[source code analysis] NVIDIA HugeCTR, GPU version parameter server - (8) - Distributed Hash, then propagate to
0x00 summary
In this series, we introduce HugeCTR, an industry-oriented recommendation system training framework, which is optimized for large-scale CTR models with model parallel embedding and data parallel intensive networks. This article introduces the backward operation of distributed slotsparseembeddinghash.
Which draws lessons from HugeCTR source code reading Thank you for this masterpiece.
Other articles in this series are as follows:
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- (1)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (2)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (3)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (4)
[[source code analysis] NVIDIA HugeCTR, GPU version parameter server - (5) embedded hash table
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (6) - Distributed hash table
[[source code analysis] NVIDIA HugeCTR, GPU version parameter server - (7) - Distributed Hash
0x01 review
Previously, we introduced the forward propagation process of Distributed Hash, and its logical flow is as follows:
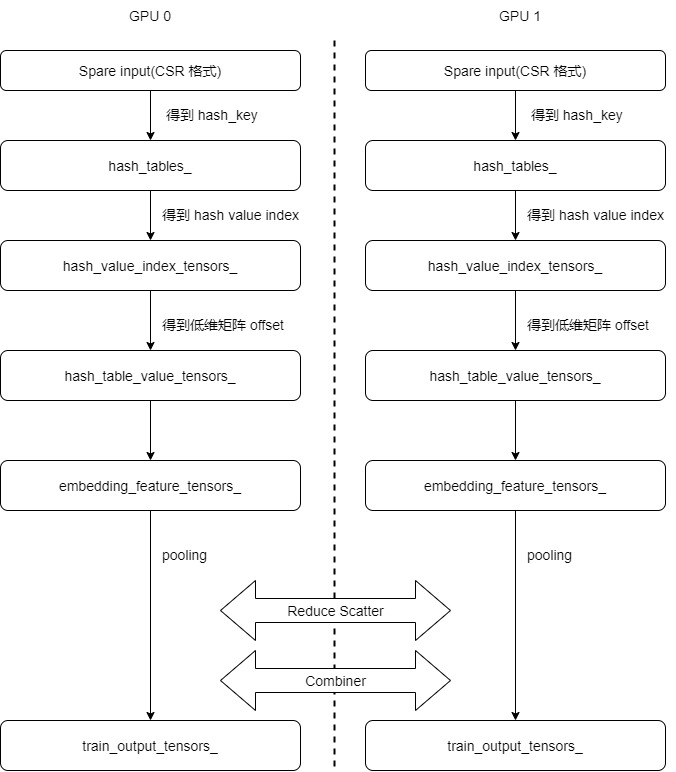
In this article, let's take a look at how to carry out backward communication.
0x02 general
Back propagation is to find out what impact the changes of various weights can have on the final error, or how to adjust various weights to make the estimation error as small as possible. In fact, it is to find the fastest direction of gradient decline for various weights and make the loss function quickly reach a best advantage globally.
2.1 notes
We can see from the comments that there are the following ideas. For backward propagation, it is to calculate the gradient and then update the embedded table. We will follow this idea to analyze the code.
/** * All the CUDA kernel functions used by embedding layer are defined in this file, including * forward propagation, backward propagation. The functions are defined by propagation type * and combiner type(sum or mean) as below: * 1) forward * sum: calling forward_sum_kernel() * mean: calling foward_sum_kernel() + forward_scale_kernel() * 2) backward: * calculating wgrad: * sum: calling backward_sum_kernel() * mean: calling backward_mean_kernel() * update embedding table: including several steps as below, * step1: expand sample IDs, calling sample_id_expand_kernel() * step2: get value_index by key (will call hash_table->get_insert() in nv_hashtable lib) * step3: sort by value_index (will call cub::DeviceRadixSort::SortPairs in cub lib) * step4: count the number for each unduplicated value_index, calling value_count_kernel() * step5: use optimizer method to compute deltaw, and record corresponding, including three * types of optimizer: Adam: caling opt_adam_kernel() Momentum sgd: calling * opt_momentum_sgd_kernel() Nesterov: calling opt_nesterov_kernel() step6: update embedding table * by deltaw, calling update_kernel() */
2.2 code
There are the following codes in session::train(), which correspond to the general idea.
- backward performs back propagation calculations.
- exchange_wgrad exchange gradient.
- update_params to update parameters.
// Embedding backward
for (const auto& one_embedding : embeddings_) {
one_embedding->backward();
}
// Exchange wgrad and update params
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
exchange_wgrad(id);
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
exchange_wgrad(0);
networks_[0]->update_params();
}
for (const auto& one_embedding : embeddings_) {
one_embedding->update_params();
}
0x03 input
Let's first look at how to get the input of back propagation. Because it is difficult to find from the embedded layer, let's change our thinking and look at it from the reshape layer.
3.1 definitions
You can see that its main member variable is the input in_tensors_ And output out_tensors_.
/**
* Layer which reshapes a 3D/2D input tensor to 2D output tensor,
* e.g., (batch_size, n_slots, vector_size) to (batch_size, n_slots * vector_size),
* e.g., (batch_size * n_slots, vector_size) to (batch_size, n_slots * vector_size),
* If the input tensor is 3D, you can choose which slots participate by calling the different Ctor
*/
template <typename T>
class ReshapeLayerCPU : public LayerCPU {
/*
* stores the weight tensors of this layer.
*/
Tensors2<T> weights_;
/*
* stores the weight gradient tensors of this layer.
*/
Tensors2<T> wgrad_;
/*
* stores the references to the input tensors of this layer.
*/
Tensors2<T> in_tensors_;
/*
* stores the references to the output tensors of this layer.
*/
Tensors2<T> out_tensors_;
bool in_place_;
int batch_size_;
int n_slot_;
int vector_length_;
size_t n_active_slot_;
Tensor2<int> selected_tensor_;
std::vector<int> selected_;
}
3.2 switching
From the code, we can know that the two member variables in are used repeatedly during training_ Tensor and out_tensor to switch.
- In forward propagation, fprop transfers data from in_ Copy tensor to out_tensor.
- When propagating backward, bprop transfers data from out_ Copy tensor to in_tensor.
Therefore, the input variable of forward propagation is used as the input variable during back propagation. Therefore, we can know that the embedded layer is also this routine.
template <typename T>
void ReshapeLayer<T>::fprop(bool is_train) {
prop_common(true, is_train, get_gpu().get_stream());
}
template <typename T>
void ReshapeLayer<T>::bprop() {
prop_common(false, true, get_gpu().get_stream());
}
template <typename T>
void ReshapeLayer<T>::prop_common(bool forward, bool is_train, cudaStream_t stream) {
CudaDeviceContext context(get_device_id());
Tensor2<T>& in_tensor = get_in_tensors(is_train)[0];
Tensor2<T>& out_tensor = out_tensors_[0];
if (in_place_) {
if (forward) { // Forward propagation
CK_CUDA_THROW_(cudaMemcpyAsync(out_tensor.get_ptr(), in_tensor.get_ptr(),
in_tensor.get_size_in_bytes(), cudaMemcpyDeviceToDevice,
stream));
} else { // Back propagation
CK_CUDA_THROW_(cudaMemcpyAsync(in_tensor.get_ptr(), out_tensor.get_ptr(),
out_tensor.get_size_in_bytes(), cudaMemcpyDeviceToDevice,
stream));
}
} else {
int block_size = 128;
int n_block = get_gpu().get_sm_count() * 16;
T* in = in_tensor.get_ptr();
T* out = out_tensor.get_ptr();
reshape_kernel<<<n_block, block_size>>>(in, out, batch_size_, n_slot_, vector_length_,
selected_tensor_.get_ptr(), n_active_slot_, forward);
}
#ifndef NDEBUG
CK_CUDA_THROW_(cudaDeviceSynchronize());
CK_CUDA_THROW_(cudaGetLastError());
#endif
}
0x04 backward
4.1 overall code
From the previous analysis, we can know that during back propagation, the input gradient is stored in embedding_data_.get_output_tensors(true). The overall code is divided into two parts. The first step is to use the all gather operation to collect all gradients of all samples on each GPU. The second step is to call functions_ Backward.
/**
* The first stage of backward propagation of embedding layer,
* which only computes the wgrad by the dgrad from the top layer.
*/
void backward() override {
// Read dgrad from output_tensors -> compute wgrad
// do all-gather to collect the top_grad
size_t send_count = embedding_data_.get_batch_size_per_gpu(true) *
embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.embedding_vec_size;
functors_.all_gather(send_count, embedding_data_.get_output_tensors(true),
embedding_feature_tensors_, embedding_data_.get_resource_manager());
// do backward
functors_.backward(embedding_data_.embedding_params_.get_batch_size(true),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner, row_offset_allreduce_tensors_,
embedding_feature_tensors_, wgrad_tensors_,
embedding_data_.get_resource_manager());
return;
}
4.2 AllGather
The first step of back propagation is to use the all gather operation to all the gradients of all samples collected on each GPU, so that subsequent calculation can be carried out and the parameters on each GPU can be updated.
4.2.1 principle
First, let's look at the AllGather principle. During AllGather operation, each of the K processors will aggregate N values from each processor into an output with dimension K*N. The output is sorted by rank index. The AllGather operation will be affected by different rank or device mapping, because rank determines the data layout.
Note: executing ReduceScatter + AllGather is equivalent to AllReduce.
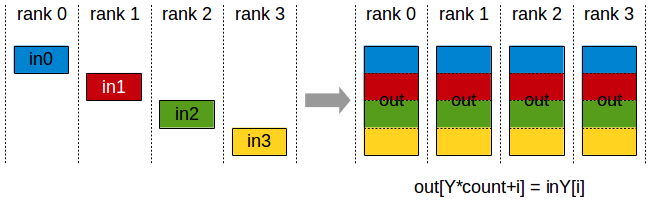
4.2.2 code
The calling code is as follows. You can see that it will embed the gradient from the back-propagation input_ data_. get_ output_ Tensors (true) copy to embedding_feature_tensors_. Therefore, embedding_feature_tensors_ Will have all the gradients.
functors_.all_gather(send_count, embedding_data_.get_output_tensors(true),
embedding_feature_tensors_, embedding_data_.get_resource_manager());
Operators are as follows:
/**
* collection communication: all_gather.
* @param send_count the count of elements will be sent.
* @param send_tensors the send tensors of multi GPUs.
* @param recv_tensors the recv tensors of multi GPUs.
* @param device_resources all gpus device resources.
* @param context gpu device context, for switching device.
*/
template <typename Type>
void SparseEmbeddingFunctors::all_gather(size_t send_count, const Tensors2<Type> &send_tensors,
Tensors2<Type> &recv_tensors,
const ResourceManager &resource_manager) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
size_t total_gpu_count = resource_manager.get_global_gpu_count();
// need to know the Type
ncclDataType_t type;
switch (sizeof(Type)) {
case 2:
type = ncclHalf;
break;
case 4:
type = ncclFloat;
break;
default:
CK_THROW_(Error_t::WrongInput, "Error: Type not support by now");
}
// for multi GPUs, use NCCL to do All-Gather
if (total_gpu_count > 1) {
CK_NCCL_THROW_(ncclGroupStart());
for (size_t id = 0; id < local_gpu_count; id++) {
const auto &local_gpu = resource_manager.get_local_gpu(id);
CK_NCCL_THROW_(ncclAllGather(send_tensors[id].get_ptr(), // send buff
recv_tensors[id].get_ptr(), // recv buff
send_count, type, local_gpu->get_nccl(),
local_gpu->get_stream()));
}
CK_NCCL_THROW_(ncclGroupEnd());
}
// for single GPU, just do memcpyD2D
else { // total_gpu_count == 1
const auto &local_gpu = resource_manager.get_local_gpu(0);
CudaDeviceContext context(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(recv_tensors[0].get_ptr(), send_tensors[0].get_ptr(),
send_count * sizeof(Type), cudaMemcpyDeviceToDevice,
local_gpu->get_stream()));
}
return;
}
4.3 backward
This part completes the following functions: calculate the gradient on each GPU locally. When this function is complete, wgrad_tensors_ The member variable is the new gradient generated by the GPU calculation.
// do backward
functors_.backward(embedding_data_.embedding_params_.get_batch_size(true),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner, row_offset_allreduce_tensors_,
embedding_feature_tensors_, wgrad_tensors_,
embedding_data_.get_resource_manager());
calculating wgrad, one of the following two options will be selected:
- sum: calling backward_sum_kernel() ;
- mean: calling backward_mean_kernel();
The specific backward code is as follows:
template <typename TypeHashKey, typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::backward(size_t batch_size,
const std::vector<size_t> &slot_num_per_gpu,
size_t embedding_vec_size, int combiner,
const Tensors2<TypeHashKey> &row_offset_allreduce_tensors,
const Tensors2<TypeEmbeddingComp> &embedding_feature_tensors,
Tensors2<TypeEmbeddingComp> &wgrad_tensors,
const ResourceManager &resource_manager) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
CudaDeviceContext context;
for (size_t id = 0; id < local_gpu_count; id++) { // Traverse local GPU
if (slot_num_per_gpu[id] == 0) {
continue;
}
const auto &local_gpu = resource_manager.get_local_gpu(id);
context.set_device(local_gpu->get_device_id());
// Get the gradient and offset information corresponding to a GPU
const TypeEmbeddingComp *top_grad = embedding_feature_tensors[id].get_ptr();
const TypeHashKey *row_offset = row_offset_allreduce_tensors[id].get_ptr();
TypeEmbeddingComp *wgrad = wgrad_tensors[id].get_ptr();
// Calculate and update local gradient
if (combiner == 0) // sum
{
backward_sum(batch_size, slot_num_per_gpu[id], embedding_vec_size, top_grad, wgrad,
local_gpu->get_stream());
} else if (combiner == 1) // mean
{
backward_mean(batch_size, slot_num_per_gpu[id], embedding_vec_size, row_offset, top_grad,
wgrad, local_gpu->get_stream());
} else {
CK_THROW_(Error_t::WrongInput, "Invalid combiner type ");
}
}
return;
}
We take backward_ Taking sum as an example, GPU multithreading update is adopted to speed up the speed.
template <typename TypeEmbeddingComp>
void backward_sum(size_t batch_size, size_t slot_num, size_t embedding_vec_size,
const TypeEmbeddingComp *top_grad, TypeEmbeddingComp *wgrad,
cudaStream_t stream) {
const size_t grid_size = batch_size; // each block corresponds to a sample
const size_t block_size = embedding_vec_size;
backward_sum_kernel<<<grid_size, block_size, 0, stream>>>(batch_size, slot_num,
embedding_vec_size, top_grad, wgrad);
}
// backward kernel function: for combiner=sum
template <typename TypeEmbeddingComp>
__global__ void backward_sum_kernel(int batch_size, int slot_num, int embedding_vec_size,
const TypeEmbeddingComp *top_grad, TypeEmbeddingComp *wgrad) {
int tid = threadIdx.x;
int bid = blockIdx.x;
if (bid < batch_size && tid < embedding_vec_size) {
for (int i = 0; i < slot_num; i++) {
// First find the position of a dense tensor, and then add tid to get the position of an element in the tensor (the element corresponding to this tid)
size_t feature_index = (size_t)(bid * slot_num + i) * embedding_vec_size + tid;
// Update gradient value
wgrad[feature_index] = top_grad[feature_index];
}
}
}
For comparison, post backward_mean_kernel, you can compare and learn.
// backward kernel function: for combiner=mean
template <typename TypeKey, typename TypeEmbeddingComp>
__global__ void backward_mean_kernel(int batch_size, int slot_num, int embedding_vec_size,
const TypeKey *row_offset, const TypeEmbeddingComp *top_grad,
TypeEmbeddingComp *wgrad) {
int bid = blockIdx.x;
int tid = threadIdx.x;
if (bid < batch_size && tid < embedding_vec_size) {
for (int i = 0; i < slot_num; i++) {
size_t feature_row_index = bid * slot_num + i;
int value_num = row_offset[feature_row_index + 1] - row_offset[feature_row_index];
float scaler = 1.0f;
if (value_num > 1) {
scaler = 1.0f / value_num; // partial derivatice of MEAN
}
size_t feature_index = feature_row_index * embedding_vec_size + tid;
float g = TypeConvertFunc<float, TypeEmbeddingComp>::convert(top_grad[feature_index]);
g *= scaler;
wgrad[feature_index] = TypeConvertFunc<TypeEmbeddingComp, float>::convert(g);
}
}
}
Now, wgrad_tensors_ It is already the gradient generated by the local GPU. You need to update the weight of the embedded layer according to this, that is, update the hash_table_value.
0x05 ExchangeWgrad
session.train will then exchange gradients and update network parameters.
// Exchange wgrad and update params
if (networks_.size() > 1) {
#pragma omp parallel num_threads(networks_.size())
{
size_t id = omp_get_thread_num();
exchange_wgrad(id);
networks_[id]->update_params();
}
} else if (resource_manager_->get_global_gpu_count() > 1) {
exchange_wgrad(0);
networks_[0]->update_params();
}
The specific codes are as follows:
void Session::exchange_wgrad(size_t device_id) {
auto& gpu_resource = resource_manager_->get_local_gpu(device_id);
CudaCPUDeviceContext context(gpu_resource->get_device_id());
PROFILE_RECORD("exchange_wgrad.start", gpu_resource->get_stream(), false);
exchange_wgrad_->allreduce(device_id, gpu_resource->get_stream());
PROFILE_RECORD("exchange_wgrad.stop", gpu_resource->get_stream(), false);
}
5.1 definitions
As can be seen from the definition, the function of exchange wgrad is to simply encapsulate the underlying resources.
class ExchangeWgrad {
public:
virtual void allocate() = 0;
virtual void update_embed_wgrad_size(size_t size) = 0;
virtual void allreduce(size_t device_id, cudaStream_t stream) = 0;
};
template <typename TypeFP>
class NetworkExchangeWgrad : public ExchangeWgrad {
public:
const BuffPtrs<TypeFP>& get_network_wgrad_buffs() const { return network_wgrad_buffs_; }
const BuffPtrs<TypeFP>& get_embed_wgrad_buffs() const { return null_wgrad_buffs_; }
void allocate() final;
void update_embed_wgrad_size(size_t size) final;
void allreduce(size_t device_id, cudaStream_t stream);
NetworkExchangeWgrad(const std::shared_ptr<ResourceManager>& resource_manager);
~NetworkExchangeWgrad() = default;
private:
BuffPtrs<TypeFP> network_wgrad_buffs_;
BuffPtrs<TypeFP> null_wgrad_buffs_;
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> bufs_;
std::shared_ptr<ResourceManager> resource_manager_;
AllReduceInPlaceComm::Handle ar_handle_;
size_t network_wgrad_size_ = 0;
size_t num_gpus_ = 0;
};
template <typename TypeFP>
class GroupedExchangeWgrad : public ExchangeWgrad {
public:
const BuffPtrs<TypeFP>& get_network_wgrad_buffs() const { return network_wgrad_buffs_; }
const BuffPtrs<TypeFP>& get_embed_wgrad_buffs() const { return embed_wgrad_buffs_; }
void allocate() final;
void update_embed_wgrad_size(size_t size) final;
void allreduce(size_t device_id, cudaStream_t stream);
GroupedExchangeWgrad(const std::shared_ptr<ResourceManager>& resource_manager);
~GroupedExchangeWgrad() = default;
private:
BuffPtrs<TypeFP> network_wgrad_buffs_;
BuffPtrs<TypeFP> embed_wgrad_buffs_;
std::vector<std::shared_ptr<GeneralBuffer2<CudaAllocator>>> bufs_;
std::shared_ptr<ResourceManager> resource_manager_;
AllReduceInPlaceComm::Handle ar_handle_;
size_t network_wgrad_size_ = 0;
size_t embed_wgrad_size_ = 0;
size_t num_gpus_ = 0;
};
5.2 functions
The exchange function mainly uses the underlying all_reduce to complete the operation.
template <typename T>
void NetworkExchangeWgrad<T>::allreduce(size_t device_id, cudaStream_t stream) {
auto ar_comm = resource_manager_->get_ar_comm();
ar_comm->all_reduce(ar_handle_, stream, device_id);
}
template <typename T>
void GroupedExchangeWgrad<T>::allreduce(size_t device_id, cudaStream_t stream) {
auto ar_comm = resource_manager_->get_ar_comm();
ar_comm->all_reduce(ar_handle_, stream, device_id);
}
0x06 update parameters
Session.train will then let the embedded layer update the parameters, specifically using the optimizer.
for (const auto& one_embedding : embeddings_) {
one_embedding->update_params();
}
The specific code is as follows. The main logic is to update the hash table in cooperation with the wgrad generated by the optimizer and backward().
/**
* The second stage of backward propagation of embedding layer, which
* updates the hash table by wgrad(from backward()) and optimizer.
*/
void update_params() override {
// accumulate times for adam optimizer
embedding_data_.embedding_params_.opt_params.hyperparams.adam.times++;
#pragma omp parallel num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
{
size_t id = omp_get_thread_num();
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
// do update params operation
embedding_optimizers_[id].update(
embedding_data_.embedding_params_.get_batch_size(true),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, max_vocabulary_size_per_gpu_,
*embedding_data_.get_nnz_array(true)[id],
embedding_data_.get_row_offsets_tensors(true)[id], hash_value_index_tensors_[id],
wgrad_tensors_[id], hash_table_value_tensors_[id],
embedding_data_.get_local_gpu(id).get_sm_count(),
embedding_data_.get_local_gpu(id).get_stream());
}
return;
}
This part is the difficulty of reverse operation. The problem now is, wgrad_tensors_ There is already a gradient in the. You need to update the weight of the embedded layer according to this, which is hash_table_value. But how to update it? For example, how to use GPU multithreaded update? Need to update hash_value_index_index? Let's analyze it step by step.
6.1 problems and ideas
If batch_size=2,slot_num=2, give an example of CSR. The format is as follows (two samples):
* 40,50,10,20 // Sample 1, slot 1 * 30,50,10 // Sample 1, slot 2 * 30,20 // Sample 2, slot 1 * 10 // Sample 2, slot 2 * Will be convert to the form of: * row offset: 0,4,7,9,10 * value: 40,50,10,20,30,50,10,30,20,10
6.1.1 forward propagation
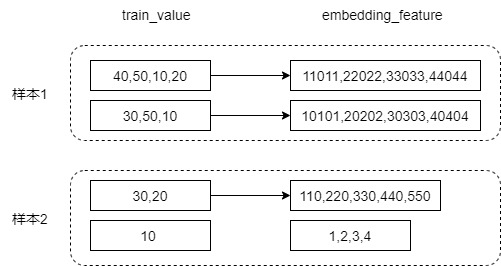
The following figure shows the embedding look example of forward propagation and the finally generated embedding_ The number of embedded vectors in the feature is: batch_size x slot_num, for our example: 40,50,10,20,30,50,10,30,20,10, which is divided into slots: [40,50,10,20], [30,50,10], [30,20], [10]. Corresponding to embedding_ Four rows in the feature matrix.
Note: the last output is train_output_tensors_, The intermediate variable is embedding_feature,embedding_ After several communication changes between GPU s, the feature evolved into a train_output_tensors_ , The two dimensions are the same, so we use embedding_feature. The numbers in the figure below are constructed for demonstration only.
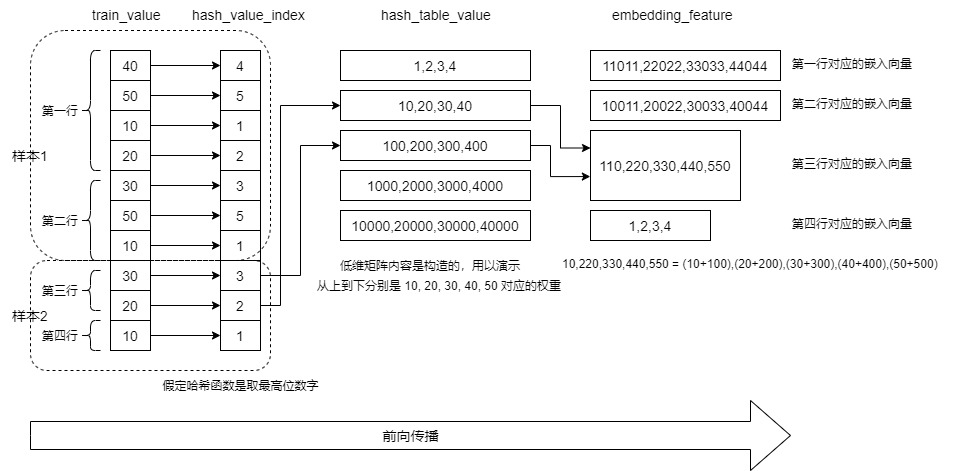
We give embedding_ The calculation process of the third vector in the feature corresponds to the first slot of the second sample, which is "30,20". So it's from hash_table_value selects the second line and the third line, and the corresponding position elements are added, that is, the calculation process given in the figure.
6.1.2 backward propagation
Let's consider backward propagation.
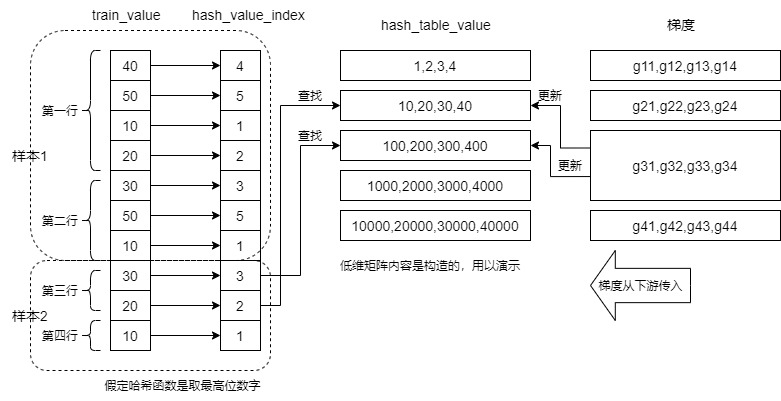
When propagating backward, use gradient to update the weight. The line G31, G32, G33 and G34 should update the hash_ table_ Line 2 and line 3 of value. In addition, if you assume that the first slot of the second sample is "30,20,20,20", you should actually update the hash with a gradient_ table_ The second line of value is three times, and the third line is once. In fact, you can also see that you don't need to know train for this update_ What is the value of value.
6.1.3 ideas
Let's sort out the above examples with conventional ideas:
- sample_ The ID list corresponds to 40, 50, 10, 20,..., 20 is a key, which embeds the hash table in the low dimension_ table_ Value corresponds to a dense vector (line 2 10,20,30,40), which is the weight.
- The output of the embedding layer is embedding_feature.
- The number of embedded vectors is: batch_size x slot_num, that is, CSR has several lines, and here there are several vectors.
- The third vector corresponds to the first slot of the second sample, which is "30,20". So it's from hash_table_value selects line 2 and line 3, and the corresponding position elements are added: 10220330440550 = (10 + 100), (20 + 200), (30 + 300), (40 + 400), (50 + 500).
- If there is a gradient dense vector, it is the result of pooling by several dense vectors of hash table value.
- For example, the third vector G31, G32, G33 and G34 of the gradient matrix corresponds to embedding_ The third vector of feature is 10220330440550. If the gradient updates the weight, the hash should be updated_ table_ Line 2 and line 3 of value.
- If there are multiple same values in the sample slot, for example, the first slot of the second sample is "30,20,20,20", then the update hash should be used_ table_ The second line of value is three times, and the third line is once.
We then look at how to update from the CUDA point of view. The purpose is to update a low dimensional matrix hash for each block_ table_ Value, so there are several questions:
-
How to find its row offset in the low dimensional moment dense vector matrix according to the block id of this GPU thread, assuming that it is the second row.
-
How to know how many times this block should update the second line.
-
Which gradient is used to update these times.
- For example, the first gradient may update the second row, and the third gradient may also update the second row. For our example, 40,50,10,20,30,50,10,30,20,10 are divided into slot s: [40,50,10,20], [30,50,10], [30,20], [10]. They correspond to four rows in the gradient matrix respectively, so it is necessary to update the hash corresponding to 10 from the gradients of rows 1, 2 and 4 in the gradient matrix_ table_ value.
- See the figure below for details. Here is train_value to gradient is only a schematic, that is, one-to-one correspondence in logic.
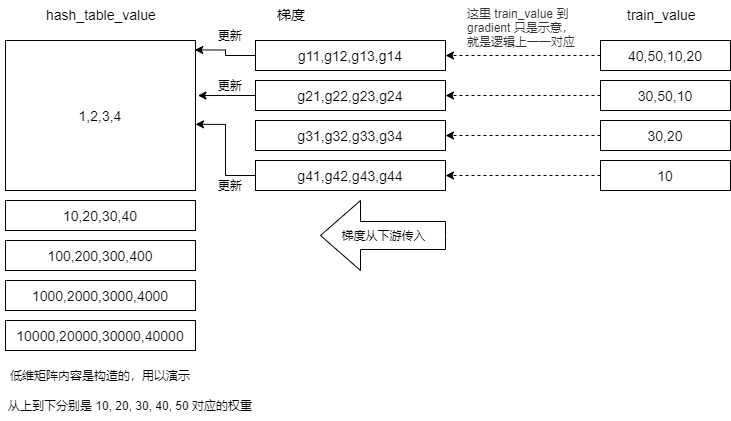
There is a question here. Why not operate like forward communication, but start over again? This is because we don't need to know the sample value to update the weight, and we don't need to go through the process of operating the hash table again. So, let's take a look at how HugeCTR solves these problems. The code here is brain burning.
6.2 embedded layer update
Let's first look at the overall code of the embedded layer and the ideas mentioned in the comments.
6.2.1 notes
There are five steps about updating in the notes. We can see the general idea:
-
step1: expand sample IDs, calling sample_id_expand_kernel();
-
step2: get value_index by key (will call hash_table->get_insert() in nv_hashtable lib);
-
step3: sort by value_index (will call cub::DeviceRadixSort::SortPairs in cub lib);
-
step4: count the number for each unduplicated value_index, calling value_count_kernel();
-
step5: use optimizer method to compute deltaw, and record corresponding;
/** * All the CUDA kernel functions used by embedding layer are defined in this file, including * forward propagation, backward propagation. The functions are defined by propagation type * and combiner type(sum or mean) as below: * 1) forward * sum: calling forward_sum_kernel() * mean: calling foward_sum_kernel() + forward_scale_kernel() * 2) backward: * calculating wgrad: * sum: calling backward_sum_kernel() * mean: calling backward_mean_kernel() * update embedding table: including several steps as below, * step1: expand sample IDs, calling sample_id_expand_kernel() * step2: get value_index by key (will call hash_table->get_insert() in nv_hashtable lib) * step3: sort by value_index (will call cub::DeviceRadixSort::SortPairs in cub lib) * step4: count the number for each unduplicated value_index, calling value_count_kernel() * step5: use optimizer method to compute deltaw, and record corresponding, including three * types of optimizer: Adam: caling opt_adam_kernel() Momentum sgd: calling * opt_momentum_sgd_kernel() Nesterov: calling opt_nesterov_kernel() step6: update embedding table * by deltaw, calling update_kernel() */
6.2.2 update code
We excerpt the code of EmbeddingOptimizer::update as follows. Here we just select optimizer_ t: : relevant part of adagrad through opt_ adagrad_ Update the kernel. We can see the following steps in the analysis one by one.
template <typename TypeHashKey, typename TypeEmbeddingComp>
void EmbeddingOptimizer<TypeHashKey, TypeEmbeddingComp>::update(
size_t batch_size, size_t slot_num, size_t embedding_vec_size,
size_t max_vocabulary_size_per_gpu, size_t nnz, const Tensor2<TypeHashKey> &row_offset,
Tensor2<size_t> &hash_value_index, const Tensor2<TypeEmbeddingComp> &wgrad,
Tensor2<float> &hash_table_value, size_t sm_count, cudaStream_t stream) {
OptimizerTensor<TypeEmbeddingComp> &opt_tensor = opt_tensors_;
OptParams &opt_params = param.opt_params;
Tensor2<TypeHashKey> &sample_id = sample_id_tensors_;
Tensor2<TypeHashKey> &sample_id_sort = sample_id_sort_tensors_;
Tensor2<size_t> &hash_value_index_sort = hash_value_index_sort_tensors_;
Tensor2<uint32_t> &hash_value_index_count_offset = hash_value_index_count_offset_tensors_;
Tensor2<uint32_t> &new_hash_value_flag = new_hash_value_flag_tensors_;
Tensor2<uint32_t> &hash_value_flag_sumed = hash_value_flag_sumed_tensors_;
Tensor2<uint32_t> &hash_value_index_count_counter = hash_value_index_count_counter_tensors_;
Tensor2<void> &temp_storage_sort = temp_storage_sort_tensors_;
Tensor2<void> &temp_storage_scan = temp_storage_scan_tensors_;
size_t block_size, grid_size;
try {
// step1: expand sample IDs
block_size = 64;
grid_size = (batch_size * slot_num - 1) / block_size + 1;
sample_id_expand_kernel<<<grid_size, block_size, 0, stream>>>(
batch_size, slot_num, row_offset.get_ptr(), sample_id.get_ptr());
if (opt_params.optimizer == Optimizer_t::SGD &&
opt_params.hyperparams.sgd.atomic_update) { // for SGD, do atomic update
const size_t block_size = embedding_vec_size;
const size_t grid_size = min(max(1ul, nnz), sm_count * 32);
float lr_scale = opt_params.lr / opt_params.scaler;
opt_sgd_atomic_kernel<<<grid_size, block_size, 0, stream>>>(
nnz, embedding_vec_size, lr_scale, hash_value_index.get_ptr(), sample_id.get_ptr(),
wgrad.get_ptr(), hash_table_value.get_ptr());
} else {
// step3: sort by hash_value_index
int end_bit = static_cast<int>(log2(static_cast<float>(max_vocabulary_size_per_gpu))) + 1;
size_t temp_storage_sort_size = temp_storage_sort.get_size_in_bytes();
CK_CUDA_THROW_(cub::DeviceRadixSort::SortPairs(
temp_storage_sort.get_ptr(), temp_storage_sort_size, hash_value_index.get_ptr(),
hash_value_index_sort.get_ptr(), sample_id.get_ptr(), sample_id_sort.get_ptr(), nnz, 0,
end_bit, stream, false));
// step4: count the number for each unduplicated hash_value_index
CK_CUDA_THROW_(
cudaMemsetAsync(hash_value_index_count_counter.get_ptr(), 0, sizeof(uint32_t), stream));
constexpr size_t max_grid_size = 384;
block_size = 256;
grid_size = min(max_grid_size, (nnz - 1) / block_size + 1);
value_count_kernel_1<<<grid_size, block_size, 0, stream>>>(
nnz, hash_value_index_sort.get_ptr(), new_hash_value_flag.get_ptr());
// a pinned memroy
CK_CUDA_THROW_(cudaMemcpyAsync(&hash_hash_value_index_count_num,
hash_value_index_count_counter.get_ptr(), sizeof(uint32_t),
cudaMemcpyDeviceToHost, stream));
// step5: use optimizer method to compute deltaw and update the parameters
block_size = embedding_vec_size;
grid_size = max(1, hash_hash_value_index_count_num);
switch (opt_params.update_type) {
case Update_t::Global: {
switch (opt_params.optimizer) {
case Optimizer_t::Adam: {
}
case Optimizer_t::AdaGrad: {
opt_adagrad_kernel<<<grid_size, block_size, 0, stream>>>(
hash_hash_value_index_count_num, embedding_vec_size, opt_params.lr,
opt_params.hyperparams.adagrad, opt_tensor.opt_accm_tensors_.get_ptr(),
sample_id_sort.get_ptr(), hash_value_index_sort.get_ptr(),
hash_value_index_count_offset.get_ptr(), wgrad.get_ptr(),
hash_table_value.get_ptr(), opt_params.scaler);
break;
}
case Optimizer_t::MomentumSGD:
case Optimizer_t::Nesterov:
case Optimizer_t::SGD:
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid opitimizer type");
} // switch (optimizer)
break;
}
case Update_t::Local: {
switch (opt_params.optimizer) {
case Optimizer_t::Adam: {
}
case Optimizer_t::AdaGrad: {
opt_adagrad_kernel<<<grid_size, block_size, 0, stream>>>(
hash_hash_value_index_count_num, embedding_vec_size, opt_params.lr,
opt_params.hyperparams.adagrad, opt_tensor.opt_accm_tensors_.get_ptr(),
sample_id_sort.get_ptr(), hash_value_index_sort.get_ptr(),
hash_value_index_count_offset.get_ptr(), wgrad.get_ptr(),
hash_table_value.get_ptr(), opt_params.scaler);
break;
}
case Optimizer_t::MomentumSGD:
case Optimizer_t::Nesterov:
case Optimizer_t::SGD:
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid opitimizer type");
} // switch (optimizer)
break;
}
case Update_t::LazyGlobal: {
switch (opt_params.optimizer) {
case Optimizer_t::Adam: {
}
case Optimizer_t::AdaGrad:
case Optimizer_t::MomentumSGD:
case Optimizer_t::Nesterov:
case Optimizer_t::SGD: {
CK_THROW_(Error_t::WrongInput,
"Error: lazy global update is only implemented for Adam");
break;
}
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid opitimizer type");
}
break;
}
default:
CK_THROW_(Error_t::WrongInput, "Error: Invalid update type");
} // switch (update type)
}
#ifndef NDEBUG
cudaDeviceSynchronize();
CK_CUDA_THROW_(cudaGetLastError());
#endif
} catch (const std::runtime_error &rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
First of all, nnz (non-zero feature number per batch) comes from the following, that is, the number of non-zero key s in this sample.
std::vector<std::shared_ptr<size_t>>& get_nnz_array(bool is_train) {
if (is_train) {
return train_nnz_array_;
} else {
return evaluate_nnz_array_;
}
}
Let's look at these steps one by one.
6.3 expand sample id
This corresponds to the first step. In subsequent codes, each key corresponds to a sample ID. The general idea is to find each key (sample ID) and gradient matrix, or embedding_ Which line in the feature corresponds to, we will directly embed it later_ From the perspective of feature, the gradient matrix is not considered for the time being. It can be roughly understood as expanding the sample ID to a list of key IDs.
step1: expand sample IDs, calling sample_id_expand_kernel()
Is to call sample_id_expand_kernel to expand the sample id. Here is sample_id is the member variable sample_id_tensors_ So that member variables can be modified directly.
Tensor2<TypeHashKey> sample_id_tensors_; /**< The temp memory to store the sample ids of hash table value in update_params(). */
The specific codes are as follows:
Tensor2<TypeHashKey> &sample_id = sample_id_tensors_;
// step1: expand sample IDs
block_size = 64;
grid_size = (batch_size * slot_num - 1) / block_size + 1;
sample_id_expand_kernel<<<grid_size, block_size, 0, stream>>>(
batch_size, slot_num, row_offset.get_ptr(), sample_id.get_ptr());
Through the previous analysis, we know that the number of embedded vectors is: batch_size x slot_num, that is, CSR has several lines, and here there are several vectors. Therefore, you can directly read the CSR line information here. That is, sample_ id_ expand_ The kernel will send the sample_id_tensors_ Set it to CSR row offset (expand sample id by row_offset) to find the index in CSR row offset.
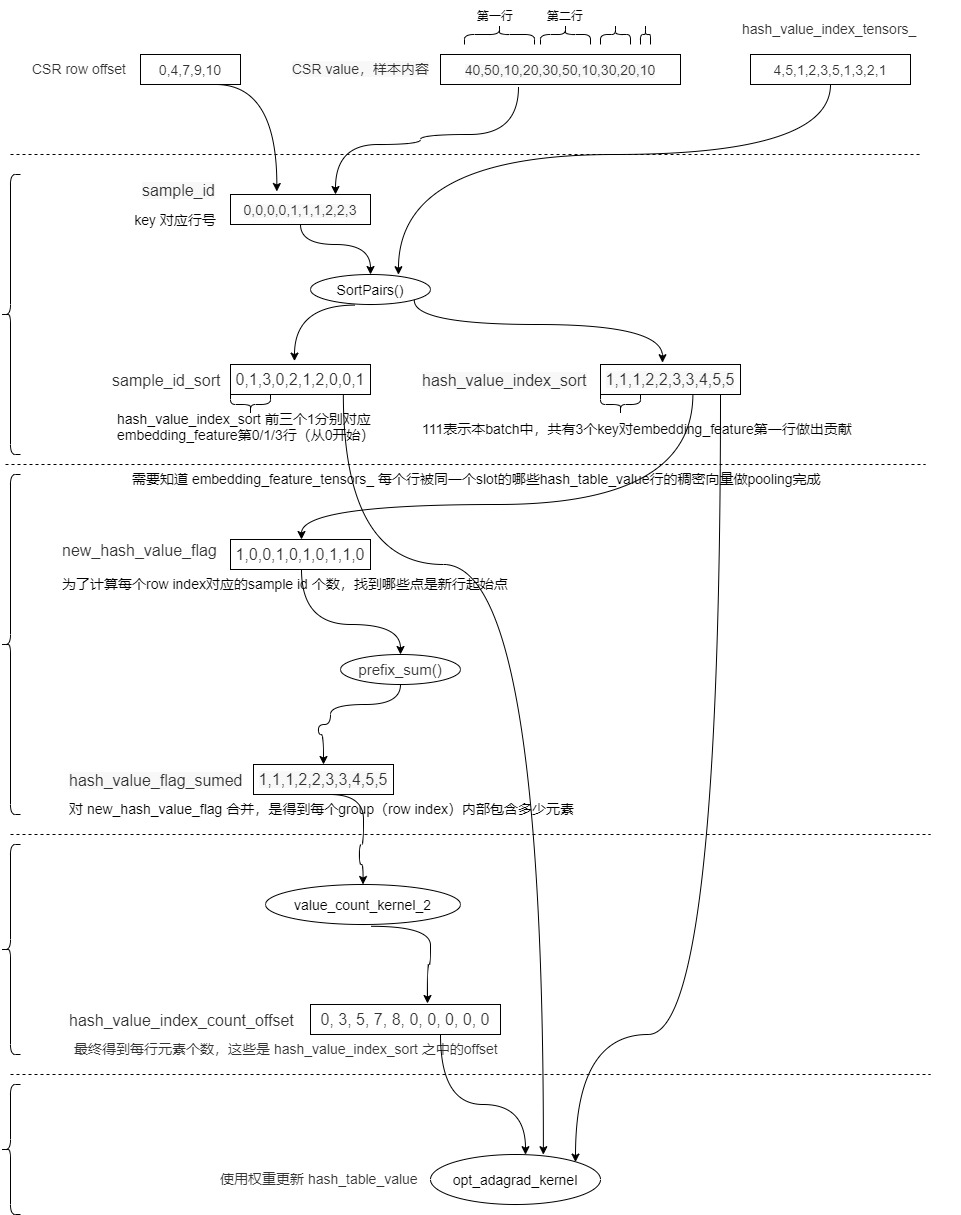
CSR row_offset = [0,4,7,9,10], the value of key in the sample is 40,50,10,20,30,50,10,30,20,10, then 40,50,10,20 corresponds to 0, 30,50,10 corresponds to 1, 30,20 corresponds to 2, and 10 corresponds to 3. Therefore, sample_ The ID value is [0,0,0,0,1,1,1,2,2,3], which records the embedding of the batch_ feature_ tensors_ row index in.
sample_ id_ expand_ The kernel code is as follows. Here are some key points:
- gid is the grid ID, indicating that this thread corresponds to embedding_feature_tensors_ Which element.
- blockIdx represents a sample.
- (batch_size * slot_num) represents that this batch outputs train in the embedded layer_ output_ tensors_ How many lines are there in, or embedded_ feature_ tensors_ How many lines does it occupy? In fact, embedding_feature_tensors_ That's it.
- sample_id[offset + i] = gid; The purpose is to record the embedding of a key in the sample_ feature_ tensors_ row index (corresponding to which row). embedding_feature_tensors_ This dense vector is generated by hash_ table_ The result is obtained by pooling the "number of elements in CSR line" in value.
// expand sample id by row_offset
template <typename TypeKey>
__global__ void sample_id_expand_kernel(int batch_size, int slot_num, const TypeKey *row_offset, TypeKey *sample_id) {
// The grid id corresponding to this thread actually corresponds to the global thread id
int gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (batch_size * slot_num)) { // If batch_size=2,slot_num=2, GID < 4
// Not every GPU thread will come here. According to our assumption, only threads with gid = 0~3 will be taken out for the following configuration operations
// For example, if the gid value range is 8, only gid=0,gid=1,gid=2,gid=3 threads will enter if to execute the operation, and other threads will not enter. For example, grid=4 will not enter
TypeKey offset = row_offset[gid]; // Get the corresponding number, such as row_offset[0],row_offset[1],row_ Value of offset [2]
int value_num = row_offset[gid + 1] - offset; // Get the number of elements in CSR line
for (int i = 0; i < value_num; i++) {
sample_id[offset + i] = gid; // Record the embedding of a key in the sample_ feature_ tensors_ row index in
}
}
}
We sort out the variables involved at present as follows. Here, it is assumed that from CSR value to hash_value_index_tensors_ The row is mapped to ten digits. For example, 50 is mapped to row 5.
| name | numerical value | significance |
|---|---|---|
| CSR row offset | 0,4,7,9,10 | Two samples and two slot s, so it is divided into four lines |
| CSR value | 40,50,10,20,30,50,10,30,20,10 | Sample content |
| hash_value_index_tensors_ | 4,5,1,2,3,5,1,3,2,1 | The index of the low dimensional embedded table. Each key of the sample corresponds to one. For example, 50 corresponds to hash_table_value line 5 |
| hash_table_value | 5 x 8 matrix | For the low dimensional embedded table, it is assumed that the dense vector length is 8, because there are only 5 different numbers, so there are only 5 rows |
| embedding_feature_tensors_ | 4 x 8 matrix | The dense vector output by the embedded layer. The shape is (batch_size * slot_num) * embedding_vec_len |
| sample_id | 0,0,0,0,1,1,1,2,2,3 | Each key of each sample corresponds to embedding_feature_tensors_ row index in. For example, the first line of CSR is 40, 50, 10 and 20, which are embedded_ feature_ tensors_ Contributed to the first line of. |
6.4 get value from key_ index
Now let's take a look at the second step. Get the hash table value index according to the key.
step2: get value_index by key (will call hash_table->get_insert() in nv_hashtable lib)
This part is only in test / uTest / embedding / spark_ embedding_ hash_ cpu. In HPP, because it is a test code, the hash table has no data and needs to be set. This step is not required for the training code.
The corresponding code is:
// step2: do hash table get() value_index by key int nnz = row_offset_[batchsize_ * slot_num_]; hash_table_->get(hash_key_.get(), hash_value_index_.get(), nnz);
The get method of HashTableCpu is as follows:
void get(const KeyType* keys, ValType* vals, size_t len) const {
if (len == 0) {
return;
}
for (size_t i = 0; i < len; i++) {
auto it = table_->find(keys[i]);
assert(it != table_->end() && "error: can't find key");
vals[i] = it->second;
}
}
6.5 sorting
This part corresponds to step 3:
step3: sort by value_index (will call cub::DeviceRadixSort::SortPairs in cub lib)
Now you get: Sample_ The ID value is [0,0,0,0,1,1,1,2,2,3], which records the embedding of the batch_ feature_ tensors_ row index in.
Is to put the sample_id according to hash_value_index, and finally put the sorting results into hash_value_index_sort and sample_id_sort. In our example, the results are as follows: hash_value_index_sort is [1,1,1,2,2,3,3,4,5,5]. sample_id_sort is [0,1,3,0,2,1,2,0,0,1].
We still use forms to record:
| name | numerical value | significance |
|---|---|---|
| CSR row offset | 0,4,7,9,10 | Two samples and two slot s, so it is divided into four lines |
| CSR value | 40,50,10,20,30,50,10,30,20,10 | Sample content |
| hash_value_index_tensors_ | 4,5,1,2,3,5,1,3,2,1 | The index of the low dimensional embedded table. Each key of the sample corresponds to one. For example, 50 corresponds to hash_table_value line 5 |
| hash_table_value | 5 x 8 matrix | For the low dimensional embedded table, it is assumed that the dense vector length is 8, because there are only 5 different numbers, so there are only 5 rows |
| embedding_feature_tensors_ | 4 x 8 matrix | The dense vector output by the embedded layer. The shape is (batch_size * slot_num) * embedding_vec_len |
| sample_id | 0,0,0,0,1,1,1,2,2,3 | Each key of each sample corresponds to embedding_feature_tensors_ Row in index. For example, the first line of CSR is 40, 50, 10 and 20, which are embedded_ feature_ tensors_ Contributed to the first line of. |
| sample_id_sort | [0,1,3,0,2,1,2,0,0,1 ] | And hash_value_index_sort corresponds to hash_ value_ index_ The first three 1s of sort correspond to embedding respectively_ Line 1, line 2 and line 4 of the feature (sequence starting from 0) |
| hash_value_index_sort | [1,1,1,2,2,3,3,4,5,5] | The result after sorting, for example, 111 means that there are three key pairs finally embedded in this batch_ The first line of the feature contributes |
The specific codes are as follows:
// step3: sort by hash_value_index
int end_bit = static_cast<int>(log2(static_cast<float>(max_vocabulary_size_per_gpu))) + 1;
size_t temp_storage_sort_size = temp_storage_sort.get_size_in_bytes();
CK_CUDA_THROW_(cub::DeviceRadixSort::SortPairs(
temp_storage_sort.get_ptr(), temp_storage_sort_size, hash_value_index.get_ptr(),
hash_value_index_sort.get_ptr(), sample_id.get_ptr(), sample_id_sort.get_ptr(), nnz, 0,
end_bit, stream, false));
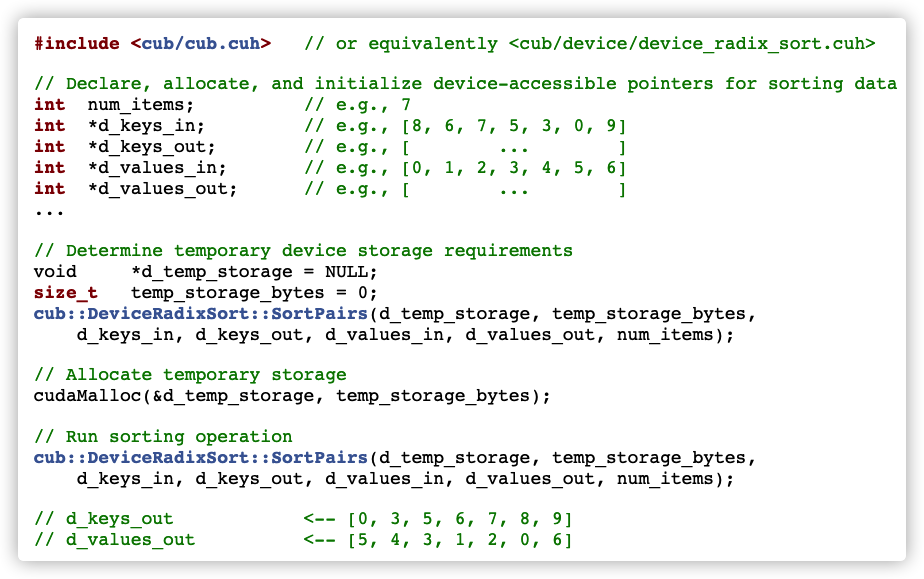
6.5.1 SortPairs
The CUB method is still used here. For details, see: https://nvlabs.github.io/cub/structcub_1_1_device_radix_sort.html#a9e14a29dc4ba6d68dc804bc6b0da7dd4 .
The method statement is as follows:
template<typename KeyT , typename ValueT > static CUB_RUNTIME_FUNCTION cudaError_t cub::DeviceRadixSort::SortPairs ( void * d_temp_storage, size_t & temp_storage_bytes, const KeyT * d_keys_in, KeyT * d_keys_out, const ValueT * d_values_in, ValueT * d_values_out, int num_items, int begin_bit = 0, int end_bit = sizeof(KeyT) * 8, cudaStream_t stream = 0, bool debug_synchronous = false )
The specific application methods are as follows:
6.6 calculating value_ Number corresponding to index
Now I know hash_value_index_sort is [1,1,1,2,2,3,3,4,5,5], sample_id_sort is [0,1,3,0,2,1,2,0,0,1].
- hash_value_index_sort is hash_ value_ The result after index sorting, for example, 111 means that there are three key pairs finally embedded in this batch_ The first line of the feature contributes
- sample_id_sort and hash_value_index_sort corresponds to hash_ value_ index_ The first three 1s of sort correspond to embedding respectively_ Line 1, line 2 and line 4 of the feature (sequence starting from 0)
Next, you need to know embedding_feature_tensors_ How many hashes are the sources of each row_ table_ Value line, for example, there are 4 in line 0 and 3 in line 1. embedding_feature_tensors_ A row in a slot is multiple hashes of the same slot_ table_ The dense vector of the value line is completed by pooling.
This part corresponds to the following:
step4: count the number for each unduplicated value_index, calling value_count_kernel()
It's hash_value_index_sort for processing. Here is the embedded table hash_ table_ row index of value.
// step4: count the number for each unduplicated hash_value_index
CK_CUDA_THROW_(
cudaMemsetAsync(hash_value_index_count_counter.get_ptr(), 0, sizeof(uint32_t), stream));
constexpr size_t max_grid_size = 384;
block_size = 256;
grid_size = min(max_grid_size, (nnz - 1) / block_size + 1);
// The purpose is to find a new group, that is, a new row index. The purpose is to calculate the number of sample IDS corresponding to each row index
value_count_kernel_1<<<grid_size, block_size, 0, stream>>>(
nnz, hash_value_index_sort.get_ptr(), new_hash_value_flag.get_ptr());
// prefix_sum
size_t temp_storage_scan_size = temp_storage_scan.get_size_in_bytes();
CK_CUDA_THROW_(cub::DeviceScan::InclusiveSum(
temp_storage_scan.get_ptr(), temp_storage_scan_size, new_hash_value_flag.get_ptr(),
hash_value_flag_sumed.get_ptr(), nnz, stream));
value_count_kernel_2<<<grid_size, block_size, 0, stream>>>(
nnz, new_hash_value_flag.get_ptr(), hash_value_flag_sumed.get_ptr(),
hash_value_index_count_offset.get_ptr(), hash_value_index_count_counter.get_ptr());
uint32_t hash_hash_value_index_count_num = 0;
// this async memcpy will not perform as a async operation because the host memory is not
// a pinned memroy
CK_CUDA_THROW_(cudaMemcpyAsync(&hash_hash_value_index_count_num,
hash_value_index_count_counter.get_ptr(), sizeof(uint32_t),
cudaMemcpyDeviceToHost, stream));
Let's analyze it a little bit.
6.6.1 value_count_kernel_1
value_count_kernel_1 the purpose is to find a new group, that is, a new row index. The purpose is to calculate the number of sample IDS corresponding to each row index. Is to find out which point is the starting point of the new line. Our expanded table is as follows.
| name | numerical value | significance |
|---|---|---|
| CSR row offset | 0,4,7,9,10 | Two samples and two slot s, so it is divided into four lines |
| CSR value | 40,50,10,20,30,50,10,30,20,10 | Sample content |
| hash_value_index_tensors_ | 4,5,1,2,3,5,1,3,2,1 | The index of the low dimensional embedded table. Each key of the sample corresponds to one. For example, 50 corresponds to hash_table_value line 5 |
| sample_id | 0,0,0,0,1,1,1,2,2,3 | Each key of each sample corresponds to embedding_feature_tensors_ row index in. For example, the first line of CSR is 40, 50, 10 and 20, which are embedded_ feature_ tensors_ Contributed to the first line of. |
| sample_id_sort | [0,1,3,0,2,1,2,0,0,1 ] | And hash_value_index_sort corresponds to hash_ value_ index_ The first three 1s of sort correspond to embedding respectively_ Line 1, line 2 and line 4 of the feature (sequence starting from 0) |
| hash_value_index_sort | [1,1,1,2,2,3,3,4,5,5] | The result after sorting, for example, 1,1,1 means that there are three key pairs finally embedded in this batch_ The first line of the feature contributes |
| new_hash_value_flag | [1,0,0,1,0,1,0,1,1,0] | To calculate the number of sample IDS corresponding to each row index. Is to find out which point is the starting point of the new line |
The specific codes are as follows:
__global__ void value_count_kernel_1(int nnz, const size_t *hash_value_index_sort,
uint32_t *new_hash_value_flag) {
for (int gid = blockIdx.x * blockDim.x + threadIdx.x; gid < nnz; gid += blockDim.x * gridDim.x) {
size_t cur_value = hash_value_index_sort[gid];
if (gid > 0) {
size_t former_value = hash_value_index_sort[gid - 1];
// decide if this is the start of a group(the elements in this group have the same
// hash_value_index_sort)
if (cur_value != former_value) {
new_hash_value_flag[gid] = 1;
} else {
new_hash_value_flag[gid] = 0;
}
} else { // gid == 0
new_hash_value_flag[gid] = 1;
}
}
}
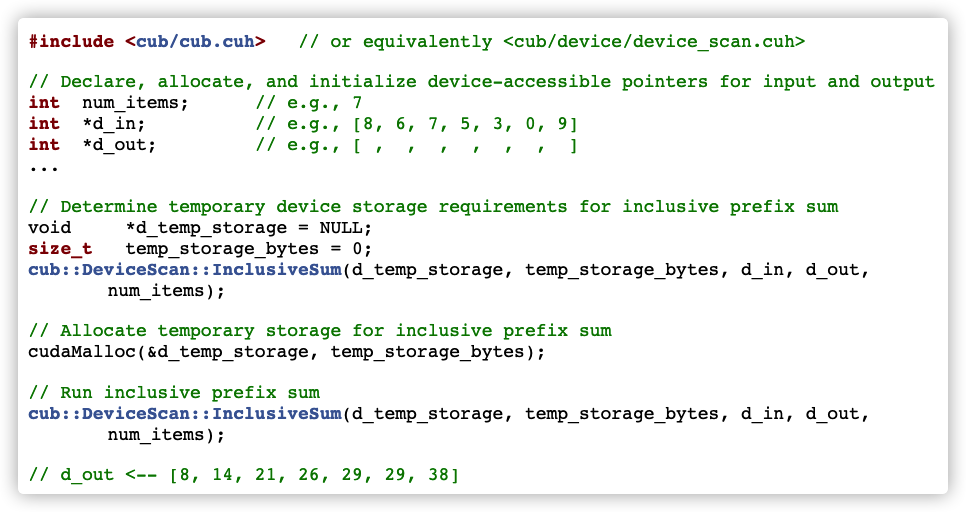
6.6.2 prefix_sum
Yes, new_ hash_ value_ The purpose of flag sorting is to get the number of elements contained in each group (row index) and put them into the hash_value_flag_sumed.
// prefix_sum
size_t temp_storage_scan_size = temp_storage_scan.get_size_in_bytes();
CK_CUDA_THROW_(cub::DeviceScan::InclusiveSum(
temp_storage_scan.get_ptr(), temp_storage_scan_size, new_hash_value_flag.get_ptr(),
hash_value_flag_sumed.get_ptr(), nnz, stream));
cub::DeviceScan::InclusiveSum is used here. If you want to further study it, please refer to https://nvlabs.github.io/cub/structcub_1_1_device_scan.html .
The following is a description of the function.

The following is how to use it.
Our expanded table is as follows.
| name | numerical value | significance |
|---|---|---|
| CSR row offset | 0,4,7,9,10 | Two samples and two slot s, so it is divided into four lines |
| CSR value | 40,50,10,20,30,50,10,30,20,10 | Sample content |
| hash_value_index_tensors_ | [4,5,1,2,3,5,1,3,2,1] | The index of the low dimensional embedded table. Each key of the sample corresponds to one. For example, 50 corresponds to hash_table_value line 5 |
| sample_id | [0,0,0,0,1,1,1,2,2,3] | Each key of each sample corresponds to embedding_feature_tensors_ row index in. For example, the first line of CSR is 40, 50, 10 and 20, which are embedded_ feature_ tensors_ Contributed to the first line of. |
| sample_id_sort | [0,1,3,0,2,1,2,0,0,1] | And hash_value_index_sort corresponds to hash_ value_ index_ The first three 1s of sort correspond to embedding respectively_ Line 1, line 2 and line 4 of the feature (sequence starting from 0) |
| hash_value_index_sort | [1,1,1,2,2,3,3,4,5,5] | The result after sorting, for example, 1,1,1 means that there are three key pairs finally embedded in this batch_ The first line of the feature contributes |
| new_hash_value_flag | [1,0,0,1,0,1,0,1,1,0] | To calculate the number of sample IDS corresponding to each row index. Is to find out which point is the starting point of the new line |
| hash_value_flag_sumed | [1,1,1,2,2,3,3,4,5,5] | Yes, new_hash_value_flag merging aims to get how many elements are contained in each group (row index). |
| hash_table_value | 5 x 8 matrix | For the low dimensional embedded table, it is assumed that the dense vector length is 8, because there are only 5 different numbers, so there are only 5 rows |
6.6.3 value_count_kernel_2
The function of this code is to get the final number of elements per line.
value_count_kernel_2<<<grid_size, block_size, 0, stream>>>(
nnz, new_hash_value_flag.get_ptr(), hash_value_flag_sumed.get_ptr(),
hash_value_index_count_offset.get_ptr(), hash_value_index_count_counter.get_ptr());
uint32_t hash_hash_value_index_count_num = 0;
// this async memcpy will not perform as a async operation because the host memory is not
// a pinned memroy
CK_CUDA_THROW_(cudaMemcpyAsync(&hash_hash_value_index_count_num,
hash_value_index_count_counter.get_ptr(), sizeof(uint32_t),
cudaMemcpyDeviceToHost, stream));
hash_hash_value_index_count_num is the total number of indexes, which is the actual number of lines, which corresponds to nnz.
* @param nnz non-zero feature number per batch
Now I know hash_value_index_sort is [1,1,1,2,2,3,3,4,5,5], sample_id_sort is [0,1,3,0,2,1,2,0,0,1], new_ hash_ value_ The flag is [1,0,0,1,0,1,0,0,1,1,0], which places whether the line is new or not. hash_value_flag_sumed is [1,1,1,2,2,3,3,4,5,5].
Let's analyze the code. The general idea is: in hash_value_index_index (the corresponding parameter passed in is hash_value_index_count_offset) set "the corresponding embedding table index (i.e. the corresponding embedding table line number) calculated by number". Because embedding_ There are only 5 rows (nnz number) of features at most, so the first five can be selected here.
For example, each block has to deal with one row of low dimensional dense matrix. If bid = 1, it wants to update row 2 of the low dimensional dense matrix, but wants to know how many times to update. So start with hash_value_index_count_offset[1] gets the value 3, and then finds the hash_value_index_sort[3].
Specifically: traverse the grid, but it needs to be less than nnz (the number of non-zero key s of the batch). In fact, it is hash_ table_ Number of rows of value. For example, nnz is equal to 10 here, and gid is 0 ~ 9. New when grid is 0, 3, 5, 7, 8_ hash_ value_ Flag [gid] is 1. hash_value_flag_sumed[gid] are: 1,2,3,4,5. So hash_value_index_count_offset is [0, 3, 5, 7, 8, 0, 0, 0, 0, 0], these are hashes_ value_ index_ offset in sort.
__global__ void value_count_kernel_2(int nnz, const uint32_t *new_hash_value_flag,
const uint32_t *hash_value_flag_sumed,
uint32_t *hash_value_index_index, uint32_t *counter)
{
// Traverse the grid, but the number of non-zero key s less than that of the batch is actually hash_ table_ Number of rows of value
for (int gid = blockIdx.x * blockDim.x + threadIdx.x; gid < nnz; gid += blockDim.x * gridDim.x) {
uint32_t flag = new_hash_value_flag[gid];
if (flag == 1) {
// set up
hash_value_index_index[hash_value_flag_sumed[gid] - 1] = gid;
}
}
if (blockIdx.x * blockDim.x + threadIdx.x == 0) {
*counter = hash_value_flag_sumed[nnz - 1];
hash_value_index_index[*counter] = nnz;
}
}
So far, all variables are as follows:
| name | numerical value | significance |
|---|---|---|
| CSR row offset | 0,4,7,9,10 | Two samples and two slot s, so it is divided into four lines |
| CSR value | 40,50,10,20,30,50,10,30,20,10 | Sample content |
| hash_table_value | 5 x 8 matrix | For the low dimensional embedded table, it is assumed that the dense vector length is 8, because there are only 5 different numbers (nnz), so there are only 5 rows |
| embedding_feature_tensors_ | 4 x 8 matrix | The dense vector output by the embedded layer. The shape is (batch_size * slot_num) * embedding_vec_len |
| hash_value_index_tensors_ | [4,5,1,2,3,5,1,3,2,1] | The index of the low dimensional embedded table. Each key of the sample corresponds to one. For example, 50 corresponds to hash_table_value line 5 |
| sample_id | [0,0,0,0,1,1,1,2,2,3] | Each key of each sample corresponds to embedding_feature_tensors_ Row in index. For example, the first line of CSR is 40, 50, 10 and 20, which are embedded_ feature_ tensors_ Contributed to the first line of. |
| sample_id_sort | [0,1,3,0,2,1,2,0,0,1] | And hash_value_index_sort corresponds to hash_ value_ index_ The first three 1s of sort correspond to embedding respectively_ Line 1, line 2 and line 4 of the feature (sequence starting from 0) |
| hash_value_index_sort | [1,1,1,2,2,3,3,4,5,5] | The result after sorting, for example, 1,1,1 means that there are three key pairs finally embedded in this batch_ The first line of the feature contributes |
| new_hash_value_flag | [1,0,0,1,0,1,0,1,1,0] | To calculate the number of sample IDS corresponding to each row index. Is to find out which point is the starting point of the new line |
| hash_value_flag_sumed | [1,1,1,2,2,3,3,4,5,5] | Yes, new_hash_value_flag merging aims to get how many elements are contained in each group (row index). |
| hash_value_index_count_offset | [0, 3, 5, 7, 8, 0, 0, 0, 0, 0] | Each block deals with one row of low dimensional dense matrix. If bid = 1, it wants to update row 2 of the low dimensional dense matrix, but wants to know how many times to update. So start with hash_value_index_count_offset[1] gets the value 3, and then finds the hash_value_index_sort[3]. Because embedding_ There are only 5 rows (nnz number) of features at most, so the first five can be selected here |
The final idea is as follows:
-
Each block deals with one row of low dimensional dense matrix. If bid=0, if you want to update the first row of the low dimensional matrix, you need to update the dense vector of the low dimensional matrix corresponding to 10.
-
bid corresponds to the gradient of keys, such as 40,50,10,20,30,50,10,30,20,10. The keys are 10 ~ 50.
-
hash_value_index_count_offset: this bid needs to be updated several times for low dimensional dense matrix. sum_num = hash_value_index_count_offset[1] - hash_value_index_count_offset[0] = 3 - 0 = 3, so it is updated 3 times.
-
hash_value_index_sort: find 1,1,1 in [1,1,1,2,2,3,3,4,5,5], which indicates that there are three key pairs in this batch, which are finally embedded_ The first line of the feature contributes.
-
So bid = 0 is hash_ table_ The line value [0] has three 1s and should be updated three times.
-
sample_id_sort: update is accumulation, which line of the gradient is entered for the three updates? Three tens are in the lines of 0, 1 and 3 of the gradient.
6.7 update weights
This is the last step, corresponding to the following:
step5: use optimizer method to compute deltaw and update the parameters
The calling code is as follows:
Note that sample is passed here_ id_ Sort [0,1,3,0,2,1,2,0,0,1], corresponding hash_value_index_sort is [1,1,1,2,2,3,3,4,5,5], hash_value_index_count_offset is [0, 3, 5, 7, 8, 0, 0, 0, 0, 0].
case Optimizer_t::AdaGrad: {
opt_adagrad_kernel<<<grid_size, block_size, 0, stream>>>(
hash_hash_value_index_count_num, embedding_vec_size, opt_params.lr,
opt_params.hyperparams.adagrad, opt_tensor.opt_accm_tensors_.get_ptr(),
sample_id_sort.get_ptr(), hash_value_index_sort.get_ptr(),
hash_value_index_count_offset.get_ptr(), wgrad.get_ptr(),
hash_table_value.get_ptr(), opt_params.scaler);
break;
}
Obviously, it is to update the hash with weights_ table_ value.
// Local update for the Adagrad optimizer: compute the gradients and update the accumulators and the
// weights
template <typename TypeKey, typename TypeEmbeddingComp>
__global__ void opt_adagrad_kernel(uint32_t hash_value_index_count_num, int embedding_vec_size,
float lr, const AdaGradParams adagrad,
TypeEmbeddingComp *accum_ptr, const TypeKey *sample_id,
const size_t *hash_value_index_sort,
const uint32_t *hash_value_index_count_offset,
const TypeEmbeddingComp *wgrad, float *hash_table_value,
float scaler) {
int bid = blockIdx.x; // A block corresponds to a key in a sample, such as 30 in the example
int tid = threadIdx.x; // This thread
if (tid < embedding_vec_size && bid < hash_value_index_count_num) {
// Find the thread sample in hash_ value_ index_ Offset of sort
uint32_t offset = hash_value_index_count_offset[bid]; // [0, 3, 5, 7, 8, 0, 0, 0, 0, 0]
// Cumulative gradient
float gi = accumulate_gradients(embedding_vec_size, sample_id, hash_value_index_count_offset,
wgrad, scaler, offset, bid, tid);
// Find the row index of this sample in the low dimensional matrix
size_t row_index = hash_value_index_sort[offset]; // [1,1,1,2,2,3,3,4,5,5]
// Note, hash_table_value is the element level. For example, if the dense vector length is 8, then in hash_ table_ There are eight elements in value
// feature_index is to get which element in the embedding vector corresponding to this thread
size_t feature_index = row_index * embedding_vec_size + tid;
float accum = //accum_ptr from optimizer
TypeConvertFunc<float, TypeEmbeddingComp>::convert(accum_ptr[feature_index]) + gi * gi;
accum_ptr[feature_index] = TypeConvertFunc<TypeEmbeddingComp, float>::convert(accum);
float weight_diff = -lr * gi / (sqrtf(accum) + adagrad.epsilon);
// Update gradient
hash_table_value[feature_index] += weight_diff;
}
}
accumulate_ The logic of gradients is:
// Helper function to accumulate the weight gradients for a thread's embedding vector
template <typename TypeKey, typename TypeEmbeddingComp>
__device__ __forceinline__ float accumulate_gradients(int embedding_vec_size,
const TypeKey *sample_id,
const uint32_t *hash_value_index_count_offset,
const TypeEmbeddingComp *wgrad, float scaler,
uint32_t offset, int bid, int tid) {
// Which line is updated several times
// Sum if bid=0_ num = hash_ value_ index_ count_ offset[1] - hash_ value_ index_ count_ Offset [0] = 3 - 0 = 3. Bid corresponds to keys, such as 40,50,10,20,30,50,10,30,20,10. The keys are 10 ~ 50. So bid=0 is to update the dense vector of the low dimensional matrix corresponding to 10, which is hash_ table_ There are three 1s in the line of value [0], which should be updated three times.
uint32_t sample_num = hash_value_index_count_offset[bid + 1] - hash_value_index_count_offset[bid];
// Calculated gradient
float gi = 0.0f;
// sample_id_sort [0,1,3,0,2,1,2,0,0,1] - which line exactly matches wgrad
for (int i = 0; i < sample_num; i++) { // offset is 0, 3, 5, 7 and 8. For example, for line 1, it needs to be updated three times
// sample_id is [0,1,3,0,2,1,2,0,0,1], corresponding to the 1st, 2nd, 4th,... Of low dimensional matrix, Row is the row in which the three 10s output the dense vector respectively
// Updating these times is a accumulation. What gradients are used to accumulate this accumulation.
int sample_index = sample_id[offset + i]; // Find the gradient of this sample
gi += TypeConvertFunc<float, TypeEmbeddingComp>::convert(
wgrad[sample_index * embedding_vec_size + tid]); // This thread gradient, and accumulated
}
return gi / scaler;
}
The final details are as follows:
So far, our analysis of DistributedSlotSparseEmbeddingHash has been completed. The next article introduces local slotsparseembeddinghash.
0xEE personal information
★★★★★★★ thinking about life and technology ★★★★★★
Wechat public account: Rossi's thinking
If you want to get the news push of personal writing articles in time, or want to see the technical materials recommended by yourself, please pay attention.

0xFF reference
https://nvlabs.github.io/cub/annotated.html
https://developer.nvidia.com/blog/introducing-merlin-hugectr-training-framework-dedicated-to-recommender-systems/
https://developer.nvidia.com/blog/announcing-nvidia-merlin-application-framework-for-deep-recommender-systems/
https://developer.nvidia.com/blog/accelerating-recommender-systems-training-with-nvidia-merlin-open-beta/
How does the embedding layer back propagate
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
Sparse matrix storage format summary + storage efficiency comparison: COO,CSR,DIA,ELL,HYB
Making something out of nothing: on the Embedding idea in Recommendation Algorithm
tf. nn. embedding_ Principle of lookup function
Please explain the embedding of tensorflow_ What does the lookup interface mean?
[technical dry goods] talk about how embedding is done in the recommended scenes of large factories
Can ctr prediction algorithm splice the embedding of sequence features and input MLP? And pooling
Depth matching model in Recommendation System
Indigenous processing: how is the Embedding layer realized?
Unequal distance two bar model_ Depth matching model in search (Part 2)
Depth feature fast cattle strategy on high-level and low-level feature fusion
[deep learning] DeepFM introduction and pytoch code explanation
Recommended algorithm 7 -- DeepFM model
DeepFM parameter understanding (II)
Recommendation system meets deep learning (III) – theory and practice of DeepFM model
[deep learning] DeepFM introduction and pytoch code explanation
https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/usage/operations.html
Take you to know the key algorithm of large model training: distributed training Allreduce algorithm