
Preface
Before, my classmates selected tutors for postgraduate study. I helped them refer to them. I found that some teachers are very young, but the data of Google Scholar are ridiculously high (mainly citation and h-index), and even easily crush some calf guides in the ears of the population. Intuitively, this kind of data should be falsely high. I guess it is because there are more cooperation between teachers. An article has the names of several teachers, and the embodiment of sharing this achievement on gs is that everyone has one more article. Learning materials for programming: Click to get them for free
Although it is a basic academic norm to sign papers, and it is certainly no problem for teachers to cooperate and share achievements, this will lead to the false high gs data of teachers and mislead students. Therefore, we can use the public data on gs to analyze the co authorship of teachers. For example, we can see how many teachers participate in each article in all papers... This information can help us reduce the noise and provide some reference when we choose teachers.
principle
To analyze a teacher's co authorship, we first need to obtain all the teacher's publications. We can climb the teacher's thesis list from Google Scholar. After getting the list of papers, we need to extract the authors of each article, and then sort the occurrence frequency of these authors. Finally, we have to rely on our prior knowledge to judge. If we are familiar with the teachers in the college, we can directly recognize who are teachers. For code implementation, all we need to do is crawl the list of papers and count the frequency of authors.
realization
Crawling paper list
First of all, the paper list of the gs user homepage is not displayed all at once. You need to manually click the expansion below, and the expanded new information is not loaded at the beginning, but requested through a new url after clicking, so you need to crawl in batches (this is the only stupid way to contact the crawler for the first time). However, fortunately, the format of the new url has rules to follow. Therefore, only according to the total number of user papers, we can determine how many URLs are needed and what each url should be.
The format of the url is:
- The url corresponding to the first 20 paper data (i.e. 20 articles displayed on the home page) is the link to the user's home page;
- For articles 20-100, add & cstart = 20 & PageSize = 80 after the home page link;
- For articles 100-200, add & cstart = 100 & PageSize = 100 after the home page link;
- For articles 200-300, add & cstart = 200 & PageSize = 100 after the home page link;
- and so on.
Therefore, you only need to define a urls list and put all urls in it according to the number of teachers' papers.
Then, define a data string, splice the crawled information into the string, and then extract the effective information with regular expression.
Then, define the function to get the information:
def getData(url):
header_dict={'Host': 'scholar.google.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'https://scholar.google.co.id/citations?hl=zh-CN&user=oqYL6fQAAAAJ',
'Connection': 'keep-alive'}
req = urllib.request.Request(url=url,headers=header_dict)
response = urllib.request.urlopen(req,timeout=120)
tempdata = response.read()
tempdata = tempdata.decode()
return tempdata
Copy codeIn the urls just defined, a for loop is used to crawl the data of each url in turn and splice it onto the data string.
urls = ['https://scholar.google.co.id/citations?hl=zh-CN&user=oqYL6fQAAAAJ',
'https://scholar.google.co.id/citations?hl=zh-CN&user=oqYL6fQAAAAJ&cstart=20&pagesize=80',
'https://scholar.google.co.id/citations?hl=zh-CN&user=oqYL6fQAAAAJ&cstart=100&pagesize=100',
'https://scholar.google.co.id/citations?hl=zh-CN&user=oqYL6fQAAAAJ&cstart=200&pagesize=100']
for each in urls:
data += getData(each)
Copy codeIn this way, we have obtained the original paper list data. Next, we need to extract effective information from these data.
Extract information
This step is mainly realized through regular expressions. The regular expression pattern of paper title, author, publication and other information can be obtained through simple observation, as follows:
title_pattern = re.compile(r'gsc_a_at">.*?<') author_pattern = re.compile(r'<div class="gs_gray">.*?</div><') publisher_pattern = re.compile(r'</div><div class="gs_gray">.*?<span') Copy code
Then we use these pattern s to extract the corresponding information, store it in the list, and cut it at the same time to further remove the redundant characters; If there are multiple authors in an article, they also need to be separated into a list according to commas.
title = re.findall(title_pattern, data)
author = re.findall(author_pattern, data)
publisher = re.findall(publisher_pattern, data)
for i in range(len(title)):
title[i] = title[i][10:-1]
for i in range(len(author)):
author[i] = author[i][21:-7]
author_list.append(author[i].split(', '))
Copy codeAfter completing the above operations, you will get the title and author list of each paper, and then find the co-occurrence of the author's name.
Co authorship analysis
This step is to simply count and sort. My approach is to define an author class with the attributes including name and number of papers, then traverse the above to get the author list, count the number of papers participated by an author, and finally sort these authors. Final output result:
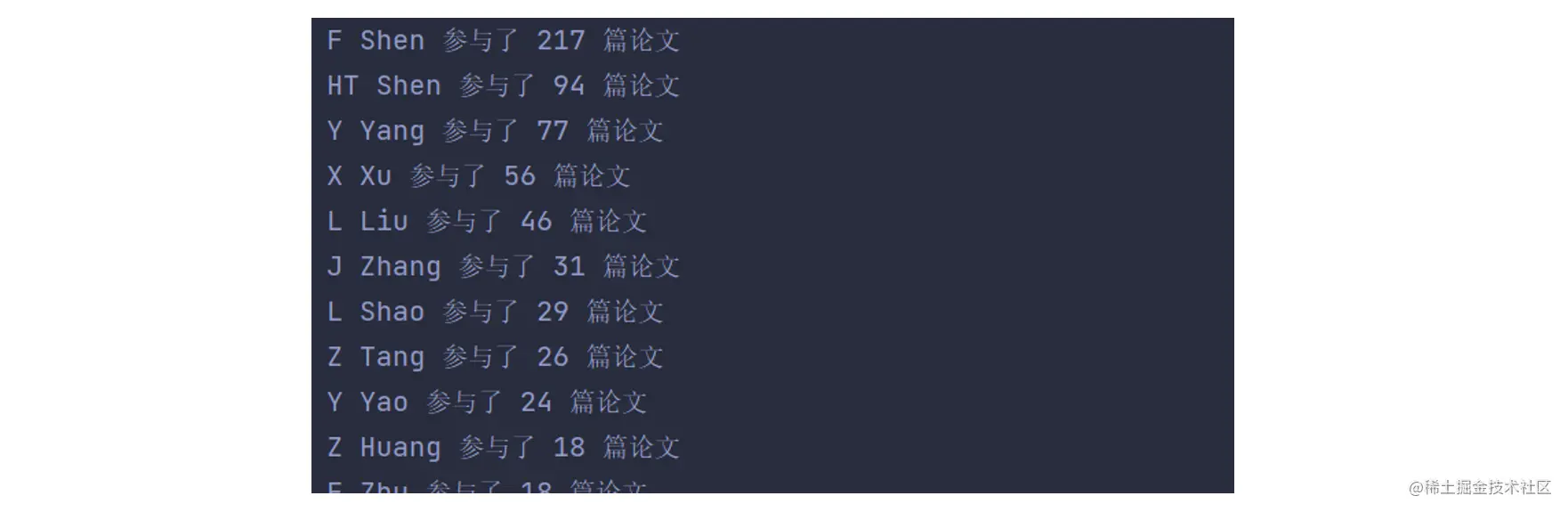
From this result, it can be seen that the scholars that Mr. F Shen often cooperates with are teachers such as HT Shen and Y Yang. Of course, with the list of authors obtained above, it can be analyzed from various dimensions. The screenshot above is just one of the very simple application scenarios.
Here I use the data of Mr. F Shen's paper. I need to mention that I'm just giving an example here. It doesn't mean I have any prejudice against this teacher. In fact, Mr. F Shen is a teacher I have always admired and one of my intended mentors. He has a good reputation. Here's a recommendation~
epilogue
The above is the general process of CO authorship analysis using Google Scholar data. There is no difficulty in technical implementation. On the one hand, it is written here to share some experience, such as how to design the regular expression pattern in Google Scholar paper data; On the other hand, it also provides you with an idea to further understand teachers. After all, Google Scholar's indexes do not represent everything. I hope it can help.
① More than 3000 Python e-books
② Python development environment installation tutorial
③ Python 400 set self-study video
④ Common vocabulary of software development
⑤ Python learning Roadmap
⑥ Project source code case sharing
If you can use it, you can take it away directly. In my QQ technical exchange group (technical exchange and resource sharing, advertising is not allowed) you can take it away by yourself. The group number is 895937462.