1, Read and return html tree from URL
1.1 rcull package
Using the Rcurl package, you can easily send requests to the server and capture URI, get and post forms. It provides a higher level of interaction than R socket connection, and supports FTP/FTPS/TFTP, SSL/HTTPS,telnet and cookies. The functions used in this article are basicTextGatherer and getURL. To learn more about this package, click the resources link.
R command:
h <- basicTextGatherer( ) # View the header information returned by the server
txt <- getURL(url, headerfunction = h$update,.encoding="UTF-8...") # Return html in string formThe parameter url is the url to be accessed. Here, the parameter uses the header information returned by the previous command with headerfunction Encoding specifies that the encoding method of the web page is "UTF-8".
There are many ways to encode web pages, generally using UTF-8. Some Chinese web pages are encoded as "gbk", which can be seen in the web page code of the browser or the string returned by getURL.
Small wood bug web page code view

It can be seen that the coding method of woodworm web page is gbk.
1.2 XML package
The R language XML package has the function of reading or creating XML (HTML) files. It can local files, support HTTP or FTP, and also provide Xpath(XML path language) parsing methods. The function htmlparse here parses the file into an XML or HTML tree to facilitate further data extraction or editing.
R command:
htmlParse(file,asText=T,encoding="UTF-8"...) #The parameter file is the XML or HTML file name or text, the asText parameter is T, specifies that the file is text, and encoding specifies the encoding method of the web page.
Here we need to read the web page and get the html Tree content
Custom function download,input strURL,strURL For web address, return html Tree content
download <- function(strURL){
h <- basicTextGatherer( )# View the header information returned by the server
txt <- getURL(strURL, headerfunction = h$update,.encoding="gbk") ## String form
htmlParse(txt,asText=T,encoding="gbk") #Select gbk to parse web pages
}2, Get all the URL s of a web page
Sometimes we need to enter the sub links on each web page to get the analysis data. At this time, we can use the getHTMLLinks function of the XML package.
R command:
getHTMLLinks(doc, xpQuery = "//a/@href"...) #doc is the parsed HTML tree file, and xpQuery specifies the Xpath element to match
(I'll talk about the basics of Xpath in detail below).
Here we need to get links to all topics under the "tutor enrollment" page of xiaomuchong.
2.1 first of all, we need to get the website of the first page, the second page, the third page and even the last page of the tutor's enrollment.
Tutor enrollment home page

Tutor enrollment page 2, page 3.


The home page URL is http://muchong.com/html/f430.html , the rest of the URLs match http://muchong.com/html/f430_ +Page + html
So we can edit the website manually.
strURLs="http://muchong.com/html/f430.html"
n=50
strURLs <- c(strURLs,paste(rep("http://muchong.com/html/f430_",n),c(2:n),".html",sep=""))
strURLs includes all 1 to 50 pages of tutor enrollment web sites.
2.2 get links to multiple topics in each page of tutor enrollment
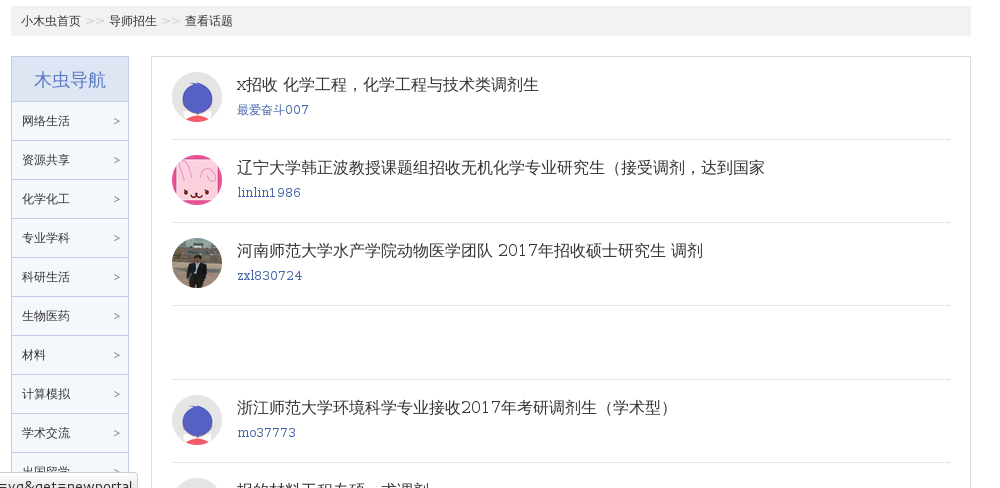
There are many topics under the tutor enrollment page. We need to get links to each topic.
Use the getHTMLLinks function to view all URLs in the tutor enrollment, and then compare the topic URL.

http://muchong.com/html/201702/11075436.html
Discovery topic URL is a component of http://muchong.com/ + html/201702/11075436.html like URL
At this time, I first extract all URLs from the tutor enrollment page, and then match HTML * HTML format URL, finally preceded by http://muchong.com/ Strategy for.
The custom greg function is used for regular matching and gets the matching string.
greg <- function(pattern,istring){
gregout <- gregexpr(pattern,istring) #Pattern is the matching pattern and istring is the string to be matched
substr(istring,gregout[[1]],gregout[[1]]+attr(gregout[[1]],'match.length')-1)
}
The user-defined extradress function is used to extract the URL in the strURL web page, and finally process the links returning to each topic web page.
extradress <- function(strURL){
prefix <- "http://muchong.com/"
pattern <- "html/[0-9/]+.html"
links <- getHTMLLinks(strURL)
needlinks <- gregexpr(pattern,links)
needlinkslist <- list()
for (i in which(unlist(needlinks)>0)){
preadress <- substr(links[i],needlinks[[i]],needlinks[[i]]+attr(needlinks[[i]],'match.length')-1)
needlinkslist<- c(needlinkslist,list(preadress))
adresses <- lapply(needlinkslist,function(x)paste(prefix,x,sep=""))
}
return (adresses)
}
3, Get the data we want from the HTML tree
3.1 basic knowledge of XML documents
The following is part of the small wood bug html:

html is the root element, head and body are the child elements of html, div is the child element of body, div has attribute ID and style, and the attribute is followed by the attribute value. "Wood bug" -- "line is the text content of the p element.
3.2 get the content of an element
The getNodeSet function and getNodeSet function in the XML package are used here
R command:
getNodeSet(doc, path...) #doc
Is the html tree file object, and path is the element path. You can use / / to specify a path layer by layer from the root element, or you can use / / to directly locate an element layer.
For example, to locate the div under the body under html, the path is / html/body/div, or / / body/div can be located directly from the body. Returns a list. If you navigate to multiple elements, a list of multiple elements will be returned. This time we want to set the topic content to the web page:

Here we go directly to the p element and filter it from the list.
Enter the command first
getNodeSet(doc,'//p')

getNodeSet(doc,'//p')[[2]] is what we need.

However, the returned result is an object. To convert it into a string, you need to use the function xmlValue to obtain the element value.
xmlValue(x...) # x is the object obtained by getNodeSet
here
xmlValue(getNodeSet(a,'//p')[[2]]) get what we want

At this time, when we get the content of each topic, we can extract effective information from the content, whether to recruit and adjust, university name, tutor name, research direction, contact person, email, telephone, etc.
4, Example of obtaining dispensing information from small wood insect
My junior sister is a biology major student who needs to be adjusted. Now she needs to extract the information published by others from xiaomuchong website and make it into a form for screening, viewing and sending emails.
The following is the full code content
library(RCurl)
library(XML)
download <- function(strURL){
h <- basicTextGatherer()# View header information returned by the server
txt <- getURL(strURL, headerfunction = h$update,.encoding="gbk") ## String form
htmlParse(txt,asText=T,encoding="gbk") #Select gbk to parse web pages
}
extradress <- function(strURL){
prefix <- "http://muchong.com/"
pattern <- "html/[0-9/]+.html"
links <- getHTMLLinks(strURL)
needlinks <- gregexpr(pattern,links)
needlinkslist <- list()
for (i in which(unlist(needlinks)>0)){
preadress <- substr(links[i],needlinks[[i]],needlinks[[i]]+attr(needlinks[[i]],'match.length')-1)
needlinkslist<- c(needlinkslist,list(preadress))
adresses <- lapply(needlinkslist,function(x)paste(prefix,x,sep=""))
}
return (adresses)
}
gettopic <- function(doc){
xmlValue(getNodeSet(doc,'//p')[[2]])
}
greg <- function(pattern,istring){
gregout <- gregexpr(pattern,istring)
substr(istring,gregout[[1]],gregout[[1]]+attr(gregout[[1]],'match.length')-1)
}
getinf <- function(topic){
pattern1 <- "Recruit[\u4E00-\u9FA5]+[0-9-]*[\u4E00-\u9FA5]*[: ,;,,;]*[\u4E00-\u9FA5]*[: ,;,,;]*[\u4E00-\u9FA5]*[: ,;,,;]*[\u4E00-\u9FA5]*[: ,;,,;]*[\u4E00-\u9FA5]*(graduate student)|(Adjust)"
pattern2 <- "([\u4E00-\u9FA5]*research group|[\u4E00-\u9FA5]*team)"
pattern21 <- "[\u4E00-\u9FA5]*[: ,;,,;]*(professor|doctor)"
pattern3 <- "[\u4E00-\u9FA5]*[: ,;,,;]*[-A-Za-z0-9_.%]+@[-A-Za-z0-9_.%]+\\.[A-Za-z]+[.A-Za-z]*"
#Match @ 163 Com or @ ABC edu. Cn two types of mailboxes
pattern4 <- "[\u4E00-\u9FA5]+teacher" #Match a teacher
pattern5 <- "[\u4E00-\u9FA5]*[: :]*1[3,5,8]{1}[0-9]{1}[0-9]{8}|0[0-9]{2,3}-[0-9]{7,8}(-[0-9]{1,4})?" #Match contacts and numbers
pattern6 <- "(main|be engaged in)*[\u4E00-\u9FA5]*(Research|direction)by*[: ,;,,;]*[\u4E00-\u9FA5]*"
pattern7 <- "[\u4E00-\u9FA5]+(university|college|research institute|graduate school)"
pattern8 <-"[-A-Za-z0-9_.%]+@[-A-Za-z0-9_.%]+\\.[A-Za-z]+[.A-Za-z]*" #Exact match mailbox
cate <- greg(pattern1,topic)
proj <- greg(pattern2,topic)
PI <- greg(pattern21,topic)
email <- greg(pattern3,topic)
man <- greg(pattern4,topic)
phone <- greg(pattern5,topic)
direc <- greg(pattern6,topic)
univ <- greg(pattern7,topic)
print(cate)
if (greg("(molecule|biology|Botany|Cells|Medical Science|animal|water)+",topic) !=""){
if (man =="" && proj != ""){
man <- unlist(strsplit(proj,"research group")[1])
}
if (email != ""){
email <- greg(pattern10,email)
}
data.frame("category"=cate,"university"=univ,"topic"=proj,"PI"=PI,"contacts"=man,"mailbox"=email,"direction"=direc,"Telephone"=phone)
}
else{
return("")
}
}
strURLs="http://muchong.com/html/f430.html"
n=50
dat <- data.frame("URL"="URL","category"="category","university"="university","topic"="topic","PI"="PI","contacts"="contacts","mailbox"="mailbox","direction"="direction","Telephone"="Telephone")
strURLs <- c(strURLs,paste(rep("http://muchong.com/html/f430_",n),c(2:n),".html",sep=""))
output1 <- "a2017.2.21.txt" #Unprocessed data for further processing
output2 <- "b2017.2.21.txt" #Further filtered data for viewing
for ( strURL in strURLs){
adresses <- extradress(strURL)
for (adress in adresses){
message(adress)
doc <- download(adress)
topic <- gettopic(doc)
inf <- getinf(topic)
if (inf != ""){
URL <- data.frame("URL"=adress)
inf <- cbind(URL,inf)
dat<- rbind(dat,inf)
}
}
}
write.table(dat, file = output1, row.names = F, col.names=F,quote = F, sep="\t") # tab delimited files
message("Done!")
dat <- read.table(output1,sep="\t",header=T)
dat <- dat[dat$mailbox, ] #Remove no mailbox data
dat <- dat[!duplicated(dat$mailbox), ] #Remove duplicate mailbox data
dat$index <- as.numeric(rownames(dat))
dat <- dat[order(dat$index,decreasing=F),] #Reorder the disordered data according to index
dat$index <- NULL
write.table(dat, file = output2, row.names = F, col.names=F,quote = F, sep="\t") # tab delimited files
message("Done!") Finally, I wish all those who take the postgraduate entrance examination can be successfully admitted by their favorite school!
reference material:
Rcurl package: https://cran.r-project.org/web/packages/RCurl/RCurl.pdf
XML package: https://cran.r-project.org/web/packages/XML/XML.pdf
XML Basics: http://www.cnblogs.com/thinkers-dym/p/4090840.html