You're right. I don't know if other programming languages and tools can do 10000 popular science short videos a month, but it can be done with the MoviePy module of Python.
In 19 years, when I was still in school, the leader arranged for me to use pr to make a popular science short video of traditional Chinese medicine. I really couldn't get that thing. Later, I grabbed the traditional Chinese medicine data of traditional Chinese medicine website with a crawler and found that the data were in a fixed format. Since it was a repetitive work, I should be able to mass produce it with Python script.
Let's take a look at a case of finished products. The production takes about 5 minutes. The idea can be expanded. Videos similar to this popular science can be mass produced. If you are interested, look down at the implementation method.
YYSD can produce 10000 short videos per month in Python for correct posture of traditional Chinese Medicine
Software, hardware and skill requirements
- The CPU should be above I7-8750, or the overall production will be very slow
- Python version 3.6 or above
- The Moviepy module does not support GPU temporarily, so the quality of the graphics card is ignored
- PyEcharta module map making and image rendering, because the video needs to be used
- Routine data cleaning and processing operations, otherwise the video content cannot be done
- Need to be able to use PPT to make materials, pictures and videos
- You need to be able to write the basis of the crawler. The Scrapy framework is not available
- You need to be able to operate the Moviepy module. If not, please see the corresponding introduction and operation methods in my column
- 1-N mobile phone numbers are required to apply for Baidu AI's free API
- It requires patience and fine tuning in many places
Data acquisition
The content manuscript of the video naturally needs data. The data of this video is public and can be found in the drug intelligence data.
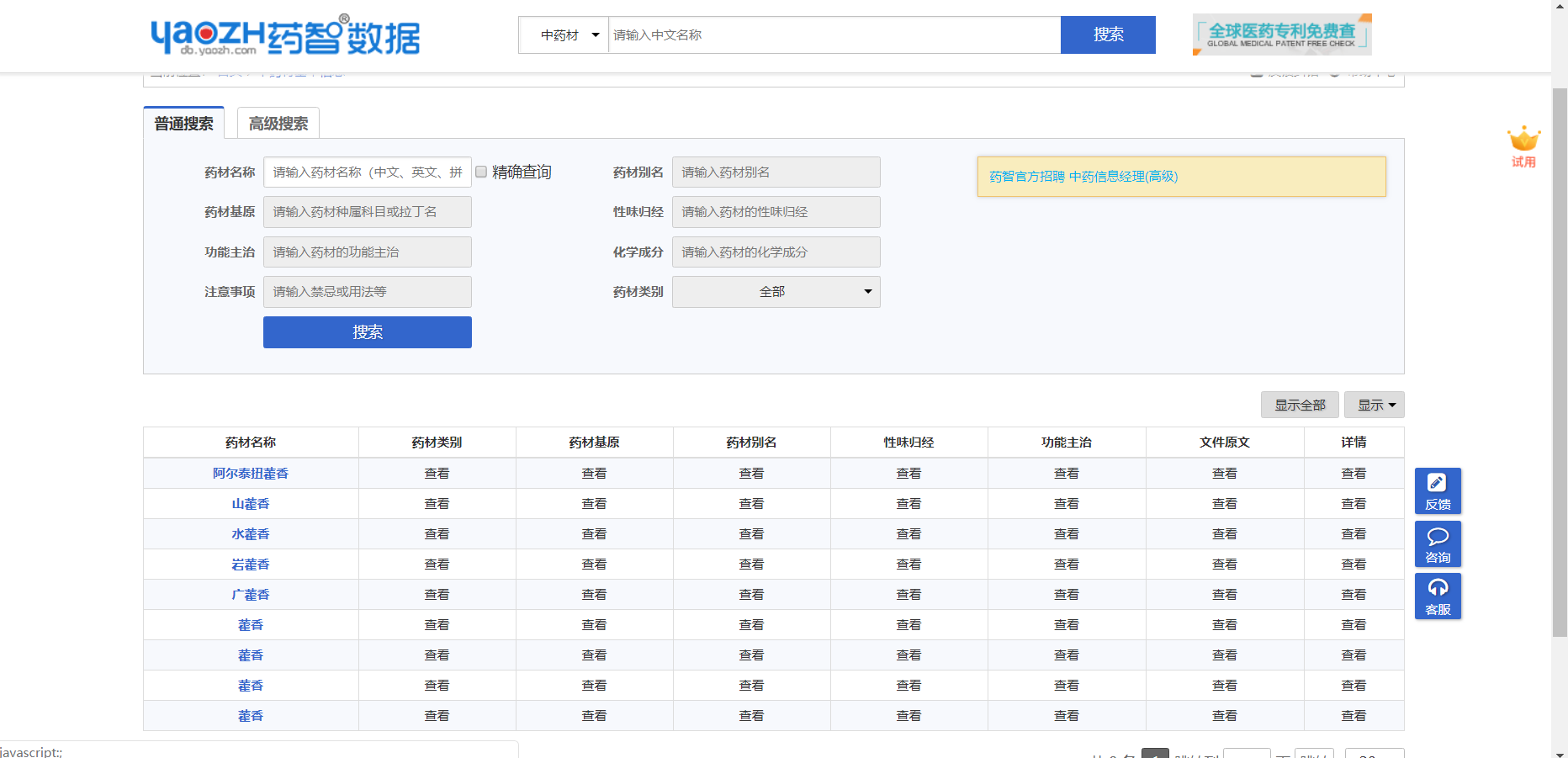
Here's the data. The specific capture method is very simple. Python can write a crawler script. It takes an hour as a whole. The last data is so long that it is found that there are 13000 + kinds of traditional Chinese medicine in our country, which is really eye opening.
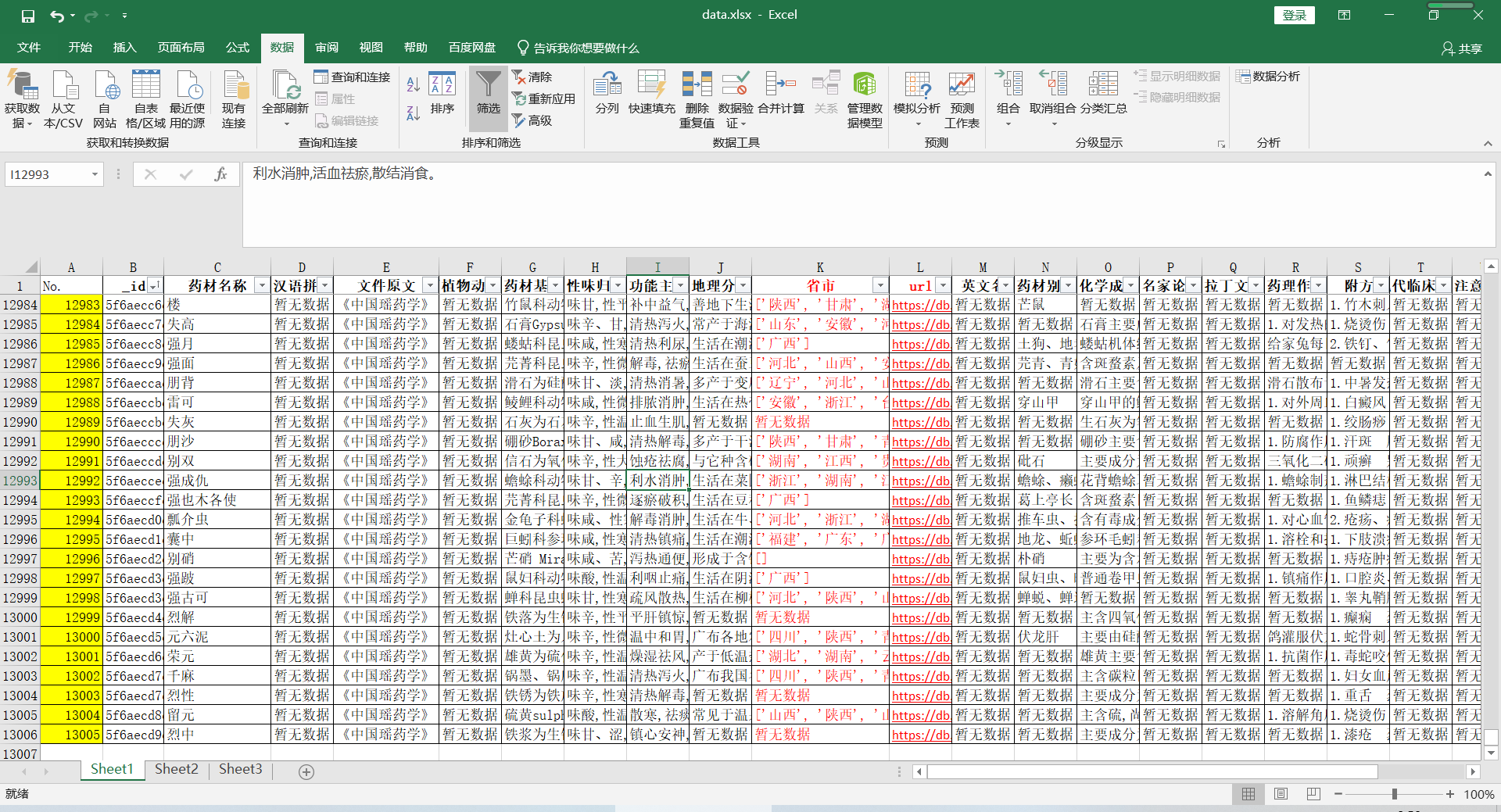
The red font part is the name of the province and city where the medicinal materials are grown and the website page of the corresponding data access extracted through the excel form. The part without data is filled in automatically after grabbing the blank part of the original data, which will be used later.
Basic material preparation
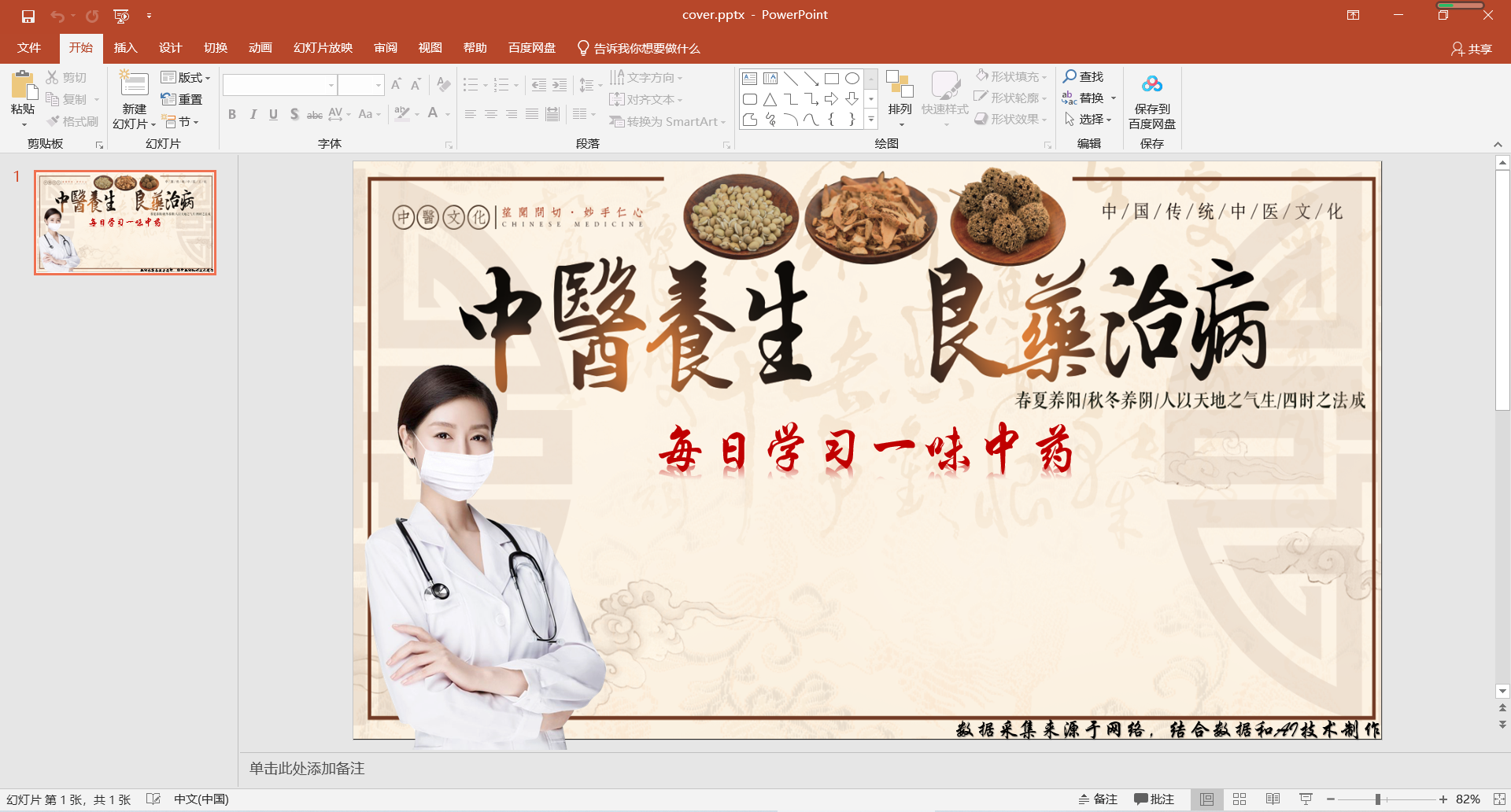
Video cover material, fixed template video cover. This thing can be done with PPT. It's very simple. Then save the created image as jpg image.
Watermark production, using a picture factory to make one is also relatively simple. Remember to save it in png format.

Other general material pictures, such as prescriptions and decoction pictures, are almost the same after all.
These picture materials are put into material_jpg\base directory.
Video template, which can also be done with PPT, and then saved into a circular video, which can be cut with code later. Then cut the template of this video into two parts: transition and part. If you need a trailer video, just make one yourself.
Text to speech API, just take a mobile phone number and apply for Baidu AI interface service. If you are not afraid of expensive, you can use iFLYTEK. Choose by yourself, and the code will be fine tuned according to the interface. I won't read the API documents carefully. If I don't have patience, I don't need to read them later.
Process and code
Understanding the production process of business processing is helpful to understand the code, or it is easy to understand the code.
Let's take a look at the overall project catalogue first.
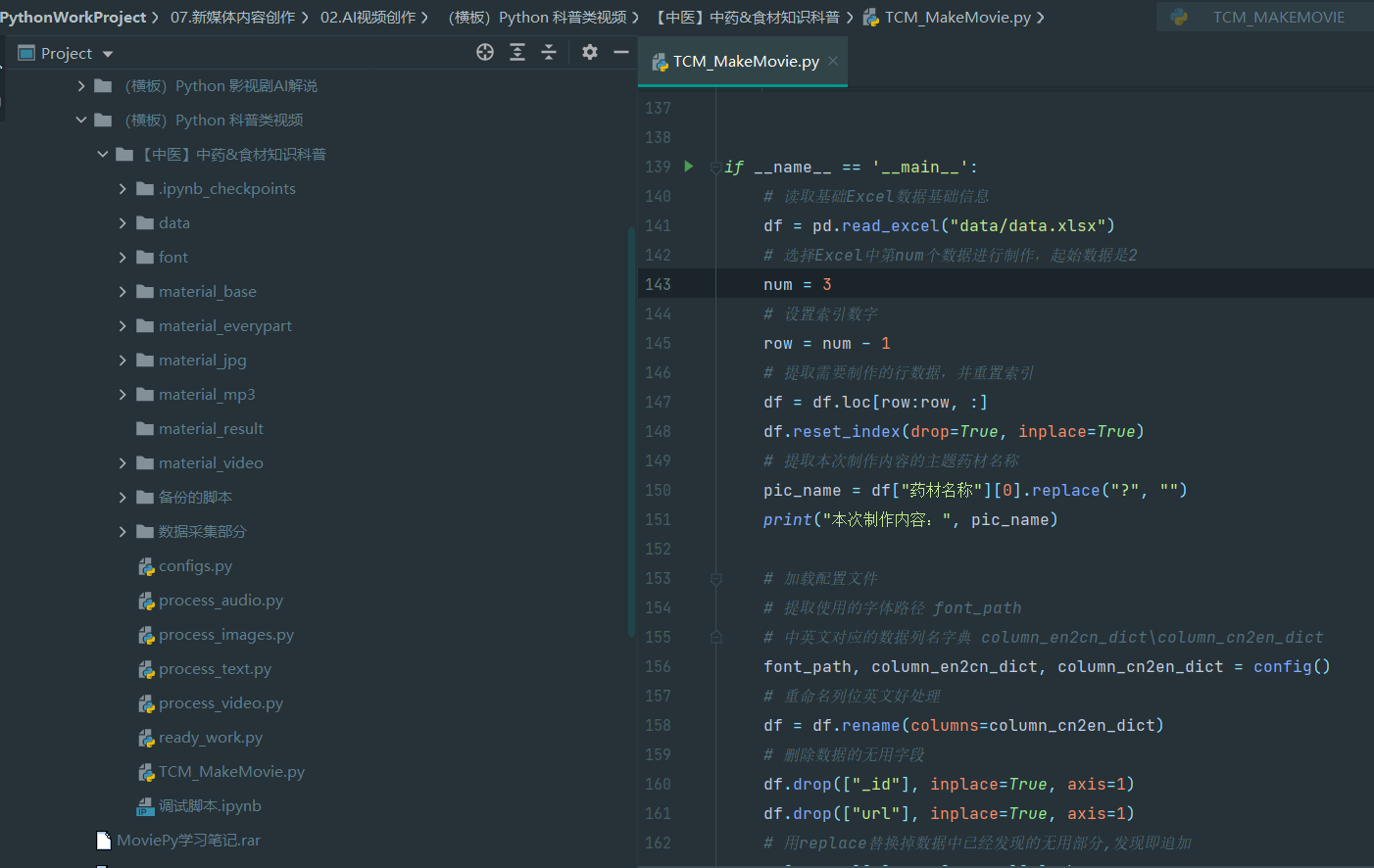
Overall project execution document
- TCM_MakeMovie.py
# coding:utf-8
__author__ = 'Mr.Data Yang'
__explain__ = 'File directory description:' \
'data: Used to store the generated content in the video excel Tabular data, and AI Matting log file' \
'font: Used to store font files' \
'material_base: It is used to store video material, including the beginning, end, middle and end of the film MP4' \
'material_everypart: No voice generated according to different content storage algorithms part Material and cover' \
'material_jpg: It is used to store watermarks, covers and pictures generated according to rules with different contents for video' \
'material_mp3: Used to store Baidu AI Generated MP3 file' \
'material_result: It is used to store the result file generated by the final video. If the same content is generated, the source file needs to be deleted' \
'material_video: After storing the synthetic speech generated by the algorithm according to different contents part Material and cover, total synthesis results' \
'Backup script: this item Debug Process of' \
'' \
'instructions:' \
'1.stay material_jpg The folder whose name corresponds to the content created in pic_name Name of' \
'2.Collect pictures of corresponding contents on the Internet and change their names pic_name.jpg format' \
'3.Brainless startup script, etc material_result Result' \
'4.At line 423 of code, according to material_jpg of base Under folder fuyong,zhongzhi Randomly switch pictures to generate different contents, and the materials can be done by themselves' \
'5.Watermark basis material_jpg of base Lower logo.png Replace' \
'6.Cover according to material_jpg of base Lower cover.pptx Operation generation base.jpg Replace'
# Load the third-party installation package used
import pandas as pd
# Load custom py method
from configs import * # Engineering configuration data
from ready_work import * # Preparation for project start-up
from process_images import * # Processing image data required by the project
from process_audio import * # Process audio data required by the project
from process_video import * # Processing video data required by the project
if __name__ == '__main__':
# Read basic Excel data and basic information
df = pd.read_excel("data/data.xlsx")
# Select the num data in Excel to make, and the starting data is 2
num = 3
# Set index number
row = num - 1
# Extract the row data to be made and reset the index
df = df.loc[row:row, :]
df.reset_index(drop=True, inplace=True)
# Extract the name of the subject medicine of this production
pic_name = df["Medicinal material name"][0].replace("?", "")
print("Content of this production:", pic_name)
# Load configuration file
# Extract the font path used font_path
# Chinese and English corresponding data column name dictionary column_en2cn_dict\column_cn2en_dict
font_path, column_en2cn_dict, column_cn2en_dict = config()
# Renaming columns is easy in English
df = df.rename(columns=column_cn2en_dict)
# Delete useless fields of data
df.drop(["_id"], inplace=True, axis=1)
df.drop(["url"], inplace=True, axis=1)
# Replace the useless parts found in the data with replace, and the discovery is the addition
df["QYFB"][0] = df["QYFB"][0]. \
replace(" ", ""). \
replace("ecological environment", ""). \
replace("resource distribution ", "")
# Fill in parts without data
df = df.fillna("No data")
# Create the production directory that will be used in the word video, and the corresponding directory is pic_name is the top-level directory
# 1. Material directory of each part of a single video_ everypart
# 2. Synthesize the directory of each part of the material and the directory of material combined with all the materials_ video
# 3. Catalogue of picture materials used in a single video_ jpg
# 4. Catalogue of audio materials used in a single video_ mp3
MakeMaterialDir(pic_name)
# Avoid making mistakes in material data repeatedly, and empty the original old data every time
# 1. Clear the material directory of each part of a single video_ everypart
# 2. Clear the material directory of each part of the synthesis_ video
# 3. Clear the audio material directory used by a single video_ mp3
CleanFiles(pic_name)
# If the picture needs to be replaced from Baidu Encyclopedia
# Try to crawl Wikipedia again in the future
RequestGetImage(pic_name)
# The captured pictures of medicinal materials are automatically removed from the background by the algorithm
CutoutJPG(pic_name)
# Use the basic background picture to synthesize the matting image and synthesize the picture to the cover
CompositeCoverJPG(pic_name)
# Audio file data processing
# Use the API interface to generate the audio file corresponding to the caption and save it to material_ Under the corresponding directory of MP3
ChangeWordsToMp3(df)
time_name_dict = Mp3Info(df)
# Body 1-6
try:
FirstPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
SecondPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
ThirdPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
FourthPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
FifthPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
try:
SixthPart(pic_name, df, time_name_dict, column_en2cn_dict)
except:
pass
# Composite cover MP4 file
MakeCoverMp4(pic_name)
# Splicing video to synthesize background music
StitchingVideo(pic_name)
Several important py files.
- configs.py # engineering configuration data
- process_audio.py # process audio data required by the project
- process_images.py # process the picture data required by the project
- process_text.py # process the text data required by the project
- process_video.py # process video data required by the project
- ready_ work. Preparation for py # project startup
According to the above idea, the production file of corresponding traditional Chinese medicine will be generated.
material_everypart

material_jpg
material_mp3
material_video

The final resultant video is result mp4.