
Data synchronization mode
Two ways of data synchronization
CDC based on SQL query (change data capture):
- Offline scheduling query jobs, batch processing. Synchronize a table to other systems and obtain the latest data in the table through query every time. That is what we call SQL based query extraction;
- The consistency of data cannot be guaranteed, and the data may have been changed many times in the process of query;
- The real-time performance is not guaranteed, and there is natural delay based on off-line scheduling;
- The tool software, represented by Kettle (latest version of Apache Hop) and DataX, needs to be used in combination with the task scheduling system.
Log based CDC:
- Real time consumption log and stream processing. For example, the binlog log of MySQL completely records the changes in the database, and the binlog file can be used as the data source of the stream;
- Ensure data consistency, because binlog file contains all historical change details;
- Ensure real-time performance, because log files like binlog can be consumed in streaming mode and provide real-time data;
- Tool software is represented by Flink CDC, Alibaba Canal and Debezium.
Incremental data synchronization principle based on SQL query
How can we query incremental data with SQL? Data can be added, modified and deleted
Deleting data adopts the method of logical deletion, such as defining an is_ The deleted field identifies the logical deletion
If the data is updated, that is, it will be modified, then where UPDATE_ datetime >= last_ Datetime is incremental data
If the data is APPEND ONLY, in addition to the update time, you can also use where id > = to schedule the last last time_ id
Combined task scheduling system
If the scheduling time is once a day, then last_datetime = the start time of the current scheduling - 24 hours, and the delay is 1 days.
If the scheduling time is once every 15 minutes, then last_datetime = the start time of the current scheduling - 15 minutes, and the delay is 15 minutes.
In this way, incremental data is captured to realize incremental synchronization
Building an offline incremental data synchronization platform with dolphin scheduler + dataX
This practice uses
Single machine 8c16g
DataX 2022-03-01 official website download
Dolphin scheduler 2.0.3 (please refer to the official website for the installation process of dolphin scheduler)
Set the DataX environment variable in the dolphin scheduler
Dolphin scheduler provides a visual definition of job flow, which is used to schedule DataX Job jobs off-line. It is very smooth to use
Application of offline data synchronization based on SQL query
Why not use log based real-time method? Not no, but according to the field. Considering the actual business needs, the offline method based on SQL query is not completely eliminated
In particular, when the real-time requirements of the business are not high and the incremental data of each scheduling is not so large, the distributed architecture is not required to load. In this case, it is a more appropriate choice
Scenario example:
For the millions and tens of millions of content search of websites and apps, hundreds of content are added and modified every day. ES (elastic search) will be used in the search, so it is necessary to synchronize the increment of MySQL content data to ES
DataX can meet the demand!
Configure DataX MySQL To ElasticSearch workflow in dolphin scheduler
Workflow definition
Workflow definition > create workflow > drag 1 SHELL component > drag 1 DATAX component
SHELL component (article)
script
echo 'Article synchronization MySQL To ElasticSearch'
DATAX component (t_article)
Two plug-ins mysqlreader and elasticsearchwriter^[1] are used
Selected from defined templates:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://${biz_mysql_host}:${biz_mysql_port} / your database? useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF8&autoReconnect=true&useSSL=false&&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
],
"querySql": [
"select a.id as pk,a.id,a.title,a.content,a.is_delete,a.delete_date,a.create_date,a.update_date from t_article a.update_date >= '${biz_update_dt}';"
]
}
],
"password": "${biz_mysql_password}",
"username": "${biz_mysql_username}"
}
},
"writer": {
"name": "elasticsearchwriter",
"parameter": {
"endpoint": "${biz_es_host}",
"accessId": "${biz_es_username}",
"accessKey": "${biz_es_password}",
"index": "t_article",
"type": "_doc",
"batchSize": 1000,
"cleanup": false,
"discovery": false,
"dynamic": true,
"settings": {
"index": {
"number_of_replicas": 0,
"number_of_shards": 1
}
},
"splitter": ",",
"column": [
{
"name": "pk",
"type": "id"
},
{
"name": "id",
"type": "long"
},
{
"name": "title",
"type": "text"
},
{
"name": "content",
"type": "text"
}
{
"name": "is_delete",
"type": "text"
},
{
"name": "delete_date",
"type": "date"
},
{
"name": "create_date",
"type": "date"
},
{
"name": "update_date",
"type": "date"
}
]
}
}
}
],
"setting": {
"errorLimit": {
"percentage": 0,
"record": 0
},
"speed": {
"channel": 1,
"record": 1000
}
}
}
}The field configuration of reader and writer should be consistent
Custom parameters:
biz_update_dt: ${global_bizdate}
biz_mysql_host: Yours mysql ip
biz_mysql_port: 3306
biz_mysql_username: Yours mysql account number
biz_mysql_password: Yours mysql password
biz_es_host: Yours es Address with protocol and port http://127.0.0.1:9200
biz_es_username: Yours es account number
biz_es_password: Yours es passwordThe configured custom parameters will automatically replace the variables with the same name in the json template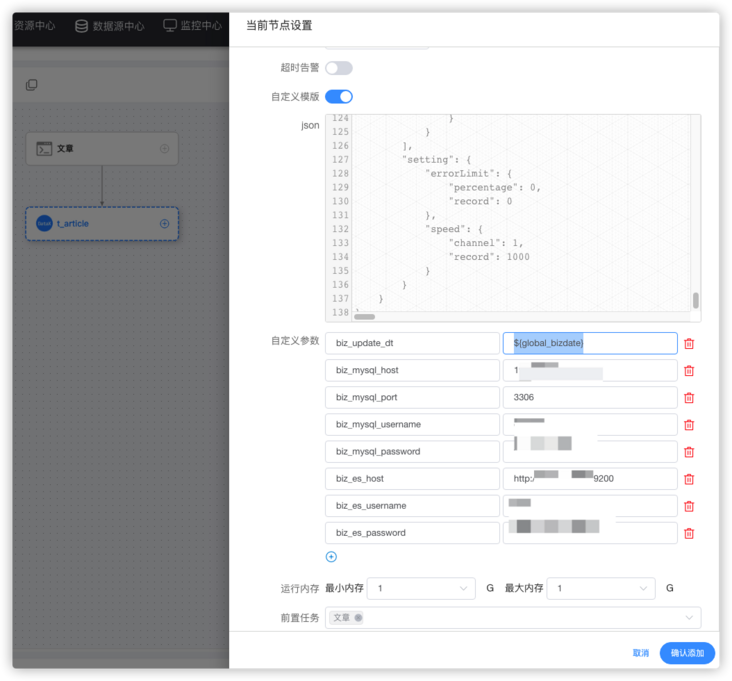
reader mysqlreader plug-in key configuration: a.update_ Date > = '${biz_update_dt}' is the key configuration to realize incremental synchronization
Key configurations in the writer elasticsearchwriter plug-in:``
"column": [
{
"name": "pk",
"type": "id"
},
......
]type = id is configured to map the article primary key to the ES primary key_ id to achieve the same primary key id. if the data is repeatedly written, the data will be updated. If not, the configuration data will be repeatedly imported into es
Save workflow
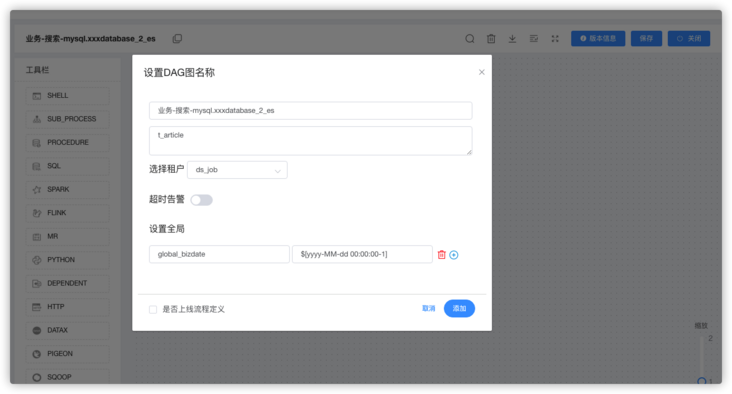
Global variable settings
global_bizdate: $[yyyy-MM-dd 00:00:00-1]
global_ The variables referenced by bizdate are built-in variables of dolphin scheduler. Please refer to the official website document ^ [2] for details
The window duration of time rolling is designed in combination with the scheduling time. For example, if the time is increased by 1 day, the time here is reduced by 1 day
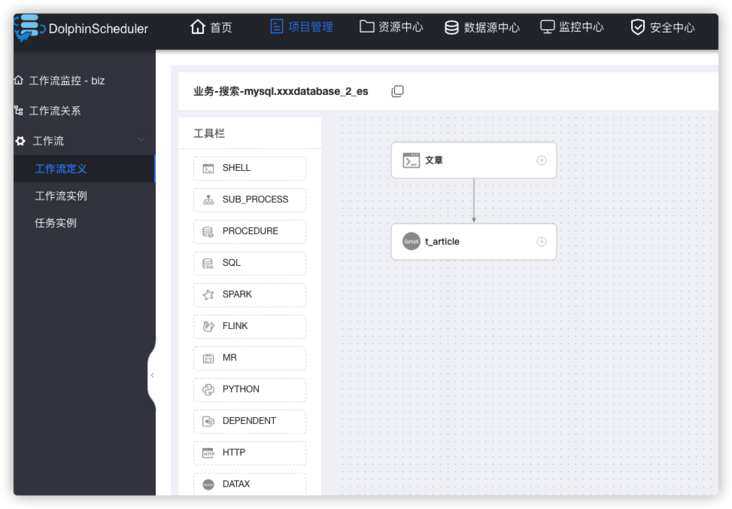
The final workflow DAG diagram is:
by running water managing fish 𞓜 wwek
reference resources
1. DataX ElasticSearchWriter plug-in document
2. Built in parameters of Apache dolphin scheduler
This article was first published in Running water fish blog , please indicate the source if you want to reprint.
Welcome to my official account: liushuiliyu, stack, cloud native, Homelab communication.
If you are interested in relevant articles, you can also follow my blog: www.iamle.com There's more on it