Python WeChat Subscription Applet Course Video
https://edu.csdn.net/course/detail/36074
Python Actual Quantitative Transaction Finance System
https://edu.csdn.net/course/detail/35475
Introduction to Gin
Gin is a HTTP web framework written in Go (Golang). It features a Martini-like API with much better performance – up to 40 times faster. If you need smashing performance, get yourself some Gin.
- This is from github Gin Introduction
Gin Is a useful Go Write the HTTP web framework, which is similar to Martini Framework, but Gin Used httprouter This route is 40 times faster than martini. If you pursue high performance, then Gin Fit.
Of course Gin There are other features:
- High routing performance
- Support Middleware
- Routing Group
- JSON Validation
- Error Management
- Scalability
Gin Documentation:
- https://gin-gonic.com/
- https://github.com/gin-gonic/gin
- https://gin-gonic.com/zh-cn/docs/ Chinese Documents
Gin Quick Start Demo
I've written demo s before about getting started with Gin apps. Ad locum.
Gin v1.7.0 , Go 1.16.11
The official one quickstart:
Copypackage main
import "github.com/gin-gonic/gin"
// https://gin-gonic.com/docs/quickstart/
func main() {
r := gin.Default()
r.GET("/ping", func(c *gin.Context) {
c.JSON(200, gin.H{
"message": "pong",
})
})
r.Run() // Listen on default port 8080, 0.0.0:8080
}
This completes a runnable Gin program.
Analyze the Demo above
Step one: gin.Default()
Engine struct It is the most important structure in the Gin framework and contains many fields that the Gin framework uses, such as routing (group), configuration options, HTML, and so on.
New() and Default() Both functions initialize the Engine structure.
RouterGroup struct Is the Gin routing related structure with which routing related operations are related.
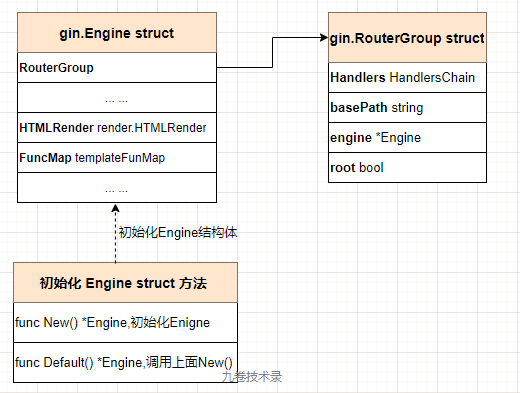
- A. Default() function
This function is used in gin.go/Default() , which instantiates an Engine and calls New() Function:
Copy// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L180
// Instantiate Engine with Logger and Recovery by default, which calls New()
// Default returns an Engine instance with the Logger and Recovery middleware already attached.
func Default() *Engine {
debugPrintWARNINGDefault() // debug program
engine := New() // Create a new Engine instance. The original Default() function was to call New() to create a new Engine instance
engine.Use(Logger(), Recovery()) // Use some Middleware
return engine
}
What is Engine?
- B. What is Engine struct and the New() function:
Engine Is a struct type that contains many fields. The code below shows only the main fields:
Copy// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L57
// The largest structure in gin that stores routes, settings, and Middleware
// Invoke New() or Default() methods to instantiate Engine struct
// Engine is the framework's instance, it contains the muxer, middleware and configuration settings.
// Create an instance of Engine, by using New() or Default()
type Engine struct {
RouterGroup // Group Routing (Routing Related Fields)
... ...
HTMLRender render.HTMLRender
FuncMap template.FuncMap
allNoRoute HandlersChain
allNoMethod HandlersChain
noRoute HandlersChain
noMethod HandlersChain
pool sync.Pool
trees methodTrees
maxParams uint16
trustedCIDRs []*net.IPNet
}
type HandlersChain []HandlerFunc
gin.go/New() instantiation gin.go/Engine struct The simplified code is as follows:
This New function is to initialize Engine struct.
Copy// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L148
// Initialize Engine, instantiate an engine
// New returns a new blank Engine instance without any middleware attached.
// By default the configuration is:
// - RedirectTrailingSlash: true
// - RedirectFixedPath: false
// - HandleMethodNotAllowed: false
// - ForwardedByClientIP: true
// - UseRawPath: false
// - UnescapePathValues: true
func New() *Engine {
debugPrintWARNINGNew()
engine := &Engine{
RouterGroup: RouterGroup{
Handlers: nil,
basePath: "/",
root: true,
},
FuncMap: template.FuncMap{},
... ...
trees: make(methodTrees, 0, 9),
delims: render.Delims{Left: "{{", Right: "}}"},
secureJSONPrefix: "while(1);",
}
engine.RouterGroup.engine = engine // The engine in RouterGroup is assigned here, and the RouterGroup structure is analyzed below
engine.pool.New = func() interface{} {
return engine.allocateContext()
}
return engine
}
- C. RouterGroup
gin.go/Engine struct In routergroup.go/RouterGroup struct This routing-related field, which is also a structure, is coded as follows:
Copy//https://github.com/gin-gonic/gin/blob/v1.7.0/routergroup.go#L41
// Configure Storage Routing
// Handlers after routing
// RouterGroup is used internally to configure router, a RouterGroup is associated with
// a prefix and an array of handlers (middleware).
type RouterGroup struct {
Handlers HandlersChain // Storage Processing Routing
basePath string
engine *Engine // engine
root bool
}
// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L34
type HandlersChain []HandlerFunc
https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L31
// HandlerFunc defines the handler used by gin middleware as return value.
type HandlerFunc func(*Context)
Step 2: r.GET()
r.GET() This is the routing registration and routing handler.
routergroup.go/GET(),handle() -> engine.go/addRoute()
Copy// https://github.com/gin-gonic/gin/blob/v1.7.0/routergroup.go#L102
// GET is a shortcut for router.Handle("GET", path, handle).
func (group *RouterGroup) GET(relativePath string, handlers ...HandlerFunc) IRoutes {
return group.handle(http.MethodGet, relativePath, handlers)
}
handle Processing functions:
Copy// https://github.com/gin-gonic/gin/blob/v1.7.0/routergroup.go#L72
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes {
absolutePath := group.calculateAbsolutePath(relativePath)
handlers = group.combineHandlers(handlers)
group.engine.addRoute(httpMethod, absolutePath, handlers)
return group.returnObj()
}
combineHandlers() Function combines all routing handler s.
addRoute() This function adds methods, URI s, and handler s. The main code for this function is as follows:
Copy// https://github.com/gin-gonic/gin/blob/v1.7.0/gin.go#L276
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) {
... ...
// Every http method(GET, POST, PUT...) All build a cardinality tree
root := engine.trees.get(method) // Get the cardinality tree for the method
if root == nil { // Create a new tree if not
root = new(node) // Create root node of cardinality tree
root.fullPath = "/"
engine.trees = append(engine.trees, methodTree{method: method, root: root})
}
root.addRoute(path, handlers)
... ...
}
The root above. AddRoute function in tree.go Where most of the code comes from httprouter This routing library.
The gin ri is called 40 times faster.
How on earth did it work?
httprouter routing data structure Radix Tree
httprouter document
stay httprouter In the document, there is a sentence like this:
The router relies on a tree structure which makes heavy use of common prefixes, it is basically a compact prefix tree (or just Radix tree)
Preix tree prefix tree or Radix tree cardinality tree is used. and Trie The dictionary tree is relevant.
Radix Tree, called the cardinal Trie tree or the compressed prefix tree, is a more space-saving Trie tree.
Trie Dictionary Tree
Trie, known as a prefix tree or dictionary tree, is an ordered tree in which the keys are usually words and strings, so it is also called a word-finding tree.
It is a multifork tree, where each node may have multiple branches and the root node does not contain strings.
From the root node to a node, the characters passed along the path are concatenated to be the string corresponding to that node.
Each node contains only one character except the root node.
All child nodes of each node contain different characters.
Advantages: Use string common prefix to reduce query time and unnecessary string comparison
Trie tree diagram:
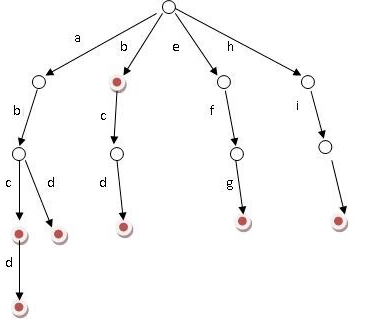
(trie tree created for the seven words b, abc, abd, bcd, abcd, efg, hii, https://baike.baidu.com/item/ Dictionary Tree/9825209)
Code implementation of trie tree: https://baike.baidu.com/item/ Dictionary Tree/9825209#5
Radix Tree cardinality tree
Understanding cardinality trees:
Radix Tree, a cardinal Trie tree or a compressed prefix tree, is a more space-saving Trie tree. It compresses the trie tree.
Look at how compressed, if you have the following set of data key-val s:
Copy{
"def": "redisio",
"dcig":"mysqlio",
"dfo":"linux",
"dfks":"tdb",
"dfkz":"dogdb",
}
Construct a trie tree with key s from the data above:
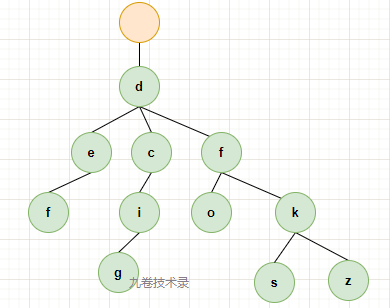
Now by compressing the only child node in the Compressed trie Tree, you can build a radix tree cardinality tree.
If the number of first-level child nodes under the parent node is less than 2, it can be compressed. Merge the child nodes onto the parent node, and compress the number of <2 child nodes in the above figure to the following figure:
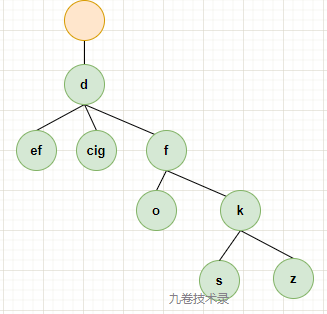
Compress c, f and c, i, g together, which saves some space. After compression, the branch height decreases.
This is to compress the trie tree into a radix tree.
Look at another graph of the Radix Tree that appears a lot:
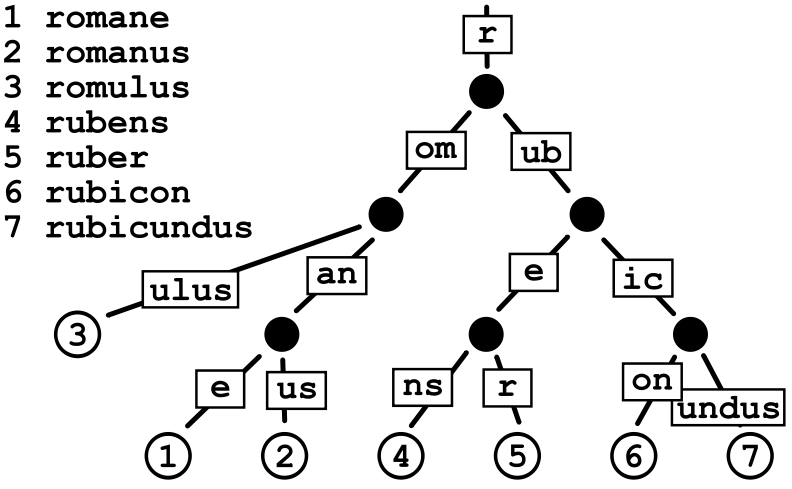
(Figure Radix_tree is from: https://en.wikipedia.org/wiki/Radix_tree)
The unique child nodes of the cardinality tree are merged with their parent nodes, and edges can store both multiple element sequences and a single element. For example, r, om, an, e in the figure above.
The bottom number of the graph of the cardinality tree corresponds to the sorting number of the graph above, for example  Is the ruber character,
Is the ruber character,  .
.
When is it appropriate to use a cardinality tree:
The number of string elements is not very large and the cardinality tree is a good data structure when there are many identical prefixes.
Scenarios for cardinality trees:
A router in httprouter.
Use radix tree to build an associated array with key s as strings.
Many building IP routes also use Radix trees, such as linux, because IPS often have a large number of identical prefixes.
The radix tree is also used to store all key information corresponding to slot s in Redis cluster mode. file rax.h/rax.c .
radix tree is also widely used in inverted indexing.
Cardinality tree in httprouter
Copy// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L46
type node struct {
path string // The string path corresponding to the node
wildChild bool // Is it a parameter node, and if it is a parameter node, wildChild=true
nType nodeType // Node type, there are several enumerated values to see the definition of nodeType below
maxParams uint8 // Maximum number of parameters for node paths
priority uint32 // Node weight, total handler number of child nodes
indices string // The first character of a split between a node and a child node
children []*node // Child Node
handle Handle // http request handling method
}
Node type nodeType Definition:
Copy// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L39
// Node type
const (
static nodeType = iota // default, static node, normal match (/user)
root // root node
param // Parameter Node (/user/:id)
catchAll // Universal matching, matching any parameter (*user)
)
indices This field is the first character in the cache for the next child node.
For example, route: r.GET("/user/one"), r.GET("/user/two"), indices field caches the first character of the next node, that is, "ot" 2 characters. This is to optimize the search matching.
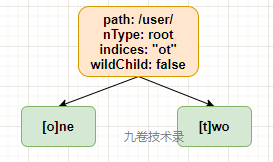
If wildChild=true, indices="" when parameter node.
addRoute Add Route:
addRoute() Add a routing function, which has a lot of code.
Insertion when divided into empty and non-empty trees.
Insert the empty tree directly:
Copyn.insertChild(numParams, path, fullPath, handlers) n.nType = root // Node nType is root type
Processing of non-empty trees:
First it determines that the tree is not empty (non-empty tree), then it is a for loop, and all the processing below is on the for loop surface.
- Update maxParams field
- Find the longest prefix character in common
Copy// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L100
// Find the longest common prefix. Find prefixes with the same characters, represented by i numbers
// This also implies that the common prefix contains no':'or'*', which means there is no special match: or *
// since the existing key can't contain those chars.
i := 0
max := min(len(path), len(n.path))
for i < max && path[i] == n.path[i] {
i++
}
- split edge begins splitting nodes
For example, if the first route path is u Ser and a new route u ber, u is their common prefix, then u is the parent node, the remaining ser, BER is its child node
Copy// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L107
// Split edge
if i < len(n.path) {
child := node{
path: n.path[i:], // It has been determined above that the common parts of the matched characters are represented by i, [i:] Compute from I to take the different parts of the characters remaining as child nodes
wildChild: n.wildChild, // Node type
nType: static, // Static Node Normal Matching
indices: n.indices,
children: n.children,
handle: n.handle,
priority: n.priority - 1, // Node Demotion
}
// Update maxParams (max of all children)
for i := range child.children {
if child.children[i].maxParams > child.maxParams {
child.maxParams = child.children[i].maxParams
}
}
n.children = []*node{&child} // The child node of the current node is modified to the node just split above
// []byte for proper unicode char conversion, see #65
n.indices = string([]byte{n.path[i]})
n.path = path[:i]
n.handle = nil
n.wildChild = false
}
- ihttps://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L137
- 4.1 n.wildChild = true, handling of special parameter nodes,: and *
Copy // https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L133
if n.wildChild {
n = n.children[0]
n.priority++
// Update maxParams of the child node
if numParams > n.maxParams {
n.maxParams = numParams
}
numParams--
// Check if the wildcard matches
if len(path) >= len(n.path) && n.path == path[:len(n.path)] &&
// Adding a child to a catchAll is not possible
n.nType != catchAll &&
// Check for longer wildcard, e.g. :name and :names
(len(n.path) >= len(path) || path[len(n.path)] == '/') {
continue walk
} else {
// Wildcard conflict
var pathSeg string
... ...
}
}
- 4.2 Begin processing indices
Copy// https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go#L171
c := path[0] // Get the first character
// slash after param, handles cases where nType is a parameter
if n.nType == param && c == '/' && len(n.children) == 1
// Check if a child with the next path byte exists
// Determine if the child node matches the current path, using the indices field to determine
// For example, the child nodes of u are ser and ber, indices are U. If a routing u b b is newly inserted, it will have a common part B with the child node ber, and continue to split the BER node
for i := 0; i < len(n.indices); i++ {
if c == n.indices[i] {
i = n.incrementChildPrio(i)
n = n.children[i]
continue walk
}
}
// Otherwise insert it
// indices is not a parameter-wildcard match
if c != ':' && c != '*' {
// []byte for proper unicode char conversion, see #65
n.indices += string([]byte{c})
child := &node{
maxParams: numParams,
}
// New Child Node
n.children = append(n.children, child)
n.incrementChildPrio(len(n.indices) - 1)
n = child
}
n.insertChild(numParams, path, fullPath, handle)
- i=len(path) paths are the same
Error if handler handler handler already exists, assign handler if not
insertChild inserts child nodes:
getValue path lookup:
The above two functions can be analyzed alone -!
Visualize radix tree operations
https://www.cs.usfca.edu/~galles/visualization/RadixTree.html
The radix tree's algorithm operations are shown here on the fly.
Reference resources
- https://github.com/gin-gonic/gin/tree/v1.7.0 gin source
- https://github.com/julienschmidt/httprouter httprouter address
- https://github.com/julienschmidt/httprouter/blob/v1.3.0/tree.go httprouter tree source
- https://gin-gonic.com/docs/quickstart/ gin doc
- https://www.cs.usfca.edu/~galles/visualization/RadixTree.html radix tree algorithm step visualization
- https://baike.baidu.com/item/ Dictionary Tree/9825209 Encyclopedia cardinality tree
- Algorithms 5.2 Word Search Tree Author: Robert Sedgewick / Kevin Wayne
- https://en.wikipedia.org/wiki/Trie Wiki trie tree (en)
- https://en.wikipedia.org/wiki/Radix_tree Wikiradix tree (en)
- https://zh.wikipedia.org/wiki/ radix tree Wikipedia Tree (zh)
- https://github.com/redis/redis/blob/6.0.14/src/rax.c radix tree in redis uses
- https://github.com/redis/redis/blob/6.0.14/src/rax.h radix tree in redis uses