I'm kangarooking, not my brother's brother. An Internet worm "gua" cow, sincerely share experience and technical dry goods. I hope my article is helpful to you. Pay attention to me and make a little progress every day ❗ ❗ ❗
preface
This article is applicable to the following groups:
- The old fellow who wanted to change jobs recently.
- Brothers who review or learn concurrentHashMap for the first time;
- Want to dig through the volume king of the source code of concurrentHashMap.

Tip: before reading this article, you'd better have a certain understanding of the principle of hashMap
The following contents are some experiences and conclusions drawn from the emperor's repeated reading and debug source code. Iron people can eat at ease, and children and old people are not deceived ~.
This article covers knowledge:
- cas optimistic lock
- synchronized lock upgrade
- volatile keyword
- Binary conversion and operation
Mock interview
Here are some common questions about ConcurrentHashMap in interviews.
Cut the crap and go straight to work.
Interviewer: what's wrong with HashMap? Why should there be concurrent HashMap?
Me: as far as I know, hashMap thread is dangerous and concurrent hashMap thread is safe
Unsafe places of hashMap thread:
- jdk1.7 may cause link and data loss;
- jdk1.8. There will be the problem of data coverage.
jdk1. hashMap under 8:
- Overlay header node: when thread a and thread b simultaneously judge that there is no node in the same subscript (null), the time slice of thread a ends, thread b executes, thread b inserts a node in the subscript, and then thread a resumes execution, and a will directly overlay the node inserted by b;
- Overwrite size: after the put operation is completed, the number of nodes in the map is calculated using + + size. Threads a and b will get the current size=10 at the same time, and then thread a +1 size = 11. When thread b+1 size = 11.
Interviewer: do you know how concurrent HashMap ensures thread safety?
I: many variables of ConcurrentHashMap are decorated with volatile to ensure visibility under multithreading and prohibit instruction reordering. However, volatile does not guarantee atomicity, so cas optimistic lock and synchronized keyword are introduced to ensure atomicity.
Interviewer: how does it go?
Me: first calculate the hash value of the key, and then there is a for(;) As the spin operation of cas, the loop inside for initializes the table array by cas first, then calculates a subscript position through the hash value of key and the capacity of the array, adds a synchronized lock to the chain header node at the subscript, and then performs subsequent operations.
Interviewer: why do these two places use different locks? Why are they designed like this?
Me: cas is a lightweight lock, which is a simple process of comparison and replacement, and the process instructions are completed at the cpu level, so it is very efficient. Because the table is initialized only once, even in the case of fierce multi-threaded competition, as long as one thread is initialized successfully, the competition will end directly, and there will be no case that some threads can't grab the lock and waste cpu all the time. Why add synchronized in the header node? Because if the whole table is locked, other threads have to wait for all the put operations of one thread to complete before they can execute the put operation. The efficiency of program operation will be greatly reduced. If it is added to each node, when traversing the linked list, each node must be locked and unlocked, and the competition at the node is not fierce, which wastes performance. Therefore, adding it to the head node of the subscript will not affect the operation of other threads on other subscripts, and can ensure the thread safety of the whole linked list under the same subscript. It can be said that the granularity of locking is just good.
CAS calls the CAS method of Unsafe class of java, which is a native method (implemented in c + +), and the underlying implementation completes CAS operation at CPU level through cmpxchgl this instruction. A lock instruction needs to be added under multi-core; lock cmpxchg to ensure atomicity; The lock instruction locks the cache line or bus of the CPU
synchronized has been optimized for lock upgrade in java8, and it is a jvm level lock. Compared with the lock implemented in Java, it is closer to the operating system, so its performance is not poor.
Interviewer: how is the capacity of concurrent HashMap expanded?
I: for multi-threaded capacity expansion, putVal method has two entries for capacity expansion method. One is to judge whether other threads are currently expanding capacity before locking the head node, and if so, help with capacity expansion. The other is to determine whether the current capacity needs to be expanded or to help with the expansion in the method of counting the size after the node is added. During capacity expansion, the method of segmented capacity expansion is adopted. The size of each segment is 16 (the minimum is 16). Each thread obtains a segment of data to be processed from the back to the front according to the size of the segment for transfer.
Example: the current capacity is 64. There are three threads a, b, c and a. the first one starts to expand the capacity. A will first create a new array twice the size of the original array, that is, a new array with a capacity of 128, and then successively obtain the elements of the subscripts 63 ~ 47 (63, 62, 61... Obtained in this way) of the original array and transfer them to the new array. At this time, when thread b finds that a thread is expanding during put, it will help expand the capacity. Thread b will obtain the elements of the subscripts 47 ~ 31 of the original array for transfer. Where to transfer to the new array? It is obtained through simple calculation according to the hash value of the key (instead of rehash, which is also an optimization point, which will be discussed later). After calculation, it is either placed at the subscript position of the original array or at the subscript position of the original array + the capacity of the original array.
Interviewer: how does concurrent HashMap record size?
I: in the putVal method, the key value of put has been successfully put into the map, and then the operation of + 1 on size is started. In order to ensure thread safety, concurrentHashMap uses cas to accumulate baseCount. In order to prevent threads from losing cas and wasting cpu in the case of fierce multi-threaded competition, another method is introduced
The counter cell [] object array allows the thread that fails the competition to obtain an object in the object array, and then increase the value of a variable value in the object (the value is also increased by cas). Finally, the size value of the whole map is the sum of the value values of each counter cell object in the basecount + counter cell [] array. The advantage of this design is to use the idea of segmented locking to allocate the competition to each CounterCell object, so as to improve the efficiency of program operation.
Interviewer: what is the role of sizeCtl, the variable of concurrentHashMap?
I: between multiple threads, read the sizeCtl attribute modified by volatile to judge the current state of ConcurrentHashMap. Set sizeCtl attribute through CAS to inform other threads of the status change of ConcurrentHashMap. So sizeCtl is a variable that identifies the state of ConcurrentHashMap.
sizeCtl has different meanings in different states:
- Uninitialized: sizeCtl=0: indicates that no initial capacity is specified. Sizecl > 0: indicates the initial capacity.
- Initializing: sizeCtl=-1, marking function, informing other threads that initialization is in progress
- Normal state: sizeCtl=0.75n, capacity expansion threshold
- During capacity expansion: sizectl < 0: indicates that other threads are performing capacity expansion
- sizeCtl = (resizeStamp(n) << RESIZE_ STAMP_ Shift) + 2 indicates that only one thread is performing capacity expansion at this time
After the interview, the interviewer found the leader and said, "brother Ming, this guy is good today. Those people who came before were won by me with two moves of ConcurrentHashMap. Today, it's hard to distinguish between me and him. I think it's him?". Leader: "Xiao Gou, I forgot to tell you. President Li brought someone here this morning and occupied the pit. Now there is no need to recruit people." Interviewer: "OK." The interviewer's inner activity: "ha ha, ha ha, great, it's been two months. Today is finally over. Go back to Wuhei to celebrate tonight".
After a week, I said, "wc, I shouldn't. I'm very good at this one. I basically answered all the questions. What's the situation ❓ ❓ ❓” gg

Hahaha, don't think what I said above is fictional. I'm sure this similar plot must often happen in reality. Art comes from life. So I want to say that the interview still depends on fate. Don't be discouraged because you have met many families, or you feel good about the interview and can't get an offer. This family can't go out and turn right to the next one. Keep an ordinary mind and stick to it. Remember not to go to any one because of anxiety. You must believe that there is a better choice waiting for you.
Source code analysis
We mainly focus on the source code of put method. Before formally introducing the put method, let's first some methods called in Kangkang put method.
1. Calculate hash value:
static final int HASH_BITS = 0x7fffffff; // usable bits of normal node hash
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
On the basis that the original HashMap shifts the hashCode value to the right by 16 bits, another hash is & created_ Bits (which is different from HashMap), 7fff converted to binary:
0111 1111 1111 1111 1111 1111 1111 1111
The highest bit is 0, which is to make (H ^ (H > > > 16)) & hash_ The highest bit of bits value is always 0, which means that the final hash value is always positive (the positive and negative number of binary is determined by the highest bit, the highest bit is 0 is positive, and the highest bit is 1 is negative). Because some identifiers with negative hash value are defined in ConcurrentHashMap, the hash value calculated normally must be positive if it is to be distinguished from it.
static final int MOVED = -1; // hash for forwarding nodes static final int TREEBIN = -2; // hash for roots of trees static final int RESERVED = -3; // hash for transient reservations
2. Initialization (initTable method)
When put, determine whether the array is null or the length is 0, and then perform the initialization operation
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
//Loop to determine whether the array is empty or the length is 0
while ((tab = table) == null || tab.length == 0) {
//If czetl = - sizetl is initializing
//sizeCtl here cannot be less than - 1, because if it is expanding, it will not enter this logic
//Judge and assign sizeCtl to sc
if ((sc = sizeCtl) < 0)
//If there are other threads initializing, the current thread will give up the cpu
Thread.yield(); // lost initialization race; just spin
//If no other thread is initializing, cas will compete for the right to initialize
//That is, compare whether sizeCtl (memory value) and SC (expected value) are equal. If they are equal, assign sizeCtl to - 1
//And return true, otherwise return false
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
//Here again, judge whether the array is null or length is 0
//After the first thread initializes the array, other threads are prevented from entering the next loop to repeat initialization
if ((tab = table) == null || tab.length == 0) {
//Here, judge whether to use the default capacity or the initial capacity set by the developer
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
//Create array
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//Calculate the capacity expansion threshold (equivalent to total capacity * 0.75)
sc = n - (n >>> 2);
}
} finally {
//Assign the expansion threshold to sizeCtl
sizeCtl = sc;
}
break;
}
}
return tab;
}
Summary: the initialization operation of ConcurrentHashMap is to initialize the array. If the initial size is not set, the default size is 16. Initialization uses sizeCtl as an identifier to determine whether other threads are initializing. cas optimistic lock and double detection mechanism are used to ensure thread safety and efficiency.
put k v (putVal method)
putVal method will be called inside the put method
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
//initialization
tab = initTable();
//If current subscript = null
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//Then the cas optimistic lock is directly used to store the header node
//Why not use synchronized here? My understanding is that the operation of storing header nodes is simple and fast (that is, the spinning time of other threads is short)
//The cpu is not wasted, and the resource competition is not so fierce, because the header node of each subscript will be set only once.
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//If the hash value of the current header node is MOVED=-1, it means
//The current node has been migrated and is being expanded
else if ((fh = f.hash) == MOVED)
//Go and help expand the capacity
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//Here is the judgment. If the header node is not empty, add synchronized
//The reason why synchronized is added here is that the operation logic of the current code block is complex
//(the main logic here is the operation of linked list or red black tree)
//When the execution is relatively slow and the hash conflict is higher, the resource competition is fierce
//At this time, if cas is used, other threads may not get the lock for a long time
//Lead to waste of cpu
//Here, only the header node of a certain subscript is locked, and the operation of other subscripts will not be affected.
synchronized (f) {
if (tabAt(tab, i) == f) {
//A hash value greater than or equal to 0 indicates that the current node is a linked list structure
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//Otherwise, it is judged to be a red black tree
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
//Judge whether the length of the node reaches 8
if (binCount >= TREEIFY_THRESHOLD)
//Transform the red black tree structure
//Of course, it also needs to judge whether the array capacity has reached 64
//If it does not reach 64, it will be solved by capacity expansion
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//Recalculate the total number of elements, that is, size
//binCount, which records the length of the linked list of the subscript where key value is located or the number of elements in the red black tree.
addCount(1L, binCount);
return null;
Summary: putVal method uses a for (Node < K, V > [] tab = table;) Infinite loop as the spin operation of cas. After obtaining the subscript through the hash value &n, first judge whether the subscript is null. If it is null, directly put the subscript and break out the loop. If there is a header Node, get the hash value of the header Node. If its hash value = = MOVED, it indicates that the header Node is a transfer Node, so go to help expand the capacity first. Otherwise, lock the head Node directly, and finally put the new Node object generated by key value into the linked list or red black tree. Finally, add up the size by 1.

Come on, the difference between excellent and ordinary is that they can do what others can't, such as continuing to read code that others can't see. ☔ ⛅ 🌈
size accumulation 1 (addCount method)
Add 1 to the value of an object in baseCount or CounterCell [].
private transient volatile long baseCount;
@sun.misc.Contended static final class CounterCell {
volatile long value;
CounterCell(long x) { value = x; }
}
Analysis of addCount method
private final void addCount(long x, int check) {
ConcurrentHashMap.CounterCell[] as; long b, s;
//Judge whether counterCells is empty,
//1). No matter whether it is empty or not, it will first try to modify the baseCount variable through cas operation and perform atomic accumulation operation on this variable (Note: if there is no competition, baseCount is still used to record the number of elements)
//2). If the cas record fails this time, it indicates that there is competition. Instead of using baseCount to accumulate, use the object array of CounterCell [] to record
//Understanding: in fact, it is to accumulate baseCount by cas first. If the accumulation fails, it means there is competition, and then use counter cell [] as a segmented locking method
//To improve the processing efficiency in the case of fierce multi-threaded competition. The implementation of LongAdder, another tool under juc, is similar.
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
ConcurrentHashMap.CounterCell a; long v; int m;
boolean uncontended = true;
//Here are a few judgments
//1. If the count table is empty, call fullAddCount directly
//2. Randomly take out an array from the count table whose position is empty, and directly call fullAddCount
//3. Modify the value of counter cell random location through CAS. If the modification fails, it indicates concurrency (another ingenious method is used here), and call fullAndCount
//Random will have performance problems when threads are concurrent and may produce the same random number. Threadlocalrandom Getprobe can solve this problem, and its performance is higher than random
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
//CounterCell [] initializes with a default capacity of 2 and fills in two CounterCell objects with a value of 0
fullAddCount(x, uncontended);
return;
}
/**
* if (check <= 1)
* The premise of executing this code is that the program enters this judgment if ((as = countercells)= null || ! U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x))
* Entering this judgment represents the current countercells= Null or cas atom accumulation fails - the thread competition is fierce. Under such fierce competition, if the length of the linked list of the current node is less than or equal to 1, it proves that there is still a lot of space left at present
* This time, we will return directly. There is no need to check whether the capacity is expanded
*/
if (check <= 1)
//If the length of the linked list is less than or equal to 1, the expansion will not be considered directly
return;
s = sumCount();
}
//If the length of the linked list is greater than or equal to 0, check whether capacity expansion is needed or help
if (check >= 0) {
ConcurrentHashMap.Node<K,V>[] tab, nt; int n, sc;
//s identifies the collection size. If the collection size is greater than or equal to the capacity expansion threshold (0.75 of the default value)
//And the table is not empty, and the length of the table is less than the maximum capacity
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
//As long as one of the five conditions is true, it means that the current thread cannot help with this capacity expansion and directly jumps out of the loop
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
//Here is to help expand capacity
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// The first thread is to expand the capacity
// If the current capacity is not being expanded, then rs must be a positive number, through rs < < resize_ STAMP_ Shift sets sc to a negative number, + 2 indicates that a thread is performing capacity expansion
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
Let's take a look at the method of size statistics in ConcurrentHashMap: you can see the total value of all objects in size=baseCount + CounterCell [].
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
size accumulation diagram:
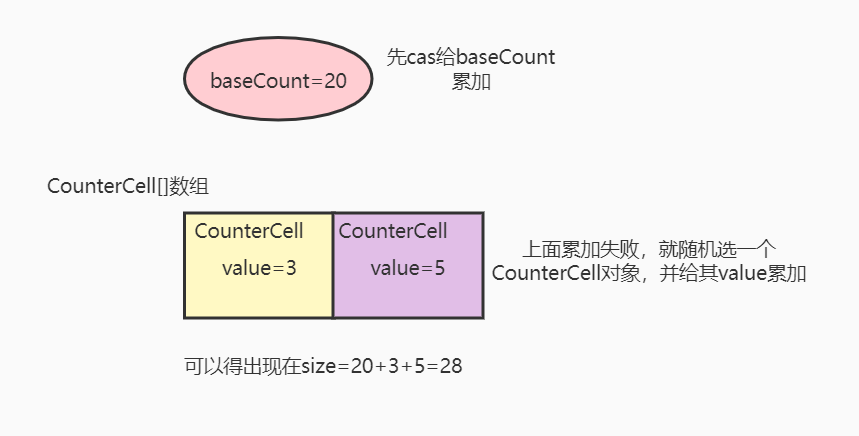
Summary: the first step is to accumulate the size. First, perform the accumulation of cas and baseCount. If the accumulation is successful, it proves that the competition is not fierce. Go directly to the following to judge the expansion. If the accumulation fails and the competition is fierce, add the value 1 to the counter cell object of counter cell [], obtain a random number through as [threadlocalrandom. Getprobe() & M], and ensure that the number will not collide under multithreading. Try to let different threads obtain different subscripts of CounterCell [] to reduce contention and improve efficiency. In the logic of checking expansion, you should pay attention to sizeCtl = RS < < resize_ STAMP_ Shift) + 2 means that there is only one thread for capacity expansion at present. For each new thread that helps to expand the capacity, sizeCtl will be + 1, and reducing one sizeCtl will be - 1.
4. Capacity expansion mechanism (transfer method)
The following describes the capacity expansion mechanism of concurrent HashMap, which is multi-threaded segmented capacity expansion and executed from back to front. To transfer a node in the original array, set the node of the original array as a forwarding node, and the hash value of the transfer node is - 1, that is, MOVED.
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//Stripe step size (that is, the number of buckets allocated by each thread during capacity expansion, with a minimum of 16)
//Calculate the step size according to the number of cpu cores
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
//Initializes a new array twice the size of the original array
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
//Initialize the transfer node, and its hash value is MOVED=-1
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
//i is the subscript of the current transfer position of the old array, and bound is the boundary, which identifies where the current thread is transferred to stop the transfer (and cas obtains the transfer interval again)
//That is, the nodes in the subscript [bound,i] interval of the old array will be transferred, and the transferIndex will be - 16 every cas time
// (this ensures that the next thread will not get the same interval as the previous thread)
//For example: current i=32 (indicating that the current thread is transferring nodes with subscript 32 of the old array), i-1 for each transfer (a transfer order from the back to the front)
//bound=16, which means that the current thread starts to transfer forward from the node with subscript 32 until the subscript is 16, and the current thread ends this transfer.
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
//When the nodes in the [bound,i] interval are transferred, cas will be used again to obtain a new interval,
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
/**
This is where the last thread exits the transfer method
Before exiting, the last thread will perform node transfer again from the [0,length] interval of the old array
Guess is to ensure that all nodes are transferred successfully. If the transfer node is encountered in the process of interval transfer
Then I'll skip.
*/
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
/**
The first expanded thread will execute sizectl = (resizestamp (n) < < resize) before entering the transfer method_ STAMP_ SHIFT) + 2)
The threads that help to expand capacity later will execute sizeCtl = sizeCtl+1 before entering the transfer method
Before exiting the transfer method, each thread will execute sizeCtl = sizeCtl-1, that is, the following cas code U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)
So until the last thread exits:
There must be SC = = (resizestamp (n) < < resize_ STAMP_ Shift) + 2), that is, the following judgment (SC - 2) = = resizestamp (n) < < resize_ STAMP_ SHIFT
If they are not equal, it means that the last thread cannot be reached. return the transfer method directly
*/
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
//The last thread assigns the original array length n to i from here, and then traverses and checks again.
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
//Judge whether to skip if it is a transfer node
advance = true; // already processed
else {
//Start migrating nodes (f is the head node on the bucket)
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
/** Split the original list into two
* One is placed at the subscript position of the original array
* The other is placed at the position of the subscript of the original array + the length of the original array
*/
int runBit = fh & n;
Node<K,V> lastRun = f;
//Loop search to find the last node in the linked list with a different value from its previous node hash & n
//As lastRun, its hash & n value is runBit
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//Assign initial value to the following cycle calculation
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//Cycle to assemble two linked lists (depending on the situation, there may be two linked lists at the end,
// Or there may be only one linked list, or there may be only one header node)
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//Put a linked list into the new array (position: the subscript of the original array is)
setTabAt(nextTab, i, ln);
//Put another linked list into the new array (position: original array subscript + original array length)
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
//Migrating red black trees
else if (f instanceof ConcurrentHashMap.TreeBin) {
ConcurrentHashMap.TreeBin<K,V> t = (ConcurrentHashMap.TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new ConcurrentHashMap.TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new ConcurrentHashMap.TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
Summary: note that after each thread transfer is completed, the method will exit. For each thread exited, sizeCtl will be - 1 until the last thread is left (if ((SC - 2)= resizeStamp(n) << RESIZE_ STAMP_ Shift) to judge whether there is only one thread left in the current transfer method. At this time, the last thread will traverse the whole old array from the end of the old array to the front, check whether all nodes on the old array have been transferred (check whether they are all transfer nodes forwardingnodes), and check whether there are no missing nodes, The last thread will exit the transfer method.
Expansion diagram:
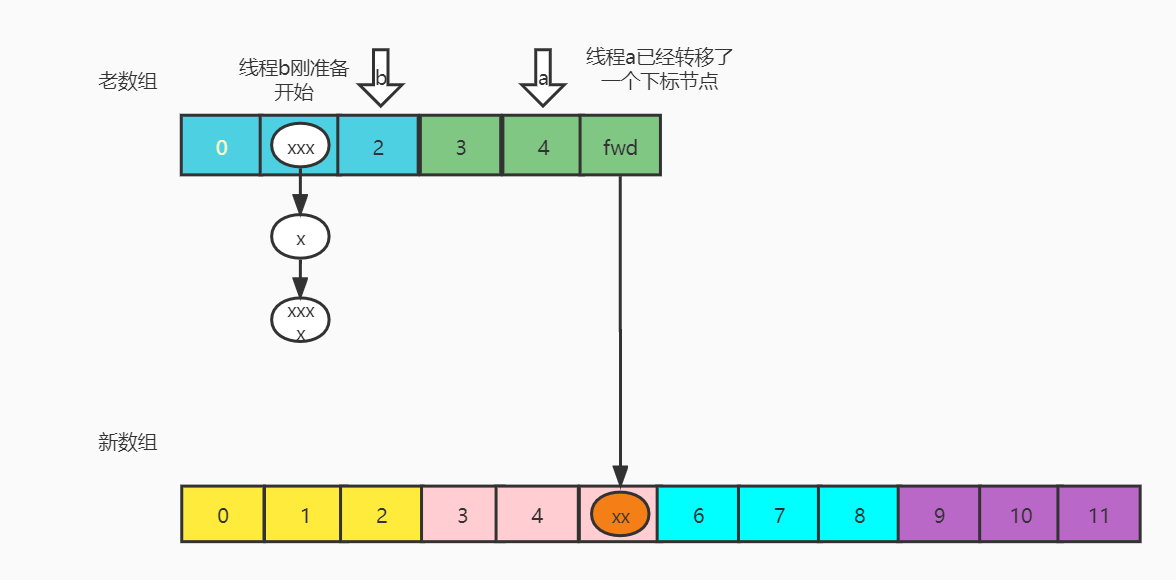
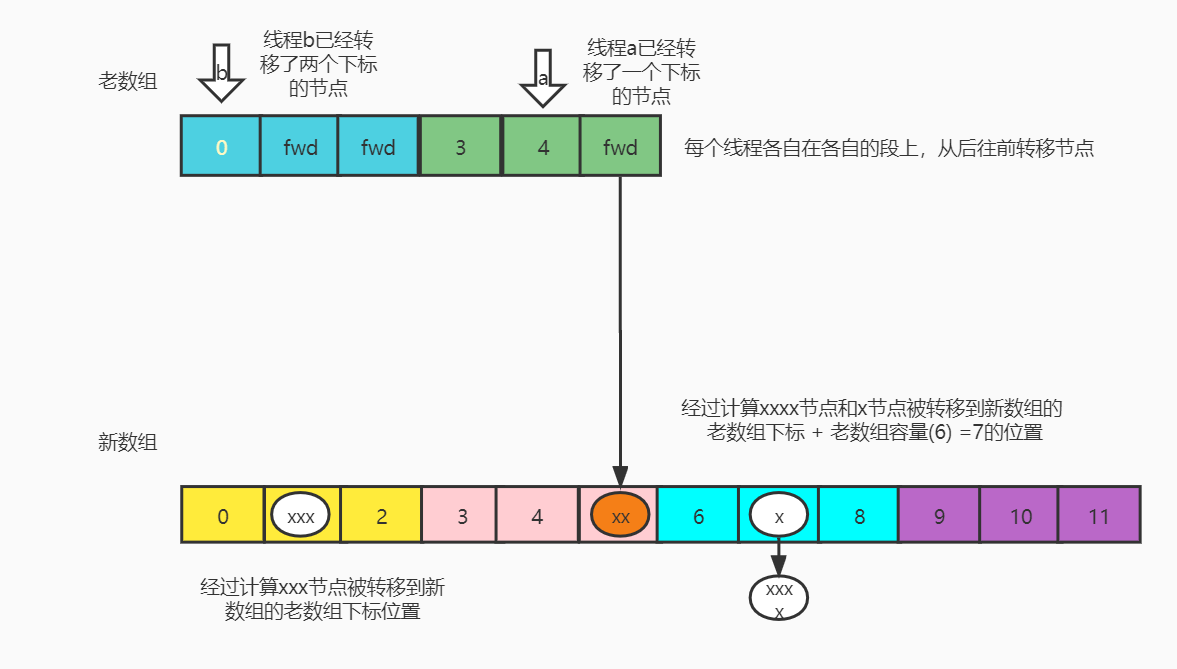
Supplementary knowledge points
The calculation methods of initial capacity of ConcurrentHashMap and HashMap are different:
Note: array initialization is not performed when setting the initial capacity.
The algorithm of initial capacity is different:
The calculation method of setting the initial capacity adds a calculation on the basis of HashMap, that is, multiply the value you pass in by 1.5, and then calculate the initial capacity of HashMap. For example, if you pass in the value of 32, it will multiply 32 by 1.5, calculate the HashMap, and finally calculate the initial capacity of 64. The capacity expansion threshold of 64 * 0.75 = 48 will be assigned to sizeCtl. If the initial capacity is not assigned, then the default capacity is CETL = 16;
-= =-i
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
//The bit operation here is equivalent to initialCapacity * 1.5
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
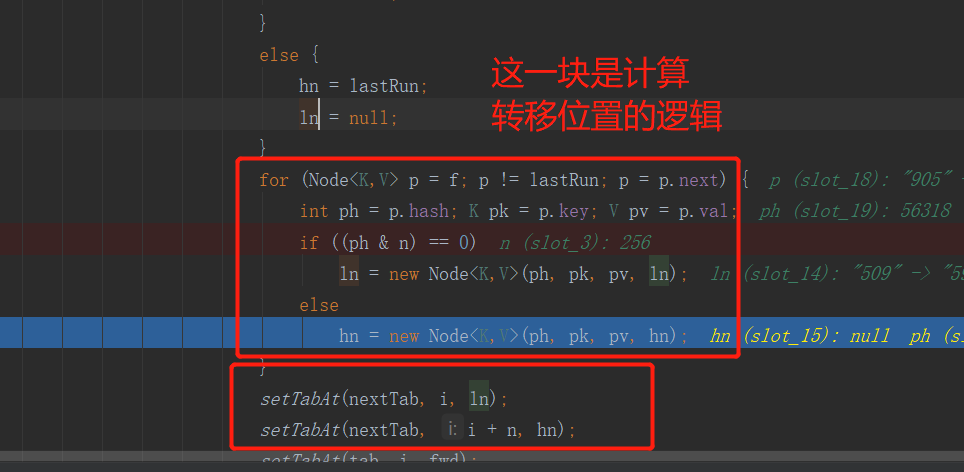
Why is it transferred to the position of the original array or the position of the original array + the length of the original array:
Let's take a look at the conclusion first: during capacity expansion, the node is transferred to either the original position or the position (original position + original array length). This only depends on whether the hash value of the node is the same as the 1 on the left of the binary data of the old array length. If it is 0, it will be in the original position, and if it is 1, it will be in the position (original position + original array length), The specific algorithm is to use the hash value of the node and the bitwise sum of the length of the old array (pH & n):
[the external chain picture transfer fails. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-e8saqamz-1645975130368) (ba82ac7f7aaf41369f4275991a3c18eaa)]
[the external chain picture transfer fails. The source station may have anti-theft chain mechanism. It is recommended to save the picture and upload it directly (img-9GOshDDj-1645975130368)(D54B1184F2424685BDECDA9007285F0A)]
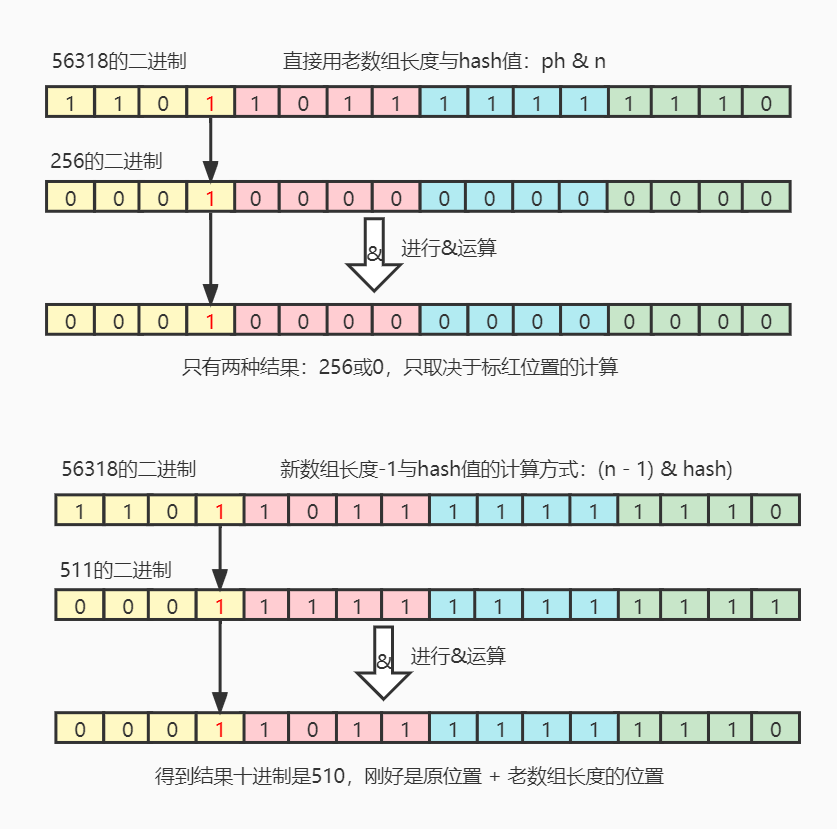
As can be seen from the above figure, the hash of the current node is 56318, the length of the old array is 256, and the length of the new array is 512. The subscript of the current node in the old array is 254. Through calculation, we can conclude that the node will be placed in the 510 subscript position of the new array.
From the figure below, we can see that (hash & oldcap) = = 0? I: I + oldcap and (newCap-1) & hash can calculate the subscript position of the node in the new array, but why use the former instead of the latter in capacity expansion? This involves the knowledge points of and operation, 1 & 1 = 1, 0 & 1 = 0, 0 & 0 = 0. It can be seen that if the currently obtained bit value is 1, you still need to judge whether the & is 0 or 1. If the currently obtained bit value is 0, you can directly get the result of 0 without knowing another value participating in the & operation. Therefore, it can be concluded that the performance of the former must be higher (because it is more than 0 a!).

debug source tips
See here to deal with the general interview is basically no problem. Next, it belongs to the content of volume king. I'm kidding. To tell you the truth, you can't understand it but you're not familiar with it. You forget it faster (don't think you're Zhang Wuji). You'd better debug it yourself. The following content shares my experience in debugging, so that brothers can save some time.
First of all, concurrent HashMap is used for concurrent programming. Do you want to do some multithreading before debug? Hey, hey, Ben Di is ready for you.
debug code address: https://gitee.com/kangarooking/demo-code/blob/master/src/main/java/com/example/demo/user/admin/juc/MapClient.java
1. Code positioning
Double click Shift, search for ConcurrentHashMap, and click to enter the ConcurrentHashMap class. Then ctrl + f, search putVal globally in this class and locate the put code.
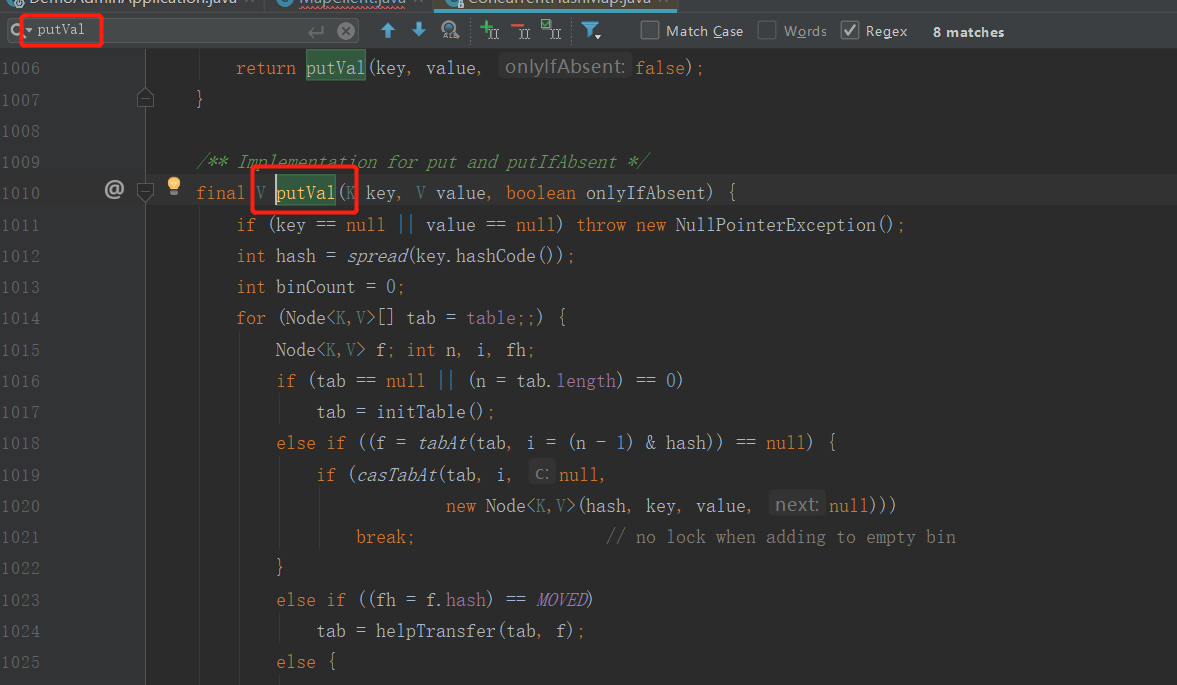
The codes analyzed and viewed are putVal, addCount, transfer, helpTransfer and fullAddCount.
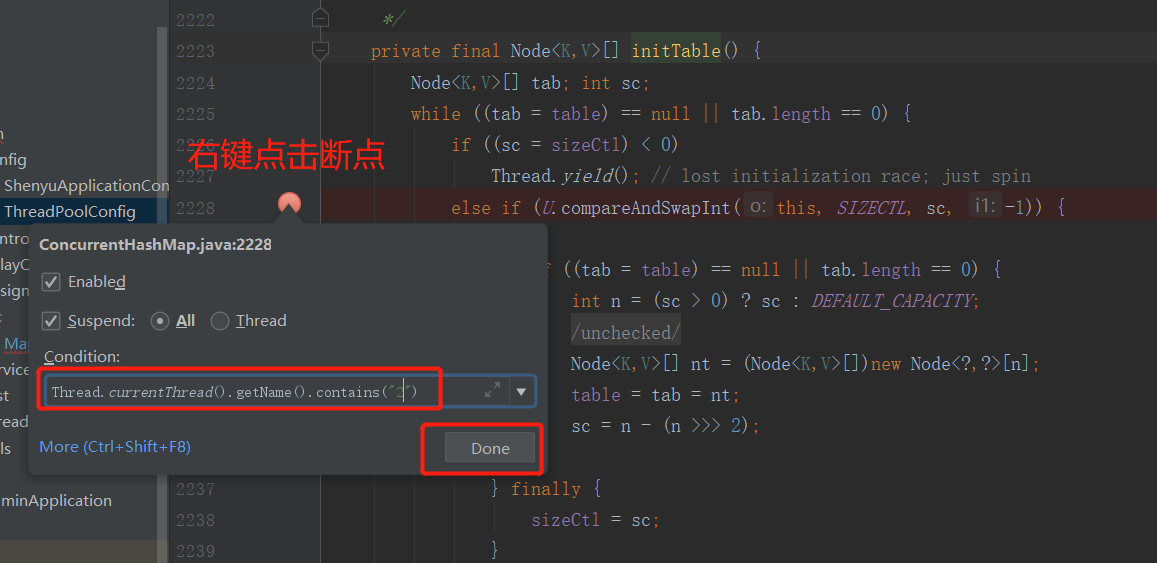
2. Break point under multithreading
Set breakpoint judgment. If you want to see all threads except main thread:
!Thread.currentThread().getName().contains("main")
If you want to see a specified thread:
Thread.currentThread().getName().contains("pool-1-thread-2")
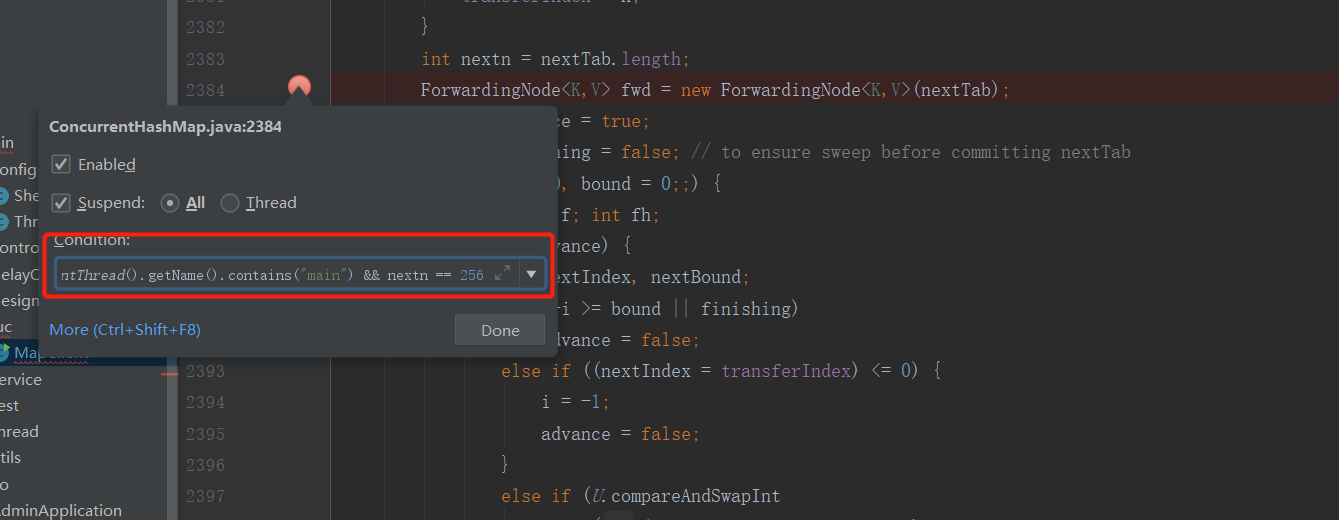
3. View the expansion effect
Thread can be set here currentThread(). getName(). Contains ("pool-1-thread-2") & & nextn = = 256 nextn represents the length of the new array.
Then break the point at the code after the transfer to see the comparison effect before and after the transfer.
Here, the breakpoint is also set with the same condition thread currentThread(). getName(). contains("pool-1-thread-2") && nextn == 256
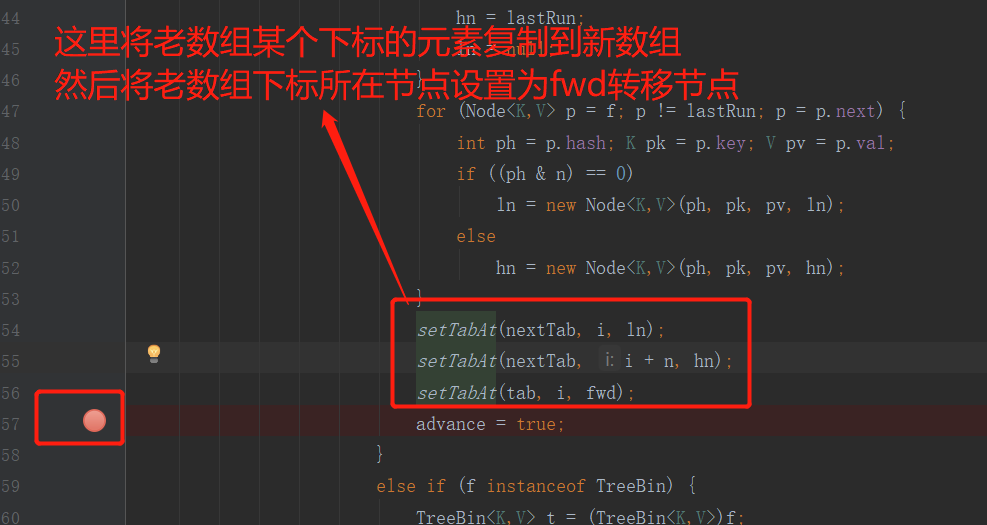
Press F9 to view the data of old arrays and new arrays in the process of capacity expansion and constantly change, so as to deepen the understanding of the capacity expansion mechanism of ConcurrentHashMap.
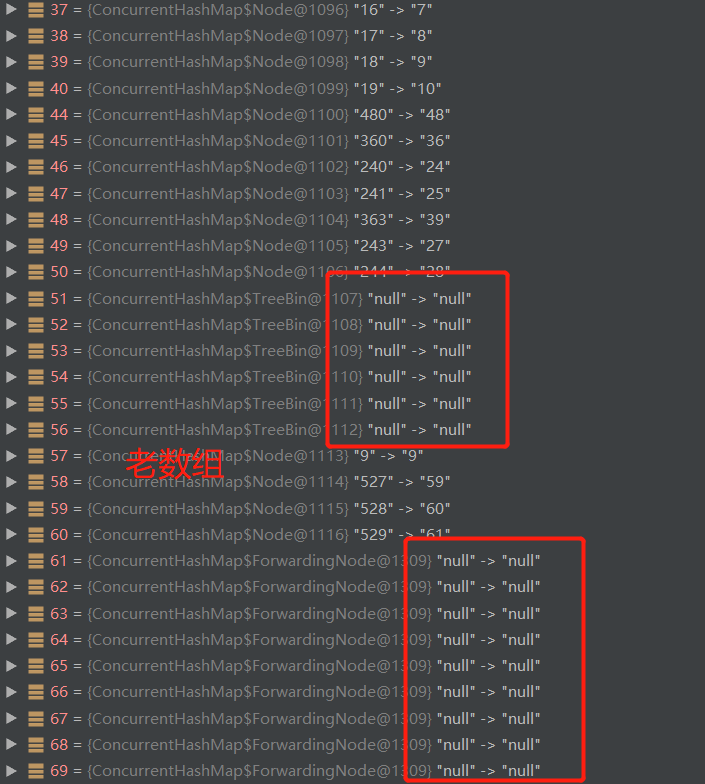
Note: you may have to restart the program several times before it can stop at the breakpoint. In the process of debug ging (F9), other threads will also run at the same time, so you should consider the operation of other threads when looking at the results.
summary
Reading articles only plays an auxiliary role in program learning. Many times, you still need to read the source code and operate it yourself in order to master this knowledge more firmly. There is no secret under the source code. After reading the source code more, you will find that there are many requirements or designs in the actual development, which can learn from the design ideas or some codes in the source code. In short, your skill of assignment and pasting is improved again.
For example, obtain random numbers that will not collide with numbers under multithreading:
ThreadLocalRandom.getProbe()
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
Get the number of cpu cores in the current system, which can be used to initialize the number of core threads in the thread pool in some scenarios:
/** Number of CPUS, to place bounds on some sizings */
static final int NCPU = Runtime.getRuntime().availableProcessors();
When you need to use cas in your project, you can also refer to the use of its source code, etc...

WeChat official account, "kangaroo's Inn", is available for comment. If you think my sharing is helpful to you, or think I have something, support my fledgling writer, Sanlian, Sanlian ~ ~. give the thumbs-up 👍 follow ❤️ share 👥