1 Overview
This article mainly describes the similarities and differences between ArrayList and LinkedList, as well as their underlying implementation environment (OpenJDK 11.0.10).
2 difference between the two
Before introducing the underlying implementation of the two in detail, let's take a brief look at the similarities and differences between the two.
2.1 similarities
- Both implement the List interface and inherit AbstractList (LinkedList inherits indirectly and ArrayList inherits directly)
- Are thread unsafe
- Both have methods of adding, deleting, checking and modifying
2.2 differences
- The underlying data structures are different: ArrayList is based on Object [] array and LinkedList is based on LinkedList Node bidirectional linked list
- Random access efficiency is different: ArrayList random access can achieve O(1), because elements can be found directly through subscripts, while LinkedList needs to traverse from the pointer, with time O(n)
- Initialization operations are different: an initialization capacity needs to be specified during ArrayList initialization (the default is 10), while LinkedList does not
- Capacity expansion: when the length of ArrayList is not enough to accommodate new elements, it will be expanded, while LinkedList will not
3. ArrayList bottom layer
3.1 basic structure
The bottom layer is implemented by Object [] array, and the member variables are as follows:
private static final long serialVersionUID = 8683452581122892189L; private static final int DEFAULT_CAPACITY = 10; private static final Object[] EMPTY_ELEMENTDATA = new Object[0]; private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = new Object[0]; transient Object[] elementData; private int size; private static final int MAX_ARRAY_SIZE = 2147483639;
The default initialization capacity is 10, followed by two empty arrays for the default construction method and the construction method with initialization capacity:
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else {
if (initialCapacity != 0) {
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
}
this.elementData = EMPTY_ELEMENTDATA;
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
Let's look at some important methods, including:
- add()
- remove()
- indexOf()/lastIndexOf()/contains()
3.2 add()
The add() method has four:
- add(E e)
- add(int index,E e)
- addAll(Collection<? extends E> c)
- addAll(int index, Collection<? extends E> c
3.2.1 single element (add)
Let's take a look at add (E, e) and add(int index,E eelment):
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length) {
elementData = this.grow();
}
elementData[s] = e;
this.size = s + 1;
}
public boolean add(E e) {
++this.modCount;
this.add(e, this.elementData, this.size);
return true;
}
public void add(int index, E element) {
this.rangeCheckForAdd(index);
++this.modCount;
int s;
Object[] elementData;
if ((s = this.size) == (elementData = this.elementData).length) {
elementData = this.grow();
}
System.arraycopy(elementData, index, elementData, index + 1, s - index);
elementData[index] = element;
this.size = s + 1;
}
Add (E) actually calls a private method. After judging whether the capacity needs to be expanded, it is directly added to the end. add(int index,E element) will first check whether the subscript is legal, if it is legal, then determine whether the expansion is required, and then call System.. Arraycopy copies the array, and finally assigns a value and increases the length by 1.
About system Arraycopy, the official documents are as follows:
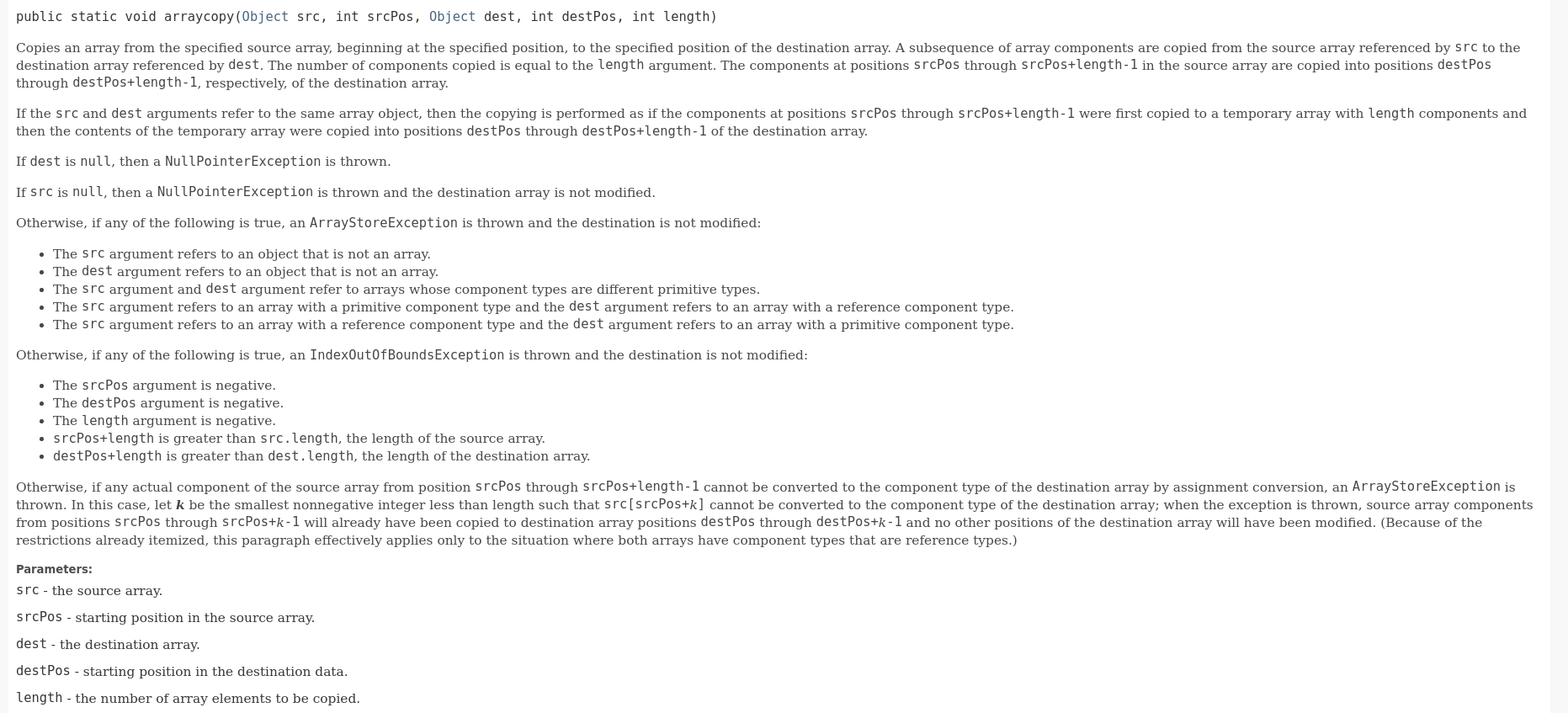
There are five parameters:
- First parameter: original array
- The second parameter: the position where the original array needs to be copied
- Third parameter: target array
- The fourth parameter: copy to the beginning of the target array
- The fifth parameter: the number of copies required
in other words:
System.arraycopy(elementData, index, elementData, index + 1, s - index);
The function of is to "move back" the elements of the original array after the index, leaving a place for the index to insert.
3.2.2 addAll()
Let's look at two addAll():
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
++this.modCount;
int numNew = a.length;
if (numNew == 0) {
return false;
} else {
Object[] elementData;
int s;
if (numNew > (elementData = this.elementData).length - (s = this.size)) {
elementData = this.grow(s + numNew);
}
System.arraycopy(a, 0, elementData, s, numNew);
this.size = s + numNew;
return true;
}
}
public boolean addAll(int index, Collection<? extends E> c) {
this.rangeCheckForAdd(index);
Object[] a = c.toArray();
++this.modCount;
int numNew = a.length;
if (numNew == 0) {
return false;
} else {
Object[] elementData;
int s;
if (numNew > (elementData = this.elementData).length - (s = this.size)) {
elementData = this.grow(s + numNew);
}
int numMoved = s - index;
if (numMoved > 0) {
System.arraycopy(elementData, index, elementData, index + numNew, numMoved);
}
System.arraycopy(a, 0, elementData, index, numNew);
this.size = s + numNew;
return true;
}
}
In the first addAll, first judge whether to expand the capacity, and then directly call the target set to add it to the tail. In the second addAll, due to the addition of a subscript parameter, the processing steps are a little more:
- First, judge whether the subscript is legal
- Then judge whether the capacity needs to be expanded
- Then calculate whether the original array element needs to be "moved back", that is, the system in if arraycopy
- Finally, copy the target array to the specified index position
3.2.3 capacity expansion
The above add() method involves capacity expansion, that is, the grow method. Let's take a look:
private Object[] grow(int minCapacity) {
return this.elementData = Arrays.copyOf(this.elementData, this.newCapacity(minCapacity));
}
private Object[] grow() {
return this.grow(this.size + 1);
}
private int newCapacity(int minCapacity) {
int oldCapacity = this.elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (this.elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(10, minCapacity);
} else if (minCapacity < 0) {
throw new OutOfMemoryError();
} else {
return minCapacity;
}
} else {
return newCapacity - 2147483639 <= 0 ? newCapacity : hugeCapacity(minCapacity);
}
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) {
throw new OutOfMemoryError();
} else {
return minCapacity > 2147483639 ? 2147483647 : 2147483639;
}
}
Growth () first calculates the capacity to be expanded through newCapacity, and then calls arrays Copyof copies the old element and overwrites the return value to the original array. In newCapacity, there are two variables:
- newCapacity: the new capacity is 1.5 times of the old capacity by default, that is, the default capacity expansion is 1.5 times
- minCapacity: minimum required capacity
If the minimum capacity is greater than or equal to the new capacity, it is one of the following:
- Array initialized by default Construction: returns the maximum value of minCapacity and 10
- Overflow: throw OOM directly
- Otherwise, the minimum capacity value is returned
If not, judge whether the new capacity reaches the maximum value (I'm a little curious about why MAX_ARRAY_SIZE is not used here. I guess it's a decompilation problem). If the maximum value is not reached, return the new capacity. If the maximum value is reached, call hugeCapacity.
hugeCapacity will also first judge whether the minimum capacity is less than 0. If it is less than 0, throw OOM. Otherwise, judge it with the maximum value (MAX_ARRAY_SIZE). If it is greater than 0, return integer MAX_ Value, otherwise Max is returned_ ARRAY_ SIZE.
3.3 remove()
remove() contains four methods:
- remove(int index)
- remove(Object o)
- removeAll()
- removeIf()
3.3.1 single element remove()
That is, remove(int index) and remove(Object o):
public E remove(int index) {
Objects.checkIndex(index, this.size);
Object[] es = this.elementData;
E oldValue = es[index];
this.fastRemove(es, index);
return oldValue;
}
public boolean remove(Object o) {
Object[] es = this.elementData;
int size = this.size;
int i = 0;
if (o == null) {
while(true) {
if (i >= size) {
return false;
}
if (es[i] == null) {
break;
}
++i;
}
} else {
while(true) {
if (i >= size) {
return false;
}
if (o.equals(es[i])) {
break;
}
++i;
}
}
this.fastRemove(es, i);
return true;
}
The logic of remove(int index) is relatively simple. First check the validity of the subscript, then save the value to be removed, and call fastRemove() to remove it. In remove(Object o), directly traverse the array and judge whether there are corresponding elements. If there are no elements, directly return false. If there are, call fastRemove() and return true.
Let's take a look at fastRemove():
private void fastRemove(Object[] es, int i) {
++this.modCount;
int newSize;
if ((newSize = this.size - 1) > i) {
System.arraycopy(es, i + 1, es, i, newSize - i);
}
es[this.size = newSize] = null;
}
First, increase the number of modifications by 1, then reduce the length of the array by 1, and judge whether the new length is the last one. If it is the last one, it does not need to be moved. If not, call system Arraycopy "moves" the array forward by 1 bit, and finally sets an extra value at the end to null.
3.3.2 removeAll()
public boolean removeAll(Collection<?> c) {
return this.batchRemove(c, false, 0, this.size);
}
boolean batchRemove(Collection<?> c, boolean complement, int from, int end) {
Objects.requireNonNull(c);
Object[] es = this.elementData;
for(int r = from; r != end; ++r) {
if (c.contains(es[r]) != complement) {
int w = r++;
try {
for(; r < end; ++r) {
Object e;
if (c.contains(e = es[r]) == complement) {
es[w++] = e;
}
}
} catch (Throwable var12) {
System.arraycopy(es, r, es, w, end - r);
w += end - r;
throw var12;
} finally {
this.modCount += end - w;
this.shiftTailOverGap(es, w, end);
}
return true;
}
}
return false;
}
removeAll actually calls batchRemove(). In batchRemove(), there are four parameters with the following meanings:
- Collection<?> c: Target set
- Boolean complexity: if the value is true, it means to retain the elements contained in the target set c in the array. If it is false, it means to delete the elements contained in the target set c in the array
- from/end: interval range, left closed and right open
Therefore, the passed (c,false,0,this.size) means to delete the elements in the target set c in the array. The following steps are briefly described:
- First, judge the empty space
- Then find the first element that meets the requirements (here is the first element to be deleted)
- After finding, continue to search backward from this element, and record the subscript w of the last element in the deleted array
- try/catch is a kind of protective behavior, because contains() will use Iterator in the implementation of AbstractCollection. Here, system. Is still called after catch exception Arraycopy, so that the elements that have been processed are "moved" to the front
- Finally, the number of modifications will be increased and shiftTailOverGap will be called. This method will be explained in detail later
3.3.3 removeIf()
public boolean removeIf(Predicate<? super E> filter) {
return this.removeIf(filter, 0, this.size);
}
boolean removeIf(Predicate<? super E> filter, int i, int end) {
Objects.requireNonNull(filter);
int expectedModCount = this.modCount;
Object[] es;
for(es = this.elementData; i < end && !filter.test(elementAt(es, i)); ++i) {
}
if (i < end) {
int beg = i;
long[] deathRow = nBits(end - i);
deathRow[0] = 1L;
++i;
for(; i < end; ++i) {
if (filter.test(elementAt(es, i))) {
setBit(deathRow, i - beg);
}
}
if (this.modCount != expectedModCount) {
throw new ConcurrentModificationException();
} else {
++this.modCount;
int w = beg;
for(i = beg; i < end; ++i) {
if (isClear(deathRow, i - beg)) {
es[w++] = es[i];
}
}
this.shiftTailOverGap(es, w, end);
return true;
}
} else if (this.modCount != expectedModCount) {
throw new ConcurrentModificationException();
} else {
return false;
}
}
In removeIf, to delete a qualified element, empty judgment will be performed first, and then the subscript of the first qualified element will be found. If it cannot be found (I > = end), judge whether there is a concurrent operation problem. If not, return false. If I < end, the deletion process will be officially entered:
- Record start subscript beg
- Deatherow is a tag array with a length of (end-i-1) > > 6 + 1. Starting from beg, if a qualified element is encountered, the subscript will be marked (call setBit)
- The so-called deletion is actually to move the unqualified elements one by one to the position after the beg
- Call shiftTailOverGap to process the element at the end
- Returns true, indicating that there are qualified elements and the deletion operation has been performed
3.3.4 shiftTailOverGap()
removeAll() and removeIf() above both involve shiftTailOverGap(). Let's take a look at the implementation:
private void shiftTailOverGap(Object[] es, int lo, int hi) {
System.arraycopy(es, hi, es, lo, this.size - hi);
int to = this.size;
for(int i = this.size -= hi - lo; i < to; ++i) {
es[i] = null;
}
}
This method moves the elements in the es array forward by hi Lo bit, and sets the extra elements at the end to null.
3.4 indexOf() series
include:
- indexOf()
- lastIndexOf()
- contains()
3.4.1 indexOf
public int indexOf(Object o) {
return this.indexOfRange(o, 0, this.size);
}
int indexOfRange(Object o, int start, int end) {
Object[] es = this.elementData;
int i;
if (o == null) {
for(i = start; i < end; ++i) {
if (es[i] == null) {
return i;
}
}
} else {
for(i = start; i < end; ++i) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
indexOf() is actually a packaged method, which will call the internal indexOfRange() to search. The logic is very simple. First, judge whether the value to be searched is empty. If it is not empty, use equals() to judge. Otherwise, use = = to judge. If found, return the subscript, otherwise return - 1.
3.4.2 contains()
contains() is actually the package of indexOf():
public boolean contains(Object o) {
return this.indexOf(o) >= 0;
}
Call indexOf() method to judge whether it is greater than or equal to 0 according to the returned subscript. If yes, it returns existence; otherwise, it returns nonexistence.
3.4.3 lastIndexOf()
The implementation of lastIndexOf() is similar to indexOf(), except that it starts from the tail and calls lastIndexOfRange():
public int lastIndexOf(Object o) {
return this.lastIndexOfRange(o, 0, this.size);
}
int lastIndexOfRange(Object o, int start, int end) {
Object[] es = this.elementData;
int i;
if (o == null) {
for(i = end - 1; i >= start; --i) {
if (es[i] == null) {
return i;
}
}
} else {
for(i = end - 1; i >= start; --i) {
if (o.equals(es[i])) {
return i;
}
}
}
return -1;
}
4 LinkedList bottom layer
4.1 basic structure
First, let's take a look at the member variables:
transient int size; transient LinkedList.Node<E> first; transient LinkedList.Node<E> last; private static final long serialVersionUID = 876323262645176354L;
One represents the length, a head pointer and a tail pointer.
Where LinkedList Node implementation is as follows:
private static class Node<E> {
E item;
LinkedList.Node<E> next;
LinkedList.Node<E> prev;
Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
You can see that LinkedList is actually implemented based on double linked list.
Let's look at some important methods, including:
- add()
- remove()
- get()
4.2 add()
The add() method includes six steps:
- add(E e)
- add(int index,E e)
- addFirst(E e)
- addLast(E e)
- addAll(Collection<? extends E> c)
- addAll(int index, Collection<? extends E> c)
4.2.1 add() implemented by linkfirst / linklast / linkbefore
Let's take a look at the four relatively simple add():
public void addFirst(E e) {
this.linkFirst(e);
}
public void addLast(E e) {
this.linkLast(e);
}
public boolean add(E e) {
this.linkLast(e);
return true;
}
public void add(int index, E element) {
this.checkPositionIndex(index);
if (index == this.size) {
this.linkLast(element);
} else {
this.linkBefore(element, this.node(index));
}
}
It can be seen that the above four add() operations do not add elements. Add() is just the encapsulation of adding elements. The methods that really implement the add operation are linkLast(), linkFirst() and linkBefore(). As the name suggests, these methods link elements to the end or head of the linked list, or to the front of a node of the linked list:
void linkLast(E e) {
LinkedList.Node<E> l = this.last;
LinkedList.Node<E> newNode = new LinkedList.Node(l, e, (LinkedList.Node)null);
this.last = newNode;
if (l == null) {
this.first = newNode;
} else {
l.next = newNode;
}
++this.size;
++this.modCount;
}
private void linkFirst(E e) {
LinkedList.Node<E> f = this.first;
LinkedList.Node<E> newNode = new LinkedList.Node((LinkedList.Node)null, e, f);
this.first = newNode;
if (f == null) {
this.last = newNode;
} else {
f.prev = newNode;
}
++this.size;
++this.modCount;
}
void linkBefore(E e, LinkedList.Node<E> succ) {
LinkedList.Node<E> pred = succ.prev;
LinkedList.Node<E> newNode = new LinkedList.Node(pred, e, succ);
succ.prev = newNode;
if (pred == null) {
this.first = newNode;
} else {
pred.next = newNode;
}
++this.size;
++this.modCount;
}
The implementation is basically the same, one is to add to the tail, one is to add the head, and one is to insert to the front. In addition, the three methods have the following operations at the end of the method:
++this.size; ++this.modCount;
The first represents the number of nodes plus 1, while the second represents the number of modifications to the linked list plus 1.
For example, at the end of the unliklast method, there is the following code:
--this.size; ++this.modCount;
Unliklast operation is to remove the last node. When the number of nodes is reduced by 1, the number of modifications to the linked list is increased by 1.
On the other hand, generally speaking, the linked list insertion operation needs to find the location of the linked list, but in the three link methods, there is no code for the for loop to find the insertion location. Why?
Because the head and tail pointers are saved, linkFirst() and linkLast() do not need to traverse to find the insertion position, but for linkBefore(), they need to find the insertion position. However, linkBefore() has no parameters such as "insertion position / insertion subscript", but only one element value and one subsequent node. In other words, this successor node is the insertion position obtained through the loop. For example, the calling code is as follows:
this.linkBefore(element, this.node(index));
You can see in this In node (), a subscript is passed in and a subsequent node is returned, that is, the traversal operation is completed in this method:
LinkedList.Node<E> node(int index) {
LinkedList.Node x;
int i;
if (index < this.size >> 1) {
x = this.first;
for(i = 0; i < index; ++i) {
x = x.next;
}
return x;
} else {
x = this.last;
for(i = this.size - 1; i > index; --i) {
x = x.prev;
}
return x;
}
}
Here, first judge which side the subscript is on. If it is close to the head, traverse backward from the head pointer. If it is close to the tail, traverse backward from the tail pointer.
4.2.2 addAll() of traversal implementation
public boolean addAll(Collection<? extends E> c) {
return this.addAll(this.size, c);
}
public boolean addAll(int index, Collection<? extends E> c) {
this.checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0) {
return false;
} else {
LinkedList.Node pred;
LinkedList.Node succ;
if (index == this.size) {
succ = null;
pred = this.last;
} else {
succ = this.node(index);
pred = succ.prev;
}
Object[] var7 = a;
int var8 = a.length;
for(int var9 = 0; var9 < var8; ++var9) {
Object o = var7[var9];
LinkedList.Node<E> newNode = new LinkedList.Node(pred, o, (LinkedList.Node)null);
if (pred == null) {
this.first = newNode;
} else {
pred.next = newNode;
}
pred = newNode;
}
if (succ == null) {
this.last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
this.size += numNew;
++this.modCount;
return true;
}
}
First, you can see that the two addAll actually call the same method. The steps are as follows:
- First, judge whether the subscript is legal through checkPositionIndex
- Then convert the target set into an Object [] array
- Perform some special judgment processing to determine whether the index range is inserted in the middle or at the end
- The for loop traverses the target array and inserts it into the linked list
- Modify the node length and return
4.3 remove()
Similar to add(), remove includes:
- remove()
- remove(int index)
- remove(Object o)
- removeFirst()
- removeLast()
- removeFirstOccurrence(Object o)
- removeLastOccurrence(Object o)
Of course, there are actually two removeAll and removeIf, but they are actually the methods of the parent class, which will not be analyzed here.
4.3.1 remove() implemented by unlinkfirst() / unlinklast()
Remove(), removeFirst(), removeLast() are actually deleted by calling unlikfirst() / unliklast(), where remove() is only an alias of removeFirst():
public E remove() {
return this.removeFirst();
}
public E removeFirst() {
LinkedList.Node<E> f = this.first;
if (f == null) {
throw new NoSuchElementException();
} else {
return this.unlinkFirst(f);
}
}
public E removeLast() {
LinkedList.Node<E> l = this.last;
if (l == null) {
throw new NoSuchElementException();
} else {
return this.unlinkLast(l);
}
}
The logic is very simple. After the sentence is empty, call unlinkFirst()/unlinkLast():
private E unlinkFirst(LinkedList.Node<E> f) {
E element = f.item;
LinkedList.Node<E> next = f.next;
f.item = null;
f.next = null;
this.first = next;
if (next == null) {
this.last = null;
} else {
next.prev = null;
}
--this.size;
++this.modCount;
return element;
}
private E unlinkLast(LinkedList.Node<E> l) {
E element = l.item;
LinkedList.Node<E> prev = l.prev;
l.item = null;
l.prev = null;
this.last = prev;
if (prev == null) {
this.first = null;
} else {
prev.next = null;
}
--this.size;
++this.modCount;
return element;
}
In these two unlink s, since the positions of the head pointer and tail pointer have been saved, they can be removed directly in O(1). Finally, reduce the node length by 1, increase the number of modifications by 1, and return the old element.
4.3.2 remove() implemented by unlink()
Take another look at remove(int index), remove(Object o), removeFirstOccurrence(Object o), removeLastOccurrence(Object o):
public E remove(int index) {
this.checkElementIndex(index);
return this.unlink(this.node(index));
}
public boolean remove(Object o) {
LinkedList.Node x;
if (o == null) {
for(x = this.first; x != null; x = x.next) {
if (x.item == null) {
this.unlink(x);
return true;
}
}
} else {
for(x = this.first; x != null; x = x.next) {
if (o.equals(x.item)) {
this.unlink(x);
return true;
}
}
}
return false;
}
public boolean removeFirstOccurrence(Object o) {
return this.remove(o);
}
public boolean removeLastOccurrence(Object o) {
LinkedList.Node x;
if (o == null) {
for(x = this.last; x != null; x = x.prev) {
if (x.item == null) {
this.unlink(x);
return true;
}
}
} else {
for(x = this.last; x != null; x = x.prev) {
if (o.equals(x.item)) {
this.unlink(x);
return true;
}
}
}
return false;
}
These methods actually call unlink to remove elements. removeFirstOccurrence(Object o) is equivalent to remove(Object o). Let's talk about remove(int index). The logic of this method is relatively simple. First check the validity of the subscript, and then find the node through the subscript and unlink.
In remove(Object o), you need to first judge whether the value of the element is null. In fact, the effect of the two loops is equivalent, and the first element with the same target value will be removed. In removeLastOccurrence(Object o), the code is basically the same, except that remove(Object o) traverses from the beginning pointer, while removeLastOccurrence(Object o) traverses from the end pointer.
As you can see, these remove methods actually locate the nodes to be deleted, and finally call unlink() to delete them. Let's take a look at unlink():
E unlink(LinkedList.Node<E> x) {
E element = x.item;
LinkedList.Node<E> next = x.next;
LinkedList.Node<E> prev = x.prev;
if (prev == null) {
this.first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
this.last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
--this.size;
++this.modCount;
return element;
}
The implementation logic is similar to unlinkFirst()/unlinkLast(). It is deleted in O(1), which is just some simple special judgment operations. Finally, reduce the node length by 1, increase the modification times by 1, and finally return the old value.
4.4 get()
The get method is relatively simple and provides three external functions:
- get(int index)
- getFirst()
- getLast()
Because getFirst() and getLast() save the head and tail pointers, after special judgment, they will directly return to O(1):
public E getFirst() {
LinkedList.Node<E> f = this.first;
if (f == null) {
throw new NoSuchElementException();
} else {
return f.item;
}
}
public E getLast() {
LinkedList.Node<E> l = this.last;
if (l == null) {
throw new NoSuchElementException();
} else {
return l.item;
}
}
And get(int index) undoubtedly needs O(n) time:
public E get(int index) {
this.checkElementIndex(index);
return this.node(index).item;
}
get(int index) after judging the subscript, the actual operation is this Node (), because this method finds the corresponding node through the subscript, which is also written in the front of the source code, so it will not be analyzed here. It takes O(n) time.
5 Summary
- ArrayList is implemented based on Object [] and LinkedList is implemented based on double linked list
- The random access efficiency of ArrayList is higher than that of LinkedList
- LinkedList provides more insertion methods than ArrayList, and the head and tail insertion efficiency is higher than ArrayList
- The two methods of deleting elements are not exactly the same. ArrayList provides unique removeIf(), while LinkedList provides unique removeFirstOccurrence() and removeLastOccurrence()
- The get() method of ArrayList is always O(1), while only getFirst()/getLast() of LinkedList is O(1)
- The two core methods in ArrayList are growth () and system Arraycopy, the former is the capacity expansion method, which defaults to 1.5 times the capacity expansion, and the latter is the copy array method, which is a native method, which needs to be used for insertion, deletion and other operations
- Many methods in LinkedList require special judgment on the head and tail. It is simpler to create than ArrayList without initialization and does not involve capacity expansion
Appendix 6: an experiment on insertion and deletion
As for insertion and deletion, LinkedList is generally considered to be more efficient than ArrayList, but this is not the case. Here is a small experiment to test the insertion and deletion time.
Relevant instructions:
- Test times: 1000 times
- Array length: 4000, 40w, 4000w
- Test array: randomly generated
- Insert and delete subscripts: randomly generated
- Result value: average time of 1000 inserts and deletions
code:
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Main {
public static void main(String[] args){
int len = 40_0000;
Random random = new Random();
List<Integer> list = Stream.generate(random::nextInt).limit(len).collect(Collectors.toList());
LinkedList<Integer> linkedList = new LinkedList<>(list);
ArrayList<Integer> arrayList = new ArrayList<>(list);
long start;
long end;
double linkedListTotalInsertTime = 0.0;
double arrayListTotalInsertTime = 0.0;
int testTimes = 1000;
for (int i = 0; i < testTimes; i++) {
int index = random.nextInt(len);
int element = random.nextInt();
start = System.nanoTime();
linkedList.add(index,element);
end = System.nanoTime();
linkedListTotalInsertTime += (end-start);
start = System.nanoTime();
arrayList.add(index,element);
end = System.nanoTime();
arrayListTotalInsertTime += (end-start);
}
System.out.println("LinkedList average insert time:"+linkedListTotalInsertTime/testTimes+" ns");
System.out.println("ArrayList average insert time:"+arrayListTotalInsertTime/testTimes + " ns");
linkedListTotalInsertTime = arrayListTotalInsertTime = 0.0;
for (int i = 0; i < testTimes; i++) {
int index = random.nextInt(len);
start = System.nanoTime();
linkedList.remove(index);
end = System.nanoTime();
linkedListTotalInsertTime += (end-start);
start = System.nanoTime();
arrayList.remove(index);
end = System.nanoTime();
arrayListTotalInsertTime += (end-start);
}
System.out.println("LinkedList average delete time:"+linkedListTotalInsertTime/testTimes+" ns");
System.out.println("ArrayList average delete time:"+arrayListTotalInsertTime/testTimes + " ns");
}
}
When the array length is 4000, the output is as follows:
LinkedList average insert time:4829.938 ns ArrayList average insert time:745.529 ns LinkedList average delete time:3142.988 ns ArrayList average delete time:1703.76 ns
When the array length is 40w (parameters - Xmx512m -Xms512m), the output is as follows:
LinkedList average insert time:126620.38 ns ArrayList average insert time:25955.014 ns LinkedList average delete time:119281.413 ns ArrayList average delete time:25435.593 ns
Adjust the array length to 4000w (parameter - Xmx16g -Xms16g), and the time is as follows:
LinkedList average insert time:5.6048377238E7 ns ArrayList average insert time:2.5303627956E7 ns LinkedList average delete time:5.4753230158E7 ns ArrayList average delete time:2.5912990133E7 ns
Although this experiment has some limitations, it also proves that the insertion and deletion performance of ArrayList is no worse than that of LinkedList. In fact, from the source code (see the analysis below), we can know that the main time-consuming of ArrayList insertion and deletion is system Arraycopy, and LinkedList mainly takes this Node (), in fact, both require O(n) time.
As for why the insertion and deletion speed of ArrayList is faster than LinkedList, the author guesses that it is system Arraycopy is faster than the for loop traversal in LinkedList, because the insertion / deletion location in LinkedList is found through this Node (), and this method is implemented using a simple for loop (of course, the bottom layer first judges which side it is on. If it is close to the head, it will traverse from the head, and if it is close to the tail, it will traverse from the tail). Relative to system Arraycopy's native C + + method implementation may be slower than C + +, resulting in speed differences.