⬅️ preface
The main reason is that the last time server12 was pulled full by one of its own train direct threads (yes... server8 was also pulled full by emm. I didn't find out at first that it was me)
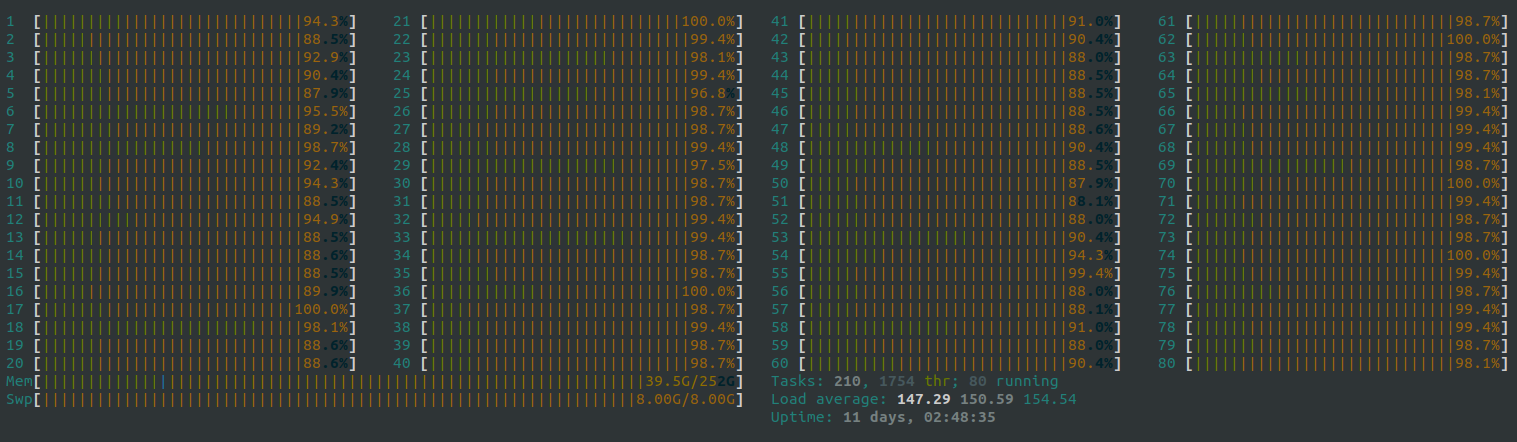
Live situation
Later, Liu Suo told me that let me see if there are too many processes in the dataset. In this way, the utilization rate of GPU is not high. It is suggested that the processing should be completed first and then directly trained by load; Because the cpu on the server is not very good, playing like that will slow down the training speed at the beginning. There are two options:
- Put all cpu operations on gpu
- First save the cpu operation as data, so you don't have to do an operation every time epoch
The following is the analysis and scheme confirmation for the two items mentioned in the preface
✔️ 1. Pretreatment
📍 Final solution (concurrent multithreading, dataset → pkl)
reference resources:
A series of operations such as thread parallelism and multi machine parallelism:
tips:
Programming in Ray: Tips for first-time users - RISE Lab
For details, see:
mmfn/phase1_preprocess.py · develop · kinzhang / transfuser
- Multi CPU thread parallel library
- One process runs more sample → ray append
Relevant codes and explanations
# Remember to change num cpus
sample_in_pre_run = 50
@ray.remote(num_cpus=48)
def write_pkl(save_dir, cur_num, dataset, run_num, pba: ActorHandle):
# print(cur_num, cur_num + run_num)
for i in range(cur_num, min(cur_num + run_num, len(dataset))):
with open(f'{save_dir}/%d.pkl'%(i), 'wb') as fd:
pickle.dump(dataset[i], fd)
pba.update.remote(1)
- num_cpus needs to be set according to the number of threads. The more, the better! For example, about 12 or 8 on the server is OK, because it takes a lot of time to start a thread. If the cost of starting a thread > > the cost of a process, it's better to run by a single process
- According to the above prompt, sample is introduced_ in_ pre_ Run is how much work is done in a process. If there are too many, the process may slow down, open too few threads and waste
Some operations are progress bars that can be ignored. Note that the concurrent ray original tqdm progress bar will fail!
See the official for details: (also see the progress bar under copy in the above gitlab)
ray_train_set = ray.put(train_set)
for cur_num in range(0, len(train_set), sample_in_pre_run):
tasks_pre.append(write_pkl.remote(train_dir, cur_num, ray_train_set, sample_in_pre_run))
ray_val_set = ray.put(val_set)
for cur_num in range(0, len(val_set), sample_in_pre_run):
tasks_pre.append(write_pkl.remote(val_dir, cur_num, val_set, sample_in_pre_run))
pb.print_until_done()
tasks = ray.get(tasks_pre)
# Progress bar related
tasks == list(range(num_ticks))
num_ticks == ray.get(actor.get_counter.remote())
-
You can see that remote is added to each process in for, which is the function required by ray. You can see the walkin above
-
append every task to tasks_ After pre, unify ray Just get (tasks_pre)
-
Notice the addition of a new ray Put is because the append operation is found to be extremely slow when accessing the server's big data, and then it is checked that it is related to the incoming parameters, so the parameters are directly put into the put share
-
If you don't want the progress bar, the concise version is like this:
from torch.utils.data import DataLoader from datasets.config import GlobalConfig # The initial data operation is in the get of dataset_ What's done in item from datasets.dataloader import CARLA_Data # The initial data operation is in the get of dataset_ What's done in item import ray ray.init() sample_in_pre_run = 50 @ray.remote(num_cpus=48) def write_pkl(save_dir, cur_num, dataset, run_num): # print(cur_num, cur_num + run_num) for i in range(cur_num, min(cur_num + run_num, len(dataset))): with open(f'{save_dir}/%d.pkl'%(i), 'wb') as fd: pickle.dump(dataset[i], fd) ray_train_set = ray.put(train_set) for cur_num in range(0, len(train_set), sample_in_pre_run): tasks_pre.append(write_pkl.remote(train_dir, cur_num, ray_train_set, sample_in_pre_run)) ray_val_set = ray.put(val_set) for cur_num in range(0, len(val_set), sample_in_pre_run): tasks_pre.append(write_pkl.remote(val_dir, cur_num, val_set, sample_in_pre_run)) # Concurrent processing together ray.get(tasks_pre)
Speed effect comparison
Final effect speed comparison:
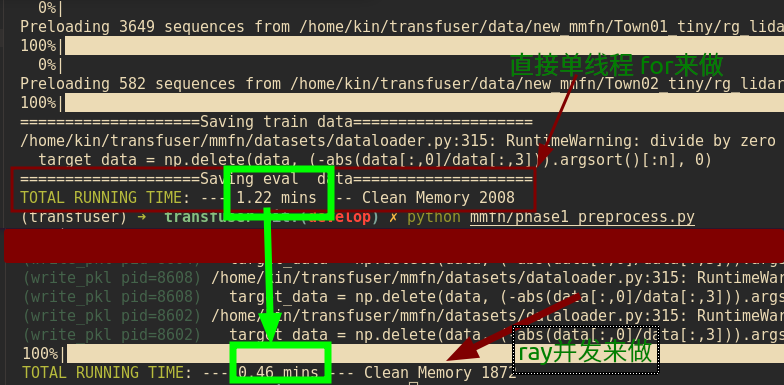
About 2.5 times the processing speed
-
But I don't know why the server doesn't move when running a large amount of data. Is the waiting time for emmm too short?
As mentioned above, the append operation is too slow to transfer into the dataset every time. It is fast to share it in the put
After that, if it is still very slow, it will not be the pot of CPU. It is recommended to check the reading speed of io as follows:
Remember the location of a server IO bottleneck · TesterHome
Utilization comparison
It is mainly to read the dataset directly through the files saved by pkl after processing the data. For example, Carla is processed above_ Data and then write a dataset that directly loads pkl
class PRE_Data(Dataset):
def __init__(self, root, config, data_use='train'):
self.preload_dict = []
preload_file = os.path.join(root, 'rg_mmfn_diag_pl_'+str(self.seq_len)+'_'+str(self.pred_len)+ '_' + data_use +'.npy')
preload_dict = []
if not os.path.exists(preload_file):
# list sub-directories in root
for pkl_file in os.listdir(root):
if pkl_file.split('.')[-1]=='pkl':
pkl_file = str(root) + '/' + pkl_file
preload_dict.append(pkl_file)
np.save(preload_file, preload_dict)
# load from npy if available
preload_dict = np.load(preload_file, allow_pickle=True)
self.preload_dict = preload_dict
print("Preloading sequences from " + preload_file)
def __len__(self):
"""Returns the length of the dataset. """
return len(self.preload_dict)
def __getitem__(self, index):
"""Returns the item at index idx. """
with open(self.preload_dict[index], 'rb') as fd:
data = pickle.load(fd)
return data
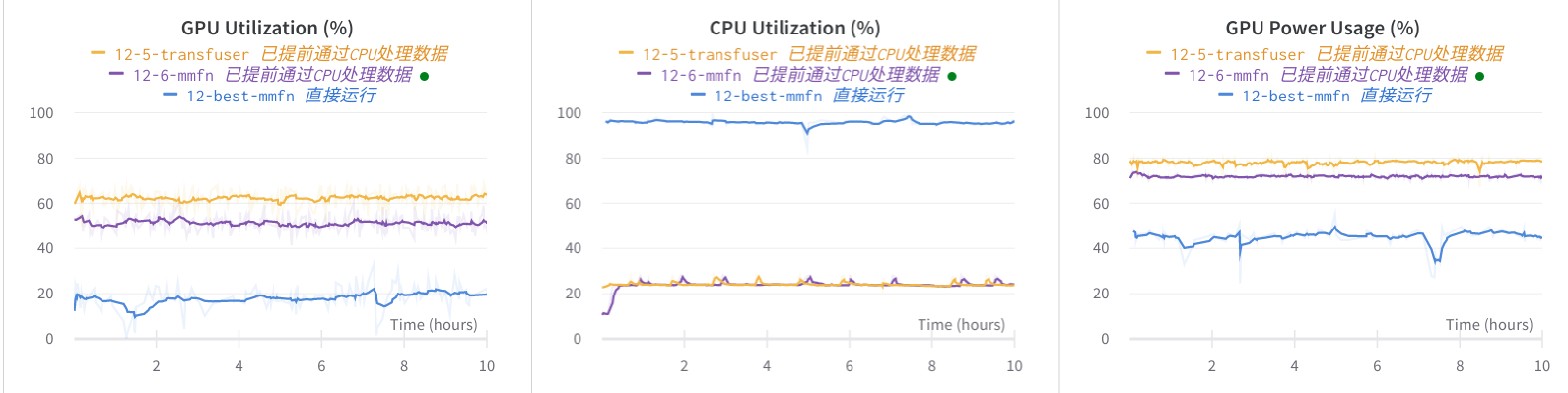
It can be seen that after processing in advance, the CPU utilization will not be full to 100% or even equal to none (because other people use the server at the same time)
At the same time, the utilization rate of GPU has also tripled, mainly because the previous utilization rate has been kept at 20%, and the CPU has been kept at all when it is full
✔️ 2. Single machine multi card parallel
reference resources:
Official DDP tutorial:
Getting Started with Distributed Data Parallel - PyTorch Tutorials 1.10.1+cu102 documentation
github 211star Chinese:
https://github.com/jia-zhuang/pytorch-multi-gpu-training
It's mainly about the investigation That reference link First, according to the official documents, let's take a look at the official differences and efficiency between DistributedDataParallel and DataParallel. The official recommends the former: Before we dive in, let's clarify why, destroy the added complexity, you would consider using DistributedDataParallel over DataParallel:
- First of all, if it's not so urgent, DataParallel is OK, mainly because it's really easy to implement. Adding one line is really one line
- The distributed data parallel is different. It needs to add many lines (OK, OK), but it is efficient
I didn't compare the efficiency between the two, so we came to this conclusion according to the official documents
Theoretical knowledge of two schemes
The following is Official comparison link human translation
- DataParallel is single process and multi-threaded, and can only be performed on one machine, that is, single machine and multi card
- Distributed dataparallel multi process can be used for single machine training or multi machine training
Moreover, because the cross thread operation of DataParallel makes GIL competition between threads, replication model synchronization between each iteration, and decentralized input and integrated output, these will lead to additional overhead. Even on a single machine, DataParallel is usually slower than distributed DataParallel.
This is one of them. Second, if your model is too large to fit a small GPU, DataParallel will fail, because you must use model parallelism to split it into multiple GPUs. Distributed DataParallel works in parallel with the model, but DataParallel is not implemented at present
The third point is that the small reminder has nothing to do with comparison: when DDP is combined with model parallelism, each DDP process will use model parallelism, and all processes will use data parallelism. If the model needs to span multiple machines, or the model scheme is not suitable for the data parallel paradigm, see RPC API For more general distributed training support.
After learning the theoretical knowledge, enter the code practice part
Code part modification
https://github.com/jia-zhuang/pytorch-multi-gpu-training
Just as in the github (in fact, the hhhh hh is well written. The following are some repetitions and additions, because emmm is hard to say when encountering some unexpected situations)
DataParallel
The reason why it's simple is... It only needs one line, just put your own model into the network
be careful reference resources For more details, click the reference link
For ease of illustration, we assume that the model input is (32, input_dim), where 32 represents batch_size, the model output is (32, output_dim), and four GPUs are used for training. nn. The function of dataparallel is to divide the 32 samples into 4 parts, send them to 4 GPUs for forward respectively, and then generate 4 outputs with the size of (8, output_dim), and then collect the 4 outputs on cuda:0 and combine them into (32, output_dim)
As can be seen, NN Dataparallel does not change the input and output of the model, so other parts of the code do not need to be changed, which is very convenient. However, the disadvantage is that the subsequent loss calculation will only be carried out on cuda:0, which can not be parallel, so it will lead to the problem of load imbalance; If the loss is calculated in the model, the above problem of load imbalance can be alleviated
# Model
model = TransFuser(config, args.device)
if args.is_multi_gpu:
print(bcolors.OKGREEN + "Multi GPU USE"+ bcolors.ENDC)
model = nn.DataParallel(model)
DistributedDataParallel
Implementation is more troublesome because it is multi process
From the beginning, multiple processes will be started (the number of processes is equal to the number of GPUs). Each process has an exclusive GPU, and each process will execute code independently. This means that each process initializes the model and trains independently. Of course, in each iteration process, it will share the gradient through inter process communication, integrate the gradient, and then update the parameters independently.
CUDA_VISIBLE_DEVICES=0,1 python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 train.py
So you run a sentence, but it's similar to a script running four python, so all printing and saving will run four. The way is to judge that this is args local_ When rank is 0, perform these save and print operations
CUDA_VISIBLE_DEVICES is the GPU id that the script can see when running, nproc_per_node is the number of GPUs, nnodes is the number of hosts, and a single machine is 1, train Py is your normal training code. Please pay attention to the following modifications:
-
Local_ The incoming of rank is specified by a local rank when running
from torch.utils.data.distributed import DistributedSampler parser = argparse.ArgumentParser() parser.add_argument("--local_rank", type=int, default=-1) args = parser.parse_args()-
Broken thoughts can also follow the way specified in the program, such as Official such
"""run.py:""" #!/usr/bin/env python import os import torch import torch.distributed as dist import torch.multiprocessing as mp def run(rank, size): """ Distributed function to be implemented later. """ pass def init_process(rank, size, fn, backend='gloo'): """ Initialize the distributed environment. """ os.environ['MASTER_ADDR'] = '127.0.0.1' os.environ['MASTER_PORT'] = '29500' dist.init_process_group(backend, rank=rank, world_size=size) fn(rank, size) if __name__ == "__main__": size = 2 processes = [] mp.set_start_method("spawn") for rank in range(size): p = mp.Process(target=init_process, args=(rank, size, run)) p.start() processes.append(p) for p in processes: p.join()
-
-
Because each process initializes a model, in order to ensure that the random weights generated in the process of model initialization are the same, it is necessary to set random seeds. The method is as follows:
def set_seed(seed): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) -
train_set to the DistributedSampler
# Data train_set = PRE_Data(root=config.train_data, config=config, data_use='train') val_set = PRE_Data(root=config.val_data, config=config, data_use='val') # Multi GPU training train_sampler = DistributedSampler(train_set) val_sampler = DistributedSampler(val_set) dataloader_train = DataLoader(train_set, batch_size=args.batch_size, sampler=train_sampler, num_workers=8, pin_memory=True) dataloader_val = DataLoader(val_set, batch_size=args.batch_size, sampler=val_sampler, num_workers=4, pin_memory=True)
-
Save and eval only need to be done once → wandb record and print only need to be done once
if epoch % args.val_every == 0 and args.local_rank == 0: trainer.validate(model, dataloader_val, config) if epoch % args.save_every == 0: trainer.save(model, optimizer) # Official preservation if rank == 0: # All processes should see same parameters as they all start from same # random parameters and gradients are synchronized in backward passes. # Therefore, saving it in one process is sufficient. torch.save(ddp_model.state_dict(), CHECKPOINT_PATH)Save only once because (comments also exist): all processes should see the same parameters, because they all start with the same random parameters, and the gradient is synchronized in the reverse transfer. Therefore, it is sufficient to save it in one process.
-
When saving the model, it should be noted that it only needs to be saved once, and it must be on the GPU. There will be problems with the cpu, as mentioned in the problem column below
torch.save(model.module.state_dict(), os.path.join(self.logdir, 'best_model.pth'))
Be sure to pay attention to 1 Map to cpu 2 Map all the layer s. See the question bar later
state_dict = torch.load(os.path.join(self.config_path.model_path, 'best_model.pth'), map_location=torch.device('cpu')) pretrained_dict = {key.replace("module.", ""): value for key, value in state_dict.items()} self.net.load_state_dict(pretrained_dict) -
To ensure that all GPUs are evenly distributed with video memory, please execute it earlier than the model. See the problem column for details
# These are the two sentences torch.cuda.set_device(args.local_rank) torch.cuda.empty_cache() # These are the two sentences # Model model = TransFuser(config, args.device) model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
Please check the remaining problems in advance. See the relevant problems in the follow-up section
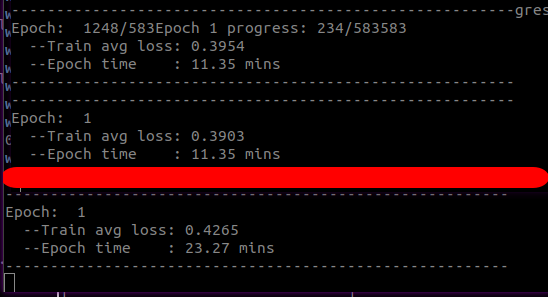
Effect comparison
Multi GPU speed
For the comparison of two 2080Ti and one 2080Ti with the same amount of data, the final effect speed comparison of DistributedDataParallel is used:
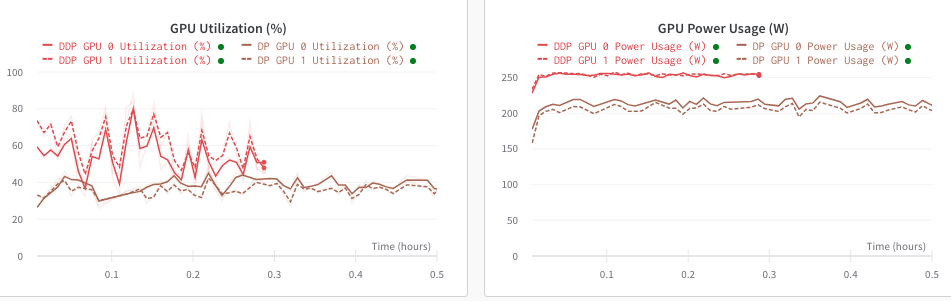
Comparison of DP and DDP utilization
Another disadvantage of DP is that the utilization rate of GPU is very low. I don't know whether it is due to the problem of splitting the sample into distribution, and the utilization rate is directly halved. As shown in the comparison below, the same data set is compared with the utilization rate of training DDP and DP (with the more GPU, the lower the utilization rate)
❓ 3. Problems encountered and Solutions
DistributedDataParallel
-
RuntimeError: NCCL communicator was aborted
I encountered this problem at random. Under the same model, there is no error in the small data set, but I found that emmm is very random when it is full; The links to the relevant pytorch discussion area are as follows:
RuntimeError: NCCL communicator was aborted
It seems that the reason has been found. It should not be saved cpu model file because even if to will also report an error, so save args directly local_ The model with rank of 0 is OK, because the official does the same
All processes should see the same parameters because they all start with the same random parameters and the gradient is synchronized in the reverse pass. Therefore, it is sufficient to save it in one process.
-
Pytorch distributed RuntimeError: Address already in use
Because the emergency kill is lost, which leaves future problems. Although the pid is killed through the command line, it still seems to occupy the default port. For example, select all kill through the command line in htop
kill -9 $(pgrep -f "/opt/conda/envs/python37/bin/python -u mmfn" | xargs echo)
Then it seems that the mouth still can't release Change the port number On the line:
python -m torch.distributed.launch --nproc_per_node=4 --master_port 12120 --nnodes=1 mmfn/phase2_train_multipgpu.py
-
Note that when DDP is used, I don't know that more video memory is needed. For example, a piece of 3090 is used, and the video memory is 24G. During normal separate GPU training, batch_ The size is set to 64, which takes up 20G of video memory. When it comes to DDP, although it is multi process operation, it should also be set to 64. After all, the others are 3090, but what! During the actual operation, I found that the first block needs to occupy more things. If there are more GPUs, the more it needs to occupy (2G / block) → but I think Huage seems... There is no such phenomenon. I guess I didn't notice it
-
Site facts:
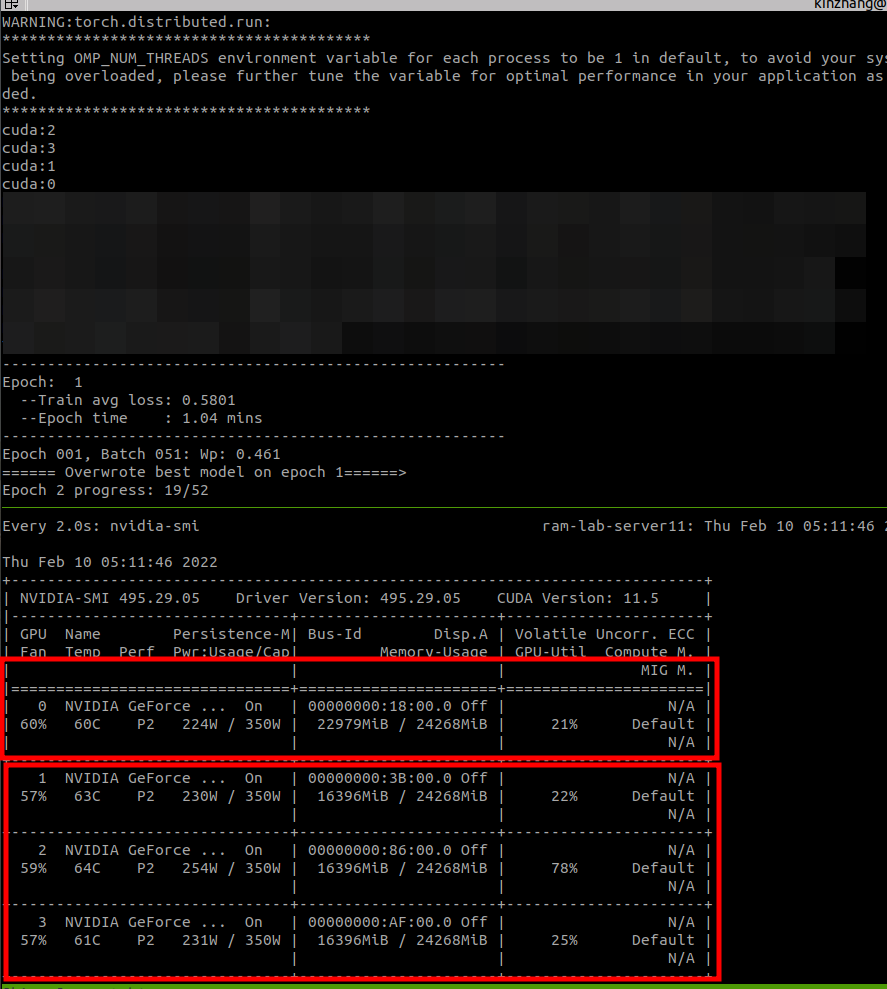
Jacko is so strong! Ah! Find the reason! He meow... He wanted to explain it in front of the model
Extra 10GB memory on GPU 0 in DDP tutorial
# These are the two sentences torch.cuda.set_device(args.local_rank) torch.cuda.empty_cache() # These are the two sentences # Model model = TransFuser(config, args.device) model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
-
-
If you resume, you need to reorganize the read layer id and the related links:
https://github.com/bearpaw/pytorch-classification/issues/27
Missing keys & unexpected keys in state_dict when loading self trained model
# for DDP model load use state_dict = torch.load(os.path.join(args.logdir, 'best_model.pth')) optimizer.load_state_dict(torch.load(os.path.join(args.logdir, 'best_optim.pth'))) from collections import OrderedDict new_state_dict = OrderedDict() for k, v in state_dict.items(): if 'module' not in k: k = 'module.'+k else: k = k.replace('features.module.', 'module.features.') new_state_dict[k]=v model.load_state_dict(new_state_dict)
DataParallel
This is mainly about the batch_size is allocated, that is, the number of GPU s will be divided. If such a situation is involved in your processing, the size of relevant data will not match
For example, in the dataloader, the data in batch is maximized as a length; Then continue to process the data as the length in the forward of the model, then; Four scattered batches will have four different size s and lengths, and certain problems will occur. The facts ahead are as follows:
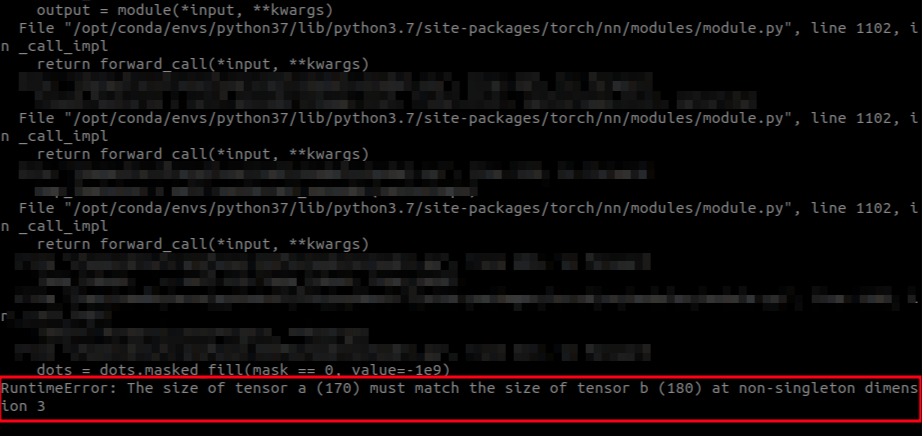
Recommended measures: all data size determination shall be completed in the loader section
The following is the initial investigation
Relevant cause analysis
-
Low GPU utilization: https://zhuanlan.zhihu.com/p/410244780
-
To be done: still analyzing whether the problem of slow speed can be solved → half can be solved
Additional: explanation of CPU and htop parameters: Understanding and using htop to monitor system resources
It is also mentioned here that small loader s are too small. It is best to process them into large ones and then read them: https://github.com/Lyken17/Efficient-PyTorch#data-loader
pkl
It has been written, but it comes out directly in the loader, that is, batch_size is settled from here → wrong approach
lmdb: https://github.com/dotchen/WorldOnRails/blob/release/docs/DATASET.md
See if you can use Ctrip lmdb style and loader style. It's a little too violent