1. Document analysis
analysis includes the following processes:
- Dividing a piece of text into independent entries suitable for inverted indexing;
- Unify these entries into a standard format to improve their "searchability", or recall;
when the analyzer performs the above work, it actually encapsulates three functions into a package:
- Character filter
- First, the string passes through each character filter in order. Their task is to sort out strings before word segmentation. A character filter can be used to remove HTML or convert & to and.
- Tokenizer
- Secondly, the string is divided into a single entry by the word splitter. When a simple word splitter encounters spaces and punctuation, it may split the text into entries.
- Token filter
- Pass each entry in the order of token. This process may change entries (for example, lowercase Quick), delete entries (for example, useless words such as a, and, the), or add entries (for example, synonyms such as jump and leap).
1.1 built in analyzer
Elasticsearch also comes with a prepackaged analyzer that can be used directly. Next, we will list the most important analyzers. To prove the difference, let's see which terms each parser will get from the following string:
"Set the shape to semi-transparent by calling set_trans(5)"
- Standard analyzer
- The standard analyzer is the analyzer used by Elasticsearch by default. It is the most commonly used choice for analyzing various language texts. It divides the text according to the word boundary defined by the Unicode Union, removes most punctuation, and finally lowercases the entry. It produces:
set, the, shape, to, semi, transparent, by, calling, set_trans, 5
- The standard analyzer is the analyzer used by Elasticsearch by default. It is the most commonly used choice for analyzing various language texts. It divides the text according to the word boundary defined by the Unicode Union, removes most punctuation, and finally lowercases the entry. It produces:
- Simple analyzer
- The simple parser separates text wherever it is not a letter and lowercases entries. It produces:
set, the, shape, to, semi, transparent, by, calling, set, trans
- The simple parser separates text wherever it is not a letter and lowercases entries. It produces:
- Space Analyzer
- The Space Analyzer divides text in spaces. It produces:
Set, the, shape, to, semi-transparent, by, calling, set_trans(5)
- The Space Analyzer divides text in spaces. It produces:
- Language analyzer
- The language specific analyzer can be used in many languages. They can consider the characteristics of the specified language. For example, the English analyzer comes with a set of useless English words (common words, such as and or the, which have little effect on relevance), which will be deleted. Due to the understanding of the rules of English grammar, this word splitter can extract the stem of English words.
- The English word splitter will produce the following entries:
set, shape, semi, transpar, call, set_tran, 5
Pay attention to transparent, calling and set_trans has been changed to root format.
1.2 analyzer usage scenario
when we index a document, its full-text field is analyzed into terms to create an inverted index. However, when we search in the full-text domain, we need to pass the query string through the same analysis process to ensure that the entry format we search is consistent with that in the index.
full text queries understand how each domain is defined, so they can do the right thing:
- When you query a full-text domain, the same parser will be applied to the query string to generate the correct list of search terms;
- When you query an exact value field, you will not analyze the query string, but search the exact value you specify.
1.3 test analyzer
sometimes it's hard to understand the process of word segmentation and the entries actually stored in the index, especially when you just came into contact with Elasticsearch. To understand what is happening, you can use the analyze API to see how the text is analyzed. In the message body, specify the analyzer and the text to be analyzed:
GET http://localhost:9200/_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}
each element in the result represents a separate entry:
{
"tokens": [
{
"token": "text",
"start_offset": 0,
"end_offset": 4,
"type": "<ALPHANUM>",
"position": 0
},
{
"token": "to",
"start_offset": 5,
"end_offset": 7,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "analyze",
"start_offset": 8,
"end_offset": 15,
"type": "<ALPHANUM>",
"position": 2
}
]
}
token is the term actually stored in the index. Position indicates where the entry appears in the original text. start_offset and end_offset indicates the position of the character in the original string.
1.4 specify analyzer
when Elasticsearch detects a new string field in your document, it will automatically set it as a full-text string field and analyze it with a standard analyzer. You don't want to be like this all the time. Maybe you want to use a different parser for the language your data uses. Sometimes you want a string field to be a string field (without analysis), which directly indexes the exact value you pass in, such as user ID or an internal status field or tag. To do this, we must manually specify the mapping of these domains.
1.5 IK word splitter
first, we send a GET request through Postman to query the word segmentation effect:
# GET http://localhost:9200/_analyze
{
"text":"Test words"
}
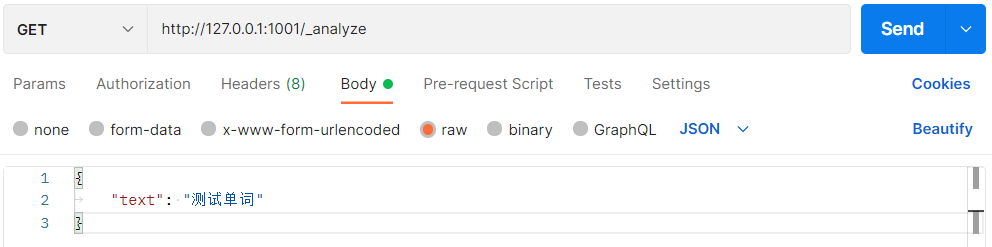
the default word splitter of ES cannot recognize words such as tests and words in Chinese, but simply divides each word into one word:
{
"tokens": [
{
"token": "measure",
"start_offset": 0,
"end_offset": 1,
"type": "<IDEOGRAPHIC>",
"position": 0
},
{
"token": "try",
"start_offset": 1,
"end_offset": 2,
"type": "<IDEOGRAPHIC>",
"position": 1
},
{
"token": "single",
"start_offset": 2,
"end_offset": 3,
"type": "<IDEOGRAPHIC>",
"position": 2
},
{
"token": "Words",
"start_offset": 3,
"end_offset": 4,
"type": "<IDEOGRAPHIC>",
"position": 3
}
]
}
this result obviously does not meet our use requirements, so we need to download the Chinese word splitter of the corresponding version of ES.
we use IK Chinese word segmentation here. The download address is: https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.17.0
put the unzipped folder into the plugins directory under the root directory of ES, and restart es to use it.
this time, we add a new query parameter "analyzer":"ik_max_word".
# GET http://localhost:9200/_analyze
{
"text":"Test words",
"analyzer":"ik_max_word"
}
- ik_max_word: the text will be split at the finest granularity;
- ik_smart: it will split the text at the coarsest granularity;
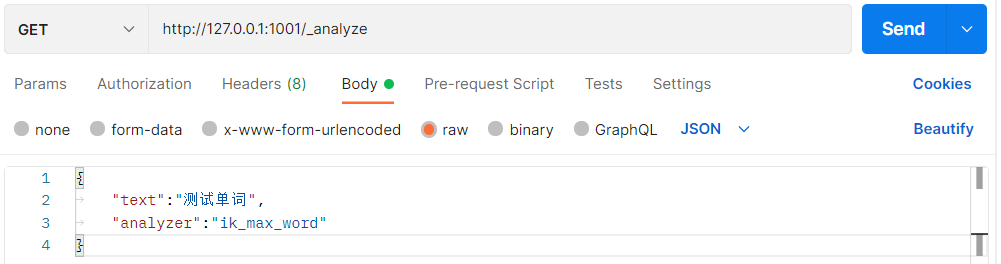
the result of using Chinese word segmentation is:
{
"tokens": [
{
"token": "test",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "word",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
}
]
}
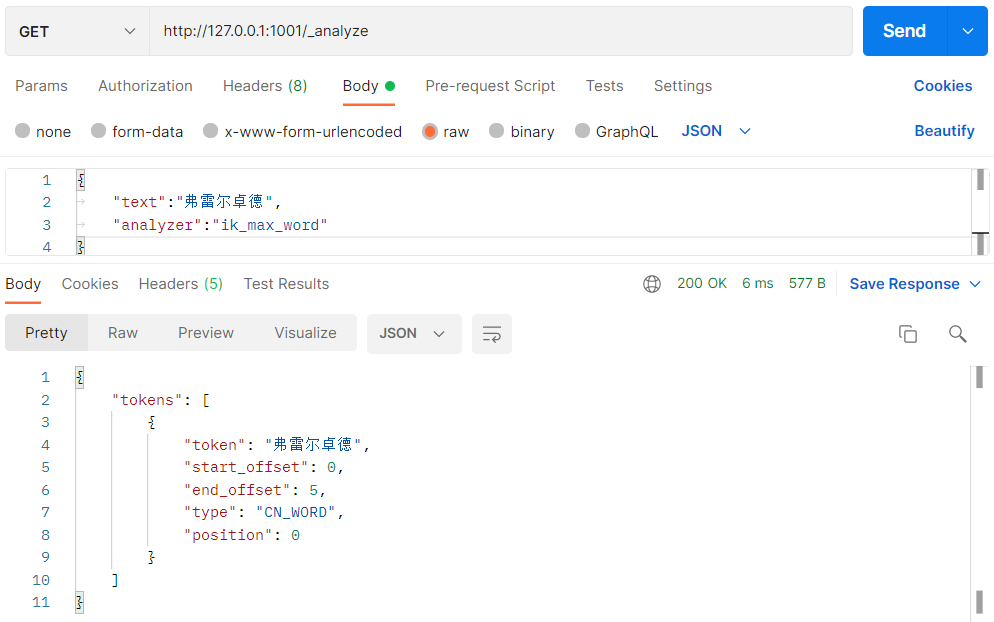
ES can also expand vocabulary. First query:
# GET http://localhost:9200/_analyze
{
"text":"Freldrod",
"analyzer":"ik_max_word"
}
we can only get the word segmentation result of each word. What we need to do is to make the word splitter recognize that fredrode is also a word:
{
"tokens": [
{
"token": "Fu",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "thunder",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "Er",
"start_offset": 2,
"end_offset": 3,
"type": "CN_CHAR",
"position": 2
},
{
"token": "Outstanding",
"start_offset": 3,
"end_offset": 4,
"type": "CN_CHAR",
"position": 3
},
{
"token": "virtue",
"start_offset": 4,
"end_offset": 5,
"type": "CN_CHAR",
"position": 4
}
]
}
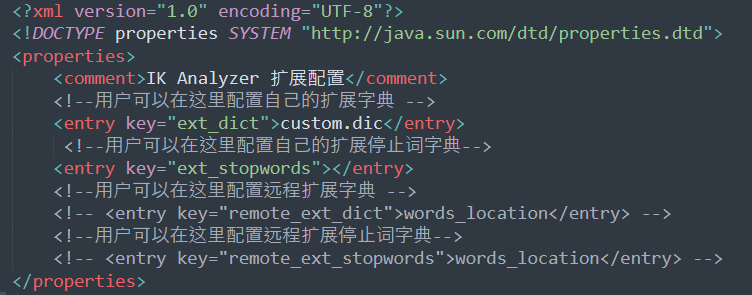
first enter the ik folder under the plugins folder in the ES root directory, enter the config directory, and create custom DIC file, write to freldrod. Open ikanalyzer at the same time cfg. XML file to create a new custom. XML file DIC configuration, where the ES server is restarted.
1.6 custom analyzer
although Elasticsearch has some ready-made analyzers, the real strength of Elasticsearch in analyzers is that you can create self-defined analyzers by combining character filters, word separators and lexical unit filters in a setting suitable for your specific data. In analysis and analyzer, we said that an analyzer is a wrapper that combines three functions in a package, and the three functions are executed in order:
- Character filter
- The character filter is used to sort out a string that has not been segmented. For example, if our text is in HTML format, it will contain HTML tags such as < p > or < div >, which we don't want to index. We can use the HTML clear character filter to remove all HTML tags, and like & Aacute; Convert to the corresponding Unicode character Á. In this way, convert HTML entities. A parser may have 0 or more character filters.
- Tokenizer
- An parser must have a unique word breaker. A word splitter decomposes a string into a single entry or lexical unit. The standard word splitter used in the standard analyzer decomposes a string into a single entry according to the word boundary, and removes most of the punctuation. However, there are other word splitters with different behaviors.
- For example, the keyword separator completely outputs the same string received without any word segmentation. The space participle splits text only based on spaces. The regular word splitter splits text based on matching regular expressions.
- Word unit filter
- After word segmentation, the resulting word unit stream will pass through the specified word unit filter in the specified order. Word unit filters can modify, add, or remove word units. We have already mentioned lowercase and stop word filters, but there are many word unit filters to choose from in elastic search. Stem filters contain words as stems. ascii_ The folding filter removes diacritical notes and converts a word like "tr è s" to "tres". ngram and edge_ The ngram word unit filter can generate word units suitable for partial matching or automatic completion.
next, let's look at how to create a custom analyzer:
# PUT http://localhost:9200/my_index
{
"settings": {
"analysis": {
"char_filter": {
"&_to_and": {
"type": "mapping",
"mappings": [ "&=> and "]
}},
"filter": {
"my_stopwords": {
"type": "stop",
"stopwords": [ "the", "a" ]
}},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [ "html_strip", "&_to_and" ],
"tokenizer": "standard",
"filter": [ "lowercase", "my_stopwords" ]
}}
}}}
after the index is created, use the analyze API to test the new analyzer
# GET http://127.0.0.1:9200/my_index/_analyze
{
"text":"The quick & brown fox",
"analyzer": "my_analyzer"
}
the following abbreviated results show that our analyzer is running correctly:
{
"tokens": [
{
"token": "quick",
"start_offset": 4,
"end_offset": 9,
"type": "<ALPHANUM>",
"position": 1
},
{
"token": "and",
"start_offset": 10,
"end_offset": 11,
"type": "<ALPHANUM>",
"position": 2
},
{
"token": "brown",
"start_offset": 12,
"end_offset": 17,
"type": "<ALPHANUM>",
"position": 3
},
{
"token": "fox",
"start_offset": 18,
"end_offset": 21,
"type": "<ALPHANUM>",
"position": 4
}
]
}