Week 5 function and code reuse
5.1 definition and use of functions
Use the reserved word def to define the function and lambda to define the anonymous function
Optional parameters (initial value), variable parameters (* b), name transfer
The reserved word return can return any number of results
The reserved word global declaration uses global variables and some implicit rules

5.2 Example 7: Seven Segment nixie tube drawing
Understanding method thinking
Modular thinking: determine the module interface and encapsulate the function
Regular thinking: the abstract process is a rule, which is automatically executed by the computer
Turn complexity into simplicity: turn big functions into small function combinations and divide and rule them

code:
# coding:utf-8
import turtle,time
def drawGap():
turtle.penup()
turtle.fd(5)
def drawLine(draw):
drawGap()
turtle.pendown() if draw else turtle.penup()
turtle.fd(40)
drawGap()
turtle.right(90)
def drawDigit(digit):
drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,6,8] else drawLine(False)
turtle.left(90)
drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180)
turtle.penup()
turtle.fd(20)
def drawDate(date):
turtle.pencolor("red")
for i in date:
if i =="-":
turtle.write("year",font=("Arial",18,"normal"))
turtle.pencolor("green")
turtle.fd(40)
elif i =="=":
turtle.write("month",font=("Arial",18,"normal"))
turtle.pencolor("red")
turtle.fd(40)
elif i =="+":
turtle.write("day",font=("Arial",18,"normal"))
turtle.pencolor("blue")
else:
drawDigit(eval(i))
def main():
turtle.setup(800,350,200,200)
turtle.penup()
turtle.fd(-300)#300 pixels to the left from the origin of the drawing center
turtle.pensize(5)
drawDate(time.strftime("%Y-%m=%d+",time.gmtime()))
turtle.hideturtle()
turtle.done()
main()
5.3 code reuse and function recursion
Modular design: loose coupling and tight coupling
Two features of function recursion: base case and chain
Implementation of function recursion: function + branch structure
Hanoi Tower problem

count=0
def hanoi(n,src,dst,mid):
global count
if n==1:
print("{}:{}>{}".format(1,src,dst))
count+=1
else:
hanoi(n-1,src,mid,dst)
print("{}:{}>{}".format(n,src,dst))
count+=1
hanoi(n-1,mid,dst,src)
hanoi(3,"A","B","C")
print(count)
5.4 module 4: use of pyinstaller Library
Common parameters of PyInstaller Library
Parameter description
-h view help
– clean up temporary files during packaging
-D. -- onedir default value, generate dist folder
-F. -- onefile only generates independent package files in dist folder
-I < icon file name ICO > specifies the icon file used by the packer
5.5 example 8: Koch snowflake package
Koch curve, also known as snowflake curve
Fractal geometry is an iterative geometric figure, which widely exists in nature
Fractal geometry
Cantor set, shelbinsky triangle, Menger sponge
Dragon curve, space filling curve, koch curve
Deep application of function recursion
code:
#Koch snowflake curve 1 first order
#KochDraw1.py
import turtle
def koch(size,n):
if n==0:
turtle.fd(size)
else:
for angle in [0,60,-120,60]:
turtle.left(angle)
koch(size/3,n-1)
def main():
turtle.setup(800,400)
turtle.penup()
turtle.goto(-350,-50)
turtle.pendown()
turtle.pensize(2)
koch(600,3)
turtle.hideturtle()
main()
#Koch snowflake curve 2 third order
import turtle
def koch(size,n):
if n==0:
turtle.fd(size)
else:
for angle in [0,60,-120,60]:
turtle.left(angle)
koch(size/3,n-1)
def main():
turtle.setup(800,600)
turtle.penup()
turtle.goto(-200,100)
turtle.pendown()
turtle.pensize(2)
koch(400,level)
turtle.right(120)
koch(400,level)
turtle.right(120)
koch(400, level)
turtle.hideturtle()
level=3#You can also set local variables directly in the topic
main()
Week 6 combined data type
6.1 collection type and operation
The collection is created using the {} and set() functions
Operations between sets: intersection (&), Union (|), difference (-), complement (^), comparison (> = <)
Collection type method: add(),. discard(),. pop() etc
Collection types are mainly used for: including relationship comparison and data De duplication
6.2 sequence type and operation
Sequence is the base class type, and extension types include string, tuple and list
Inverse list

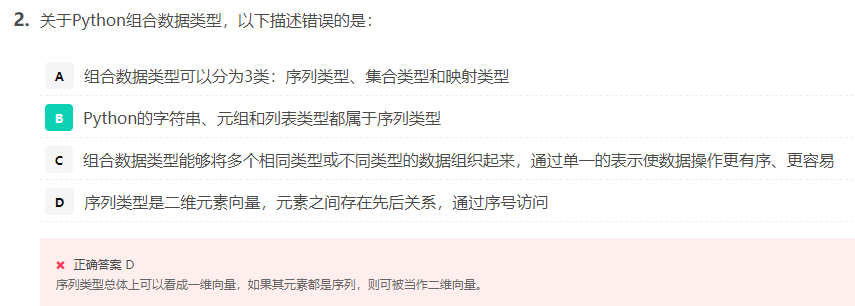
Tuples are created with () and tuple(), and lists are created with [] and set()
Tuple operation is basically the same as sequence operation
On the basis of sequence operation, list operation adds more flexibility
6.3 Example 9: Calculation of basic statistical values
Get multiple data: a method to get multiple uncertain data from the console
Separating multiple functions: a modular design approach
Make full use of functions: make full use of the built-in functions provided by Python

#Calculation of basic statistics
def getNum():#Get user variable length input
nums=[]
iNumStr=input("please enter a number(Enter exit):")
while iNumStr!="":
nums.append(eval(iNumStr))
iNumStr = input("please enter a number(Enter exit):")
return nums
def mean(numbers):#Calculate average
s=0.0
for num in numbers:
s+=num
return s/len(numbers)
#Calculate standard deviation
def dev(numbers,mean):
sdev=0.0
for num in numbers:
sdev+=(num-mean)**2
return pow(sdev/(len(numbers)-1),0.5)
#Calculate median
def median(numbers):
numbers.sort()
#You must have a return value when using the sorted function
#Or numbers = numbers sorted()
size=len(numbers)
if size%2==0:
med=(numbers[size//2-1]+numbers[size//2])/2
else:
med=numbers[size//2]
return med
n=getNum()
m=mean(n)
print("The average is{},The standard deviation is{:.2},The median is{}".format(m,dev(n,m),median(n)))

6.4 dictionary type and operation
The mapping relationship is expressed by key value pairs
Dictionary types are created using {} and dict(), and key value pairs are separated by:
The d[key] method can be indexed or assigned
Dictionary types have a number of operation methods and functions, most importantly get()



6.5 module 5: use of Jieba Library
jieba word segmentation relies on Chinese Thesaurus
Using a Chinese Thesaurus, the association probability between Chinese characters is determined
Chinese characters with high probability form phrases to form word segmentation results
In addition to word segmentation, users can also add custom phrases
Three modes of jieba word segmentation:
Precise mode, full mode, search engine mode
Precise mode: cut the text accurately, and there are no redundant words
Full mode: scan out all possible words in the text with redundancy
Search engine mode: on the basis of precise mode, long words are segmented again
6.6 example 10: text word frequency statistics
Text denoising and normalization
Chinese text segmentation
Use a dictionary to express word frequency
Extender problem solving
Text word frequency statistics: English version Hamlet
#calHamletV1.py
def getText():
txt=open("hamlet.txt","r").read()
txt=txt.lower()
for ch in "!#$%&()*+,-./:;<=>?@[\\]^_'{|}~":
txt=txt.replace(ch," ")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))
Statistics on word frequency of Chinese text:
# coding:utf-8
import jieba
txt=open("threekingdoms.txt", "r",encoding="UTF-8").read()
excludes = {"general","But say","Jingzhou","Two people","must not","No","such",
"Discuss","how","The world","about","Lord","Army horse","Sergeant","Lead troops","The next day","Soochow"}
#There are still many words to be excluded before the statistics are finished
words=jieba.lcut(txt)
counts={}
for word in words:
if len(word)==1:
continue
elif word == "Zhuge Liang" or word == "Kong Mingyue":
rword = "kong ming"
elif word == "Guan Yu" or word == "Cloud length":
rword = "Guan Yu"
elif word == "Xuande" or word == "Xuande said":
rword = "Liu Bei"
elif word == "Meng de" or word == "the prime minister":
rword = "Cao Cao"
else:
counts[word]=counts.get(word,0)+1
for word in excludes:
del counts[word]
items=list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count=items[i]
print("{0:<10}{1:>5}".format(word,count))

After class exercise: Dictionary flip output

Note:
Read in a dictionary type string.
Dictionary flipping output is actually to exchange key value pairs. Use the input function to obtain the input, and use the eval function to remove quotation marks and assign values to the variable S. at this time, the variable is the obtained dictionary. Then traverse the dictionary s and re assign the key and value of s to the dictionary dict. In fact, it is to read the existing dictionary and re create the dictionary and output it.
If we still don't quite understand it, we can split the code S[i] and use the print statement for output. In fact, it obtains the value of dictionary S. We take the value as the key dict[S[i]] and then add the key I as the value to dictionary dict again.
s=input()
try:
S=eval(s)
dict={}
for i in S:
dict[S[i]]=i
print(dict)
except:
print("Input error")
After class exercise: the most words in the silent lamb
The attachment is the content of the Chinese version of the silent lamb. Please read the content and output the most words with a length of more than 2 after word segmentation.
If there are multiple words with the same frequency, output the largest word sorted by Unicode.
# #The silent lamb
import jieba
f=open("Silent lamb.txt","r",encoding="UTF-8").read()
words=jieba.lcut(f)
counts={}
for word in words:
counts[word]=counts.get(word,0)+1
maxc = 0
maxw = ""
for k in words:
if counts[k] > maxc and len(k) > 2:
maxc = counts[k]
maxw = k
if counts[k] == maxc and len(k) > 2 and k > maxw:
maxw = k
print(maxw)
Unit test program questions
1. Sum of different numbers
describe
Obtain an integer N input by the user and output the sum of different numbers in N.
For example: the user enters 123123, in which the different numbers are: 1, 2 and 3, and the sum of these numbers is 6.
N=input()
s=set(N)
sum=0
for i in s:
sum+=eval(i)
print(sum)
2. Statistics of the largest number of names
describe
A string is given in the programming template, which contains duplicate names. Please directly output the names of the people who appear most.
#2. Statistics of the largest number of names
# #A string is given in the programming template, which contains duplicate names. Please directly output the names of the people who appear most.
s = '''Shuanger Hong Qigong, Zhao Min, Xiaoyao son, aobai, Yin Tianzheng, king of the golden wheel, Qiao Feng, Yang Guo, Hong Qigong, Guo Jing
Yang Xiao Ao Bai Yin Tianzheng Duan Yu Yang Xiao Murong Fu a Zi Murong Fu Guo Fu Qiao Feng Linghu Chong Guo Fu
Yang Guo, the little dragon daughter of the king of the golden wheel, Murong Fu, Mei Chaofeng, Li Mochou, Hong Qigong, Zhang Wuji, Mei Chaofeng, Yang Xiao
Aobai Yue buqun Huang pharmacist Huang Rong Duanyu Golden Wheel Dharma King Kublai Khan Zhang Sanfeng Qiao Feng Qiao Feng
A Zi Qiao Feng, king of the golden wheel, Yuan Guannan, Zhang Wuji, Guo Xiang, Huang Rong, Li Mochou, Zhao Min, Zhao Min, Guo Fu, Zhang Sanfeng
Qiao Feng, Zhao Min, Mei Chaofeng, Shuanger, aobai, Chen Jialuo, Yuan Guan, Nan Guofu, Guo Fu, Yang Xiao, Zhao Min, king of the Golden Wheel
Kublai Khan murongfu Zhang Sanfeng Zhao Min Yang Xiao Linghu Chong Huang pharmacist yuan Guannan Yang Xiao Wanyan Honglie Yin Tianzheng
Li Mochou a Zi Xiaoyao Zi Qiao Feng Xiaoyao Zi Wan Yan Honglie Guo Fu Yang Xiao Zhang Wuji Yang Guo murongfu
Xiao Yao Zi Xu Zhu Shuang Er Qiao Feng Guo Fu Huang Rong Li Mochou Chen Jialuo Yang Guo Kublai Khan aobai Wang Yuyan
Hong Qigong, Wei Xiaobao, a Zhu, Mei Chaofeng, Duan Yu, Yue Lingshan, Wan Yan Honglie, Qiao Feng, Duan Yu, Yang Guo, Yang Guo, murongfu
Huang Rong, Yang Guo, a Zi, Yang Xiao, Zhang Sanfeng, Zhang Sanfeng, Zhao Min, Zhang Sanfeng, Yang Xiao, Huang Rong, king of the golden wheel, Guo Xiang
Zhang Sanfeng Linghu Chong Zhao Min Guo Fu Wei Xiaobao Huang pharmacist a Zi Wei Xiaobao Golden Wheel Dharma King Yang Xiao Linghu Chong a Zi
Hong Qigong, Yuan Guannan, Shuanger, Guo Jing, Ao Bai, Xie Xun, a Zi, Guo Xiang, Mei Chaofeng, Zhang Wuji, Duan Yu, Kublai Khan
Wanyan Honglie's son Xie Xun, Wanyan Honglie's son, Yan Tianzheng, king of the golden wheel, Zhang Sanfeng, his son, Guo Xiang, ah Zhu
Guo Xiang's son Li Mochou Guo Xiang Kublai Khan king of the Golden Wheel Zhang Wuji obeisance to Kublai Khan Guo Xiang Linghu Chong
Xie Xun Mei Chaofeng Yin Tianzheng Duanyu yuan Guannan Zhang Sanfeng Wang Yuyan a Zi Xie Xun Yang Guo Jing Huang Rong
Twin extinction abbess Duan Yu Zhang Wuji Chen Jialuo Huang Rong aobai Huang Yaoshi Xiaoyao son Kublai Khan Zhao Min
Xiaoyaozi Wanyan Honglie, the two sons of the Golden Wheel Dharma king aobai, Hong Qigong, Guo Fu, Guo Xiang, Zhao Min'''
#In the traditional solution, first use the dictionary to establish the relationship between "name and occurrence times", and then find the name corresponding to the most occurrence times.
#Initialize empty dictionary
dict={}
#Split string
words=s.split()
#Traverse the elements in the dictionary
for i in words:
dict[i]=dict.get(i,0)+1
max_name,max_cnt="",0
#Traversal dictionary
for k in dict:
if dict[k] > max_cnt:
max_name,max_cnt=k,dict[k]
print(max_name)
#There is another way to be concise
#The results are represented in a list. Each item is a tuple and stores key and value
#result=list(dict.items())
#You can also use the sort function to sort
#result.sort(key=lambda x:x[1],reverse=True)
#print(result[0][0])