[source code analysis] NVIDIA HugeCTR, GPU version parameter server -- (9) -- local hash table
0x00 summary
In this series, we introduce HugeCTR, an industry-oriented recommendation system training framework, which is optimized for large-scale CTR models with model parallel embedding and data parallel intensive networks. This article introduces the backward operation of localized slotsparseembeddinghash.
Which draws lessons from HugeCTR source code reading Thank you for this masterpiece.
Other articles in this series are as follows:
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- (1)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- - (2)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- - (3)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server -- - (4)
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (5) embedded hash table
[Source code analysis] NVIDIA HugeCTR, GPU version parameter server - (6) -- distributed hash table
0x01 previous review
From the previous analysis, we can see that the overall process of an embedded table lookup is as follows.
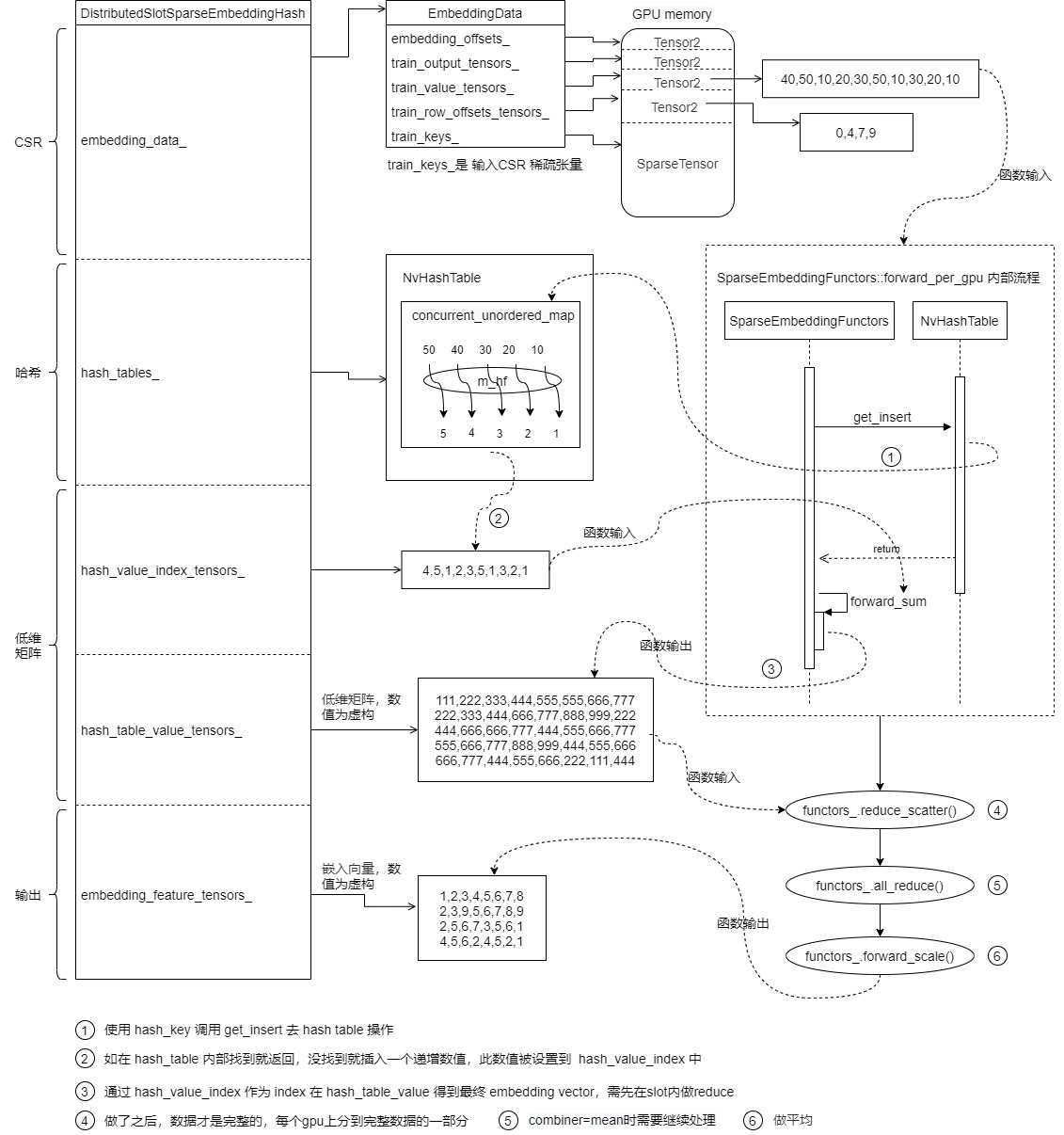
0x02 definition
The LocalizedSlotSparseEmbeddingHash class inherits from the Embedding class, which is the base class that implements all embedded layers. In the LocalizedSlotSparseEmbeddingHash class, some slots in the embedded table are assigned to a single GPU, called localized slots. For example, slot 0 on GPU-0, slot 1 on GPU-1, slot 2 on GPU-0, slot 3 on GPU-1, etc. In contrast, some of the slots in the DistributedSlotSparseEmbeddingHash are allocated to multiple GPUs.
The embedded table is encapsulated in a hash table. The key in the hash table is called hash_table_key, the value in the hash table is called hash_table_value_index indicates the row number of the embedding feature in the embedding table. The embedding feature is called hash_table_value.
LocalizedSlotSparseEmbeddingHash implements all the operations required for the training process of the embedded layer, including forward propagation and backward propagation. Forward propagation corresponds to API forward. The API of back propagation is divided into two stages: backward and update_params. This class also provides the operation of uploading the hash table (including hash table key, hash table value index and hash table value) from the host file to the GPU (named load_parameters) and downloading the hash table from the GPU to the host file (named dump_parameters).
template <typename TypeHashKey, typename TypeEmbeddingComp>
class LocalizedSlotSparseEmbeddingHash : public IEmbedding {
using NvHashTable = HashTable<TypeHashKey, size_t>;
private:
EmbeddingData<TypeHashKey, TypeEmbeddingComp> embedding_data_;
std::vector<LocalizedFilterKeyStorage<TypeHashKey>> filter_keys_storages_;
std::vector<std::shared_ptr<NvHashTable>> hash_tables_; /**< Hash table. */
// define tensors
Tensors2<float> hash_table_value_tensors_; /**< Hash table value. */
std::vector<Tensors2<float>> value_table_tensors_;
Tensors2<size_t> hash_table_slot_id_tensors_; /**< the tensors for storing slot ids */
Tensors2<size_t> hash_value_index_tensors_; /**< Hash value index. The index is corresponding to
the line number of the value. */
Tensors2<TypeEmbeddingComp>
embedding_feature_tensors_; /**< the output tensor of the forward(). */
Tensors2<TypeEmbeddingComp> wgrad_tensors_; /**< the input tensor of the backward(). */
std::vector<EmbeddingOptimizer<TypeHashKey, TypeEmbeddingComp>> embedding_optimizers_;
size_t max_vocabulary_size_;
size_t max_vocabulary_size_per_gpu_; /**< Max vocabulary size for each GPU. */
std::vector<size_t> slot_num_per_gpu_; /* slot_num per GPU */
std::vector<size_t> slot_size_array_;
SparseEmbeddingFunctors functors_;
Tensors2<TypeEmbeddingComp> all2all_tensors_; /**< the temple buffer to store all2all results */
Tensors2<TypeEmbeddingComp> utest_all2all_tensors_;
Tensors2<TypeEmbeddingComp> utest_reorder_tensors_;
Tensors2<TypeEmbeddingComp> utest_backward_temp_tensors_;
Tensors2<TypeEmbeddingComp> utest_forward_temp_tensors_;
}
0x03 build
3.1 call
In HugeCTR/src/parsers/create_embedding.cpp contains the following calls:
case Embedding_t::LocalizedSlotSparseEmbeddingHash: {
const SparseEmbeddingHashParams embedding_params = {batch_size,
batch_size_eval,
max_vocabulary_size_per_gpu,
slot_size_array,
embedding_vec_size,
sparse_input.max_feature_num_per_sample,
sparse_input.slot_num,
combiner, // combiner: 0-sum, 1-mean
embedding_opt_params};
embeddings.emplace_back(new LocalizedSlotSparseEmbeddingHash<TypeKey, TypeFP>(
sparse_input.train_sparse_tensors, sparse_input.evaluate_sparse_tensors, embedding_params,
resource_manager));
break;
}
3.2 constructor
The constructor of LocalizedSlotSparseEmbeddingHash is as follows. For the specific logic, see the notes below.
template <typename TypeHashKey, typename TypeEmbeddingComp>
LocalizedSlotSparseEmbeddingHash<TypeHashKey, TypeEmbeddingComp>::LocalizedSlotSparseEmbeddingHash(
const SparseTensors<TypeHashKey> &train_keys, const SparseTensors<TypeHashKey> &evaluate_keys,
const SparseEmbeddingHashParams &embedding_params,
const std::shared_ptr<ResourceManager> &resource_manager)
: embedding_data_(Embedding_t::LocalizedSlotSparseEmbeddingHash, train_keys, evaluate_keys,
embedding_params, resource_manager),
slot_size_array_(embedding_params.slot_size_array) {
try {
// Set the maximum amount of data per GPU
if (slot_size_array_.empty()) {
max_vocabulary_size_per_gpu_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu;
max_vocabulary_size_ = embedding_data_.embedding_params_.max_vocabulary_size_per_gpu *
embedding_data_.get_resource_manager().get_global_gpu_count();
} else {
max_vocabulary_size_per_gpu_ =
cal_max_voc_size_per_gpu(slot_size_array_, embedding_data_.get_resource_manager());
max_vocabulary_size_ = 0;
for (size_t slot_size : slot_size_array_) {
max_vocabulary_size_ += slot_size;
}
}
CudaDeviceContext context;
// Traverse local GPU
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
// Set current context
context.set_device(embedding_data_.get_local_gpu(id).get_device_id());
// Number of slot s per GPU
size_t gid = embedding_data_.get_local_gpu(id).get_global_id();
size_t slot_num_per_gpu =
embedding_data_.embedding_params_.slot_num /
embedding_data_.get_resource_manager().get_global_gpu_count() +
((gid < embedding_data_.embedding_params_.slot_num %
embedding_data_.get_resource_manager().get_global_gpu_count())
? 1
: 0);
slot_num_per_gpu_.push_back(slot_num_per_gpu);
// new GeneralBuffer objects
const std::shared_ptr<GeneralBuffer2<CudaAllocator>> &buf = embedding_data_.get_buffer(id);
embedding_optimizers_.emplace_back(max_vocabulary_size_per_gpu_,
embedding_data_.embedding_params_, buf);
// The next step is to allocate memory for various variables
// new hash table value vectors
if (slot_size_array_.empty()) {
Tensor2<float> tensor;
buf->reserve(
{max_vocabulary_size_per_gpu_, embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
hash_table_value_tensors_.push_back(tensor);
} else {
const std::shared_ptr<BufferBlock2<float>> &block = buf->create_block<float>();
Tensors2<float> tensors;
size_t vocabulary_size_in_current_gpu = 0;
for (size_t i = 0; i < slot_size_array_.size(); i++) {
if ((i % embedding_data_.get_resource_manager().get_global_gpu_count()) == gid) {
Tensor2<float> tensor;
block->reserve(
{slot_size_array_[i], embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
tensors.push_back(tensor);
vocabulary_size_in_current_gpu += slot_size_array_[i];
}
}
value_table_tensors_.push_back(tensors);
if (max_vocabulary_size_per_gpu_ > vocabulary_size_in_current_gpu) {
Tensor2<float> padding_tensor_for_optimizer;
block->reserve({max_vocabulary_size_per_gpu_ - vocabulary_size_in_current_gpu,
embedding_data_.embedding_params_.embedding_vec_size},
&padding_tensor_for_optimizer);
}
hash_table_value_tensors_.push_back(block->as_tensor());
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true),
embedding_data_.embedding_params_.max_feature_num},
&tensor);
embedding_data_.train_value_tensors_.push_back(tensor);
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(false),
embedding_data_.embedding_params_.max_feature_num},
&tensor);
embedding_data_.evaluate_value_tensors_.push_back(tensor);
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve(
{embedding_data_.embedding_params_.get_batch_size(true) * slot_num_per_gpu + 1},
&tensor);
embedding_data_.train_row_offsets_tensors_.push_back(tensor);
}
{
Tensor2<TypeHashKey> tensor;
buf->reserve(
{embedding_data_.embedding_params_.get_batch_size(false) * slot_num_per_gpu + 1},
&tensor);
embedding_data_.evaluate_row_offsets_tensors_.push_back(tensor);
}
{ embedding_data_.train_nnz_array_.push_back(std::make_shared<size_t>(0)); }
{ embedding_data_.evaluate_nnz_array_.push_back(std::make_shared<size_t>(0)); }
// new hash table value_index that get() from HashTable
{
Tensor2<size_t> tensor;
buf->reserve({1, embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num},
&tensor);
hash_value_index_tensors_.push_back(tensor);
}
// new embedding features reduced by hash table values(results of forward)
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve(
{embedding_data_.embedding_params_.get_universal_batch_size() * slot_num_per_gpu,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
embedding_feature_tensors_.push_back(tensor);
}
// new wgrad used by backward
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true) * slot_num_per_gpu,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
wgrad_tensors_.push_back(tensor);
}
// the tenosrs for storing slot ids
// TODO: init to -1 ?
{
Tensor2<size_t> tensor;
buf->reserve({max_vocabulary_size_per_gpu_, 1}, &tensor);
hash_table_slot_id_tensors_.push_back(tensor);
}
// temp tensors for all2all
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.get_universal_batch_size_per_gpu() *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
all2all_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_forward_temp_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.get_batch_size_per_gpu(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_all2all_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.get_batch_size_per_gpu(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_reorder_tensors_.push_back(tensor);
}
{
Tensor2<TypeEmbeddingComp> tensor;
buf->reserve({embedding_data_.embedding_params_.get_batch_size(true) *
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size},
&tensor);
utest_backward_temp_tensors_.push_back(tensor);
}
{
size_t max_nnz = embedding_data_.embedding_params_.get_universal_batch_size() *
embedding_data_.embedding_params_.max_feature_num;
size_t rowoffset_count = embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.get_universal_batch_size() +
1;
filter_keys_storages_.emplace_back(buf, max_nnz, rowoffset_count);
}
}
hash_tables_.resize(embedding_data_.get_resource_manager().get_local_gpu_count());
#pragma omp parallel for num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
// Initialize internal hash table
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
// construct HashTable object: used to store hash table <key, value_index>
hash_tables_[id].reset(new NvHashTable(max_vocabulary_size_per_gpu_));
embedding_data_.get_buffer(id)->allocate();
}
// Initialize optimizer
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); id++) {
context.set_device(embedding_data_.get_local_gpu(id).get_device_id());
embedding_optimizers_[id].initialize(embedding_data_.get_local_gpu(id));
} // end of for(int id = 0; id < embedding_data_.get_local_gpu_count(); id++)
if (!embedding_data_.embedding_params_.slot_size_array.empty()) {
std::vector<TypeHashKey> embedding_offsets;
TypeHashKey slot_sizes_prefix_sum = 0;
for (size_t i = 0; i < embedding_data_.embedding_params_.slot_size_array.size(); i++) {
embedding_offsets.push_back(slot_sizes_prefix_sum);
slot_sizes_prefix_sum += embedding_data_.embedding_params_.slot_size_array[i];
}
for (size_t id = 0; id < embedding_data_.get_resource_manager().get_local_gpu_count(); ++id) {
CudaDeviceContext context(embedding_data_.get_local_gpu(id).get_device_id());
CK_CUDA_THROW_(
cudaMemcpy(embedding_data_.embedding_offsets_[id].get_ptr(), embedding_offsets.data(),
embedding_offsets.size() * sizeof(TypeHashKey), cudaMemcpyHostToDevice));
}
}
// sync
functors_.sync_all_gpus(embedding_data_.get_resource_manager());
} catch (const std::runtime_error &rt_err) {
std::cerr << rt_err.what() << std::endl;
throw;
}
return;
}
3.3 how to determine a slot
Next, let's look at how to determine which GPU has which slot. In init_ Init_ is invoked in params. Embedding completes the build.
/**
* Initialize the embedding table
*/
void init_params() override {
// do hash table value initialization
if (slot_size_array_.empty()) { // if no slot_sizes provided, use the old method to init
init_embedding(max_vocabulary_size_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
hash_table_value_tensors_);
} else {
if (slot_size_array_.size() == embedding_data_.embedding_params_.slot_num) {
#ifndef DATA_READING_TEST
init_embedding(slot_size_array_, embedding_data_.embedding_params_.embedding_vec_size,
value_table_tensors_, hash_table_slot_id_tensors_);
#endif
} else {
throw std::runtime_error(
std::string("[HCDEBUG][ERROR] Runtime error: the size of slot_sizes != slot_num\n"));
}
}
}
init_embedding will create an embedded table on top of each GPU.
template <typename TypeHashKey, typename TypeEmbeddingComp>
void LocalizedSlotSparseEmbeddingHash<TypeHashKey, TypeEmbeddingComp>::init_embedding(
const std::vector<size_t> &slot_sizes, size_t embedding_vec_size,
std::vector<Tensors2<float>> &hash_table_value_tensors,
Tensors2<size_t> &hash_table_slot_id_tensors) {
// Get the number of GPUs on this node and the number of global GPUs
size_t local_gpu_count = embedding_data_.get_resource_manager().get_local_gpu_count();
size_t total_gpu_count = embedding_data_.get_resource_manager().get_global_gpu_count();
for (size_t id = 0; id < local_gpu_count; id++) { // Traverse local GPU
// global id is used here to set
size_t device_id = embedding_data_.get_local_gpu(id).get_device_id();
size_t global_id = embedding_data_.get_local_gpu(id).get_global_id();
functors_.init_embedding_per_gpu(global_id, total_gpu_count, slot_sizes, embedding_vec_size,
hash_table_value_tensors[id], hash_table_slot_id_tensors[id],
embedding_data_.get_local_gpu(id));
}
for (size_t id = 0; id < local_gpu_count; id++) {
CK_CUDA_THROW_(cudaStreamSynchronize(embedding_data_.get_local_gpu(id).get_stream()));
}
return;
}
Let's analyze init_embedding_per_gpu, in fact, is simply allocated with% operation. Give an example: if there are 10 slots and 3 GPUs, the slot ID is 0 ~ 9 and the GPU id is 0 ~ 2. 0 ~ 10% 3 = 0,1,2,0,1,2,0,1,2,0, so 10 slots are allocated to 3 GPUs:
-
GPU 0 : 0,3,6,9
-
GPU 1 : 1,4,7,
-
GPU 2 : 2,5,8,
Therefore, slot per gpu is not equal.
void SparseEmbeddingFunctors::init_embedding_per_gpu(size_t gid, size_t total_gpu_count,
const std::vector<size_t> &slot_sizes,
size_t embedding_vec_size,
Tensors2<float> &embedding_tables,
Tensor2<size_t> &slot_ids,
const GPUResource &gpu_resource) {
CudaDeviceContext context(gpu_resource.get_device_id());
size_t *slot_ids_ptr = slot_ids.get_ptr();
size_t key_offset = 0;
size_t value_index_offset = 0;
for (size_t i = 0, j = 0; i < slot_sizes.size(); i++) { // Traverse slot
size_t slot_size = slot_sizes[i];
if ((i % total_gpu_count) == gid) { // This GPU id
// The operation will continue only when i is equal to gid
float up_bound = sqrt(1.f / slot_size);
HugeCTR::UniformGenerator::fill(
embedding_tables[j++], -up_bound, up_bound, gpu_resource.get_sm_count(),
gpu_resource.get_replica_variant_curand_generator(), gpu_resource.get_stream());
// Configure slot id
memset_const(slot_ids_ptr, i, slot_size, gpu_resource.get_stream());
value_index_offset += slot_size;
slot_ids_ptr += slot_size;
}
key_offset += slot_size;
}
}
0x04 forward propagation
4.1 General
Let's first summarize the steps of forward communication:
-
First, use filter_keys_per_gpu configures EmbeddingData.
-
Second, use forward_per_gpu looks up from embedding, that is, call functions_ forward_ per_ The gpu performs a lookup operation from the hashmap of the gpu to obtain a dense vector.
-
Use all2all_forward allows each GPU to have all the data of all samples. The ultimate goal here is similar to dist's idea. There are only a few complete samples for each GPU, and the samples on different GPUs are different. Therefore, you need to copy the data of the current sample in other slots to this GPU. In other words, among the results of all2all, only other slots of the current sample are selected.
-
Use forward_reorder adjusts the internal order of the data of each GPU (which will be described in detail later).
-
Using store_slot_id stores the slot id. The reason to save the slot id corresponding to the parameter is that there are different slots on each GPU. Now all slots of a sample should be placed on the same GPU, so you need to know which slot to load when loading.
The specific codes are as follows:
/**
* The forward propagation of embedding layer.
*/
void forward(bool is_train, int eval_batch = -1) override {
#pragma omp parallel num_threads(embedding_data_.get_resource_manager().get_local_gpu_count())
{
size_t i = omp_get_thread_num();
CudaDeviceContext context(embedding_data_.get_local_gpu(i).get_device_id());
if (embedding_data_.embedding_params_.is_data_parallel) {
filter_keys_per_gpu(is_train, i, embedding_data_.get_local_gpu(i).get_global_id(),
embedding_data_.get_resource_manager().get_global_gpu_count());
}
functors_.forward_per_gpu(
embedding_data_.embedding_params_.get_batch_size(is_train), slot_num_per_gpu_[i],
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner, is_train,
embedding_data_.get_row_offsets_tensors(is_train)[i],
embedding_data_.get_value_tensors(is_train)[i],
*embedding_data_.get_nnz_array(is_train)[i], *hash_tables_[i],
hash_table_value_tensors_[i], hash_value_index_tensors_[i], embedding_feature_tensors_[i],
embedding_data_.get_local_gpu(i).get_stream());
}
// At this point, embedding_feature_tensors_ Inside is the embedding table. Inside is the embedding vector
// do all-to-all
#ifndef ENABLE_MPI
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_forward(embedding_data_.get_batch_size_per_gpu(is_train), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_feature_tensors_, all2all_tensors_,
embedding_data_.get_resource_manager());
} else {
CK_CUDA_THROW_(cudaMemcpyAsync(
all2all_tensors_[0].get_ptr(), embedding_feature_tensors_[0].get_ptr(),
embedding_data_.get_batch_size_per_gpu(is_train) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#else
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_forward(embedding_data_.get_batch_size_per_gpu(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_feature_tensors_, all2all_tensors_,
embedding_data_.get_resource_manager());
} else {
CK_CUDA_THROW_(cudaMemcpyAsync(
all2all_tensors_[0].get_ptr(), embedding_feature_tensors_[0].get_ptr(),
(size_t)embedding_data_.get_batch_size_per_gpu(is_train) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#endif
// reorder
functors_.forward_reorder(embedding_data_.get_batch_size_per_gpu(is_train),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
all2all_tensors_, embedding_data_.get_output_tensors(is_train),
embedding_data_.get_resource_manager());
// store slot ids
functors_.store_slot_id(embedding_data_.embedding_params_.get_batch_size(is_train),
embedding_data_.embedding_params_.slot_num, slot_num_per_gpu_,
embedding_data_.get_row_offsets_tensors(is_train),
hash_value_index_tensors_, hash_table_slot_id_tensors_,
embedding_data_.get_resource_manager());
return;
}
Let's take the following figure as an example. Here, we assume a total of 2 sample s and 4 slots. embedding_vec_size = 8,batch_size_per_gpu = 2. Here is an important place: how to determine which slot is on which GPU.
0 ~ 3% 2 = 0, 1, 0, 1, so 4 slot s are allocated to 2 GPU s:
- GPU 0 : slot 0,slot 2;
- GPU 1 : slot 1,slot 3;
It should be noted that the slot order here is not 1, 2, 3 and 4, which is why we need to reorder later. Because slots are not in simple ascending order, the following numerical allocation is not in simple ascending order, but:
-
GPU 0 : 1,3,5,7;
-
GPU 1 : 2,4,6,8;
Why is it distributed like this? It can be known after the end of the last forward propagation.
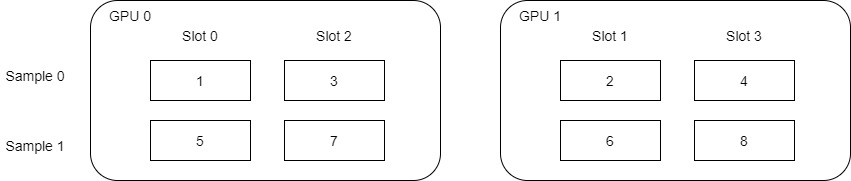
4.2 alltoall
Because forward_ per_ The GPU function has been introduced earlier, so let's look directly at the alltoall operation.
As we mentioned earlier, after each GPU obtains the dense vector locally, it will be stored in embedding_feature_tensors_. This is a one-dimensional array. Under dist type, the length is sample_num(batch_size) * slot_num_per_gpu[i] * embedding_vec_size. In local, this is batch_size_per_gpu * slot_num_per_gpu[i] * embedding_vec_size.
So the next step is to send embedding between GPUs_ feature_ tensors_, Then each GPU only accepts what it should accept.
template <typename Type>
void SparseEmbeddingFunctors::all2all_forward(size_t batch_size_per_gpu,
const std::vector<size_t> &slot_num_per_gpu,
size_t embedding_vec_size,
const Tensors2<Type> &send_tensors,
Tensors2<Type> &recv_tensors,
const ResourceManager &resource_manager) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
// Fill in partition table, ith Topo GPU to jth Topo GPU
std::vector<std::vector<size_t>> table(local_gpu_count, std::vector<size_t>(local_gpu_count));
for (size_t i = 0; i < local_gpu_count; i++) {
size_t element_per_send = batch_size_per_gpu * slot_num_per_gpu[i] * embedding_vec_size;
for (size_t j = 0; j < local_gpu_count; j++) {
table[i][j] = element_per_send;
}
}
std::vector<const Type *> src(local_gpu_count);
std::vector<Type *> dst(local_gpu_count);
for (size_t id = 0; id < local_gpu_count; id++) {
src[id] = send_tensors[id].get_ptr();
dst[id] = recv_tensors[id].get_ptr();
}
std::vector<std::vector<const Type *>> src_pos(local_gpu_count,
std::vector<const Type *>(local_gpu_count));
std::vector<std::vector<Type *>> dst_pos(local_gpu_count, std::vector<Type *>(local_gpu_count));
// Set offset of source data
// Calculate the src offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t src_offset = 0;
for (size_t j = 0; j < local_gpu_count; j++) {
src_pos[i][j] = src[i] + src_offset;
src_offset += table[i][j];
}
}
// Set the offset of the target data
// Calculate the dst offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t dst_offset = 0;
for (size_t j = 0; j < local_gpu_count; j++) {
dst_pos[i][j] = dst[i] + dst_offset;
dst_offset += table[j][i];
}
}
// need to know the Type
ncclDataType_t type;
switch (sizeof(Type)) {
case 2:
type = ncclHalf;
break;
case 4:
type = ncclFloat;
break;
default:
CK_THROW_(Error_t::WrongInput, "Error: Type not support by now");
}
// Do the all2all transfer
CK_NCCL_THROW_(ncclGroupStart());
for (size_t i = 0; i < local_gpu_count; i++) {
const auto &local_gpu = resource_manager.get_local_gpu(i);
for (size_t j = 0; j < local_gpu_count; j++) {
CK_NCCL_THROW_(ncclSend(src_pos[i][j], table[i][j], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
CK_NCCL_THROW_(ncclRecv(dst_pos[i][j], table[j][i], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
}
}
CK_NCCL_THROW_(ncclGroupEnd());
return;
}
MPI_Alltoall and MPI_ Compared with allgahter, the difference is:
- MPI_AllGather: different processes collect exactly the same data from a process (aggregation result process).
- MPI_Alltoall: different processes collect different data from a process (aggregation result process).
For example:
rank=0, Send 0 1 2 rank=1, Send 3 4 5 rank=2, Send 6 7 8
Then accept:
rank=0, Accept 0 3 6 rank=1, Accept 1 4 7 rank=2, Accept 2 5 8
For our example, at present, it is as follows:
GPU0 Send: 1,3,5,7 GPU1 Send: 2,4,6,8 GPU0 Accepted: 1,3,2,4 GPU1 Accepted: 5,7,6,8
Get as follows, "..." For all2all_tensors_ The length is more than 4 item s.
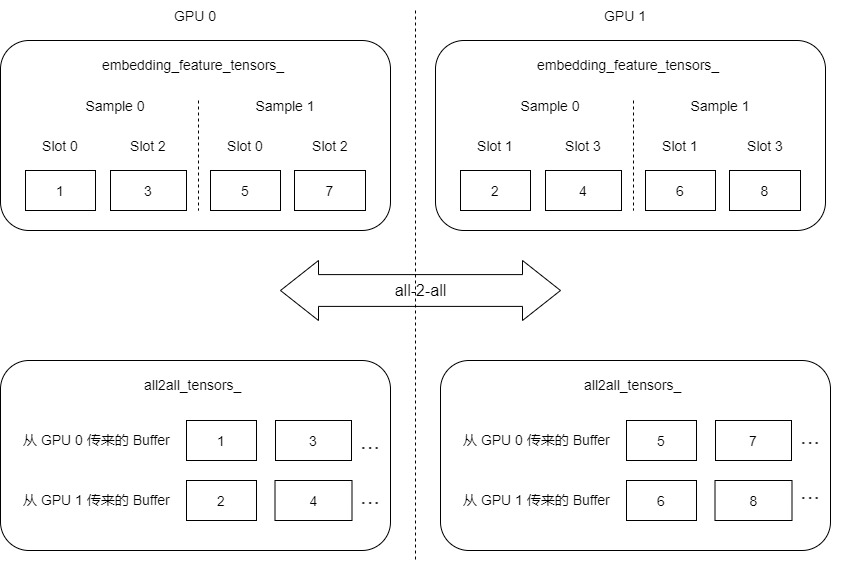
4.3 Reorder
We can find that each GPU now has its own data (each GPU is a complete sample), but there is a problem with the internal order of the sample data, which is not in the ascending order of the slot. Let's roughly adjust and refine the above figure (the legend is in and out of the actual variables, which is just for better demonstration).
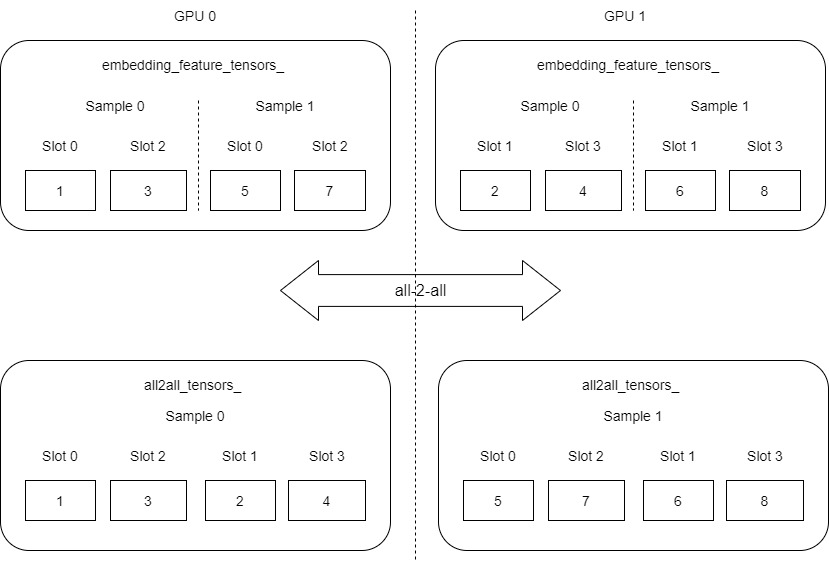
Next, use Reorder to retrieve the data from all2all_ Copy tensor to embedding_data_.get_output_tensors(is_train). The order will be adjusted during the copying process. The purpose is to convert slot 0, slot 2, slot 1 and slot 3 into slot 0, slot 1, slot 2 and slot 3.
template <typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::forward_reorder(size_t batch_size_per_gpu, size_t slot_num,
size_t embedding_vec_size, size_t total_gpu_count,
const Tensors2<TypeEmbeddingComp> &src_tensors,
Tensors2<TypeEmbeddingComp> &dst_tensors,
const ResourceManager &resource_manager) {
CudaDeviceContext context;
size_t local_gpu_count = resource_manager.get_local_gpu_count();
for (size_t id = 0; id < local_gpu_count; id++) { // Traverse local GPU
const auto &local_gpu = resource_manager.get_local_gpu(id);
context.set_device(local_gpu->get_device_id());
// Copy
do_forward_reorder(batch_size_per_gpu, slot_num, embedding_vec_size, total_gpu_count,
src_tensors[id].get_ptr(), dst_tensors[id].get_ptr(),
local_gpu->get_stream());
}
}
do_ forward_ The reorder code is as follows, which relies on forward_ reorder_ The kernel completes the specific logic.
template <typename TypeEmbeddingComp>
void do_forward_reorder(size_t batch_size_per_gpu, size_t slot_num, size_t embedding_vec_size,
size_t total_gpu_count, const TypeEmbeddingComp *input,
TypeEmbeddingComp *output, cudaStream_t stream) {
const size_t grid_size = batch_size_per_gpu;
const size_t block_size = embedding_vec_size;
forward_reorder_kernel<<<grid_size, block_size, 0, stream>>>(
batch_size_per_gpu, slot_num, embedding_vec_size, total_gpu_count, input, output);
}
4.3.1 ideas
The specific logic is:
- gpu_num is the number of GPUs in the global. Later, we want to calculate it according to the global information, because all2all is already a global perspective.
- Get the sample id of the current sample in the current GPU (in fact, it is bid, and each bid corresponds to a sample), and then process it for this sample id, so as to ensure that only the samples of this GPU are retained. For example, the second sample_id = 1.
- Get the starting position of the first slot of the current sample, such as 1 * 4 * 8 = 32.
- Get the size of the embedding vector corresponding to a slot, that is, the stripe between slot and slot = 8
- Traverse the slots of the sample, ranging from 0 to slot num, in order to copy these slots from all2all to embedding_data_.get_output_tensors, so you need to find the starting position of the slot of this sample in all2all.
- For each slot, you need to find out which gpu the slot is on.
- Traverse the GPU. The purpose of traversing the GPU is to find the location of the previous GPU because the slot is allocated according to the GPU. offset_ The final result of pre is the number of slots on the GPU before this slot.
- The key code here is gpu_id = slot_id % gpu_num, which is used to determine "a slot is found on the buffer from which GPU".
- For our example, when alltoall is sent, two slots are sent together. Here, reorder needs one slot to find data. At this time, gpu_id is the key point used to find.
- Get the number of slot s corresponding to each GPU.
- Get the offset of the current sample in the current GPU.
- Get the data starting position of the current sample in other slot s.
- Get the current slot in embedding_ data_. get_ output_ The location of the sotens.
- Copy the slot corresponding to this sample_ ID information.
- Traverse the GPU. The purpose of traversing the GPU is to find the location of the previous GPU because the slot is allocated according to the GPU. offset_ The final result of pre is the number of slots on the GPU before this slot.
The code is as follows:
// reorder operation after all2all in forward propagation
template <typename TypeEmbeddingComp>
__global__ void forward_reorder_kernel(int batch_size_per_gpu, int slot_num, int embedding_vec_size,
int gpu_num, const TypeEmbeddingComp *input,
TypeEmbeddingComp *output) {
// blockDim.x = embedding_vec_size; // each thread corresponding to one element of embedding
// vector gridDim.x = batch_size / gpu_num = samples_per_gpu; // each block corresponding to one
// sample on each GPU Each thread needs to process slot_num slots
int tid = threadIdx.x;
int bid = blockIdx.x;
// The sample id of the current GPU is processed for this sample id later, which can ensure that only the samples of the GPU are retained
int sample_id = bid; // sample_id on the current GPU, such as the second sample, sample_id = 1
if ((bid < batch_size_per_gpu) && (tid < embedding_vec_size)) {
// The starting position of the first slot of the current sample, such as 1 * 4 * 8 = 32
int dst_offset =
sample_id * slot_num * embedding_vec_size; // offset for the first slot of one sample
// The size of the embedding vector corresponding to a slot is the stripe = 8 between slots
int dst_stride = embedding_vec_size; // stride from slot to slot
// Traverse the slots of the sample, ranging from 0 to slot num, in order to copy these slots from all2all to embedding_data_.get_output_tensors
// Therefore, you need to find the starting position of the slot of this sample in all2all
for (int slot_id = 0; slot_id < slot_num; slot_id++) {
int gpu_id = slot_id % gpu_num; // Key code to determine which gpu the slot is on
int offset_pre = 0; // offset in previous gpus
// The purpose of traversing the GPU is to find the location of the previous GPU, because the slot is allocated according to the GPU
// offset_pre finally gets the number of slots on the GPU before this slot
for (int id = 0; id < gpu_id; id++) {
int slot_num_per_gpu = slot_num / gpu_num + ((id < (slot_num % gpu_num)) ? 1 : 0);
int stride = batch_size_per_gpu * slot_num_per_gpu;
offset_pre += stride; // Find the front position
}
// How many slot s does each GPU correspond to
int slot_num_per_gpu = slot_num / gpu_num + ((gpu_id < (slot_num % gpu_num)) ? 1 : 0);
// The offset of the current sample in the current GPU
int offset_cur = sample_id * slot_num_per_gpu; // offset in current gpu
// The current sample is at the data starting position corresponding to other slot s
// (offset_cur + offset_pre + (int)(slot_id / gpu_num)) is the number of slots in front of this slot
int src_addr = (offset_cur + offset_pre + (int)(slot_id / gpu_num)) * embedding_vec_size;
// The current slot is embedded_ data_. get_ output_ Target location in tensors
int dst_addr = dst_offset + dst_stride * slot_id;
// Copy the slot corresponding to this sample_ ID information
output[dst_addr + tid] = input[src_addr + tid];
}
}
}
4.3.2 diagram
This is for demonstration. The logic is simplified_ feature_ tensors_, all2all_ tensors_ It should have been a one-dimensional array, which is abstracted into a two-dimensional array.
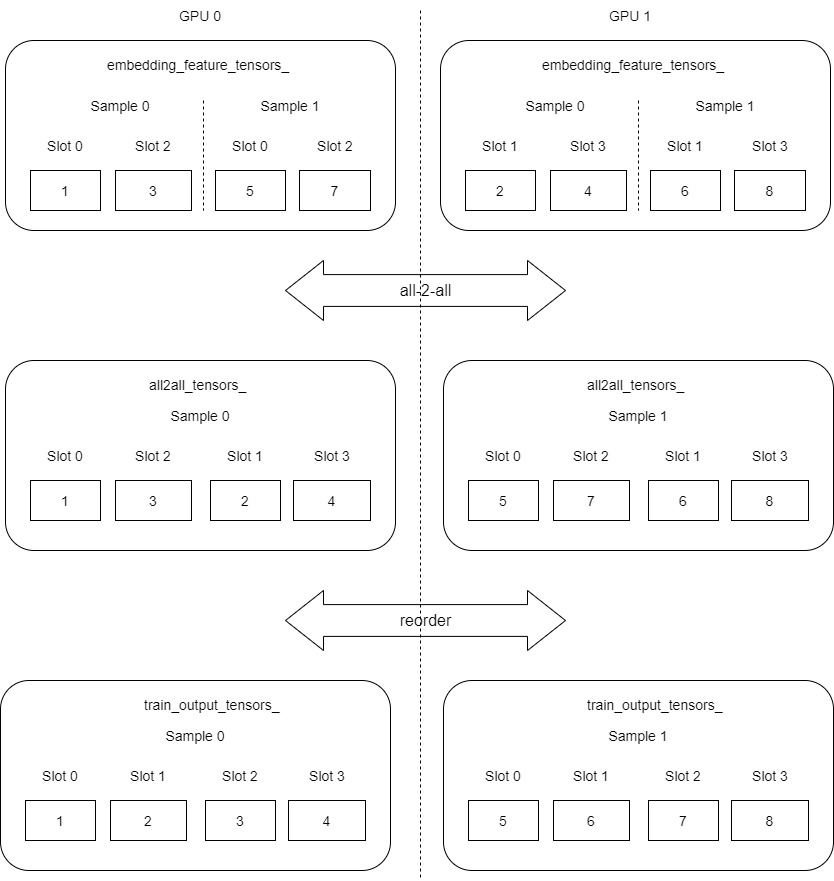
4.4 slot id
Finally, you need to store the slot id. The reason to save the slot id corresponding to the parameter is that there are different slots on each GPU. Now all slots of a sample should be placed on the same GPU, so you need to know which slot to load when loading.
// store slot_id by row_offset and value_index
template <typename TypeKey, typename TypeValueIndex>
__global__ void store_slot_id_kernel(size_t batch_size,
int slot_num, // total slot number in hash table
int slot_num_per_gpu,
int gpu_num, // total gpu number
int gpu_id, // global gpu device id
const TypeKey *row_offset, const TypeValueIndex *value_index,
TypeValueIndex *slot_id) {
size_t gid = blockIdx.x * blockDim.x + threadIdx.x;
if (gid < (batch_size * slot_num_per_gpu)) {
int sid = gid % slot_num_per_gpu;
sid = gpu_id + sid * gpu_num; // global slot id
if (sid < slot_num) {
TypeKey offset = row_offset[gid];
int value_num = row_offset[gid + 1] - offset;
for (int i = 0; i < value_num; i++) {
TypeValueIndex index = value_index[offset + i]; // row number
slot_id[index] = sid;
}
}
}
}
} // namespace
template <typename TypeKey>
void SparseEmbeddingFunctors::store_slot_id(size_t batch_size, size_t slot_num,
const std::vector<size_t> &slot_num_per_gpu,
const Tensors2<TypeKey> &row_offset_tensors,
const Tensors2<size_t> &value_index_tensors,
Tensors2<size_t> &slot_id_tensors,
const ResourceManager &resource_manager) {
CudaDeviceContext context;
size_t local_gpu_count = resource_manager.get_local_gpu_count();
size_t total_gpu_count = resource_manager.get_global_gpu_count();
for (size_t id = 0; id < local_gpu_count; id++) {
if (slot_num_per_gpu[id] == 0) {
continue;
}
const auto &local_gpu = resource_manager.get_local_gpu(id);
size_t local_device_id = local_gpu->get_device_id();
size_t global_id = local_gpu->get_global_id();
const size_t block_size = 64;
const size_t grid_size = (batch_size * slot_num_per_gpu[id] + block_size - 1) / block_size;
context.set_device(local_device_id);
store_slot_id_kernel<<<grid_size, block_size, 0, local_gpu->get_stream()>>>(
batch_size, slot_num, slot_num_per_gpu[id], total_gpu_count, global_id,
row_offset_tensors[id].get_ptr(), value_index_tensors[id].get_ptr(),
slot_id_tensors[id].get_ptr());
}
}
4.5 output matrix
Let's look at the size of the output dense matrix through a function, which is batch_size_per_gpu * slot_num * embedding_vec_size.
// only used for results check
/**
* Get the forward() results from GPUs and copy them to the host pointer
* embedding_feature. This function is only used for unit test.
* @param embedding_feature the host pointer for storing the forward()
* results.
*/
void get_forward_results(bool is_train, Tensor2<TypeEmbeddingComp> &embedding_feature) {
size_t memcpy_size = embedding_data_.get_batch_size_per_gpu(is_train) *
embedding_data_.embedding_params_.slot_num *
embedding_data_.embedding_params_.embedding_vec_size;
functors_.get_forward_results(memcpy_size, embedding_data_.get_output_tensors(is_train),
embedding_feature, utest_forward_temp_tensors_,
embedding_data_.get_resource_manager());
return;
}
get_batch_size_per_gpu is defined as follows:
size_t get_batch_size_per_gpu(bool is_train) const {
return embedding_params_.get_batch_size(is_train) / resource_manager_->get_global_gpu_count();
}
0x05 backward propagation
Because the forward propagation has done all2all and backward successively, the backward propagation should first do its reverse operation, and then do backward.
Although we know all2all_backward and backward_reorder is the reverse operation of forward propagation, but the code here is still brain burning. It will be better in combination with the figure.
/**
* The first stage of backward propagation of embedding layer,
* which computes the wgrad by the dgrad from the top layer.
*/
void backward() override {
// Read dgrad from output_tensors -> compute wgrad
// reorder
functors_.backward_reorder(embedding_data_.get_batch_size_per_gpu(true),
embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.get_output_tensors(true), all2all_tensors_,
embedding_data_.get_resource_manager());
// do all2all
#ifndef ENABLE_MPI
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_backward(embedding_data_.get_batch_size_per_gpu(true), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
all2all_tensors_, embedding_feature_tensors_,
embedding_data_.get_resource_manager());
} else {
CudaDeviceContext context(embedding_data_.get_local_gpu(0).get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(
embedding_feature_tensors_[0].get_ptr(), all2all_tensors_[0].get_ptr(),
embedding_data_.get_batch_size_per_gpu(true) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#else
if (embedding_data_.get_resource_manager().get_global_gpu_count() > 1) {
functors_.all2all_backward(
embedding_data_.get_batch_size_per_gpu(true), embedding_data_.embedding_params_.slot_num,
embedding_data_.embedding_params_.embedding_vec_size, all2all_tensors_,
embedding_feature_tensors_, embedding_data_.get_resource_manager());
} else {
CudaDeviceContext context(embedding_data_.get_local_gpu(0).get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(
embedding_feature_tensors_[0].get_ptr(), all2all_tensors_[0].get_ptr(),
embedding_data_.get_batch_size_per_gpu(true) * slot_num_per_gpu_[0] *
embedding_data_.embedding_params_.embedding_vec_size * sizeof(TypeEmbeddingComp),
cudaMemcpyDeviceToDevice, embedding_data_.get_local_gpu(0).get_stream()));
}
#endif
// do backward
functors_.backward(embedding_data_.embedding_params_.get_batch_size(true), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner,
embedding_data_.get_row_offsets_tensors(true), embedding_feature_tensors_,
wgrad_tensors_, embedding_data_.get_resource_manager());
return;
}
5.1 Reorder backward
The purpose of Reorder backpropagation is to make all gradients above GPUs be dispersed and copied to all2all_tensors_ Different locations. In the following figure, each slot corresponds to a gradient embedding vector, now train_output_tensors_(gradients) is the gradient. Now the gradient above each GPU is a complete gradient of two sample s.
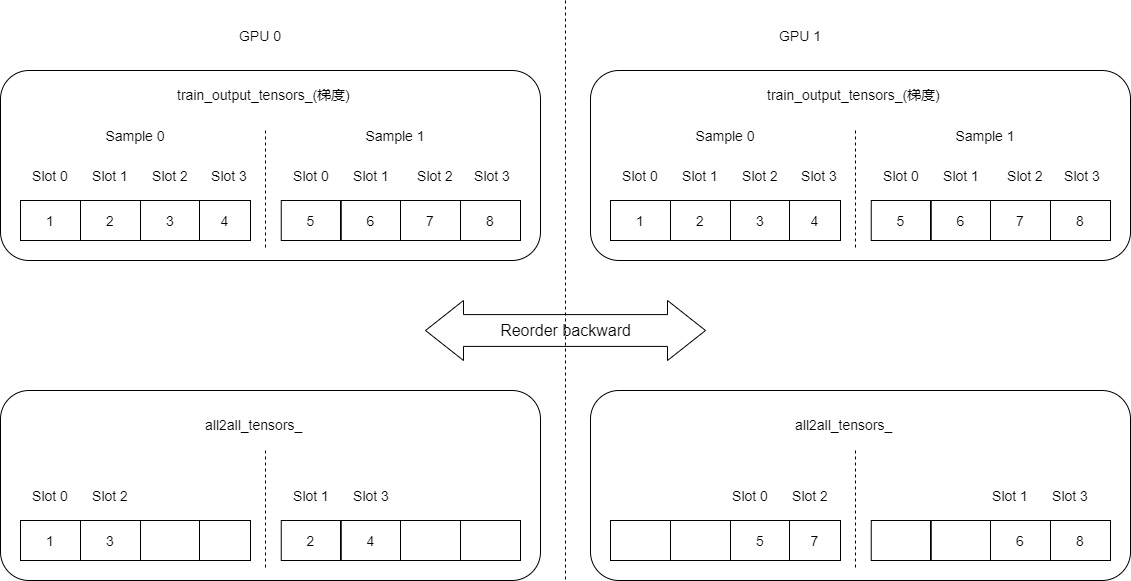
The specific code is as follows. There will be two bid s on each GPU, corresponding to sample 1 and sample 2 respectively:
// reorder operation before all2all in backward propagation
template <typename TypeEmbeddingComp>
__global__ void backward_reorder_kernel(int batch_size_per_gpu, int slot_num,
int embedding_vec_size, int gpu_num,
const TypeEmbeddingComp *input, TypeEmbeddingComp *output) {
// blockDim.x = embedding_vec_size; // each thread corresponding to one element of embedding
// vector gridDim.x = batch_size / gpu_num = samples_per_gpu; // each block corresponding to one
// sample on each GPU Each thread needs to process slot_num slots
int tid = threadIdx.x;
int bid = blockIdx.x;
int sample_id = bid; // sample_id on the current GPU
if ((bid < batch_size_per_gpu) && (tid < embedding_vec_size)) {
// Source: the starting position of the gradient of this sample. GPU0 is 0 and GPU1 is 1*4*embedding_vec_size
int src_offset = sample_id * slot_num * embedding_vec_size;
int src_stride = embedding_vec_size; // Span. This is 4
for (int slot_id = 0; slot_id < slot_num; slot_id++) { // The value is 0 ~ 3
int gpu_id = slot_id % gpu_num; // The value is 0 ~ 1
int offset_pre = 0; // offset in previous gpus
for (int id = 0; id < gpu_id; id++) {
// The value is 2
int slot_num_per_gpu = slot_num / gpu_num + ((id < (slot_num % gpu_num)) ? 1 : 0);
// The value is 2 * 2
int stride = batch_size_per_gpu * slot_num_per_gpu;
// Find the starting position of all samples in the previous GPU. GPU0 is 0 and GPU1 is 4
offset_pre += stride;
}
// Target location: find the starting location of this sample in the current GPU
// slot_num_per_gpu = 2
int slot_num_per_gpu = slot_num / gpu_num + ((gpu_id < (slot_num % gpu_num)) ? 1 : 0);
// 2*sample_id
int offset_cur = sample_id * slot_num_per_gpu; // offset in current gpu
// It should be noted that embedding_vec_size is 4, but in the figure, we all put embedding_vec_size comes down to a slot
// If it corresponds to the graph, it is in the unit of slot, embedding_vec_size is 1, so it is simplified as follows:
// GPU0=sample_id*2+0+slot_id/gpu_num, sample1 is 0 ~ 1, sample2 is 4 ~ 5
// GPU1=sample_id*2+4+slot_id/gpu_num, sample1 is 2 ~ 3, sample2 is 6 ~ 7
int dst_addr = (offset_cur + offset_pre + (int)(slot_id / gpu_num)) * embedding_vec_size;
// Source position: find the starting position of this sample in the current gradient
// It should be noted that embedding_vec_size is 4, but in the figure, we all put embedding_vec_size comes down to a slot
// If it corresponds to the graph, it is in the unit of slot, embedding_vec_size is 1, so it is simplified as follows:
// src_offset=sample_id * slot_num
// src_addr = sample_id * slot_num + slot_id
// Then src_addr should be: sample_id * slot_num + slot_id
// Therefore, the value range of GPU0 and GPU1 is sample1=0 ~ 3 and sample2=4 ~ 7
int src_addr = src_offset + src_stride * slot_id;
output[dst_addr + tid] = input[src_addr + tid]; // Copy the gradient of this sample to all2all_tensors_ The position that the tensor should be in
}
}
}
5.2 All2all backward
Here is the exchange. The essence is the same as the beginning of forward communication. Send yourself in groups, but only accept what you should accept. Finally, each GPU has only the gradient of its original sample. We can see that the final gradient is the same as the original embedding_feature_tensors_ Exactly, whether it's sample, slot or specific value.
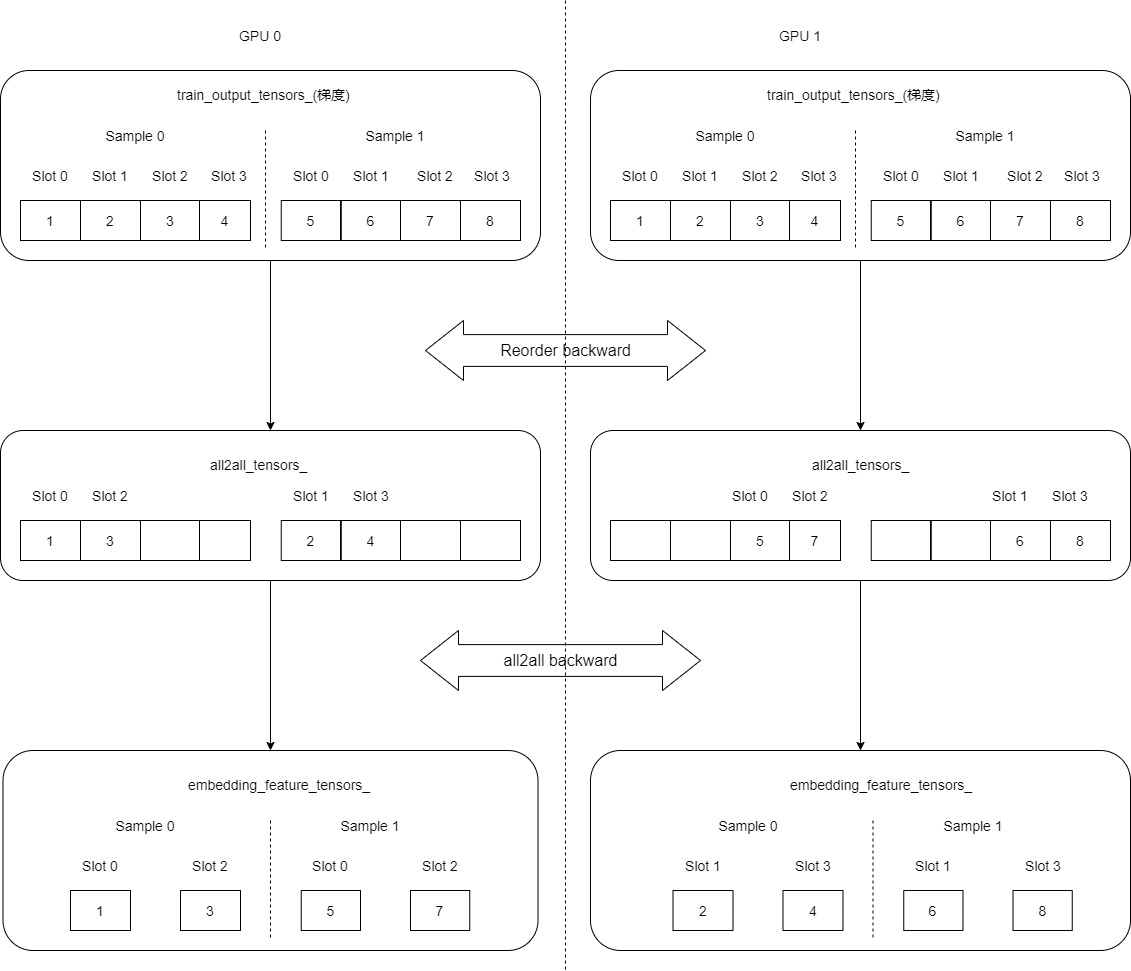
The specific codes are as follows:
/**
* nccl all2all communication for backward
* @param batch_size_per_gpu batch size per GPU
* @param slot_num slot number
* @param embedding_vec_size embedding vector size
* @param send_tensors the send tensors of multi GPUs.
* @param recv_tensors the recv tensors of multi GPUs.
* @param device_resources all gpus device resources.
*/
template <typename Type>
void SparseEmbeddingFunctors::all2all_backward(size_t batch_size_per_gpu, size_t slot_num,
size_t embedding_vec_size,
const Tensors2<Type> &send_tensors,
Tensors2<Type> &recv_tensors,
const ResourceManager &resource_manager) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
size_t total_gpu_count = resource_manager.get_global_gpu_count();
size_t num_proc = resource_manager.get_num_process();
std::vector<const Type *> src(local_gpu_count);
std::vector<Type *> dst(local_gpu_count);
for (size_t id = 0; id < local_gpu_count; id++) {
src[id] = send_tensors[id].get_ptr(); // send_tensors is a list that corresponds to multiple GPU s
dst[id] = recv_tensors[id].get_ptr(); // recv_tensors is a list that corresponds to multiple GPU s
}
std::vector<std::vector<size_t>> send_table(local_gpu_count,
std::vector<size_t>(total_gpu_count));
std::vector<std::vector<size_t>> recv_table(local_gpu_count,
std::vector<size_t>(total_gpu_count));
// Fill in receiving partition table, ith Topo GPU receive from jth global GPU
for (size_t i = 0; i < local_gpu_count; i++) {
size_t global_id = resource_manager.get_local_gpu(i)->get_global_id();
size_t slot_num_per_gpu =
slot_num / total_gpu_count + ((global_id < (slot_num % total_gpu_count)) ? 1 : 0);
size_t element_per_recv = batch_size_per_gpu * slot_num_per_gpu * embedding_vec_size;
for (size_t j = 0; j < total_gpu_count; j++) {
recv_table[i][j] = element_per_recv;
}
}
// Fill in sending partition table, ith Topo GPU send to jth global GPU
for (size_t j = 0; j < total_gpu_count; j++) {
size_t global_id = j;
size_t slot_num_per_gpu =
slot_num / total_gpu_count + ((global_id < (slot_num % total_gpu_count)) ? 1 : 0);
size_t element_per_send = batch_size_per_gpu * slot_num_per_gpu * embedding_vec_size;
for (size_t i = 0; i < local_gpu_count; i++) {
send_table[i][j] = element_per_send;
}
}
std::vector<std::vector<const Type *>> src_pos(local_gpu_count,
std::vector<const Type *>(total_gpu_count));
std::vector<std::vector<Type *>> dst_pos(local_gpu_count, std::vector<Type *>(total_gpu_count));
// Calculate the src offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t src_offset = 0;
for (size_t j = 0; j < total_gpu_count; j++) {
src_pos[i][j] = src[i] + src_offset;
src_offset += send_table[i][j];
}
}
// Calculate the dst offset pointer from each GPU to each other
for (size_t i = 0; i < local_gpu_count; i++) {
size_t dst_offset = 0;
for (size_t j = 0; j < total_gpu_count; j++) {
dst_pos[i][j] = dst[i] + dst_offset;
dst_offset += recv_table[i][j];
}
}
// need to know the Type
ncclDataType_t type;
switch (sizeof(Type)) {
case 2:
type = ncclHalf;
break;
case 4:
type = ncclFloat;
break;
default:
CK_THROW_(Error_t::WrongInput, "Error: Type not support by now");
}
// Do the all2all transfer
CK_NCCL_THROW_(ncclGroupStart());
for (size_t i = 0; i < local_gpu_count; i++) {
const auto &local_gpu = resource_manager.get_local_gpu(i);
for (size_t j = 0; j < total_gpu_count; j++) {
CK_NCCL_THROW_(ncclSend(src_pos[i][j], send_table[i][j], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
CK_NCCL_THROW_(ncclRecv(dst_pos[i][j], recv_table[i][j], type, j, local_gpu->get_nccl(),
local_gpu->get_stream()));
}
}
CK_NCCL_THROW_(ncclGroupEnd());
return;
}
5.3 backward
Now we get the gradient corresponding to the original sample on the GPU, so we can carry out backward. This part has been introduced before, so we won't repeat it.
// do backward
functors_.backward(embedding_data_.embedding_params_.get_batch_size(true), slot_num_per_gpu_,
embedding_data_.embedding_params_.embedding_vec_size,
embedding_data_.embedding_params_.combiner,
embedding_data_.get_row_offsets_tensors(true), embedding_feature_tensors_,
wgrad_tensors_, embedding_data_.get_resource_manager());
0x06 storage
Here is a brief analysis. When storing, rank 0 is responsible for writing files.
Error_t Session::download_params_to_files_(std::string weights_file,
std::string dense_opt_states_file,
const std::vector<std::string>& embedding_files,
const std::vector<std::string>& sparse_opt_state_files) {
try {
{
// Storage parameters
int i = 0;
for (auto& embedding_file : embedding_files) {
embeddings_[i]->dump_parameters(embedding_file);
i++;
}
}
{
// Storage optimizer
int i = 0;
for (auto& sparse_opt_state_file : sparse_opt_state_files) {
std::ofstream out_stream_opt(sparse_opt_state_file, std::ofstream::binary);
embeddings_[i]->dump_opt_states(out_stream_opt);
out_stream_opt.close();
i++;
}
}
// The rank 0 node is responsible for writing files
if (resource_manager_->is_master_process()) {
std::ofstream out_stream_weight(weights_file, std::ofstream::binary);
networks_[0]->download_params_to_host(out_stream_weight);
std::ofstream out_dense_opt_state_weight(dense_opt_states_file, std::ofstream::binary);
networks_[0]->download_opt_states_to_host(out_dense_opt_state_weight);
std::string no_trained_params = networks_[0]->get_no_trained_params_in_string();
if (no_trained_params.length() != 0) {
std::string ntp_file = weights_file + ".ntp.json";
std::ofstream out_stream_ntp(ntp_file, std::ofstream::out);
out_stream_ntp.write(no_trained_params.c_str(), no_trained_params.length());
out_stream_ntp.close();
}
out_stream_weight.close();
out_dense_opt_state_weight.close();
}
} catch (const internal_runtime_error& rt_err) {
std::cerr << rt_err.what() << std::endl;
return rt_err.get_error();
} catch (const std::exception& err) {
std::cerr << err.what() << std::endl;
return Error_t::UnspecificError;
}
return Error_t::Success;
}
Take optimizer as an example. Other worker nodes send data to rank 0 node. After receiving the data, rank 0 node will process it.
template <typename TypeEmbeddingComp>
void SparseEmbeddingFunctors::dump_opt_states(
std::ofstream& stream, const ResourceManager& resource_manager,
std::vector<Tensors2<TypeEmbeddingComp>>& opt_states) {
size_t local_gpu_count = resource_manager.get_local_gpu_count();
CudaDeviceContext context;
for (auto& opt_state : opt_states) {
size_t total_size = 0;
for (size_t id = 0; id < local_gpu_count; id++) {
total_size += opt_state[id].get_size_in_bytes();
}
size_t max_size = total_size;
#ifdef ENABLE_MPI
bool is_master_process = resource_manager.is_master_process();
CK_MPI_THROW_(MPI_Reduce(is_master_process ? MPI_IN_PLACE : &max_size, &max_size,
sizeof(size_t), MPI_CHAR, MPI_MAX,
resource_manager.get_master_process_id(), MPI_COMM_WORLD));
#endif
std::unique_ptr<char[]> h_opt_state(new char[max_size]);
size_t offset = 0;
for (size_t id = 0; id < local_gpu_count; id++) {
size_t local_size = opt_state[id].get_size_in_bytes();
auto& local_gpu = resource_manager.get_local_gpu(id);
context.set_device(local_gpu->get_device_id());
CK_CUDA_THROW_(cudaMemcpyAsync(h_opt_state.get() + offset, opt_state[id].get_ptr(),
local_size, cudaMemcpyDeviceToHost, local_gpu->get_stream()));
offset += local_size;
}
sync_all_gpus(resource_manager);
int pid = resource_manager.get_process_id();
if (resource_manager.is_master_process()) {
// rank 0 is responsible for writing
stream.write(h_opt_state.get(), total_size);
}
#ifdef ENABLE_MPI
else {
// Other worker nodes send data to the rank 0 node
int tag = (pid << 8) | 0xBA;
CK_MPI_THROW_(MPI_Send(h_opt_state.get(), total_size, MPI_CHAR,
resource_manager.get_master_process_id(), tag, MPI_COMM_WORLD));
}
if (resource_manager.is_master_process()) {
for (int r = 1; r < resource_manager.get_num_process(); r++) {
int tag = (r << 8) | 0xBA;
int recv_size = 0;
MPI_Status status;
CK_MPI_THROW_(MPI_Probe(r, tag, MPI_COMM_WORLD, &status));
CK_MPI_THROW_(MPI_Get_count(&status, MPI_CHAR, &recv_size));
// The rank 0 node received data
CK_MPI_THROW_(MPI_Recv(h_opt_state.get(), recv_size, MPI_CHAR, r, tag, MPI_COMM_WORLD,
MPI_STATUS_IGNORE));
stream.write(h_opt_state.get(), recv_size);
}
}
#endif
MESSAGE_("Done");
}
}
0xFF reference
How does the embedding layer back propagate
https://web.eecs.umich.edu/~justincj/teaching/eecs442/notes/linear-backprop.html
Sparse matrix storage format summary + storage efficiency comparison: COO,CSR,DIA,ELL,HYB
Making something out of nothing: on the Embedding idea in Recommendation Algorithm
tf. nn. embedding_ Principle of lookup function
Please explain the embedding of tensorflow_ What does the lookup interface mean?
[technical dry goods] talk about how embedding is done in the recommended scenes of large factories