the pointer, and what we modify is the direction of the copy, which does not affect the original pointer, but what if it is a reference?
int num = 1;
void modifyPointB(int*& p)
{
p = #
}What is passed here can be understood as the pointer that wants to be modified, so it can be modified successfully.
Remember the saying "don't understand as a pointer" at the beginning, because some places may be understood as a pointer, but like the above paragraph "int * & p", if it is understood as a pointer, '*' and '&' will not offset? How do you understand that?
Then fill in the hole buried in front. The difference between const int & a , and int & & a ,. Code!
void modifyA(int&& a)
{
a += 11;//Can be modified
cout << a;
}
void modifyB(const int& a)
{
a += 11;//It will report an error and prompt you that "the expression must be a modifiable lvalue"
cout << a;
}The difference between them is that they act as function parameters. It can be seen that what is passed in is a constant reference, which can be modified without error. But does the modification really change the original constant? In fact, it is not. It can be understood here that an interface for modifying the right value is provided in the function. The modification will not change the original value of A. for example, if we pass 1 in, it may be changed to 12 in this function, but it is still it, 1 or 1 out of this function. In the second function, const , means read-only. Naturally, if it cannot be modified, an error will be reported.
(2) Function return value (increase the use of lvalues)
What do you mean? Look at the code first!
int num = 1;
int getData()
{
return num;
}
int main()
{
getData() = 1001;//An error will be reported, which will tell you that "the expression must be a modifiable lvalue"
return 0;
}
It can be seen that the return value of previous functions is "right value", that is, "all are determined values".
But the returned reference is a modifiable lvalue!
int num = 1;
int& getValue()
{
return num;
}
int main()
{
getValue() = 1001;
cout << num;
return 0;
}The printing results are as follows:

It can be seen that not only can it be modified, but also the modified result actually works on num, so we can understand it this way: the return reference is equivalent to the return variable itself!
5.auto type (auto inference type)
(1) How to define variables with auto
auto a;//If you can't define it like this, an error will be reported auto b = 1;//b is inferred as an integer type
auto # will infer the type of the variable to be defined according to the type assigned later, which is very convenient.
(2) auto is widely used
Here's an example to better understand its convenience:
void Fun1(int a, int b)
{
//Any function
}
void Fun2(int(*Fun1)(int,int),int a,int b)
{
//Any function that wants to pass Fun1 as an argument
}Now we want to define a function pointer pointing to Fun2. The method in C language is as follows:
void(*p)(int(*)(int, int), int, int) = Fun2;
auto in C + + is like this:
auto p = Fun2;
It can be seen that using auto has brought us a lot of convenience!
IV Function thought
1. Introverted thought (inline keyword)
What function can be called introverted?
The compiled code of this function exists directly in binary form, which can be called introverted. The introverted function is "space for time", which runs very fast. Functions defined in classes and structs are introverted by default. Generally, functions that are used more and are short and concise can be defined as introverted functions. It is defined as follows:
inline void Fun1()
{
//Any function
}2. Function overloading
In C + +, functions with the same name and different parameters are allowed to exist. In C language, the same name is not allowed.
Such functions are:
(1) The number of parameters is different;
(2) Different parameter types;
(3) The order of parameters is different; (based on different types)
int print(int a, int b)
{
}
int print(char a, int b)
{
}
int print(int a, char b)
{
}When calling overloaded functions, the functions with the same type shall be called first.
3. Function default
In C + +, it is allowed to initialize function parameters, but the order must be from right to left:
int Fun1(int a = 1, int b)//Will report an error
{
}
int Fun2(int a = 1, int b = 2)//No error will be reported
{
}How to understand function default? It can be understood as a comprehensive writing method of overloading.
int Fun(int a = 1, int b = 2, int c = 3)
{
}
int main()
{
Fun(); //a = 1,b = 2,c = 3
Fun(10); //a = 10,b = 2,c = 3
Fun(10, 20); //a = 10,b = 20,c = 3
Fun(10.20,30);//a = 10,b = 20,c = 30
}
The value passed in will overwrite the initialized value. If it is not passed in, it will remain unchanged.
For beginners of C + +, there may be some wrong explanations. Welcome to communicate and correct with the big guys passing by!!!