preface
Use selenium+requests to visit the page and crawl the hook bar recruitment information
Tip: the following is the main content of this article. The following cases can be used for reference
1, Analyze url
By observing the page, we can see that the page data belongs to dynamic loading, so now we get the data packet through the packet capture tool
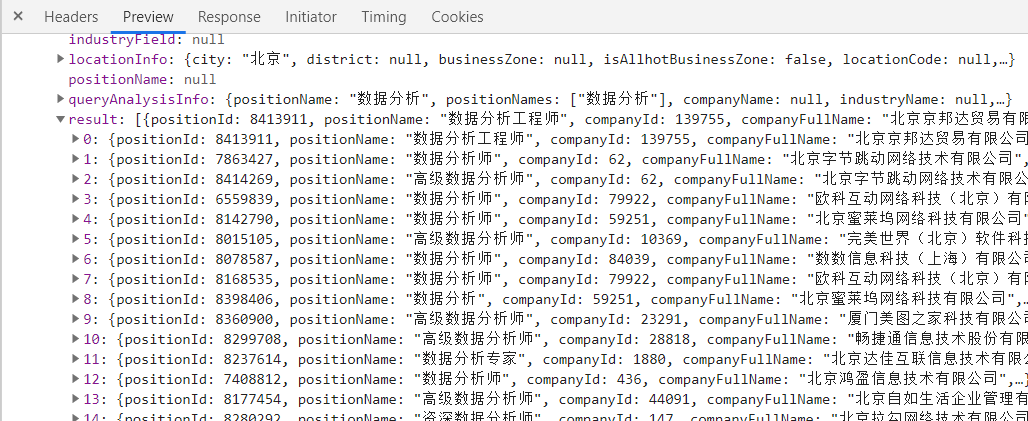
Observe its url and parameters
url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" Parameters: city=%E5%8C%97%E4%BA%AC ==>city first=true ==>useless pn=1 ==>the number of pages kd=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90 ==>Commodity keywords
Therefore, if we want to achieve full site crawling, we need city and page number
2, Get all cities and pages
After opening the dragline, we found that his data is not fully displayed. For example, in the selection of cities, only 30 pages are displayed nationwide, but the total number of pages is far greater than 30 pages; I chose Beijing and found that it is 30 pages, and Haidian District under Beijing is 30 pages. Maybe we can't crawl all the data, but we can crawl as much data as possible
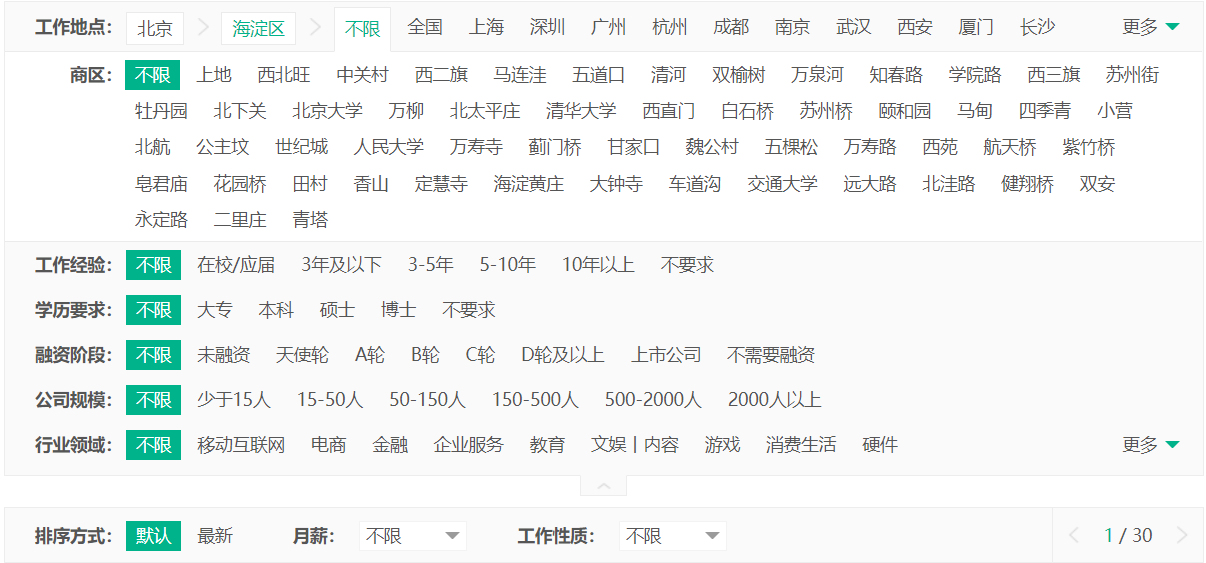
In order to obtain the data of the whole station, we must have two parameters: one is the city and the other is the number of pages. Therefore, we use selenium automation to obtain all cities and the corresponding number of pages
def City_Page(self):
City_Page={}
url="https://www.lagou.com/jobs/allCity.html?keyword=%s&px=default&companyNum=0&isCompanySelected=false&labelWords="%(self.keyword)
self.bro.get(url=url)
sleep(30)
print("Start getting cities and their maximum pages")
if "Verification system" in self.bro.page_source:
sleep(40)
html = etree.HTML(self.bro.page_source)
city_urls = html.xpath('//table[@class="word_list"]//li/input/@value')
for city_url in city_urls:
try:
self.bro.get(city_url)
if "Verification system" in self.bro.page_source:
sleep(40)
city=self.bro.find_element_by_xpath('//a[@class="current_city current"]').text
page=self.bro.find_element_by_xpath('//span[@class="span totalNum"]').text
City_Page[city]=page
sleep(0.5)
except:
pass
self.bro.quit()
data = json.dumps(City_Page)
with open("city_page.json", 'w', encoding="utf-8")as f:
f.write(data)
return City_Page
3, Generate params parameters
When we have the maximum number of pages corresponding to each city, we can generate the parameters required to access the page
def Params_List(self):
with open("city_page.json", "r")as f:
data = json.loads(f.read())
Params_List = []
for a, b in zip(data.keys(), data.values()):
for i in range(1, int(b) + 1):
params = {
'city': a,
'pn': i,
'kd': self.keyword
}
Params_List.append(params)
return Params_List
4, Get data
Finally, we can access the page to get the data by adding the request header and using the params url
def Parse_Data(self,params):
url = "https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false"
header={
'referer': 'https://www.lagou.com/jobs/list_%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90?labelWords=&fromSearch=true&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36',
'cookie':''
}
try:
text = requests.get(url=url, headers=header, params=params).text
if "frequently" in text:
print("The operation is frequent and has been found. It is currently the second%d individual params"%(i))
data=json.loads(text)
result=data["content"]["positionResult"]["result"]
for res in result:
with open(".//lagou1.csv", "a",encoding="utf-8") as f:
writer = csv.DictWriter(f, res.keys())
writer.writerow(res)
sleep(1)
except Exception as e:
print(e)
pass
summary
Although the data only shows the first 30 pages, the data is not fully obtained
When using selenium to obtain the maximum number of pages in the city, you should log in to dragnet manually, and there may be verification problems during the access, and the system needs to be verified
When using requests to access the page to obtain data, try to sleep for a long time. Frequent operations will block the IP
Finally, if you are interested in crawler projects, you can browse to my home page, and have updated several reptiles. So the data source code is in the official account "Python", this source code gets the reply "hook" to get.

If you think this article is good, just like it 👍, This is the biggest support for original bloggers
Please indicate the source of reprint