Full steps of Douban movie big data project
1. Douban reptile:
When I started to write Douban TV series crawler, I thought it was very simple, but in practice, there was an IP sealing situation, which led to my distress for a long time, and now I finally wrote it
No more nonsense, just go to the code:
The run function is used to obtain the data of the page. Here I use the proxy to enter
def run(self, k, nd, p):
global data_json, response
while True:
url = 'https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=%E7%94%B5%E8%A7%86%E5%89%A7&start={}&countries=%E4%B8%AD%E5%9B%BD%E5%A4%A7%E9%99%86&year_range={}'.format(
str(k), nd)
print(url)
px = self.get_proxy_ip()
proxies = {'http': '{}'.format(px),
'https': '{}'.format(px)}
print(proxies)
try:
response = self.get_url(url, proxies)
data_json = json.loads(response.text)
if len(data_json['data']) > 0:
print("Crawling-----------------------------Please wait")
for i in data_json['data']:
title_name = str(i['title']).strip().replace('\n', '').replace('\t', '').replace(',', ',')
mv_url = i['url']
# print(mv_url)
zhuyan = ''
if len(i['casts']) != 0:
for e, o in zip(i['casts'], range(len(i['casts']))):
if o + 1 == len(i['casts']):
zhuyan += e
else:
zhuyan += e + '/'
else:
zhuyan += 'None'
if title_name not in p:
jishu, guanyingshu, leixing, year, short = self.get_insert_html(mv_url, proxies)
# time.sleep(1)
cunt_data = [title_name, zhuyan, jishu, guanyingshu, leixing, year, short]
p.append(title_name)
print(title_name, jishu, guanyingshu, leixing, year, short)
time.sleep(2)
# f.write(
# str(
# cunt_data[0]) + ',' + str(
# cunt_data[1]) + ',' + str(cunt_data[2]) + ',' + str(cunt_data[3]) + ',' + str(
# cunt_data[4]) + ',' + str(cunt_data[5]) + ',' + str(cunt_data[6]) + '\n')
print("The write file step has been performed")
else:
print("Existing data exists")
print("Finished crawling data on this page" + "-----------------------------" + "Buffering time")
else:
break
if k < 480:
next_url_num = k + 20
time.sleep(5)
c = []
self.run(next_url_num, nd, c)
except Exception as e:
print(e)
print('Error reported on this page--------------------Re crawling')
self.run(k, nd, p)
if 'data' not in str(data_json):
print(data_json)
break
elif len(data_json) == 0:
# print(data_json)
break
elif k == 480:
break
else:
# print(data_json)
break
get_ insert_ The HTML function is used to enter the link obtained in the run function into the details page and then obtain the data
def get_insert_html(self, url, proxies):
global jishu, response
print(url)
try:
response = self.get_url(url, proxies)
html = etree.HTML(response.text)
# Set number
if 'number' in str(html.xpath('//*[@id="info"]//span[@class="pl"]/text()')):
jishu = ''
if 'Set number:' in html.xpath('//*[@id="info"]//span[@class="pl"]/text()'):
jishu += str(
html.xpath('//*[@ id="info"]//span[text() = "number of sets:"] / following sibling:: text() [position() = 1] '[0])
else:
if html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[1]'):
l = html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[1]/text()')[
0]
if 'number' not in l:
if html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[2]'):
b = html.xpath(
'//div[@id="info"]//span[@property="v:initialReleaseDate"]/following-sibling::span[2]/text()')[
0]
if 'number' not in b:
jishu += 'None'
else:
jishu += str(html.xpath(
'//div[@id="info"]/span[text()="{}"]/following-sibling::text()[position()=1]'.format(
str(b)))[0]).strip()
else:
jishu += str(html.xpath(
'//div[@id="info"]/span[text()="{}"]/following-sibling::text()[position()=1]'.format(
str(l)))[
0]).strip()
else:
if html.xpath('//*[@ id="info"]//span[text() = "number of sets:"] / following sibling:: text() [position() = 1]):
jishu += str(
html.xpath(
'//*[@ id="info"]//span[text() = "number of sets:"] / following sibling:: text() [position() = 1] '[0])
elif html.xpath('//*[@ id="info"]//span[text() = "number of seasons:"] / following sibling:: text() [position() = 1]):
jishu += str(html.xpath(
'//*[@ id="info"]//span[text() = "number of seasons:"] / following sibling:: text() [position() = 1] '[0])
else:
jishu += 'None'
else:
jishu = ''
jishu += 'None'
# Number of viewers
if html.xpath('//*[@id="comments-section"]/div[1]//span[@class="pl"]/a/text()'):
guanyingshu = \
re.findall('(\d+)', html.xpath('//*[@id="comments-section"]/div[1]//span[@class="pl"]/a/text()')[0])[0]
else:
guanyingshu = 'None'
# type
k = ''
if html.xpath('//div[@id="info"]//span[@property="v:genre"]/text()'):
types = html.xpath('//div[@id="info"]//span[@property="v:genre"]/text()')
for i, j in zip(types, range(len(types))):
if j + 1 == len(types):
k += i
else:
k += i + '/'
else:
k += 'None'
# Get comments
if html.xpath('//*[@id="hot-comments"]/div[1]/div/p/span/text()'):
# print(html.xpath('//*[@id="hot-comments"]/div[1]/div/p/span/text()'))
short = str(html.xpath('//*[@id="hot-comments"]/div[1]/div/p/span/text()')[0]).strip().replace('\n',
'').replace(
'\t', '').replace(',', ',')
else:
short = 'None'
# short = html.xpath('//*div[@id="hot-comments"]/div[1]//p[@class="comment-content"]/span/text()')
# Year of publication
if html.xpath('//span[@class="year"]/text()'):
year = str(html.xpath('//span[@class="year"]/text()')[0]).replace('(', '').replace(')', '').split('-')[
0]
elif html.xpath('//*[@ id="info"]//span[text() = "Premiere:"] / following sibling:: span [1] / text()):
year = re.findall('(\d+)',str(html.xpath('//*[@ id="info"]//span[text() = "Premiere:"] / following sibling:: span [1] / text() '[0]) [0]
else:
year = 'None'
a = [jishu, guanyingshu, k, year, short]
if len(a) != 5:
self.get_insert_html(url, proxies)
else:
return jishu, guanyingshu, k, year, short
# if len(a) == 5:
# return jishu, guanyingshu, k, year, short
# else:
# print("there is only one data - crawling again")
# self.get_insert_html(url, proxies)
except Exception as e:
print(e)
print(url + "An error occurred in the current link------Reassigning ip-Crawling")
px = self.get_proxy_ip()
next_proxies = {'http': '{}'.format(px),
'https': '{}'.format(px)}
self.get_insert_html(url, next_proxies)
get_ proxy_ The IP function is used to obtain the proxy IP
def get_proxy_ip(self):
try:
urls = requests.get(
"http://39.104.96.30:7772/Tools/proxyIP.ashx?action=GetIPAPI&OrderNumber=7bbb88a8d9186d00fed9eaaf3033d9d0&poolIndex=1617254228&qty=1&Split=JSON2").text
info = json.loads(urls)
quota = info['LeftIp']
ip = info['Data'][0]['Ip']
port = info['Data'][0]['Port']
proxy_ip = "{}:{}".format(ip, port)
print("Obtained{},Residual Quota {}".format(proxy_ip, quota))
return proxy_ip
except:
self.get_proxy_ip()
def get_url(self, url, proxies):
response = requests.get(url, headers=self.get_url_headers, proxies=proxies, allow_redirects=False, timeout=30)
return response
Proxy IP, I use the proxy IP I bought here, because 90% of those online who say that crawling for free proxy IP can't be used, so don't always think about whoring for nothing.
There is also the need to deal with the data, because I sometimes have problems saving the data here, that is, sometimes the data will only return comments and then be saved as csv, resulting in data loss.
But I ran the page of problematic data, and the test showed that there was no problem. The comments were all available, and the data was also OK. I really didn't understand what was going on. I hope someone can help me solve it!!!
Save the data as csv and then operate in excel. Use search to locate, find a column that is empty and delete it. The following is the process after spark operation:
Now the last step is to convert the data into something that people can intuitively see. This is what these data mean:
This is visualization
First create a flash project, and then import the processed data into the project
Direct code:
from flask import Flask, request, render_template, jsonify
import pandas as pd
import json
import re
import jieba
app = Flask(__name__, static_folder='/')
@app.route('/')
def hello_world():
return render_template('index.html')
@app.route('/TestEcharts', methods=['POST'])
def TestEcharts():
data = pd.read_csv('part-00000.txt', names=['db_name', 'db_zhuyan', 'db_jishu', 'db_gks', 'db_types', 'db_years', 'db_short'])
a = []
z = {}
for i in data['db_types']:
for k in i.split('/'):
a.append(k)
for c in a:
if c in list(z.keys()):
p = z.get(c) + 1
z[c] = p
else:
z.update({c: 1})
xdatas = list(z.keys())
yvalues = list(z.values())
l = {}
l['xdays'] = xdatas
l['yvalues'] = yvalues
j = json.dumps(l)
return (j)
@app.route('/qushi1',methods=['POST'])
def qushi1():
df_2000 = pd.read_csv('2000-2010.csv')
df_2000_groupby = df_2000[['db_years', 'db_gks']].groupby(by='db_years', as_index=False).max()
c_1 = [str(i) for i in df_2000_groupby['db_years']]
c_2 = [int(i) for i in df_2000_groupby['db_gks']]
l = {}
l['xdays'] = c_1
l['yvalues'] = c_2
q1 = json.dumps(l)
return (q1)
@app.route('/qushi2',methods=['POST'])
def qushi2():
df_2011 = pd.read_csv('2011-2021.csv')
df_2011_groupby = df_2011[['db_years', 'db_gks']].groupby(by='db_years', as_index=False).max()
d_1 = [str(i) for i in df_2011_groupby['db_years']]
d_2 = [int(i) for i in df_2011_groupby['db_gks']]
l = {}
l['xdays'] = d_1
l['yvalues'] = d_2
q2 = json.dumps(l)
return (q2)
@app.route('/paiming',methods=['POST'])
def paiming():
data = pd.read_csv('part-00000.txt',
names=['db_name', 'db_zhuyan', 'db_jishu', 'db_gks', 'db_types', 'db_years', 'db_short'])
data['db_name'] = data['db_name'].str.replace(r'(', '')
data['db_short'] = data['db_short'].str.replace(r')', '')
# out_data=data[(data['db_zhuyan']>=2000)&(data['db_years']<=2010)]
a = []
z = {}
for i in data['db_zhuyan']:
for k in i.split('/'):
a.append(k)
for c in a:
if c in list(z.keys()):
p = z.get(c) + 1
z[c] = p
else:
z.update({c: 1})
sort_d = sorted(z.items(), key=lambda z: z[1], reverse=True)
count = 0
k = {}
for key, value in sort_d:
count += 1
k[key] = value
if count >= 10:
break
cate = list(k.keys())
data = list(k.values())
l = {}
l['xdays'] = cate
l['yvalues'] = data
j = json.dumps(l)
return (j)
@app.route('/temps',methods=['POST'])
def temps():
data = pd.read_csv('Number of statistical sets.txt', names=['db_fanwei', 'db_all_jishu'])
k = []
for i, j in zip(data['db_fanwei'], data['db_all_jishu']):
c = {}
c['value'] = j
c['name'] = i
k.append(c)
return json.dumps(k)
@app.route('/wrodcloud',methods=['POST'])
def WordCloud():
data = pd.read_csv('part-00000.txt',
names=['db_name', 'db_zhuyan', 'db_jishu', 'db_gks', 'db_types', 'db_years', 'db_short'])
c = ''
data['db_short'] = data['db_short'].str.replace(r')', '')
for i in data['db_short']:
c += i
pattern = re.compile(r'([\u4e00-\u9fa5]+|[a-zA-Z]+)')
deal_comments = re.findall(pattern, c)
# print(deal_comments)
newComments = ""
for item in deal_comments:
newComments += item
words_lst = jieba.cut(newComments.replace('\n', '').replace(' ', ''))
total = {}
for i in words_lst:
total[i] = total.get(i, 0) + 1
data_s = dict(
sorted({k: v for k, v in total.items() if len(k) >= 2}.items(), key=lambda x: x[1], reverse=True)[:200])
k = []
for i, j in zip(list(data_s.keys()), list(data_s.values())):
c = {}
c['name'] = i
c['value'] = j
k.append(c)
return json.dumps(k)
if __name__ == '__main__':
app.run(debug = True)
In HTML, I use Ajax to get the data request and then show the processing, so I need to write that step myself
First show the index file. Here I onclick to trigger the button event, and then click which block to call back which HTML page to display:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<link rel="stylesheet" href="../static/css/stly.css">
<link rel="stylesheet" href="../static/css/font-awesome-4.7.0/css/font-awesome.min.css">
<script src="../static/js/index_js.js" type='text/javascript'></script>
<script src="../static/js/jquery-3.3.1.min.js" type='text/javascript'></script>
</head>
<body>
<div >
<!-- Left Navigation -->
<div class="left_div" id="left">
<div class="top_left_div">
<i class="fa fa-rocket"></i> Data visualization
</div>
<div class="-left_div">
<ul>
<li> <i class="fa fa-cog"></i> visualization
<dl>
<dd id="types" onclick="changehtml(this)">Statistics of TV series types</dd>
<dd id="jishu" onclick="changehtml(this)">Set statistics</dd>
<dd id="qushi" onclick="changehtml(this)">TV trends</dd>
<dd id="paiming" onclick="changehtml(this)" >Actor ranking</dd>
<dd id="pinglun" onclick="changehtml(this)" >comment</dd>
</dl>
</li>
</ul>
</div>
<div class="main_right">
<iframe id="Ifram" frameborder="0" scrolling="yes" style="width: 100%;height: 100%;" src="/templates/TestEcharts.html" ></iframe>
</div>
</div>
</div>
</body>
</html>
This is a simple visualization. Since I'm too lazy to turn the video into GIF dynamic diagram, I'll just take a screenshot and have a look
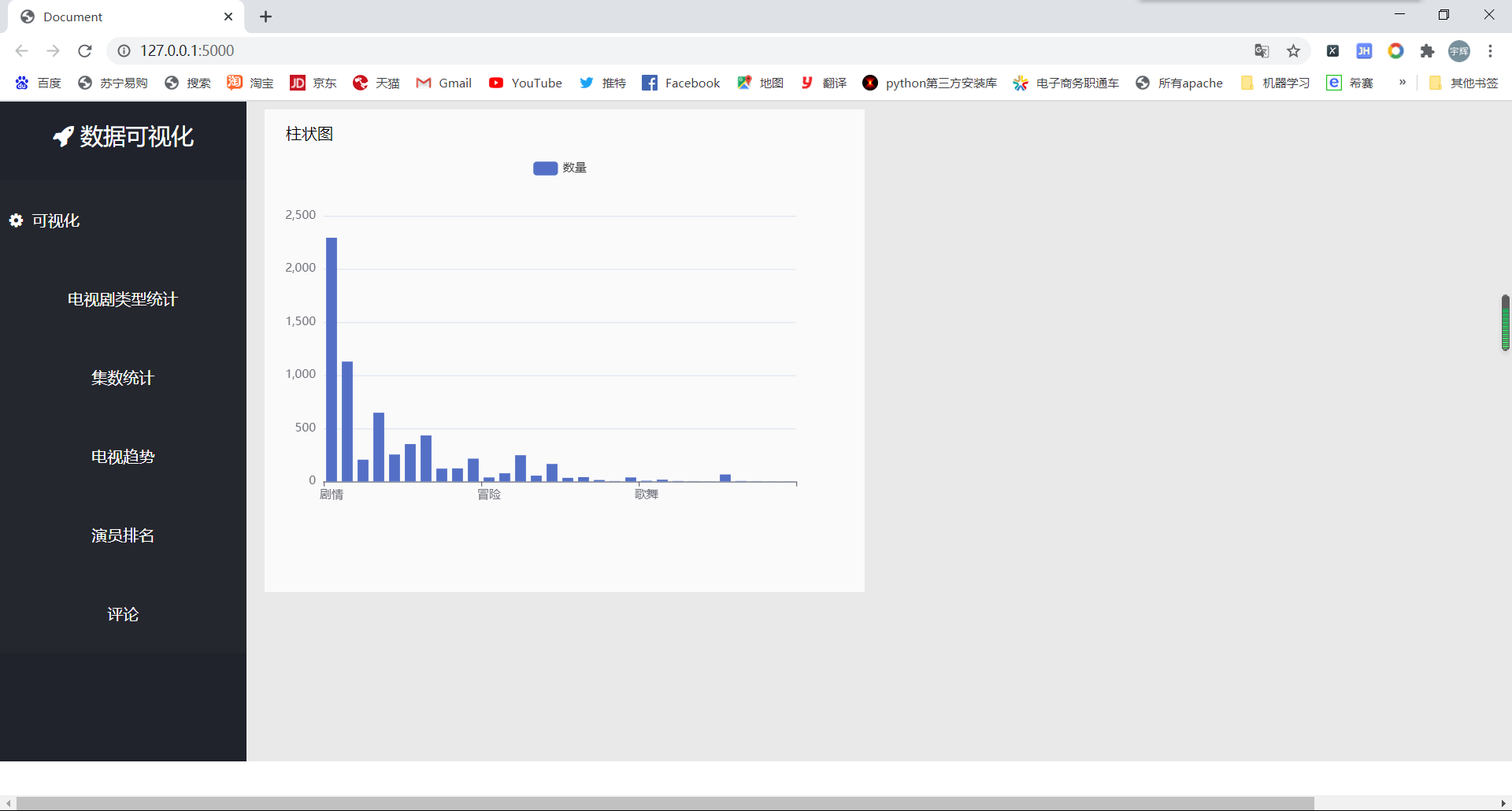

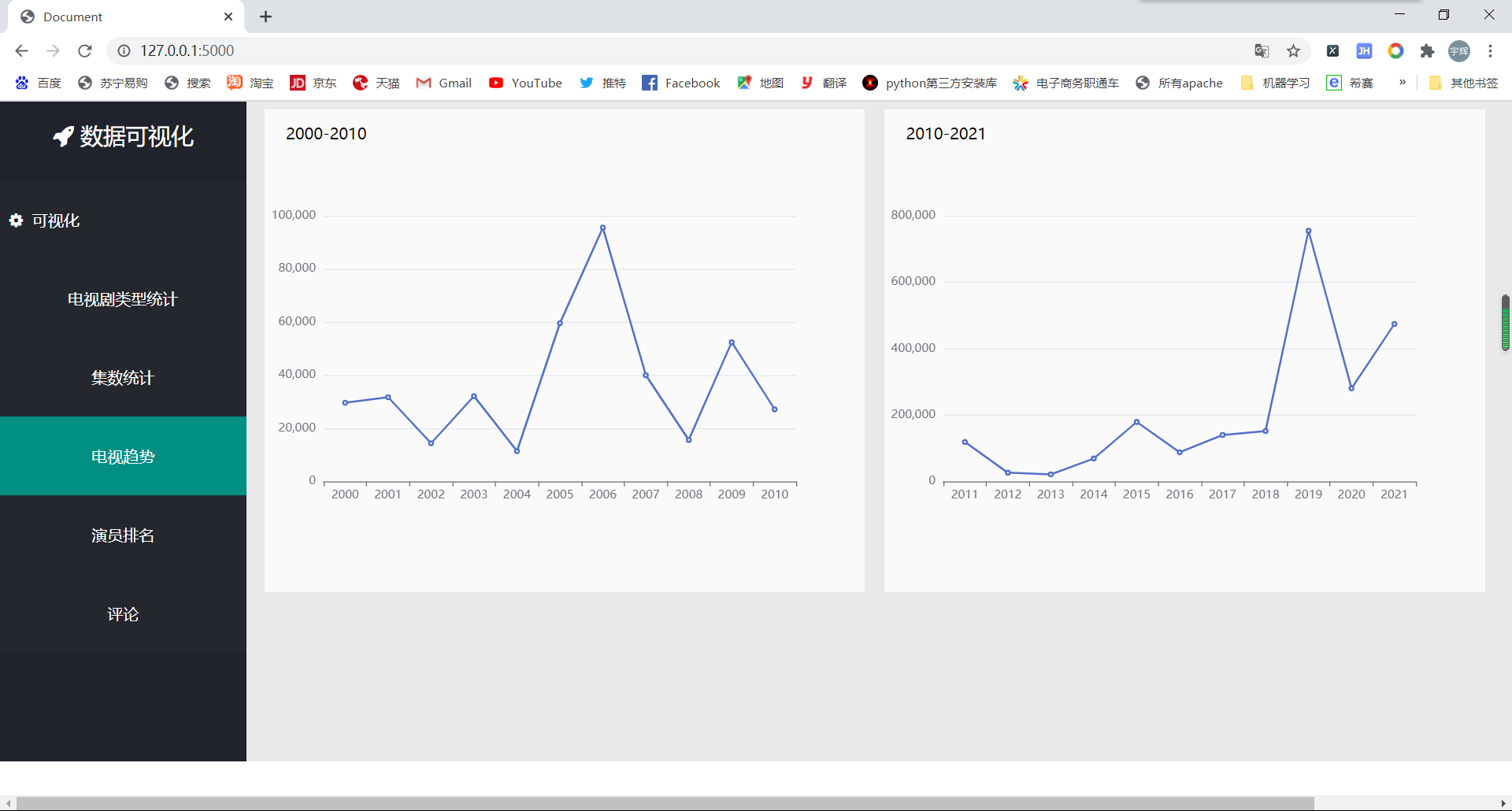
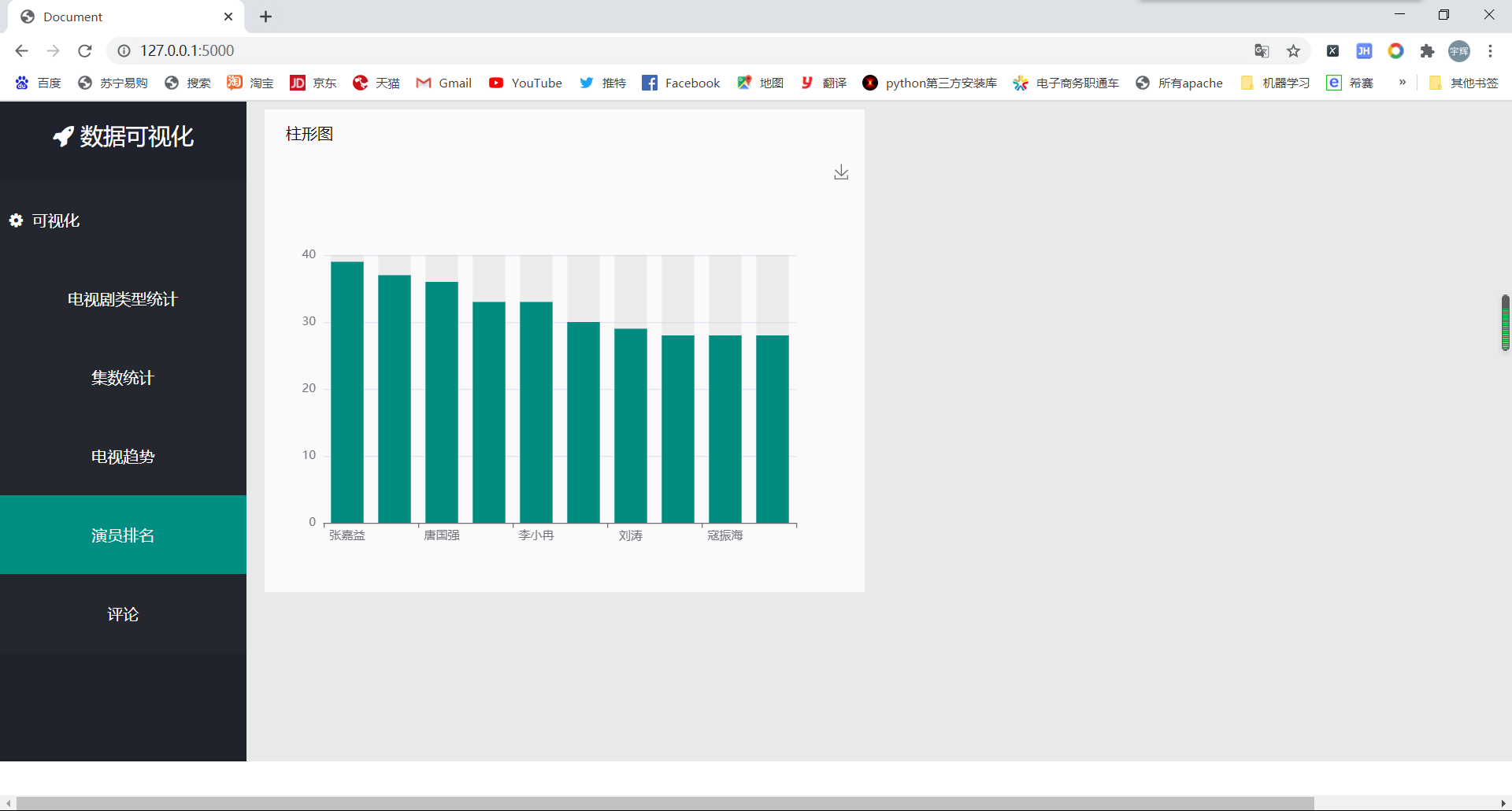
By the way, I use the JS interface of the network to load the word cloud: https://cdn.bootcss.com/echarts/3.7.0/echarts.simple.js
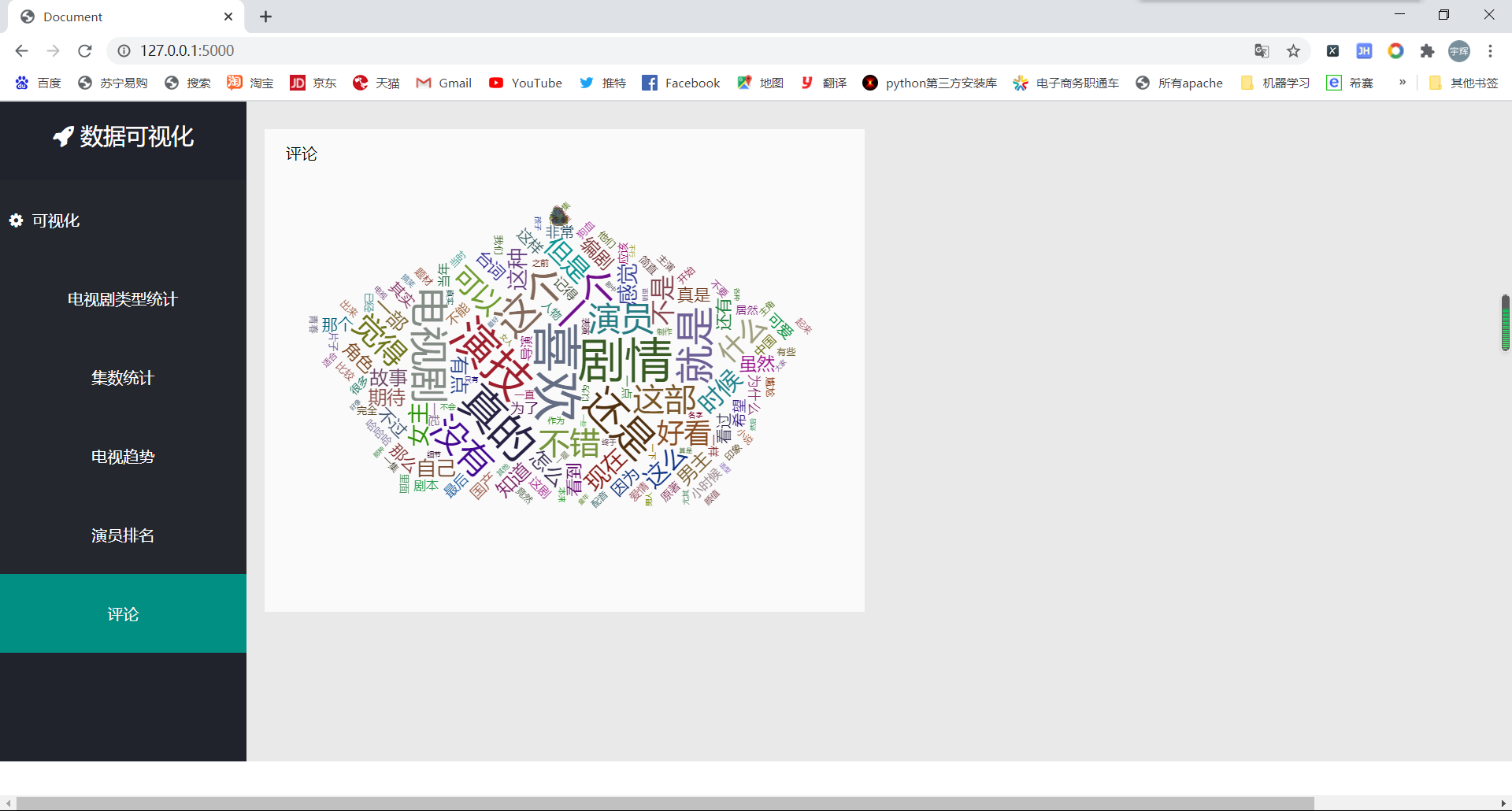
- This is the whole process
- As this is my first blog, it's not very beautiful, so I'll make do with it
- Thank you for watching the whole process!!!