1. Type problem
When you create an index directly, the default type is set to_ doc.
You can also use put below to specify the type, and then delete this document. Hehe. Does it implement an empty and typed index
PUT / index name / type name (can not be directly replaced by _doclater) / document id
{
Request body
}
2. Field type in document
es automatically specifies the type according to the inserted data by default. Most of them are:
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}In fact, two types of are created. text and keyword. When you need to use keyword, you need to use name keyword.
Of course, you can also define the type directly when creating the index.
PUT /lala
{
"mappings":{
"properties":{
"name":{
"type":"text"
},
"age":{
"type":"long"
},
"birthday":{
"type":"date"
}
}
}
}text type
1:Support word segmentation and full-text retrieval,Support fuzzy and accurate query,Aggregation is not supported,Sort operation; 2:test The maximum supported character length of type is unlimited,Suitable for large field storage; Usage scenario: Storing full-text search data, for example: Email content, address, code block, blog post content, etc. Default combination standard analyzer(Standard parser)Word segmentation and inverted indexing of text. By default, the standard analyzer is used to score word hit and word frequency correlation.
keyword
1:Direct indexing without word segmentation,Support fuzzy, precise matching, aggregation and sorting operations. 2:keyword The maximum supported length of type is - 32766 UTF-8 Characters of type,You can set ignore_above Specify the length of self-contained characters. Data exceeding the given length will not be indexed and cannot be passed term Exact match retrieval returns results. Usage scenario: Store mailbox number url,name,title,Mobile phone number, host name, status code, postal code, label, age, gender and other data. Used to filter data(for example: select * from x where status='open'),Sorting and aggregation(Statistics). Save the complete text directly to the inverted index. That is, it will not"I am Chinese,"This field is divided into"I","yes","I am","China".... But directly"I am Chinese,"This field is saved in the inverted index.
common problem
When using API to query, when using text and keyword to query the same type respectively, the results are also different.
//The data in name is "when I am Chinese"
//The wildcardQuery here supports wildcards
BoolQueryBuilder builder = QueryBuilders.boolQuery();
builder.must(QueryBuilders.wildcardQuery("name.keyword","*I am*"));
builder.must(QueryBuilders.wildcardQuery("name","*I am*"));For example, the Fuzzy Lookup above. See API usage in the directory for specific methods.
builder.must(QueryBuilders.wildcardQuery("name","*I am*"));
When just using name Time,When performing fuzzy query,When making the above query,No data will be queried.
When modified to:
builder.must(QueryBuilders.wildcardQuery("name","*yes*"));
You can query the data. Because direct use name It will be used by default text Type.
Will data ik_max_word Perform maximum word segmentation. Therefore, only multiple data of one word can be obtained. Therefore, only one word can obtain data when querying.And use keyword:
builder.must(QueryBuilders.wildcardQuery("name.keyword","*I am*"));
No matter how many data are placed in the wildcard,The corresponding data will be queried.
because keword The data will not be segmented.
The complete data is always used to match some of the fields we query.There are also text and keyword problems in other methods. Remember to pay attention!
3. Port problem
We will find that when ElasticSearch starts, it will occupy two ports 9200 and 9300. Their specific roles are as follows:
9200 is the port used by ES node for external communication. It is the RESTful interface of http protocol
Through port 9200, elasticsearch itself can be accessed through http protocol. It has its own restful access mode. Other languages and direct test access are accessed through port 9200
9300 is the port used for communication between ES nodes. It is a tcp communication port, which is used by both clusters and tcpclients.
Through port 9300, port 9300 is open to java api to access calls, and only to java to access through specific client s
To sum up, 9300 is used to integrate elasticsearch in java projects, and 9200 is used in other cases
4. Paging problem
Solve the problem that only 10000 pieces of data can be returned from size.
PUT _all/_settings
{"max_result_window":"1000000000"}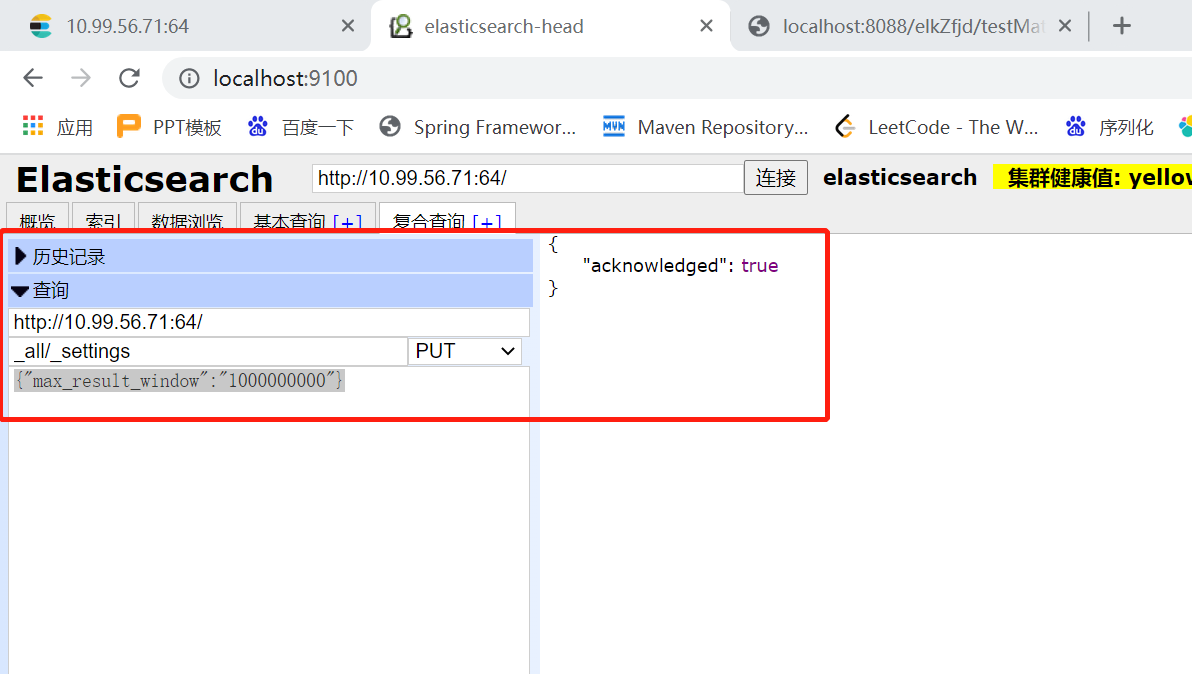
Of course, if there is a large amount of data, using the above methods will slow down the retrieval speed of es index library.
The maximum value set can only be 1000000000. Otherwise, an error will be reported.