Daily test
Brief description of deadlock Which queues have you used This paper expounds the concept and basic use of process pool and thread pool What is a collaborative process and how to implement it simply
summary
""" Multithreading under multi process Reuse process under multithreading Maximum length can improve the efficiency of software operation """
I. Introduction to IO model
In order to better understand the IO model, we need to review in advance: synchronous, asynchronous, blocking and non blocking
What are the differences between synchronous IO and asynchronous IO, blocking IO and non blocking IO?
In fact, different people may give different answers to this question. For example, wiki thinks that asynchronous IO and non blocking IO are the same thing. This is actually because different people have different knowledge backgrounds, and the context is also different when discussing this issue. Therefore, in order to better answer this question, I will first limit the context of this article.
The background of this paper is network IO in Linux environment. The most important reference for this article is Richard Stevens's "UNIX" ® Network Programming Volume 1, Third Edition: The Sockets Networking ", Section 6.2" I/O Models ", Stevens described in detail the characteristics and differences of various IO in this section. If the English is good enough, it is recommended to read it directly. Stevens's style of writing is famous for its simplicity, so don't worry about not understanding it. The flow chart in this paper is also taken from references.
Stevens compares five IO models in this article:
- blocking IO
- nonblocking IO
- IO multiplexing
- signal driven IO
- asynchronous IO
signal driven IO is not commonly used in practice, so we mainly introduce the other four IO models.
Let's talk about the objects and steps involved in io. For a network IO (here we take read as an example), it will involve two system objects, one is the process (or thread) calling the IO, and the other is the system kernel. When a read operation occurs, the operation will go through two stages:
#1) Waiting for the data to be ready #2) Copying the data from the kernel to the process
It is important to remember these two points, because the difference between these IO models is that there are different situations in the two stages. Supplement:
#1. Input operations: five functions: read, readv, recv, recvfrom and recvmsg. If the state is blocked, the two stages of wait data and copy data will be managed. If it is set to non blocking, an exception will be thrown when the wait does not reach data #2. Output operation: there are five functions: write, writev, send, sendto and sendmsg. When the send buffer is full, it will be blocked in place. If it is set to non blocking, an exception will be thrown #3. Receive foreign links: accept, similar to the input operation #4. Initiate outgoing link: connect, which is similar to the output operation
Blocking IO
In linux, all socket s are blocking by default. A typical read operation flow is as follows: 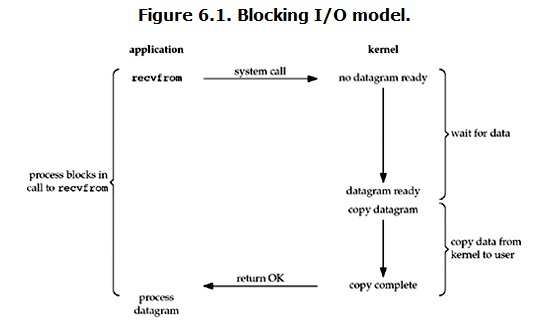 When the user process calls recvfrom, the kernel starts the first stage of IO: preparing data. For network io, many times the data has not arrived at the beginning (for example, a complete UDP packet has not been received). At this time, the kernel has to wait for enough data to arrive. On the user process side, the whole process will be blocked. When the kernel waits until the data is ready, it will copy the data from the kernel to the user's memory, and then the kernel returns the result, and the user process will release the block state and run again. Therefore, the characteristic of blocking IO is that it is blocked in both stages of IO execution (waiting for data and copying data). Almost all programmers first come into contact with network programming from interfaces such as listen(), send(), recv(). Using these interfaces can easily build the server / client model. However, most socket interfaces are blocking. As shown in the following figure ps: the so-called blocking interface refers to that the system call (generally IO interface) does not return the call result and keeps the current thread blocked. It is returned only when the system call obtains the result or there is a timeout error.
When the user process calls recvfrom, the kernel starts the first stage of IO: preparing data. For network io, many times the data has not arrived at the beginning (for example, a complete UDP packet has not been received). At this time, the kernel has to wait for enough data to arrive. On the user process side, the whole process will be blocked. When the kernel waits until the data is ready, it will copy the data from the kernel to the user's memory, and then the kernel returns the result, and the user process will release the block state and run again. Therefore, the characteristic of blocking IO is that it is blocked in both stages of IO execution (waiting for data and copying data). Almost all programmers first come into contact with network programming from interfaces such as listen(), send(), recv(). Using these interfaces can easily build the server / client model. However, most socket interfaces are blocking. As shown in the following figure ps: the so-called blocking interface refers to that the system call (generally IO interface) does not return the call result and keeps the current thread blocked. It is returned only when the system call obtains the result or there is a timeout error. 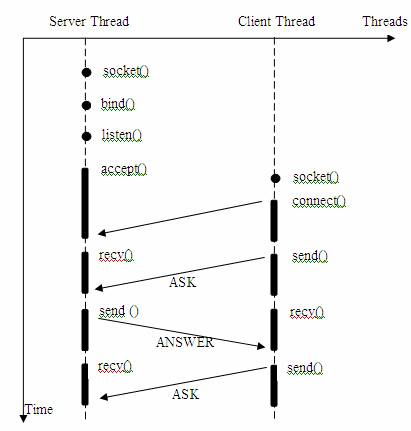 In fact, unless otherwise specified, almost all IO interfaces (including socket interfaces) are blocking. This brings a big problem to network programming. For example, when calling recv(1024), the thread will be blocked. During this period, the thread will not be able to perform any operation or respond to any network request. A simple solution:
In fact, unless otherwise specified, almost all IO interfaces (including socket interfaces) are blocking. This brings a big problem to network programming. For example, when calling recv(1024), the thread will be blocked. During this period, the thread will not be able to perform any operation or respond to any network request. A simple solution:
#Use multithreading (or multiprocessing) on the server side. The purpose of multithreading (or multi process) is to let each connection have an independent thread (or process), so that the blocking of any connection will not affect other connections.
The programme's problems are:
#In the way of opening multiple processes or threads, when it comes to responding to hundreds of connection requests at the same time, both multiple threads and multiple processes will seriously occupy system resources, reduce the efficiency of the system's response to the outside world, and it is easier for threads and processes themselves to enter the pseudo dead state.
Improvement plan:
#Many programmers may consider using "thread pool" or "connection pool". "Thread pool" aims to reduce the frequency of creating and destroying threads, maintain a reasonable number of threads, and let idle threads take on new execution tasks again. "Connection pool" maintains the cache pool of connections, reuses existing connections as much as possible, and reduces the frequency of creating and closing connections. These two technologies can reduce the system overhead, and are widely used in many large-scale systems, such as websphere, tomcat and various databases.
In fact, the improved scheme also has problems:
#"Thread pool" and "connection pool" technologies only alleviate the resource occupation caused by frequent calls to IO interfaces to a certain extent. Moreover, the so-called "pool" always has its upper limit. When the request greatly exceeds the upper limit, the response of the system composed of "pool" to the outside world is not much better than that without pool. Therefore, the use of "pool" must consider the response scale it faces, and adjust the size of "pool" according to the response scale.
Corresponding to the thousands or even tens of thousands of client requests that may occur at the same time in the above example, "thread pool" or "connection pool" may alleviate some of the pressure, but it can not solve all the problems. In short, multithreading model can easily and efficiently solve small-scale service requests, but in the face of large-scale service requests, multithreading model will also encounter bottlenecks. We can try to solve this problem with non blocking interface.
III. non blocking IO
Under Linux, you can set socket to make it non blocking. When reading a non blocking socket, the process is as follows: 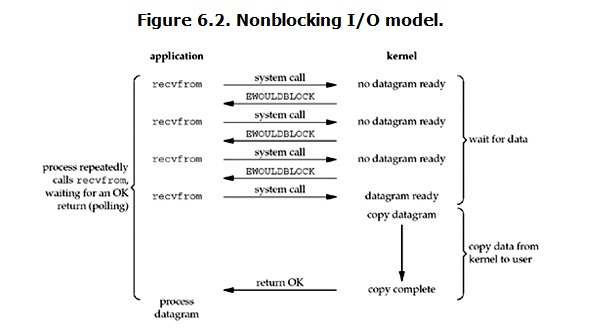 As can be seen from the figure, when the user process issues a read operation, if the data in the kernel is not ready, it will not block the user process, but immediately return an error. From the perspective of user process, it does not need to wait after initiating a read operation, but gets a result immediately. When the user process judges that the result is an error, it knows that the data is not ready, so the user can do other things within the time interval from this time to the next time when the read query is initiated, or directly send the read operation again. Once the data in the kernel is ready and the system call of the user process is received again, it immediately copies the data to the user memory (this stage is still blocked), and then returns. In other words, after the non blocking recvform system call, the process is not blocked, and the kernel immediately returns to the process. If the data is not ready, an error will be returned at this time. After the process returns, it can do something else, and then launch the recvform system call. Repeat the above process and call the recvform system repeatedly. This process is often called polling. Poll and check the kernel data until the data is ready, and then copy the data to the process for data processing. It should be noted that during the whole process of copying data, the process is still in a blocked state. Therefore, in non blocking IO, the user process actually needs to constantly actively ask whether the kernel data is ready.
As can be seen from the figure, when the user process issues a read operation, if the data in the kernel is not ready, it will not block the user process, but immediately return an error. From the perspective of user process, it does not need to wait after initiating a read operation, but gets a result immediately. When the user process judges that the result is an error, it knows that the data is not ready, so the user can do other things within the time interval from this time to the next time when the read query is initiated, or directly send the read operation again. Once the data in the kernel is ready and the system call of the user process is received again, it immediately copies the data to the user memory (this stage is still blocked), and then returns. In other words, after the non blocking recvform system call, the process is not blocked, and the kernel immediately returns to the process. If the data is not ready, an error will be returned at this time. After the process returns, it can do something else, and then launch the recvform system call. Repeat the above process and call the recvform system repeatedly. This process is often called polling. Poll and check the kernel data until the data is ready, and then copy the data to the process for data processing. It should be noted that during the whole process of copying data, the process is still in a blocked state. Therefore, in non blocking IO, the user process actually needs to constantly actively ask whether the kernel data is ready.
# Server
import socket
import time
server=socket.socket()
server.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
server.bind(('127.0.0.1',8083))
server.listen(5)
server.setblocking(False)
r_list=[]
w_list={}
while 1:
try:
conn,addr=server.accept()
r_list.append(conn)
except BlockingIOError:
# Emphasize:!!! The essence of non blocking IO is that there is no blocking at all!!!
# time.sleep(0.5) # This line of comments is opened purely for the convenience of viewing the effect
print('Doing other things')
print('rlist: ',len(r_list))
print('wlist: ',len(w_list))
# Traverse the read list and take out the socket to read the contents in turn
del_rlist=[]
for conn in r_list:
try:
data=conn.recv(1024)
if not data:
conn.close()
del_rlist.append(conn)
continue
w_list[conn]=data.upper()
except BlockingIOError: # If the reception is not successful, continue to retrieve the reception of the next socket
continue
except ConnectionResetError: # If the current socket is abnormal, close it, then add it to the deletion list and wait for it to be cleared
conn.close()
del_rlist.append(conn)
# Traverse the write list and take out the contents sent by the socket in turn
del_wlist=[]
for conn,data in w_list.items():
try:
conn.send(data)
del_wlist.append(conn)
except BlockingIOError:
continue
# Clean up useless sockets without listening for their IO operations
for conn in del_rlist:
r_list.remove(conn)
for conn in del_wlist:
w_list.pop(conn)
#client
import socket
import os
client=socket.socket()
client.connect(('127.0.0.1',8083))
while 1:
res=('%s hello' %os.getpid()).encode('utf-8')
client.send(res)
data=client.recv(1024)
print(data.decode('utf-8'))
However, the non blocking IO model is never recommended. We can't do otherwise. Its advantage is that we can do other work while waiting for the task to be completed (including submitting other tasks, that is, multiple tasks can be executed in the "background" at the same time). But it is hard to hide its shortcomings:
#1. Calling recv() circularly will greatly increase CPU utilization; This is why we leave a sentence time in the code Sleep (2), otherwise it is very easy to get stuck under the condition of low configuration host #2. The response delay of task completion increases because the read operation is polled only after a period of time, and the task may be completed at any time between two polls. This will result in a reduction in the overall data throughput.
In addition, in this scheme, recv() is more used to detect whether the operation is completed. The actual operating system provides a more efficient interface to detect whether the operation is completed. For example, select() multiplexing mode can detect whether multiple connections are active at one time.
IO multiplexing
The word IO multiplexing may be a little strange, but if I say select/epoll, I can probably understand it. In some places, it is also called event driven io. As we all know, the advantage of select/epoll is that a single process can handle the IO of multiple network connections at the same time. Its basic principle is that the select/epoll function will continuously poll all the sockets it is responsible for. When a socket has data, it will notify the user process. Its flow chart is as follows: 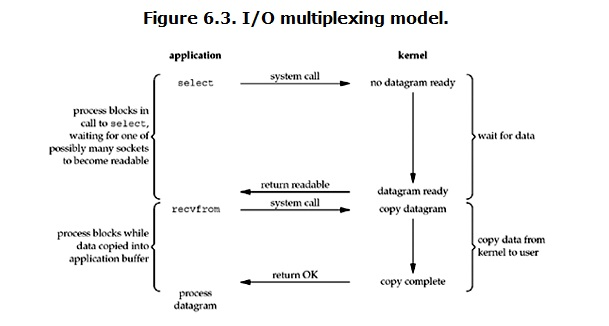 When the user process calls select, the whole process will be blocked, and at the same time, the kernel will "monitor" all the sockets in charge of select. When the data in any socket is ready, select will return. At this time, the user process calls the read operation to copy the data from the kernel to the user process. This diagram is not much different from the diagram of blocking io. In fact, it is worse. Because two system calls (select and recvfrom) are needed here, while blocking IO only calls one system call (recvfrom). However, the advantage of using select is that it can handle multiple connections at the same time. Emphasis: 1 If the number of connections processed is not very high, the web server using select/epoll may not have better performance than the web server using multi threading + blocking IO, and the delay may be greater. The advantage of select/epoll is not that it can handle a single connection faster, but that it can handle more connections. 2. In the multiplexing model, each socket is generally set to non blocking. However, as shown in the above figure, the whole user's process is always blocked. The only thing is that process is given to block by the select function, not by socket IO.
When the user process calls select, the whole process will be blocked, and at the same time, the kernel will "monitor" all the sockets in charge of select. When the data in any socket is ready, select will return. At this time, the user process calls the read operation to copy the data from the kernel to the user process. This diagram is not much different from the diagram of blocking io. In fact, it is worse. Because two system calls (select and recvfrom) are needed here, while blocking IO only calls one system call (recvfrom). However, the advantage of using select is that it can handle multiple connections at the same time. Emphasis: 1 If the number of connections processed is not very high, the web server using select/epoll may not have better performance than the web server using multi threading + blocking IO, and the delay may be greater. The advantage of select/epoll is not that it can handle a single connection faster, but that it can handle more connections. 2. In the multiplexing model, each socket is generally set to non blocking. However, as shown in the above figure, the whole user's process is always blocked. The only thing is that process is given to block by the select function, not by socket IO.
Conclusion: the advantage of select is that it can handle multiple connections and is not suitable for single connection select network IO model
#Server
from socket import *
import select
server = socket(AF_INET, SOCK_STREAM)
server.bind(('127.0.0.1',8093))
server.listen(5)
server.setblocking(False)
print('starting...')
rlist=[server,]
wlist=[]
wdata={}
while True:
rl,wl,xl=select.select(rlist,wlist,[],0.5)
print(wl)
for sock in rl:
if sock == server:
conn,addr=sock.accept()
rlist.append(conn)
else:
try:
data=sock.recv(1024)
if not data:
sock.close()
rlist.remove(sock)
continue
wlist.append(sock)
wdata[sock]=data.upper()
except Exception:
sock.close()
rlist.remove(sock)
for sock in wl:
sock.send(wdata[sock])
wlist.remove(sock)
wdata.pop(sock)
#client
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8093))
while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
data=client.recv(1024)
print(data.decode('utf-8'))
client.close()
select process analysis of monitoring fd changes:
#The user process creates a socket object and copies the monitored fd to the kernel space. Each fd will correspond to a system file table. After the fd in the kernel space responds to the data, it will send a signal to the user process that the data has arrived; #The user process sends the system call again, for example (accept) copy the data in the kernel space to the user space, and clear it as the data in the kernel space of the receiving data end. In this way, when fd listening again, new data can be responded to (the sending end needs to be cleared after receiving the response because it is based on the TCP protocol).
Advantages of this model:
#Compared with other models, the event driven model using select() only uses a single thread (process) to execute, occupies less resources, does not consume too much CPU, and can provide services for multiple clients at the same time. If you try to build a simple event driven server program, this model has a certain reference value.
Disadvantages of this model:
#First, the select() interface is not the best choice to implement "event driven". Because when the handle value to be detected is large, the select() interface itself needs to spend a lot of time polling each handle. Many operating systems provide more efficient interfaces, such as epoll for linux, kqueue for BSD, and / dev/poll for Solaris. If you need to implement more efficient server programs, interfaces like epoll are more recommended. Unfortunately, the epoll interfaces specially provided by different operating systems are very different, so it will be difficult to use an interface similar to epoll to realize a server with good cross platform capability. #Secondly, the model mixes event detection and event response together. Once the actuator of event response is huge, it will be disastrous to the whole model.
V. asynchronous I / O
In fact, asynchronous IO under Linux is not used much. It was introduced from kernel version 2.6. Let's take a look at its process first: 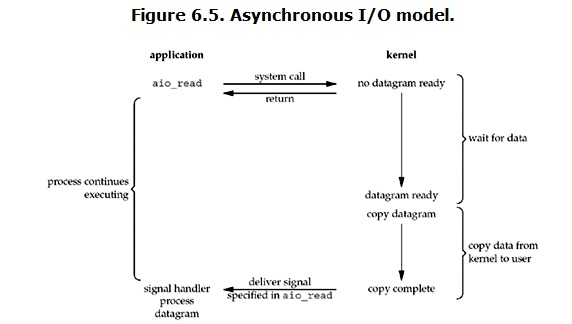 After the user process initiates the read operation, it can immediately start to do other things. On the other hand, from the perspective of the kernel, when it receives an asynchronous read, it will return immediately, so it will not generate any block to the user process. Then, the kernel will wait for the data preparation to be completed, and then copy the data to the user's memory. When all this is completed, the kernel will send a signal to the user process to tell it that the read operation is completed.
After the user process initiates the read operation, it can immediately start to do other things. On the other hand, from the perspective of the kernel, when it receives an asynchronous read, it will return immediately, so it will not generate any block to the user process. Then, the kernel will wait for the data preparation to be completed, and then copy the data to the user's memory. When all this is completed, the kernel will send a signal to the user process to tell it that the read operation is completed.
Comparative analysis of six IO models
So far, all four IO models have been introduced. Now let's go back to the first few questions: what's the difference between blocking and non blocking, and what's the difference between synchronous IO and asynchronous IO. First answer the simplest one: blocking vs non blocking. In fact, the previous introduction has clearly explained the difference between the two. Calling blocking IO will block the corresponding process until the operation is completed, while non blocking IO will return immediately when the kernel is still preparing data. Before explaining the difference between synchronous IO and asynchronous IO, you need to give their definitions first. The definition given by Stevens (actually POSIX) is like this: a synchronous I / O operation causes the requesting process to be blocked until that I / O operation completes; An asynchronous I/O operation does not cause the requesting process to be blocked; The difference between the two is that synchronous IO blocks the process when doing "IO operation". According to this definition, the four IO models can be divided into two categories. The previously mentioned blocking IO, non blocking IO and IO multiplexing all belong to the category of synchronous IO, while asynchronous I / O belongs to the latter category. Some people may say that non blocking IO is not blocked. There is a very "cunning" place here. The "IO operation" referred to in the definition refers to the real IO operation, which is the recvfrom system call in the example. When the non blocking IO executes the recvfrom system call, if the kernel data is not ready, the process will not be blocked at this time. However, when the data in the kernel is ready, recvfrom will copy the data from the kernel to the user's memory. At this time, the process is blocked. During this time, the process is blocked. Asynchronous IO is different. When a process initiates an IO operation, it returns directly and ignores it until the kernel sends a signal telling the process that IO is complete. In the whole process, the process is not blocked at all. The comparison of each IO Model is shown in the figure:  After the above introduction, you will find that the difference between non blocking IO and asynchronous IO is still obvious. In non blocking IO, although the process will not be blocked most of the time, it still requires the process to actively check. When the data is ready, the process also needs to actively call recvfrom again to copy the data to the user's memory. Asynchronous IO is completely different. It's like the user process gives the whole IO operation to someone else (kernel) to complete, and then the other person sends a signal after it is completed. During this period, the user process does not need to check the status of IO operations, nor does it need to actively copy data.
After the above introduction, you will find that the difference between non blocking IO and asynchronous IO is still obvious. In non blocking IO, although the process will not be blocked most of the time, it still requires the process to actively check. When the data is ready, the process also needs to actively call recvfrom again to copy the data to the user's memory. Asynchronous IO is completely different. It's like the user process gives the whole IO operation to someone else (kernel) to complete, and then the other person sends a signal after it is completed. During this period, the user process does not need to check the status of IO operations, nor does it need to actively copy data.
Seven selectors module
select,poll,epoll
IO reuse: in order to explain this term, first understand the concept of reuse, which means sharing. This understanding is still somewhat abstract. Therefore, let's understand the use of reuse in the communication field. In the communication field, in order to make full use of the physical medium of network connection, Time division multiplexing or frequency division multiplexing technology is often used on the same network link to transmit multiple signals on the same link. Here, we basically understand the meaning of multiplexing, that is, sharing a "medium" to do the same kind of things as much as possible. What is the "medium" of IO multiplexing? To this end, let's first look at the model of server programming. The server will generate a process to serve the request sent by the client. Every time a client request comes, a process will be generated to serve. However, the process cannot be generated indefinitely. Therefore, in order to solve the problem of a large number of client access, IO reuse technology is introduced, That is, a process can serve multiple customer requests at the same time. In other words, the "media" of IO reuse is processes (specifically, select and poll are reused, because processes are also realized by calling select and poll). Reuse one process (select and poll) to serve multiple IOS. Although the IO sent by the client is concurrent, the read and write data required for IO is not ready in most cases, Therefore, a function (select and poll) can be used to monitor the status of these data required by io. Once the IO has data that can be read and written, the process will serve such io.
After understanding IO reuse, let's take a look at the differences and connections between the three APIs (select, poll and epoll) in io reuse
Select, poll and epoll are IO multiplexing mechanisms. I/O multiplexing is a mechanism that can monitor multiple descriptors. Once a descriptor is ready (generally read ready or write ready), it can notify the application to perform corresponding read-write operations. However, select, poll and epoll are synchronous I/O in essence, because they need to be responsible for reading and writing after the reading and writing events are ready, that is, the reading and writing process is blocked, while asynchronous I/O does not need to be responsible for reading and writing. The implementation of asynchronous I/O will be responsible for copying data from the kernel to user space. The prototypes of the three are as follows:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); int poll(struct pollfd *fds, nfds_t nfds, int timeout); int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
1. The first parameter nfds of select is the maximum descriptor value in the fdset set plus 1. Fdset is a bit group whose size is limited to__ FD_ Set size (1024), each bit of the bit group represents whether its corresponding descriptor needs to be checked. The second, third and fourth parameters represent the file descriptor bit array that needs to pay attention to read, write and error events. These parameters are both input parameters and output parameters, which may be modified by the kernel to indicate which descriptors have events of interest. Therefore, it is necessary to reinitialize fdset before calling select every time. The timeout parameter is the timeout time, which will be modified by the kernel, and its value is the remaining time of timeout.
select The calling steps are as follows: (1)use copy_from_user Copy from user space fdset To kernel space (2)Registering Callbacks __pollwait (3)Traverse all fd,Call its corresponding poll Method (for socket,this poll The method is sock_poll,sock_poll It will be called according to the situation tcp_poll,udp_poll perhaps datagram_poll) (4)with tcp_poll For example, its core implementation is__pollwait,That is, the callback function registered above. (5)__pollwait My main job is to current(The current process) is hung to the waiting queue of the device. Different devices have different waiting queues tcp_poll For example, its waiting queue is sk->sk_sleep(Note that hanging a process in the waiting queue does not mean that the process is asleep. After the device receives a message (network device) or fills in the file data (disk device), it will wake up the process waiting for sleep on the queue. At this time current Was awakened. (6)poll Method returns a that describes whether the read-write operation is ready mask Mask, according to this mask Mask to fd_set Assignment. (7)If you traverse all the fd,A read-write has not been returned mask Mask, the schedule_timeout Is calling select Process (i.e current)Go to sleep. When the device driver reads and writes its own resources, it will wake up the process waiting for sleep on the queue. If a certain timeout period is exceeded( schedule_timeout Specified), or if no one wakes up, call select The process will be awakened again CPU,Then traverse again fd,Judge whether there is ready fd. (8)hold fd_set Copy from kernel space to user space. To sum up select Several disadvantages of: (1)Every call select,All need to fd The cost of copying collections from user state to kernel state is fd Many times it will be very big (2)At the same time, each call select You need to traverse all the data passed in the kernel fd,What's the cost fd Many times it's big (3)select The number of supported file descriptors is too small. The default is 1024
2. Unlike select, poll passes events that need attention to the kernel through a pollfd array, so there is no limit on the number of descriptors. The events field and events in pollfd are used to mark the events that need attention and the events that occur, so pollfd array only needs to be initialized once.
poll Implementation mechanism and select Similarly, it corresponds to the sys_poll,Just poll Pass to kernel pollfd Array, and then pollfd Each descriptor in the poll,Comparison processing fdset For example, poll More efficient. poll After returning, you need to pollfd Each element in checks its revents Value to indicate whether the event occurred.
3. Until Linux 2 The implementation method directly supported by the kernel, epoll, is recognized as Linux 2 6, the best multi-channel I/O ready notification method. Epoll can support both horizontal trigger and edge trigger (Edge Triggered, which only tells the process which file descriptors have just become ready. It only says once. If we don't take action, it won't tell again. This method is called edge trigger). Theoretically, the performance of edge trigger is higher, but the code implementation is quite complex. Epoll also tells only those ready file descriptors, and when we call epoll_ When wait() obtains ready file descriptors, it returns not the actual descriptors, but a value representing the number of ready descriptors. You only need to obtain the corresponding number of file descriptors in turn from an array specified by epoll. Memory mapping (mmap) technology is also used here, which completely eliminates the cost of copying these file descriptors during system call. Another essential improvement is that epoll adopts event based ready notification. In select/poll, the kernel scans all monitored file descriptors only after the process calls a certain method, and epoll passes epoll in advance_ CTL () to register a file descriptor. Once a file descriptor is ready, the kernel will use a callback mechanism similar to callback to quickly activate the file descriptor. When the process calls epoll_ You are notified when you wait ().
epoll Since it's right select and poll The improvement of should be able to avoid the above three shortcomings. that epoll How did you solve it? Before that, let's take a look epoll and select and poll Different on the calling interface of, select and poll Only one function is provided—— select perhaps poll Function. and epoll Three functions are provided, epoll_create,epoll_ctl and epoll_wait,epoll_create Is to create a epoll Handle; epoll_ctl Register the event type to listen to; epoll_wait Is waiting for the event to occur. For the first disadvantage, epoll Our solution is epoll_ctl Function. Each time a new event is registered epoll When in handle (in epoll_ctl Specified in EPOLL_CTL_ADD),Will take all fd Copy into the kernel, not in the epoll_wait Duplicate copies when needed. epoll Guaranteed every fd It will only be copied once in the whole process. For the second disadvantage, epoll Our solution is not like select or poll The same every time current Join in turn fd The corresponding device is in the waiting queue, but only in the epoll_ctl Shi Ba current Hang it up (this one is essential) and fd Specify a callback function. When the device is ready and wakes up the waiting person on the waiting queue, this callback function will be called, and this callback function will put the ready fd Add a ready list). epoll_wait In fact, the work of is to check whether there is ready in the ready linked list fd(utilize schedule_timeout()Achieve sleep for a while, judge the effect of a while, and select Step 7 in the implementation is similar). For the third disadvantage, epoll Without this limitation, it supports FD The upper limit is the maximum number of files that can be opened, which is generally much greater than 2048,for instance, In 1 GB The memory on the machine is about 100000, and the specific number can be cat /proc/sys/fs/file-max Observe,Generally speaking, this number has a lot to do with the system memory.
Summary:
(1)select,poll The implementation needs to continuously poll all users fd Set until the device is ready, during which sleep and wake-up may alternate several times. and epoll In fact, it also needs to be called epoll_wait Continuously polling the ready linked list, during which sleep and wake-up may alternate for many times, but it calls the callback function when the device is ready fd Put it into the ready linked list and wake it up in epoll_wait The process of entering sleep. Although we have to sleep and alternate, but select and poll When you are "awake", you have to traverse the whole fd Set, and epoll When "awake", just judge whether the ready linked list is empty, which saves a lot of time CPU Time, which is the performance improvement brought by the callback mechanism. (2)select,poll Every time you call fd The set is copied from the user state to the kernel state once, and the current Hang up the device waiting queue once, and epoll Just one copy, and put current Hang to the waiting queue only once (at epoll_wait At the beginning of, note that the waiting queue here is not a device waiting queue, but a epoll Internally defined waiting queue), which can also save a lot of overhead.
These three IO multiplexing models have different supports on different platforms, but epoll does not support them under windows. Fortunately, we have selectors module to help us select the most appropriate one under the current platform by default
#Server
from socket import *
import selectors
sel=selectors.DefaultSelector()
def accept(server_fileobj,mask):
conn,addr=server_fileobj.accept()
sel.register(conn,selectors.EVENT_READ,read)
def read(conn,mask):
try:
data=conn.recv(1024)
if not data:
print('closing',conn)
sel.unregister(conn)
conn.close()
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn)
conn.close()
server_fileobj=socket(AF_INET,SOCK_STREAM)
server_fileobj.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
server_fileobj.bind(('127.0.0.1',8088))
server_fileobj.listen(5)
server_fileobj.setblocking(False) #Set the socket interface to non blocking
sel.register(server_fileobj,selectors.EVENT_READ,accept) #It is equivalent to that a file handle server is attached in the read list of net select_ Fileobj, and a callback function accept is bound
while True:
events=sel.select() #Check whether all fileobj s have completed the wait data
for sel_obj,mask in events:
callback=sel_obj.data #callback=accpet
callback(sel_obj.fileobj,mask) #accpet(server_fileobj,1)
#client
from socket import *
c=socket(AF_INET,SOCK_STREAM)
c.connect(('127.0.0.1',8088))
while True:
msg=input('>>: ')
if not msg:continue
c.send(msg.encode('utf-8'))
data=c.recv(1024)
print(data.decode('utf-8'))
Job: concurrent FTP based on selectors module Reference: link: https://pan.baidu.com/s/1qYPrHCg Password: 9is4
Combing network concurrency knowledge points
- Software development architecture * Internet Protocol
""" osi Seventh floor Fifth floor What's on every floor Ethernet protocol broadcast storm IP agreement TCP/UDP """
- Three handshakes and four waves * introduction to socket * TCP packet sticking problem custom fixed length header * UDP protocol * socketserver module * operating system development history * multi-channel technology * process theory * two ways to start the process * mutual exclusion lock * producer consumer model * thread theory * two ways to start the thread * GIL global interpreter lock * process pool thread pool * concept of the process *Understanding of IO model
om/s/1qYPrHCg)
Combing network concurrency knowledge points
- Software development architecture * Internet Protocol
""" osi Seventh floor Fifth floor What's on every floor Ethernet protocol broadcast storm IP agreement TCP/UDP """
- Three handshakes and four waves * introduction to socket * TCP packet sticking problem custom fixed length header * UDP protocol * socketserver module * operating system development history * multi-channel technology * process theory * two ways to start the process * mutual exclusion lock * producer consumer model * thread theory * two ways to start the thread * GIL global interpreter lock * process pool thread pool * concept of the process *Understanding of IO model