1.Redis cache double write consistency
2. Several update strategies for database and cache consistency
2.1 update the database first and then the cache
2.2 delete the cache first and then update the database
2.3 update the database first and then delete the cache
2.4 update the cache first, and then update the database
3. canal of the implementation case of redis and MySQL data double write consistency project
4. Summary
1.Redis cache double write consistency
We all know that as long as we use redis, we will encounter double storage and double write of cache and database. As long as it is double write, there will be data consistency problems. In order to ensure double write consistency, should we first move redis or mysql?
Generally speaking, in order to ensure data consistency, there are two situations:
1) If there is data in redis, we need the same value as in the database
2) If there is no data in redis, the value in the database is the latest value
2. Several update strategies for database and cache consistency
We need to ensure the consistency of the database and cache, but these are two tools after all, which will inevitably cause a certain delay, so we need to ensure the final consistency!
We can set the expiration time for the cached key, which is the solution to ensure the final consistency.
We set the expiration time for the data stored in the cache. All write operations are subject to the database, and only try our best to cache operations. If the database is written successfully and the cache update fails, as long as the expiration time is reached, the subsequent read requests will naturally get new values from the database, and then write back to the cache to achieve consistency.
The above case is only the current mainstream + mature practice. Considering the different business nature of each company, please choose the method suitable for our own company.
2.1 update the database first and then the cache
When we perform this operation, if the thread concurrency is large enough, two problems will generally occur. We describe them in a tabular way:
Exception 1:
| time | Thread A | Thread B |
|---|---|---|
| t1 | Update database values | |
| t2 | Query request, cache hits old data, resulting in dirty data query | |
| t3 | Update cached data |
Exception 2:
| time | Thread A | Thread B |
|---|---|---|
| t1 | Update database values | |
| t2 | Query request, cache hits old data, resulting in dirty data query | |
| t3 | Cache update failed, resulting in dirty data being queried within a certain period of time |
2.2 delete the cache first and then update the database
Exception 1:
| time | Thread A | Thread B |
|---|---|---|
| t1 | Delete cache | |
| t2 | A large number of query requests directly lead to cache breakdown | |
| t3 | Server downtime |
Exception 1 solution:
The solution of cache breakdown has been explained in the previous blog.
Deep understanding of redis -- cache avalanche / cache breakdown / cache penetration
Exception 2:
| time | Thread A | Thread B |
|---|---|---|
| t1 | Delete cache | |
| t2 | Query request, cache no data, go to the database to query the old data | |
| t3 | Update the value of mysql, resulting in inconsistency with the data in the cache |
Exception 2 solution:
Delay double deletion strategy is adopted
public void delayDoubleDeleteUser(TUser user) throws InterruptedException {
//The thread successfully deleted the redis cache
redisTemplate.delete(CACHE_KEY_USER + user.getId());
//Thread updates mysql again
userMapper.updateById(user);
//Sleep for two seconds and wait until other query business logic is executed first and the cache is completely old
Thread.sleep(2000);
//Delete the cache again
redisTemplate.delete(CACHE_KEY_USER + user.getId());
}Problem 1 caused by delayed double deletion: how long does the thread sleep after delayed double deletion?
Generally, when a business project is running, first count the read and write operation time of the next thread, and then add a hundred milliseconds based on the sleep time of writing data and the time consumption of reading data business logic.
Problem 2 caused by delayed double deletion: what about the throughput reduction caused by this synchronization strategy?
Just open another thread.
public void delayDoubleDeleteUser(TUser user) throws InterruptedException, ExecutionException {
//The thread successfully deleted the redis cache
redisTemplate.delete(CACHE_KEY_USER + user.getId());
//Thread updates mysql again
userMapper.updateById(user);
//Sleep for two seconds and wait for other business logic to be executed first
//Open a thread and delete the cache again
CompletableFuture.supplyAsync(()->{
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return redisTemplate.delete(CACHE_KEY_USER + user.getId());
}).get();
}2.3 update the database first and then delete the cache
This is the solution advocated by the industry:
Exception 1:
| time | Thread A | Thread B |
|---|---|---|
| t1 | Update database | |
| t2 | The old data was found in the cache before it could be deleted | |
| t3 | Delete cache |
So the question is, should we delete the cache first and then update the database, or update the database first and then delete the cache?
Generally speaking, for an operation that cannot guarantee transaction, it must involve the problem of "which task to do first and which task to do later". The direction to solve this problem is: in case of inconsistency, who does it first has less impact on the business and who executes it first.
Delete the cache first and then update the database: the exception of this method occurs in that after deleting the cache, the old value is refreshed back to the cache immediately before the database is updated.
Update the database first and then delete the cache: the exception of this method is that after updating the database, the cache has not been eliminated for a short time, and the old data is read.
We can clearly conclude that the first scheme has a higher probability of exceptions. The interval between deleting the cache and the completion of the write operation is much longer than the interval from updating the database to deleting the cache, so we should choose the second scheme.
But what if you have to ensure consistency?
There is no way to achieve absolute consistency, which is determined by the CAP theory. The applicable scenario of the cache system is the scenario of non strong consistency, so it belongs to the AP in the CAP.
Therefore, we have to compromise and achieve the final consistency in BASE theory.
This leads to our canal tool! (use will be explained below)
2.4 update the cache first, and then update the database
Generally, no one will do this. It is not recommended that the cached data be ahead of the database.
3. canal of the implementation case of redis and MySQL data double write consistency project
What is canal:
canal is mainly used for subscription, consumption and analysis of incremental log data in mysql database. It is developed and open source by Alibaba and developed in java language.
The historical background is that in the early stage, Alibaba had the business requirement of cross machine room data synchronization due to the deployment of dual machine rooms in Hangzhou and the United States. The implementation method is mainly to obtain incremental changes based on business trigger s. Since 2010, Alibaba has gradually tried to synchronize incremental changes by parsing database logs, which has derived the canal project;
Summary: Canal is a component for incremental subscription and consumption based on MySQL change logs. It subscribes to MySQL incremental logs and synchronizes to other components (mysql/redis/mq, etc.) to achieve the final consistency of data.
How canal works:
Before looking at the working principle of canal, let's first understand the working principle of mysql master-slave synchronization:
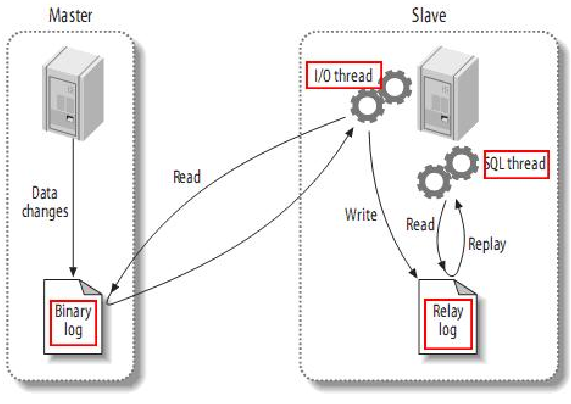
Master slave synchronization process of Mysql:
1. When the data on the master master server changes, write the changes into the binary event log file;
2. The slave server will detect the binary log on the master server within a certain time interval to detect whether it has changed.
If it is detected that it has changed, start an I/O Thread to request the binary log of read master.
3. At the same time, the master server starts a dump Thread for each I/O Thread, which is used to send binary event logs to the I/O Thread.
4.slave saves the received binary event log to its local relay log file from the server.
5.slave slave server will start SQL Thread to read binary logs from intermediate logs and replay them locally to make the data consistent with the master server.
6. Finally, after I/O Thread and SQL Thread are executed, they will sleep and wait for the next wake-up.
Canal is also a synchronization protocol simulating MySQL slave, pretending to be MySQL slave and sending dump protocol to Mysql Master. Mysql Master receives the dump request and starts pushing binary log to slave (i.e. canal). Canal parses binary log object (originally byte stream)
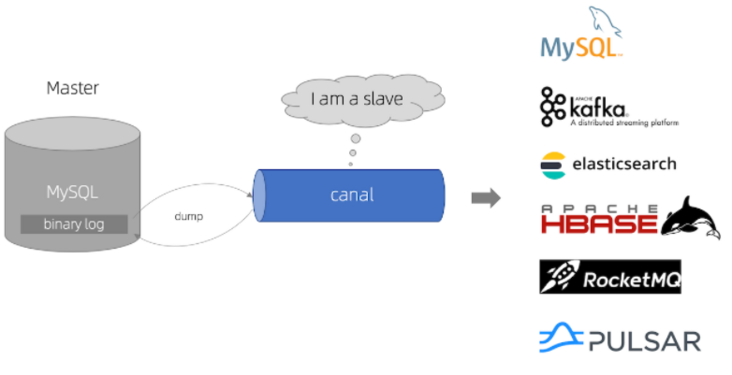
However, this solution can only achieve final consistency, and cannot achieve strong consistency.
Use of canal:
Connect to MySQL and type the command: show variables like 'log_%'; Check whether binlog is enabled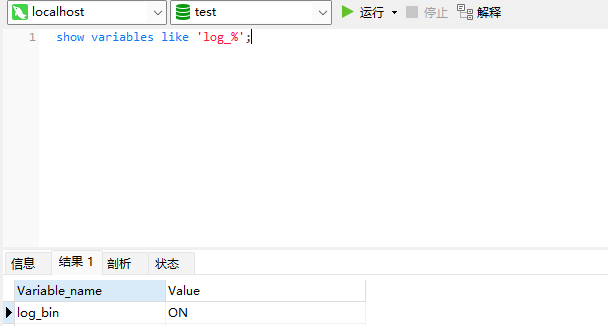
If log_ If the value of bin is OFF, the configuration file my Ini and add the following code:
log-bin=log-bin binlog-format=ROW
ROW: in addition to recording sql statements, the mode also records the changes of each field. It can clearly record the change history of each ROW of data, but it will occupy more space.
STATEMENT: the mode only records sql statements, but does not record context information, which may lead to data loss during data recovery;
MIX: flexible record mode. Theoretically, when the table structure changes, it will be recorded as statement mode. When the data is updated or deleted, it will change to row mode;
Modify conf / canal Properties configuration file. The registered address is the local database address
Modify conf / example / instance Properties configuration file, configuring database information
Using startup.exe under Windows bat
pom.xml add dependency
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>package com.example.demo.redisDemo.config.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
/**
* @author sulingfeng
* @title: RedisUtils
* @projectName demo
* @description: TODO
* @date 2022/2/16 16:01
*/
public class RedisUtils {
private static JedisPool jedisPool;
static {
JedisPoolConfig jedisPoolConfig=new JedisPoolConfig();
jedisPoolConfig.setMaxTotal(20);
jedisPoolConfig.setMaxIdle(10);
jedisPool=new JedisPool(jedisPoolConfig,"127.0.0.1",6379);
}
public static Jedis getJedis() throws Exception {
if(null!=jedisPool){
return jedisPool.getResource();
}
throw new Exception("Jedispool was not init");
}
}
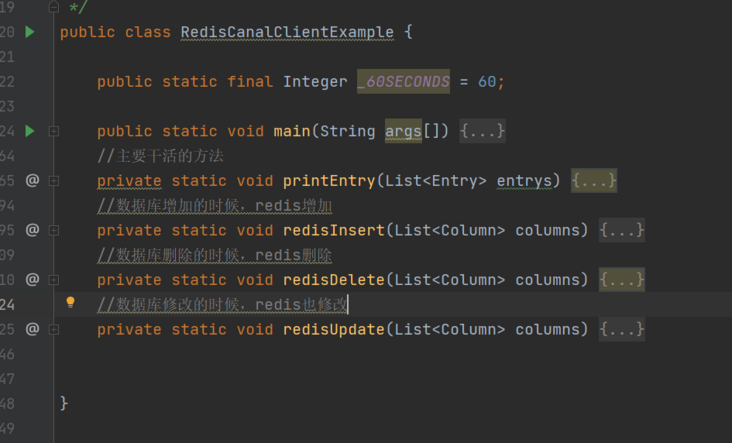
package com.example.demo.canalDemo;
import com.alibaba.fastjson.JSONObject;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry.*;
import com.alibaba.otter.canal.protocol.Message;
import com.example.demo.redisDemo.config.utils.RedisUtils;
import redis.clients.jedis.Jedis;
import java.net.InetSocketAddress;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @auther
* @create 2020-11-11 17:13
*/
public class RedisCanalClientExample {
public static final Integer _60SECONDS = 60;
public static void main(String args[]) {
// Create a link to the canal server. The example is the canal instance name
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("199.16.1.135",
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
System.out.println("----------------Start the program and start listening mysql Changes in:");
try {
connector.connect();
//connector.subscribe(".*\\..*");
//connector.subscribe("db2020.t_order");
//Subscribe to mysql table
connector.subscribe("test.t_user");
connector.rollback();
int totalEmptyCount = 10 * _60SECONDS;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // Get the specified amount of data
long batchId = message.getId();
int size = message.getEntries().size();
//If there is no data modification
if (batchId == -1 || size == 0) {
emptyCount++;
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
//If there is data modification
emptyCount = 0;
printEntry(message.getEntries());
System.out.println();
}
connector.ack(batchId); // Submit for confirmation
// connector.rollback(batchId); // Processing failed, rollback data
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
//Main working methods
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error,data:" + entry.toString(), e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================ binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(), eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
//If it is new
if (eventType == EventType.INSERT) {
redisInsert(rowData.getAfterColumnsList());
//If delete
} else if (eventType == EventType.DELETE) {
redisDelete(rowData.getBeforeColumnsList());
} else {//EventType.UPDATE
redisUpdate(rowData.getAfterColumnsList());
}
}
}
}
//When the database increases, redis increases
private static void redisInsert(List<Column> columns) {
JSONObject jsonObject = new JSONObject();
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " insert=" + column.getUpdated());
jsonObject.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
try (Jedis jedis = RedisUtils.getJedis()) {
jedis.set(columns.get(0).getValue(), jsonObject.toJSONString());
} catch (Exception e) {
e.printStackTrace();
}
}
}
//redis deletes the database when it is deleted
private static void redisDelete(List<Column> columns) {
JSONObject jsonObject = new JSONObject();
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " delete=" + column.getUpdated());
jsonObject.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
try (Jedis jedis = RedisUtils.getJedis()) {
jedis.del(columns.get(0).getValue());
} catch (Exception e) {
e.printStackTrace();
}
}
}
//When the database is modified, redis is also modified
private static void redisUpdate(List<Column> columns) {
JSONObject jsonObject = new JSONObject();
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
jsonObject.put(column.getName(), column.getValue());
}
if (columns.size() > 0) {
try (Jedis jedis = RedisUtils.getJedis()) {
jedis.set(columns.get(0).getValue(), jsonObject.toJSONString());
System.out.println("---------update after: " + jedis.get(columns.get(0).getValue()));
} catch (Exception e) {
e.printStackTrace();
}
}
long startTime = System.currentTimeMillis();
long endTime = System.currentTimeMillis();
System.out.println("----costTime: " + (endTime - startTime) + " millisecond");
}
}
Data in the original database: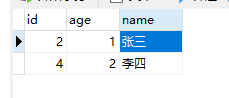
Original data in redis: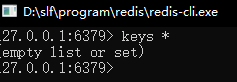
mysql adds a piece of data: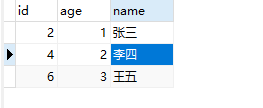
redis also added a piece of data: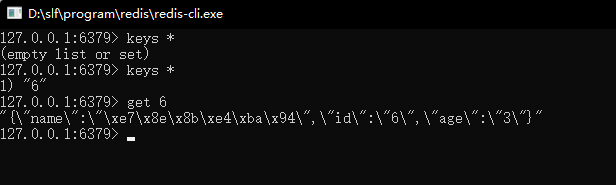
Console:
Flow chart of a more rigorous approach:
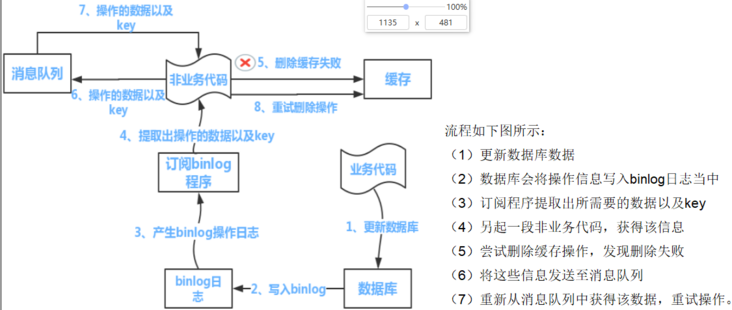
4. Summary
As for the double write consistency of cache, because strong consistency cannot be achieved, we still take the final consistency as the solution.